
A Novel Implicit Neural Representation for Volume Data


Abstract
:1. Introduction
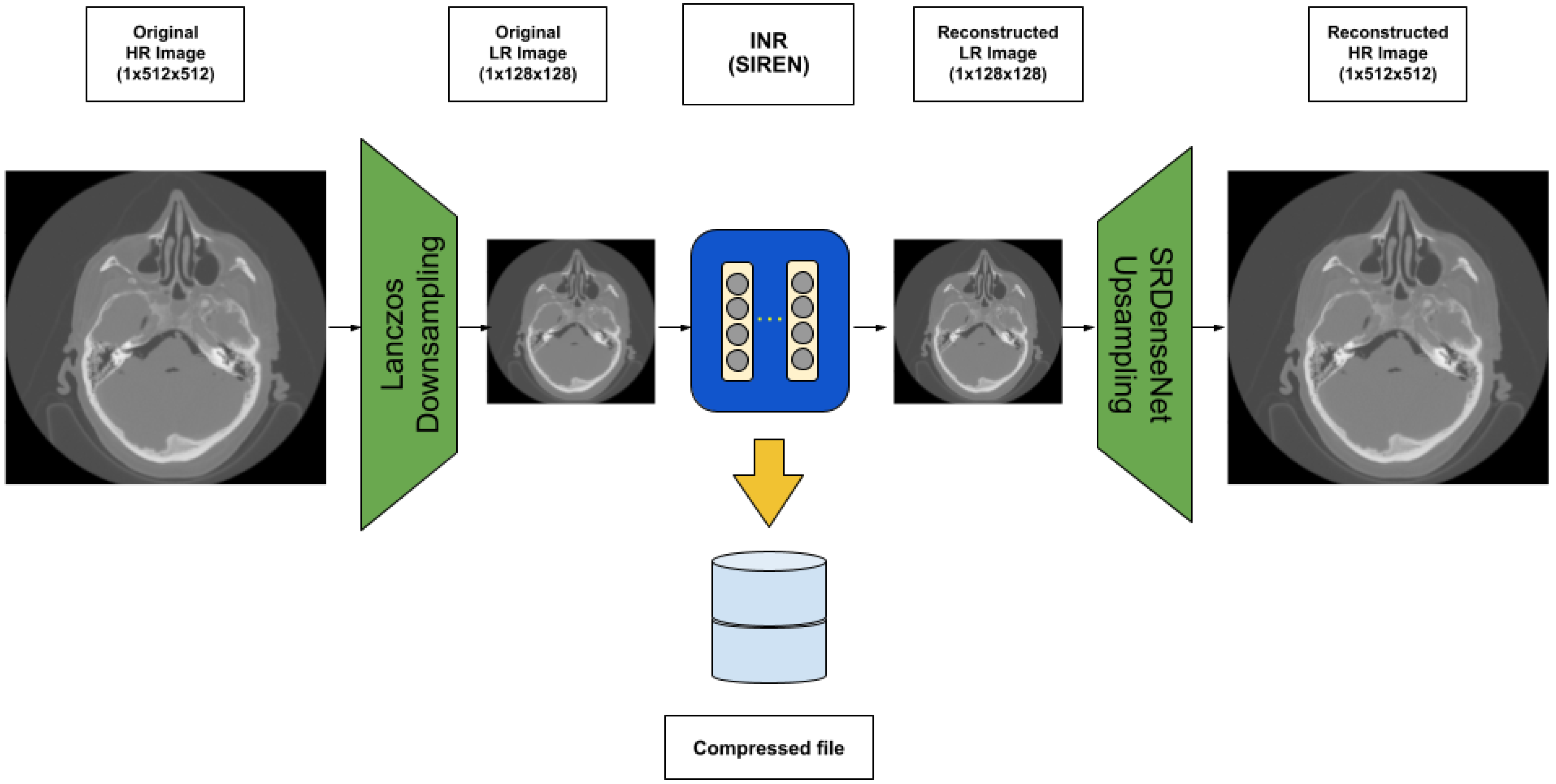
- Our architecture consists of the Lanczos downsampling scheme, SIREN deep network, and SRDenseNet upsampling scheme, which increase the speed of training and decrease the demand for GPU memory in comparison with existing INR-based compression techniques;
- Our architecture can reach both a high compression rate and high quality of the final volume data rendering.
2. Related Work
2.1. Implicit Neural Representation
2.2. Deep Neural Network in Medical Image Restoration
2.3. Deep Learning and Super-Resolution (SR) Techniques
2.4. Volume Data Compression
3. Methodology
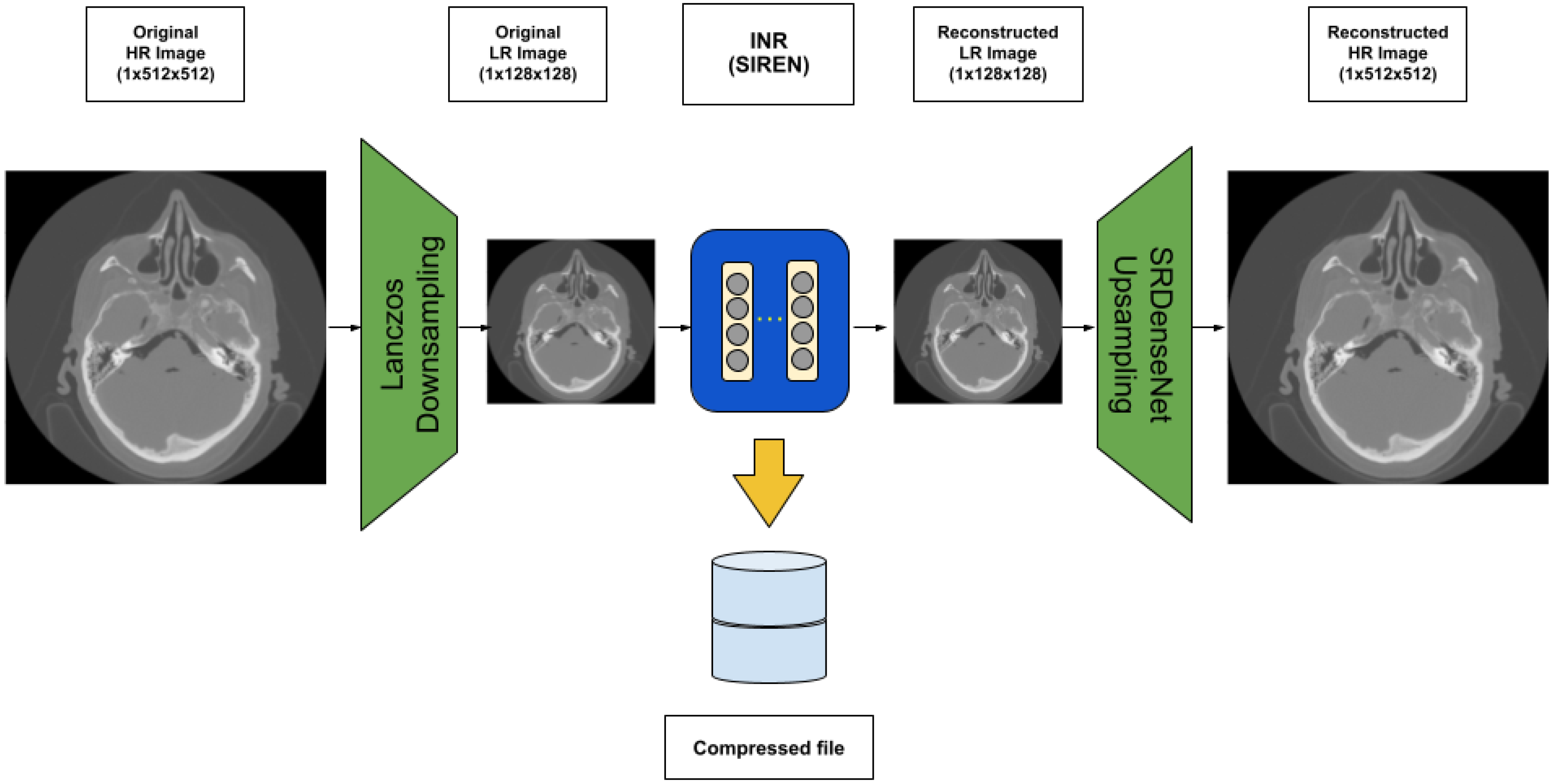
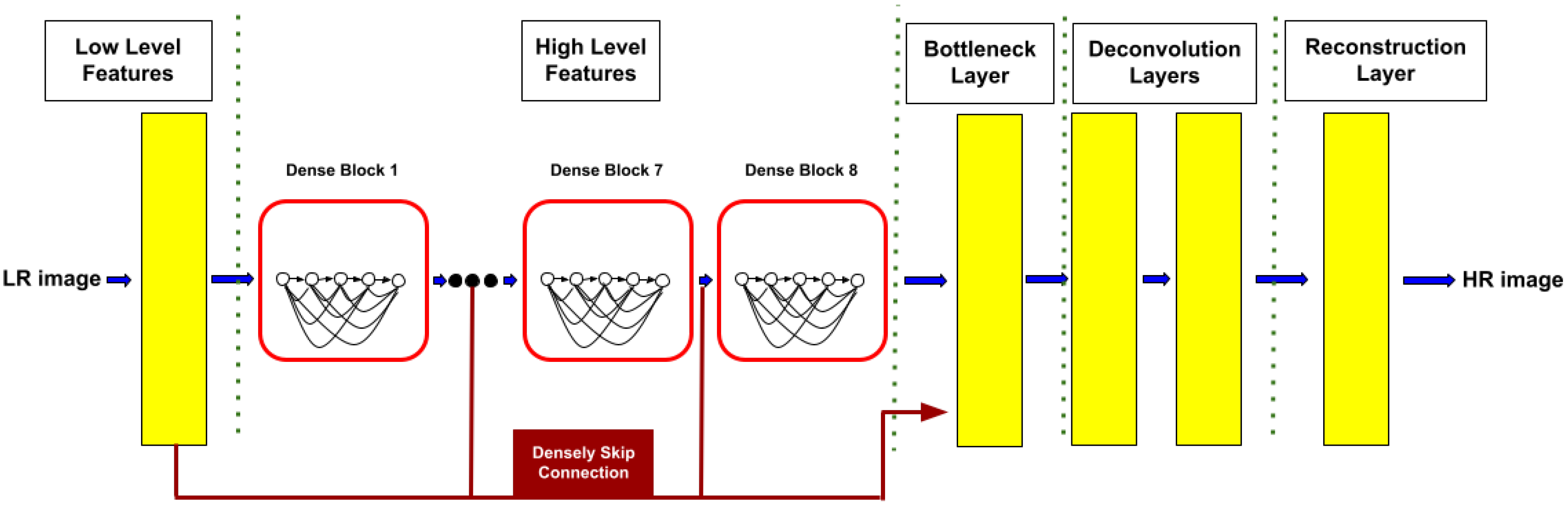
3.1. Our Architecture
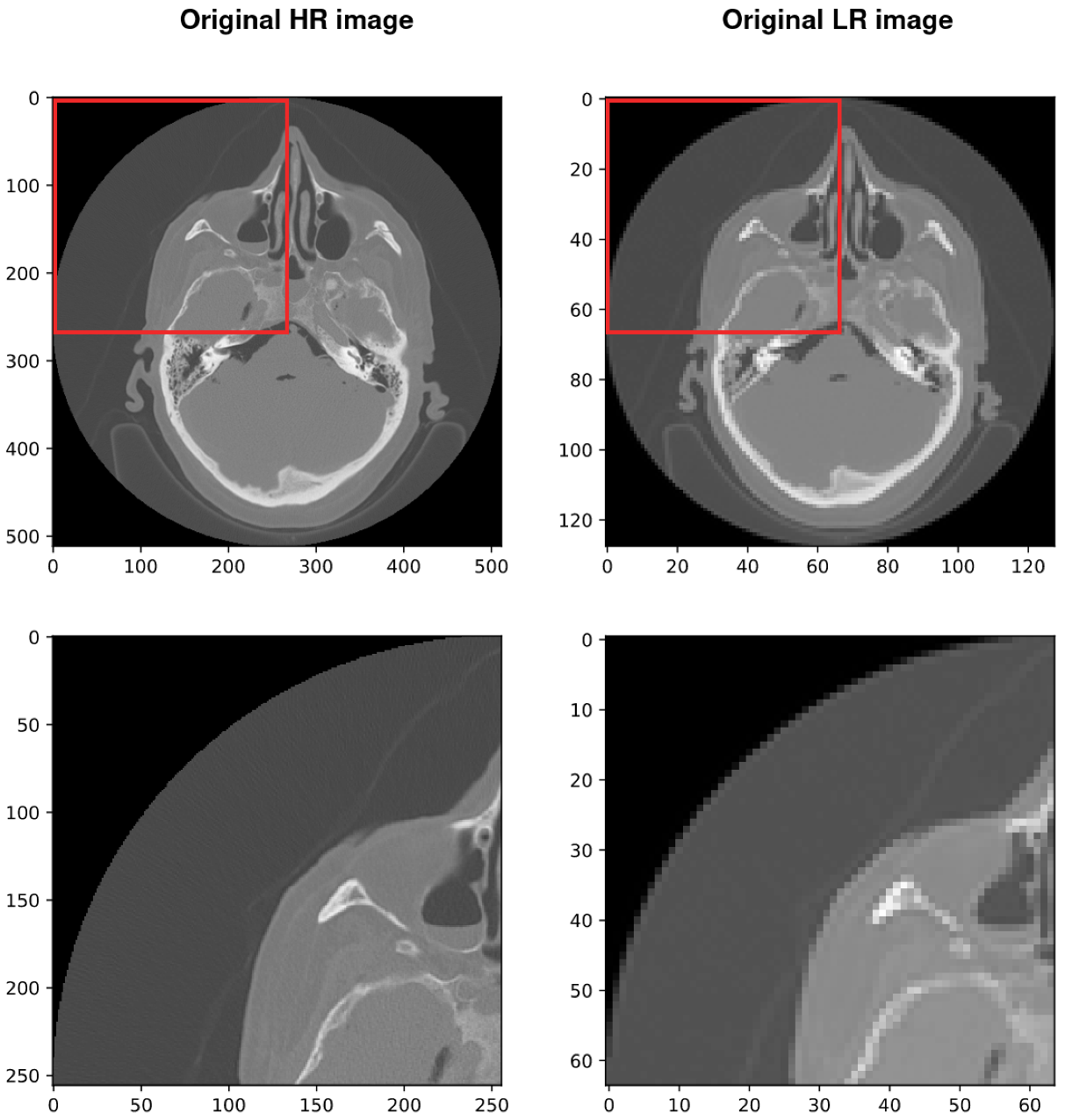
3.2. Lanczos Resampling
3.3. Sinusoidal Representation Networks (SIREN)
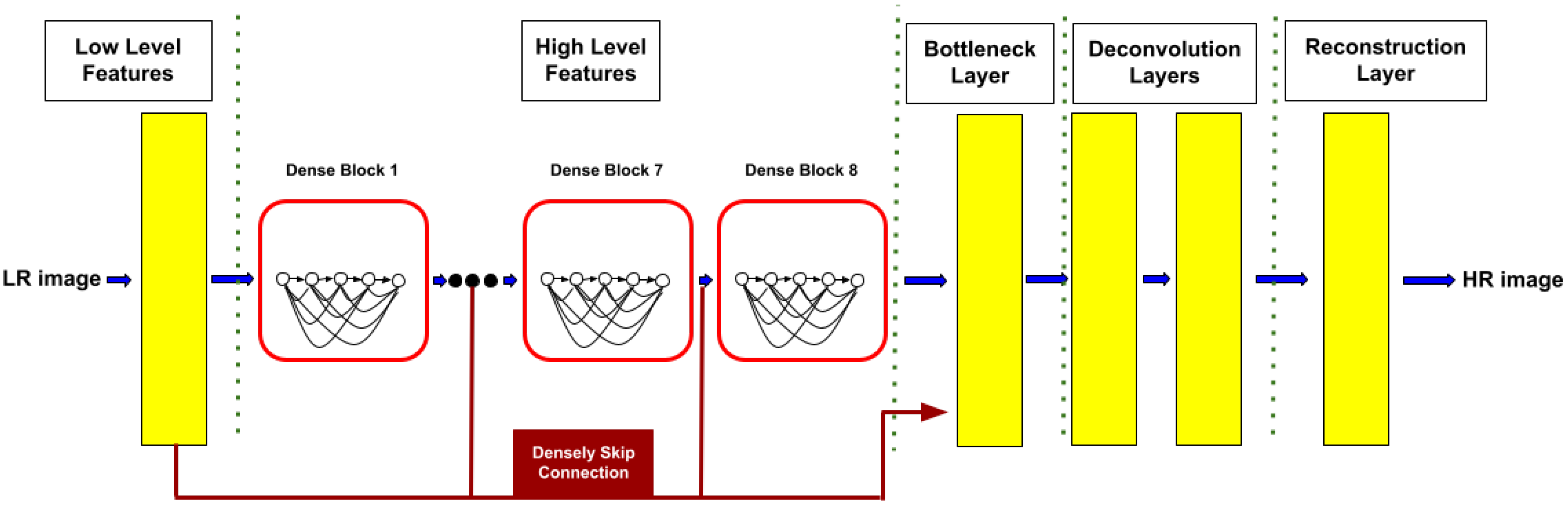
3.4. SRDenseNet
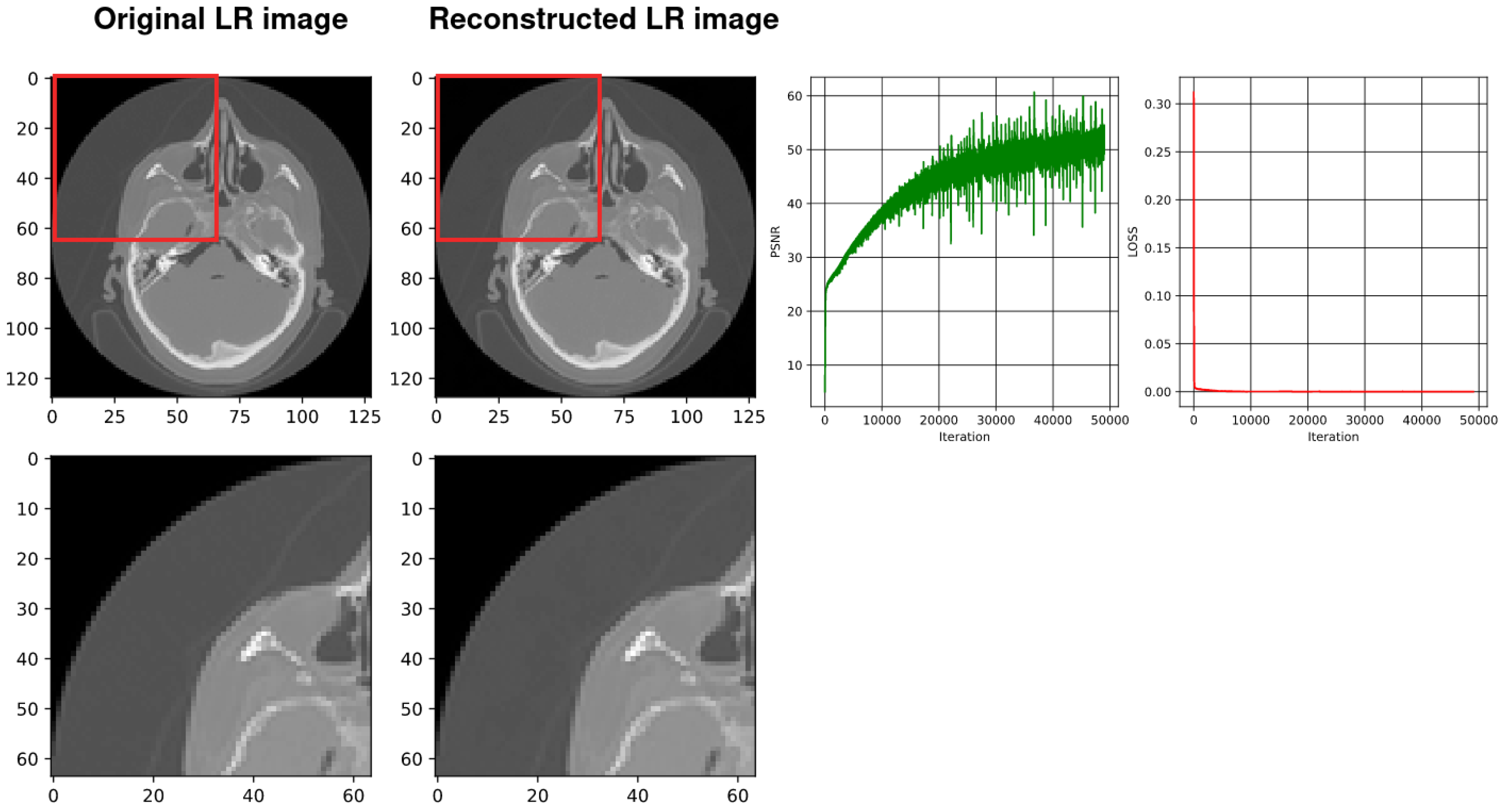
3.5. Peak Signal-to-Noise Ratio
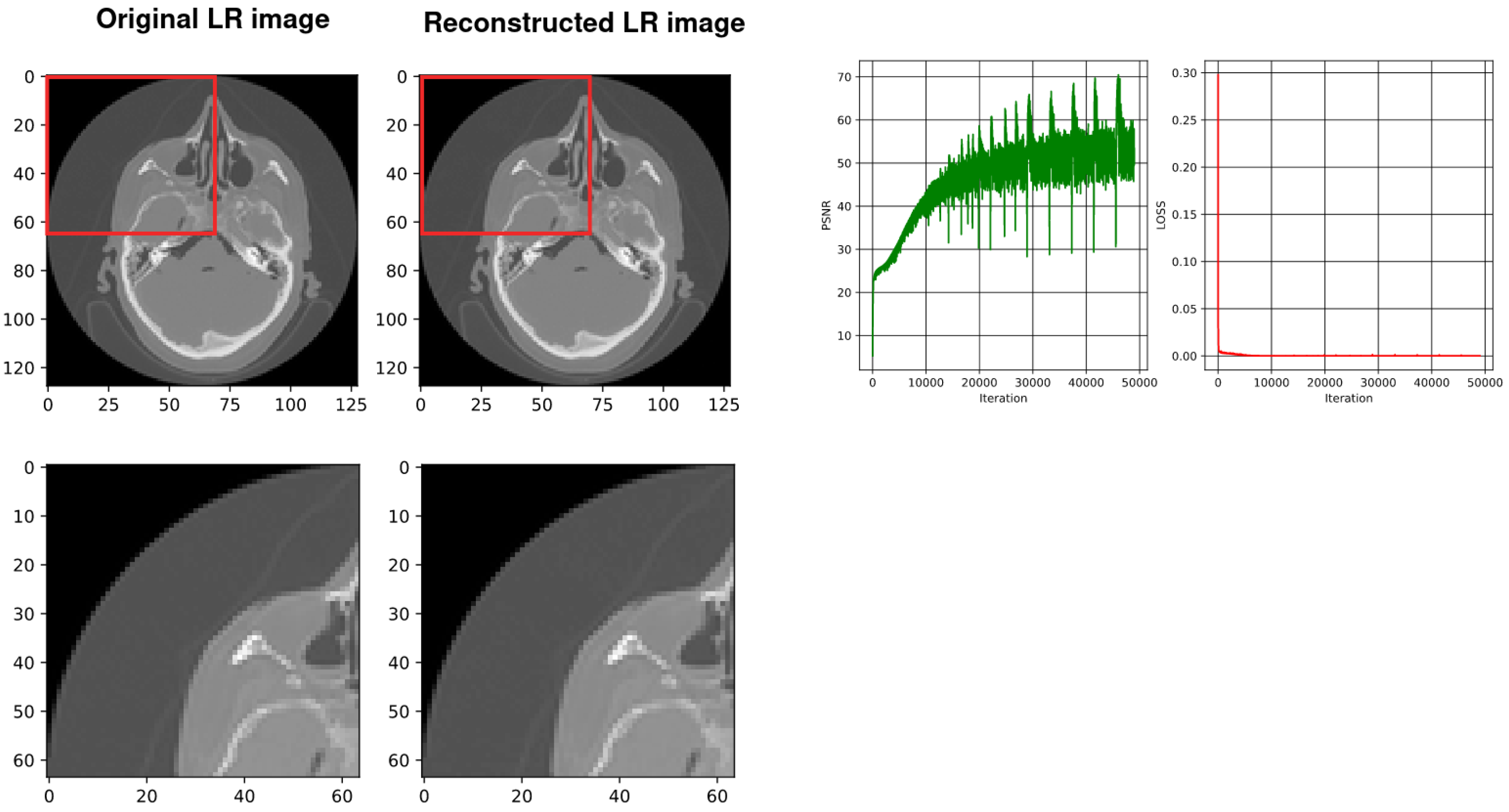
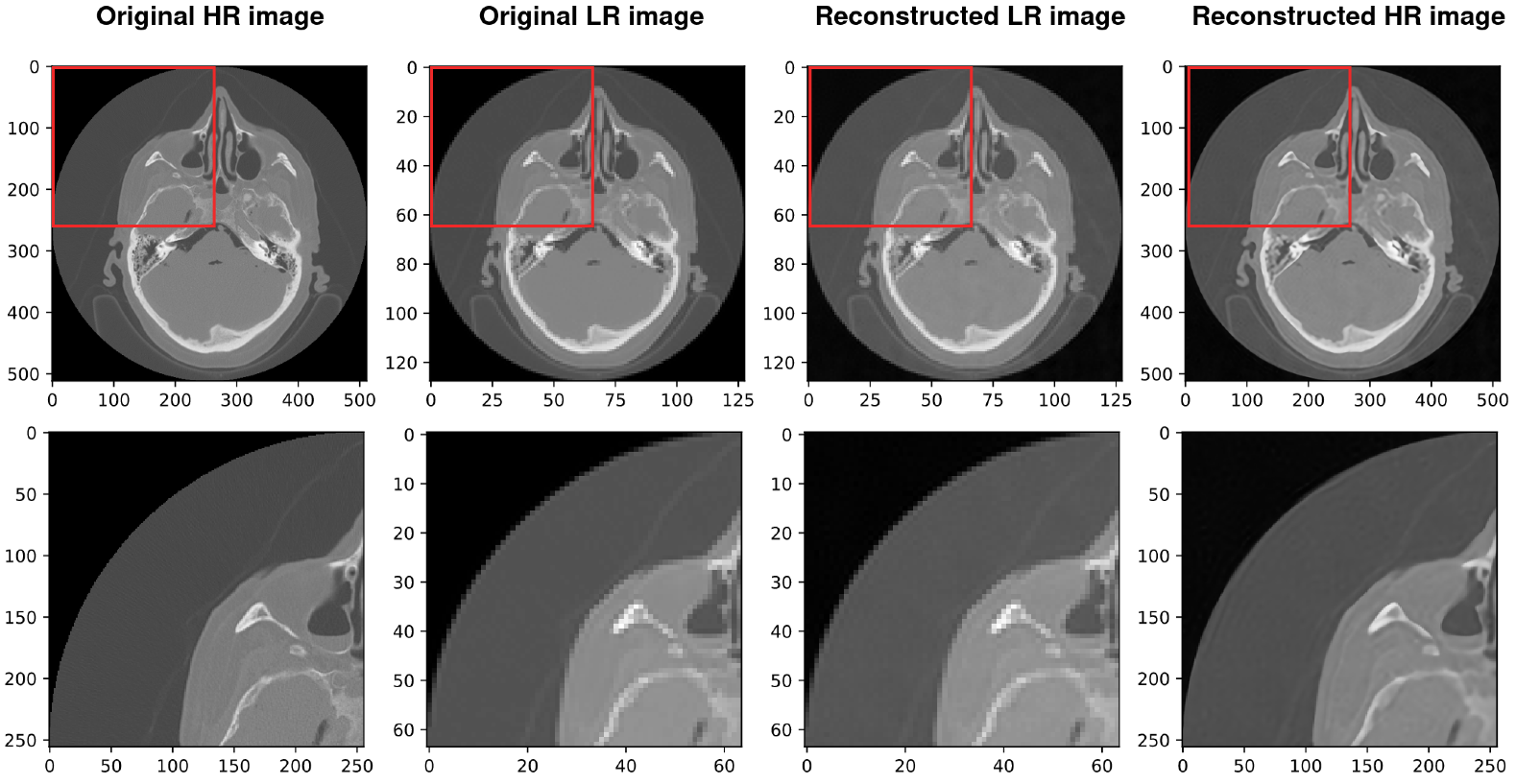
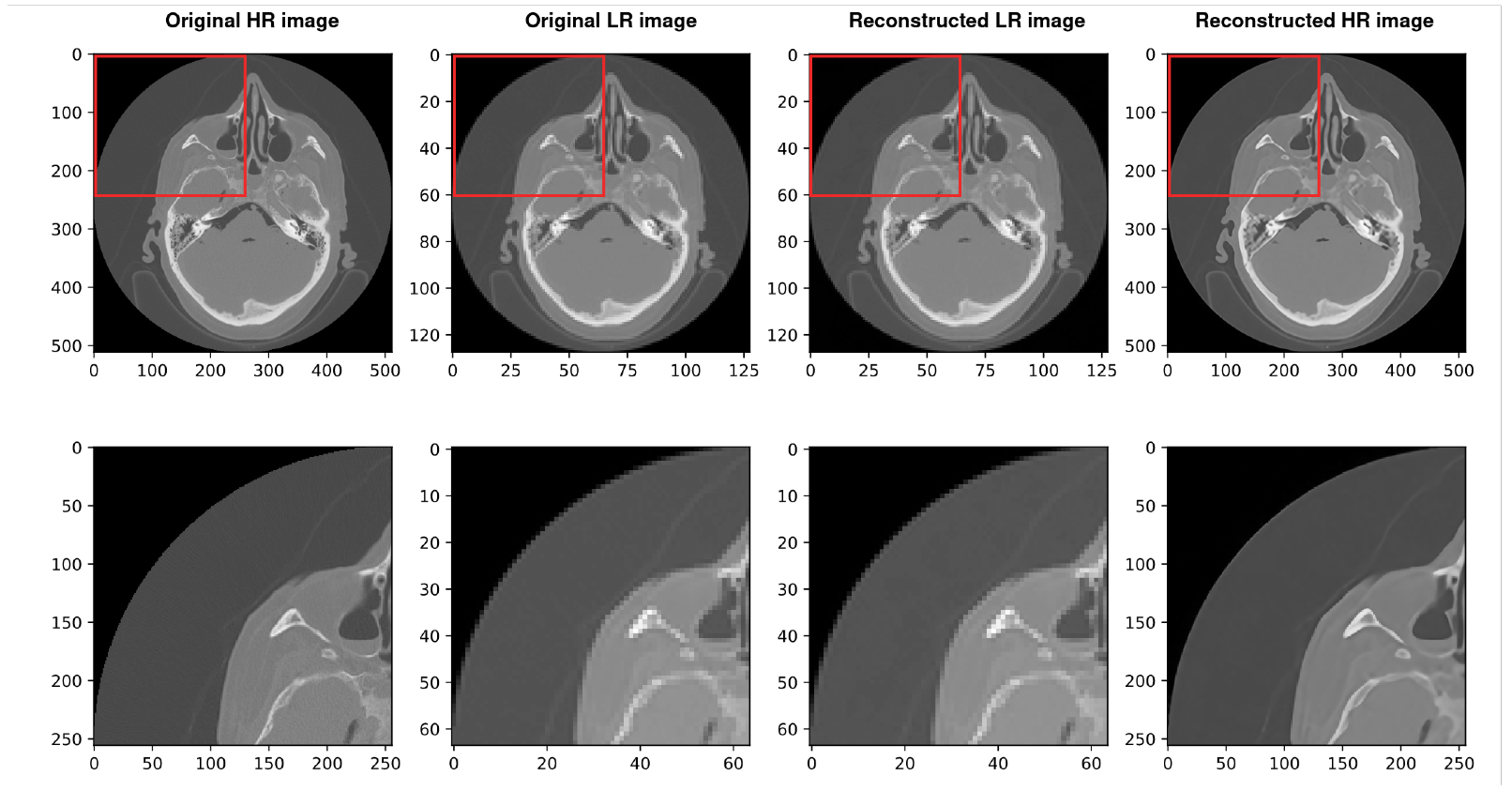
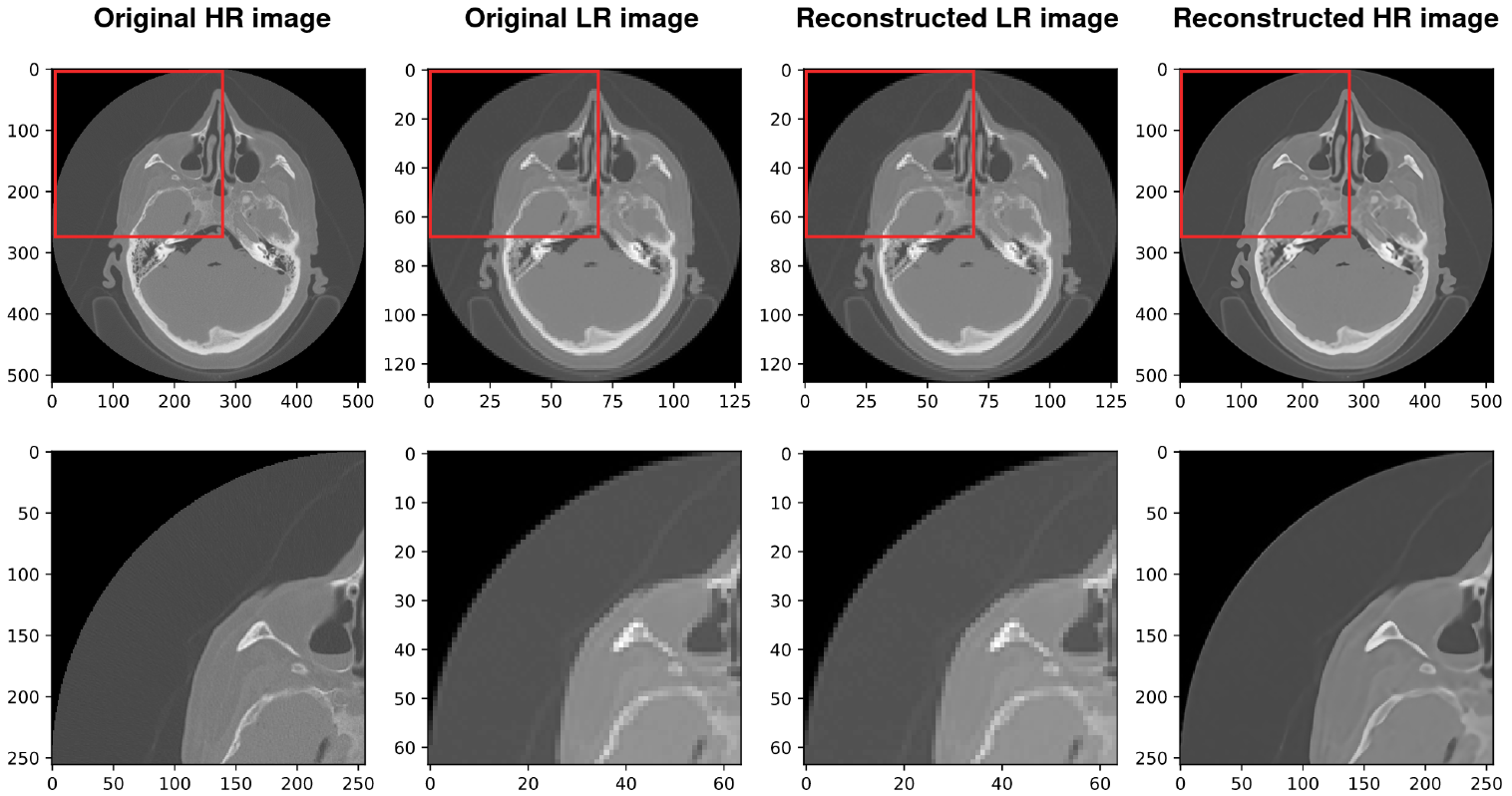
4. Results and Discussion
4.1. Dataset
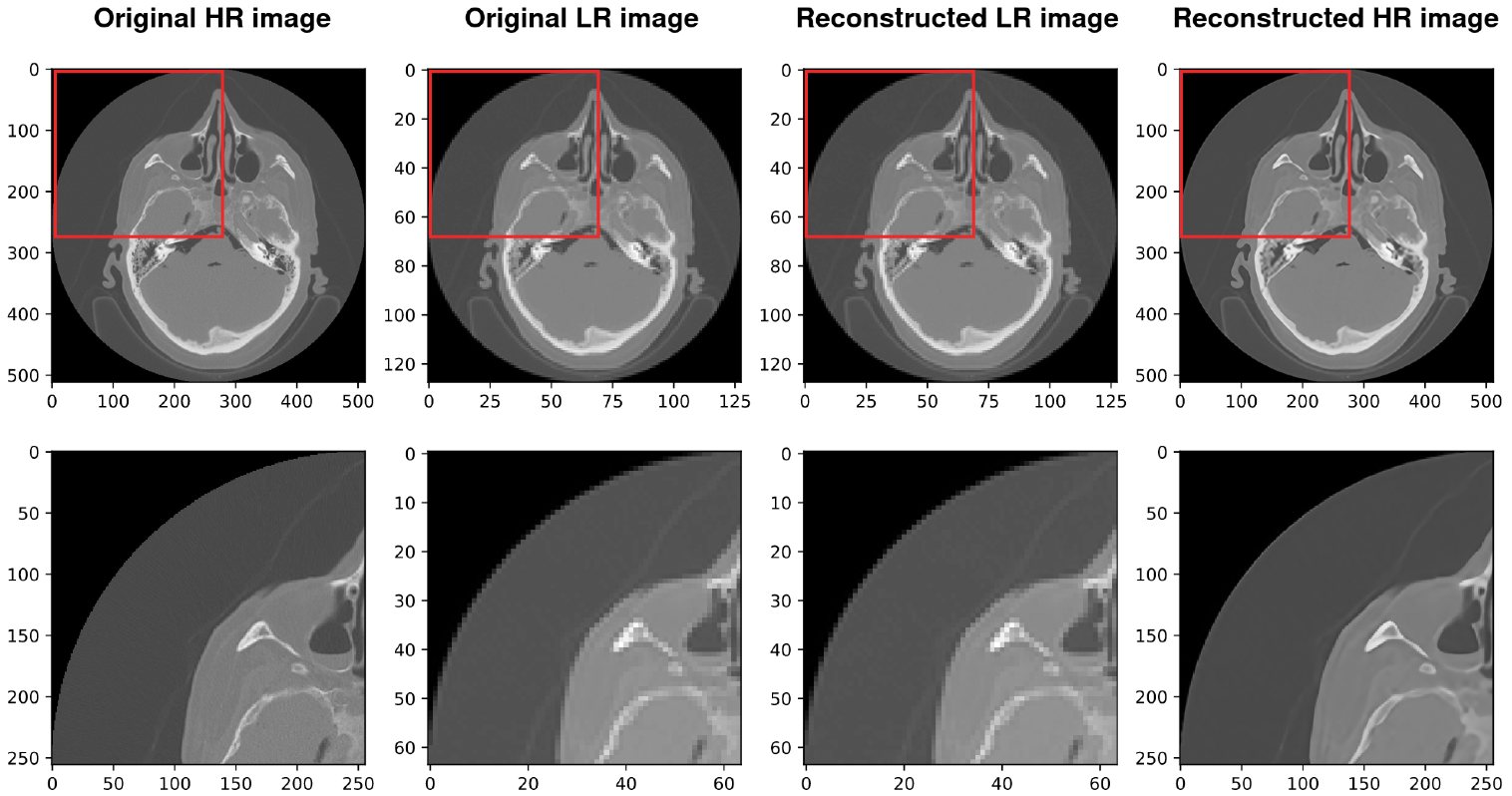
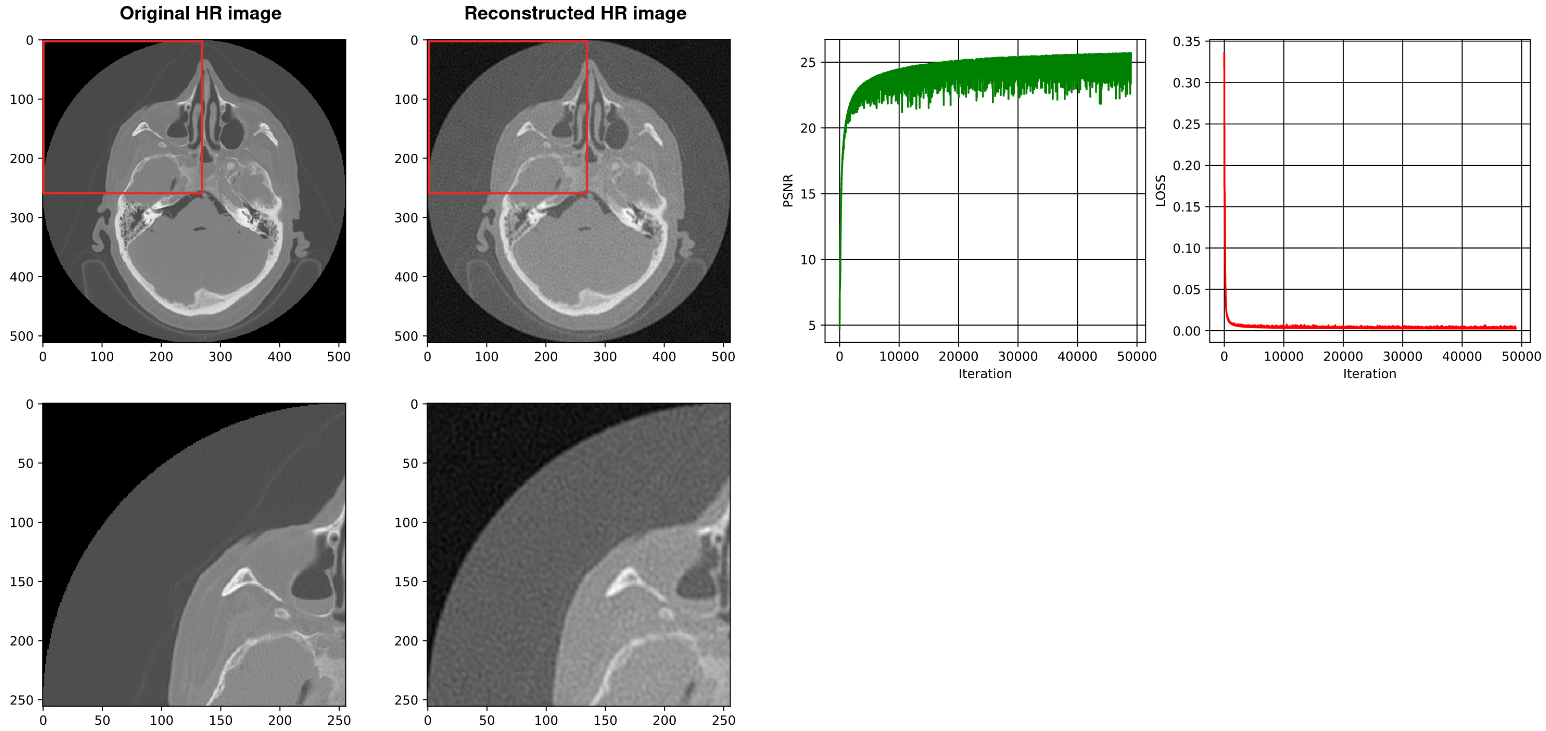
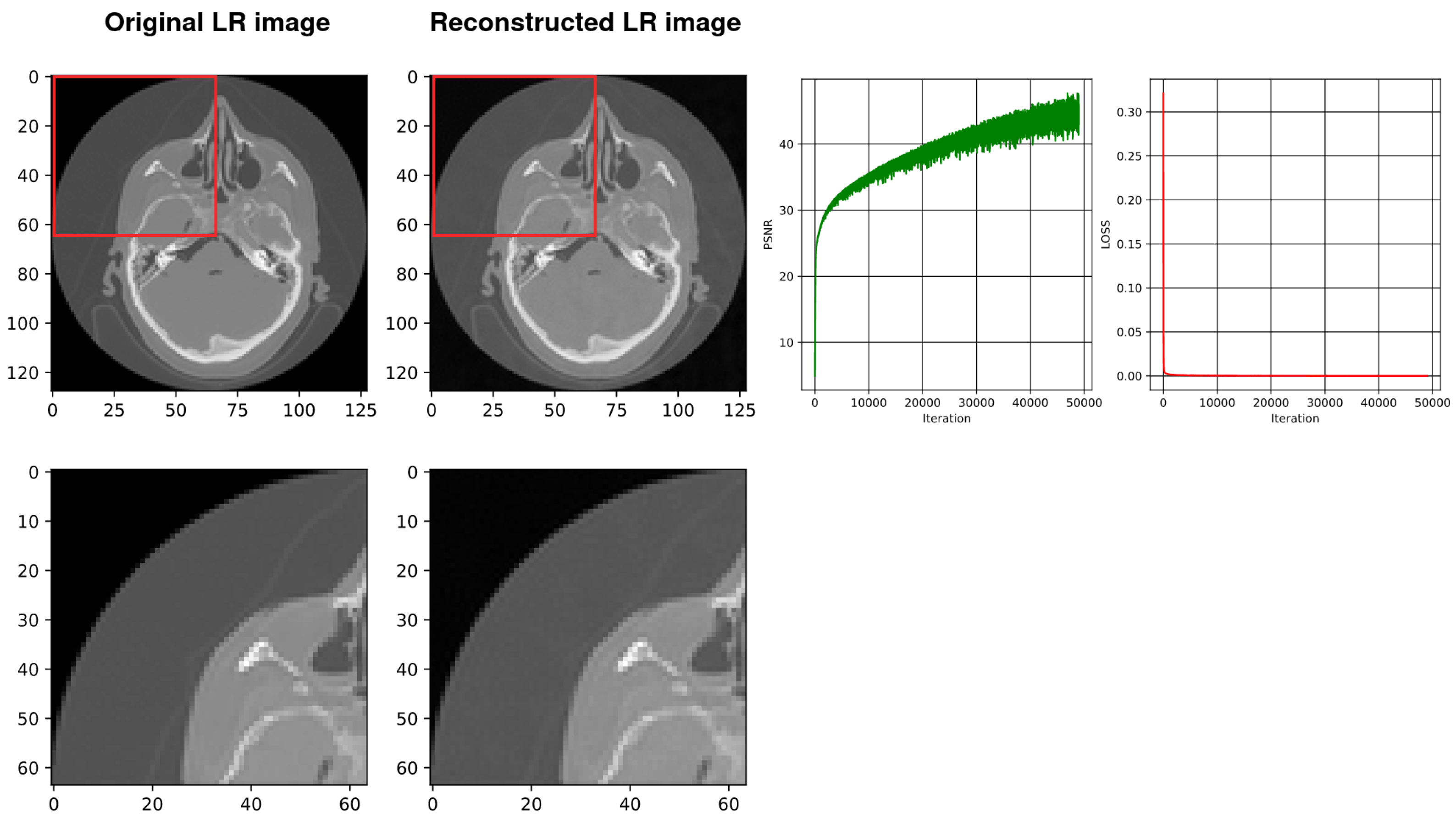
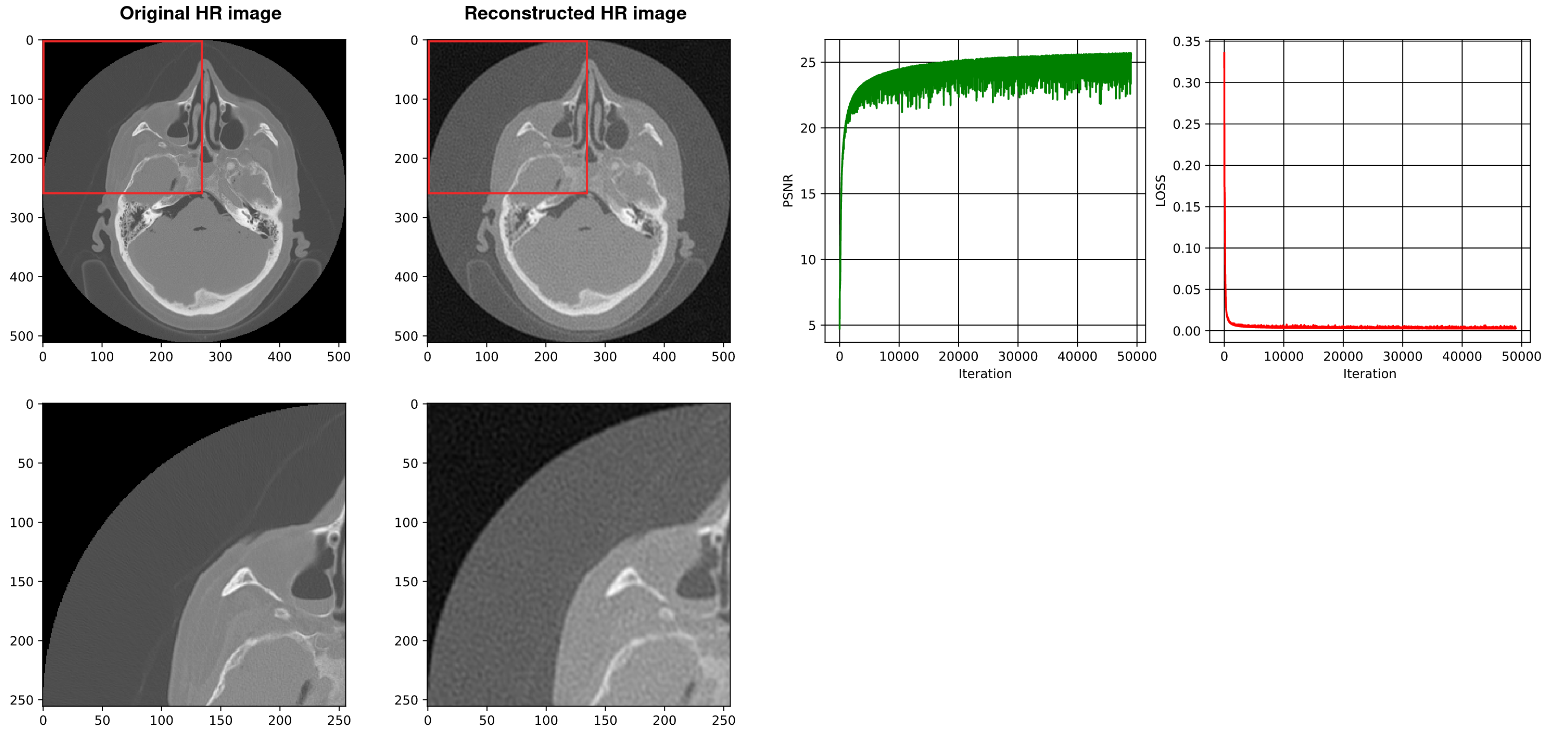
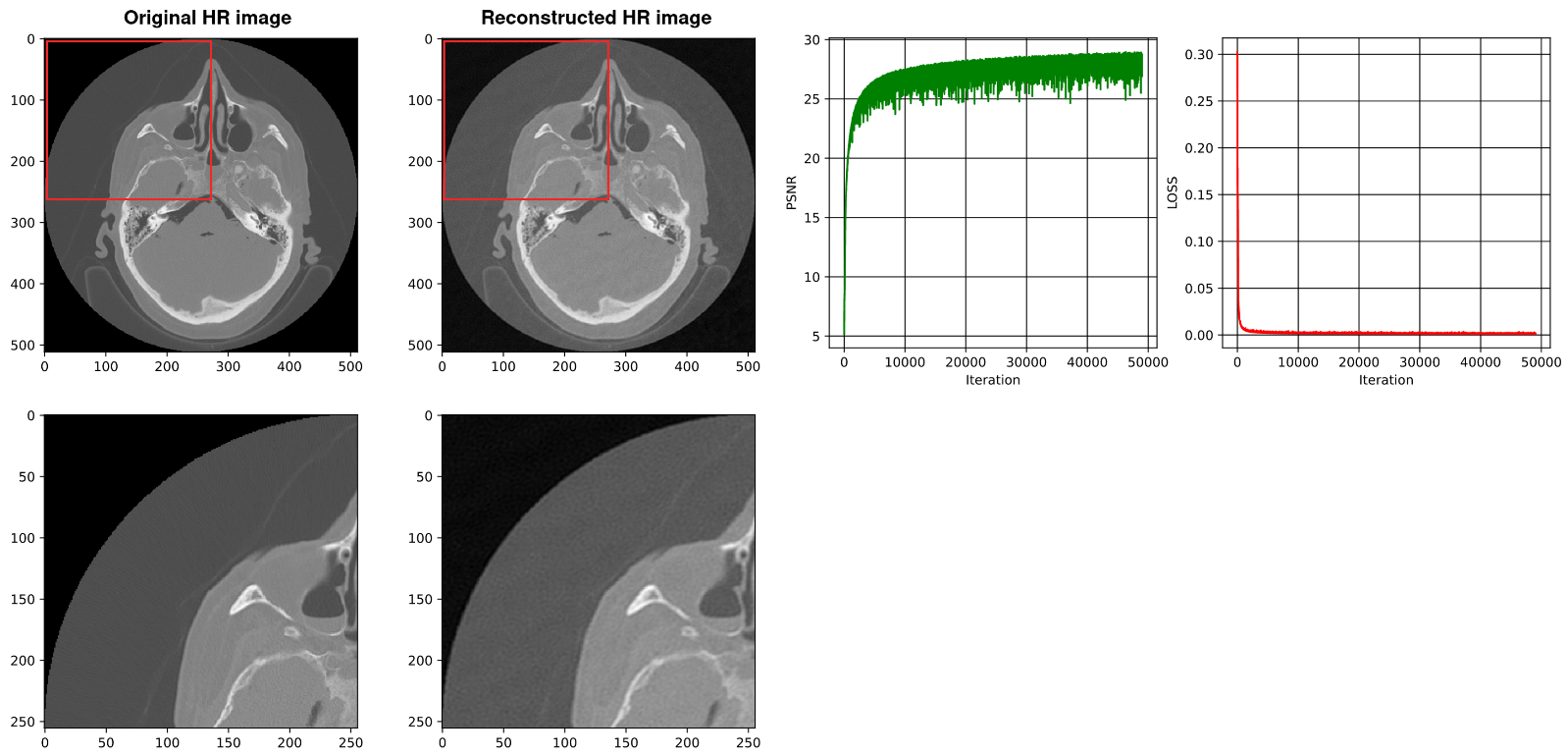
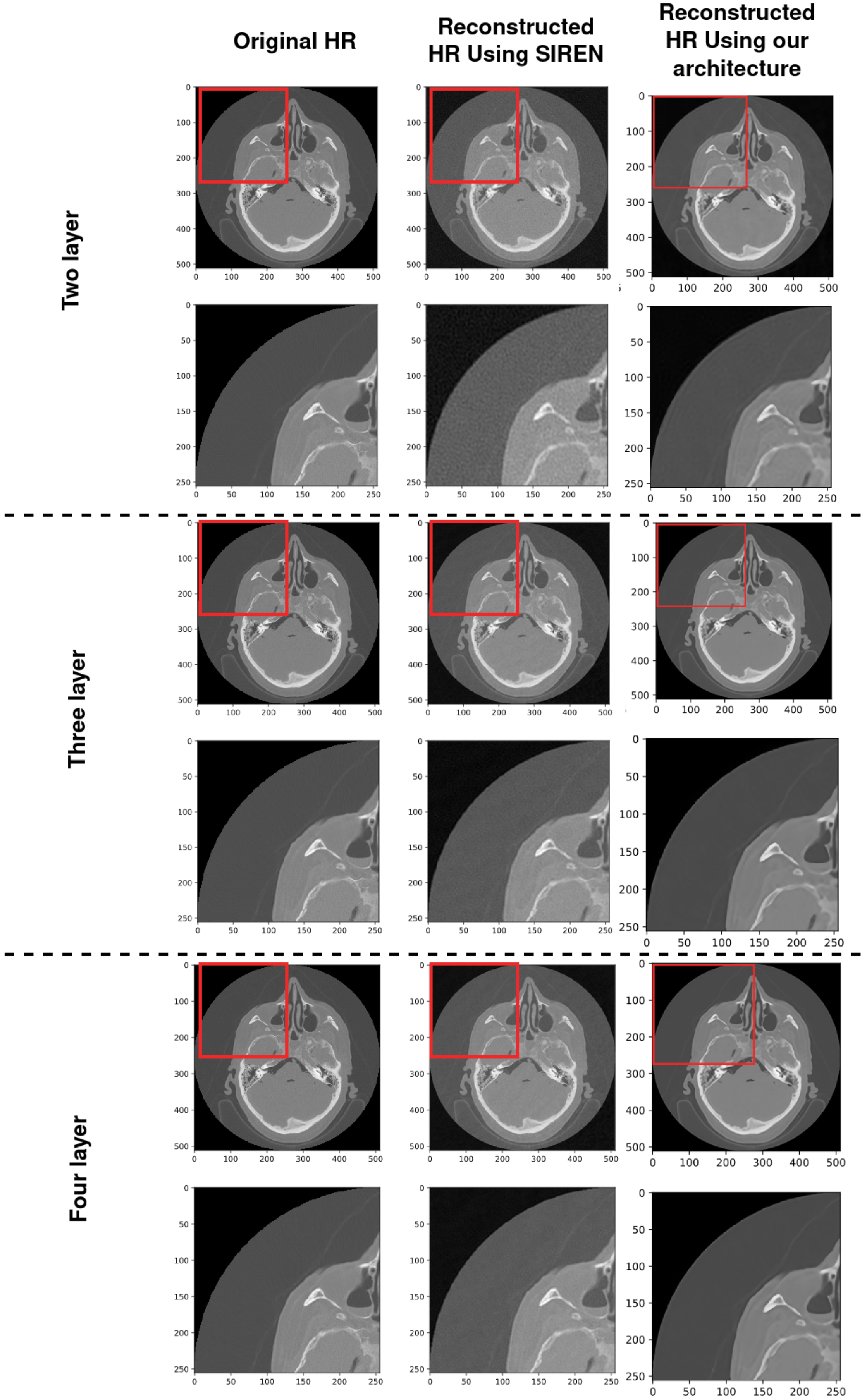
4.2. Using SIREN with Our Architecture
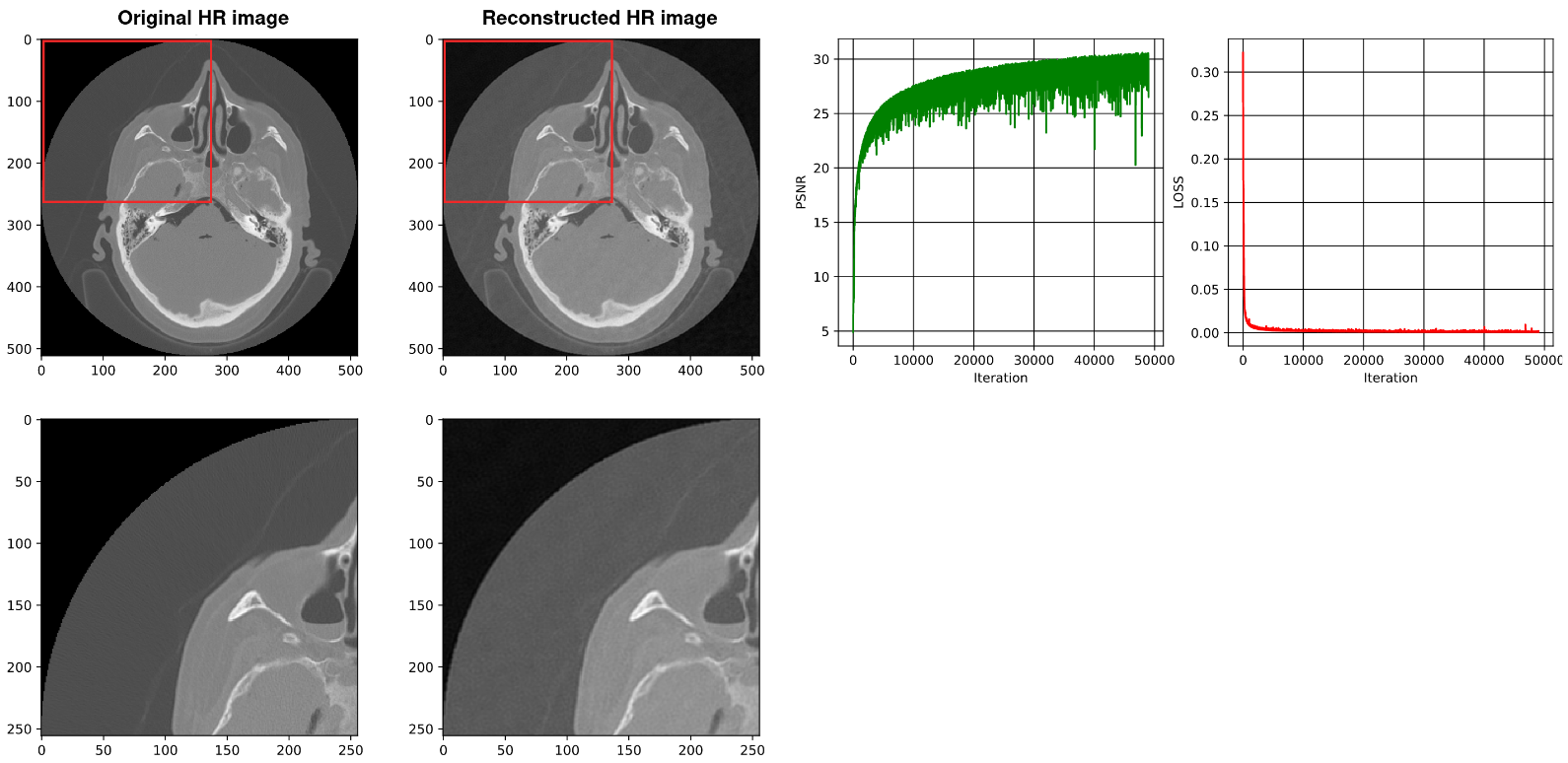
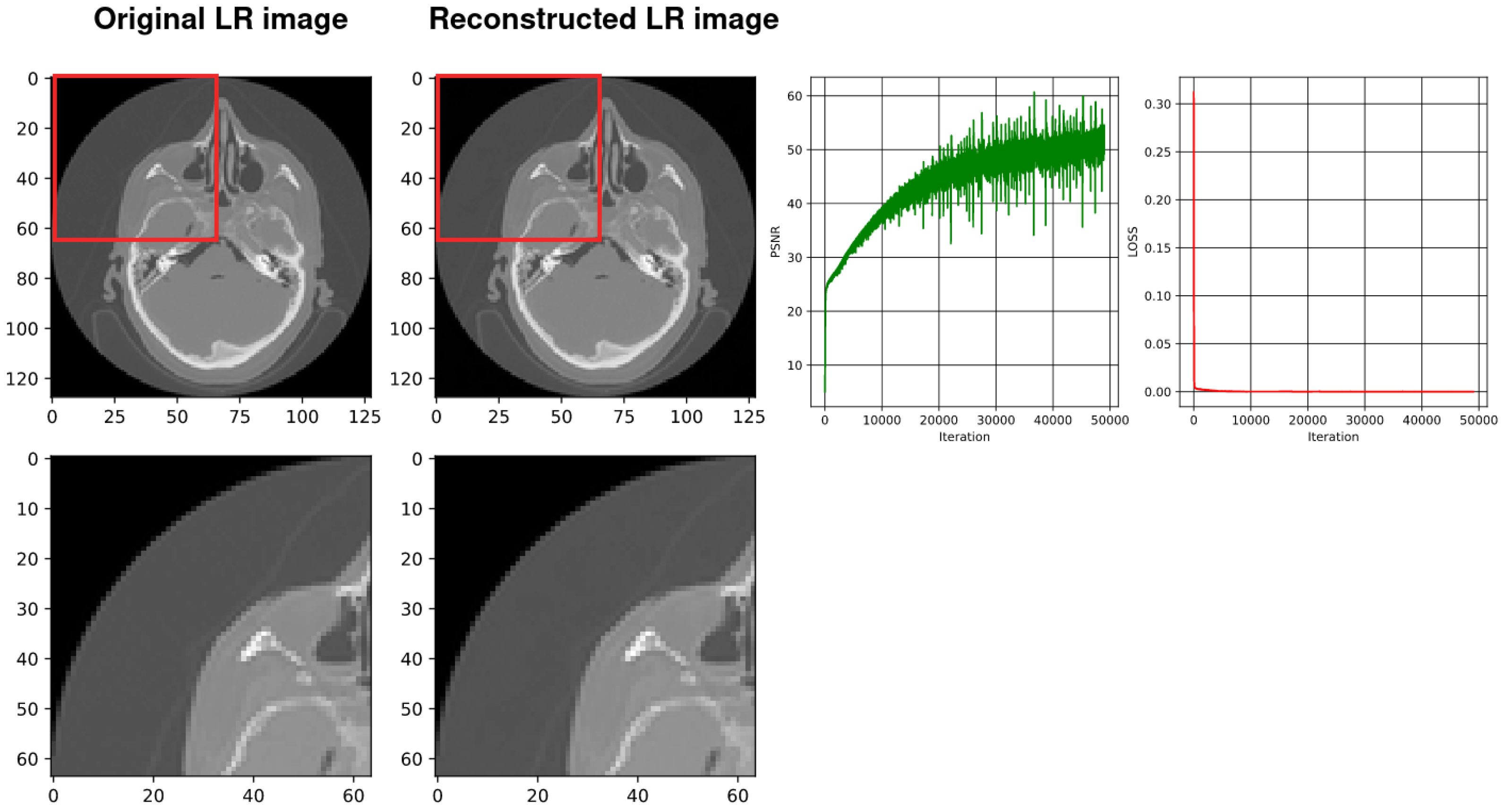
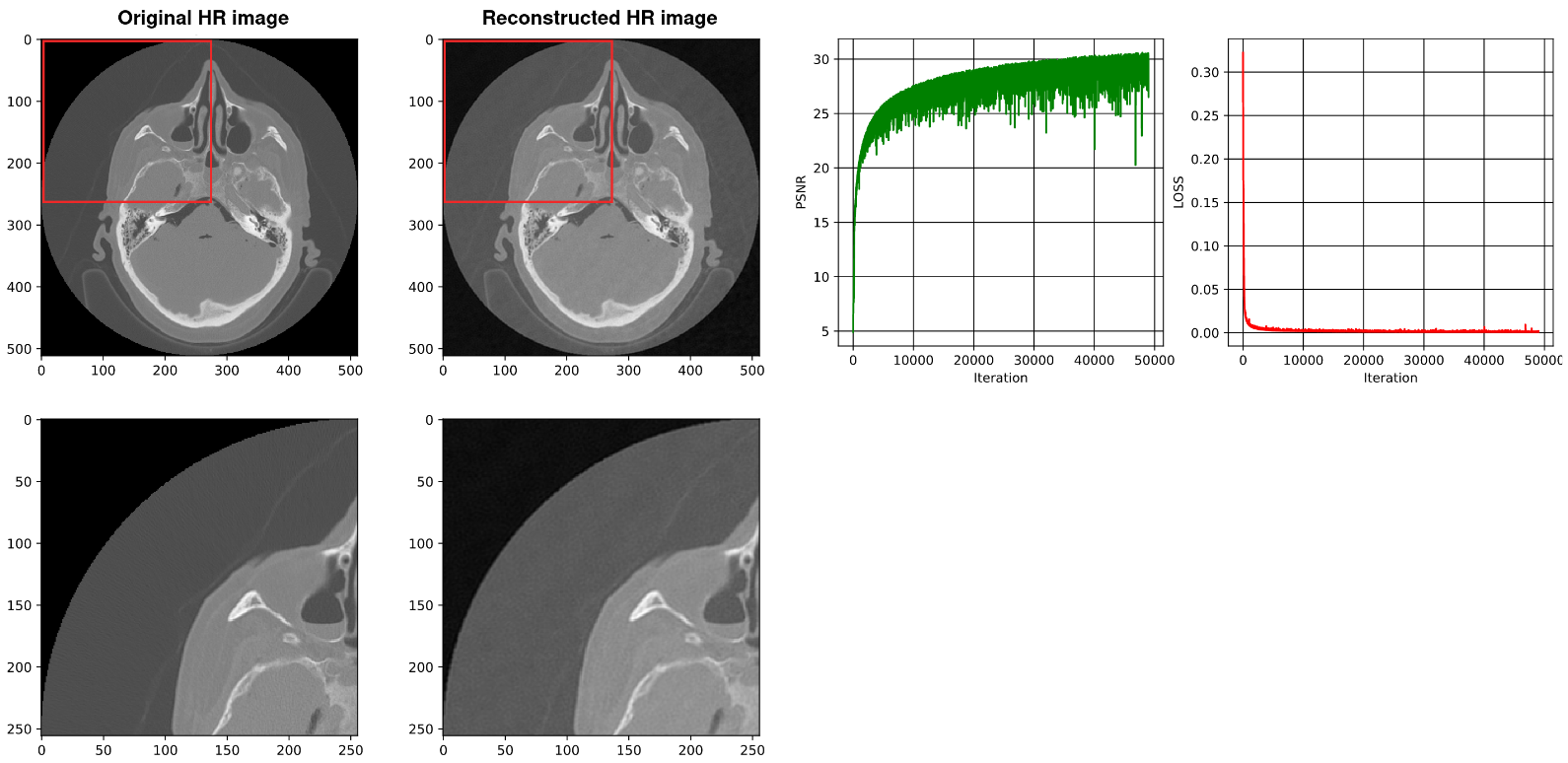
4.3. Using SIREN without Our Architecture [2]
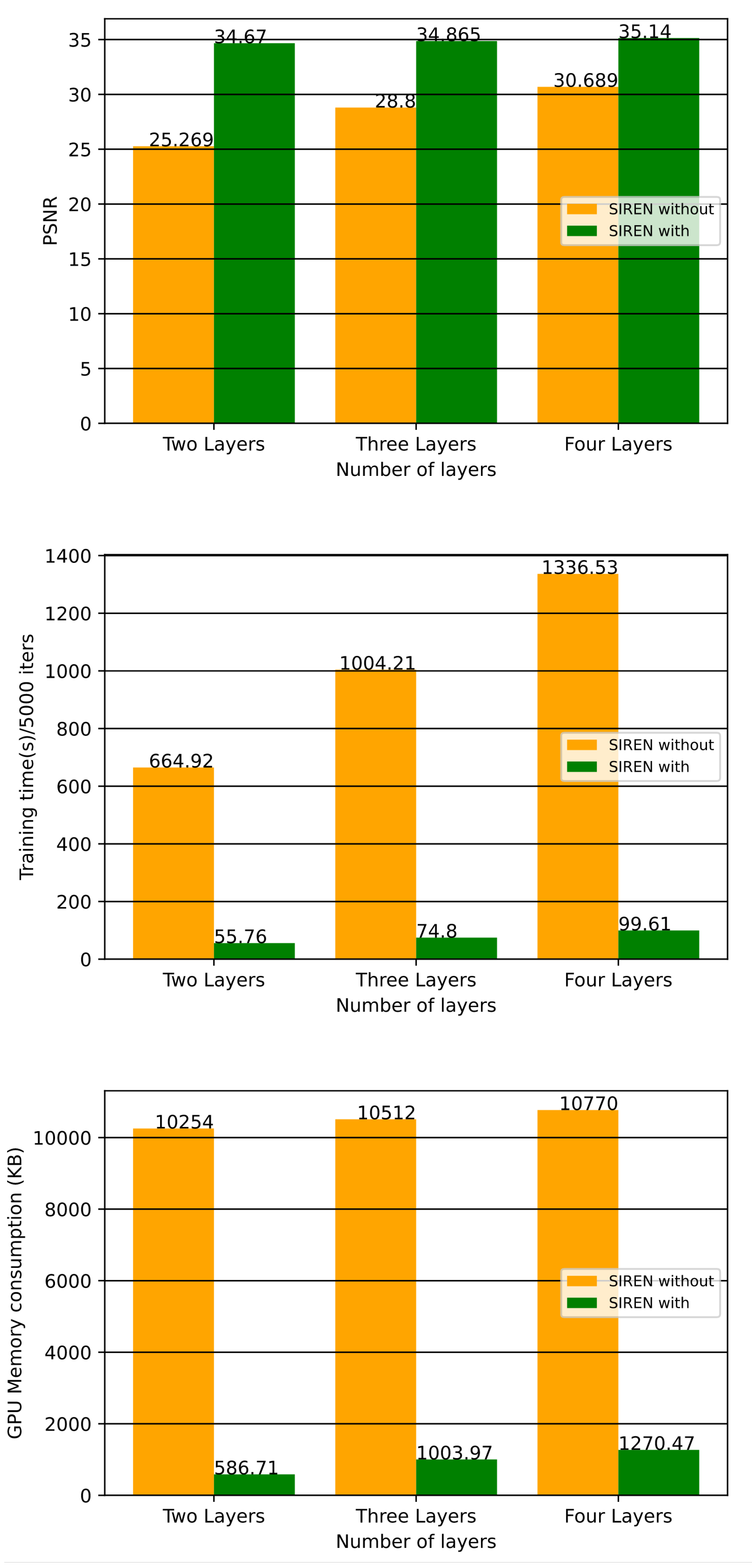
4.4. Comparison with Existing Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| INR | Implicit Neural Representation |
| MLP | Multi-Layer Perceptron |
| CT | Computed Tomography |
| SIREN | Sinusoidal representation network |
References
- Sitzmann, V.; Martel, J.N.P.; Bergman, A.W.; Lindell, D.B.; Wetzstein, G. Implicit Neural Representations with Periodic Activation Functions. arXiv 2020, arXiv:2006.09661. [Google Scholar] [CrossRef]
- Mancini, M.; Jones, D.K.; Palombo, M. Lossy compression of multidimensional medical images using sinusoidal activation networks: An evaluation study. arXiv 2022, arXiv:2208.01602. [Google Scholar] [CrossRef]
- Strümpler, Y.; Postels, J.; Yang, R.; van Gool, L.; Tombari, F. Implicit Neural Representations for Image Compression. arXiv 2021, arXiv:2112.04267. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, C.; Zhang, X.; Zhang, Z.; Freeman, W.T.; Tenenbaum, J.B. Learning Shape Priors for Single-View 3D Completion and Reconstruction. arXiv 2018, arXiv:1809.05068. [Google Scholar] [CrossRef]
- Khan, M.O.; Fang, Y. Implicit Neural Representations for Medical Imaging Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2022; Wang, L., Dou, Q., Fletcher, P.T., Speidel, S., Li, S., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 433–443. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. arXiv 2019, arXiv:1901.05103. [Google Scholar] [CrossRef]
- Tang, D.; Singh, S.; Chou, P.A.; Haene, C.; Dou, M.; Fanello, S.; Taylor, J.; Davidson, P.; Guleryuz, O.G.; Zhang, Y.; et al. Deep Implicit Volume Compression. arXiv 2020, arXiv:2005.08877. [Google Scholar] [CrossRef]
- Nagoor, O.H.; Whittle, J.; Deng, J.; Mora, B.; Jones, M.W. MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM). In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2874–2881. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. arXiv 2020, arXiv:2003.08934. [Google Scholar] [CrossRef]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. arXiv 2018, arXiv:1812.03828. [Google Scholar] [CrossRef]
- Dupont, E.; Goliński, A.; Alizadeh, M.; Teh, Y.W.; Doucet, A. COIN: COmpression with Implicit Neural representations. arXiv 2021, arXiv:2103.03123. [Google Scholar] [CrossRef]
- Skorokhodov, I.; Ignatyev, S.; Elhoseiny, M. Adversarial Generation of Continuous Images. arXiv 2020, arXiv:2011.12026. [Google Scholar] [CrossRef]
- Shen, L.; Pauly, J.; Xing, L. NeRP: Implicit Neural Representation Learning with Prior Embedding for Sparsely Sampled Image Reconstruction. arXiv 2021, arXiv:2108.10991. [Google Scholar] [CrossRef] [PubMed]
- Eslami, S.M.A.; Rezende, D.J.; Besse, F.; Viola, F.; Morcos, A.S.; Garnelo, M.; Ruderman, A.; Rusu, A.A.; Danihelka, I.; Gregor, K.; et al. Neural scene representation and rendering. Science 2018, 360, 1204–1210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tancik, M.; Srinivasan, P.P.; Mildenhall, B.; Fridovich-Keil, S.; Raghavan, N.; Singhal, U.; Ramamoorthi, R.; Barron, J.T.; Ng, R. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; NIPS’20; Curran Associates Inc.: Red Hook, NY, USA, 2022. [Google Scholar]
- Dar, S.U.H.; Özbey, M.; Çatlı, A.B.; Çukur, T. A Transfer-Learning Approach for Accelerated MRI Using Deep Neural Networks. Magn. Reson. Med. 2020, 84, 663–685. [Google Scholar] [CrossRef] [Green Version]
- Qin, C.; Schlemper, J.; Caballero, J.; Price, A.N.; Hajnal, J.V.; Rueckert, D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med Imaging 2019, 38, 280–290. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Ma, Y.; Liu, J.; Du, J.; Xing, L. Self-attention convolutional neural network for improved MR image reconstruction. Inf. Sci. 2019, 490, 317–328. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhang, Y.; Zhao, Q.; Lv, T.; Wu, W.; Cai, N.; Quan, G.; Yang, W.; Chen, Y.; Luo, L.; et al. Deep iterative reconstruction estimation (DIRE): Approximate iterative reconstruction estimation for low dose CT imaging. Phys. Med. Biol. 2019, 64, 135007. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liang, J.; Cheng, J.; Guo, Y.; Zeng, L. Deep learning based image reconstruction algorithm for limited-angle translational computed tomography. PLoS ONE 2020, 15, e0226963. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.; Shan, H.; Wang, G. Deep Encoder-Decoder Adversarial Reconstruction (DEAR) Network for 3D CT from Few-View Data. Bioengineering 2019, 6, 111. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Zheng, X.; Chen, Y.; Xie, L.; Liu, J.; Zhang, Y.; Yan, J.; Zhu, H.; Hu, Y. Artifact removal using improved GoogLeNet for sparse-view CT reconstruction. Sci. Rep. 2018, 8, 6700. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Zeng, X.; Huang, Z.; Li, W.; Zhang, H. Low-dose chest X-ray image super-resolution using generative adversarial nets with spectral normalization. Biomed. Signal Process. Control 2020, 55, 101600. [Google Scholar] [CrossRef]
- Khodajou-Chokami, H.; Hosseini, S.A.; Ay, M.R. A deep learning method for high-quality ultra-fast CT image reconstruction from sparsely sampled projections. Nucl. Instruments Methods Phys. Res. Sect. Accel. Spectrometers Detect. Assoc. Equip. 2022, 1029, 166428. [Google Scholar] [CrossRef]
- Wang, T.; He, M.; Shen, K.; Liu, W.; Tian, C. Learned regularization for image reconstruction in sparse-view photoacoustic tomography. Biomed. Opt. Express 2022, 13, 5721–5737. [Google Scholar] [CrossRef] [PubMed]
- Gong, K.; Catana, C.; Qi, J.; Li, Q. Direct Reconstruction of Linear Parametric Images From Dynamic PET Using Nonlocal Deep Image Prior. IEEE Trans. Med Imaging 2022, 41, 680–689. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Häggström, I.; Schmidtlein, C.R.; Campanella, G.; Fuchs, T.J. DeepPET: A deep encoder–decoder network for directly solving the PET image reconstruction inverse problem. Med Image Anal. 2019, 54, 253–262. [Google Scholar] [CrossRef] [PubMed]
- Kandarpa, V.S.S.; Bousse, A.; Benoit, D.; Visvikis, D. DUG-RECON: A Framework for Direct Image Reconstruction Using Convolutional Generative Networks. IEEE Trans. Radiat. Plasma Med Sci. 2021, 5, 44–53. [Google Scholar] [CrossRef]
- Yokota, T.; Kawai, K.; Sakata, M.; Kimura, Y.; Hontani, H. Dynamic PET Image Reconstruction Using Nonnegative Matrix Factorization Incorporated With Deep Image Prior. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Hu, D.; Hao, S.; Liu, J.; Quan, G.; Zhang, Y.; Ji, X.; Chen, Y. DREAM-Net: Deep Residual Error Iterative Minimization Network for Sparse-View CT Reconstruction. IEEE J. Biomed. Health Inform. 2023, 27, 480–491. [Google Scholar] [CrossRef]
- Xie, H.; Thorn, S.; Liu, Y.H.; Lee, S.; Liu, Z.; Wang, G.; Sinusas, A.J.; Liu, C. Deep-Learning-Based Few-Angle Cardiac SPECT Reconstruction Using Transformer. IEEE Trans. Radiat. Plasma Med Sci. 2023, 7, 33–40. [Google Scholar] [CrossRef]
- Hu, D.; Zhang, Y.; Liu, J.; Luo, S.; Chen, Y. DIOR: Deep Iterative Optimization-Based Residual-Learning for Limited-Angle CT Reconstruction. IEEE Trans. Med Imaging 2022, 41, 1778–1790. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sens. 2022, 14. [Google Scholar] [CrossRef]
- Arefin, M.R.; Michalski, V.; St-Charles, P.L.; Kalaitzis, A.; Kim, S.; Kahou, S.E.; Bengio, Y. Multi-image super-resolution for remote sensing using deep recurrent networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 206–207. [Google Scholar]
- Yu, Y.; Li, X.; Liu, F. E-DBPN: Enhanced deep back-projection networks for remote sensing scene image superresolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5503–5515. [Google Scholar] [CrossRef]
- Chen, S.; Han, Z.; Dai, E.; Jia, X.; Liu, Z.; Xing, L.; Zou, X.; Xu, C.; Liu, J.; Tian, Q. Unsupervised image super-resolution with an indirect supervised path. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 468–469. [Google Scholar]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-Transfer Learning for Zero-Shot Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Gao, L.; Sun, H.M.; Cui, Z.; Du, Y.; Sun, H.; Jia, R. Super-resolution reconstruction of single remote sensing images based on residual channel attention. J. Appl. Remote Sens. 2021, 15, 016513. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Lu, Y.; Li, W.; Wang, Z.; Huang, Z. RBPNET: An asymptotic Residual Back-Projection Network for super-resolution of very low-resolution face image. Neurocomputing 2020, 376, 119–127. [Google Scholar] [CrossRef]
- Chen, C.; Gong, D.; Wang, H.; Li, Z.; Wong, K.Y.K. Learning Spatial Attention for Face Super-Resolution. IEEE Trans. Image Process. 2021, 30, 1219–1231. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Y.; Wang, L.; Wang, L.; Alfarraj, O.; Tolba, A. Lightweight Feedback Convolution Neural Network for Remote Sensing Images Super-Resolution. IEEE Access 2021, 9, 15992–16003. [Google Scholar] [CrossRef]
- Xu, Y.; Luo, W.; Hu, A.; Xie, Z.; Xie, X.; Tao, L. TE-SAGAN: An Improved Generative Adversarial Network for Remote Sensing Super-Resolution Images. Remote Sens. 2022, 14, 2425. [Google Scholar] [CrossRef]
- Li, X.; Zhang, D.; Liang, Z.; Ouyang, D.; Shao, J. Fused Recurrent Network Via Channel Attention For Remote Sensing Satellite Image Super-Resolution. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Klajnšek, G.; Žalik, B. Progressive lossless compression of volumetric data using small memory load. Comput. Med. Imaging Graph. 2005, 29, 305–312. [Google Scholar] [CrossRef]
- Senapati, R.K.; Prasad, P.M.K.; Swain, G.; Shankar, T.N. Volumetric medical image compression using 3D listless embedded block partitioning. SpringerPlus 2016, 5, 2100. [Google Scholar] [CrossRef] [Green Version]
- Guthe, S.; Goesele, M. GPU-based lossless volume data compression. In Proceedings of the 2016 3DTV-Conference: The True Vision—Capture, Transmission and Display of 3D Video (3DTV-CON), Hamburg, Germany, 4–6 July 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Nguyen, K.G.; Saupe, D. Rapid High Quality Compression of Volume Data for Visualization. Comput. Graph. Forum 2001, 20, 49–57. [Google Scholar] [CrossRef]
- Dai, Q.; Song, Y.; Xin, Y. Random-Accessible Volume Data Compression with Regression Function. In Proceedings of the 2015 14th International Conference on Computer-Aided Design and Computer Graphics (CAD/Graphics), Xi’an, China, 26–28 August 2015; pp. 137–142. [Google Scholar] [CrossRef]
- Shen, H.; David Pan, W.; Dong, Y.; Alim, M. Lossless compression of curated erythrocyte images using deep autoencoders for malaria infection diagnosis. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Mishra, D.; Singh, S.K.; Singh, R.K. Lossy Medical Image Compression using Residual Learning-based Dual Autoencoder Model. arXiv 2021, arXiv:2108.10579. [Google Scholar] [CrossRef]
- Moraes, T.; Amorim, P.; Silva, J.V.D.; Pedrini, H. Medical image interpolation based on 3D Lanczos filtering. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020, 8, 294–300. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Linear-1 | [−1, 1, 128] | 512 |
| Linear-2 | [−1, 1, 128] | 16,512 |
| Linear-3 | [−1, 1, 1] | 129 |
| Total params: 17,153 | ||
| Trainable params: 17,153 | ||
| Non-trainable params: 0 | ||
| Input size (MB): 0.00 | ||
| Forward/backward pass size (MB): 0.00 | ||
| Params size (MB): 0.07 | ||
| Estimated total size (MB): 0.07 |
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Linear-1 | [−1, 1, 128] | 512 |
| Linear-2 | [−1, 1, 128] | 16,512 |
| Linear-3 | [−1, 1, 128] | 16,512 |
| Linear-4 | [−1, 1, 1] | 129 |
| Total params: 33,665 | ||
| Trainable params: 33,665 | ||
| Non-trainable params: 0 | ||
| Input size (MB): 0.00 | ||
| Forward/backward pass size (MB): 0.00 | ||
| Params size (MB): 0.13 | ||
| Estimated total size (MB): 0.13 |
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Linear-1 | [−1, 1, 128] | 512 |
| Linear-2 | [−1, 1, 128] | 16,512 |
| Linear-3 | [−1, 1, 128] | 16,512 |
| Linear-4 | [−1, 1, 128] | 16,512 |
| Linear-5 | [−1, 1, 1] | 129 |
| Total params: 50,177 | ||
| Trainable params: 50,177 | ||
| Non-trainable params: 0 | ||
| Input size (MB): 0.00 | ||
| Forward/backward pass size (MB): 0.00 | ||
| Params size (MB): 0.19 | ||
| Estimated total size (MB): 0.20 |
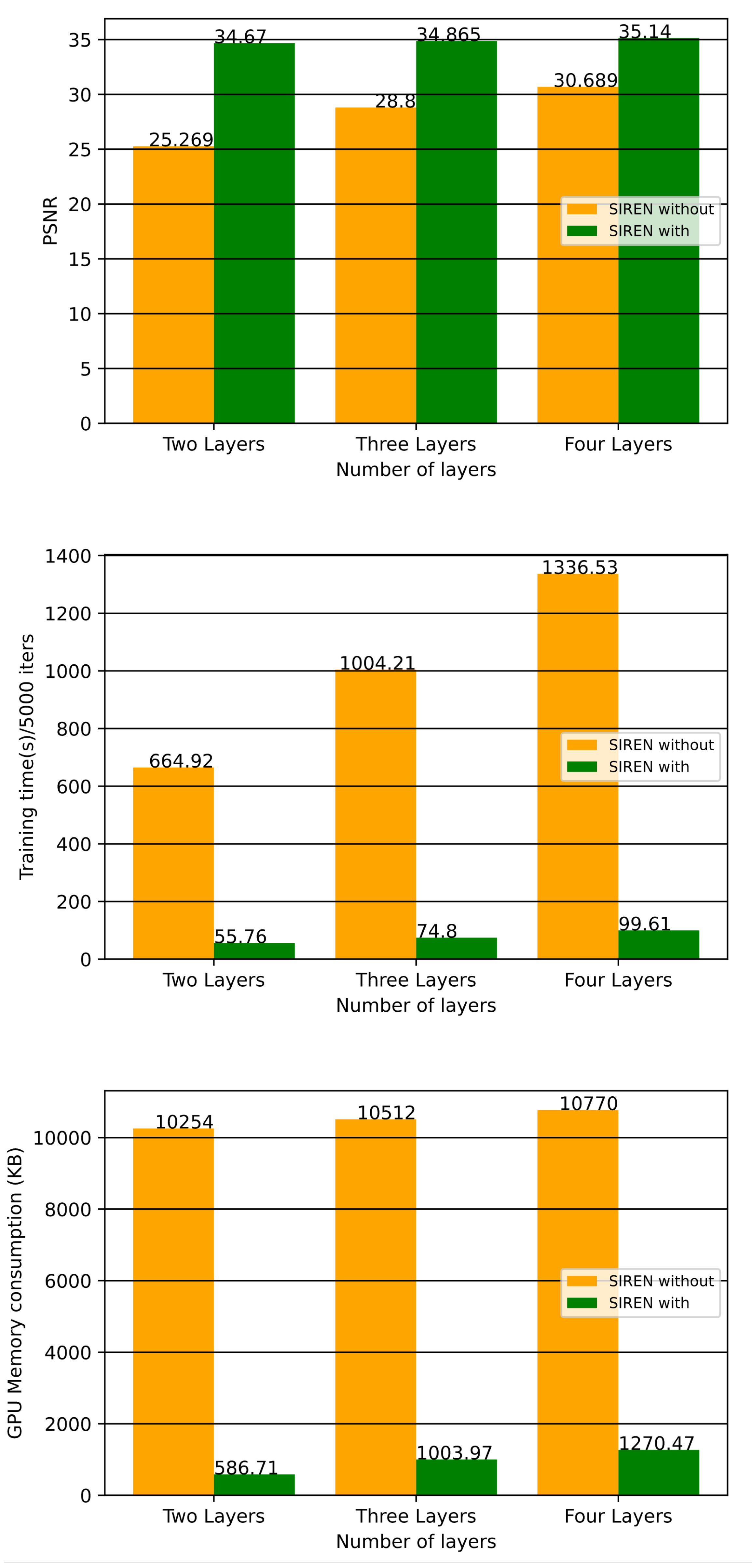
| Number of Layers | Best PSNR | Training Time(s)/50,000 Iters | Compression Rate | GPU Memory (KB) |
|---|---|---|---|---|
| Two Layer | 34.670 | 55.76 | 3.65 | 1038 |
| Three Layer | 34.865 | 74.80 | 1.96 | 1296 |
| Four Layer | 35.140 | 99.61 | 1.28 | 1554 |
| Number of Layers | Best PSNR | Training Time(s)/50,000 Iters | Compression Rate | GPU Memory (KB) |
|---|---|---|---|---|
| Two Layer | 25.269 | 664.92 | 3.65 | 10,254 |
| Three Layer | 28.800 | 1004.21 | 1.96 | 10,512 |
| Four Layer | 30.689 | 1336.53 | 1.28 | 10,770 |
| Number of Layers | SIREN without Our Architecture [2] | SIREN with Our Architecture | |
|---|---|---|---|
| Best PSNR (dB) | 2 layers | 25.269 | 34.670 |
| 3 layers | 28.800 | 34.865 | |
| 4 layers | 30.689 | 35.140 | |
| Training time(s) (for 15000 iters) | 2 layers | 664.92 | 55.76 |
| 3 layers | 1004.21 | 74.80 | |
| 4 layers | 1336.53 | 99.61 | |
| GPU memory consumption (KB) | 2 layers | 10,254 | 1038 |
| 3 layers | 10,512 | 1296 | |
| 4 layers | 10,770 | 1554 |
| Methods | Best PSNR |
|---|---|
| Shen’s [52] | 27.50 |
| Mishra’s [53] | 29.33 |
| SIREN [2] (2 layers) | 25.269 |
| SIREN [2] (3 layers) | 28.800 |
| SIREN [2] (4 layers) | 30.689 |
| Ours (2 layers) | 34.670 |
| Ours (3 layers) | 34.865 |
| Ours (4 layers) | 35.140 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheibanifard, A.; Yu, H. A Novel Implicit Neural Representation for Volume Data. Appl. Sci. 2023, 13, 3242. https://doi.org/10.3390/app13053242
Sheibanifard A, Yu H. A Novel Implicit Neural Representation for Volume Data. Applied Sciences. 2023; 13(5):3242. https://doi.org/10.3390/app13053242
Chicago/Turabian StyleSheibanifard, Armin, and Hongchuan Yu. 2023. "A Novel Implicit Neural Representation for Volume Data" Applied Sciences 13, no. 5: 3242. https://doi.org/10.3390/app13053242
APA StyleSheibanifard, A., & Yu, H. (2023). A Novel Implicit Neural Representation for Volume Data. Applied Sciences, 13(5), 3242. https://doi.org/10.3390/app13053242