
Combining the Transformer and Convolution for Effective Brain Tumor Classification Using MRI Images
 , , , and
, , , and 
Abstract
:1. Introduction
- We propose a hybrid model that extracts local as well as retains global information simultaneously for an effective BT classification.
- In the proposed work the FFM and IMM models are employed, the FFM module is responsible for converting the CNN feature maps to PE, while the IMM is responsible for fusion between the feature maps, PE an adaptive and intelligent process.
- Our model has been evaluated on two publicly available datasets and the experimental results of our model for BT classification outperforms state-of-the-art methods.

2. Literature Review
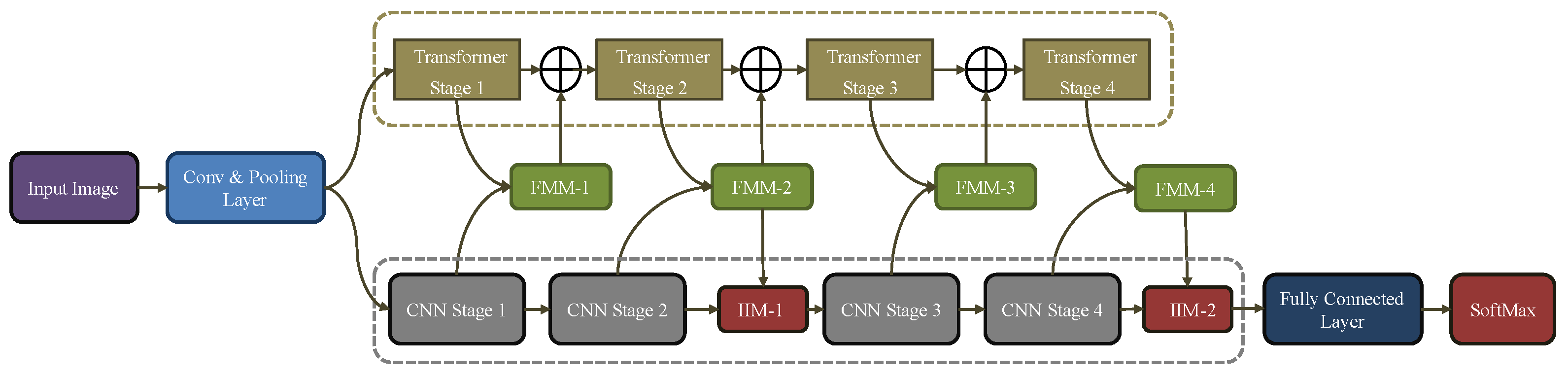
3. Research Methodology
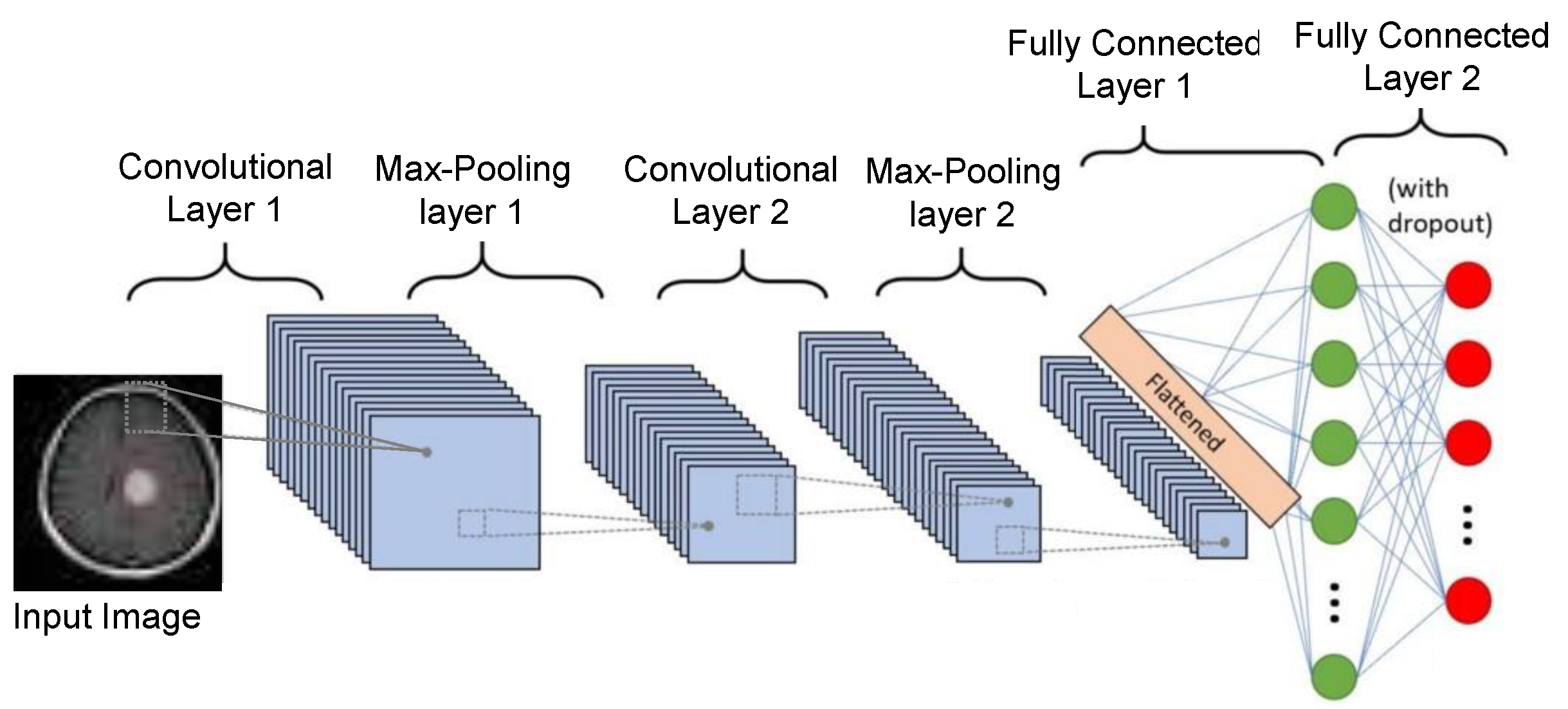
3.1. CNN Feature Extractor
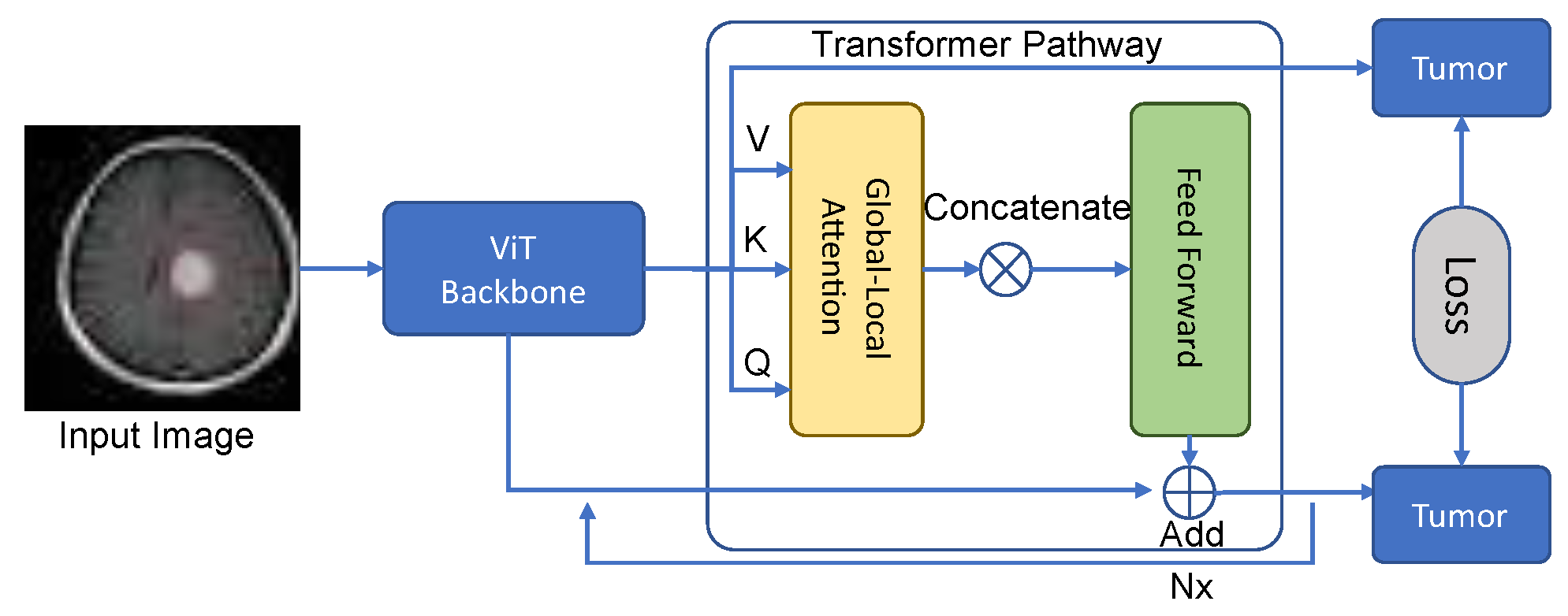
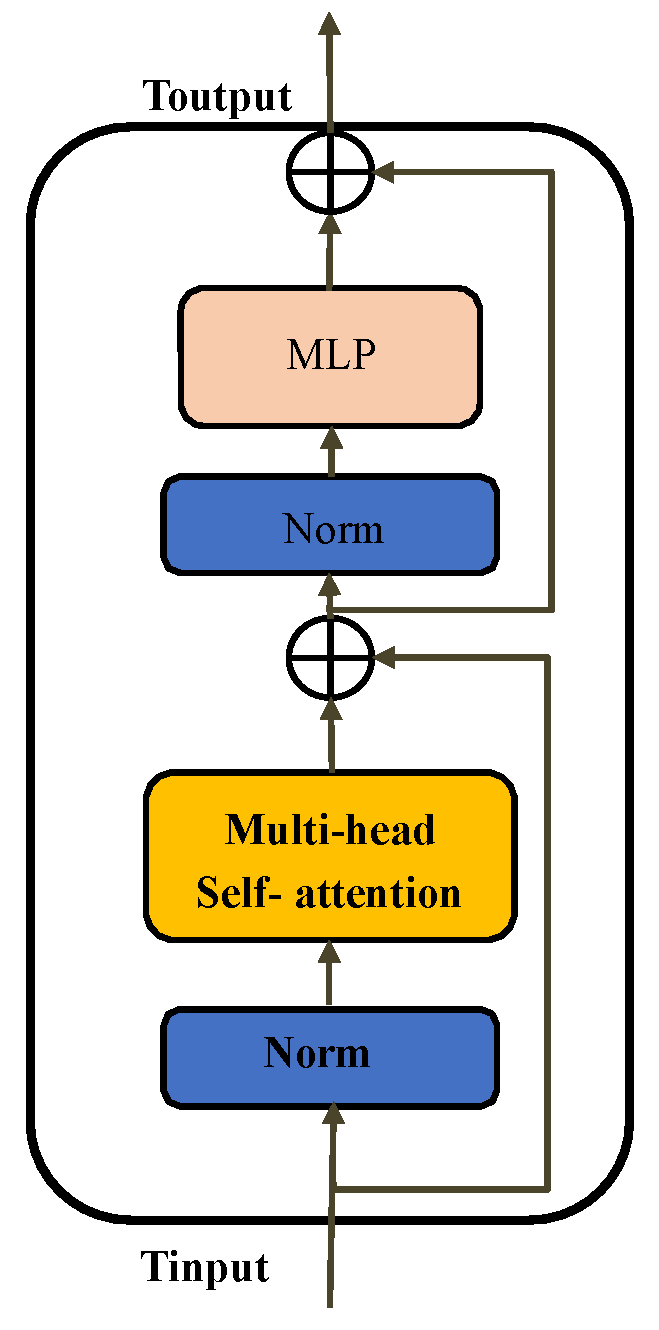
3.2. Transformer Pathway
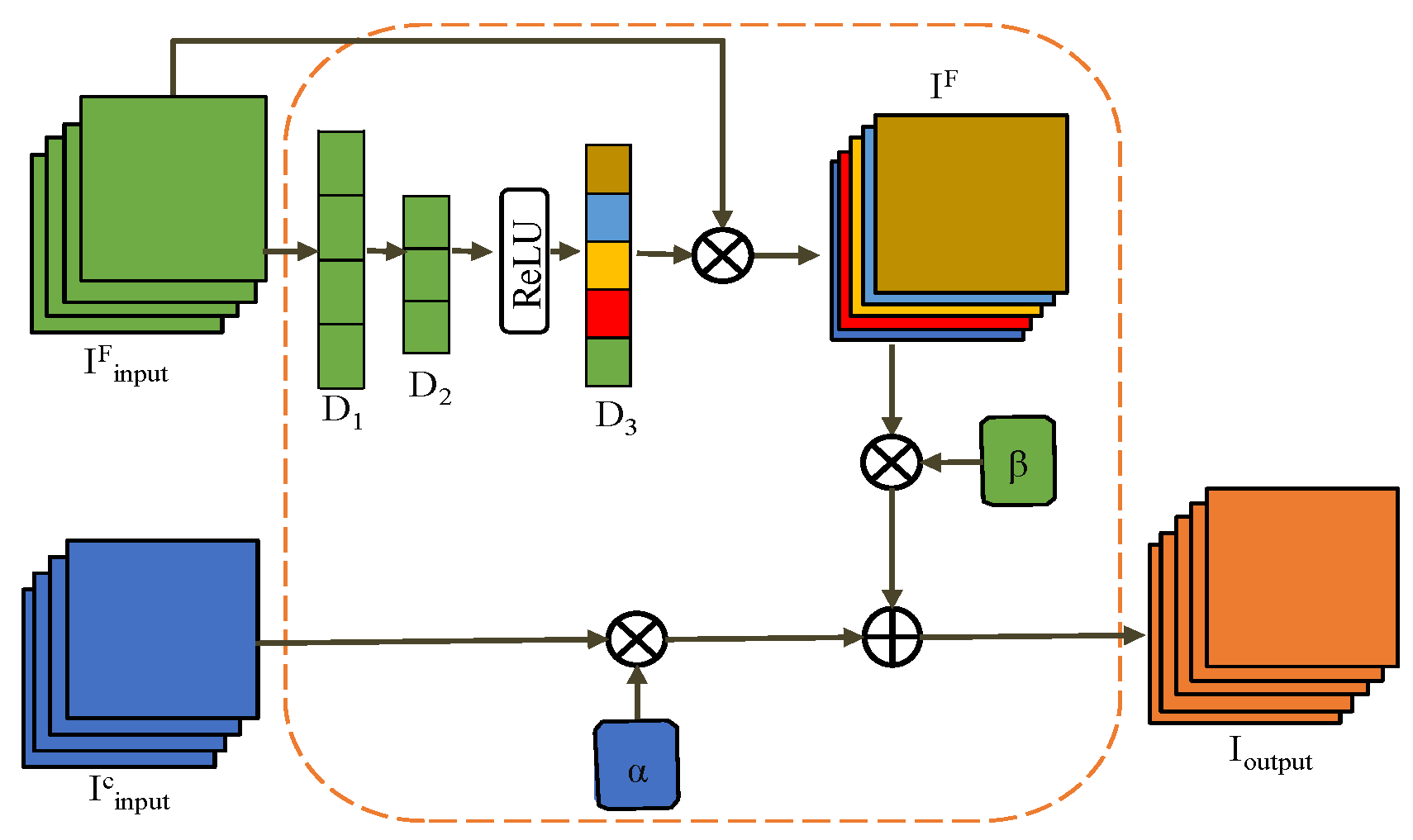
3.3. Feature Merge Module
3.4. Intelligent Merge Module
| Algorithm 1 Training and testing steps of our model provided |
| Input: Dataset of BT images Dataset division: Training, Validation, and Testing Output: Class labels Training: Model parameters
|
3.5. Datasets Explanation
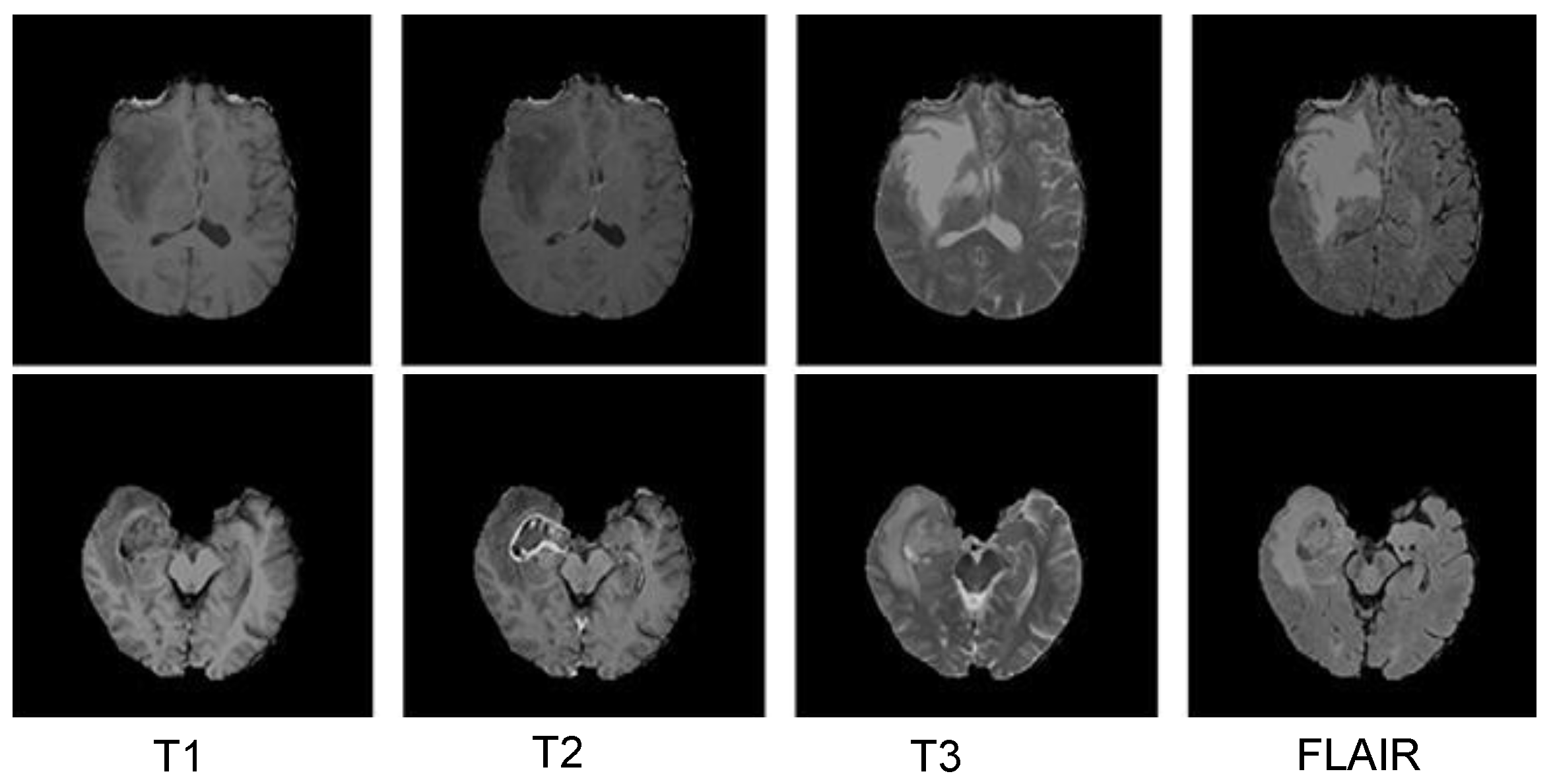
3.5.1. BraTS 2018 Dataset
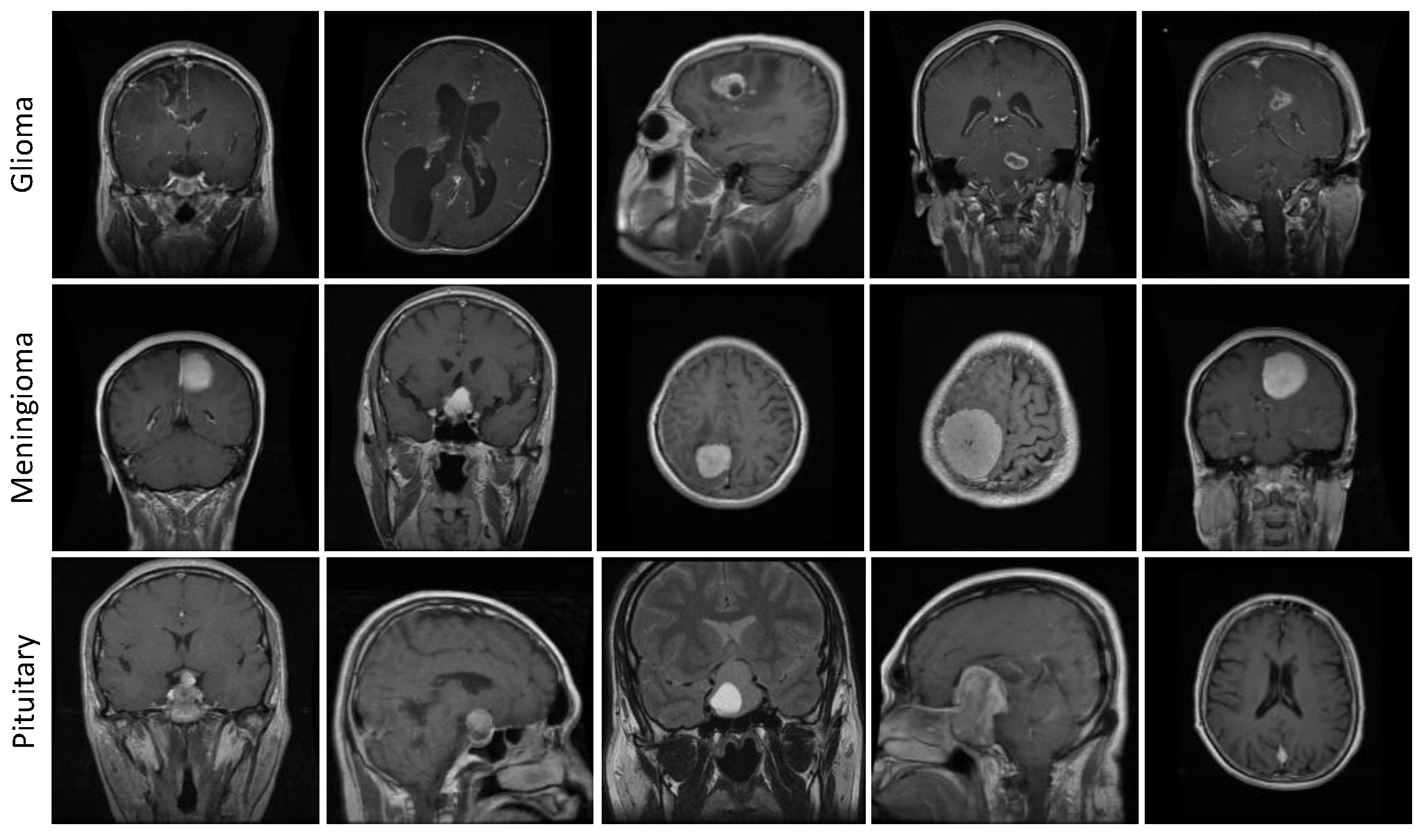
3.5.2. Figshare Dataset
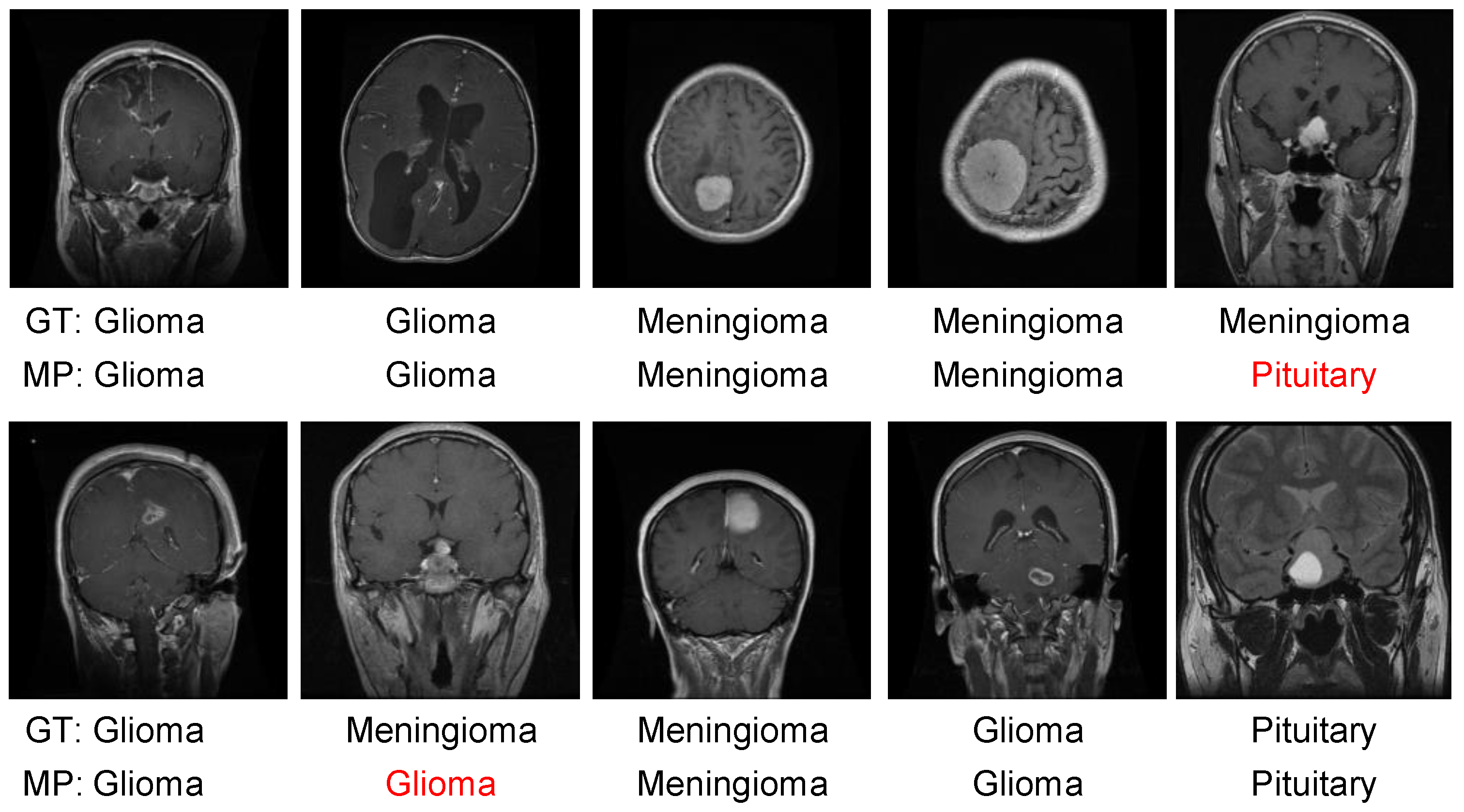
4. Results and Discussions
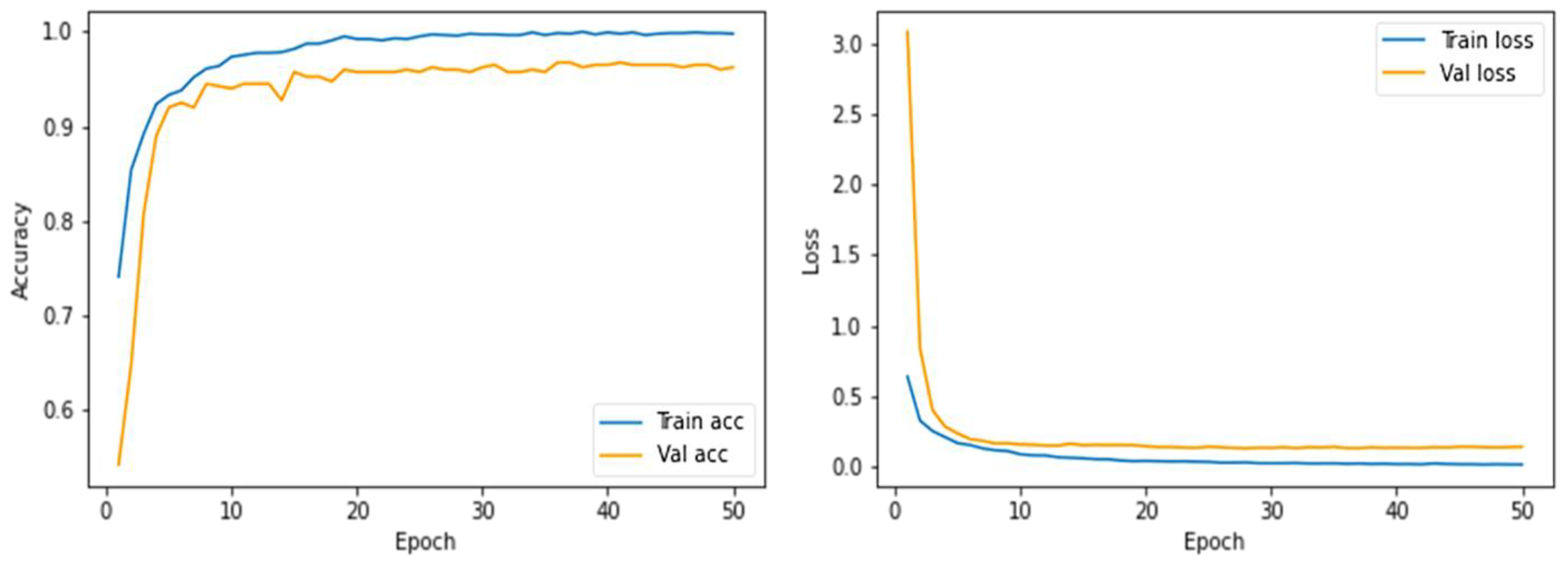
4.1. Training Details
4.2. Evaluation Parameters
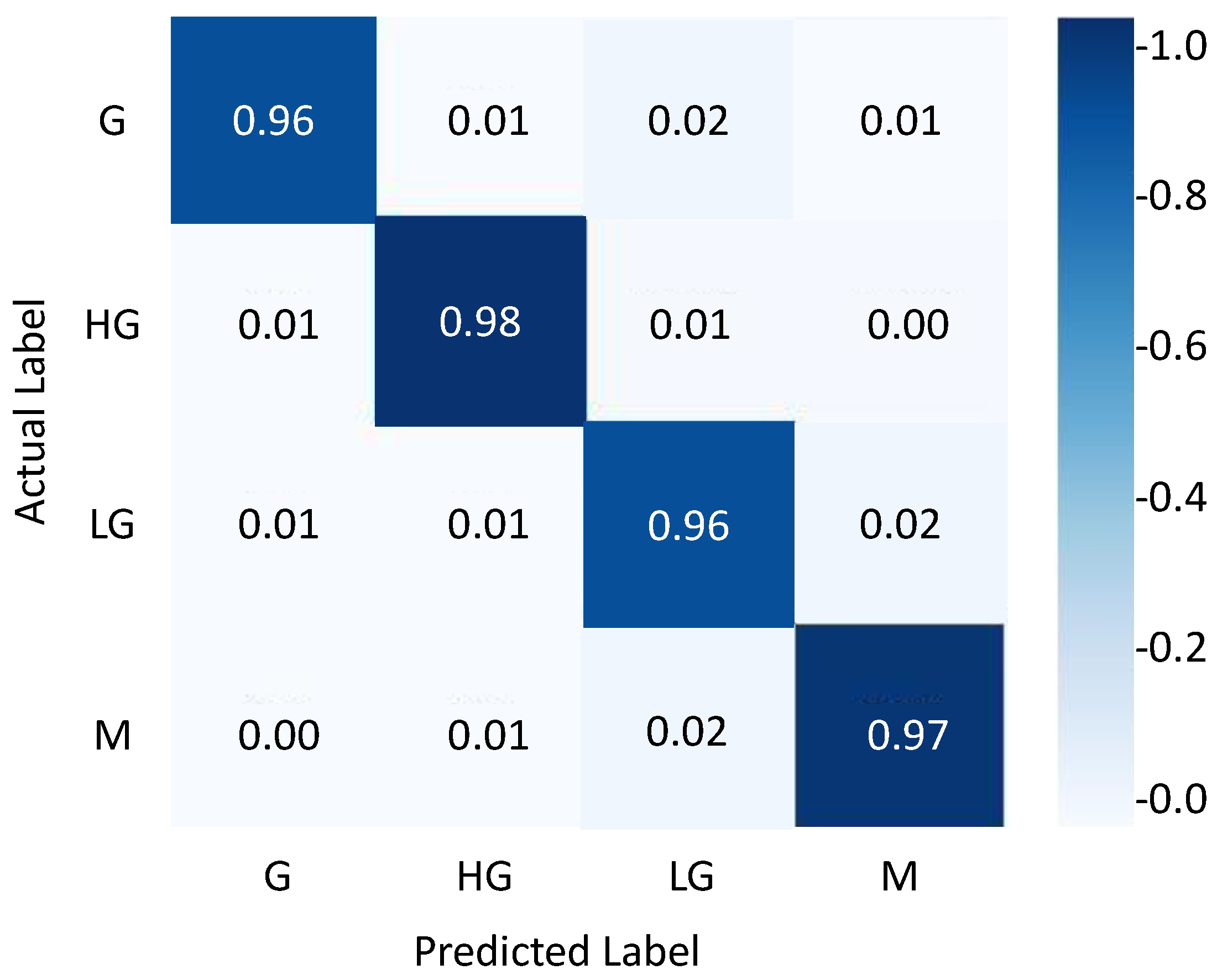
4.3. Results Evaluation Using BraTS 2018 Dataset
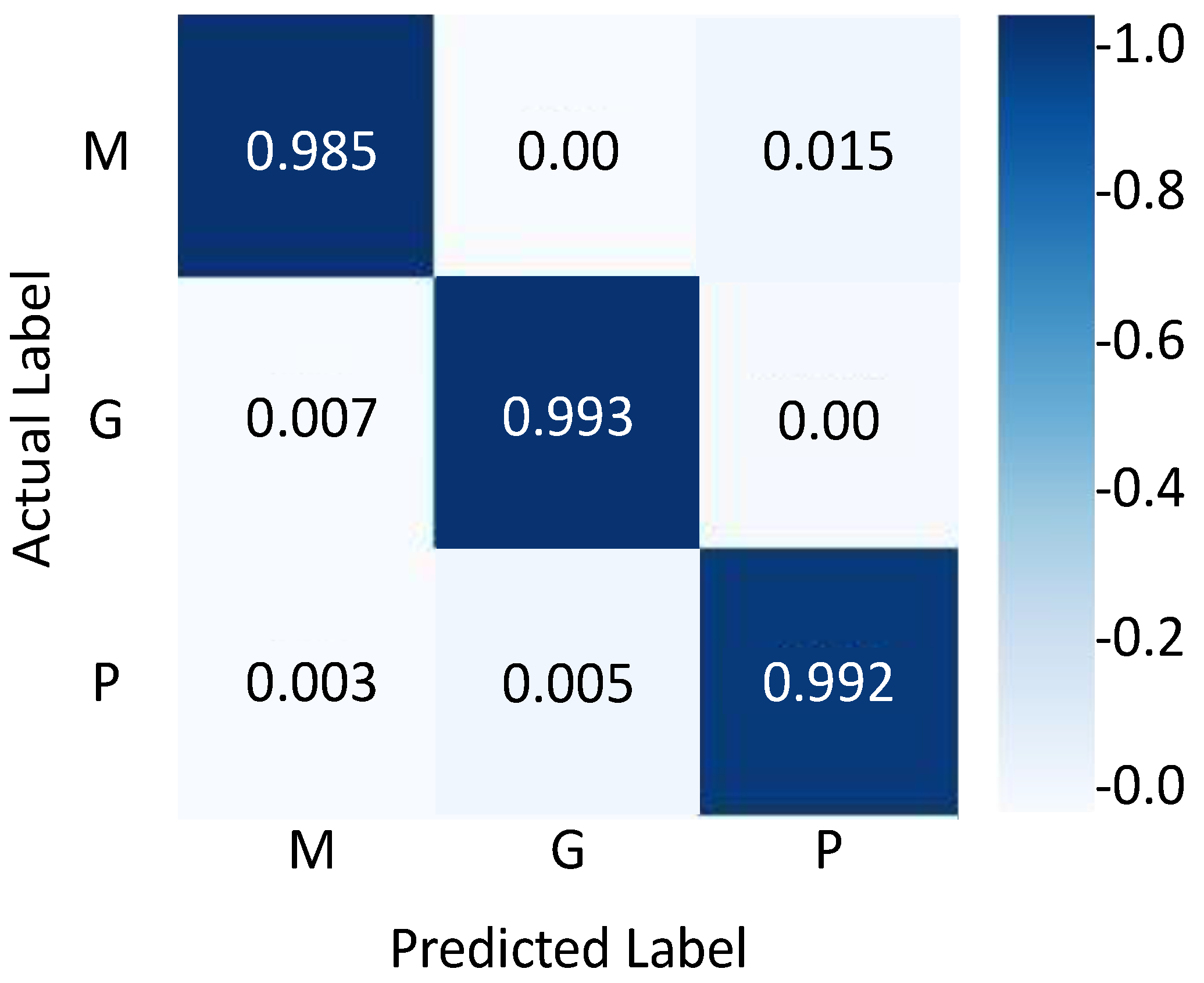
4.4. Results Evaluation Using Figshare Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Accuracy |
|---|---|
| Ari et al. [72] | 97.64% |
| Cheng et al. [28] | 94.68% |
| Abir et al. [69] | 83.33% |
| Afshar et al. [76] | 86.56% |
| Cheng et al. [67] | 91.28% |
| Deepak and Ameer [71] | 97.10% |
| Kaur and Gandhi [75] | 96.95% |
| Ayadi et al. [77] | 90.27% |
| Pashaei et al. [78] | 93.68% |
| Swati et al. [74] | 94.80% |
| Deepak and Ameer [79] | 95.82% |
| Bodapati et al. [66] | 95.23% |
| Türkoğlu M et al. [73]. | 98.04% |
| Proposed Model | 99.10% |
4.5. Comparing the Proposed Model with Various CNN and ViT-Based Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, L.; Jia, K. Multiscale CNNs for brain tumor segmentation and diagnosis. Comput. Math. Methods Med. 2016, 2016, 8356294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajinikanth, V.; Fernandes, S.L.; Bhushan, B.; Harisha; Sunder, N.R. Segmentation and analysis of brain tumor using Tsallis entropy and regularised level set. In Proceedings of the 2nd International Conference on Micro-Electronics, Electromagnetics and Telecommunications, Ghaziabad, India, 20–21 September 2018. [Google Scholar]
- Cancer Research UK. Together We Will Beat Cancer; Cancer Research UK: London, UK. Available online: https://fundraise.cancerresearchuk.org/page/together-we-will-beat-cancer (accessed on 13 December 2022).
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2019, 30, 174–182. [Google Scholar] [CrossRef]
- Varuna Shree, N.; Kumar, T. Identification and classification of brain tumor MRI images with feature extraction using DWT and probabilistic neural network. Brain Inform. 2018, 5, 23–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeng, K.; Zheng, H.; Cai, C.; Yang, Y.; Zhang, K.; Chen, Z. Simultaneous single-and multi-contrast super-resolution for brain MRI images based on a convolutional neural network. Comput. Biol. Med. 2018, 99, 133–141. [Google Scholar] [CrossRef] [PubMed]
- Mittal, M.; Goyal, L.M.; Kaur, S.; Kaur, I.; Verma, A.; Hemanth, D.J. Deep learning based enhanced tumor segmentation approach for MR brain images. Appl. Soft Comput. 2019, 78, 346–354. [Google Scholar] [CrossRef]
- Bunevicius, A.; Schregel, K.; Sinkus, R.; Golby, A.; Patz, S. MR elastography of brain tumors. NeuroImage Clin. 2020, 25, 102109. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 565. [Google Scholar] [CrossRef]
- Iqbal, S.; Ghani, M.U.; Saba, T.; Rehman, A. Brain tumor segmentation in multi-spectral MRI using convolutional neural networks (CNN). Microsc. Res. Tech. 2018, 81, 419–427. [Google Scholar] [CrossRef]
- Arakeri, M.P.; Reddy, G. Computer-aided diagnosis system for tissue characterization of brain tumor on magnetic resonance images. Signal Image Video Process. 2013, 9, 409–425. [Google Scholar] [CrossRef]
- Usman, K.; Rajpoot, K. Brain tumor classification from multi-modality MRI using wavelets and machine learning. Pattern Anal. Appl. 2017, 20, 871–881. [Google Scholar] [CrossRef] [Green Version]
- Mohsen, H.; El-Dahshan, E.-S.A.; El-Horbaty, E.-S.M.; Salem, A.-B.M. Classification using deep learning neural networks for brain tumors. Future Comput. Inform. J. 2018, 3, 68–71. [Google Scholar] [CrossRef]
- Habib, S.; Alyahya, S.; Ahmed, A.; Islam, M.; Khan, S.; Khan, I.; Kamil, M. X-ray Image-Based COVID-19 Patient Detection Using Machine Learning-Based Techniques. Comput. Syst. Sci. Eng. 2022, 43, 671–682. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Khan, Z.A.; Koundal, D.; Lee, M.Y.; Baik, S.W. Vision sensor-based real-time fire detection in resource-constrained IoT environments. Comput. Intell. Neurosci. 2021, 2021, 5195508. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized Dual Fire Attention Network and Medium-Scale Fire Classification Benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef] [PubMed]
- Ullah, W.; Hussain, T.; Khan, Z.A.; Haroon, U.; Baik, S.W. Intelligent dual stream CNN and echo state network for anomaly detection. Knowl.-Based Syst. 2022, 253, 109456. [Google Scholar] [CrossRef]
- Habib, S.; Alsanea, M.; Aloraini, M.; Al-Rawashdeh, H.S.; Islam, M.; Khan, S. An Efficient and Effective Deep Learning-Based Model for Real-Time Face Mask Detection. Sensors 2022, 22, 2602. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Haq, I.U.; Ullah, F.U.M.; Baik, S.W. Towards efficient and effective renewable energy prediction via deep learning. Energy Rep. 2022, 8, 10230–10243. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Baik, S. Boosting energy harvesting via deep learning-based renewable power generation prediction. J. King Saud Univ.-Sci. 2022, 34, 101815. [Google Scholar] [CrossRef]
- Albattah, W.; Kaka Khel, M.H.; Habib, S.; Islam, M.; Khan, S.; Abdul Kadir, K. Hajj Crowd Management Using CNN-Based Approach. Comput. Mater. Contin. 2020, 66, 2183–2197. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, F.U.M.; Gupta, S.K.; Lee, M.Y.; Baik, S.W. Randomly Initialized CNN with Densely Connected Stacked Autoencoder for Efficient Fire Detection. Eng. Appl. Artif. Intell. 2022, 116, 105403. [Google Scholar] [CrossRef]
- Seetha, J.; Raja, S. Brain Tumor Classification Using Convolutional Neural Networks. Biomed. Pharmacol. J. 2018, 11, 1457–1461. [Google Scholar] [CrossRef]
- Habib, S.; Hussain, A.; Albattah, W.; Islam, M.; Khan, S.; Khan, R.U.; Khan, K. Abnormal Activity Recognition from Surveillance Videos Using Convolutional Neural Network. Sensors 2021, 21, 8291. [Google Scholar] [CrossRef] [PubMed]
- Khan, K.; Khan, R.U.; Albattah, W.; Nayab, D.; Qamar, A.M.; Habib, S.; Islam, M. Crowd Counting Using End-to-End Semantic Image Segmentation. Electronics 2021, 10, 1293. [Google Scholar] [CrossRef]
- Ullah, R.; Hayat, H.; Siddiqui, A.A.; Siddiqui, U.A.; Khan, J.; Ullah, F.; Hassan, S.; Hasan, L.; Albattah, W.; Islam, M.; et al. A real-time framework for human face detection and recognition in cctv images. Math. Probl. Eng. 2022, 2022, 3276704. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Yasmin, M.; Saba, T.; Anjum, M.A.; Fernandes, S.L. A New Approach for Brain Tumor Segmentation and Classification Based on Score Level Fusion Using Transfer Learning. J. Med. Syst. 2019, 43, 326. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, S.; Li, W.; Cao, Y.; Lu, X. Combining the Convolution and Transformer for Classification of Smoke-Like Scenes in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4512519. [Google Scholar] [CrossRef]
- Yar, H.; Abbas, N.; Sadad, T.; Iqbal, S. Lung nodule detection and classification using 2D and 3D convolution neural networks (CNNs). In Artificial Intelligence and Internet of Things; CRC Press: Boca Raton, FL, USA, 2021; pp. 365–386. [Google Scholar] [CrossRef]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Rehman, A.; Garcia-Zapirain, B. Automated knee MR images segmentation of anterior cruciate ligament tears. Sensors 2022, 22, 1552. [Google Scholar] [CrossRef]
- Alyami, J.; Rehman, A.; Sadad, T.; Alruwaythi, M.; Saba, T.; Bahaj, S.A. Automatic skin lesions detection from images through microscopic hybrid features set and machine learning classifiers. Microsc. Res. Tech. 2022, 85, 3600–3607. [Google Scholar] [CrossRef]
- Gull, S.; Akbar, S.; Hassan, S.A.; Rehman, A.; Sadad, T. Automated Brain Tumor Segmentation and Classification Through MRI Images. In Proceedings of the International Conference on Emerging Technology Trends in Internet of Things and Computing, Erbil, Iraq, 6–8 June 2021; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Ayesha, H.; Iqbal, S.; Tariq, M.; Abrar, M.; Sanaullah, M.; Abbas, I.; Rehman, A.; Niazi, M.F.K.; Hussain, S. Automatic medical image interpretation: State of the art and future directions. Pattern Recognit. 2021, 114, 107856. [Google Scholar] [CrossRef]
- Talo, M.; Baloglu, U.B.; Yıldırım, Ö.; Acharya, U.R. Application of deep transfer learning for automated brain abnormality classification using MR images. Cogn. Syst. Res. 2019, 54, 176–188. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Akram, F.; Imran, M. A Deep Learning-Based Framework for Automatic Brain Tumors Classification Using Transfer Learning. Circuits Syst. Signal Process. 2019, 39, 757–775. [Google Scholar] [CrossRef]
- Mehrotra, R.; Ansari, M.; Agrawal, R.; Anand, R. A Transfer Learning approach for AI-based classification of brain tumors. Mach. Learn. Appl. 2020, 2, 100003. [Google Scholar] [CrossRef]
- Khan, H.A.; Jue, W.; Mushtaq, M.; Mushtaq, M.U. Brain tumor classification in MRI image using convolutional neural network. Math. Biosci. Eng. 2020, 17, 6203–6216. [Google Scholar] [CrossRef]
- Ayadi, W.; Elhamzi, W.; Charfi, I.; Atri, M. Deep CNN for Brain Tumor Classification. Neural Process. Lett. 2021, 53, 671–700. [Google Scholar] [CrossRef]
- Pereira, S.; Meier, R.; Alves, V.; Reyes, M.; Silva, C.A. Automatic brain tumor grading from MRI data using convolutional neural networks and quality assessment. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications; Springer: Cham, Switzerland, 2018; pp. 106–114. [Google Scholar]
- Farman, H.; Khan, T.; Khan, Z.; Habib, S.; Islam, M.; Ammar, A. Real-Time Face Mask Detection to Ensure COVID-19 Precautionary Measures in the Developing Countries. Appl. Sci. 2022, 12, 3879. [Google Scholar] [CrossRef]
- Jude Hemanth, D.; Vijila, C.S.; Selvakumar, A.; Anitha, J. Performance Improved Iteration-Free Artificial Neural Networks for Abnormal Magnetic Resonance Brain Image Classification. Neurocomputing 2014, 130, 98–107. [Google Scholar] [CrossRef]
- Abiwinanda, N.; Hanif, M.; Hesaputra, S.T.; Handayani, A.; Mengko, T.R. Brain Tumor Classification Using Convolutional Neural Network. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering, Prague, Czech Republic, 3–8 June 2018; pp. 183–189. [Google Scholar]
- Zhou, Y.; Li, Z.; Zhu, H.; Chen, C.; Gao, M.; Xu, K.; Xu, J. Holistic brain tumor screening and classification based on densenet and recurrent neural network. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16 September 2018. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N.; Oikonomou, A.; Benali, H. From handcrafted to deep-learning-based cancer radiomics: Challenges and opportunities. IEEE Signal Process. Mag. 2019, 36, 132–160. [Google Scholar] [CrossRef] [Green Version]
- Sharif, M.I.; Khan, M.A.; Alhussein, M.; Aurangzeb, K.; Raza, M. A decision support system for multimodal brain tumor classification using deep learning. Complex Intell. Syst. 2021, 8, 3007–3020. [Google Scholar] [CrossRef]
- Sekhar, A.; Biswas, S.; Hazra, R.; Sunaniya, A.K.; Mukherjee, A.; Yang, L. Brain tumor classification using fine-tuned GoogLeNet features and machine learning algorithms: IoMT enabled CAD system. IEEE J. Biomed. Health Inform. 2021, 26, 983–991. [Google Scholar] [CrossRef] [PubMed]
- Abbood, A.A.; Shallal, Q.; Fadhel, M. Automated brain tumor classification using various deep learning models: A comparative study. Indones. J. Electr. Eng. Comput. Sci. 2021, 22, 252. [Google Scholar] [CrossRef]
- Tummala, S.; Kadry, S.; Bukhari, S.A.C.; Rauf, H.T. Classification of Brain Tumor from Magnetic Resonance Imaging Using Vision Transformers Ensembling. Curr. Oncol. 2022, 29, 7498–7511. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Prasanna, P. Brain Cancer Survival Prediction on Treatment-Naïve MRI using Deep Anchor Attention Learning with Vision Transformer. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022. [Google Scholar]
- Nallamolu, S.; Nandanwar, H.; Singh, A.; Subalalitha, C.N. A CNN-based Approach for Multi-Classification of Brain Tumors. In Proceedings of the 2022 2nd Asian Conference on Innovation in Technology (ASIANCON), Ravet, India, 26–28 August 2022. [Google Scholar]
- Aladhadh, S.; Alsanea, M.; Aloraini, M.; Khan, T.; Habib, S.; Islam, M. An Effective Skin Cancer Classification Mechanism via Medical Vision Transformer. Sensors 2022, 22, 4008. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021. [Google Scholar]
- Jiang, Y.; Zhang, Y.; Lin, X.; Dong, J.; Cheng, T.; Liang, J. SwinBTS: A method for 3D multimodal brain tumor segmentation using swin transformer. Brain Sci. 2022, 12, 797. [Google Scholar] [CrossRef]
- Gai, D.; Zhang, J.; Xiao, Y.; Min, W.; Zhong, Y.; Zhong, Y. RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation. Brain Sci. 2022, 12, 1145. [Google Scholar] [CrossRef]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Aladhadh, S.; Almatroodi, S.A.; Habib, S.; Alabdulatif, A.; Khattak, S.U.; Islam, M. An Efficient Lightweight Hybrid Model with Attention Mechanism for Enhancer Sequence Recognition. Biomolecules 2023, 13, 70. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Khan, Z.A.; Lee, M.Y.; Baik, S.W. Fire Detection via Effective Vision Transformers. J. Korean Inst. Next Gener. Comput. 2021, 17, 21–30. [Google Scholar]
- Gull, S.; Akbar, S.; Khan, H. Automated detection of brain tumor through magnetic resonance images using convolutional neural network. BioMed Res. Int. 2021, 2021, 3365043. [Google Scholar] [CrossRef]
- Abd El Kader, I.; Xu, G.; Shuai, Z.; Saminu, S.; Javaid, I.; Ahmad, I.S. Differential deep convolutional neural network model for brain tumor classification. Brain Sci. 2021, 11, 352. [Google Scholar] [CrossRef]
- Sharif, M.I.; Li, J.P.; Khan, M.A.; Saleem, M.A. Active deep neural network features selection for segmentation and recognition of brain tumors using MRI images. Pattern Recognit. Lett. 2020, 129, 181–189. [Google Scholar] [CrossRef]
- Bodapati, J.D.; Shaik, N.S.; Naralasetti, V.; Mundukur, N.B. Joint training of two-channel deep neural network for brain tumor classification. Signal Image Video Process. 2021, 15, 753–760. [Google Scholar] [CrossRef]
- Cheng, J.; Huang, W.; Cao, S.; Yang, R.; Yang, W.; Yun, Z.; Wang, Z.; Feng, Q. Enhanced Performance of Brain Tumor Classification via Tumor Region Augmentation and Partition. PLoS ONE 2015, 10, e0140381. [Google Scholar] [CrossRef]
- Cheng, J.; Yang, W.; Huang, M.; Huang, W.; Jiang, J.; Zhou, Y.; Yang, R.; Zhao, J.; Feng, Y.; Feng, Q.; et al. Retrieval of Brain Tumors by Adaptive Spatial Pooling and Fisher Vector Representation. PLoS ONE 2016, 11, e0157112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abir, T.A.; Siraji, J.A.; Ahmed, E.; Khulna, B. Analysis of a novel MRI based brain tumour classification using probabilistic neural network (PNN). Int. J. Sci. Res. Sci. Eng. Technol 2018, 4, 65–79. [Google Scholar]
- Hossain, A.; Islam, M.T.; Abdul Rahim, S.K.; Rahman, M.A.; Rahman, T.; Arshad, H.; Khandakar, A.; Ayari, M.A.; Chowdhury, M.E.H. A Lightweight Deep Learning Based Microwave Brain Image Network Model for Brain Tumor Classification Using Reconstructed Microwave Brain (RMB) Images. Biosensors 2023, 13, 238. [Google Scholar] [CrossRef] [PubMed]
- Deepak, S.; Ameer, P. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef]
- Arı, A.; Alcin, O.; Hanbay, D. Brain MR image classification based on deep features by using extreme learning machines. Biomed. J. Sci. Tech. Res. 2020, 25. [Google Scholar] [CrossRef]
- Türkoğlu, M. Brain Tumor Detection using a combination of Bayesian optimization based SVM classifier and fine-tuned based deep features. Avrupa Bilim Teknol. Derg. 2021, 27, 251–258. [Google Scholar] [CrossRef]
- Swati, Z.N.K.; Zhao, Q.; Kabir, M.; Ali, F.; Ali, Z.; Ahmed, S.; Lu, J. Brain tumor classification for MR images using transfer learning and fine-tuning. Comput. Med. Imaging Graph. 2019, 75, 34–46. [Google Scholar] [CrossRef] [PubMed]
- Kaur, T.; Gandhi, T.K. Deep convolutional neural networks with transfer learning for automated brain image classification. Mach. Vis. Appl. 2020, 31, 20. [Google Scholar] [CrossRef]
- Alsanea, M.; Dukyil, A.S.; Afnan; Riaz, B.; Alebeisat, F.; Islam, M.; Habib, S. To Assist Oncologists: An Efficient Machine Learning-Based Approach for Anti-Cancer Peptides Classification. Sensors 2022, 22, 4005. [Google Scholar] [CrossRef] [PubMed]
- Ayadi, W.; Charfi, I.; Elhamzi, W.; Atri, M. Brain tumor classification based on hybrid approach. Vis. Comput. 2020, 38, 107–117. [Google Scholar] [CrossRef]
- Pashaei, A.; Sajedi, H.; Jazayeri, N. Brain tumor classification via convolutional neural network and extreme learning machines. In Proceedings of the 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 25–26 October 2018. [Google Scholar]
- Deepak, S.; Ameer, P. Automated categorization of brain tumor from mri using cnn features and svm. J. Ambient Intell. Humaniz. Comput. 2021, 12, 8357–8369. [Google Scholar] [CrossRef]


| Classes | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| G | 0.96 | 0.98 | 0.969 | 96.0 |
| HG | 0.98 | 0.97 | 0.974 | 98.0 |
| LG | 0.96 | 0.96 | 0.96 | 96.0 |
| M | 0.97 | 0.97 | 0.97 | 97.0 |
| Average | 0.967 | 0.970 | 0.968 | 96.75 |
| Approach | Accuracy |
|---|---|
| DR LBP features + k–NN [65] | 85.10 |
| Inception V3 + SVM [65] | 87.40 |
| PSO features + Softmax [65] | 92.50 |
| Two-Channel DNN [66] | 93.69 |
| Proposed model | 96.75 |
| Classes | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Meningiomas | 0.99 | 0.99 | 0.99 | 99.35 |
| Gliomas | 0.99 | 0.99 | 0.99 | 99.02 |
| Pituitary tumors | 0.98 | 0.99 | 0.98 | 98.95 |
| Average | 0.987 | 0.99 | 0.987 | 99.10 |
| Dataset | Reference | Method | Parameters (M) | Accuracy |
|---|---|---|---|---|
| BraTS 2018 | Nallamolu et al. [51] | AlexNet | 60 | 92.20 |
| Inception V3 | 23.9 | 94.66 | ||
| VGG19 | 143.7 | 93.26 | ||
| ResNet50 | 25.6 | 91.78 | ||
| ViT | 93.48 | |||
| CNN with Ten Conv layers | -- | 94.72 | ||
| The proposed model | TECNN | 96.75 | ||
| FIGSHARE | Tummala et al. [49] | ViT-B/16 (224 × 224) | 86 | 97.06 |
| ViT-B/32 (224 × 224) | 86 | 96.25 | ||
| ViT-L/16 (224 × 224) | 307 | 96.74 | ||
| ViT-L/32 (224 × 224) | 307 | 96.01 | ||
| ViT-B/16 (384 × 384) | 86 | 97.72 | ||
| ViT-B/32 (384 × 384) | 86 | 97.87 | ||
| ViT-L/16 (384 × 384) | 307 | 97.55 | ||
| ViT-L/32 (384 × 384) | 307 | 98.21 | ||
| Ensemble of ViTs | -- | 98.70 | ||
| The proposed model | TECNN | 22.5 | 99.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aloraini, M.; Khan, A.; Aladhadh, S.; Habib, S.; Alsharekh, M.F.; Islam, M. Combining the Transformer and Convolution for Effective Brain Tumor Classification Using MRI Images. Appl. Sci. 2023, 13, 3680. https://doi.org/10.3390/app13063680
Aloraini M, Khan A, Aladhadh S, Habib S, Alsharekh MF, Islam M. Combining the Transformer and Convolution for Effective Brain Tumor Classification Using MRI Images. Applied Sciences. 2023; 13(6):3680. https://doi.org/10.3390/app13063680
Chicago/Turabian StyleAloraini, Mohammed, Asma Khan, Suliman Aladhadh, Shabana Habib, Mohammed F. Alsharekh, and Muhammad Islam. 2023. "Combining the Transformer and Convolution for Effective Brain Tumor Classification Using MRI Images" Applied Sciences 13, no. 6: 3680. https://doi.org/10.3390/app13063680
APA StyleAloraini, M., Khan, A., Aladhadh, S., Habib, S., Alsharekh, M. F., & Islam, M. (2023). Combining the Transformer and Convolution for Effective Brain Tumor Classification Using MRI Images. Applied Sciences, 13(6), 3680. https://doi.org/10.3390/app13063680