

Robustness of Contrastive Learning on Multilingual Font Style Classification Using Various Contrastive Loss Functions

Abstract
:1. Introduction
2. Related Works
2.1. Convolutional Neural Networks for Font Classification
2.2. Contrastive Learning
3. Dataset
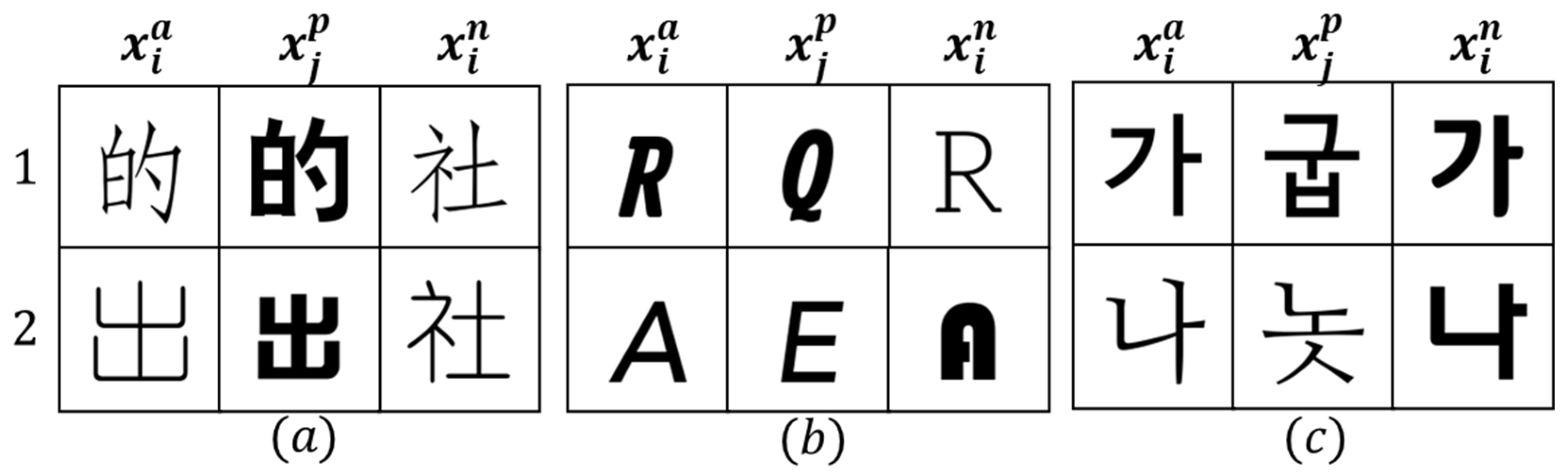
3.1. Triplet Dataset Sampling
3.2. Self-Supervised and Supervised Contrastive Data Sampling
4. Training Details
4.1. Contrastive Learning Framework
4.1.1. Pretext Training
4.1.2. Downstream Task
4.2. Hardware and Software
5. Results and Evaluation
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:14091556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. CoRR [Internet]. arXiv 2014, arXiv:1409.4842. Available online: http://arxiv.org/abs/1409.4842 (accessed on 1 September 2022).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. CoRR [Internet]. arXiv 2016, arXiv:1608.06993. Available online: http://arxiv.org/abs/1608.06993 (accessed on 1 September 2022).
- Hinton, G.; Srivastava, N.; Swersky, K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited 2012, 14, 2. [Google Scholar]
- Hassan, A.U.; Memon, I.; Choi, J. Real-time high quality font generation with Conditional Font GAN. Expert Syst. Appl. 2022, 213, 118907. [Google Scholar] [CrossRef]
- Hassan, A.U.; Ahmed, H.; Choi, J. Unpaired font family synthesis using conditional generative adversarial networks. Knowl. Based Syst. 2021, 229, 107304. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Hjelm, D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. Available online: http://jmlr.org/papers/v10/weinberger09a.html (accessed on 15 September 2022).
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; 2018. Available online: https://openreview.net/forum?id=r1Ddp1-Rb (accessed on 1 September 2022).
- Yun, S.; Han, D.; Chun, S.; Oh, S.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE Computer Society. pp. 6022–6031. Available online: https://doi.ieeecomputersociety.org/10.1109/ICCV.2019.00612 (accessed on 12 November 2022).
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Available online: https://proceedings.neurips.cc/paper/2016/file/6b180037abbebea991d8b1232f8a8ca9-Paper.pdf (accessed on 1 November 2022).
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhou, Z.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J. Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4761–4772. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. CoRR [Internet]. arXiv 2018, arXiv:1812.01187. Available online: http://arxiv.org/abs/1812.01187 (accessed on 1 November 2022).
- Triantafillou, E.; Zemel, R.S.; Urtasun, R. Few-Shot Learning Through an Information Retrieval Lens. CoRR [Internet]. arXiv 2017, arXiv:1707.02610. Available online: http://arxiv.org/abs/1707.02610 (accessed on 1 September 2022).
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.; Huang, J.B. A Closer Look at Few-shot Classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. Available online: https://www.sciencedirect.com/science/article/pii/S0893608098001166 (accessed on 1 September 2022). [CrossRef] [PubMed]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. CoRR [Internet]. arXiv 2020, arXiv:2006.07733. Available online: https://arxiv.org/abs/2006.07733 (accessed on 1 November 2022).
- Gunel, B.; Du, J.; Conneau, A.; Stoyanov, V. Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning. CoRR [Internet]. arXiv 2020, arXiv:2011.01403. Available online: https://arxiv.org/abs/2011.01403 (accessed on 1 November 2022).
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9062–9071. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A Baseline for Few-Shot Image Classification. CoRR [Internet]. arXiv 2019, arXiv:1909.02729. Available online: http://arxiv.org/abs/1909.02729 (accessed on 15 September 2022).
- Afzal, M.Z.; Capobianco, S.; Malik, M.I.; Marinai, S.; Breuel, T.M.; Dengel, A.; Liwicki, M. Deepdocclassifier: Document classification with deep convolutional neural network. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1111–1115. [Google Scholar]
- Harley, A.W.; Ufkes, A.; Derpanis, K.G. Evaluation of deep convolutional nets for document image classification and retrieval. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 991–995. [Google Scholar]
- Cloppet, F.; Eglin, V.; Helias-Baron, M.; Kieu, C.; Vincent, N.; Stutzmann, D. Icdar2017 competition on the classification of medieval handwritings in latin script. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1371–1376. [Google Scholar]
- Kang, L.; Kumar, J.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for document image classification. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3168–3172. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. Script identification in the wild via discriminative convolutional neural network. Pattern Recognit. 2016, 52, 448–458. [Google Scholar] [CrossRef]
- Narayan, A.; Muthalagu, R. Image Character Recognition using Convolutional Neural Networks. In Proceedings of the 2021 Seventh International Conference on Bio Signals, Images, and Instrumentation (ICBSII), Chennai, India, 25–27 March 2021; pp. 1–5. [Google Scholar]
- Tensmeyer, C.; Saunders, D.; Martinez, T. Convolutional Neural Networks for Font Classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 985–990. [Google Scholar]
- Wang, T.; Isola, P. Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere. In Proceedings of the International Conference on Machine Learning, Miami, FL, USA, 14–17 December 2020; pp. 9929–9939. [Google Scholar]
- Izacard, G.; Caron, M.; Hosseini, L.; Riedel, S.; Bojanowski, P.; Joulin, A.; Grave, E. Towards Unsupervised Dense Information Retrieval with Contrastive Learning. CoRR [Internet]. arXiv 2021. Available online: https://arxiv.org/abs/2112.09118 (accessed on 1 December 2022).


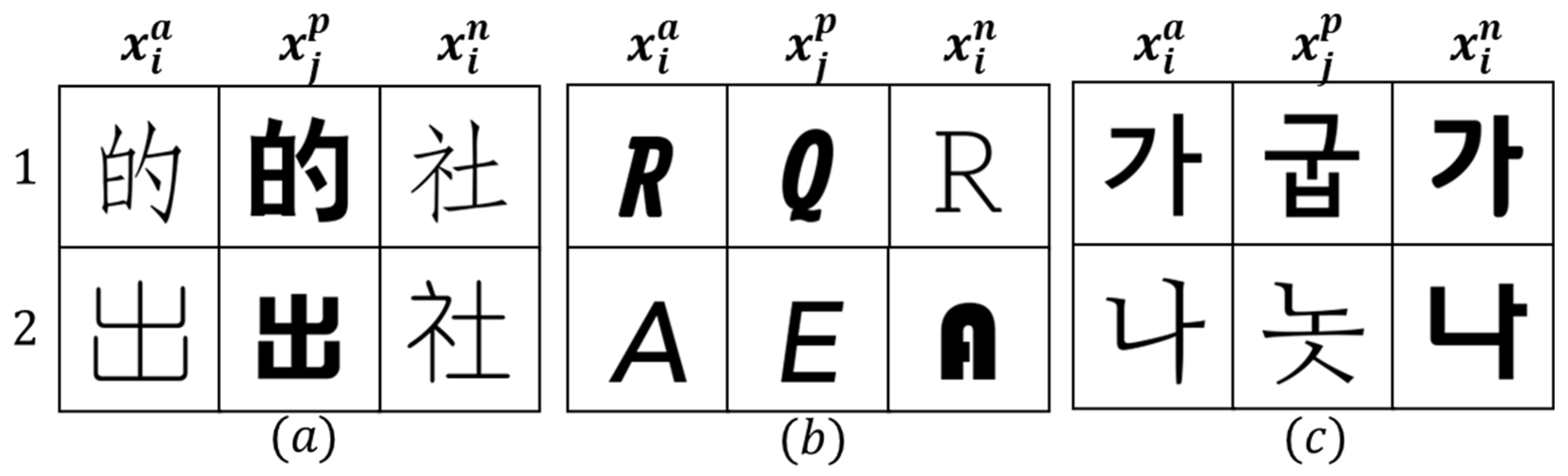
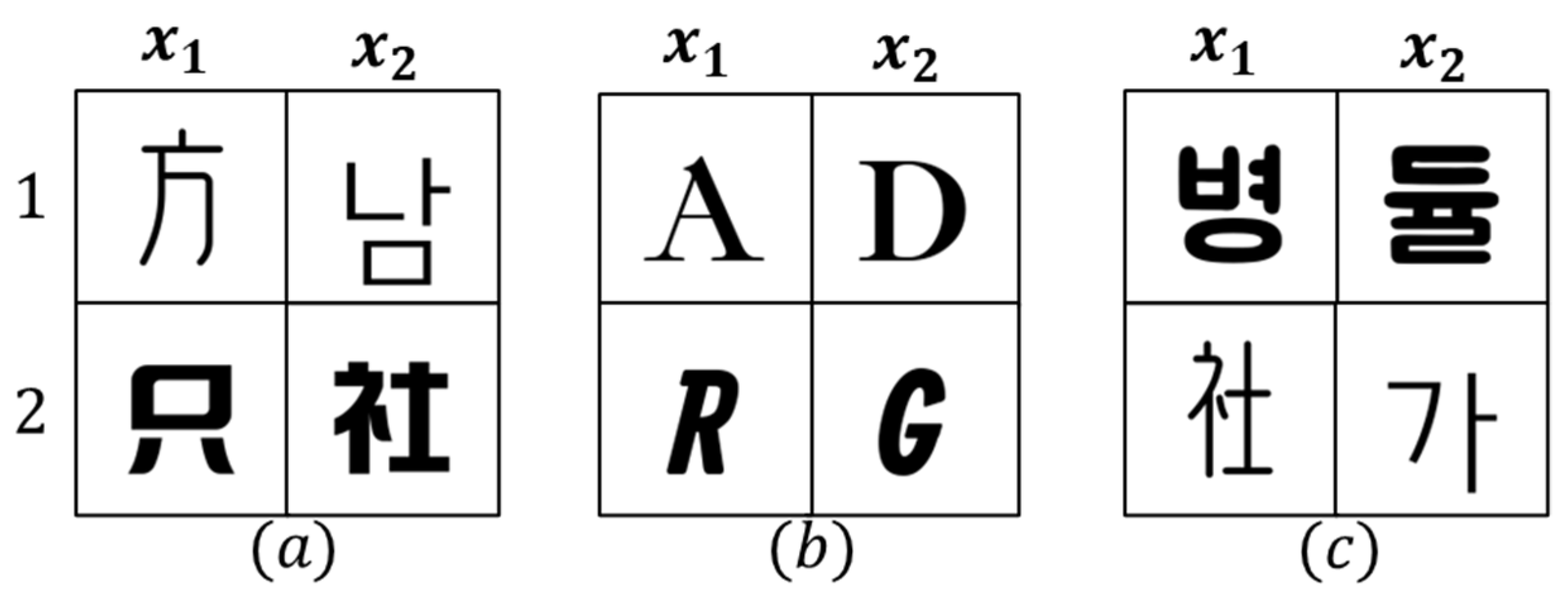



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | Method | Epochs | Labeled Dataset Size | Training Accuracy | Test Accuracy |
|---|---|---|---|---|---|
| Chinese | Supervised | 500 | 65,000 | 99.90 | 99.38 |
| NT-Xent | 50/50 | 65,000 (100%) | 99.23 | 98.67 | |
| 32,500 (50%) | 99.00 | 98.58 | |||
| 6500 (10%) | 98.34 | 98.13 | |||
| Triplet | 50/50 | 65,000 (100%) | 99.78 | 99.11 | |
| 32,500 (50%) | 99.63 | 98.98 | |||
| 6500 (10%) | 98.93 | 98.27 | |||
| Supervised Contrastive | 50/50 | 65,000 (100%) | 99.82 | 99.31 | |
| 32,500 (50%) | 99.53 | 99.14 | |||
| 6500 (10%) | 98.45 | 98.00 | |||
| English | Supervised | 500 | 52,000 | 100 | 99.95 |
| NT-Xent | 50/50 | 52,000 (100%) | 99.35 | 98.10 | |
| 26,000 (50%) | 99.15 | 98.37 | |||
| 5200 (10%) | 98.90 | 98.45 | |||
| Triplet | 50/50 | 52,000 (100%) | 99.85 | 99.17 | |
| 26,000 (50%) | 98.68 | 98.40 | |||
| 5200 (10%) | 99.33 | 99.20 | |||
| Supervised Contrastive | 50/50 | 52,000 (100%) | 99.91 | 99.73 | |
| 26,000 (50%) | 99.53 | 99.07 | |||
| 5200 (10%) | 98.10 | 97.80 | |||
| Korean | Supervised | 500 | 35,000 | 100 | 100 |
| NT-Xent | 50/50 | 35,000 (100%) | 99.35 | 99.00 | |
| 17,500 (50%) | 99.15 | 98.13 | |||
| 3500 (10%) | 98.90 | 98.05 | |||
| Triplet | 50/50 | 35,000 (100%) | 99.85 | 99.17 | |
| 17,500 (50%) | 99.53 | 99.07 | |||
| 3500 (10%) | 99.10 | 98.95 | |||
| Supervised Contrastive | 50/50 | 35,000 (100%) | 100 | 99.76 | |
| 17,500 (50%) | 99.68 | 99.40 | |||
| 3500 (10%) | 98.33 | 98.10 |
| Fine-Tuning Method | N-Shots | Training Accuracy | Test Accuracy |
|---|---|---|---|
| Fully Supervised | 50/500 | 89.0 | 35.0 |
| 100/500 | 95.6 | 53.0 | |
| 250/500 | 98.9 | 74.4 | |
| Contrastive based | 50/500 | 93.0 | 82.0 |
| 100/500 | 98.3 | 89.6 | |
| 250/500 | 99.1 | 96.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Memon, I.; Muhammad, A.u.H.; Choi, J. Robustness of Contrastive Learning on Multilingual Font Style Classification Using Various Contrastive Loss Functions. Appl. Sci. 2023, 13, 3635. https://doi.org/10.3390/app13063635
Memon I, Muhammad AuH, Choi J. Robustness of Contrastive Learning on Multilingual Font Style Classification Using Various Contrastive Loss Functions. Applied Sciences. 2023; 13(6):3635. https://doi.org/10.3390/app13063635
Chicago/Turabian StyleMemon, Irfanullah, Ammar ul Hassan Muhammad, and Jaeyoung Choi. 2023. "Robustness of Contrastive Learning on Multilingual Font Style Classification Using Various Contrastive Loss Functions" Applied Sciences 13, no. 6: 3635. https://doi.org/10.3390/app13063635
APA StyleMemon, I., Muhammad, A. u. H., & Choi, J. (2023). Robustness of Contrastive Learning on Multilingual Font Style Classification Using Various Contrastive Loss Functions. Applied Sciences, 13(6), 3635. https://doi.org/10.3390/app13063635