1. Introduction
SLAM is a technology for self-positioning and environment map construction in unknown environments with sensors on machines [
1,
2,
3]. In the early research of SLAM, researchers described the problem of SLAM as a state estimation problem of spatial uncertainty, and used an extended Kalman filter (EKF), a particle filter (PF) and maximum likelihood estimation (MLE) to eliminate the uncertainty in the process of positioning and mapping [
4,
5,
6]. In 2009, Lourakis and Argyros [
7] realized the sparsity and symmetric structure of the Hessian matrix in bundle adjustment (BA) and published their research results, which enabled BA to be accelerated. Since then, BA as the core graph optimization algorithm began to replace the filtering algorithm to become the mainstream method to eliminate uncertainty.
Visual SLAM (V-SLAM) uses the camera as the main sensor and only obtains input information from the image [
8,
9]. Compared with other LiDAR or inertial sensors, it has the advantages of rich information, low cost, lightweight and small volume. At present, V-SLAM is widely used in autonomous driving, AR (augmented reality)/VR (virtual reality), and other fields [
10,
11,
12]. The framework of V-SLAM is mainly divided into two parts: visual front-end and back-end optimization. The visual front-end is also commonly referred to visual odometry (VO) [
13,
14]. The main function of VO is to calculate the rough poses of the camera and generate new map points. The back-end optimization uses general graph optimization (
) [
15] to optimize the data passed from the front-end to eliminate random errors. There are two kinds of VO: the feature-based method and the direct method. The feature-based method extracts representative points from the frames and then uses them to estimate the camera poses and build the map. The feature-based method has high robustness because it can still identify the same points when the scene and camera perspective slightly change. However, for the feature point with higher robustness, its calculation consumes higher resources. The representative SLAM of the feature-based method is the ORB-SLAM series algorithms [
16,
17]. The direct method SLAM estimates the pose and builds the map according to the brightness information of the pixels, which consumes fewer resources. The direct SLAM can generate a dense or semi-dense map. However, it is sensitive to the image quality [
18,
19,
20]. Direct sparse odometry (DSO) [
21] is the representative SLAM of the direct method SLAM. At present, the feature-based method is the mainstream method of VO in V-SLAM.
At present, most of the high robustness and high efficiency of V-SLAM are achieved in a static environment. However, the real world is complex and dynamic most of the time. The movement of people, animals and vehicles may cause V-SLAM to fail in feature matching and loop closure detection. To deal with these problems, researchers have come up with various processing methods to find moving objects in images [
22,
23]. One method is based on deep learning, and the other is based on consistency detection.
Deep-learning-based methods use deep neural networks to identify objects that are thought to move with high probability, such as Mask R-CNN [
24], SegNet [
25] and you only look once (YOLO) [
26,
27] and then track and maintain these objects or cover them with a mask [
28,
29]. To reduce the impact of the neural network on the real-time performance of V-SLAM, some researchers run the neural network in an independent thread [
23,
30] or just use the neural network in some specifically selected frames and spread the detection results to other frames by feature points matching [
31,
32,
33]. More recent methods based on deep learning tend to go further by not just removing the dynamic foreground, but also inpainting or reconstructing the static background that is occluded by moving targets [
34,
35,
36]. Benefiting from the rapid advances in deep learning and easy embedding into V-SLAM, this kind of dynamic SLAM works well in most scenarios. However, low running rate and inability to deal with objects that the neural network has not yet trained are two unavoidable disadvantages that need more research. Therefore, this paper focuses on the real-time V-SLAM method, which is not based on deep learning.
For the method based on consistency detection, researchers search for consistency between static backgrounds or dynamic objects, such as geometric or physical consistency and so on. Compared with learning-based dynamic V-SLAM, this kind of SLAM usually has better real-time performance. Some researchers try to find the dynamic objects in a single scene. Alcantarilla et al. [
37] used scene flow to distinguish moving objects from the static scene, and the calculation of the scene flow was based on a result estimated by VO. Li and Lee [
38] presented an RGB-D SLAM based on static point weighting (SPWSLAM), which extracted the feature points at the depth edges of the RGB-D frames. In addition, some studies have tried to use multi-scene contrast to find dynamic objects. For example, Kerl et al. [
39] proposed dense visual odometry and SLAM (DVO), which found the dynamic region by minimizing the photometric error between two consecutive RGB-D frames and used a robust error function to reduce the influence of large residuals. Kim and Kim [
40] presented an effective background model-based DVO, which obtained the static region in images by computing the depth differences between consecutive RGB-D frames. Sun et al. [
41] proposed a novel motion removal SLAM (MotionRemove), which computed the camera ego-motion using RANSAC-based homography estimation with two consecutive RGB-D images. Then, the moving-object motions are roughly detected by subtracting the current RGB-D frame with the ego-motion-compensated last RGB-D frame. Dai et al. [
42] proposed a dynamic SLAM (DSLAM), which used Delaunay triangulation to connect mapped points to surrounding points and then treated the two points that remain connected in the next several frames as two points on the same rigid object, finally assuming the largest set of points that remain connected as a static background.
There are some other improved V-SLAM methods based on consistency detection. For example, Zou and Tan [
43] used two moving cameras to identify dynamic objects and considered the objects tracked successfully by one camera but unsuccessfully by the other camera in successive frames as moving objects but did not consider the occlusion problem under different viewing angles. Zhang et al. [
44] used PWC-net to obtain optical flow from RGB-D images. The error of optical flow was also judged by the initial relative poses of the front and back frames, and the optical flow with a large error was regarded as a dynamic object. Based on the KinectFusion dense SLAM system, Palazzolo et al. [
45] calculated the residual of each pixel and then obtained the approximate dynamic region by adaptive threshold segmentation, finally obtaining the final dynamic region and the static background map by morphological processing. However, it still needs a lot of research on parameter judgment and threshold setting. It is worth noting that many researchers are trying to use both deep learning and consistency detection in dynamic SLAM.
As introduced above, the dynamic SLAM using consistency detection can usually run at high speed, but it is usually not guaranteed to completely screen out the small dynamic region in the image, and it is still disturbed in some scenes where objects are moving slowly. Thus, we propose an improved V-SLAM to reduce the impact of moving objects in a dynamic environment. In the proposed method, a concept of map point reliability is presented, which is used to describe the map points with high observation times as reliable map points. In addition, a concept of unreliable map points is presented, which is used to define the map points with fewer observation times. Based on the two concepts of the map points, we deal with those obvious and unobvious dynamic objects in V-SLAM.
The main contributions of this paper are as follows: (1) An improved V-SLAM method based on ORB-SLAM3 is proposed, which can not only retain its original performance but also work well in dynamic environments. (2) A mixed strategy combining new map points screening with repeated exiting map points elimination is proposed to identify obviously dynamic map points. (3) The strategy utilizes map point reliability to identify unobviously dynamic map points. (4) Extensive experiments demonstrate the benefits of the processing strategies for dynamic objects in the V-SLAM method. The proposed method achieves accuracy that outperforms the state-of-the-art real-time V-SLAM methods on the TUM RGB-D dataset.
The rest of this paper is structured as follows:
Section 2 introduces the framework of our proposed V-SLAM method in detail.
Section 3 reports the experiment results evaluated on the TUM dataset. The conclusions and future work are given in
Section 4.
2. Proposed Method
In this section, we introduce the overall framework of our proposed SLAM system.Then, we introduce the concept of map points reliability and our two main improvements using this concept in a dynamic environment.
2.1. Framework of Our Method
Our method is based on ORB-SLAM3, which has been proven to be efficient in static environments [
16,
46]. ORB-SLAM3 is the first open-source SLAM system capable of performing vision, visual inertia, and multiple maps with monocular, binocular, and RGB-D cameras using pinhole or fisheye camera models. ORB-SLAM3 includes four parts: atlas, tracking thread, local mapping thread and loop and map merging thread. Its biggest advantage is that it allows matching and using observations made before BA, enabling data association in the short, medium and long term. However, ORB-SLAM3 is designed to run in a static environment or a very slightly dynamic environment. ORB-SLAM3 calculates the pose of the current frame through feature matching and
algorithm in the tracking thread. When it comes to a dynamic environment, the number of correct matching points between two dynamic feature points significantly increases, exceeding the range that the
algorithm can optimize. Because of this, ORB-SLAM3 cannot perform well in a dynamic environment.
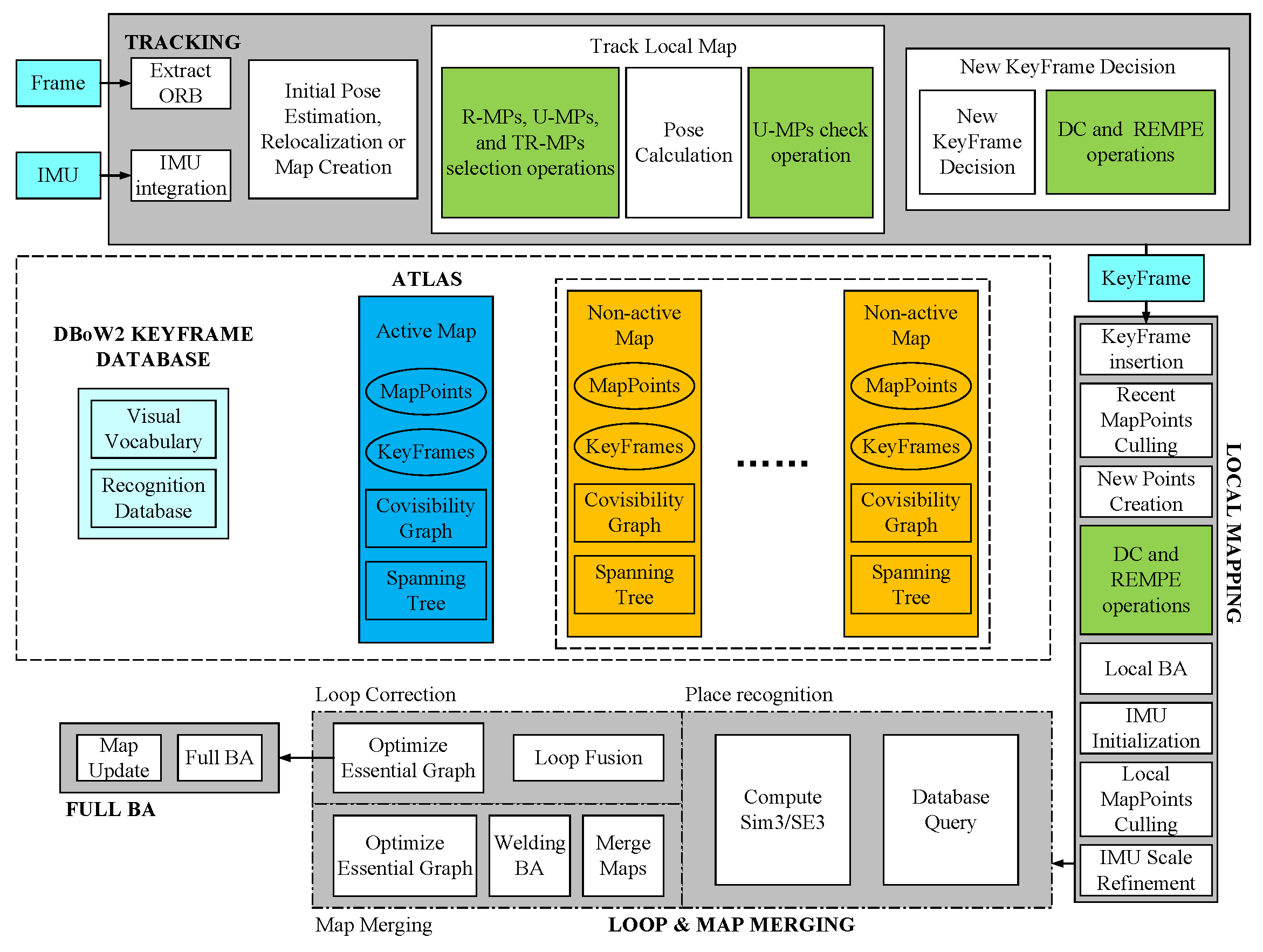
The framework of our proposed algorithm is shown in
Figure 1, which is introduced as follows. (1) ATLAS: It is a multi-map representation composed of a set of disconnected maps. Only the activated map is used by the tracking thread and optimized by the local mapping thread. (2) TRACKING: This thread processes sensor information and computes the pose of the current frame according to the active map in real-time by reliable map points and temporary reliable map points, minimizing the reprojection error of the matched map features, checking the reliability of unreliable map points, selecting the new keyframe and handling the new map points. (3) Local mapping: This thread adds keyframes and points to the active map, removes the redundant ones and refines the map using visual or visual-inertial bundle adjustment and operating in a local window of keyframes close to the current frame. New map points generated in this thread will be processed in the same way as new map points in the tracking thread. (4) Loop and map merging: This thread detects common regions between the active map and the whole ATLAS at the keyframe rate. (5) Loop correction: This thread will be performed if the common area belongs to the active map. Otherwise, SLAM merges non-activated items into the active map, then runs a full BA in an independent thread.
The basic workflow of the proposed method is the same as ORB-SLAM3. However, there are some differences between the proposed method and the traditional ORB-SLAM3. In the proposed method, the map points are divided into three categories, namely the reliable map points (R-MPs), the unreliable map points (U-MPs) and the temporary reliable map points (TR-MPs). Based on this classification of map points, some novel map points processing strategies are added to the framework of ORB-SLAM3, including a map point selection operation, an unreliable map point check operation, etc. In this section, only the different parts of the proposed method are introduced in detail.
2.2. New Map Points Processing Strategy
The algorithm in this section mainly deals with new map points. In the general ORB-SLAM3 algorithm, new map points may have similar descriptors to existing map points, or they may be influenced by a mismatch in the dynamic environment or two frames that are too close together in triangulation, which will lead to generating a wrong coordinate. To deal with this problem, we propose a new map points processing (called NMPP) strategy. In this strategy, for each new map point, we perform the following two operations, namely a distance check and a repeated existing map points elimination operation.
2.2.1. Distance Check Operation
While ORB-SLAM3 runs in a dynamic environment, if the dynamic objects occupy most of the field of view, the new map point will be generated at an error coordinate caused by a mismatch or wrong triangulation. They are clustered around the camera’s photo center, as shown in
Figure 2.
Therefore, after generating new map points, we need to perform a distance check operation (called DC) to calculate the Euclidean distance between the map point and the camera, which is described as follows:
where
is the distance between map point and camera,
is the coordinate of the map point, and
is the translation of the camera at this time. Then, the map points whose distance is lower than the threshold are eliminated.
2.2.2. Repeated Existing Map Points Elimination Operation
When SLAM runs in a dynamic environment, dynamic landmarks may leave repeated map points in the map point set, whereas the original ORB-SLAM3 has no mechanism to deal with this problem. So, we add a repeated existing map points elimination operation (called REMPE) to the ORB-SLAM. As shown in
Figure 3, if the moving map points are not removed in time, they will leave a large number of outdated map points in the map point set of the SLAM system, which represent the objects that have passed through these places. Therefore, before a new map point is added to the map point set, it is necessary to eliminate the existing similar map points.
Directly traversing all the map points in the map point set one by one is time-consuming work, which seriously affects the real-time performance of the SLAM system. As the map has more points, it will take a longer time. The ORB-SLAM3 system uses DBoW2 [
47] to accelerate loopback detection, reference keyframe tracking and relocation tracking. In this paper, we use the existing DBoW2 bag of words model in ORB-SLAM3 to calculate the NodeId of each map point when each map point is generated by the SLAM system. Then, each of these new map points is compared with the existing map points that have the same NodeId. A similar score is described as:
where
d is the description of the current map point,
is the description of one map point which has the same NodeId as the current map point, and
is the score function which is in integer form.
The specific steps of the proposed repeated existing map points elimination operation are: the SLAM system finds the remaining map points whose similarity with the descriptor is within the threshold range (which is set as 0.5 in this study) and then removes them from the map point atlas. The pseudocode of the proposed operation is shown in Algorithm 1.
2.3. Unreliable Map Points Processing Strategy
The algorithm in this section mainly deals with map points left in SLAM by landmarks that are not moving fast enough. As we know, the traditional V-SLAM uses the PnP (perspective-n-point) method to calculate the pose of a frame, which is as follows:
where the
p is the feature point extracted from the current frame and is a projection of a landmark in the real world,
is the camera calibration and distortion parameters,
P is a map point of the same landmark which is generated in the previous frame, and
T is the pose of the current frame. In a static environment,
P can always be treated as a landmark. However, when it comes to dynamic environments,
P can only represent the map point of the landmark at the previous time. Although
p and
P can be matched through the description, this matched pair cannot be used for pose calculation.
| Algorithm 1 Repeated map points elimination operation |
Input:P: New map points in current frame; : A set of all map points in the active map; - 1:
for each do - 2:
%Compute the node serial number (denoted by ) of P; - 3:
; - 4:
% is the algorithm of DBoW2; - 5:
; - 6:
%Get the map points set in at the same as p; - 7:
for each do - 8:
if then - 9:
% is the score function; is the description of the current map point p; - 10:
if then - 11:
% is the flag to denote whether s has been checked before; - 12:
Break; - 13:
else - 14:
; - 15:
end if - 16:
end if - 17:
end for - 18:
end for - 19:
for each do - 20:
; - 21:
; - 22:
%Insert p into the end of ; - 23:
end for
|
To deal with this problem, we propose an unreliable map points processing strategy (called UMPP). As we know, in feature-based visual SLAM, matching pairs of map points and projection points are used to calculate the pose of the camera in each frame. There are correct matches and mismatches in these matching pairs, but not all matching pairs in the current frame are needed. The proposed UMPP strategy can be described as follows:
where
is the reliable part of map points, and
is the unreliable part of map points. As shown in
Figure 4, the idea of the proposed UMPP strategy is that we can calculate the pose of the camera with reliable map points (regardless of whether they are mismatches) and then calculate the reprojection of the rest of the map points with unknown reliability at this pose.
In the proposed V-SLAM method, we set the map points which have not been checked three times as unreliable map points (called U-MPs). If the error between the reprojection coordinate and the corresponding feature point coordinate is within the threshold range, the current unknown reliability point is considered to pass the check at this time. Otherwise, the current map point is considered a dynamic map point (called D-MP), which needs to be eliminated from the current frame. Finally, the U-MPs whose reliability exceeds the threshold are set as the reliable map points (called R-MPs).
It is noted that within an early period of time when SLAM is running, we cannot find any reliable map points, so the map points matched by these frames can be set as R-MPs only by passing the test described in
Section 2.2.
2.3.1. Map Points Selection Operation
In the stage of pose calculation, we use R-MPs to calculate the pose. However, in the actual processing, we need a certain number of matching point pairs to achieve enough redundancy. When the number of these R-MPs is insufficient, we need to choose some temporary reliable points (called TR-MPs) from the map points for pose calculation. So, we propose a map point selection operation (MPS). The basic idea of MPS is introduced as follows.
We think that a point has a higher probability of being reliable if most of the points around it are reliable. Our method is to triangulate all feature points in the current frame by the Delaunay triangulation. Triangulation is the process of obtaining a set of triangles from a set of planar points. Delaunay triangulation is one of the best triangulations with a lot of advantages, including maximizing the minimum angles of the triangles and forming a triangle with the closest three points. With the Delaunay triangulation, each point is connected to its surrounding points by edges. We rank the map points from greatest to smallest in terms of their overall reliability with the surrounding points, and the top 20% of the map points are set as TR-MPs to calculate the frame pose. The details of the proposed MPS operation are shown as Algorithm 2.
| Algorithm 2 The proposed MPS operation |
Input:P: Map points in current frame; Output:: Temporary reliable map points; - 1:
; - 2:
% is the function used to get the set of feature points of P; - 3:
; - 4:
% is the function used to convert a point set to a triangle set; - 5:
for each do - 6:
= { }; %Set up a sub triangle set; - 7:
for each do - 8:
if then - 9:
; %Insert t into the end of ; - 10:
end if - 11:
end for - 12:
= Get_U(); - 13:
%Get_U(·) is the function used to get all unique points in ; - 14:
; - 15:
for each do - 16:
- 17:
%Get the reliability of the map point with the feature point ; - 18:
if then - 19:
% is the flag to denote whether belongs to a reliable map point; - 20:
- 21:
else - 22:
- 23:
end if - 24:
end for - 25:
; % denotes the reliability weight of the feature point p; - 26:
end for - 27:
P = Sort(P); - 28:
%Sort the map points according to the reliability weight of their feature point; - 29:
= Select(P); - 30:
%Select the top 20 percent of P as ;
|
The examples of the proposed MPS operation based on the Delaunay triangulation are shown in
Figure 5. The green points are the feature points of R-MPs, which are used for pose calculation. The blue and red points are the feature points of TR-MPs and U-MPs, respectively. Finally, it should be noted that there is no R-MP in the early stage of SLAM. So, we set all the U-MPs as TR-MPs in this stage.
2.3.2. Unreliable Map Points Check Operation
After calculating the pose of the current frame, we present an unreliable map points check (UMPC) operation. The details of the proposed UMPC operation are introduced as follows.
First, we calculate the reprojection points of the U-MPs by the pose of the current frame. Then, we calculate the Euclidean distance between each projection point and its corresponding feature point. Map points whose distance exceeds the threshold will be removed from the current frame.
The proposed SLAM can work in three modes: RGB-D, monocular and stereo. For each frame, the coordinate of the unreliable map point is ; the observation point of the map point in the RGB-D image is , and the observation point of map point in mono image and left or right camera in stereo is .
Thus, for the map point observed by the RGB-D camera, the reprojection
of
in the normalized plane is calculated by
and for the right camera in stereo, the equation is
where
is the right-to-left transformation matrix.
Then, the coordinate of projection point
of
in the image from the RGB-D camera is shown as follows:
while for the point in a mono camera and a left or right stereo camera, the
is calculated by:
where
are the internal parameters of the camera.
The error between the reprojection point
and the observation point
p is shown as follows:
where
is the effective coefficient, and in this paper, it is the scaling coefficient of the pyramid layer where the ORB feature point is located.
To test whether the error exceeds the threshold ▵, we use a chi-square distribution, as described by
where
k is the degree of freedom, and
x is the degree of confidence. Since the dimension of the matching point of RGB-D is 3, and the 3 dimensions are independent of each other, we take the degree of freedom
, and the degree of confidence
. For mono and stereo images, we set
, and
. If
exceeds the chi-square statistic, it is considered that the reprojection of the map point under the current pose is inconsistent with the original matching point, and it will be moved.
The workflow of the proposed map points processing in the proposed method is shown in
Figure 6.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}