Abstract
Extracting good action representations from video frames is an intricate challenge due to the presence of moving objects of various sizes across current action recognition datasets. Most of the current action recognition methodologies have paid scant attention to this characteristic and have relied on deep learning models to automatically solve it. In this paper, we introduce a multi-scale receptive fields convolutional network (MSRFNet), which is fashioned after the pseudo-3D residual network architecture to mitigate the impact of scale variation in moving objects. The crux of MSRFNet is the integration of a multi-scale receptive fields block, which incorporates multiple dilated convolution layers that share identical convolutional parameters, but feature different receptive fields. MSRFNet leverages three scales of receptive fields to extract features from moving objects of diverse sizes, striving to produce scale-specific feature maps with a uniform representational power. Through visualization of the attention of MSRFNet, we analyze how the model re-allocates its attention to moving objects after implementing the multi-scale receptive fields approach. Experimental results on the benchmark dataset demonstrate that MSRFNet achieves improvement of 3.2% on UCF101, improvement of 5.8% on HMDB51, and improvement of 7.7% on Kinetics-400 compared with the baseline. Compared with state-of-the-art techniques, MSRFNet gets comparable or superior results, thereby affirming the effectiveness of the proposed approach.
1. Introduction
The recognition of human actions is a crucial task in video understanding, with practical applications such as abnormal behavior analysis, video retrieval, and human–robot interaction. Video action recognition, which involves identifying human behaviors, is a fundamental aspect of this task. In the past decade, there has been a surge of interest in video action recognition, initially driven by hand-crafted features [1,2,3,4], but increasingly by deep learning models [5,6,7,8,9,10], due to the availability of large-scale action recognition datasets, such as HMDB51 [11], UCF101 [12], and Kinetics [13].
Convolutional neural networks (ConvNets), which have shown remarkable performance in static image classification, have also been applied to video tasks. However, video differs from still images in that it contains continuous and variable spatiotemporal information, making action recognition more challenging. Existing deep learning approaches can be broadly categorized into three types: two-stream networks [5,6,14], 3D convolutional kernels, and computationally efficient methods. Two-stream networks utilize a separate ConvNet to learn the temporal information from optical flow, but this method is computationally expensive. 3D convolutional kernels, such as C3D [7], I3D [8], and R3D [15], model temporal information, but significantly increase the number of parameters, making them difficult to optimize. Computationally efficient methods reduce the number of parameters by exploring the idea of 3D factorization. For example, P3D [16] explores the idea of 3D factorization. More specifically, a 3D kernel (e.g., ) can be factorized to two separate operations, a 2D spatial convolution (e.g., ) and a 1D temporal convolution (e.g., ). This operation simplifies 3D ConvNets and reduces the number of parameters. Other examples include R(2+1)D [17], TSM [18], S3D [19], etc.
Motivated by methods that improve computational efficiency, we propose a network, called multi-scale receptive fields ConvNet (MSRFNet), consisting of pseudo-3D operations. The key to our method is a multi-scale receptive fields block, which uses a variety of receptive fields to extract features from input video frames. This block is designed to handle variously sized moving objects, which vary in size across different video samples. The input frames are processed with receptive fields of different sizes to account for this variation. MSRFNet improves upon the performance of existing methods due to the introduction of the multi-scale receptive fields block.
The contributions in this work can be summarized as follows:
- The multi-scale receptive fields block is utilized to handle variously sized moving objects, which can extract better action representations.
- The different branches in MSRFBlock shares common parameters to learn action features collaboratively. Meanwhile, it does not result in an increase in the number of parameters of MSRFNet.
- MSRFNet provides comparable or even better results than other leading methods on three benchmarks, UCF101 [12], HMDB51 [11], and Kinetics-400 [13].
2. Related Work
Video action recognition is one of the representative tasks for video understanding, which has drawn significant attention from researchers over the last decade. The existing methods of action recognition can be summarized into two kinds of methods: the methods based on hand-crafted features and the methods based on deep learning models.
Although deep learning methods have become the standard for action recognition, hand-crafted features dominated the video understanding literature before 2015 due to their high accuracy and good robustness. Hand-crafted features can be divided into global features and local features. Global features provide a holistic description of the motion target. For example, Bobick et al. [20] first used contour information as global features to describe human action, and proposed two temporal template features, motion energy image (MEI) and motion history image (MHI). The former indicates the part of the action that occurs, while the latter reflects the sequence of the action. Unlike global features, local features describe only part of the regional information of the motion target and are more widely used. Laptev et al. [21] extended the two-dimensional Harris corner point detector to three-dimensional space, thus detecting the most drastically changing space-time interest points (STIP) in the spatio-temporal dimension, which promotes the development of local features. Later, various feature descriptors were successively proposed to describe the action features in the vicinity of STIP, such as histogram of oriented gradients (HoG) [1], histogram of oriented optical flow (HoF) [2], and motion boundary histograms (MBH) [22]. The state-of-the-art hand-crafted feature is based on dense trajectory [3,4], particularly improved dense trajectories (IDT) [4], which obtains the action trajectory by calculating dense optical flow and then extracting local features along the trajectory. However, hand-crafted features have a heavy computational cost and are hard to scale and deploy.
In recent years, deep learning has made significant breakthroughs in image classification [23], semantic segmentation [24], object detection [25], and other fields. Action recognition methods based on deep learning have gradually become the focus of research. Unlike hand-crafted features, deep learning models can automatically learn feature representations from video data, and the learned features are more general. The common deep learning method currently used in the field of vision is ConvNet. The seminal work was proposed by Karpathy et al. [26], which uses a single 2D ConvNet on each video frame independently and investigates late fusion, early fusion, and slow fusion to find the best temporal connectivity patterns. However, its performance on UCF101 is 20% lower than IDT. To learn better spatio-temporal features, Simonyan et al. [5] proposed two-stream networks for action recognition. This method includes two independent 2D ConvNets. One takes RGB frames as input to capture appearance information, called the spatial stream, while the other takes a stack of optical flow images as input to capture motion information between video frames, called the temporal stream. The prediction scores from the two streams are then averaged to obtain the final prediction. By feeding the extra optical flow information to ConvNets, ConvNet-based approaches achieved similar performance to the previous best hand-crafted feature IDT. However, optical flow cannot capture long-range temporal information due to its characteristics. To tackle this problem, Wang et al. [14] proposed the temporal segment network (TSN). TSN divides a whole video into several segments, and all the segments share the same two-stream networks. Then, a segmental consensus, such as average pooling and max pooling, is performed to aggregate information from the sampled segments. Thanks to this sparse sampling strategy, TSN is able to see the content from the entire video, thus modeling long-range temporal information. There are also some works that combine ConvNets with recurrent neural networks (RNN) [27] for action recognition, such as LRCN [28], scLSTM [29], and CapsGaNet [30]. Although RNNs have a strong ability to process data with temporal relationships, their training processes are unstable, which makes them hard to train. Besides, it is still challenging for 2D ConvNets to learn temporal information directly from raw video frames.
Optical flow is an effective motion representation for describing object movement and provides orthogonal information compared with RGB images. This allows 2D ConvNets to learn temporal information. However, calculating optical flow is computationally intensive and requires significant storage. A natural way to understand a video is by using 3D convolution kernels to handle video data, which leads to the usage of 3D ConvNets. The seminal work for using 3D ConvNets for action recognition is [31]. However, the network in [31] is not deep enough to show the potential of 3D ConvNets. Therefore, Tran et al. [7] proposed to use a deeper 3D ConvNet, named C3D, for training and testing. Although the performance of C3D on standard benchmarks is not as good as expected, it shows strong generalization capability and is available as a generic feature extractor for other video tasks. However, using 3D kernels leads to an increase in the number of parameters, making 3D ConvNets hard to optimize and require large-scale action recognition datasets. This situation was alleviated when Carreira et al. [8] proposed inflated 3D ConvNets (I3D). The main contribution of I3D is inflating the ImageNet pre-trained 2D model weights to their counterparts in the 3D model. Thus, 3D ConvNets can avoid being trained from scratch. Moreover, I3D achieves high recognition accuracy on UCF101 and HMDB51 after pre-training on a new large-scale dataset, Kinetics-400. Wu et al. [32] proposed a method for human activity recognition using depth videos with both spatial and temporal characteristics. They constructed a hierarchical difference image and fed it to a pre-trained CNN, which then classified human activities by combining the videos. Although this method achieved better accuracy than skeleton-based models, it should be noted that the limited availability of datasets may have contributed to this result.There are also works aiming to reduce the training complexity of 3D ConvNets. For example, P3D [16] and R(2+1)D [17] explore the idea of 3D factorization into two separate operations, a 2D spatial convolution and a 1D temporal convolution. This split operation allows spatial and temporal features to be optimized separately, thus reducing the optimization difficulty of the model. The difference between P3D and R(2+1)D is how they arrange the two factorized operations and how they formulate each residual block. Zhou et al. [33] propose another way of simplifying 3D ConvNets. They integrate 2D and 3D ConvNets in a single network, termed MiCTNet. MiCTNet is proposed on the hypothesis of the uneven distribution of spatiotemporal information in video, aiming to generate deeper and more informative feature maps. S3D [19] combines the merits of the approaches mentioned above, proving that it is feasible to replace 3D convolution with low-cost 2D convolution. Table 1 shows the number of parameters of ResNet-50 in 2D, 3D, and P3D structures. To avoid a large number of parameters, our network employs the structure of P3D networks.

Table 1.
The comparison of the number of parameters of 2D, 3D and P3D ResNet-50.
In this paper, we aim to handle the situation that the size of moving objects in different video samples is not consistent. Some of them look very small in a video frame while some occupy the whole frame. We propose a method of multi-scale receptive fields to process large or small moving objects. The structure of P3D is adopted, with dilated convolution being deployed in some related layers to change the receptive field.
3. Method
The key of our method is adopting the multi-scale receptive fields block. We first show the motivation for our method and then introduce the entire network architecture of MSRFNet.
3.1. Motivation
Sun et al. [34] argue that the success of deep learning can be attributed to three key factors: high capacity models, the rapid growth of computing power, and the availability of large-scale datasets. While the significance of models and computing power is undeniable, the importance of datasets cannot be overstated, as they set the performance ceiling for deep learning models. Consequently, a thorough analysis of datasets can aid in designing better models. UCF101 [12] is a widely used dataset in the field of action recognition, consisting of 13,320 video clips spanning 101 action categories, and sourced from YouTube. Upon analyzing the dataset, it is observed that the proportion of moving objects in video frames varies across different samples. In some cases, the moving objects only occupy a small portion of the frame, while in others, they almost fill the entire frame. Figure 1 displays some video samples from UCF101, which highlights that the moving object in the “Nunchucks” activity occupies a small proportion of the frame, whereas the moving object in the “Shaving Beard” action takes up the entire frame. The proportion of moving objects in other actions also varies. ConvNets typically employ one type of convolution kernel to extract spatial features, resulting in a fixed receptive field. We surmise that using a fixed receptive field to capture moving objects of different sizes can affect the accuracy of action recognition.

Figure 1.
Some video samples from UCF101.
Moreover, it should be noted that the problem of varying object sizes in videos is not unique to the UCF101, HMDB51, or Kinetics-400 datasets. It is a common issue in action recognition datasets. As illustrated in Figure 2, different actions have varying degrees of object-size variation in their video frames. For instance, in the “Parkour Jump” and “Ice Skating” activities, small moving objects are present. Conversely, larger moving objects are observed in activities such as “Chewing Gum” and “Laughing”. Collecting action datasets with consistent object proportions in all video samples is a challenging task. In fact, even for the same action, the proportion of moving objects in different video samples may vary. This increases the intra-class variation and, therefore, the complexity of the action recognition task.

Figure 2.
Some video samples from HMDB51 and Kinetics-400.
3.2. Multi-Scale Receptive Fields
To address the challenge of handling moving objects of different sizes, we draw inspiration from the behavior of human observers. When observing a static object, humans tend to move closer or farther away from it in order to focus on specific parts or obtain a broader view. This behavior is linked to changes in the field of vision, which can be thought of as analogous to the concept of receptive fields in convolutional neural networks. Specifically, receptive fields refer to the size of the convolution kernels used in the network, and can be adjusted to handle objects of different sizes. By using large receptive fields, ConvNets can effectively capture information from large moving objects, while smaller receptive fields can be used to capture details from smaller objects. This approach allows for more effective handling of intra-class variability and improved performance on action recognition tasks.
A large convolution kernel often has a large receptive field. However, a large kernel is not recommended for use because it is hard to optimize during training process. Besides, a large kernel also leads to the increase of parameters. In order to address this, Simonyan et al. [35] proposed the use of very small receptive fields throughout the whole network, and showed that stacking multiple convolution layers can achieve the same effect as using larger kernels. They found that a stack of two convolution layers has an effective receptive field of , and three such layers have a effective receptive field, as shown in Figure 3. Additionally, a stack of three convolution layers incorporates three non-linear rectification layers instead of a single one, making the decision function more discriminative. This approach also reduces the number of parameters compared with using larger kernels, and avoids the loss of texture details in the original feature map that can occur with the use of too many convolution layers.
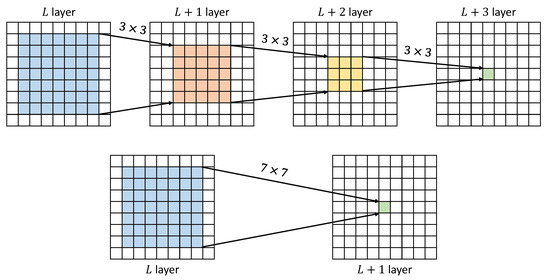
Figure 3.
A stack of three convolution layers has an effective receptive field of .
Dilated convolution offers a solution to enlarging the receptive field without increasing the size of convolution kernels. This technique introduces a parameter known as the “dilation rate”, which specifies the spacing distance between each convolution point. As the dilation rate increases, the receptive field grows larger, as demonstrated in Figure 4.
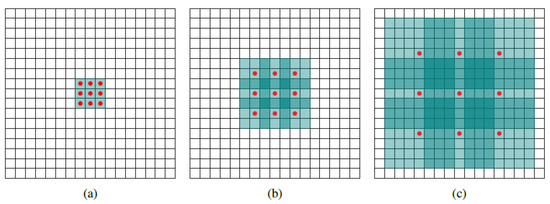
Figure 4.
Systematic dilation supports exponential expansion of the receptive field without loss of resolution or coverage [36]. (a) A 1-dilated convolution; each output element has a receptive field of . (b) Dilated convolution with dilation rate being 2; each output element has a receptive field of . (c) Dilated convolution with dilation rate being 4; each output element has a receptive field of . The number of parameters of each above dialted convolution is identical.
By adopting dilated convolution, this paper proposes a multi-scale receptive fields block. The block is modified on the basis of pseudo-3D residual block, as shown in Figure 5. The pseudo-3D residual block contains one convolution layer, one convolution layer, and one convolution layer. The function of convolution is to extract temporal features and reduce the number of channels of feature maps, which lowers the computational complexity. The convolution is used for extracting spatial features, and the last convolution is applied to increase the number of channels to enrich the feature information.
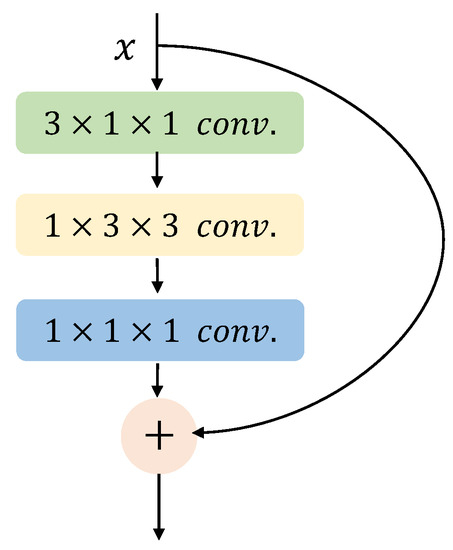
Figure 5.
Pseudo-3D residual block.
The proposed multi-scale receptive fields block is designed to tackle the challenge of varying receptive field sizes. Instead of using a convolution layer, the block employs three parallel dilated convolution layers. These dilated convolutions share the same convolution kernel, but with different dilation rates, which enables the block to capture information from diverse receptive fields. As depicted in Figure 6, larger dilation rates are applied to handle larger moving objects, while smaller dilation rates are better suited for smaller moving objects. The features extracted from these dilated convolutions are not processed separately but are fused to provide a more comprehensive observation of the moving object. By integrating the features from multiple receptive fields, the block can extract richer action information with different scales.
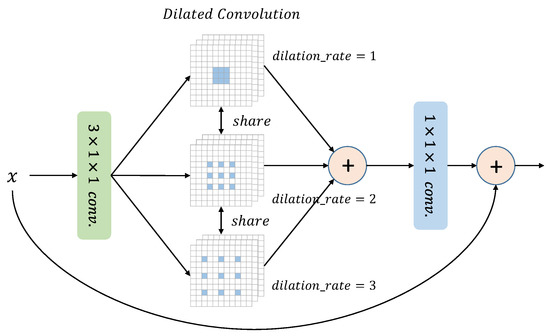
Figure 6.
The structure of multi-scale receptive fields block.
The addition of two extra convolutions will inevitable increase the number of parameters. To address this issue, we adopt parameter sharing of convolution kernels across different branches, which keeps the number of parameters almost consistent with the pseudo-3D residual block, as shown in Table 1. This approach enables the influences from three branches to act on the same parameter, promoting collaborative learning. Additionally, it helps to alleviate the problem of convolutional discontinuity that is caused by dilated convolution. The multi-scale receptive fields block is a versatile technique that can replace the residual block and is widely applicable in various scenarios.
3.3. Network Architecture
Our proposed MSRFNet model was motivated by [37]. Specifically, we utilize the P3D ResNet-50 architecture as the backbone of our model. The detailed structure of the P3D ResNet-50 is provided in Table 2. Notably, the first convolution layer in res2 and res3 stages is . However, in the res4 and res5 stages, the first convolution layer is replaced by a convolutional layer. This design decision was made to avoid degradation of spatial representation caused by the temporal convolution in the early stages.
Table 2.
Architectures for P3D ResNet-50.
The overall structure of MSRFNet is presented in Figure 7. To avoid compromising the performance of spatial representation in the early stages of the network, the temporal convolution is removed when using the multi-scale receptive fields block to replace residual blocks in res2 and res3 stages. MSRFNet can be trained end-to-end.
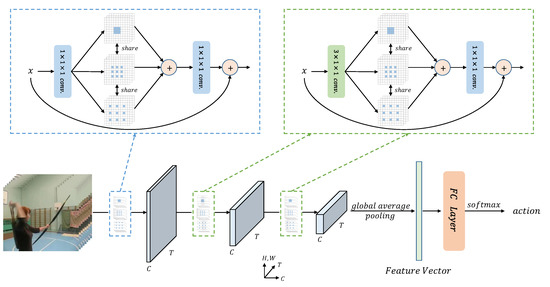
Figure 7.
The overall structure of MSRFNet.
Table 3 illustrates the architecture of MSRFNet, including the change in feature maps. As suggested by [38], recognition performance improves with more input video frames, but the improvement is not significant beyond 5 frames. Therefore, we use 4 video frames as input, considering device limitations. The network accepts a video frame input of , where 3 represents RGB channels, 4 is the number of frames, and is the spatial resolution that is halved after each stage. The network outputs a feature map of after the last stage. A feature vector of 2048 dimensions is obtained by global average pooling, which is then used for action recognition.
Table 3.
Architectures for MSRFNet. ("dr" means dilation rate).
4. Experiments
4.1. Experimental Settings and Datasets
4.1.1. Datasets
We evaluate MSRFNet on three action recognition datasets, HMDB51 [11], UCF101 [12], and Kinetics-400 [13]. HMDB51 was introduced in 2011, and is collected mainly from movies. It consists of 6776 video clips divided into 51 action classes, each containing a minimum of 101 video clips. HMDB51 has three official splits for public use. One year later, UCF101 is introduced, which contains 13,320 video clips from YouTube, with 101 action categories. UCF101 also has three official splits, similar to HMDB51. Most previous papers either report the top-1 recognition accuracy on split 1, or the average accuracy over three splits. Kinetics-400 is now the most widely adopted large-scale dataset. It contains a total of 300,000 video clips of 400 action classes, with at least 400 videos for each class. For this large dataset, we use its training set (240,000 clips) for training, and the validation set (20,000 clips) for testing.
4.1.2. Training & Testing
At the training stage, we follow [39] to divide each video into four segments, each picking up only one video frame randomly. The training and testing is performed for this paper on two cards of Nvidia GTX 1080Ti with 11G memory. Data augmentation is then applied to these selected frames. First, every frame is rescaled to make the smaller side no more than 256. Second, a patch is randomly cropped from each rescaled frame. Last, these cropped frames are randomly horizontally flipped and RGB jittered after the cropping step. MSRFNet is trained with the method of mini-batch stochastic gradient descent with momentum. The momentum is set to 0.9 and the weight decay is set to 0.0001. The batch size is 24. We do not use a larger batch size due to the limitation of GPU devices. The learning rate is initialized as 0.01, which is reduced at two training checkpoints. For HMDB51 and UCF101, the whole training process contains 40 epochs. At epoch 20 and 30, the leaning rate decays by 0.1. For Kinetics-400, the whole training process becomes 100 epochs. The learning rate also decays by 0.1 at epoch 50 and 75. We also fine tune pre-trained weights from Kinetics-400 on HMDB51 and UCF101. The training epochs are scaled by half (20 epochs) in the transfer learning process. To avoid over-fitting, batch normalization layers are also frozen.The other training parameters are kept the same as before. In the testing process, a video is also partitioned equally into four segments, with each segment contributing one frame. We apply the same data augmentation (except RGB jittering) as described in the training process. We use the full resolution image with shorter side 256 for evaluation, in order to give a direct comparison. The only difference is that from each rescaled frame we do not crop only one patch. Instead, we follow [5] to extract ten patches by cropping and flipping four corners and the center of each frame. The final prediction score is obtained by averaging softmax scores from ten patches.
4.2. Comparison to the Baseline
As illustrated in Section 3.3, we choose P3D ResNet-50 as our baseline. The only difference between MSRFNet and P3D ResNet-50 is the structure of basic blocks. All the residual blocks in P3D ResNet-50 are replaced by the multi-scale receptive fields block. The experiments will be conducted on three splits of UCF101 and HMDB51. Table 4 shows the comparison results on three splits. MSRFNet obtains higher recognition accuracy on both UCF101 and HMDB51, which demonstrates the effectiveness of the method of multi-scale receptive fields. On UCF101, MSRFNet outperforms the baseline by 3.2% on average accuracy. MSRFNet also gains 5.2% accuracy improvement on HMDB51. It shows that the method can effectively help the model to better capture the motion information.
Table 4.
Accuracy on three splits of UCF101 and HMDB51. P3D ResNet-50 is the baseline.
4.3. The Selection of Multiple Scales
MSRFNet uses three different dilated convolutions, with the dilation rate being {1,2,3}. In this section, we provide an extensive experiment to evaluate MSRFNet with different numbers of scales. Table 5 shows the detailed settings. The number of scales is set to 1 to 6.The set {1,2,3,4,5,6} means six dilated convolution layers are adopted, with dilation rate being {1,2,3,4,5,6}. Other scale settings have the same meanings. The experiment is performed on the first split of UCF101 and HMDB51. Top-1 and top-5 performance are both reported in Table 5.
Table 5.
Comparisons in terms of the number of scales on the first split of UCF101 and HMDB51.
It can be seen from the results on UCF101 that the top-1 and top-5 accuracy increases when the number of scales is added, which indicates that our method can help the model learn better representations. However, when the number of scales exceeds 3, the accuracy begins to decline. When the number of scales reaches 5, the top-1 accuracy of the model decreases to 56.9%, which is similar to the effect of the single scale. The main reason for the decrease of accuracy is that the enlargement of the receptive field will also amplify the influence of noise information, thus affecting the learning process of action representations. When the number of scales reaches 8, the negative effect of the large receptive field is further increased, and the top-1 accuracy drops to 56.8%. Figure 8 shows how accuracy on UCF101 varies with the number of scales. When the number of scales is no more than 3, the top-1 accuracy and top-5 accuracy have increased, and the improvement is obvious. When the number of scales exceeds 3, the accuracy of the model decreases and never exceeds the situation when the number of scales is 3. This reflects that the positive effect reaches its maximum when the scale number is 3.
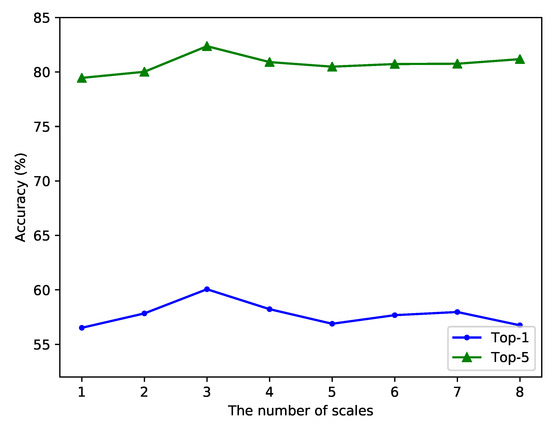
Figure 8.
Accuracy varies with the number of scales on UCF101.
We also show the accuracy variation on HMDB51 in Figure 9. The top-5 accuracy is similar to that of UCF101, but the top-1 accuracy shows different results. When the scale number is 5 or 6, the top-1 accuracy is slightly higher than when the scale number is 3. Although the top-1 accuracy further increases with the increase in the number of scales on HMDB51, the top-5 accuracy still decreases compared with when the number of scales is 3. In addition, when the number of scales further increases, the top-1 accuracy also decreases, which infers that excessive enlargement of the receptive field will indeed amplify the influence of noise information. It can also be seen from Table 5 that with the increase in the number of scales, the training time of a single epoch is correspondingly prolonged. Therefore, considering the experimental results on UCF101 and HMDB51, we finally adopt 3 dilated scales, which means the dilation rate is set as {1,2,3}.
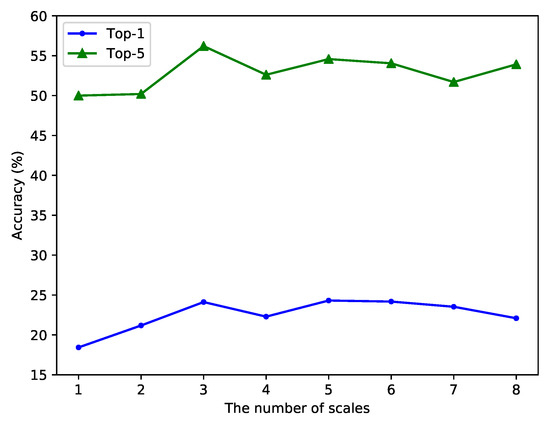
Figure 9.
Accuracy varies with the number of scales on HMDB51.
4.4. Comparison with State-of-the-Art Methods
We then compare our method with other leading methods on Kinetics-400. Table 6 presents the corresponding results. P3D ResNet-50 is the baseline. MSRFNet reaches a 73.2% top-1 accuracy and a 88.6% top-5 accuracy, which is 7.7% and 2.3% higher than the baseline, respectively. We first note that MSRFNet has better performance than two-stream, which is based on 2D ConvNets. Secondly, MSRFNet outperforms 3D ConvNets and 3D ResNet-50 with fewer parameters. Thirdly, compared with some good-design models, such as I3D, R(2+1)D, and Slow-Only, MSRFNet is also a little better, which shows that the method of multi-scale receptive fields can improve the effect of the model. However, the top-5 accuracy is still slightly lower than those three models, which shows that the generalization ability of MSRFNet needs to be further strengthened.
Table 6.
Comparison with state-of-the-art on Kinetics-400.
After training on Kinetics-400, MSRFNet is transferred to UCF101 and HMDB51 for training and testing using the transfer learning technology. The fully connected layer needs to be replaced with a new layer to match the number of action classes of new datasets. The new fully connected layer is initialized with random values and the parameters are updated during the transfer learning process. The experiments are conducted on three splits of UCF101 and HMDB51.
Table 7 shows the transfer learning results on three splits of UCF101 and HMDB51. The results of MSRFNet on three splits are close to each other, which indicates that the model has stable performance on these two datasets. MSRFNet achieves the highest top-1 accuracy of 91.5% on split-2 of UCF101. The average top-1 accuracy is 91.0% and the average top-5 accuracy is 98.0%. On HMDB51, MSRFNet achieves the highest top-1 accuracy of 60.3% on split-1. Its average top-1 and top-5 accuracy are 59.9% and 87.2%, respectively.
Table 7.
Performance on three splits of UCF101 and HMDB51 after pretraining on Kinetics-400.
Table 8 lists the comparison results with other methods after transfer learning on UCF101 and HMDB51. We take the average accuracy of three splits as the comparison result. MSRFNet achieves a recognition accuracy of 91.0% on UCF101, which is 3.2% higher than P3D ResNet-50 (the baseline). Besides, the performance of MSRFNet exceeds most of the methods in the table. The recognition accuracy of MSRFNet is only lower than I3D. The main reason is that I3D has higher model capacity, so it will have good performance after pretraining on large-scale datasets. On HMDB51, the performance advantage is not as significant as that of UCF101. However, MSRFNet still outperforms the baseline by 5.8% on HMDB51. From the experimental results of UCF101 and HMDB51, the performance of MSRFNet is better than most action recognition methods, and the accuracy is significantly improved compared with the baseline, which substantially proves the effectiveness of the method of multi-scale receptive fields.
Table 8.
Comparison with state-of-the-art on UCF101 and HMDB51 datasets after pretraining on Kinetics-400, averaged over three splits.
4.5. Visualization
Compared with the baseline, MSRFNet has shown a significant improvement in recognition accuracy. In this section, we analyze specific action classes of UCF101. Table 9 lists the action classes that improved the most after applying the method of multi-scale receptive fields. We then selected six action classes (“Pommel Horse”, “Nunchucks”, “Long Jump”, “Cricket Shot”, “Walking with Dog”, and “Shaving Beard”) from the table and drew the corresponding activation maps to visualize the model’s focus, as shown in Figure 10. It can be observed from the figure that the method of multi-scale receptive fields not only helps to handle small moving objects, but also improves the recognition of large moving objects. For instance, before our method was applied, the attention of the model for the “Walking with Dog” action was on the ground. However, after applying the method of multi-scale receptive fields, the model’s attention was focused on the moving object. A similar situation occurred in the “Long Jump” action where the multi-scale receptive fields method made the model’s attention close to the position of the moving object. In the “Shaving Beard” action, our method also made the model more focused on the hand region, resulting in better action representations. For other actions, such as “Nunchucks” and “Cricket Shot”, the model focused on the more important parts of the moving object under the influence of the multi-scale method. These results demonstrate that the model can handle moving objects of different sizes.
Table 9.
Top-16 action classes of UCF101 that get improved obviously in recognition accuracy.
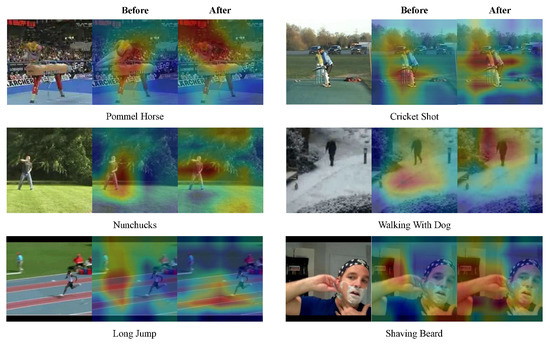
Figure 10.
Activation Maps of six selected action categories of UCF101.
5. Conclusions
In this paper, we propose a multi-scale receptive fields convolutional network (MSRFNet) to perform action recognition. The main idea of the method of multi-scale receptive fields is to handle moving objects of different sizes by corresponding receptive fields. MSRFNet further integrates the features extracted by different dilated convolutions with different receptive fields to obtain better action representations. Experimental results show that MSRFNet obtains superior results among leading methods on both UCF101, HMDB51 and Kinetics-400, which demonstrates the effectiveness of the method of multi-scale receptive fields. Visualization experiment shows that our method can help the model handle variously sized moving objects and pay more attention to them. The main limitations of this study is that we used the lightweight network P3D ResNet-50 to construct the proposed method under conditions of hardware limitations. Future work includes applying the method of weighted fusion to integrate the features extracted by different dilated convolutions to maximize the effect of the multi-scale receptive field, or combining it with a large-scale network, such as Transformer.
Author Contributions
Conceptualization, Z.D. and M.X.; Software, Z.D.; Formal analysis, Z.D.; writing—review and editing, Z.D. and M.X.; Supervision, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We appreciate the High Performance Computing Center of Shanghai University and Shanghai Engineering Research Center of Intelligent Computing System (No.19DZ2252600) for providing the computing resources.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 21–23 September 2005; Volume 1, pp. 886–893. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Cheng-Lin, L. Action recognition by dense trajectories. In Proceedings of the CVPR 2011-IEEE Conference on Computer Vision & Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Liu, S.; Wang, S.; Liu, X.; Gandomi, A.H.; Daneshmand, M.; Muhammad, K.; De Albuquerque, V.H.C. Human Memory Update Strategy: A Multi-Layer Template Update Mechanism for Remote Visual Monitoring. IEEE Trans. Multimed. 2021, 23, 2188–2198. [Google Scholar] [CrossRef]
- Liu, S.; Liu, D.; Muhammad, K.; Ding, W. Effective template update mechanism in visual tracking with background clutter. Neurocomputing 2021, 458, 615–625. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 20–36. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 7083–7093. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 428–441. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Wang, X.; Gao, L.; Song, J.; Shen, H. Beyond frame-level CNN: Saliency-aware 3-D CNN with LSTM for video action recognition. IEEE Signal Process. Lett. 2016, 24, 510–514. [Google Scholar] [CrossRef]
- Sun, X.; Xu, H.; Dong, Z.; Shi, L.; Liu, Q.; Li, J.; Li, T.; Fan, S.; Wang, Y. CapsGaNet: Deep Neural Network Based on Capsule and GRU for Human Activity Recognition. IEEE Syst. J. 2022, 16, 5845–5855. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Ma, X.; Li, Y. Spatiotemporal multimodal learning with 3D CNNs for video action recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1250–1261. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, X.; Zha, Z.J.; Zeng, W. Mict: Mixed 3d/2d convolutional tube for human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 449–458. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Shao, D.; Zhao, Y.; Dai, B.; Lin, D. Finegym: A hierarchical video dataset for fine-grained action understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2616–2625. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 6202–6211. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).