

Predicting Location of Tweets Using Machine Learning Approaches
 ,
,  ,
,
Abstract
:1. Introduction
2. Related Works
2.1. The Purpose of Tweets’ Location Prediction
2.2. Geo-Location Prediction Approaches
3. Data Collection and Preparation
3.1. Data Collection
3.2. Data Cleansing
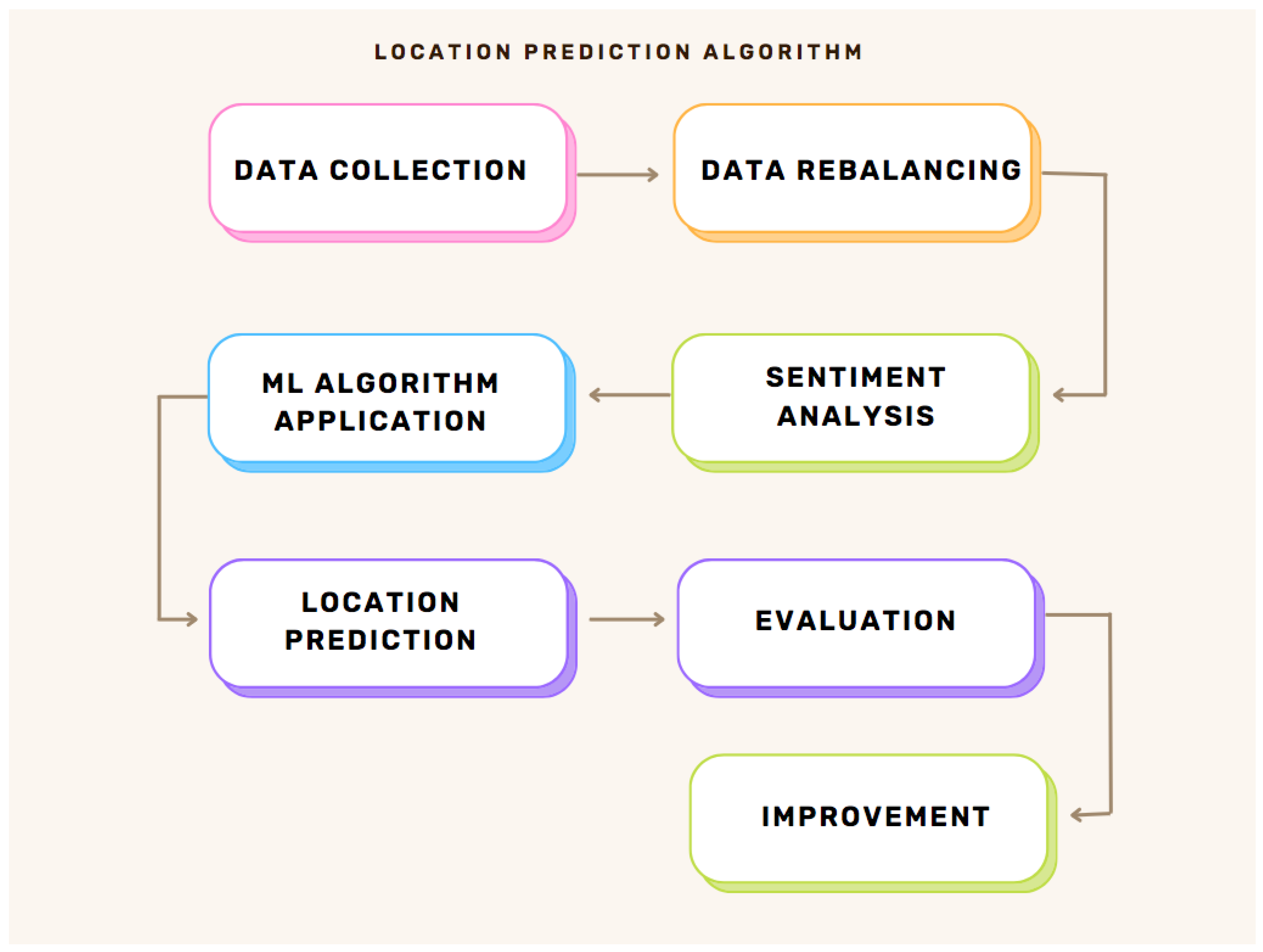
4. Methodology
4.1. Location Prediction Using Tweet Text and Home Location
4.2. Location Prediction Using Tweet Text and Named Entity
4.3. Location Prediction Using Tweet Text, Home Location, and Named Entity
4.4. Model Building
4.5. Pairwise Distance Matrix
5. Experiments and Results
5.1. Relevance of Geo-Tagging Features
5.2. Impact of Data Quality and Machine Learning Models
5.3. Comparison with Other Research Works
5.4. Challenges in Improving Accuracy Further
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GMM | Gaussian Mixture Mode. |
| VSM | Vector Space Mode. |
| TF-IDF | Term Frequency-Inverse Document Frequency. |
| CNN | Convolutional Neural Network. |
| W-NUT | Workshop on Noisy User-generated Text. |
| LR | Logistic Regression. |
| MNB | Multinomial Naive Bayes. |
| SVM | Support Vector Machine. |
| RF | Random Forest. |
Appendix A

References
- Statista. Number of Active Twitter Users. Available online: https://www.statista.com (accessed on 22 December 2022).
- Abbasi, M.A.; Chai, S.K.; Liu, H.; Sagoo, K. Real-world behavior analysis through a social media lens. In Proceedings of the International Conference on Social Computing Behavioral-Cultural Modeling, and Prediction, College Park, MD, USA, 3–5 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 18–26. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. Real-time event detection from the Twitter data stream using the TwitterNews+ Framework. Inf. Process. Manag. 2019, 56, 1146–1165. [Google Scholar] [CrossRef]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. Eventweet: Online localized event detection from twitter. Proc. VLDB Endow. 2013, 6, 1326–1329. [Google Scholar] [CrossRef]
- Weng, J.; Lee, B.S. Event detection in twitter. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Alhumoud, S. Twitter Analysis for Intelligent Transportation. Comput. J. 2019, 62, 1547–1556. [Google Scholar] [CrossRef]
- Hu, B.; Ester, M. Spatial topic modeling in online social media for location recommendation. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, 12–16 October 2013; pp. 25–32. [Google Scholar]
- Rakesh, V.; Reddy, C.K.; Singh, D. Location-specific tweet detection and topic summarization in twitter. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013; pp. 1441–1444. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K. You are where you tweet: A content-based approach to geo-locating twitter users. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 759–768. [Google Scholar]
- Ao, J.; Zhang, P.; Cao, Y. Estimating the locations of emergency events from Twitter streams. Procedia Comput. Sci. 2014, 31, 731–739. [Google Scholar] [CrossRef] [Green Version]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: A survey. ACM Comput. Surv. 2015, 47, 67. [Google Scholar] [CrossRef]
- Graham, M.; Hale, S.A.; Gaffney, D. Where in the world are you? Geolocation and language identification in Twitter. Prof. Geogr. 2014, 66, 568–578. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Han, J.; Sun, A. A survey of location prediction on twitter. IEEE Trans. Knowl. Data Eng. 2018, 30, 1652–1671. [Google Scholar] [CrossRef] [Green Version]
- Sloan, L.; Morgan, J. Who tweets with their location? Understanding the relationship between demographic characteristics and the use of geoservices and geotagging on Twitter. PLoS ONE 2015, 10, e0142209. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–29 July 2011; pp. 1524–1534. [Google Scholar]
- Liu, X.; Wei, F.; Zhang, S.; Zhou, M. Named entity recognition for tweets. ACM Trans. Intell. Syst. Technol. 2013, 4, 3. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, S.; Wei, F.; Zhou, M. Recognizing named entities in tweets. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 359–367. [Google Scholar]
- Malmasi, S.; Dras, M. Location mention detection in tweets and microblogs. In Proceedings of the Conference of the Pacific Association for Computational Linguistics, Bali, Indonesia, 19–21 May 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 123–134. [Google Scholar]
- Jurgens, D.; Finethy, T.; McCorriston, J.; Xu, Y.T.; Ruths, D. Geolocation prediction in twitter using social networks: A critical analysis and review of current practice. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Poulston, A.; Stevenson, M.; Bontcheva, K. Hyperlocal home location identification of twitter profiles. In Proceedings of the 28th ACM Conference on Hypertext and Social Media, Prague, Czech Republic, 4–7 July 2017; pp. 45–54. [Google Scholar]
- Mahmud, J.; Nichols, J.; Drews, C. Where is this tweet from? inferring home locations of twitter users. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012. [Google Scholar]
- Ukkusuri, S.V.; Yang, C. Transportation Analytics in the Era of Big Data; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Chang, H.w.; Lee, D.; Eltaher, M.; Lee, J. @ Phillies tweeting from Philly? Predicting Twitter user locations with spatial word usage. In Proceedings of the 2012 International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2012), Istanbul, Turkey, 26–29 August 2012; pp. 111–118. [Google Scholar]
- Eisenstein, J.; O’Connor, B.; Smith, N.A.; Xing, E.P. A latent variable model for geographic lexical variation. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 1277–1287. [Google Scholar]
- Mahmud, J.; Nichols, J.; Drews, C. Home location identification of twitter users. ACM Trans. Intell. Syst. Technol. 2014, 5, 47. [Google Scholar] [CrossRef] [Green Version]
- Flatow, D.; Naaman, M.; Xie, K.E.; Volkovich, Y.; Kanza, Y. On the accuracy of hyper-local geotagging of social media content. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 127–136. [Google Scholar]
- Wing, B.P.; Baldridge, J. Simple supervised document geolocation with geodesic grids. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 955–964. [Google Scholar]
- Roller, S.; Speriosu, M.; Rallapalli, S.; Wing, B.; Baldridge, J. Supervised text-based geolocation using language models on an adaptive grid. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju, Republic of Korea, 12–14 July 2012; pp. 1500–1510. [Google Scholar]
- Kinsella, S.; Murdock, V.; O’Hare, N. I’m eating a sandwich in Glasgow: Modeling locations with tweets. In Proceedings of the 3rd International Workshop on Search and Mining User-Generated Contents, Glasgow, UK, 28 October 2011; pp. 61–68. [Google Scholar]
- Paraskevopoulos, P.; Palpanas, T. Fine-grained geolocalisation of non-geotagged tweets. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Paris, France, 25–28 August 2015; pp. 105–112. [Google Scholar]
- Hulden, M.; Silfverberg, M.; Francom, J. Kernel density estimation for text-based geolocation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Mostafa, A.; Gad, W.; Abdelkader, T.; Badr, N. Pre-HLSA: Predicting home location for Twitter users based on sentimental analysis. Ain Shams Eng. J. 2022, 13, 101501. [Google Scholar] [CrossRef]
- Mahajan, R.; Mansotra, V. Predicting geolocation of tweets: Using combination of CNN and BiLSTM. Data Sci. Eng. 2021, 6, 402–410. [Google Scholar] [CrossRef] [PubMed]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Kibriya, A.M.; Frank, E.; Pfahringer, B.; Holmes, G. Multinomial naive bayes for text categorization revisited. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Cairns, Australia, 4–6 December 2004; Springer: Berlin/Heidelberg, Germany; pp. 488–499. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 2005; Volume 177. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Latitude | Longitude | User | Home Location | Text |
|---|---|---|---|---|---|
| 1**6 | 21.5**945 | 39.13**93 | S**il | Abha, Saudi Arabia | مركز الذكاء الاصطناعي في جامعة الملك خالد “The Artificial Intelligence Center at King Khalid University.” https://t.co/p***1Mdt  #Abha |
| Explanation | Number of Tweets | Percent |
|---|---|---|
| Total number of collected tweets from trending hashtags in Saudi Arabia | 50,000,000 | 100% |
| Total number of tweets with geo-tags | 253,673 | 0.5% |
| Total number of tweets with geo-tags in Saudi Arabia | 39,418 | 0.08% |
| Total number of unique tweets with geo-tags in Saudi Arabia | 35,110 | 0.07% |
| Total number of tweets after eliminating tweets that correspond to locations with less than five users or less than 70 tweets | 33,545 | 0.067% |
| Total number of user profiles with home location | 1,946,306 | 3.9% |
| City | Latitude | Longitude | Class Label |
|---|---|---|---|
| Abha | 18.2164282 | 42.5043596 | 1 |
| Al Ahsa | 23.3036077 | 50.1258804 | 2 |
| Al Bahah | 20 | 41.5 | 3 |
| Al Jubayl | 27.0006968 | 49.6532161 | 4 |
| Al Kharj Industrial City | 23.9163832 | 47.28131291 | 5 |
| Al Kharma | 21.916667 | 42.5 | 6 |
| Al Khobar | 26.3039999 | 50.1960237 | 7 |
| Al Udayd | 22.5 | 51 | 8 |
| Al Kharj | 24.148333 | 47.305 | 9 |
| Ar Ar | 130.9815531 | 41.0164788 | 10 |
| Ar Rass | 25.8685205 | 43.5038978 | 11 |
| At Taif | 21.270278 | 40.415833 | 12 |
| Az Zahran | 26.2966528 | 50.1202146 | 13 |
| Baljurshi | 19.859444 | 41.557222 | 14 |
| Baqaa | 27.5 | 42.5 | 15 |
| Bisha | 20 | 42.6 | 16 |
| Boriydah | 26.27657425 | 43.32498065 | 17 |
| Buraydah 1 | 26.331667 | 43.971667 | 18 |
| Dammam | 26.4367824 | 50.1039991 | 19 |
| Jeddah | 21.59734945 | 39.13362779 | 20 |
| Hafar Al Batin 2 | 27.901429 | 45.5283442 | 21 |
| Medina | 24.471153 | 39.6111216 | 22 |
| Ohd Rofida | 19.166667 | 43.166667 | 23 |
| Rafha | 29.6324189 | 43.5178685 | 24 |
| Riyadh | 24.6319692 | 46.7150648 | 25 |
| Sabyaa | 17.333333 | 42.666667 | 26 |
| Sakakah | 29.7851094 | 40.0354435 | 27 |
| Sharoura | 18 | 45.666667 | 28 |
| Tabuk | 27.5 | 37.333333 | 29 |
| Yanbu | 24.0889015 | 38.0666798 | 30 |
| اَ | فتحه | Fath |
| اِ | كسره | Kasr |
| اُ | ضمه | Damma |
| اّ | شده | Shadda |
 | سكون | Sukun |
| أ إ آ | ا | أكرم اكرم |
| ـة | ـه | طباعة طباعه |
| ي | ى | علي على |
| Tweet Text | Ent1 | Ent2 | Ent3 | Ent4 | Ent5 | Ent6 |
|---|---|---|---|---|---|---|
| موعدنا معكم غدا احد دوره تاثير مرض سكري على اعصاب مع استشاري طب اعصاب د احمد *** مستشفى سعودي *** حائل ‘Tomorrow is our appointment with Dr. Ahmed *** in Saudi *** Hospital Hail’ | حائل ‘Hail’ | - | - | - | - | - |
| امطار رياض اعتقد ما فيه اجمل من انك تصحى على صوت مطر ‘Riyadh rains, I think it is nothing more beautiful than to wake up to the sound of rain’ | رياض ‘Riyadh’ | مطر ‘Rains’ | - | - | - | - |
| اجواء ساحره في منطقه جنوبيه امطار خير وبركه ابها نماص تنومه باحه مندق بلجرشي اطاوله علايا بشاير ‘Charming weather in the southern region, good rain, a blessing Abha Namas Tanoma, you sleep in the courtyard of the hotel, Baha, the height of Alaya Bashyer’ | أجواء ‘weather’ | جنوبيه ‘Southern’ | ابها ‘Abha’ | نماص ‘Namas’ | تنومه ‘Tanoma’ | باحه ‘Baha’ |
| الى اين مالذي يشغل بالك ‘Where are you on your mind’ | - | - | - | - | - | - |
| Location Prediction Using Tweet Text and Home Location | Location Prediction Using Tweet Text and Named Entity | Location Prediction Using Tweet Text, Home Location, and Named Entity | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Distance | LR | RF | NB | SVM | LR | RF | NB | SVM | LR | RF | NB | SVM |
| 0 | 50.79 | 64.50 | 37.66 | 54.57 | 23.65 | 41.78 | 21.42 | 27.72 | 53.26 | 64.55 | 42.64 | 55.96 |
| 20 | 51.64 | 65.11 | 38.55 | 55.30 | 24.17 | 41.95 | 21.93 | 28.11 | 54.07 | 65.18 | 43.53 | 56.71 |
| 40 | 51.67 | 65.12 | 38.59 | 55.32 | 24.23 | 41.97 | 21.99 | 28.14 | 54.09 | 65.19 | 43.57 | 56.73 |
| 60 | 51.74 | 65.16 | 38.68 | 55.38 | 24.25 | 41.98 | 22.06 | 28.17 | 54.16 | 65.23 | 43.65 | 56.79 |
| 80 | 52.27 | 65.54 | 39.22 | 55.87 | 24.61 | 42.12 | 22.44 | 28.44 | 54.66 | 65.61 | 44.20 | 57.23 |
| 100 | 54.02 | 66.61 | 41.69 | 57.12 | 26.82 | 43.69 | 25.02 | 30.21 | 56.22 | 66.68 | 46.64 | 58.42 |
| 120 | 54.10 | 66.66 | 41.88 | 57.19 | 26.89 | 43.72 | 25.15 | 30.26 | 56.30 | 66.73 | 46.80 | 58.50 |
| 140 | 55.32 | 67.29 | 43.13 | 58.53 | 28.31 | 44.58 | 26.37 | 31.77 | 57.42 | 67.39 | 47.99 | 59.76 |
| 160 | 55.39 | 67.31 | 43.22 | 58.58 | 28.44 | 44.64 | 26.49 | 31.88 | 57.48 | 67.41 | 48.09 | 59.81 |
| 180 | 55.74 | 67.53 | 43.60 | 58.86 | 28.73 | 44.80 | 26.78 | 32.14 | 57.82 | 67.63 | 48.42 | 60.07 |
| 200 | 56.26 | 67.72 | 44.28 | 59.32 | 29.49 | 45.06 | 27.52 | 32.88 | 58.33 | 67.86 | 49.04 | 60.52 |
| 220 | 56.46 | 67.78 | 44.51 | 59.45 | 29.77 | 45.14 | 27.82 | 33.05 | 58.49 | 67.92 | 49.26 | 60.64 |
| 240 | 56.71 | 67.88 | 44.81 | 59.67 | 30.21 | 45.25 | 28.23 | 33.39 | 58.74 | 68.00 | 49.55 | 60.85 |
| 260 | 56.74 | 67.88 | 44.89 | 59.68 | 30.24 | 45.26 | 28.32 | 33.41 | 58.77 | 68.00 | 49.63 | 60.86 |
| 280 | 56.77 | 67.89 | 45.00 | 59.70 | 30.33 | 45.28 | 28.45 | 33.47 | 58.80 | 68.01 | 49.73 | 60.87 |
| 300 | 57.35 | 68.19 | 45.73 | 60.10 | 30.99 | 45.58 | 29.15 | 33.97 | 59.29 | 68.32 | 50.40 | 61.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsaqer, M.; Alelyani, S.; Mohana, M.; Alreemy, K.; Alqahtani, A. Predicting Location of Tweets Using Machine Learning Approaches. Appl. Sci. 2023, 13, 3025. https://doi.org/10.3390/app13053025
Alsaqer M, Alelyani S, Mohana M, Alreemy K, Alqahtani A. Predicting Location of Tweets Using Machine Learning Approaches. Applied Sciences. 2023; 13(5):3025. https://doi.org/10.3390/app13053025
Chicago/Turabian StyleAlsaqer, Mohammed, Salem Alelyani, Mohamed Mohana, Khalid Alreemy, and Ali Alqahtani. 2023. "Predicting Location of Tweets Using Machine Learning Approaches" Applied Sciences 13, no. 5: 3025. https://doi.org/10.3390/app13053025
APA StyleAlsaqer, M., Alelyani, S., Mohana, M., Alreemy, K., & Alqahtani, A. (2023). Predicting Location of Tweets Using Machine Learning Approaches. Applied Sciences, 13(5), 3025. https://doi.org/10.3390/app13053025