
Dimension Reduction and Redundancy Removal through Successive Schmidt Decompositions



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. The Motivation
1.1.1. Mapping Data into Quantum States to Run on Quantum Computers
1.1.2. Classical Simulation of Quantum Circuits and Designing More Efficient Quantum Circuits
2. The Schmidt Decomposition and Its Recursion Tree Structure
2.1. Singular Value Decomposition (SVD) [25]
2.2. Schmidt Decomposition [30,31]
2.3. Quantum Operations
- Let be an matrix. First, we vectorize matrix (column- or row-based vectorization can be used. In this paper, we will assume row-based vectorization.):
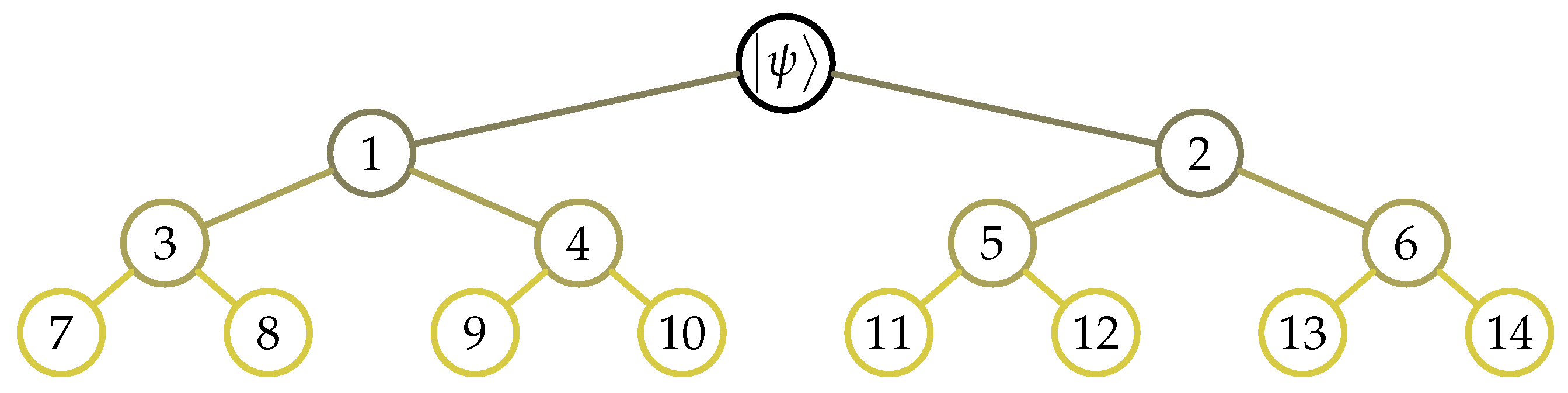
- Then we draw the recursion tree as in Figure 1.
- Since each path from the root to a leaf node is a by 1 vector, we can convert these terms back to by matrices. In that case, we can write as in the form:
- Note that the number of paths is equal to the number of leaf nodes, which is for a vector of dimension .
- To convert a tensor decomposition of a vector into an operator in tensor form, let us consider the following example term:Assuming and s are column vectors of dimension 2; from the definitions in Equations (1) and (2), we can convert this term into an operator as follows:Here, each is a 2 by 2 matrix and is not unitary. However, they can be written as a sum of two unitary matrices.
3. Approximation by Removing the Number of Paths with Smaller Coefficients
3.1. Approximation of Gram Matrix
import numpy as np
n = 8
N = 2**n
dist = "normal"
rng = np.random.default_rng()
if dist == "normal":
X = rng.normal(size = (N,N))
elif dist == "uniform":
X = rng.uniform(size = (N,N))
elif dist == "exponential":
X = rng.exponential(size = (N,N))
elif dist == "poisson":
X = rng.poisson(size = (N,N))
3.1.1. Applications in Data Science
3.1.2. Applications to Solve Systems of Linear Equations
3.2. Approximation of the Symmetric Matrix
3.3. Approximation of the Quantum (or Discrete) Fourier Transform
3.4. Data Having a Type of Circular Distributions
3.5. Approximation of the Variational Quantum Circuits
3.6. Approximation of Hamiltonians
4. Computations with the Schmidt Forms
4.1. Classical Computation
4.2. Quantum Computation

5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grover, L.K. Quantum mechanics helps in searching for a needle in a haystack. Phys. Rev. Lett. 1997, 79, 325. [Google Scholar] [CrossRef] [Green Version]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; pp. 124–134. [Google Scholar]
- Montanaro, A. Quantum algorithms: An overview. NPJ Quantum Inf. 2016, 2, 1–8. [Google Scholar] [CrossRef]
- Aaronson, S. How Much Structure Is Needed for Huge Quantum Speedups? arXiv 2022, arXiv:2209.06930. [Google Scholar]
- Pirnay, N.; Ulitzsch, V.; Wilde, F.; Eisert, J.; Seifert, J.P. A super-polynomial quantum advantage for combinatorial optimization problems. arXiv 2022, arXiv:2212.08678. [Google Scholar]
- Szegedy, M. Quantum advantage for combinatorial optimization problems, Simplified. arXiv 2022, arXiv:2212.12572. [Google Scholar]
- Kitaev, A.Y. Quantum computations: Algorithms and error correction. Russ. Math. Surv. 1997, 52, 1191. [Google Scholar] [CrossRef]
- Dawson, C.M.; Nielsen, M.A. The Solovay-Kitaev algorithm. Quantum Inf. Comput. 2006, 6, 81–95. [Google Scholar] [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Hillar, C.J.; Lim, L.H. Most tensor problems are NP-hard. J. ACM 2013, 60, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Pardalos, P.M.; Vavasis, S.A. Quadratic programming with one negative eigenvalue is NP-hard. J. Glob. Optim. 1991, 1, 15–22. [Google Scholar] [CrossRef]
- Kak, S.C. Quantum neural computing. Adv. Imaging Electron Phys. 1995, 94, 259–313. [Google Scholar]
- Bonnell, G.; Papini, G. Quantum neural network. Int. J. Theor. Phys. 1997, 36, 2855–2875. [Google Scholar] [CrossRef]
- Khan, A.; Mondal, M.; Mukherjee, C.; Chakrabarty, R.; De, D. A Review Report on Solar Cell: Past Scenario, Recent Quantum Dot Solar Cell and Future Trends. In Advances in Optical Science and Engineering; Springer: New Delhi, India, 2015; pp. 135–140. [Google Scholar]
- Zak, M.; Williams, C.P. Quantum neural nets. Int. J. Theor. Phys. 1998, 37, 651–684. [Google Scholar] [CrossRef]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum principal component analysis. Nat. Phys. 2014, 10, 631–633. [Google Scholar] [CrossRef] [Green Version]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 2015, 56, 172–185. [Google Scholar] [CrossRef] [Green Version]
- Khan, T.M.; Robles-Kelly, A. Machine learning: Quantum vs classical. IEEE Access 2020, 8, 219275–219294. [Google Scholar] [CrossRef]
- Tang, E. A quantum-inspired classical algorithm for recommendation systems. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, Phoenix, AZ, USA, 23–26 June 2019; pp. 217–228. [Google Scholar]
- Cong, I.; Choi, S.; Lukin, M.D. Quantum convolutional neural networks. Nat. Phys. 2019, 15, 1273–1278. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Stoudenmire, E.; White, S.R. The Quantum Fourier Transform Has Small Entanglement. arXiv 2022, arXiv:2210.08468. [Google Scholar]
- Huang, H.Y.; Broughton, M.; Mohseni, M.; Babbush, R.; Boixo, S.; Neven, H.; McClean, J.R. Power of data in quantum machine learning. Nat. Commun. 2021, 12, 2631. [Google Scholar] [CrossRef]
- Daskin, A. A walk through of time series analysis on quantum computers. arXiv 2022, arXiv:2205.00986. [Google Scholar]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Biamonte, J.; Bergholm, V. Tensor networks in a nutshell. arXiv 2017, arXiv:1708.00006. [Google Scholar]
- Biamonte, J. Lectures on quantum tensor networks. arXiv 2019, arXiv:1912.10049. [Google Scholar]
- Parrish, R.M.; Hohenstein, E.G.; Schunck, N.F.; Sherrill, C.D.; Martínez, T.J. Exact tensor hypercontraction: A universal technique for the resolution of matrix elements of local finite-range N-body potentials in many-body quantum problems. Phys. Rev. Lett. 2013, 111, 132505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Berry, D.W.; Gidney, C.; Huggins, W.J.; McClean, J.R.; Wiebe, N.; Babbush, R. Even more efficient quantum computations of chemistry through tensor hypercontraction. PRX Quantum 2021, 2, 030305. [Google Scholar] [CrossRef]
- Terhal, B.M.; Horodecki, P. Schmidt number for density matrices. Phys. Rev. A 2000, 61, 040301. [Google Scholar] [CrossRef] [Green Version]
- Kais, S. Entanglement, electron correlation, and density matrices. Adv. Chem. Phys. 2007, 134, 493. [Google Scholar]
- Eddins, A.; Motta, M.; Gujarati, T.P.; Bravyi, S.; Mezzacapo, A.; Hadfield, C.; Sheldon, S. Doubling the size of quantum simulators by entanglement forging. PRX Quantum 2022, 3, 010309. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Williams, C.K.; Cristianini, N.; Kandola, J. On the eigenspectrum of the Gram matrix and the generalization error of kernel-PCA. IEEE Trans. Inf. Theory 2005, 51, 2510–2522. [Google Scholar] [CrossRef] [Green Version]
- Ramona, M.; Richard, G.; David, B. Multiclass feature selection with kernel gram-matrix-based criteria. IEEE Trans. Neural Networks Learn. Syst. 2012, 23, 1611–1623. [Google Scholar] [CrossRef] [Green Version]
- Sastry, C.S.; Oore, S. Detecting out-of-distribution examples with gram matrices. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 8491–8501. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; Center for Machine Learning and Intelligent Systems: Irvine, CA, USA, 2017. [Google Scholar]
- Learned-Miller, G.B.H.E. Labeled Faces in the Wild: Updates and New Reporting Procedures; Technical Report UM-CS-2014-003; University of Massachusetts: Amherst, MA, USA, 2014. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Saad, Y. Iterative Methods for Sparse Linear Systems; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Yu, W.; Sun, J.; Han, Z.; Yuan, X. Practical and Efficient Hamiltonian Learning. arXiv 2022, arXiv:2201.00190. [Google Scholar]
- Haah, J.; Kothari, R.; Tang, E. Optimal learning of quantum Hamiltonians from high-temperature Gibbs states. arXiv 2021, arXiv:2108.04842. [Google Scholar]
- Krastanov, S.; Zhou, S.; Flammia, S.T.; Jiang, L. Stochastic estimation of dynamical variables. Quantum Sci. Technol. 2019, 4, 035003. [Google Scholar] [CrossRef] [Green Version]
- Evans, T.J.; Harper, R.; Flammia, S.T. Scalable bayesian hamiltonian learning. arXiv 2019, arXiv:1912.07636. [Google Scholar]
- Bairey, E.; Arad, I.; Lindner, N.H. Learning a local Hamiltonian from local measurements. Phys. Rev. Lett. 2019, 122, 020504. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.L.; Ranard, D. Determining a local Hamiltonian from a single eigenstate. Quantum 2019, 3, 159. [Google Scholar] [CrossRef] [Green Version]
- Gupta, R.; Selvarajan, R.; Sajjan, M.; Levine, R.D.; Kais, S. Hamiltonian learning from time dynamics using variational algorithms. arXiv 2022, arXiv:2212.13702. [Google Scholar]
- Gupta, R.; Xia, R.; Levine, R.D.; Kais, S. Maximal entropy approach for quantum state tomography. PRX Quantum 2021, 2, 010318. [Google Scholar] [CrossRef]
- Gupta, R.; Levine, R.D.; Kais, S. Convergence of a Reconstructed Density Matrix to a Pure State Using the Maximal Entropy Approach. J. Phys. Chem. A 2021, 125, 7588–7595. [Google Scholar] [CrossRef]
- Gupta, R.; Sajjan, M.; Levine, R.D.; Kais, S. Variational approach to quantum state tomography based on maximal entropy formalism. Phys. Chem. Chem. Phys. 2022, 24, 28870–28877. [Google Scholar] [CrossRef]
- Huggins, W.J.; O’Gorman, B.A.; Rubin, N.C.; Reichman, D.R.; Babbush, R.; Lee, J. Unbiasing fermionic quantum Monte Carlo with a quantum computer. Nature 2022, 603, 416–420. [Google Scholar] [CrossRef] [PubMed]
- Childs, A.M.; Wiebe, N. Hamiltonian simulation using linear combinations of unitary operations. arXiv 2012, arXiv:1202.5822. [Google Scholar] [CrossRef]
- Daskin, A.; Grama, A.; Kollias, G.; Kais, S. Universal programmable quantum circuit schemes to emulate an operator. J. Chem. Phys. 2012, 137, 234112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, D.W.; Childs, A.M.; Cleve, R.; Kothari, R.; Somma, R.D. Simulating Hamiltonian dynamics with a truncated Taylor series. Phys. Rev. Lett. 2015, 114, 090502. [Google Scholar] [CrossRef] [Green Version]
- Daskin, A.; Bian, T.; Xia, R.; Kais, S. Context-aware quantum simulation of a matrix stored in quantum memory. Quantum Inf. Process. 2019, 18, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Daskin, A. Quantum Circuit Design Methods and Applications. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2014. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daskin, A.; Gupta, R.; Kais, S. Dimension Reduction and Redundancy Removal through Successive Schmidt Decompositions. Appl. Sci. 2023, 13, 3172. https://doi.org/10.3390/app13053172
Daskin A, Gupta R, Kais S. Dimension Reduction and Redundancy Removal through Successive Schmidt Decompositions. Applied Sciences. 2023; 13(5):3172. https://doi.org/10.3390/app13053172
Chicago/Turabian StyleDaskin, Ammar, Rishabh Gupta, and Sabre Kais. 2023. "Dimension Reduction and Redundancy Removal through Successive Schmidt Decompositions" Applied Sciences 13, no. 5: 3172. https://doi.org/10.3390/app13053172