

A Meal-Assistance Robot System for Asian Food and Its Food Acquisition Point Estimation and User Interface Based on Face Recognition

 , , , and
, , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Development of a compact and portable meal assistance robot system capable of both food recognition and robot control without external computing.
- Development of a meal assistance robot system that can serve realistic Korean diets, which can easily be used in a cafeteria rather than a simple lab environment.
- Development of deep-learning-based food acquisition point estimators to utilize chopstick-type dining tools.
- Development of a non-contact user interface based on face (gaze/nod/mouth shape) recognition for critically ill patients who have difficulty using a touch interface.
2. Related Work
2.1. Commercial Products
2.2. Food Perception
2.3. User Interface
3. Materials and Methods
3.1. MAR System Overview
- The caregiver holds the robot arm and directly teaches the position that the user’s mouth can easily reach.
- The caregiver presses the start button after setting a meal on the plate. (After this, the user starts to eat alone using the user interface.)
- The robot moves to a predefined ready position and takes an image of the food tray using a camera attached to the robot arm.
- From the image, the acquisition point estimator perceives the food area and extracts picking points for each dish through post-processing. Then, it sends the robot controller the points.
- Once a user command selecting a particular food is transmitted from the user interface to the controller, the robotic arm moves to the coordinates of the acquisition point for that food.
- The robot performs a food-acquisition motion and then delivers food to the mouth position, as taught directly by the caregiver in step 1.
- The robot waits for the user to eat food for a preset amount of time.
- Steps 3–7 are repeated until the end of the meal.
3.2. Robot HW and Control
- Position repeat accuracy: less than 30 mm;
- Distance accuracy: 4.39 mm;
- Distance repeatability: 0.26 mm;
- Path speed accuracy: 4.81% (@target speed 250 mm/s).
3.3. Food Acquisition Point Estimator
3.4. Face Recognition User Interface
- Four types of eye-gaze directions(“left up,” “up,” “right up,” “center”);
- Two types of head directions(“head_left,” “head_right”);
- Two types of mouth shapes(“open,” “close”).
4. Results
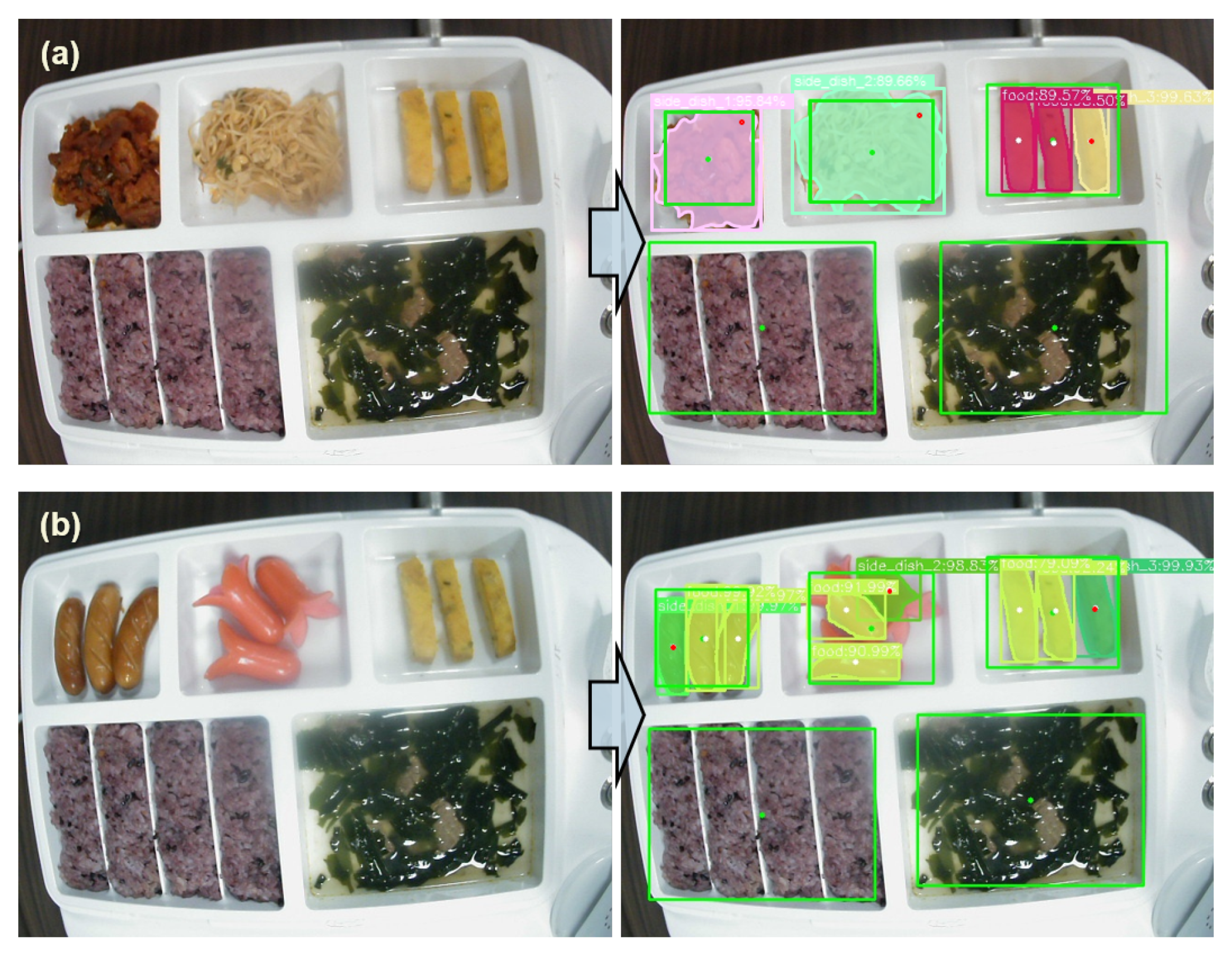
4.1. Experiment 1—Acquisition Point Estimator
4.2. Experiment 2—Face Recognition User Interface
4.3. Experiment 3—Whole MAR System Demonstration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Available online: https://www.who.int/news-room/fact-sheets/detail/disability-and-health/ (accessed on 8 December 2022).
- Naotunna, I.; Perera, C.J.; Sandaruwan, C.; Gopura, R.; Lalitharatne, T.D. Meal assistance robots: A review on current status, challenges and future directions. In Proceedings of the 2015 IEEE/SICE International Symposium on System Integration (SII), Nagoya, Japan, 11–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 211–216. [Google Scholar]
- Bhattacharjee, T.; Lee, G.; Song, H.; Srinivasa, S.S. Towards robotic feeding: Role of haptics in fork-based food manipulation. IEEE Robot. Autom. Lett. 2019, 4, 1485–1492. [Google Scholar] [CrossRef] [Green Version]
- Prior, S.D. An electric wheelchair mounted robotic arm—A survey of potential users. J. Med. Eng. Technol. 1990, 14, 143–154. [Google Scholar] [CrossRef] [PubMed]
- Stanger, C.A.; Anglin, C.; Harwin, W.S.; Romilly, D.P. Devices for assisting manipulation: A summary of user task priorities. IEEE Trans. Rehabil. Eng. 1994, 2, 256–265. [Google Scholar] [CrossRef]
- Pico, N.; Jung, H.R.; Medrano, J.; Abayebas, M.; Kim, D.Y. Climbing control of autonomous mobile robot with estimation of wheel slip and wheel-ground contact angle. J. Mech. Sci. Technol. 2022, 36, 1–10. [Google Scholar] [CrossRef]
- Pico, N.; Park, S.H.; Yi, J.S.; Moon, H. Six-Wheel Robot Design Methodology and Emergency Control to Prevent the Robot from Falling down the Stairs. Appl. Sci. 2022, 12, 4403. [Google Scholar] [CrossRef]
- Obi. Available online: https://meetobi.com/meet-obi/ (accessed on 8 December 2022).
- Meal Buddy. Available online: https://www.performancehealth.com/meal-buddy-systems (accessed on 8 December 2022).
- Specializing in Assistive Eating and Assistive Drinking Equipment for Individuals with Disabilities. Available online: https://mealtimepartners.com/ (accessed on 8 December 2022).
- Neater. Available online: https://www.neater.co.uk/ (accessed on 8 December 2022).
- Bestic Eating Assistive Device. Available online: https://at-aust.org/items/13566 (accessed on 8 December 2022).
- Automation My Spoon through Image Processing. Available online: https://www.secom.co.jp/isl/e2/research/mw/report04/ (accessed on 8 December 2022).
- CareMeal. Available online: http://www.ntrobot.net/myboard/product (accessed on 8 December 2022).
- Song, W.K.; Kim, J. Novel assistive robot for self-feeding. In Robotic Systems-Applications, Control and Programming; Intech Open: London, UK, 2012; pp. 43–60. [Google Scholar]
- Song, K.; Cha, Y. Chopstick Robot Driven by X-shaped Soft Actuator. Actuators 2020, 9, 32. [Google Scholar] [CrossRef]
- Oka, T.; Solis, J.; Lindborg, A.L.; Matsuura, D.; Sugahara, Y.; Takeda, Y. Kineto-Elasto-Static design of underactuated chopstick-type gripper mechanism for meal-assistance robot. Robotics 2020, 9, 50. [Google Scholar] [CrossRef]
- Koshizaki, T.; Masuda, R. Control of a meal assistance robot capable of using chopsticks. In Proceedings of the ISR 2010 (41st International Symposium on Robotics) and ROBOTIK 2010 (6th German Conference on Robotics), Munich, Germany, 7–9 June 2010; VDE: Berlin, Germany, 2010; pp. 1–6. [Google Scholar]
- Yamazaki, A.; Masuda, R. Autonomous foods handling by chopsticks for meal assistant robot. In Proceedings of the ROBOTIK 2012, 7th German Conference on Robotics, Munich, Germany, 21–22 May 2012; VDE: Berlin, Germany, 2012; pp. 1–6. [Google Scholar]
- Ohshima, Y.; Kobayashi, Y.; Kaneko, T.; Yamashita, A.; Asama, H. Meal support system with spoon using laser range finder and manipulator. In Proceedings of the 2013 IEEE Workshop on Robot Vision (WORV), Clearwater Beach, FL, USA, 15–17 January 2013; IEEE: New York, NY, USA, 2013; pp. 82–87. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Yanai, K.; Kawano, Y. Food image recognition using deep convolutional network with pre-training and fine-tuning. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 18–22 July 2022; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/non-food image classification and food categorization using pre-trained googlenet model. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; pp. 3–11. [Google Scholar]
- Hassannejad, H.; Matrella, G.; Ciampolini, P.; De Munari, I.; Mordonini, M.; Cagnoni, S. Food image recognition using very deep convolutional networks. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; pp. 41–49. [Google Scholar]
- Wu, Z.; Gao, Q.; Jiang, B.; Karimi, H.R. Solving the production transportation problem via a deterministic annealing neural network method. Appl. Math. Comput. 2021, 411, 126518. [Google Scholar] [CrossRef]
- Wu, Z.; Karimi, H.R.; Dang, C. An approximation algorithm for graph partitioning via deterministic annealing neural network. Neural Netw. 2019, 117, 191–200. [Google Scholar] [CrossRef] [PubMed]
- Gallenberger, D.; Bhattacharjee, T.; Kim, Y.; Srinivasa, S.S. Transfer depends on acquisition: Analyzing manipulation strategies for robotic feeding. In Proceedings of the 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Daegu, Korea, 11–14 March 2019; IEEE: New York, NY, USA, 2019; pp. 267–276. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, R.; Kim, Y.; Lee, G.; Gordon, E.K.; Schmittle, M.; Kumar, S.; Bhattacharjee, T.; Srinivasa, S.S. Robot-Assisted Feeding: Generalizing Skewering Strategies Across Food Items on a Plate. In Proceedings of the International Symposium of Robotics Research, Hanoi, Vietnam, 6–10 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 427–442. [Google Scholar]
- Gordon, E.K.; Meng, X.; Bhattacharjee, T.; Barnes, M.; Srinivasa, S.S. Adaptive robot-assisted feeding: An online learning framework for acquiring previously unseen food items. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020; IEEE: New York, NY, USA, 2020; pp. 9659–9666. [Google Scholar]
- Gordon, E.K.; Roychowdhury, S.; Bhattacharjee, T.; Jamieson, K.; Srinivasa, S.S. Leveraging Post Hoc Context for Faster Learning in Bandit Settings with Applications in Robot-Assisted Feeding. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–June 5 2021; IEEE: New York, NY, USA, 2021; pp. 10528–10535. [Google Scholar]
- Berg, J.; Lu, S. Review of interfaces for industrial human-robot interaction. Curr. Robot. Rep. 2020, 1, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, S.; Lin, X.; Kim, J.H. Interface for human machine interaction for assistant devices: A review. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; IEEE: New York, NY, USA, 2020; pp. 768–773. [Google Scholar]
- Porcheron, M.; Fischer, J.E.; Reeves, S.; Sharples, S. Voice interfaces in everyday life. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Suzuki, R.; Ogino, K.; Nobuaki, K.; Kogure, K.; Tanaka, K. Development of meal support system with voice input interface for upper limb disabilities. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; IEEE: New York, NY, USA, 2013; pp. 714–718. [Google Scholar]
- De Pace, F.; Manuri, F.; Sanna, A.; Fornaro, C. A systematic review of Augmented Reality interfaces for collaborative industrial robots. Comput. Ind. Eng. 2020, 149, 106806. [Google Scholar] [CrossRef]
- Dianatfar, M.; Latokartano, J.; Lanz, M. Review on existing VR/AR solutions in human–robot collaboration. Procedia CIRP 2021, 97, 407–411. [Google Scholar] [CrossRef]
- Chamola, V.; Vineet, A.; Nayyar, A.; Hossain, E. Brain-computer interface-based humanoid control: A review. Sensors 2020, 20, 3620. [Google Scholar] [CrossRef]
- Perera, C.J.; Naotunna, I.; Sadaruwan, C.; Gopura, R.A.R.C.; Lalitharatne, T.D. SSVEP based BMI for a meal assistance robot. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; IEEE: New York, NY, USA, 2016; pp. 2295–2300. [Google Scholar]
- Perera, C.J.; Lalitharatne, T.D.; Kiguchi, K. EEG-controlled meal assistance robot with camera-based automatic mouth position tracking and mouth open detection. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 1760–1765. [Google Scholar]
- Ha, J.; Park, S.; Im, C.H.; Kim, L. A hybrid brain–computer interface for real-life meal-assist robot control. Sensors 2021, 21, 4578. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Wang, B.; Sugi, T.; Nakamura, M. Meal assistance system operated by electromyogram (EMG) signals: Movement onset detection with adaptive threshold. Int. J. Control Autom. Syst. 2010, 8, 392–397. [Google Scholar] [CrossRef]
- Bhattacharjee, T.; Gordon, E.K.; Scalise, R.; Cabrera, M.E.; Caspi, A.; Cakmak, M.; Srinivasa, S.S. Is more autonomy always better? Exploring preferences of users with mobility impairments in robot-assisted feeding. In Proceedings of the 2020 15th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Cambridge, UK, 23–26 March 2020; IEEE: New York, NY, USA, 2020; pp. 181–190. [Google Scholar]
- Jain, L. Design of Meal-Assisting Manipulator AI via Open-Mouth Target Detection. Des. Stud. Intell. Eng. 2022, 347, 208. [Google Scholar]
- Tomimoto, H.; Tanaka, K.; Haruyama, K. Meal Assistance Robot Operated by Detecting Voluntary Closing eye. J. Inst. Ind. Appl. Eng. 2016, 4, 106–111. [Google Scholar]
- Liu, F.; Xu, P.; Yu, H. Robot-assisted feeding: A technical application that combines learning from demonstration and visual interaction. Technol. Health Care 2021, 29, 187–192. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wang, L.; Fan, X.; Zhao, P.; Ji, K. Facial Gesture Controled Low-Cost Meal Assistance Manipulator System with Real-Time Food Detection. In Proceedings of the International Conference on Intelligent Robotics and Applications, Harbin, China, 1–3 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 222–231. [Google Scholar]
- Yunardi, R.T.; Dina, N.Z.; Agustin, E.I.; Firdaus, A.A. Visual and gyroscope sensor for head movement controller system on meal-assistance application. Majlesi J. Electr. Eng. 2020, 14, 39–44. [Google Scholar] [CrossRef]
- Lopes, P.; Lavoie, R.; Faldu, R.; Aquino, N.; Barron, J.; Kante, M.; Magfory, B. Icraft-eye-controlled robotic feeding arm technology. Tech. Rep. 2012.
- Cuong, N.H.; Hoang, H.T. Eye-gaze detection with a single WebCAM based on geometry features extraction. In Proceedings of the 2010 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; IEEE: New York, NY, USA, 2010; pp. 2507–2512. [Google Scholar]
- Huang, Q.; Veeraraghavan, A.; Sabharwal, A. TabletGaze: Dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Mach. Vis. Appl. 2017, 28, 445–461. [Google Scholar] [CrossRef]
- WebCam Eye-Tracking Accuracy. Available online: https://gazerecorder.com/webcam-eye-tracking-accuracy/ (accessed on 8 December 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- George, A.; Routray, A. Real-time eye gaze direction classification using convolutional neural network. In Proceedings of the 2016 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 12–15 June 2016; IEEE: New York, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Chen, R.; Kim, T.K.; Hwang, J.H.; Ko, S.Y. A Novel Integrated Spoon-chopsticks Mechanism for a Meal Assistant Robotic System. Int. J. Control Autom. Syst. 2022, 20, 3019–3031. [Google Scholar] [CrossRef]
- Song, H.; Jung, B.J.; Kim, T.K.; Cho, C.N.; Jeong, H.S.; Hwang, J.H. Development of Flexible Control System for the Meal Assistant Robot. In Proceedings of the KSME Conference, Daejeon, Republic of Korea, 29–31 July 2020; The Korean Society of Mechanical Engineers: Seoul, Republic of Korea, 2020; pp. 1596–1598. [Google Scholar]
- Jung, B.J.; Kim, T.K.; Cho, C.N.; Song, H.; Kim, D.S.; Jeong, H.; Hwang, J.H. Development of Meal Assistance Robot for Generalization of Robot Care Service Using Deep Learning for the User of Meal Assistant Robot . Korea Robot. Soc. Rev. 2022, 19, 4–11. (In Korean) [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Park, H.; Jang, I.; Ko, K. Meal Intention Recognition System based on Gaze Direction Estimation using Deep Learning for the User of Meal Assistant Robot. J. Inst. Control Robot. Syst. 2021, 27, 334–341. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Vrânceanu, R.; Florea, C.; Florea, L.; Vertan, C. NLP EAC recognition by component separation in the eye region. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, York, UK, 27–29 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 225–232. [Google Scholar]
- Florea, L.; Florea, C.; Vrânceanu, R.; Vertan, C. Can Your Eyes Tell Me How You Think? A Gaze Directed Estimation of the Mental Activity. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/lite/ (accessed on 8 December 2022).












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, I.; Ko, K.; Song, H.; Jung, B.-J.; Hwang, J.-H.; Moon, H.; Yang, G.-H. A Meal-Assistance Robot System for Asian Food and Its Food Acquisition Point Estimation and User Interface Based on Face Recognition. Appl. Sci. 2023, 13, 3216. https://doi.org/10.3390/app13053216
Choi I, Ko K, Song H, Jung B-J, Hwang J-H, Moon H, Yang G-H. A Meal-Assistance Robot System for Asian Food and Its Food Acquisition Point Estimation and User Interface Based on Face Recognition. Applied Sciences. 2023; 13(5):3216. https://doi.org/10.3390/app13053216
Chicago/Turabian StyleChoi, Iksu, KwangEun Ko, Hajun Song, Byung-Jin Jung, Jung-Hoon Hwang, Hyungpil Moon, and Gi-Hun Yang. 2023. "A Meal-Assistance Robot System for Asian Food and Its Food Acquisition Point Estimation and User Interface Based on Face Recognition" Applied Sciences 13, no. 5: 3216. https://doi.org/10.3390/app13053216
APA StyleChoi, I., Ko, K., Song, H., Jung, B.-J., Hwang, J.-H., Moon, H., & Yang, G.-H. (2023). A Meal-Assistance Robot System for Asian Food and Its Food Acquisition Point Estimation and User Interface Based on Face Recognition. Applied Sciences, 13(5), 3216. https://doi.org/10.3390/app13053216