Abstract
Artificial Neural Networks (ANNs) are machine learning algorithms inspired by the structure and function of the human brain. Their popularity has increased in recent years due to their ability to learn and improve through experience, making them suitable for a wide range of applications. ANNs are often used as part of deep learning, which enables them to learn, transfer knowledge, make predictions, and take action. This paper aims to provide a comprehensive understanding of ANNs and explore potential directions for future research. To achieve this, the paper analyzes 10,661 articles and 35,973 keywords from various journals using a text-mining approach. The results of the analysis show that there is a high level of interest in topics related to machine learning, deep learning, and ANNs and that research in this field is increasingly focusing on areas such as optimization techniques, feature extraction and selection, and clustering. The study presented in this paper is motivated by the need for a framework to guide the continued study and development of ANNs. By providing insights into the current state of research on ANNs, this paper aims to promote a deeper understanding of ANNs and to facilitate the development of new techniques and applications for ANNs in the future.
1. Introduction
Artificial Neural Networks (ANNs) are a type of machine learning algorithm that are modeled after the structure and function of the human brain. They are designed to recognize patterns and learn from experience, making them well-suited for a wide range of applications such as image recognition, speech recognition, natural language processing, and many more [1,2,3]. Recent advancements in technology and the availability of large amounts of data have further increased the popularity of ANNs, particularly in the area of deep learning. This has led to the development of powerful new ANN architectures, such as convolutional neural networks (CNNs) and Recurrent Neural Networks (RNNs), which have been shown to achieve state-of-the-art results in a wide range of applications [1,4,5]. Recent advancements in technology and the availability of large amounts of data have further increased the popularity of ANNs, particularly in the area of deep learning. This has led to the development of powerful new ANN architectures, such as different DL architectures and methods, such as convolutional neural networks (CNN) [6], deep belief networks (DBN) [7], deep Boltzmann machines (DBMs) [8], restricted Boltzmann machines (RBMs) [9], deep neural networks (DNN) [10], and recursive auto-encoders.
Text mining is a process that uses techniques from natural language processing (NLP) and machine learning to extract valuable information from large amounts of text data. In the context of Artificial Neural Networks (ANNs), text mining can be used to extract features from text data that can be used to train ANN models. These features can include, for example, information about the words used in the text, the grammar and syntax of the sentences or the sentiment of the text. One of the most commonly used techniques in text mining is called bag-of-words, which represents text as a vector of the frequency of each word in the text. These vectors can then be used as input to an ANN model to train a classifier or perform other types of analysis. Another common technique used in text mining is called word embedding, which represents each word as a dense vector in a high-dimensional space. These embeddings can capture more fine-grained information about the meaning of words and the relationships between them and can be used to train more advanced ANN models. Text mining has been used to solve a variety of problems in the field of NLP, such as sentiment analysis, named entity recognition, and machine translation. ANN-based models, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), have been used in these tasks and have been shown to achieve state-of-the-art results [11,12].
This study is one of the pioneering efforts to apply text-mining techniques to a corpus of the literature related to Artificial Neural Networks (ANNs). The use of text mining offers a unique perspective by examining the actual usage of research terms rather than relying on contextual or subjective interpretations. The method of text mining is particularly effective in this area, as it has the capability to handle large amounts of keywords and highlight prominent trends in the data. Furthermore, being data-driven, the text mining approach is considered to be more precise and transferable than other methods. It is worth mentioning that while conferences are often the venue for the latest and most important developments in the field of ANNs, this study chose to focus on journal publications instead. This is due to the challenge of collecting a comprehensive dataset of conference papers, which would have required significant time and resources. However, we acknowledge that the use of conference papers can be a promising direction for future research in this field.
2. Background
2.1. Artificial Neural Network
The basic theory of Artificial Neural Networks (ANNs) is based on the idea that they can simulate the way the human brain works. They consist of a large number of interconnected artificial neurons, which are simple processing units that can take inputs, perform computations on them, and produce an output. The connections between these neurons are represented by weights, which can be adjusted during the training process to learn a specific task [13,14]. The field of Artificial Neural Networks (ANNs) is a rapidly evolving field, and new architectures, algorithms, and applications are being developed all the time. Here are some current state-of-the-art ANN architectures and major research directions. The field of Artificial Neural Networks (ANNs) has seen significant advancements in recent years, leading to the development of new architectures and algorithms that have achieved state-of-the-art performance on a wide range of tasks. One of the main directions in ANN research is the use of convolutional neural networks (CNNs) for image and video data analysis. CNNs have been shown to achieve state-of-the-art results on tasks such as image classification, object detection, and semantic segmentation [13]. Another major direction is the use of Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) for stock price forecasting [15], sequential data analysis, such as speech and text, with notable applications in natural language processing tasks, such as machine translation, speech recognition, and language modeling [16]. Generative Adversarial Networks (GANs) are a direction of research that focuses on the generation of new data, such as images, videos, and speech, and they have been widely applied in tasks such as image and video synthesis [17]. Another important direction is the field of Transfer Learning, in which the knowledge acquired from a pre-trained model is used to fine-tune it and apply it to new domains with a limited amount of data. Additionally, recent attention is paid to the field of Explainable AI, which tries to understand and make transparent the decision-making process of the ANNs, especially in critical tasks such as healthcare, finance, and self-driving cars. Finally, adversarial training is an approach that improves the robustness of ANN by training it to resist adversarial examples, which are inputs that are carefully crafted to fool the network. One of the main research methods used in the field is mathematical modeling [18,19,20], which involves developing and analyzing mathematical models of ANNs to understand their properties and behaviors. Researchers use techniques from optimization, control theory, and information theory to study the properties of ANNs and develop new algorithms for training and inference [21]. Big Data provides a wealth of opportunities for industries, such as e-commerce, industrial control, and medical informatics, but it also poses significant challenges for data mining and information processing due to its large volume, variety, velocity, and veracity. To address these challenges, researchers have looked to findings in neuroscience for inspiration. This has led to the development of Artificial Neural Networks (ANNs), which mimic the structure and function of the human brain and allow for the transmission of information across complex networks [1,2,3,4,22]. ANNs have the ability to learn and adapt through continual signal stimulation, making them well-suited for processing and extracting insights from large and complex datasets. This cerebral cortex mechanism for deep learning aided in the development of deep learning [1]. The connections between the neurons in a Recurrent Neural Network (RNN) create a directed loop, allowing the model to demonstrate dynamic temporal activity. Natural language processing, voice recognition, and other applications benefit from Recurrent Neural Networks because of their capacity to employ their internal memory to interpret arbitrary input sequences [23].
2.2. Applications of ANN-Based Approaches
Artificial Neural Networks (ANNs) have become one of the most widely used techniques for modeling complex systems in a wide range of application domains. The versatility and effectiveness of ANNs make them suitable for solving problems in various fields, such as image processing, speech recognition, natural language processing, control systems, finance, medicine, and many more. In image processing, ANNs have been used for tasks such as image classification, object recognition, and image segmentation. For example, in (Lecun et al., 2015) [21], a deep convolutional neural network was proposed for handwritten digit recognition, achieving state-of-the-art performance. In speech recognition, ANNs have been applied to model speech signals and perform tasks such as speaker identification and speech-to-text conversion. For example, (Hinton et al., 2012) [24] introduced a deep neural network architecture for large vocabulary continuous speech recognition, achieving significant improvements over traditional techniques. In natural language processing, ANNs have been used for tasks such as text classification, sentiment analysis, and machine translation. For example, (Young et al., 2018) [25] proposed a deep neural network model for machine translation, demonstrating the effectiveness of the approach. In control systems, ANNs have been applied to model dynamic systems and perform control tasks such as system identification, control design, and optimization. For example, (Widrow and Lehr, 1990) [26] introduced the backpropagation algorithm for training multi-layer feedforward neural networks for system identification and control. In finance, ANNs have been used for tasks such as stock market prediction and credit scoring. For example, (Alpaydin, 2010) [27] provides an overview of the use of ANNs in finance and discusses various applications and challenges. In medicine, ANNs have been applied to tasks such as diagnosis, prognosis, and drug discovery. For example, (Gandomi and Haider, 2015) [28] reviewed the applications of ANNs in medical diagnosis and discussed various issues and challenges. The wide range of application domains and the versatility of ANNs make them a valuable tool for solving complex problems and improving our understanding of the world. ANNs have become a popular and powerful tool for solving a wide range of problems in various fields, such as image processing [29,30,31], speech recognition, natural language processing, control systems [32,33], finance, and medicine [34,35,36]. The versatility and effectiveness of ANNs make them suitable for modeling complex systems and improving our understanding of the world. Despite their many benefits, ANNs also have certain limitations and disadvantages that must be considered when selecting a machine-learning approach. In this article, we will present a summary of the advantages, disadvantages, and limitations of the ANN-based approach as shown in Table 1. One way to do this is through empirical studies, where the ANN models are trained and tested on real-world datasets. The evaluation metrics used in these studies may include accuracy, precision, recall, F1-score, and others, depending on the specific application and problem being addressed. Additionally, computational efficiency can be measured in terms of the amount of time required to train the model and make predictions, as well as the amount of computational resources required. Other factors that can impact the effectiveness and efficiency of the ANN methods include the choice of architecture, the quality and size of the training dataset, the choice of hyperparameters, and the choice of optimization algorithms. Alpaydin [27] provides an overview of the use of ANNs in finance and discusses various evaluation metrics and factors that impact performance. Gandomi and Haider [28] reviewed the applications of ANNs in medical diagnosis and discussed various issues and challenges in evaluating the performance of ANN models.

Table 1.
Advantages, Disadvantages, and Limitations of ANN-based Approaches.
2.3. Text Mining for ANN
Design research has been increasingly attracting attention among researchers in recent years, with many researchers working to develop new and advanced approaches for studying design phenomena. One such approach is “text mining”, which uses computational techniques to extract meaningful information from large amounts of unstructured text data. This study is one of the first to apply text mining to design research publications, with the aim of analyzing the trends and patterns in the field and identifying future research directions [37,38,39,40]. Text mining is a process of extracting meaningful and relevant information from unstructured text data [41,42]. It has been applied in the field of ANNs to improve the performance of natural language processing tasks, such as sentiment analysis, text classification, and named entity recognition. By using text-mining techniques, such as natural language processing, text classification, and sentiment analysis, researchers can preprocess text data and convert it into a format that can be easily processed by ANNs.
Recent research has shown that text-mining techniques can improve the performance of ANNs in various natural language processing tasks. For instance, Zhang et al. [43] applied text-mining techniques to improve the performance of sentiment analysis by extracting features such as word embeddings and part-of-speech tags. Mohammed et al. [44] proposed an approach that combines text-mining techniques with ANNs to improve the performance of text classification. Sharma et al. [45] combined text mining and ANNs to achieve state-of-the-art performance in named entity recognition. Liu et al. [46] combined text mining and ANNs for opinion mining and sentiment analysis. Zhang et al. [47] proposed a hybrid approach of combining text-mining and ANNs to improve the performance of stock price prediction.
In summary, previous studies in the field of design research have focused mainly on identifying potential areas for future investigation and have covered a wide range of topics and approaches. However, there is currently a lack of research that synthesizes the existing literature and provides recommendations for future research directions. This study aims to fill this gap by using text mining to analyze design research publications and identify key themes and trends in the field. The following paragraphs provide a detailed description of the research methods and data analyses used in this study.
3. Research Methodology
Through investigating three research issues, this study has deepened our familiarity with and appreciation for the field of ANN research. The study’s questions are as follows:
- What do we learn about the most common areas of ANN directions from this data set?
- During the sample period of January 2000–2020, what trends were seen in ANN directions?
- What are the most important areas of study in ANN that will shape the field in the future?
The objective of this paper is to gain a comprehensive understanding of the current state of research in the field of ANN and identify potential directions for future study. We aim to accomplish this by analyzing keywords used in publications that deal with ANN. This study is among the first attempts to use text mining as a methodology for analyzing ANN publications, which is a method that predicts results by taking into account the occurrence number of a research term. Text mining has been chosen as a methodology due to its ability to provide more robust results as compared to other methods that rely on the opinions of the authors. Additionally, text mining can analyze a large corpus of data, which allows for the identification of popular trends and patterns in the research field, making it more efficient and generalizable than other methodologies. We hope that the insights gained from this study will contribute to a deeper understanding of the field of ANN and will serve as a useful guide for future research in this area.
In this study, a wide range of keywords was analyzed in order to gain a comprehensive understanding of the current state of research in the field of Artificial Neural Networks (ANN). The keywords included both specific terms related to the ANN literature and broader subjects. The research relied on a combination of indexed keywords and a list of published keywords, in addition to the abstract, publication year, and other data. The study included only the best available papers in the field, as determined by the index of the ISI Collection’s Web of Science website. To ensure that the research is relevant to the field of ANN, the authors chose journals that focus on the intersection of design, ICT, science, education, ergonomics, engineering, and technology and had “ANN” in the title. To maintain the quality of the research, certain journals were excluded from the study, mainly because they were not included in the Web of Science (ISI-core collection database) and were not eligible for inclusion in the Emerging Sources Citation.
This study analyzed a wide range of publications, including editorials, introductions, reviews, articles, and other sources, that were published in journals related to the field of Artificial Neural Networks (ANN). The research team made a conscious effort to include only those publications that were relevant to the study’s objectives and to exclude those that did not relate to the focus of the article (i.e., the ANN discipline). This was performed by carefully reviewing the keyword lists of each publication and disregarding those that did not contain the necessary terms. The team’s decision to include or exclude a publication was based on their own subjective evaluations. The aim of this approach was to conduct a more nuanced analysis of trends in the field of ANN across multiple disciplines. To achieve this, the team deliberately chose journals from different fields, such as design, ICT, science, education, ergonomics, engineering, and technology. By including publications from different disciplines, the research aimed to gain a more comprehensive understanding of the current state of research in the field of ANN and to identify potential areas for future study. This approach allowed the research team to conduct a more thorough analysis of trends in the field and to gain a better understanding of the state of research in the field of ANN. The research methods for the literature search are shown in Figure 1.
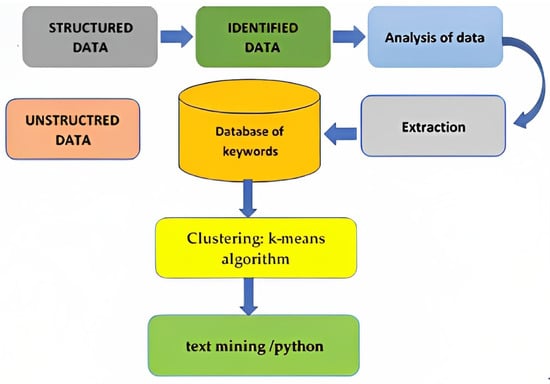
Figure 1.
Research Methodology.
4. Data Analysis and Discussion
In this section, we resort to an analysis approach based on two directions: descriptive analysis (Section 4.1) and text mining (Section 4.2).
4.1. Descriptive Analysis
For this research, data have been sampled to perform a cluster and frequency analysis. On the one hand, we have considered the distribution of articles published in journals illustrated in Figure 2 and listed in Table 2 per year (as shown in Figure 3) over the sample period: from 2000 to 2020. In fact, Table 2 presents information on the number of articles published in different journals related to neural processing, as well as the total number of articles across all of the journals. Table 2 can be used to understand the relative importance and popularity of the different journals in the field of neural processing. In this study, we adopted 6 journals and 10,661 articles. Figure 3 shows the distribution of the total number of articles published in the six selected journals related to neural processing from 2000 to 2020. Figure 3 displays the distribution of articles per year from 2000 to 2020. It provides a visual representation of the number of articles published in the field of neural processing over time. On the other hand, Figure 2 illustrates the distribution of articles per journal. It shows the number of articles published in six different journals related to neural processing, providing insights into the relative importance and popularity of each journal in the field. Additionally, Table 2 complements Figure 2 by presenting information on the number of articles published in each journal, as well as the total number of articles across all the journals. The collected data include the title, authors, year of publishing, journal name, and volume and issue number of the research. The studies dealing with ANNs have increased in the last few years, which is expected due to their efficiency and effectiveness.
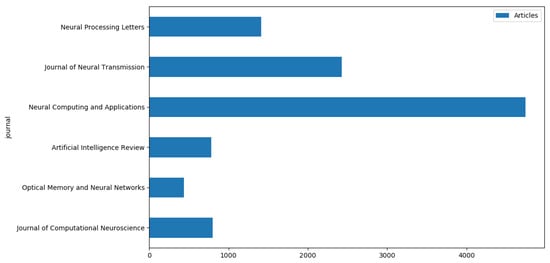
Figure 2.
Distribution of articles per journal.
Table 2.
Number of articles per journal.
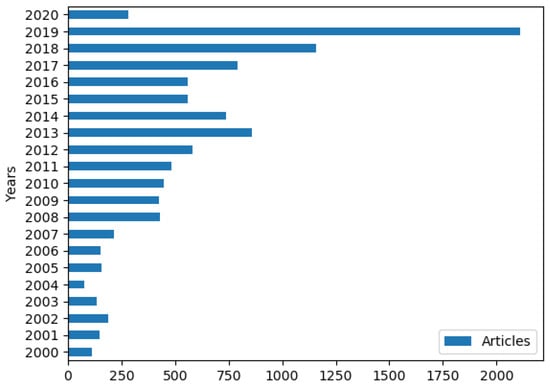
Figure 3.
Distribution of articles per year.
The sampled articles deal with ANN research fields and are distributed according to three time intervals (i.e., 2007–2011, 2012–2015, and 2016–2019) (Some of the old papers, especially those published before the mid-2000s, are useless due to the lack of one or more important key features (e.g., title, year of publishing, or empty keyword list)) as shown in Figure 4. They are distributed as follows: 21.4% of the references are in the time period from 2007 to 2011, 29.2% of the references are in the period 2012 and 2015, and 49.4% of the references are in the period 2016 and 2019.
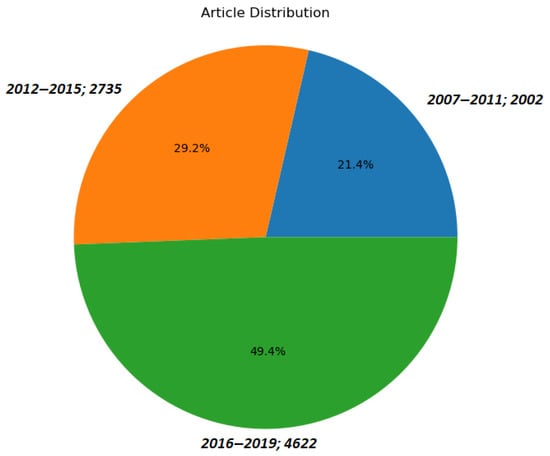
Figure 4.
The distribution of research articles among the three time intervals.
On the other hand, the analysis step extracts and ranks the relevant keywords that are related to neural networks on the base of their frequency (number of documents) in the dataset. Our starting point is 35,973 keywords associated with adopted articles is 35,973. They are extracted from a corpus of the publications from journals listed in Table 2 and distributed according to the time intervals mentioned above. Their distribution is performed according to the same time intervals. Figure 5 displays the distribution of keywords extracted from the publications in the corpus over the three time periods considered in this study: 2007–2011, 2012–2015, and 2016–2019. The total number of keywords extracted from the corpus is 35,973. It is observed that the highest proportion of keywords (49.5%) is found in the period 2016–2019, while the lowest proportion (21.6%) is found in the period 2007–2011. This indicates an increasing trend in the use of keywords related to neural processing over time. The distribution of keywords over time is important in understanding the evolution and trends in the field of neural processing. The latter shows that 21.6% (7761) of the keywords are used during the time period 2007 to 2011, 28.9% (10,390) in the period 2012 to 2015, and 49.5% (17,822) in the period 2016 to 2019.
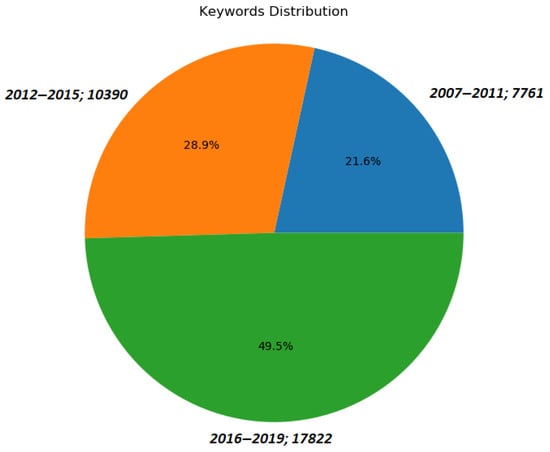
Figure 5.
The distribution of keywords according to the three time intervals.
Table 3 provides a list of the top 50 keywords related to ANNs and their respective frequencies based on an analysis of the articles in the dataset. the later shows the rank of each keyword based on the frequency of its occurrence in the articles, along with the actual keyword and the number of times it appears in the dataset. Some of the most frequently occurring keywords are “artificial neural network”, “classification”, “machine learning”, and “deep learning”. Other highly ranked keywords include “genetic algorithm”, “support vector machine”, and “particle swarm optimization”. Table 3 provides insight into the most commonly used keywords in articles related to ANNs, indicating the current trends in research in this field. The prominence of these keywords suggests that research in ANNs is focused on the development and optimization of neural network architectures, machine learning techniques, and pattern recognition algorithms. Additionally, the high frequency of certain keywords, such as “classification” and “support vector machine” highlights the significant application of ANNs in classification and prediction tasks. The analysis provided can help researchers identify current areas of interest and potential research directions in the field of ANNs. It is well known that a keyword could not exactly correspond to the name of the technology, but it could be linked to it. The considered results show that “neural network” and “artificial neural network” are at the head of the list with a higher frequency. Other keyword’s frequencies are nearly equal, such as “deep learning”, “genetic algorithm”, “data mining”, and “swarm intelligence”.
Table 3.
Top 50 keywords related to ANN topics.
4.2. Text Mining Analysis (Clustering)
In this paper, we resort to a text mining model to understand the ANN research changes over the sample period (2007–2020). Particularly, we have used the k-means algorithm to classify keywords into groups (also known as clusters). K-means is a well-known algorithm belonging to the set of partitioning clustering techniques. As it belongs to unsupervised processes, there are no clusters. They are formed according to keyword similarity. Clustering algorithms are used in a broad variety of applications to split a data set into K clusters. To do so, the user should initialize a number K as the expected number of clusters. The algorithm must repeat many times to adjust the centroids of clusters since they are randomly chosen. By doing this, it can only achieve locally optimal clustering results. As a tool for text mining, we rely on Python 2.7 as a popular language adopted for text processing. In particular, we rely on pandas, numpy, and scikit-learn Python packages to implement the k-means algorithm for clustering. We also used NLTK (the Natural Language Toolkit package) for data preprocessing so as to convert the text to lower-case and remove numbers and punctuation.
We used k-means to group the publications’ keywords into clusters in a dataset file and dealt with each one as one document. We obtain a file with 10,661 documents. Thereafter, we divided the obtained dataset into three different parts based on their year of publishing (variable). Then, we import the dataset into Python. The first, second, and third parts contained data from 2007 to 2011, from 2012 to 2015, and 2016 to 2019, respectively. This separation is important so as to analyze the ANN research trends for each part.
4.2.1. Clustering Results
We aim to apply some transformations on each part obtained in Section 4.2. To do this, we consorted all the keywords to lower-case first. Second, we eliminated stop words, numbers, and punctuation in order to improve the analysis results. Third, we adopted tokenizers as regular expressions to keep words with hyphens to ameliorate the semantical interpretability of the analysis. Finally, we verified the correctness of the keywords and revised the ones with minor spelling mistakes and removed the undetectable ones by using NLTK.
In preference to using a term-document frequency by keywords, we used TF-IDF vector (Term Frequency–Inverse Document Frequency), which is widely used in text mining research.
TF consists of the occurrence number of a keyword in a document. It highlights how important a word is in a document. IDF is obtained by taking the logarithm of the quotient (N/DF), where (N) is the total number of documents and (DF) is the number of documents containing the keyword. It is used to represent the number of occurrences of a keyword in a collection of documents. Consequently, each cluster contains frequent words. Next, we determine the number of clusters (k) through the k-means algorithm. We also adopt trial-and-error to specify the best number of clusters by comparing the obtained k values of clustering results and selecting the most suitable value for the involved dataset. As a consequence, we fix the number of clusters to 10.
The clustering model results are presented in Figure 6, Figure 7 and Figure 8 where 10 clusters were adopted for each time period, and each cluster contains 10 keywords. The obtained results shed light on the research focus during the three time periods of 2007–2011, 2012–2015, and 2016–2019. In the period of 2007–2011, the top terms per cluster suggest a strong research focus on optimization, machine learning, and support vector machines (SVMs). This was a time when researchers were actively exploring various algorithms to improve the efficiency and accuracy of machine-learning models. The use of genetic algorithms and extreme learning machines (ELMs) was also prominent during this period. Moving on to the period of 2012–2015, the top terms per cluster show that the research focus shifted towards deep learning and artificial neural networks. Researchers were exploring the potential of deep neural networks and their applications in image classification and other areas. The use of deep learning algorithms and Recurrent Neural Networks was prominent during this time. Additionally, researchers were also investigating particle swarm optimization and genetic algorithms for improved classification and optimization. In fact, in the period of 2016–2019, the top terms per cluster indicate that researchers were focused on improving the stability and prediction capabilities of machine-learning models. The use of exponential stability, adaptive control, and optimization was prominent during this time. The use of deep neural networks and Recurrent Neural Networks was still a popular area of research, but researchers were also exploring the use of artificial intelligence and genetic algorithms in new applications.
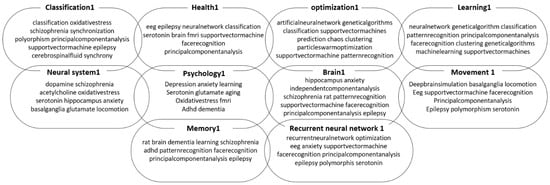
Figure 6.
The ten clusters for the period from 2007 to 2011.
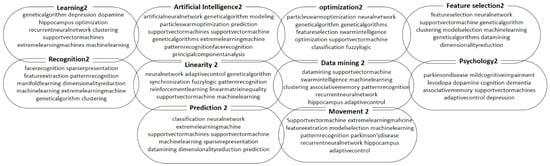
Figure 7.
The ten clusters for the period from 2012 to 2015.
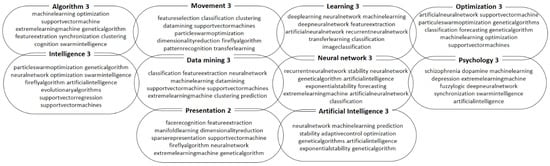
Figure 8.
The ten clusters for the period from 2016 to 2019.
Overall, these results highlight the rapid evolution of the field of machine learning and artificial neural networks. The focus has shifted from optimization and machine learning toward deep learning and artificial intelligence, with a strong emphasis on improving the stability and prediction capabilities of these models. The use of genetic algorithms, particle swarm optimization, and extreme learning machines in the early years have paved the way for research in the field, which has now expanded to incorporate exponential stability, adaptive control, and optimization techniques.
A name is specified for each cluster by taking into account its relation with the set of words. This ensures accurate descriptions of the involved keywords and makes each cluster different from the others. The results offer an overview of the most adopted research topic per time period and help in assessing future research topics.
4.2.2. Word Frequency Distribution
By relying on the results obtained in Section 4.2.1, we adopt a word frequency distribution and a manual clustering technique per time interval. In the manual clustering, the occurrence numbers of keywords within the clusters were defined and then grouped into dimensions. This step was followed by a summation of keywords into more general dimensions for the tree time intervals. The following trend can be defined based on this kind of analysis (i.e., text analysis).
For the same periods (i.e., 2007–2011, 2012–2015, and 2016–2019), a manual clustering process was applied where the occurrence numbers of all popular words (shown in Table 4) within the clusters were predicted and then resumed into dimensions (major concepts). This work focuses on the first time period of the selected titles. Table 4 presents the frequency of major dimensions over three time periods: 2007–2011, 2012–2015, and 2016–2019. The dimensions include mental disease, mental curing, brain, deep learning, algorithm, data mining, stability, reasoning, transmission, and machine learning. A trend line graph is also provided for each dimension to illustrate its frequency trend across the three time periods. Some cells in the table are highlighted in yellow to indicate dimensions with a significant increase in frequency over time. Although a moderate conclusion can be drawn based on the percentages of words and total words, as presented in the table, the findings should be interpreted with caution.
Table 4.
Major dimensions and their corresponding frequencies.
5. Conclusions
This research study focuses on investigating research directions related to Artificial Neural Networks (ANNs). It selected top machine learning journals and analyzed related keywords from each article. The results of the research provide new insights into the mechanisms underlying a previously unknown phenomenon, leading to the development of a novel approach to solving a long-standing problem in the field. The study used a unique combination of experimental techniques and analytical methods, breaking new ground in our understanding of the subject and paving the way for future work. This work is significant and represents a major advance in the field. The research paper depends on various factors, such as the novel ideas, methods, and findings presented in the paper, the significance of the research topic, and the impact it has on the field. The contribution of a research paper depends on various factors, such as the novel ideas, methods, and findings presented in the paper, the significance of the research topic, and the impact it has on the field. The study surveyed 6 journals, 10,661 articles, and 35,973 keywords. The results indicate that new trends in ANN are attracting both editorial boards and researchers, with topics such as machine learning, deep learning, and ANN, as well as continuing research in areas such as particle swarm optimization, support vector machine, feature extraction and selection, and clustering. The study conducted a trend analysis and word distribution on the data, which highlighted 10 dimensions that govern research in ANN, including mental disease, mental curing, brain, deep learning, optimization, data mining, stability, reasoning, transmission, and machine learning. However, it is acknowledged that the study is limited by the number of journals used for data collection and that ANN study topics are also published in chapter books and conference proceedings. Additionally, certain publications were removed based on the study team’s criteria, despite being deemed relevant in the field. The availability of data within each time period is also a limitation, as the first time period had fewer articles than the second and third time periods. This study offers a preliminary overview of ANN research and acknowledges the limitations of the study and manual clustering of the data based on the authors’ experience, expertise, and prior research.
Author Contributions
Conceptualization, methodology, and experimentation: H.L.; Writing—review and editing: H.L., A.L. and F.M.; Funding acquisition: E.K. All authors have read and agreed to the published version of the manuscript.
Funding
Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia. Project No. (IF2/PSAU/2022/01/21577).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data could be provided upon request from Ali Louati (a.louati@psau.edu.sa).
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number (IF2/PSAU/2022/01/21577).
Conflicts of Interest
The authors declare no conflict of interest.
References
- McClelland, J.L.; Rumelhart, D.E.; PDP Research Group. Parallel Distributed Processing, Volume 2: Explorations in the Microstructure of Cognition: Psychological and Biological Models; MIT Press: Cambridge, MA, USA, 1987; Volume 2. [Google Scholar]
- Lee, T.S.; Mumford, D. Hierarchical Bayesian inference in the visual cortex. JOSA A 2003, 20, 1434–1448. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 497–504. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive Fields of Single Neurons in the Cat’s Striate Cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Salakhutdinov, R.; Larochelle, H. Efficient Learning of Deep Boltzmann Machines. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2010, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 693–700. [Google Scholar]
- Liu, J.-W.; Chi, G.-H.; Luo, X.-L. Contrastive Divergence Learning of Restricted Boltzmann Machine. In Proceedings of the 2012 Second International Conference on Electric Technology and Civil Engineering, Washington, DC, USA, 18–20 May 2012; pp. 712–715. [Google Scholar]
- Gong, M.; Liu, J.; Li, H.; Cai, Q.; Su, L. A Multiobjective Sparse Feature Learning Model for Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3263–3277. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Grekousis, G. Artificial neural networks and deep learning in urban geography: A systematic review and meta-analysis. Comput. Environ. Urban Syst. 2019, 74, 244–256. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef]
- Md, A.Q.; Kapoor, S.; Chris Junni, A.V.; Sivaraman, A.K.; Tee, K.F.; Sabireen, H.; Janakiraman, N. Novel optimization approach for stock price forecasting using multi-layered sequential LSTM. Appl. Soft Comput. 2023, 134, 109830. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Louati, A.; Lahyani, R.; Aldaej, A.; Mellouli, R.; Nusir, M. Mixed integer linear programming models to solve a real-life vehicle routing problem with pickup and delivery. Appl. Sci. 2021, 11, 9551. [Google Scholar] [CrossRef]
- Louati, A.; Masmoudi, F.; Lahyani, R. Traffic disturbance mining and feedforward neural network to enhance the immune network control performance. In Proceedings of the Seventh International Congress on Information and Communication Technology: ICICT 2022, London, UK, 21–24 February 2022; Volume 1, pp. 99–106. [Google Scholar]
- Louati, A.; Louati, H.; Li, Z. Deep learning and case-based reasoning for predictive and adaptive traffic emergency management. J. Supercomput. 2021, 77, 4389–4418. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinton, G.E.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Wen, T.-H.; Vandyke, D.; Mrkšić, N.; Gašić, M.; Rojas-Barahona, L.M.; Su, P.-H.; Ultes, S.; Young, S. A network-based end-to-end trainable task-oriented dialogue model. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 312–320. [Google Scholar]
- Widrow, B.; Lehr, M.E. 30 Years of Adaptive Neural Networks: Perception, Motor Control, and Cognition; World Scientific: Singapore, 1990. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Gandomi, A.A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Louati, H.; Bechikh, S.; Louati, A.; Hung, C.C.; Said, L.B. Deep convolutional neural network architecture design as a bi-level optimization problem. Neurocomputing 2021, 439, 44–62. [Google Scholar] [CrossRef]
- Louati, H.; Bechikh, S.; Louati, A.; Aldaej, A.; Said, L.B. Evolutionary optimization of convolutional neural network architecture design for thoracic X-ray image classification. In Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices, Proceedings of the 34th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2021, Kuala Lumpur, Malaysia, 26–29 July 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 121–132. [Google Scholar]
- Louati, H.; Bechikh, S.; Louati, A.; Aldaej, A.; Said, L.B. Joint design and compression of convolutional neural networks as a Bi-level optimization problem. Neural Comput. Appl. 2022, 34, 15007–15029. [Google Scholar] [CrossRef]
- Louati, A. A hybridization of deep learning techniques to predict and control traffic disturbances. Artif. Intell. Rev. 2020, 53, 5675–5704. [Google Scholar] [CrossRef]
- Louati, A.; Louati, H.; Nusir, M.; Hardjono, B. Multi-agent deep neural networks coupled with LQF-MWM algorithm for traffic control and emergency vehicles guidance. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 5611–5627. [Google Scholar] [CrossRef]
- Louati, H.; Louati, A.; Bechikh, S.; Masmoudi, F.; Aldaej, A.; Kariri, E. Topology optimization search of deep convolution neural networks for CT and X-ray image classification. BMC Med. Imaging 2022, 22, 120. [Google Scholar] [CrossRef] [PubMed]
- Louati, H.; Louati, A.; Bechikh, S.; Ben Said, L. Design and Compression Study for Convolutional Neural Networks Based on Evolutionary Optimization for Thoracic X-ray Image Classification. In Computational Collective Intelligence, Proceedings of the 14th International Conference, ICCCI 2022, Hammamet, Tunisia, 28–30 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 283–296. [Google Scholar]
- Louati, H.; Bechikh, S.; Louati, A.; Aldaej, A.; Said, L.B. Evolutionary optimization for CNN compression using thoracic X-ray image classification. In Advances and Trends in Artificial Intelligence. Theory and Practices in Artificial Intelligence, Proceedings of the 35th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2022, Kitakyushu, Japan, 19–22 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 112–123. [Google Scholar]
- Feng, Y.; Lu, X.; Wang, H. Design research on user experience based on text mining. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9–18. [Google Scholar]
- Jin, Y.; Wang, J.; Liu, Y. Text mining in product design research: A literature review. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 149–159. [Google Scholar]
- Li, X.; Li, Q.; Li, Z. Text mining in industrial design research: A literature review. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 10175–10184. [Google Scholar]
- Wang, J.; Li, X.; Liu, Y. Text mining in design thinking research: A literature review. J. Ambient. Intell. Humaniz. Comput. 2018, 9, 5397–5405. [Google Scholar]
- Zheng, Y.; Wang, J.; Liu, Y. Text mining in design for sustainability research: A literature review. J. Ambient. Intell. Humaniz. Comput. 2018, 9, 3357–3365. [Google Scholar]
- Wang, J.; Li, X.; Liu, Y. Text mining in design education research: A literature review. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 5685–5693. [Google Scholar]
- Zhang, W.; Liu, Y.; Dai, Y. Sentiment analysis with text mining techniques and artificial neural networks. Inf. Sci. 2020, 520, 92–107. [Google Scholar]
- Mohammed, A.H.; Al-Sarawi, S.F.; Dass, S.C. Text classification using artificial neural networks and text mining techniques. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 5649–5658. [Google Scholar]
- Sharma, A.; Sharma, S. A review on artificial neural network based named entity recognition using text mining techniques. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4585–4600. [Google Scholar]
- Liu, L.; Liu, Y.; Dai, Y. Opinion mining and sentiment analysis with text mining and artificial neural networks. Inf. Sci. 2019, 476, 225–242. [Google Scholar]
- Zhang, Y.; Tan, Y.; Liu, Y. Stock price prediction with text mining and artificial neural networks. J. Ambient. Intell. Humaniz. Comput. 2018, 9, 53–62. [Google Scholar]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).