
GA-StackingMD: Android Malware Detection Method Based on Genetic Algorithm Optimized Stacking


Abstract
:1. Introduction
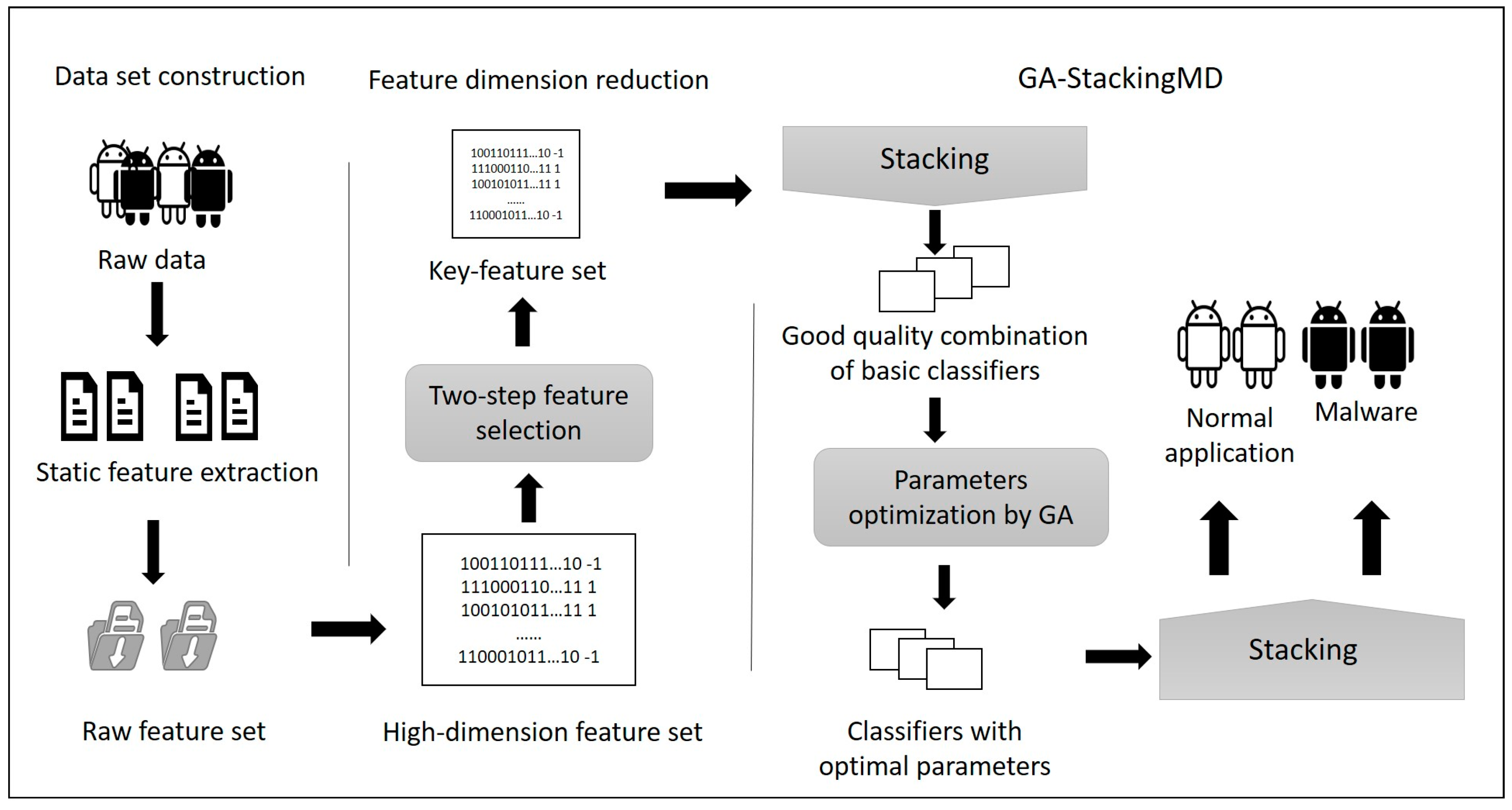
- An Android malware detection framework based on Stacking is proposed. The framework mainly includes three parts: data set construction, feature dimension reduction, and optimization method GA-StackingMD. By Stacking technology, five base classifiers are integrated to combine their advantages in order to improve malware detection performance;
- A two-step feature dimension reduction method is realized. The extracted multiple-category features have high dimensions, which may lead to redundancy, excessive computational consumption, and even over-fitting. The proposed method uses InfoGain for first feature detection and then applies Chi-square Test to reduce redundancy; finally, the key features subset with better distinguishing ability is constructed;
- A Stacking hyperparameters’ optimization method, GA-Stacking MD, is presented to improve the classifiers’ combination performance. Experiments show it achieves better accuracy than the original combination of base classifiers. The proposed method is not only applicable to the optimization of stacking hyperparameters but also can be extended to apply to different integrated classifiers’ optimization, so as to play a role in different base classifier algorithm environments.
2. Related Work
2.1. Android Malware Detection
2.2. Features of Android Malware Detection
2.3. Feature Selection and Genetic Algorithm
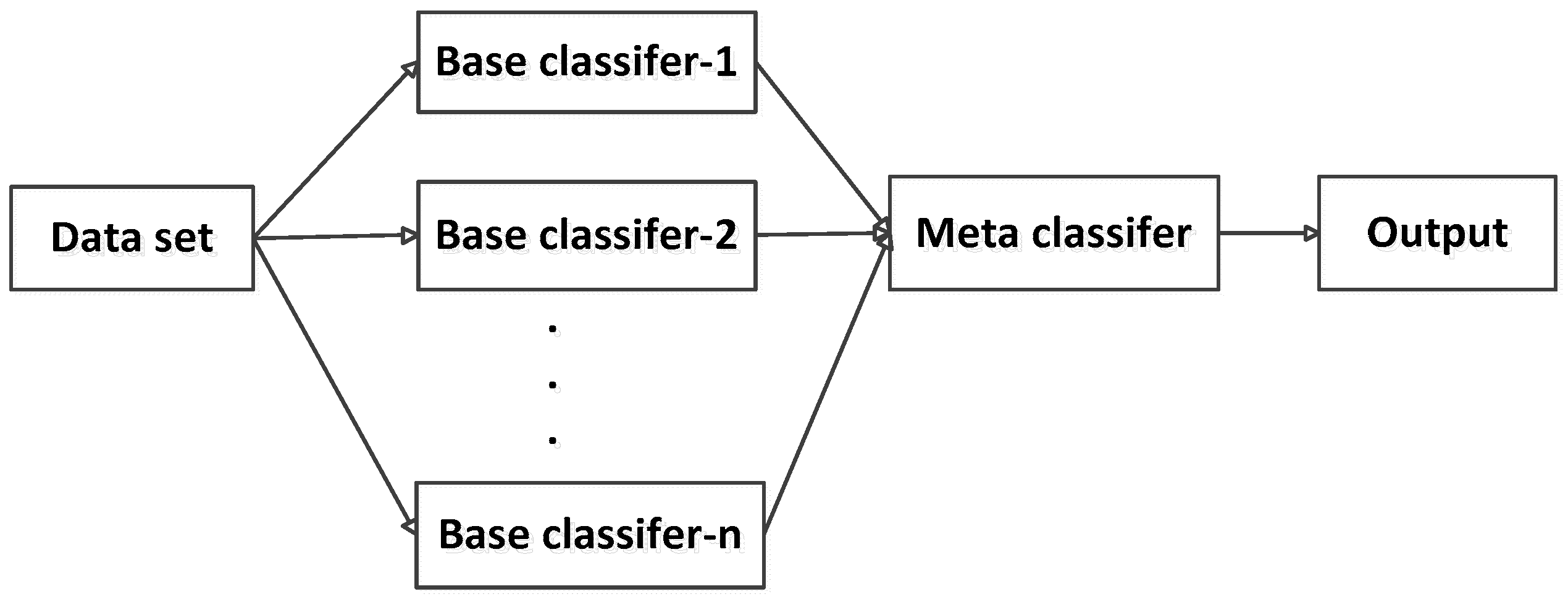
2.4. Stacking
3. Android Malware Detection Method
3.1. The GA-StackingMD Framework
- Data set construction. The Android application is decompiled and static features are extracted, including Permission, API, Dalvikopcode, Intent, and Hardware. Then the extracted features are digitized to construct the original feature set with high dimensions;
- Feature dimension reduction. A two-step feature selection method is proposed to reduce the original feature dimension. InfoGain is used for the primary election, then Chi-square Test is applied for further reduction to remove redundant and irrelevant features. The final key feature subset contains the selected features with low dimensional and good differentiation;
- GA-StackingMD. An optimization algorithm based on GA is presented to select the hyperparameters of base classifiers of Stacking. After selecting the better combination of base classifiers, GA is used to adaptively adjust the hyperparameters in a given scope, and finally, improve the malware detection performance.
3.2. Feature Processing
3.2.1. Feature Extraction
3.2.2. Two-Step Feature Selection
3.3. GA-StackingMD
3.3.1. Training the First Layer Classifiers
3.3.2. Training the Second Layer Classifier
3.3.3. Optimizing Hyperparameters by GA
3.4. GA-StackingMD Description
4. Experiments
4.1. Experimental Environment and Evaluation Index
4.2. Experiment Steps
4.2.1. Key Feature Subset Construction
4.2.2. Compare Stacking with Single Classifiers
4.2.3. The Optimized Combination of Base Classifier Selection
4.2.4. Hyperparameters’ Optimization by GA
4.2.5. Comparison of GA-StackingMD and Other Classifiers
4.3. Comparison with Literature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mobile Operating System Market Share Worldwide. Available online: https://gs.statcounter.com/os-market-share/mobile/worldwide (accessed on 30 October 2022).
- Mobile Malware Evolution. 2021. Available online: https://securelist.com/mobile-malware-evolution-2021/105876/ (accessed on 15 November 2022).
- Tsfaty, C.; Fire, M. Malicious Source Code Detection Using Transformer. arXiv 2022, arXiv:2209.07957. [Google Scholar]
- Gao, Y.; Lu, Z.; Luo, Y. Survey on malware anti-analysis. In Proceedings of the Fifth International Conference on Intelligent Control and Information Processing, Dalian, China, 18–20 August 2014; pp. 270–275. [Google Scholar]
- Singh, J.; Singh, J. A survey on machine learning-based malware detection in executable files. J. Syst. Archit. 2021, 112, 101861. [Google Scholar] [CrossRef]
- Qiang, W.; Yang, L.; Jin, H. Efficient and Robust Malware Detection Based on Control Flow Traces Using Deep Neural Networks. Comput. Secur. 2022, 122, 102871. [Google Scholar] [CrossRef]
- Lindorfer, M.; Neugschwandtner, M.; Platzer, C. Marvin: Efficient and comprehensive mobile app classification through static and dynamic analysis. In Proceedings of the 2015 IEEE 39th Annual Computer Software and Applications Conference, Taichung, Taiwan, 1–5 July 2015; pp. 422–433. [Google Scholar]
- Zhu, H.; Li, Y.; Li, R.; Li, J.; Song, H. SEDMDroid: An enhanced stacking ensemble of deep learning framework for Android malware detection. IEEE Trans. Netw. Sci. Eng. 2020, 8, 984–994. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, L.; Zhao, K.; Ding, X.; Yu, M. MFDroid: A Stacking Ensemble Learning Framework for Android Malware Detection. Sensors 2022, 22, 2597. [Google Scholar] [CrossRef]
- Cen, L.; Gates, C.S.; Si, L.; Li, N. A probabilistic discriminative model for android malware detection with decompiled source code. IEEE Trans. Dependable Secur. Comput. 2014, 12, 400–412. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; pp. 11–20. [Google Scholar]
- Singh, D.; Karpa, S.; Chawla, I. “Emerging Trends in Computational Intelligence to Solve Real-World Problems” Android Malware Detection Using Machine Learning. In Proceedings of the International Conference on Innovative Computing and Communications: Proceedings of ICICC 2021, Delhi, India, 20–21 February 2021; pp. 329–341. [Google Scholar]
- Vashishtha, L.K.; Chatterjee, K.; Sahu, S.K.; Mohapatra, D.P. A Random Forest-Based Ensemble Technique for Malware Detection. In Proceedings of the Information Systems and Management Science: Conference Proceedings of 4th International Conference on Information Systems and Management Science (ISMS) 2021, Msida, Malta, 14–15 December 2021; pp. 454–463. [Google Scholar]
- Wang, Z.; Li, K.; Hu, Y.; Fukuda, A.; Kong, W. Multilevel permission extraction in android applications for malware detection. In Proceedings of the 2019 International Conference on Computer, Information and Telecommunication Systems (CITS), Beijing, China, 28–31 August 2019; pp. 1–5. [Google Scholar]
- Peiravian, N.; Zhu, X. Machine learning for android malware detection using permission and api calls. In Proceedings of the 2013 IEEE 25th International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 4–6 November 2013; pp. 300–305. [Google Scholar]
- Han, W.; Xue, J.; Wang, Y.; Huang, L.; Kong, Z.; Mao, L. MalDAE: Detecting and explaining malware based on correlation and fusion of static and dynamic characteristics. Comput. Secur. 2019, 83, 208–233. [Google Scholar] [CrossRef]
- de la Puerta, J.G.; Sanz, B. Using dalvik opcodes for malware detection on android. Log. J. IGPL 2017, 25, 938–948. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Qin, Z.; Zhang, K.; Yin, H.; Zou, J. Dalvik opcode graph based android malware variants detection using global topology features. IEEE Access 2018, 6, 51964–51974. [Google Scholar] [CrossRef]
- Sewak, M.; Sahay, S.K.; Rathore, H. Comparison of deep learning and the classical machine learning algorithm for the malware detection. In Proceedings of the 2018 19th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Busan, Republic of Korea, 27–29 June 2018; pp. 293–296. [Google Scholar]
- Feizollah, A.; Anuar, N.B.; Salleh, R.; Suarez-Tangil, G.; Furnell, S. Androdialysis: Analysis of android intent effectiveness in malware detection. Comput. Secur. 2017, 65, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Santos, I.; Devesa, J.; Brezo, F.; Nieves, J.; Bringas, P.G. Opem: A static-dynamic approach for machine-learning-based malware detection. In Proceedings of the International Joint Conference CISIS’12-ICEUTE’ 12-SOCO’ 12 Special Sessions, Ostrava, Czech Republic, 5–7 September 2012; pp. 271–280. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Maulik, U.; Bandyopadhyay, S. Genetic algorithm-based clustering technique. Pattern Recognit. 2000, 33, 1455–1465. [Google Scholar] [CrossRef]
- Mala, C.; Sridevi, M. Multilevel threshold selection for image segmentation using soft computing techniques. Soft Comput. 2016, 20, 1793–1810. [Google Scholar] [CrossRef]
- Cpalka, K.; Łapa, K.; Przybył, A. A new approach to design of control systems using genetic programming. Inf. Technol. Control 2015, 44, 433–442. [Google Scholar] [CrossRef]
- Qiang, X.J. Computer application under the management of network information security technology using genetic algorithm. Soft Comput. 2022, 26, 7871–7876. [Google Scholar] [CrossRef]
- Changxing, Q.; Yiming, B.; Yong, L. Improved BP neural network algorithm model based on chaos genetic algorithm. In Proceedings of the 2017 3rd IEEE International Conference on Control Science and Systems Engineering (ICCSSE), Beijing, China, 17–19 August 2017; pp. 679–682. [Google Scholar]
- Elhefnawy, R.; Abounaser, H.; Badr, A. A hybrid nested genetic-fuzzy algorithm framework for intrusion detection and attacks. IEEE Access 2020, 8, 98218–98233. [Google Scholar] [CrossRef]
- Yildiz, O.; Doğru, I.A. Permission-based android malware detection system using feature selection with genetic algorithm. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 245–262. [Google Scholar] [CrossRef]
- Sesmero, M.P.; Ledezma, A.I.; Sanchis, A. Generating ensembles of heterogeneous classifiers using stacked generalization. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 21–34. [Google Scholar] [CrossRef]
- Zheng, R.; Wang, Q.; Lin, Z.; Jiang, Z.; Fu, J.; Peng, G. Cryptocurrency malware detection in real-world environment: Based on multi-results stacking learning. Appl. Soft Comput. 2022, 124, 109044. [Google Scholar] [CrossRef]
- Jiang, W.; Chen, Z.; Xiang, Y.; Shao, D.; Ma, L.; Zhang, J. SSEM: A novel self-adaptive stacking ensemble model for classification. IEEE Access 2019, 7, 120337–120349. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Kadir, A.; Taheri, L.; Ghorbani, A.A. Toward Developing a Systematic Approach to Generate Benchmark Android Malware Datasets and Classification. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; pp. 1–7. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic Android Malware Category Classification using Semi-Supervised Deep Learning. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Rutkowski, L.; Jaworski, M.; Pietruczuk, L.; Duda, P. The CART decision tree for mining data streams. Inf. Sci. 2014, 266, 1–15. [Google Scholar] [CrossRef]
- Taud, H.; Mas, J. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Cham, Switzerland, 2018; pp. 451–455. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Arslan, R.S. Identify Type of Android Malware with Machine Learning Based Ensemble Model. In Proceedings of the 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 21–23 October 2021; pp. 628–632. [Google Scholar]
- Atacak, İ.; Kılıç, K.; Doğru, İ.A. Android malware detection using hybrid ANFIS architecture with low computational cost convolutional layers. PeerJ Comput. Sci. 2022, 8, e1092. [Google Scholar] [CrossRef]
- Lu, T.; Wang, J. F2DC: Android malware classification based on raw traffic and neural networks. Comput. Netw. 2022, 217, 109320. [Google Scholar]
- Shakya, S.; Dave, M. Analysis, Detection, and Classification of Android Malware using System Calls. arXiv 2022, arXiv:2208.06130. [Google Scholar]
- Ullah, F.; Alsirhani, A.; Alshahrani, M.M.; Alomari, A.; Naeem, H.; Shah, S.A. Explainable malware detection system using transformers-based transfer learning and multi-model visual representation. Sensors 2022, 22, 6766. [Google Scholar] [CrossRef]
- Ksibi, A.; Zakariah, M.; Almuqren, L.A.; Alluhaidan, A.S. Deep Convolution Neural Networks and Image Processing for Malware Detection. Preprint (Version 1). 27 January 2023. Available online: https://www.researchsquare.com/article/rs-2508967/v1 (accessed on 4 February 2023).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| SVM | 94.83% | 87.55% | 91.34% | 84.06% |
| KNN | 91.69% | 78.71% | 88.29% | 71.01% |
| LGBM | 96.08% | 90.57% | 94.49% | 86.96% |
| CatBoost | 95.30% | 88.28% | 95.76% | 81.88% |
| RandomForest | 94.04% | 84.92% | 93.86% | 77.54% |
| Stacking | 96.55% | 91.60% | 96.77% | 86.96% |
| Classifiers | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| SVM | 98.24% | 98.82% | 98.78% | 98.86% |
| KNN | 97.85% | 98.57% | 98.44% | 98.69% |
| LGBM | 98.34% | 98.89% | 98.75% | 99.03% |
| CatBoost | 98.11% | 98.74% | 98.50% | 98.98% |
| RandomForest | 97.75% | 98.49% | 98.41% | 98.58% |
| Stacking | 98.56% | 99.03% | 98.98% | 99.09% |
| Models | Accuracy | F1-Scores | Precision | Recall |
|---|---|---|---|---|
| [‘RF’, ‘CATTREE’] | 89.34% | 68.22% | 79.35% | 59.84% |
| [‘RF’] | 89.5% | 68.84% | 79.57% | 60.66% |
| [‘CATTREE’] | 89.81% | 73.03% | 73.95% | 72.13% |
| ... | ... | ... | ... | ... |
| [‘RF’, ‘CATTREE’, ‘LGBM’] | 93.57% | 80.38% | 96.55% | 68.85% |
| [‘RF’, ‘LGBM’] | 93.57% | 80.38% | 96.55% | 68.85% |
| [‘CATTREE’, ‘LGBM’] | 93.57% | 80.38% | 96.55% | 68.85% |
| [‘SVM’, ‘LGBM’] | 93.57% | 80.38% | 96.55% | 68.85% |
| [‘KNN’, ‘LGBM’] | 94.67% | 85.59% | 88.6% | 82.79% |
| Classifiers | Hyperparameter Ranges |
|---|---|
| KNN | knn_n_neighbors = [2, 4, 6, 8, 10, 12, 14, 16] |
| LGBM | lgbm_max_depths = [4, 5, 6, 7, 8, 9, 10, −1] |
| lgbm_n_estimators = [60, 80, 100, 120, 140, 160, 200, 240] | |
| RF | rf_max_depths = [4, 5, 6, 7, 8, 9, 10, 11] |
| rf_n_estimators = [50, 60, 70, 80, 90, 100, 110, 120] |
| Data Set | Classifiers | Best Hyperparameters |
|---|---|---|
| CIC-AndMal2017 | KNN | knn_n_neighbors = 2 |
| LGBM | lgbm_max_depths = −1 | |
| lgbm_n_estimators = 80 | ||
| CICMalDroid2020 | KNN | knn_n_neighbors = 4 |
| LGBM | lgbm_max_depths = 6 | |
| lgbm_n_estimators = 160 | ||
| RF | rf_max_depths = 11 | |
| rf_n_estimators = 80 |
| Reference | Year | Data Sets | Experiment Description |
|---|---|---|---|
| [40] | 2021 | CIC-AndMal2017 | Feature Type: Permission Classifier: Ensemble model (ET, XGB, and RF) Experimental Result: Accuracy—90.40%; Precision—90.40%; Recall—90.40%; F1-score—90.40% |
| [41] | 2022 | Drebin CICMalDroid2020 | Feature Type: Permission Classifier: CNN and ANFIS (CNN, adaptive network-based fuzzy inference system) Experimental Result: Accuracy—92.00%, 94.67%; Precision—92.15%, 94.78%; Recall—92.00%, 94.67%; F1-score—92.01%, 94.66% |
| [42] | 2022 | Drebin CIC-MalDroid2020 | Feature Type: Network Traffic Classifier: F2DC (A novel traffic encoding scheme called F2D and CNN) Experimental Result: Precision—96.30%, 82.06%; Recall—96.03%, 81.60%; F1-score—96.08%, 81.34% |
| [43] | 2022 | CIC-AndMal2017 | Feature Type: System Calls Classifier: DT, KNN, LR, SVM, MLP Experimental Result: Precision—85.00%; Recall—85.00%; F1-score—85.00% |
| [44] | 2022 | CICMalDroid2020 CIC-InvesAndMal2019 | Feature Type: Textual Features Analysis and Visual Features Analysis (Network-based byte streams) Classifier: Voting-Based Ensemble Learning (Gaussian Naive Bayes, SVM, DT, LR, RF) Experimental Result: Accuracy—97.76%, 98.44% |
| [45] | 2023 | CIC-AndMal2017 CICMalDroid2020 | Feature Type: The RGB graphics Classifier: CNN, DCNN(VGG-16) [46] Experimental Result: Accuracy—97.81%; Precision—97.98%; Recall—97.63%; F1-score—97.78% |
| This paper | 2023 | CIC-AndMal2017 CICMalDroid2020 | Feature Type: Permission, API, Dalvik opcode, Intent, and Hardware Classifier: GA-StackingMD (SVM, KNN, LGBM, CatBoost, and RF) Experimental Result: Accuracy—98.43%, 98.66%; Precision—98.28%, 99.15% Recall—93.44%, 99.06%; F1-score—95.80%, 99.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, N.; Qin, Z.; Di, X. GA-StackingMD: Android Malware Detection Method Based on Genetic Algorithm Optimized Stacking. Appl. Sci. 2023, 13, 2629. https://doi.org/10.3390/app13042629
Xie N, Qin Z, Di X. GA-StackingMD: Android Malware Detection Method Based on Genetic Algorithm Optimized Stacking. Applied Sciences. 2023; 13(4):2629. https://doi.org/10.3390/app13042629
Chicago/Turabian StyleXie, Nannan, Zhaowei Qin, and Xiaoqiang Di. 2023. "GA-StackingMD: Android Malware Detection Method Based on Genetic Algorithm Optimized Stacking" Applied Sciences 13, no. 4: 2629. https://doi.org/10.3390/app13042629
APA StyleXie, N., Qin, Z., & Di, X. (2023). GA-StackingMD: Android Malware Detection Method Based on Genetic Algorithm Optimized Stacking. Applied Sciences, 13(4), 2629. https://doi.org/10.3390/app13042629