
Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping

Abstract
:1. Introduction
2. Related Work
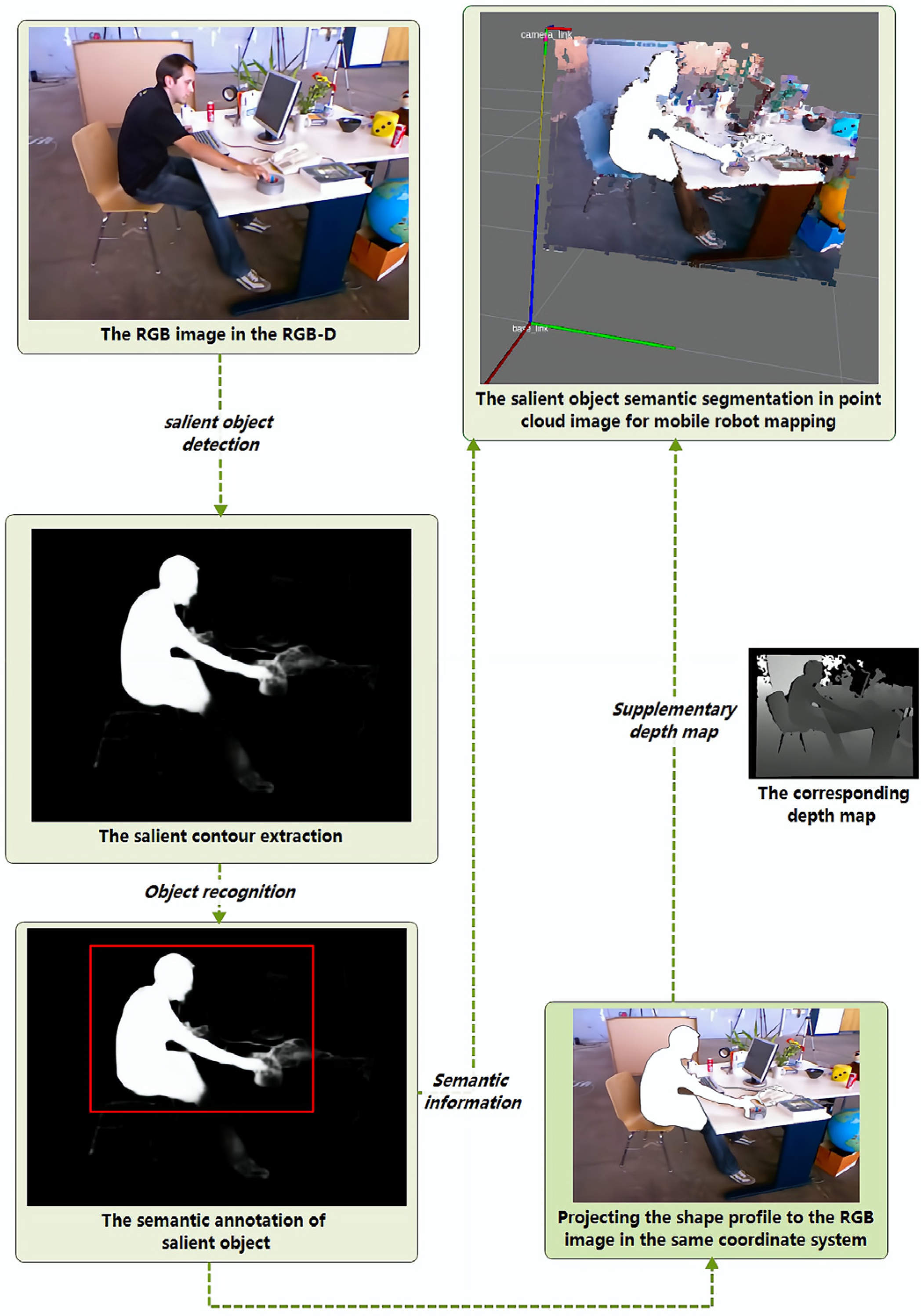
3. Salient Semantic Segmentation Methodology
3.1. Salient Object Extraction from RGB Images
3.2. Salient Object Recognition in RGB-D Image
3.3. Semantic Segmentation of Salient Objects in RGB-D Images
4. Experiments
4.1. Training and Evaluation in the Training Data
4.1.1. Training Data
4.1.2. Network Model Parameters
4.1.3. Model Evaluation
4.2. The Performance in the Testing Set Data
4.2.1. Testing Data
4.2.2. Salient Semantic Information in the Duts and Stanford Cars
4.2.3. Salient semantic information in the BDD100k
4.2.4. Salient Semantic Segmentation in RGB-D People Dataset
Semantic Annotation
Salient Semantic Segmentation
4.2.5. Speed and Performance Comparison
4.3. Converting RGB-D Image to Point Cloud
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lai, L.; Yu, X.; Qian, X.; Ou, L. 3D Semantic Map Construction System Based on Visual SLAM and CNNs. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020. [Google Scholar] [CrossRef]
- Balaska, V.; Bampis, L.; Kansizoglou, I.; Gasteratos, A. Enhancing satellite semantic maps with ground-level imagery. Robot. Auton. Syst. 2021, 139, 103760. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Li, J.; Liu, Y.; Wang, J. Building and optimization of 3D semantic map based on Lidar and camera fusion. Neurocomputing 2020, 409, 394–407. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; You, X. Combining ElasticFusion with PSPNet for RGB-D Based Indoor Semantic Mapping. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yin, R.; Cheng, Y.; Wu, H.; Song, Y.; Yu, B.; Niu, R. FusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1543–1553. [Google Scholar] [CrossRef]
- Jokić, A.; Petrović, M.; Miljković, Z. Semantic segmentation based stereo visual servoing of nonholonomic mobile robot in intelligent manufacturing environment. Expert Syst. Appl. 2022, 190, 116203. [Google Scholar] [CrossRef]
- Wang, S.; Wang, H.; She, S.; Zhang, Y.; Qiu, Q.; Xiao, Z. Swin-T-NFC CRFs: An encoder–decoder neural model for high-precision UAV positioning via point cloud super resolution and image semantic segmentation. Comput. Commun. 2023, 197, 52–60. [Google Scholar] [CrossRef]
- Zhang, B.; Kong, Y.; Leung, H.; Xing, S. Urban UAV Images Semantic Segmentation Based on Fully Convolutional Networks with Digital Surface Models. In Proceedings of the 2019 Tenth International Conference on Intelligent Control and Information Processing (ICICIP), Marrakesh, Morocco, 14–19 December 2019. [Google Scholar] [CrossRef]
- Hernandez, A.C.; Gomez, C.; Barber, R.; Mozos, O.M. Exploiting the confusions of semantic places to improve service robotic tasks in indoor environments. Robot. Auton. Syst. 2023, 159, 104290. [Google Scholar] [CrossRef]
- Wang, Z.; Tian, G. Hybrid offline and online task planning for service robot using object-level semantic map and probabilistic inference. Inf. Sci. 2022, 593, 78–98. [Google Scholar] [CrossRef]
- Miller, I.D.; Soussan, R.; Coltin, B.; Smith, T.; Kumar, V. Robust semantic mapping and localization on a free-flying robot in microgravity. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4121–4127. [Google Scholar]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Wei, L.; Zong, G. EGA-Net: Edge feature enhancement and global information attention network for RGB-D salient object detection. Inf. Sci. 2023, 626, 223–248. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.H.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 18–22 June 2019. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, H.; Yan, J.; Jiang, W.; Liu, Y. UDNet: Uncertainty-aware deep network for salient object detection. Pattern Recognit. 2023, 134, 109099. [Google Scholar] [CrossRef]
- Hu, L.; Zhang, Y.; Wang, Y.; Jiang, Q.; Ge, G.; Wang, W. A simple information fusion method provides the obstacle with saliency labeling as a landmark in robotic mapping. Alex. Eng. J. 2022, 61, 12061–12074. [Google Scholar] [CrossRef]
- Hu, L.; Zhang, Y.; Wang, Y.; Ge, G.; Wang, W. Salient Preprocessing: Robotic ICP Pose Estimation Based on SIFT Features. Machines 2023, 11, 157. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes Through the ADE20K Dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, Y.-J. 300-FPS Salient Object Detection via Minimum Directional Contrast. IEEE Trans. Image Process. 2017, 26, 4243–4254. [Google Scholar] [CrossRef]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M. Dynamic Feature Integration for Simultaneous Detection of Salient Object, Edge, and Skeleton. IEEE Trans. Image Process. 2020, 29, 8652–8667. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO v.3: Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lyu, H.; Fu, H.; Hu, X.; Liu, L. Esnet: Edge-Based Segmentation Network for Real-Time Semantic Segmentation in Traffic Scenes. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar] [CrossRef]
- Cruz, J.P.N.; Dimaala, M.L.; Francisco, L.G.L.; Franco, E.J.S.; Bandala, A.A.; Dadios, E.P. Object recognition and detection by shape and color pattern recognition utilizing Artificial Neural Networks. In Proceedings of the 2013 International Conference of Information and Communication Technology (ICoICT), Bandung, Indonesia, 20–22 March 2013. [Google Scholar] [CrossRef]
- Wu, J.; Xiao, Z. Video surveillance object recognition based on shape and color features. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010. [Google Scholar] [CrossRef]
- Murugesan, M.; Arieth, R.M.; Balraj, S.; Nirmala, R. Colon cancer stage detection in colonoscopy images using YOLOv3 MSF deep learning architecture. Biomed. Signal Process. Control 2023, 80, 104283. [Google Scholar] [CrossRef]
- Hu, J.; Gao, X.; Wu, H.; Gao, S. Detection of Workers without the Helments in Videos Based on YOLO V3. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 9–21 October 2019. [Google Scholar] [CrossRef]
- Soebhakti, H.; Prayoga, S.; Fatekha, R.A.; Fashla, M.B. The Real-Time Object Detection System on Mobile Soccer Robot using YOLO v3. In Proceedings of the 2019 2nd International Conference on Applied Engineering (ICAE), Batam, Indonesia, 2–3 October 2019. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian detection based on yolo network model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018. [Google Scholar] [CrossRef]
- Shen, L.; Tao, H.; Ni, Y.; Wang, Y.; Vladimir, S. Improved YOLOv3 model with feature map cropping for multi-scale road object detection. Meas. Sci. Technol. 2023, 34. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Shen, Z. YOLO-Submarine Cable: An Improved YOLO-V3 Network for Object Detection on Submarine Cable Images. J. Mar. Sci. Eng. 2022, 10, 1143. [Google Scholar] [CrossRef]
- Liu, H.; Duan, X.; Chen, H.; Lou, H.; Deng, L. DBF-YOLO: UAV Small Targets Detection Based on Shallow Feature Fusion. IEEJ Trans. Electr. Electron. Eng. 2023. [CrossRef]
- Xie, W.; Liu, P.X.; Zheng, M. Moving Object Segmentation and Detection for Robust RGBD-SLAM in Dynamic Environments. IEEE Trans. Instrum. Meas. 2021, 70, 5001008. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.-H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Yuan, J.; Zhu, S.; Tang, K.; Sun, Q. ORB-TEDM: An RGB-D SLAM Approach Fusing ORB Triangulation Estimates and Depth Measurements. IEEE Trans. Instrum. Meas. 2022, 71, 5006315. [Google Scholar] [CrossRef]
- Fu, Q.; Yu, H.; Lai, L.; Wang, J.; Peng, X.; Sun, W.; Sun, M. A Robust RGB-D SLAM System With Points and Lines for Low Texture Indoor Environments. IEEE Sensors J. 2019, 19, 9908–9920. [Google Scholar] [CrossRef]
- Chen, Y.; Ma, Y.; Kim, D.H.; Park, S.-K. Region-Based Object Recognition by Color Segmentation Using a Simplified PCNN. IEEE Trans. Neural Networks Learn. Syst. 2015, 26, 1682–1697. [Google Scholar] [CrossRef]
- Sasano, S.; Han, X.H.; Chen, Y.W. Food recognition by combined bags of color features and texture features. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016. [Google Scholar] [CrossRef]
- Gupta, S.; Singh, Y.J.; Kumar, M. Object detection using multiple shape-based features. In Proceedings of the 2016 Fourth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 22–24 December 2016. [Google Scholar] [CrossRef]
- Le, M.H.; Deb, K.; Jo, K.H. Recognizing outdoor scene objects using texture features and probabilistic appearance model. In Proceedings of the ICCAS 2010, Gyeonggi-do, Republic of Korea, 27–30 October 2010. [Google Scholar] [CrossRef]
- Garcia, F.; Cervantes, J.; Lopez, A.; Alvarado, M. Fruit Classification by Extracting Color Chromaticity, Shape and Texture Features: Towards an Application for Supermarkets. IEEE Lat. Am. Trans. 2016, 14, 3434–3443. [Google Scholar] [CrossRef]
- Zuo, G.; Zheng, T.; Xu, Z.; Gong, D. A dense segmentation network for fine semantic mapping. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Z.; Liu, G.; Huang, D. Large-Scale 3D Semantic Mapping Using Monocular Vision. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Hengel, A.V.D. Real-time semantic image segmentation via spatial sparsity. arXiv 2017, arXiv:1712.00213. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Efficient ConvNet for real-Time semantic segmentation. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017. [Google Scholar] [CrossRef]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M.; Zhang, H. A comparative study of real-time semantic segmentation for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Briot, A.; Viswanath, P.; Yogamani, S. Analysis of efficient CNN design techniques for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Li, Z.; Liu, G.; Zhang, D.; Xu, Y. Robust single-object image segmentation based on salient transition region. Pattern Recognit. 2016, 52, 317–331. [Google Scholar] [CrossRef]
- Scona, R.; Jaimez, M.; Petillot, Y.R.; Fallon, M.; Cremers, D. StaticFusion: Background Reconstruction for Dense RGB-D SLAM in Dynamic Environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, H.; Li, Y.; Nakamura, Y.; Zhang, L. FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic EnvironmentsIn Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [CrossRef] [Green Version]
- Yang, S.; Wang, J.; Wang, G.; Hu, X.; Zhou, M.; Liao, Q. Robust RGB-D SLAM in dynamic environment using faster R-CNN. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Sydney, Australia, 3–6 December 2013. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Phillip, K.S.; Chu, A. Keras Implementation of YOLOv3 (Tensorflow Backend). Available online: https://github.com/qqwweee/keras-yolo3 (accessed on 18 February 2018).
- Redmon, J.; Farhadi, A. YOLO: Real-Time Object Detection. Available online: https://pjreddie.com/media/files/yolov3.weights (accessed on 18 February 2018).
- Zhu, C.; Liang, J.; Zhou, F. Transfer learning-based YOLOv3 model for road dense object detection. J. Electron. Imaging 2023, 32, 062505. [Google Scholar] [CrossRef]
- Lam, L.; George, M.; Gardoll, S.; Safieddine, S.; Whitburn, S.; Clerbaux, C. Tropical Cyclone Detection from the Thermal Infrared Sensor IASI Data Using the Deep Learning Model YOLOv3. Atmosphere 2023, 14, 215. [Google Scholar] [CrossRef]
- Geng, K.; Yin, G. Using Deep Learning in Infrared Images to Enable Human Gesture Recognition for Autonomous Vehicles. IEEE Access 2020, 8, 88227–88240. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, X.; Zheng, G.; Liu, X. Object detection of UAV for anti-UAV based on improved YOLO v3. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Spinello, L.; Arras, K.O. People detection in RGB-D data. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011. [Google Scholar] [CrossRef]
- Luber, M.; Spinello, L.; Arras, K.O. People tracking in RGB-D data with on-line boosted target models. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Data Type | Number | Sampling Mode | Dataset Source |
|---|---|---|---|---|
| Persons | Original grayscale image | 224 | Random sampling | duts-tr-mask [58] |
| Dogs | Original grayscale image | 224 | Random sampling | duts-tr-mask [58] |
| Cars | We convert RGB into salient grayscale image | 224 | Random sampling | cars data set-train [57] |
| Channels | Batch | Size of Image | Momentum | Decay | Initial Learning Rate |
|---|---|---|---|---|---|
| 1 | 16 | 416 × 416 | 0.9 | 0.0005 | 0.001 |
| Experimental Configuration | Detail Information |
|---|---|
| Development environment | Pytorch Torchvision Opencv python 3.6 tensorflow 1.8.0 keras 2.3.6 anaconda pycharm |
| Memory | 8 GB |
| GPU | NVIDIA GeForce GTX 1650 |
| Processor | AMD Ryzen 5 4600H with Radeon Graphics |
| Category | Persons | Dogs | Cars | Average Value |
|---|---|---|---|---|
| F1 score | 0.977 | 0.979 | 0.982 | 0.979 |
| AP | 0.970 | 0.965 | 0.975 | 0.970 |
| Precision | 0.983 | 0.987 | 0.988 | 0.986 |
| Recall | 0.971 | 0.972 | 0.976 | 0.973 |
| Accuracy | 0.913 | 0.925 | 0.952 | 0.930 |
| Category | Data Preprocessing | Number | Sampling Mode | Dataset Source |
|---|---|---|---|---|
| Persons | Original grayscale image | 50 | Random sampling | duts-te-mask [58] |
| Dogs | Original grayscale image | 50 | Random sampling | duts-te-mask [58] |
| Cars | We convert RGB into salient grayscale image | 50 | Random sampling | cars data set-test [57] |
| Traffic scenes | We convert RGB into salient grayscale image | 300 | Random sampling | BDD 100k [65] |
| RGB-D people | We convert RGB into salient grayscale image | 100 | Random sampling | RGB-D people dataset [66,67] |
| RGB-D | We convert RGB into salient grayscale image | 100 | Random sampling | TUM dataset [68] |
| Salient Object Detection | Number of Images | Dataset Source | Average Confidence of Object Recognition |
|---|---|---|---|
| Clear contour | 175 | BDD 100K | 93.3% |
| Fuzzy contour | 76 | BDD 100K | 69.7% |
| Contour partial occlusion | 49 | BDD 100K | 51.2% |
| Model | Application | Image Size | Experimental Configuration | Speed (FPS) |
|---|---|---|---|---|
| Ours | Salient semantic segmentation | 416 × 416 | NVIDIAGTX 1650 | 8.2 |
| YOLO V3 [25] | Object recognition | 320 × 320 | M40 or Titan X GPU | 45.5 |
| Salient object detection [24] | Salient object detection | 400 × 300 | NVIDIA RTX-2080Ti GPU | 57 |
| FCN-8s [5,26] | Semantic segmentation | 224 × 224 | NVIDIA Titan | 15 |
| SegNet [8,26] | Semantic segmentation | 224 × 224 | NVIDIA Titan | 17 |
| PSPNet [6,26] | Semantic segmentation | 224 × 224 | NVIDIA Titan | 5 |
| DeepLab-v2 [7,26] | Semantic segmentation | 224 × 224 | NVIDIA Titan | 6 |
| Model | Global Accuracy | Class Average Accuracy | mIOU | Defects |
|---|---|---|---|---|
| Ours | 62.77 | 48.42 | 37.24 | Not obvious |
| FCN-8s [5] | 40.42 | 28.71 | 25.12 | Inherent Network architecture bottleneck and the model’s training require a large number of datasets with ground truth. |
| SegNet [8] | 44.76 | 35.21 | 28.13 | |
| PSPNet [6] | 44.19 | 36.37 | 29.53 | |
| DeepLab-v2 [7] | 43.35 | 32.78 | 27.26 |
| Model | Detection Content | Training Dataset | Ground Truth | Testing Dataset |
|---|---|---|---|---|
| Ours | Salient semantic segmentation of three types of objects | 224 car images, 224 dog images, 224 person images | Correct segmentation of these three types of salient objects | 100 BDD100k images |
| FCN-8s [5] | Semantic segmentation of three types of objects | 224 BDD100k images | Correct segmentation of these three types of objects | 100 BDD100k images |
| SegNet [8] | ||||
| PSPNet [6] | ||||
| DeepLab-v2 [7] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, L.; Zhang, Y.; Wang, Y.; Yang, H.; Tan, S. Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping. Appl. Sci. 2023, 13, 3576. https://doi.org/10.3390/app13063576
Hu L, Zhang Y, Wang Y, Yang H, Tan S. Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping. Applied Sciences. 2023; 13(6):3576. https://doi.org/10.3390/app13063576
Chicago/Turabian StyleHu, Lihe, Yi Zhang, Yang Wang, Huan Yang, and Shuyi Tan. 2023. "Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping" Applied Sciences 13, no. 6: 3576. https://doi.org/10.3390/app13063576
APA StyleHu, L., Zhang, Y., Wang, Y., Yang, H., & Tan, S. (2023). Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping. Applied Sciences, 13(6), 3576. https://doi.org/10.3390/app13063576