
An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector





Abstract
1. Introduction
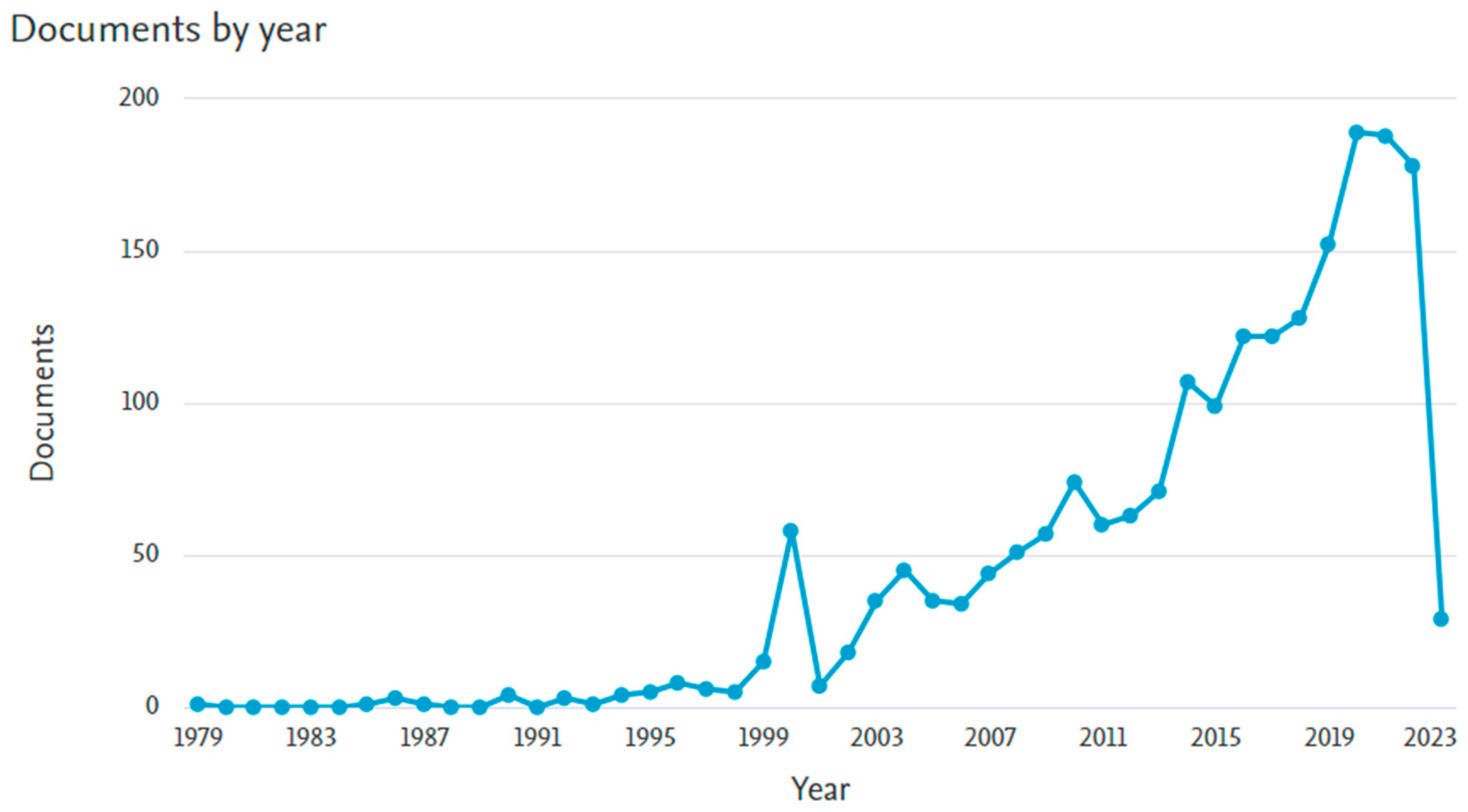
2. Literature Review
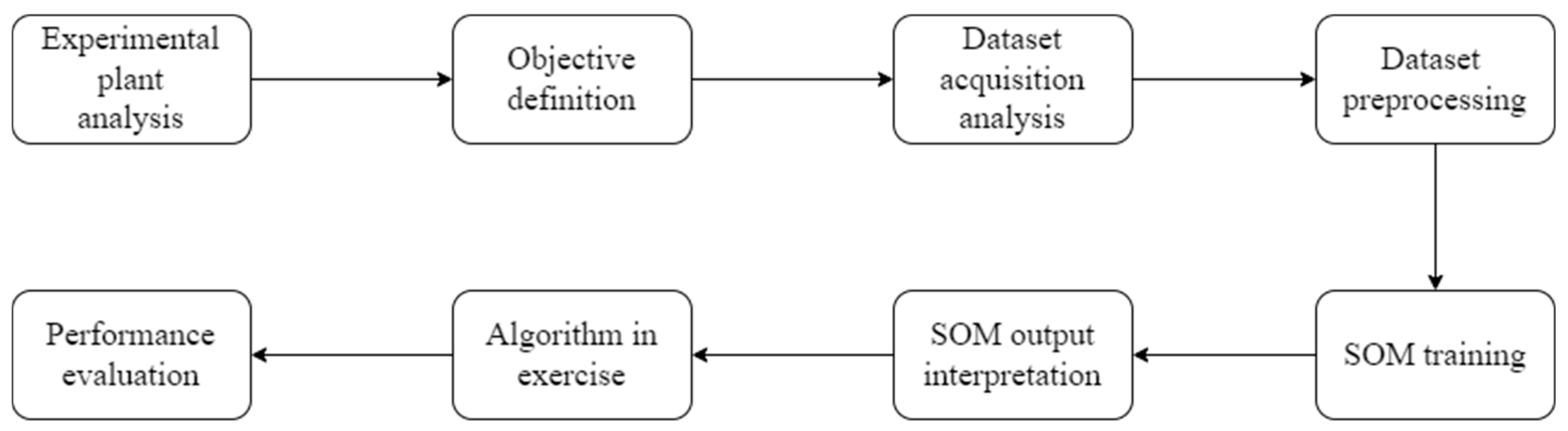
3. The Research Approach
- (i)
- Experimental plant Analysis—An AS-IS analysis is conducted in the two-phase experimental plant. All components and smart sensors it is equipped with are described (Section 3.1).
- (ii)
- Objective definition—The research project aims to use an artificial neural network to identify potential failures in an oil and gas plant (Section 3.2).
- (iii)
- Dataset Acquisition Analysis—Numerous tests are conducted on the plant. First, data are taken for the steady state of the system and fault conditions. The anomalies were created intentionally using manual shut-off valves that prevent fluid flow. For each shut-off valve, three distinct degrees of occlusion are produced (L1: low obstruction, L2: medium obstruction, L3: high obstruction) (Section 4.1).
- (iv)
- Dataset Preprocessing—The readings of steady-state and samples of all anomaly L3 tests are unified into a single database that is then standardized using the z-score method. Finally, the dataset is ready to be fed to the SOM network (Section 4.1).
- (v)
- SOM Training—The training process sees the SOM network’s optimal choice of two fundamental parameters: Learning Rate and Neighbourhood Size. The two parameters are chosen to minimize an objective function defined by the quantization error (Section 4.2).
- (vi)
- SOM Output Interpretation—The input data are projected into a two-dimensional output map. Next, the relationships between the areas and macro-areas into which the SOM network projects the different readings are studied. Finally, two parameters are considered to validate the network results: cluster purity and confusion matrix between the predicted and actual readings (Section 4.4).
- (vii)
- The algorithm in exercise—After training the algorithm and evaluating the results of anomaly L3 tests, the readings of L1 and L2 anomalous states are provided to the SOM algorithm (Section 4.6).
- (viii)
- Performance evaluation—Sums regarding the algorithm’s effectiveness and the outcomes from the two separate datasets are calculated (Section 4.7).
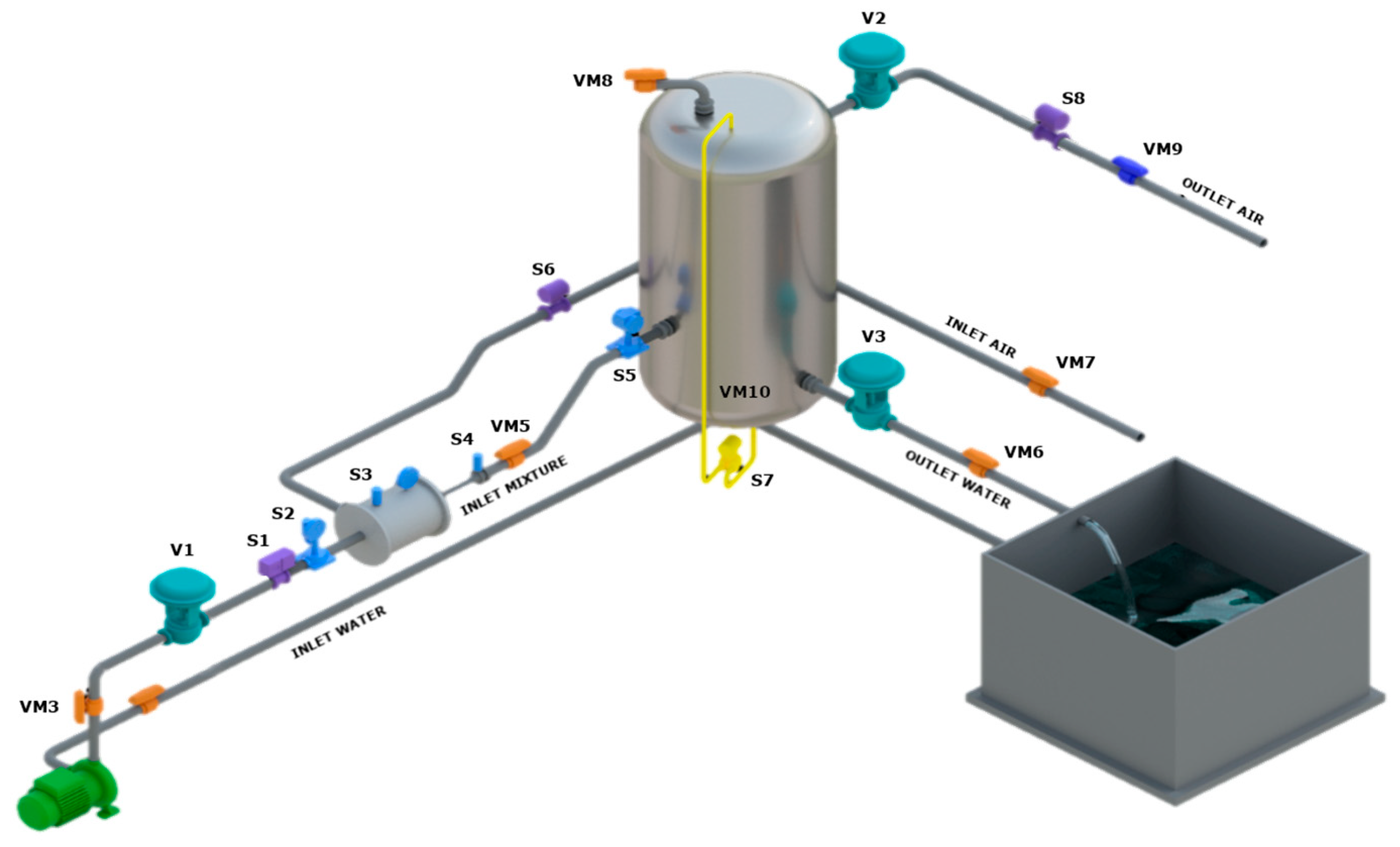
3.1. The Experimental Two-Phase Plant
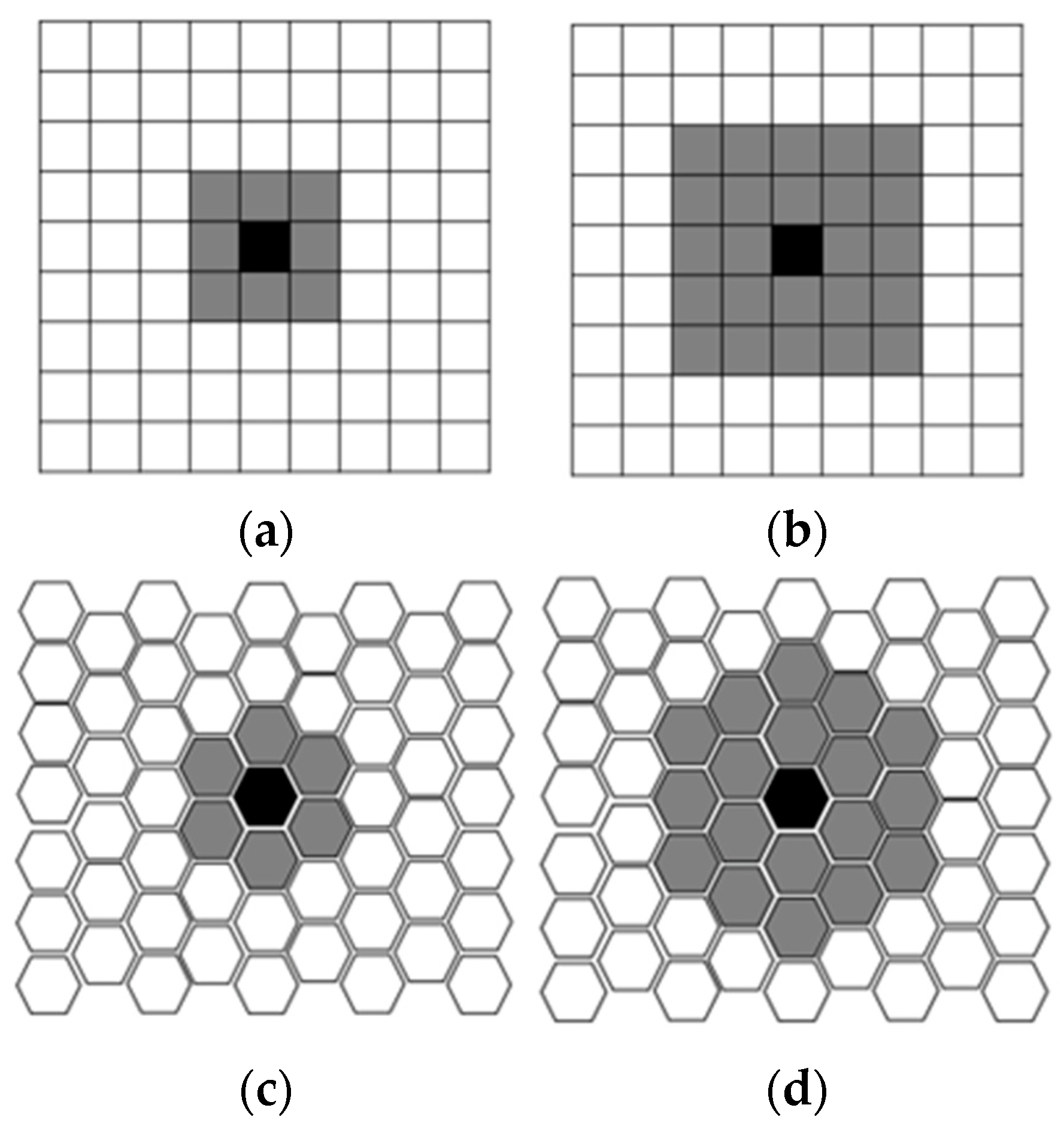
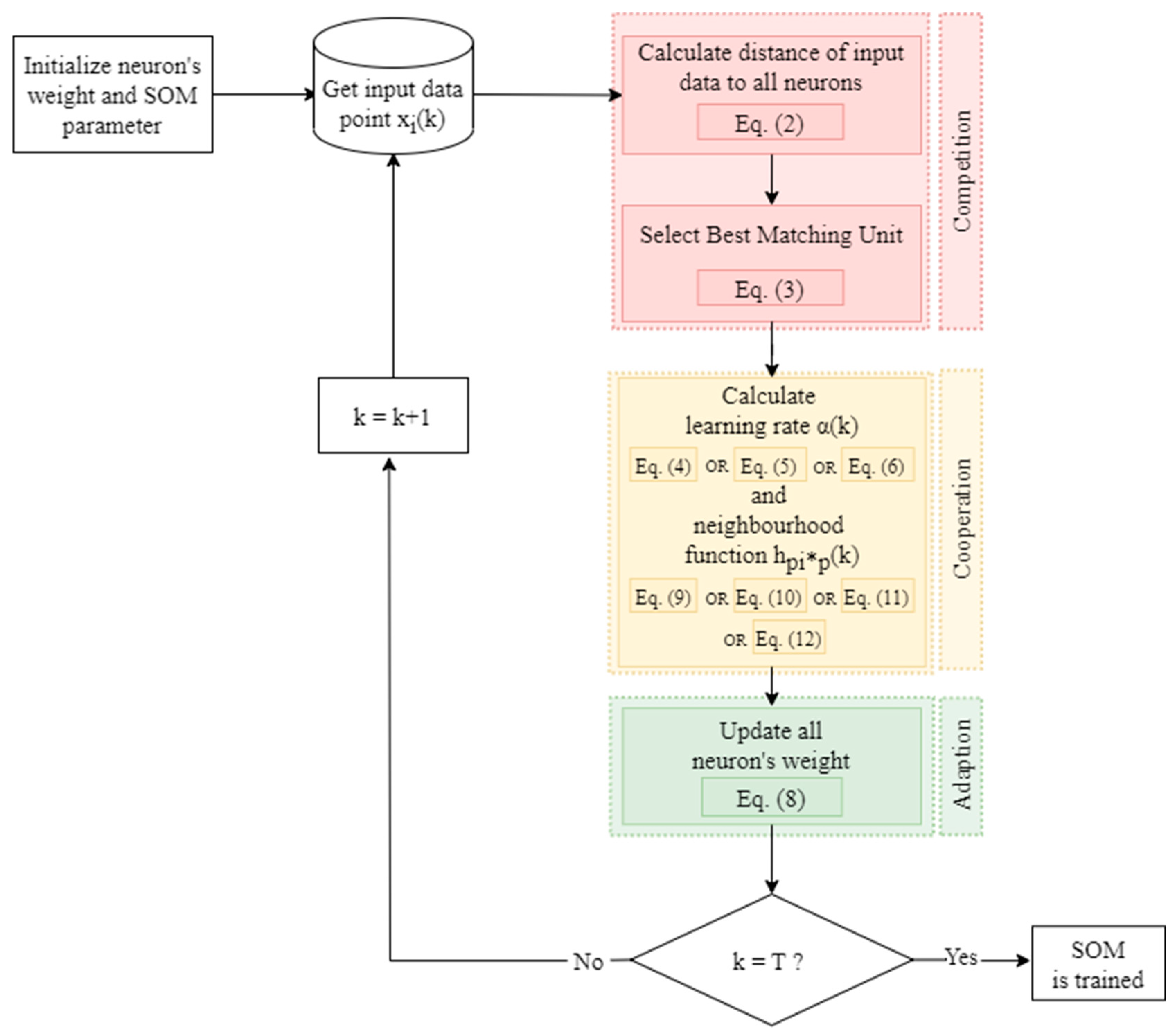
3.2. The Self-Organizing Map
3.3. Tuning Phase
- The space on which to search.
- The objective function to be minimized.
- The database in which to store all search evaluations (optional).
- The search algorithm to be used (optional).
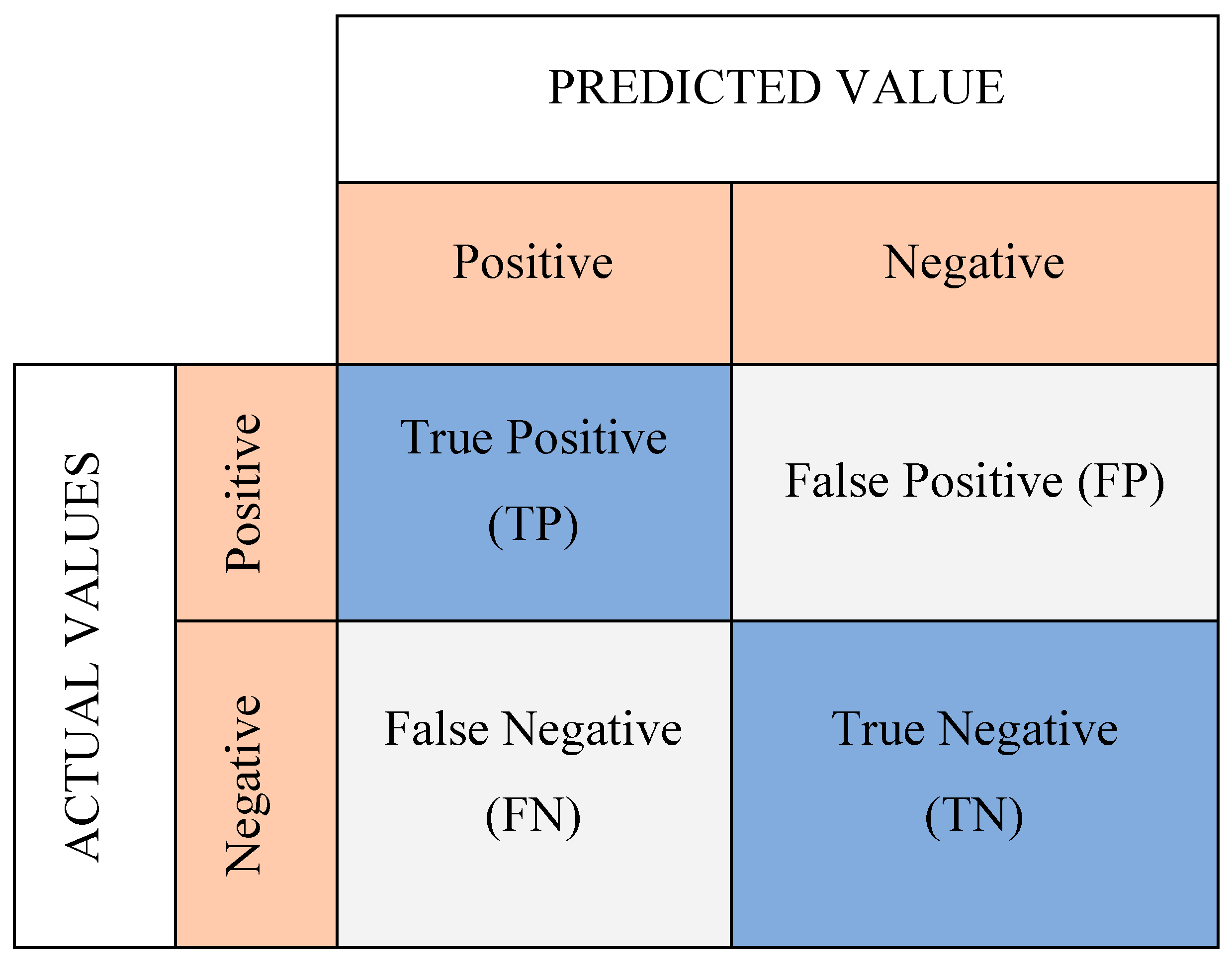
3.4. Quality of Self-Organizing Map
- True positives (TP): the actual value is positive, and the predicted is also positive.
- True negatives (TN): the actual value is negative, and the prediction is also negative.
- False positives (FP): the actual is negative, but the prediction is positive.
- False negatives (FN): the actual is positive, but the prediction is negative.
- Accuracy (Equation (22))—is the percentage of samples in the test set that were categorized correctly.
- Precision (Equation (23))—out of all the samples, how many belonged to the positive class compared to how many the model projected would.
- Recall (Equation (24))—the proportion of samples from the positive class was expected to do so.
- F1-Score (Equation (25))—the harmonic mean of the precision and recall scores obtained for the positive class.
4. Results and Discussions
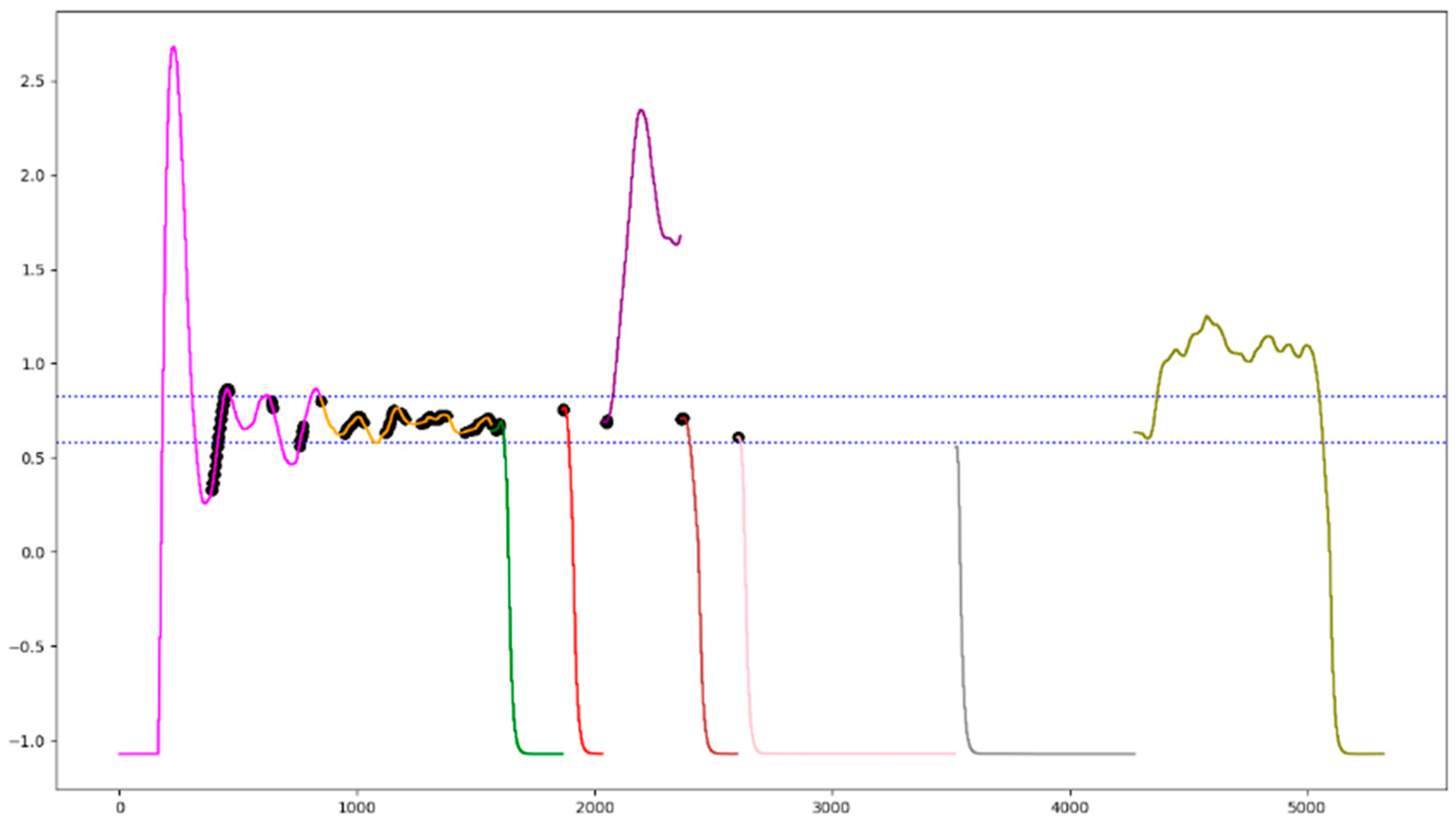
4.1. Raw Data Collection and Data Standardization
4.2. The Algorithm
- x: 18.
- y: 18.
- Input len: 5130.
- Topology: hexagonal.
- Sigma: 2.382866878925671.
- Learning rate: 2.422871364551101.
- Neighbourhood function: Gaussian Function.
- Seed: 0
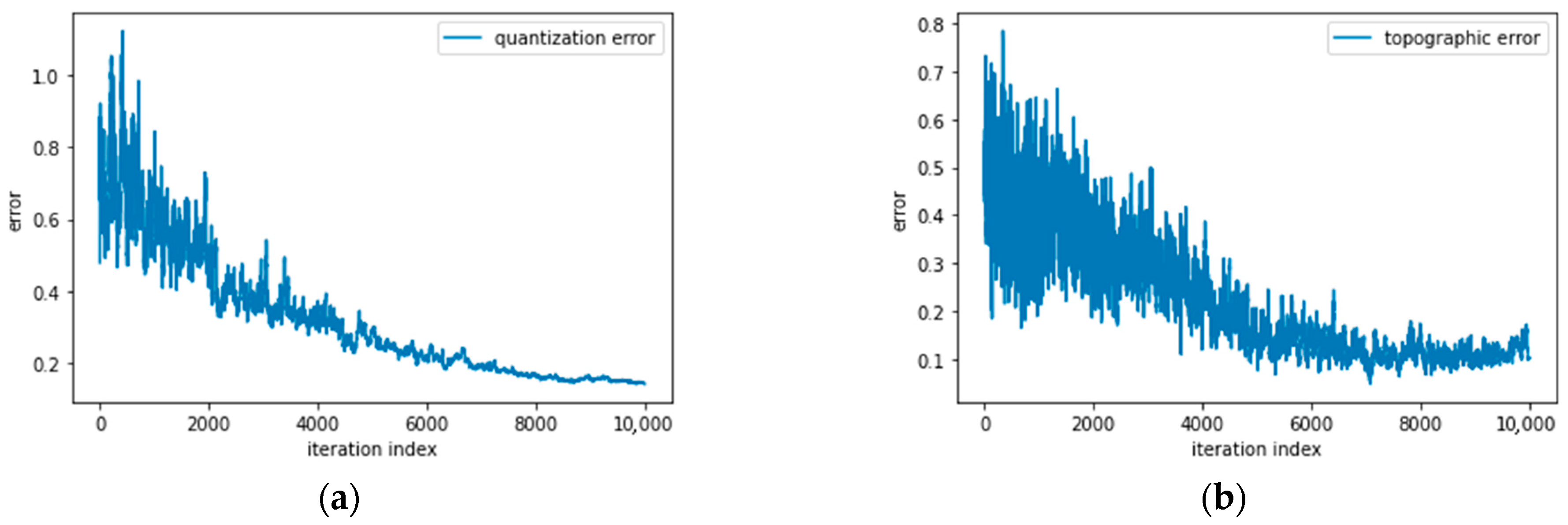
4.3. Validation
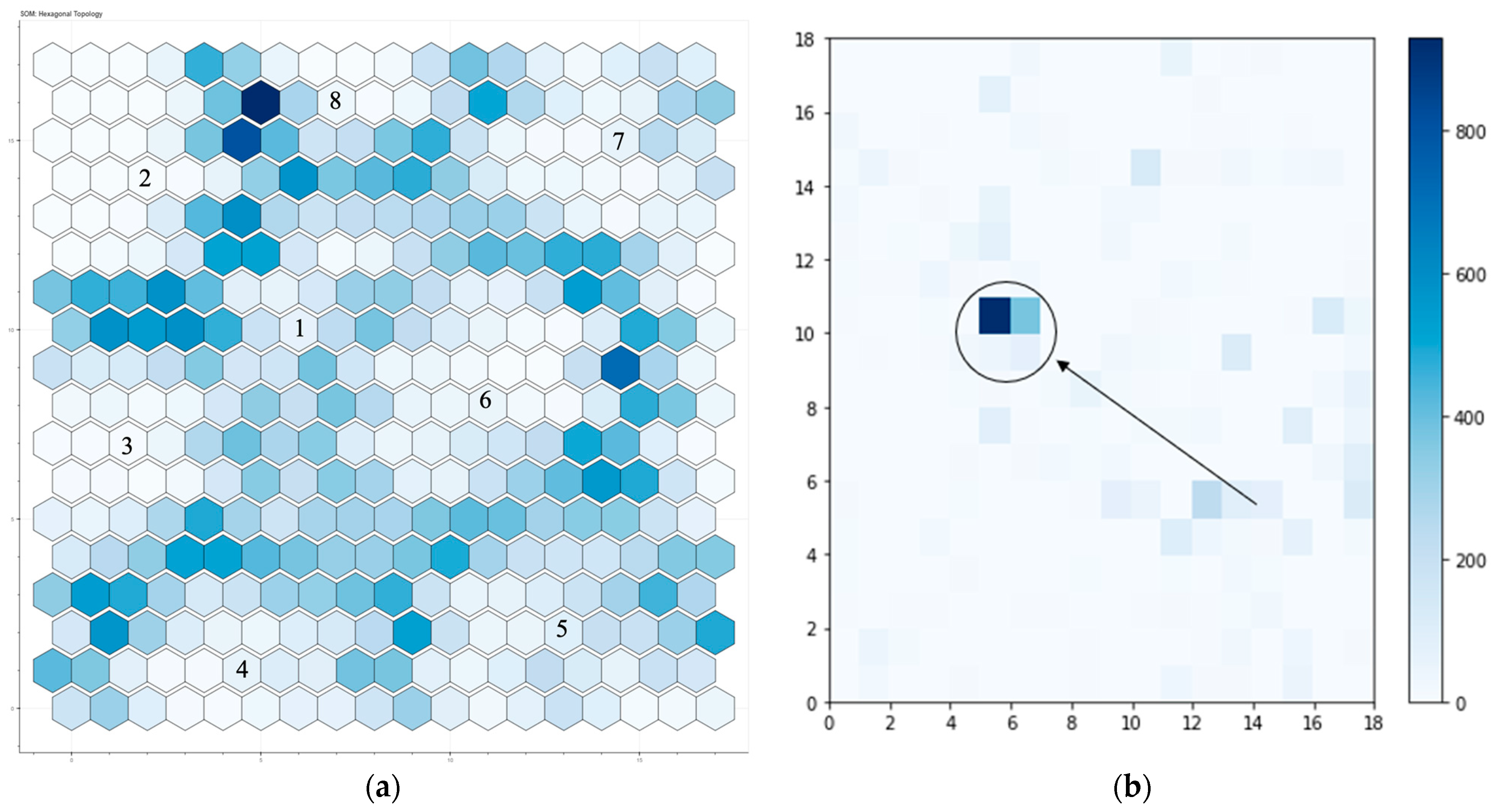
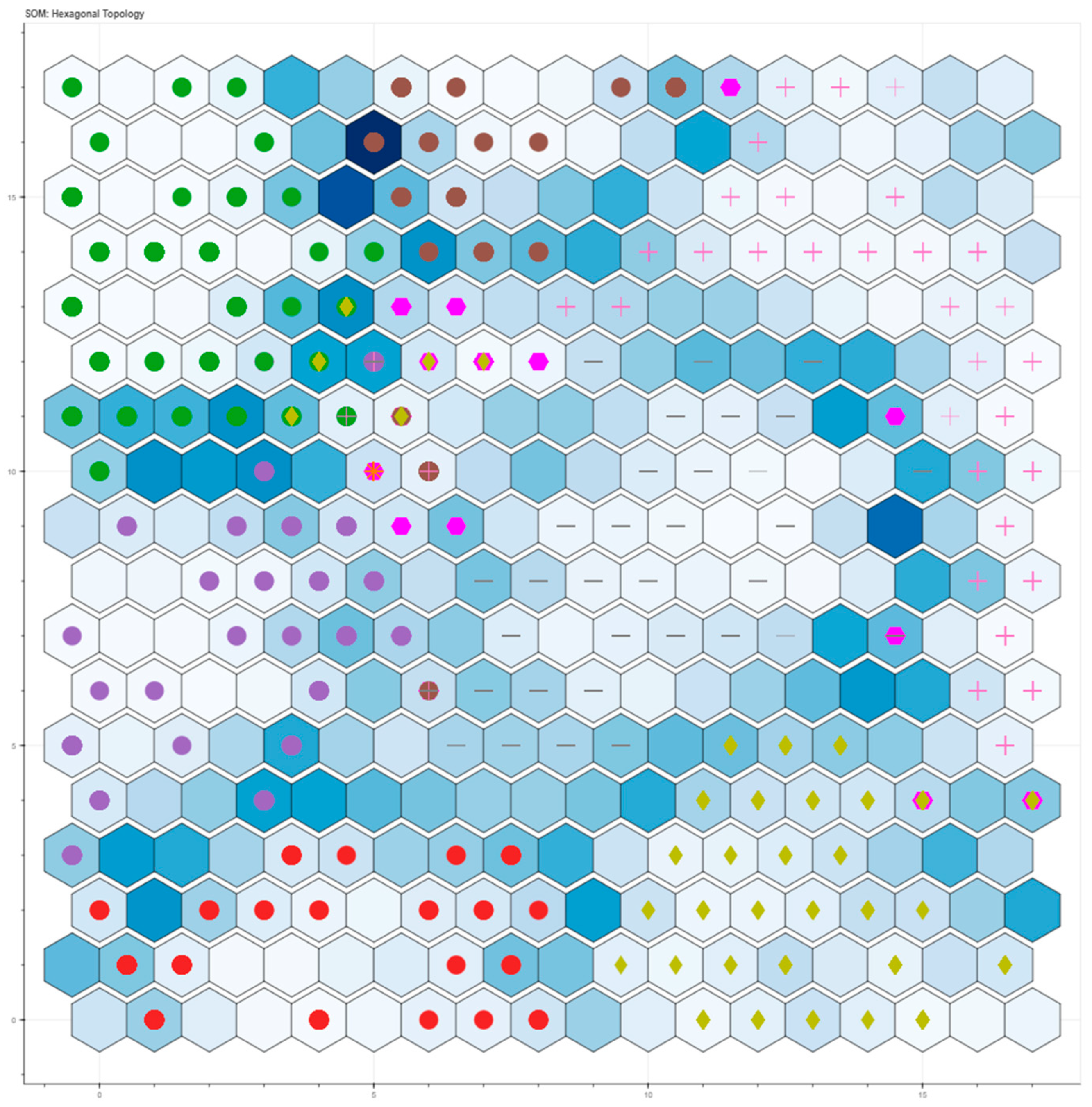
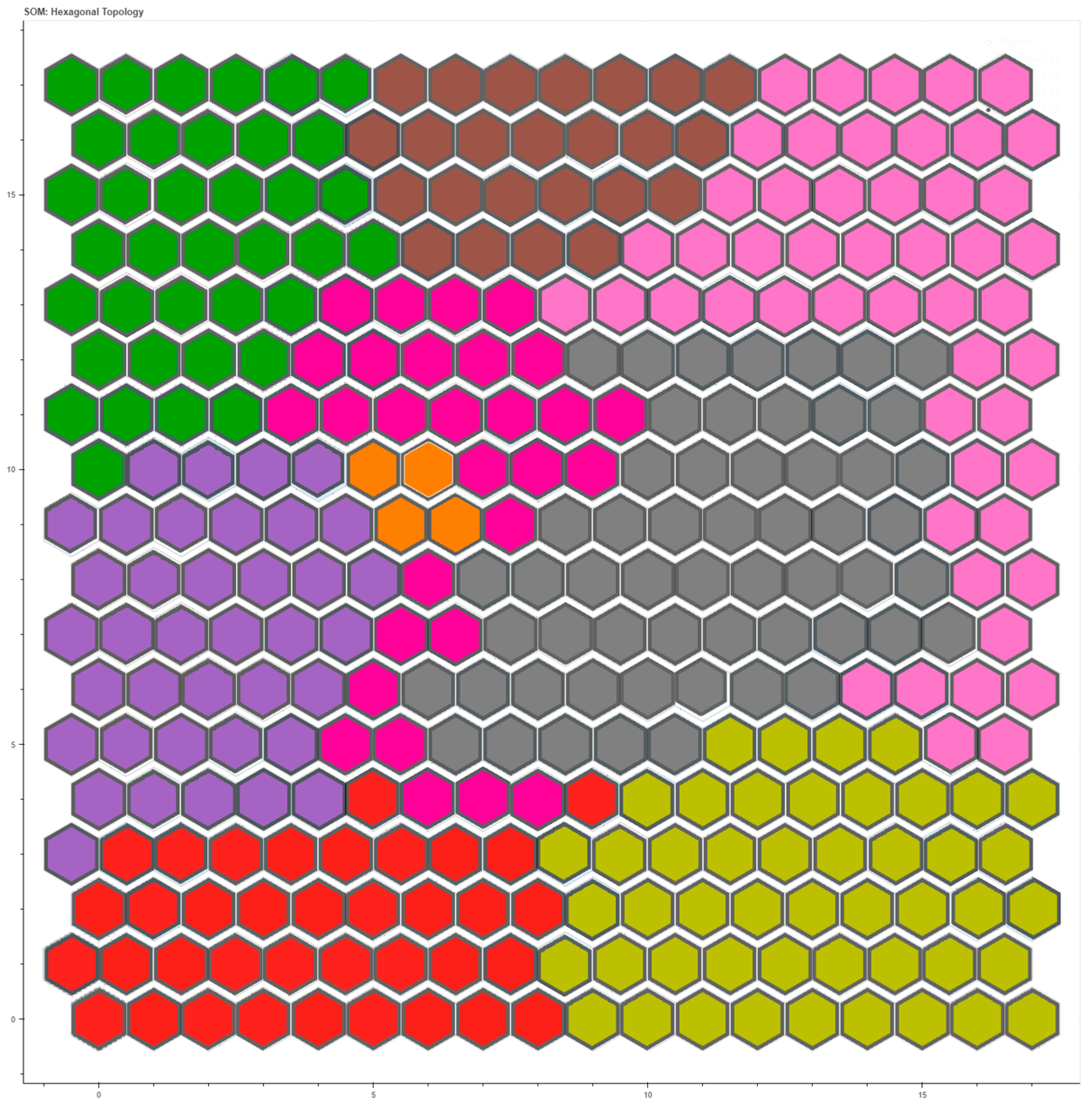
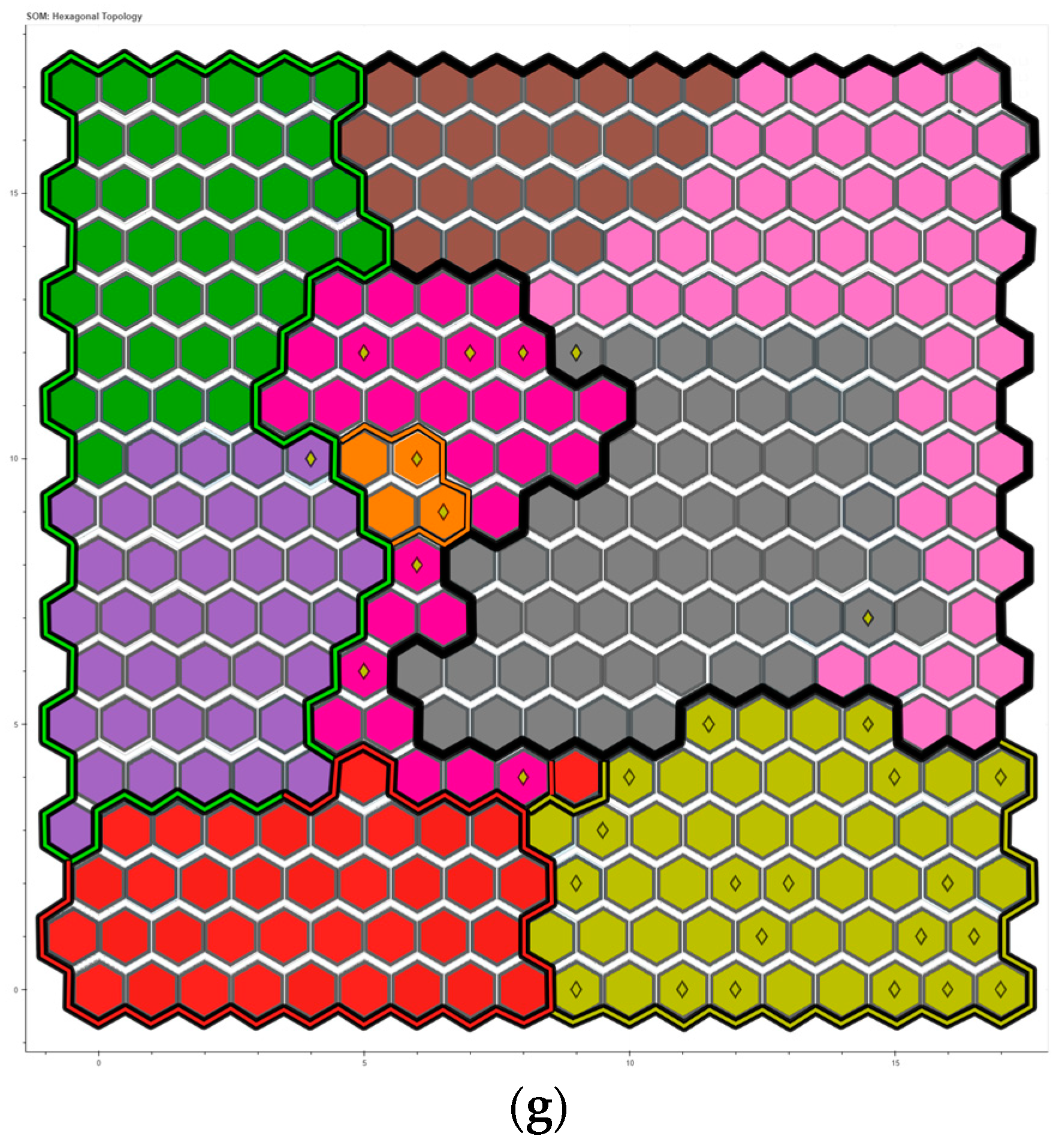
4.4. Output Map
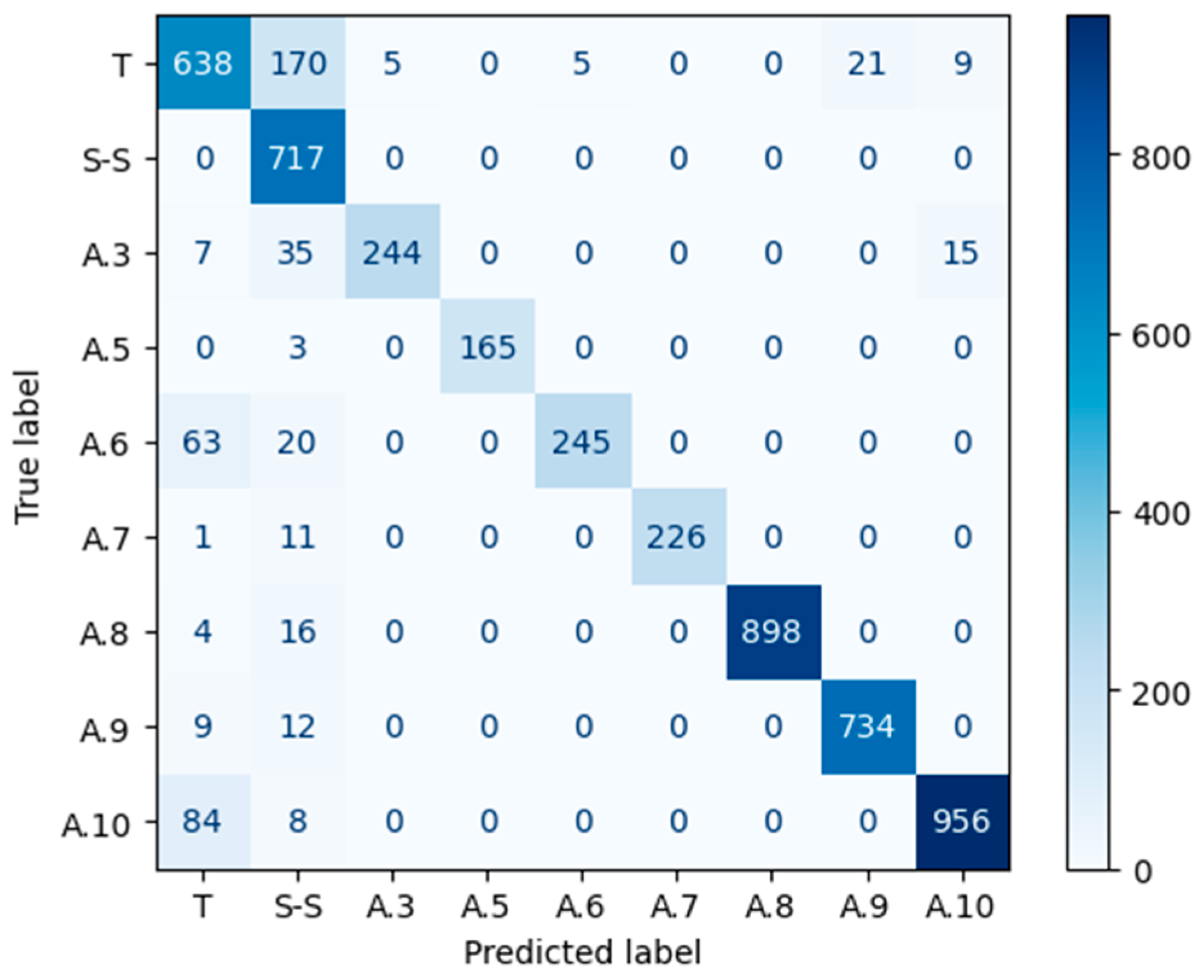
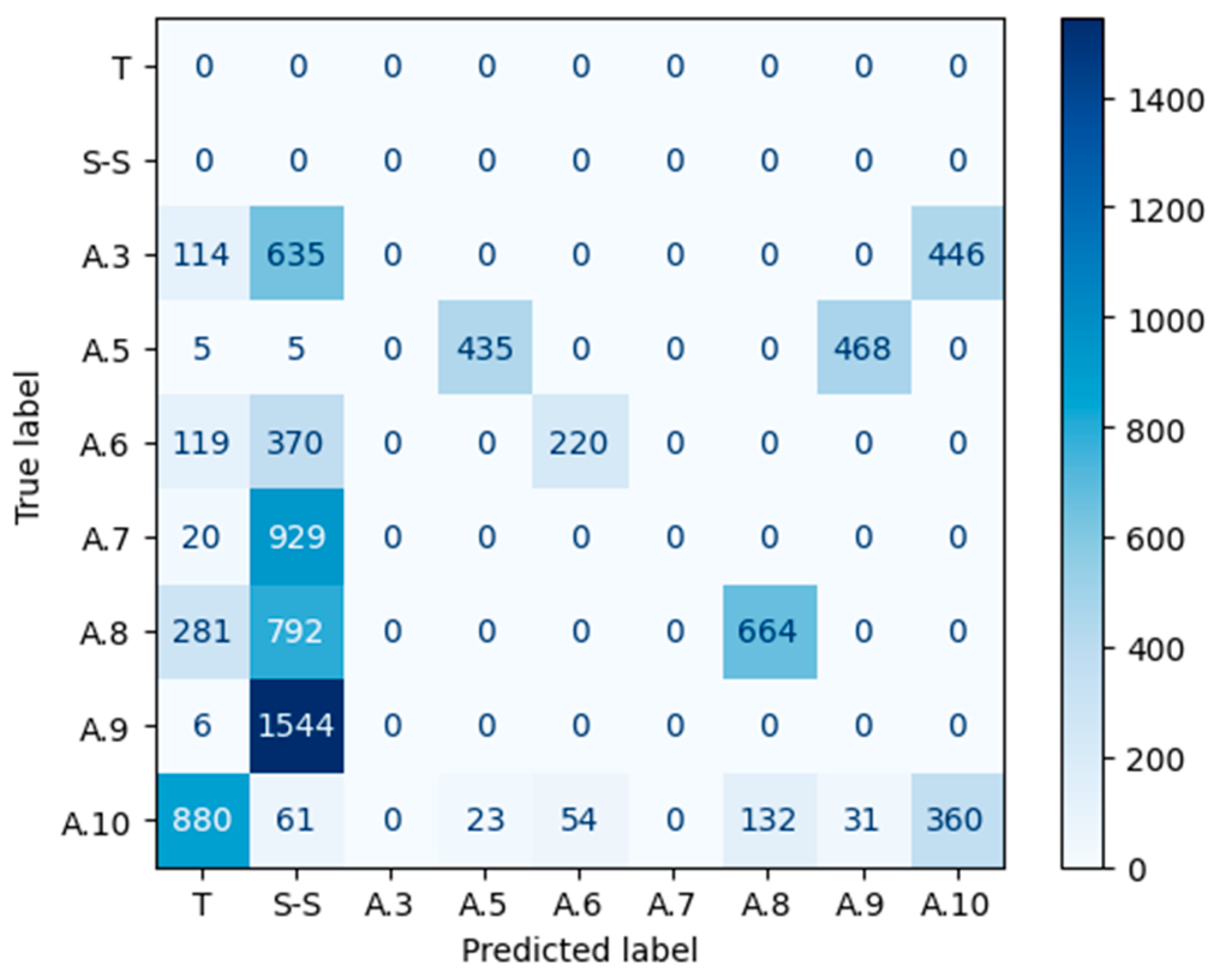
4.5. Input Data Confusion Matrix
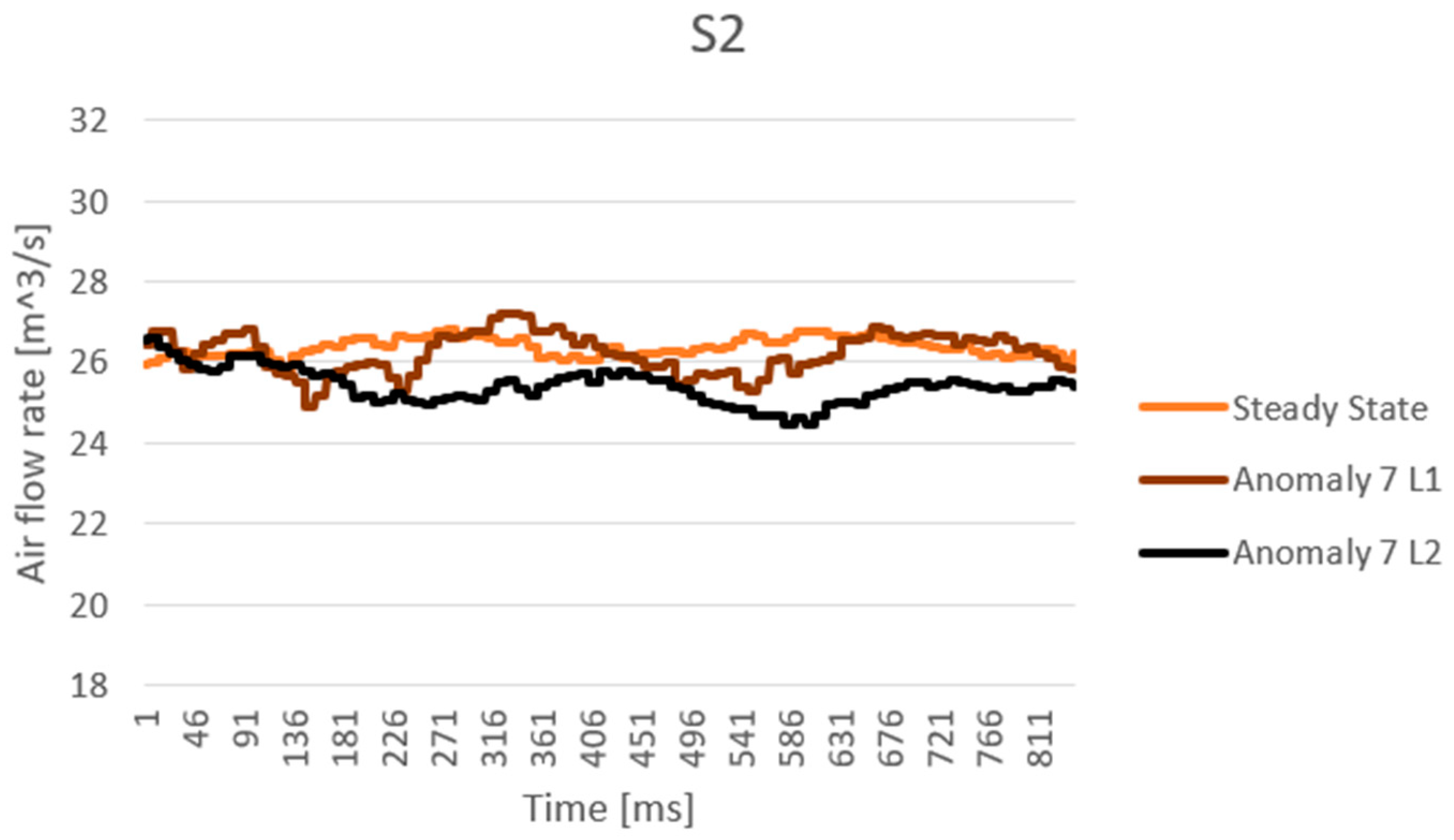
4.6. The Algorithm Evaluation
4.7. Summary
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barari, A.; Tsuzuki, M.S.G. Smart Manufacturing and Industry 4.0. Appl. Sci. 2023, 13, 1545. [Google Scholar] [CrossRef]
- Iamsumang, C.; Mosleh, A.; Modarres, M. Monitoring and learning algorithms for dynamic hybrid Bayesian network in on-line system health management applications. Reliab. Eng. Syst. Saf. 2018, 178, 118–129. [Google Scholar] [CrossRef]
- Di Carlo, F.; Mazzuto, G.; Bevilacqua, M.; Ciarapica, F. Retrofitting a Process Plant in an Industry 4.0 Perspective for Improving Safety and Maintenance Performance. Sustainability 2021, 13, 646. [Google Scholar] [CrossRef]
- Tiddens, W.; Braaksma, J.; Tinga, T. Decision Framework for Predictive Maintenance Method Selection. Appl. Sci. 2023, 13, 2021. [Google Scholar] [CrossRef]
- Mazzuto, G.; Antomarioni, S.; Ciarapica, F.E.; Bevilacqua, M. Health Indicator for Predictive Maintenance Based on Fuzzy Cognitive Maps, Grey Wolf, and K-Nearest Neighbors Algorithms. Math. Probl. Eng. 2021, 2021, 8832011. [Google Scholar] [CrossRef]
- Converso, G.; Gallo, M.; Murino, T.; Vespoli, S. Predicting Failure Probability in Industry 4.0 Production Systems: A Workload-Based Prognostic Model for Maintenance Planning. Appl. Sci. 2023, 13, 1938. [Google Scholar] [CrossRef]
- Zornio, P.; Boudreaux, M. Case Study: How Digital Transformation Paved the Way for One Refinery’s Predictive Maintenance Strategy. In Proceedings of the Offshore Technology Conference, Houston, TX, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Lian, Y.; Geng, Y.; Tian, T. Anomaly Detection Method for Multivariate Time Series Data of Oil and Gas Stations Based on Digital Twin and MTAD-GAN. Appl. Sci. 2023, 13, 1891. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Ciarapica, F.E.; Mazzuto, G. A Fuzzy Cognitive Maps Tool for Developing a RBI&M Model. Qual. Reliab. Eng. Int. 2014, 32, 373–390. [Google Scholar] [CrossRef]
- Luo, R.; Sheng, B.; Lu, Y.; Huang, Y.; Fu, G.; Yin, X. Digital Twin Model Quality Optimization and Control Methods Based on Workflow Management. Appl. Sci. 2023, 13, 2884. [Google Scholar] [CrossRef]
- Huang, J.; Pham, D.T.; Wang, Y.; Qu, M.; Ji, C.; Su, S.; Xu, W.; Liu, Q.; Zhou, Z. A case study in human–robot collaboration in the disassembly of press-fitted components. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2019, 234, 654–664. [Google Scholar] [CrossRef]
- Wanasinghe, T.R.; Wroblewski, L.; Petersen, B.; Gosine, R.G.; James, L.A.; De Silva, O.; Mann, G.K.I.; Warrian, P.J. Digital twin for the oil and gas industry: Overview, research trends, opportunities, and challenges. IEEE Access 2020, 8, 104175–104197. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Bottani, E.; Ciarapica, F.E.; Costantino, F.; Di Donato, L.; Ferraro, A.; Mazzuto, G.; Monteriù, A.; Nardini, G.; Ortenzi, M.; et al. Digital Twin Reference Model Development to Prevent Operators’ Risk in Process Plants. Sustainability 2020, 12, 1088. [Google Scholar] [CrossRef]
- Pierdicca, R.; Prist, M.; Monteriù, A.; Frontoni, E.; Ciarapica, F.; Bevilacqua, M.; Mazzuto, G. Augmented Reality Smart Glasses in the Workplace: Safety and Security in the Fourth Industrial Revolution Era. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12243, pp. 231–247. [Google Scholar] [CrossRef]
- Chen, T.; Sampath, V.; May, M.C.; Shan, S.; Jorg, O.J.; Martín, J.J.A.; Stamer, F.; Fantoni, G.; Tosello, G.; Calaon, M. Machine Learning in Manufacturing towards Industry 4.0: From ‘For Now’ to ‘Four-Know’. Appl. Sci. 2023, 13, 1903. [Google Scholar] [CrossRef]
- Zunino, C.; Valenzano, A.; Obermaisser, R.; Petersen, S. Factory Communications at the Dawn of the Fourth Industrial Revolution. Comput. Stand. Interfaces 2020, 71, 103433. [Google Scholar] [CrossRef]
- Selvik, J.T.; Bellamy, L.J. Addressing human error when collecting failure cause information in the oil and gas industry: A review of ISO 14224:2016. Reliab. Eng. Syst. Saf. 2020, 194, 106418. [Google Scholar] [CrossRef]
- Pech, M.; Vrchota, J.; Bednář, J. Predictive Maintenance and Intelligent Sensors in Smart Factory: Review. Sensors 2021, 21, 1470. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, H.; Zhang, C.; Wang, L.; Han, J. Optimization analysis of structure parameters of steam ejector based on CFD and orthogonal test. Energy 2018, 151, 79–93. [Google Scholar] [CrossRef]
- Zio, E. Prognostics and Health Management (PHM): Where are we and where do we (need to) go in theory and practice. Reliab. Eng. Syst. Saf. 2022, 218, 108119. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Zhang, C.-Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Koroteev, D.; Tekic, Z. Artificial intelligence in oil and gas upstream: Trends, challenges, and scenarios for the future. Energy AI 2021, 3, 100041. [Google Scholar] [CrossRef]
- Li, H.; Yu, H.; Cao, N.; Tian, H.; Cheng, S. Applications of Artificial Intelligence in Oil and Gas Development. Arch. Comput. Methods Eng. 2021, 28, 937–949. [Google Scholar] [CrossRef]
- Mazzuto, G.; Antomarioni, S.; Marcucci, G.; Ciarapica, F.E.; Bevilacqua, M. Learning-by-Doing Safety and Maintenance Practices: A Pilot Course. Sustainability 2022, 14, 9635. [Google Scholar] [CrossRef]
- Redutskiy, Y.; Camitz-Leidland, C.M.; Vysochyna, A.; Anderson, K.T.; Balycheva, M. Safety systems for the oil and gas industrial facilities: Design, maintenance policy choice, and crew scheduling. Reliab. Eng. Syst. Saf. 2021, 210, 107545. [Google Scholar] [CrossRef]
- Mohammed, A. Data driven-based model for predicting pump failures in the oil and gas industry. Eng. Fail. Anal. 2023, 145, 107019. [Google Scholar] [CrossRef]
- Naseri, M.; Baraldi, P.; Compare, M.; Zio, E. Availability assessment of oil and gas processing plants operating under dynamic Arctic weather conditions. Reliab. Eng. Syst. Saf. 2016, 152, 66–82. [Google Scholar] [CrossRef]
- Antomarioni, S.; Ciarapica, F.E.; Bevilacqua, M. Association rules and social network analysis for supporting failure mode effects and criticality analysis: Framework development and insights from an onshore platform. Saf. Sci. 2022, 150, 105711. [Google Scholar] [CrossRef]
- Quatrini, E.; Costantino, F.; Di Gravio, G.; Patriarca, R. Machine learning for anomaly detection and process phase classification to improve safety and maintenance activities. J. Manuf. Syst. 2020, 56, 117–132. [Google Scholar] [CrossRef]
- Zainuddin, Z.E.; Akhir, A.P.; Hasan, M.H. Predicting machine failure using recurrent neural network-gated recurrent unit (RNN-GRU) through time series data. Bull. Electr. Eng. Inform. 2021, 10, 870–878. [Google Scholar] [CrossRef]
- Wang, H.; Chen, S. Insights into the Application of Machine Learning in Reservoir Engineering: Current Developments and Future Trends. Energies 2023, 16, 1392. [Google Scholar] [CrossRef]
- Choubey, S.; Karmakar, G.P. Artificial intelligence techniques and their application in oil and gas industry. Artif. Intell. Rev. 2021, 54, 3665–3683. [Google Scholar] [CrossRef]
- Gupta, D.; Shah, M. A comprehensive study on artificial intelligence in oil and gas sector. Environ. Sci. Pollut. Res. 2022, 29, 50984–50997. [Google Scholar] [CrossRef] [PubMed]
- Aljameel, S.S.; Alomari, D.M.; Alismail, S.; Khawaher, F.; Alkhudhair, A.A.; Aljubran, F.; Alzannan, R.M. An Anomaly Detection Model for Oil and Gas Pipelines Using Machine Learning. Computation 2022, 10, 138. [Google Scholar] [CrossRef]
- Mazzuto, G.; Ciarapica, F.E.; Ortenzi, M.; Bevilacqua, M. The Digital Twin Realization of an Ejector for Multiphase Flows. Energies 2021, 14, 5533. [Google Scholar] [CrossRef]
- Barbariol, T.; Feltresi, E.; Susto, G.A. Machine Learning approaches for Anomaly Detection in Multiphase Flow Meters. IFAC-PapersOnLine 2019, 52, 212–217. [Google Scholar] [CrossRef]
- Mohammed, A.S.; Anthi, E.; Rana, O.; Saxena, N.; Burnap, P. Detection and mitigation of field flooding attacks on oil and gas critical infrastructure communication. Comput. Secur. 2023, 124, 103007. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Khoei, T.T.; Kaabouch, N. A Comparative Analysis of Supervised and Unsupervised Models for Detecting Attacks on the Intrusion Detection Systems. Information 2023, 14, 103. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Natita, W.; Wiboonsak, W.; Dusadee, S. Appropriate Learning Rate and Neighborhood Function of Self-organizing Map (SOM) for Specific Humidity Pattern Classification over Southern Thailand. Int. J. Model. Optim. 2016, 6, 61–65. [Google Scholar] [CrossRef]
- Reutterer, T.; Natter, M. Segmentation-based competitive analysis with MULTICLUS and topology representing networks. Comput. Oper. Res. 2000, 27, 1227–1247. [Google Scholar] [CrossRef]
- Hoomod, H.K.; Al-Mejibli, I.; Jabboory, A.I. Efficient Neighborhood Function and Learning Rate of Self-Organizing Map (SOM) for Cell Towers Traffic Clustering. J. Al-Qadisiyah Comput. Sci. Math. 2017, 9, 122–130. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.L.; Bischl, B. Tunability: Importance of Hyperparameters of Machine Learning Algorithms. arXiv 2018, arXiv:1802.09596. Available online: http://arxiv.org/abs/1802.09596 (accessed on 14 March 2023).
- Bassi, D.; Singh, H. A Comparative Study on Hyperparameter Optimization Methods in Software Vulnerability Prediction. In Proceedings of the 2nd International Conference on Computational Methods in Science & Technology (ICCMST), Mohali, India, 17–18 December 2021. [Google Scholar] [CrossRef]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A Python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]
- Pölzlbauer, G. Survey and Comparison of Quality Measures for Self-Organizing Maps. In Proceedings of the Fifth Workshop on Data Analysis, Vysoké Tatry, Slovakia, 24–27 June 2004; Elfa Academic Press: Vysoké Tatry, Slovakia, 2004; pp. 67–82. [Google Scholar]
- Dresp-Langley, B.; Wandeto, J. Human Symmetry Uncertainty Detected by a Self-Organizing Neural Network Map. Symmetry 2021, 13, 299. [Google Scholar] [CrossRef]
- Arockiam, A.J.M.S.; Irudhayaraj, E.S. Reclust: An efficient clustering algorithm for mixed data based on reclustering and cluster validation. Indones. J. Electr. Eng. Comput. Sci. 2022, 29, 545–552. [Google Scholar] [CrossRef]
- Jaiswal, A.; Kumar, R. Stochastic Self-Organizing Map and Proposed Enlarge C4.5 to Diagnose Breast Cancer. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering, ICACITE, Greater Noida, India, 28–29 April 2022; pp. 582–587. [Google Scholar] [CrossRef]
- Kulkarni, A.; Chong, D.; Batarseh, F.A. Foundations of data imbalance and solutions for a data democracy. In Data Democracy: At the Nexus of Artificial Intelligence, Software Development, and Knowledge Engineering; Academic Press: Cambridge, MA, USA, 2020; pp. 83–106. [Google Scholar] [CrossRef]
- Gustafsson, J.; Sandin, F. District heating monitoring and control systems. In Advanced District Heating and Cooling (DHC) Systems; Woodhead Publishing: Sawston, UK, 2015; pp. 241–258. [Google Scholar] [CrossRef]
- Amitrano, D.; Di Martino, G.; Iodice, A.; Riccio, D.; Ruello, G. Urban Area Mapping Using Multitemporal SAR Images in Combination with Self-Organizing Map Clustering and Object-Based Image Analysis. Remote Sens. 2022, 15, 122. [Google Scholar] [CrossRef]
- Wang, C. Efficient customer segmentation in digital marketing using deep learning with swarm intelligence approach. Inf. Process. Manag. 2022, 59, 103085. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keyword | # of Papers | # of Relevant Papers |
|---|---|---|
| “oil and gas sector” AND “machine learning” | 11 | 3 |
| “ onshore platform” AND “ machine learning” | 1 | 1 |
| “oil and gas sector” AND “anomaly detection” | 11 | 8 |
| “oil and gas sector” AND “artificial intelligence” | 4 | 1 |
| “oil and gas sector” AND “digital twin” | 2 | 1 |
| “multiphase flow” AND “digital twin” | 6 | 1 |
| “oil and gas sector” AND “Internet of Things” | 5 | - |
| “oil and gas sector” AND “artificial neural network” | 4 | 1 |
| “oil and gas sector” AND “Self-Organizing Map” | 1 | - |
| ID | Description | UM | Type | Tag |
|---|---|---|---|---|
| S1 | Inlet water pressure | [bar] | OUTPUT | Endress+Hauser Cerabar M PMP51 |
| S2 | Inlet water flow rate | [m3/h] | OUTPUT | Endress+Hauser Promag W |
| S3 | Ejector pressure | [bar] | OUTPUT | Setra 280E |
| S4 | Diffuser mixture pressure | [bar] | OUTPUT | Foxboro 841GM CI1 |
| S5 | Tank pressure | [bar] | OUTPUT | Foxboro 841GM-CI1 |
| S6 | Inlet air flow rate | [m3/h] | OUTPUT | Foxboro Vortez DN 50 |
| S7 | Tank water level | [mm] | OUTPUT | Foxboro IDP-10 |
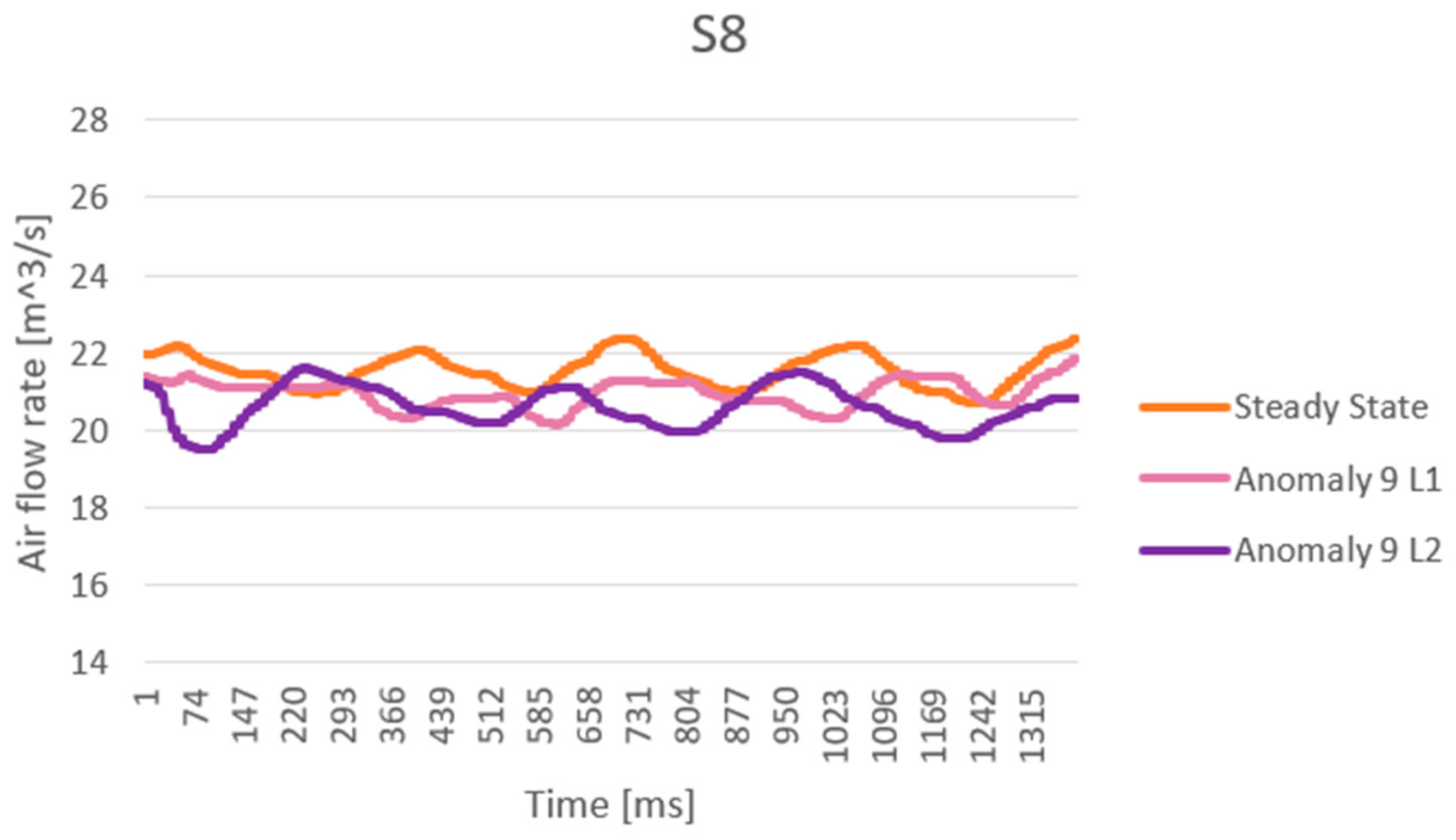
| S8 | Outlet air flow rate | [m3/h] | OUTPUT | Endress+Hauser Prowirl 200 |
| V1 | Valve 1 closure | [%] | INPUT | Spirax Sarco 9126E Pneumatic Valve |
| V2 | Valve 2 closure | [%] | INPUT | ECKARDT MB6713 Pneumatic Valve |
| V3 | Valve 3 closure | [%] | INPUT | ECKARDT MB6713 Pneumatic Valve |
| Test ID | Description |
|---|---|
| V10L1 | It describes a minor tank water leakage obtained since closing the valve VM10 by 30% |
| V10L2 | It describes a medium tank water leakage obtained since closing the valve VM10 by 60% |
| V10L3 | It describes a grave tank water leakage obtained since closing the valve VM10 by 100% |
| V3L1 | It describes a minor obstruction in the water inlet piping system obtained since closing the valve VM3 by 30% |
| V3L2 | It describes a medium obstruction in the water inlet piping system obtained since closing the valve VM3 by 60% |
| V3L3 | It describes a grave obstruction in the water inlet piping system obtained since closing the valve VM3 by 100% |
| V5L1 | It describes a minor obstruction in the mixture inlet piping system obtained since closing the valve VM5 by 30% |
| V5L2 | It describes a medium obstruction in the mixture inlet piping system obtained since closing the valve VM5 by 60% |
| V5L3 | It describes a grave obstruction in the mixture inlet piping system obtained since closing the valve VM5 by 100% |
| V6L1 | It describes a minor obstruction in the water outlet piping system obtained since closing the valve VM6 by 30% |
| V6L2 | It describes a medium obstruction in the water outlet piping system obtained since closing the valve VM6 by 60% |
| V6L3 | It describes a grave obstruction in the water outlet piping system obtained since closing the valve VM6 by 100% |
| V7L1 | It describes a minor obstruction in the air inlet piping system obtained since closing the valve VM7 by 30% |
| V7L2 | It describes a medium obstruction in the air inlet piping system obtained since closing the valve VM7 by 60% |
| V7L3 | It describes a grave obstruction in the air inlet piping system obtained since closing the valve VM7 by 100% |
| V8L1 | It describes a minor air leakage in the tank obtained since closing the valve VM8 by 30% |
| V8L2 | It describes a medium air leakage in the tank obtained since closing the valve VM8 by 60% |
| V8L3 | It describes a grave air leakage in the tank obtained since closing the valve VM8 by 100% |
| V9L1 | It describes a minor obstruction in the air outlet piping system obtained since closing the valve VM9 by 30% |
| V9L2 | It describes a medium obstruction in the air outlet piping system obtained since closing the valve VM9 by 60% |
| V9L3 | It describes a grave obstruction in the air outlet piping system obtained since closing the valve VM9 by 100% |
| System State | Type of Anomaly | Tag | Colour |
|---|---|---|---|
| Transient of steady state | / | Hex | Fuchsia |
| Steady state | / | Asterisk | Orange |
| Anomaly 3 L3 | Water | Dot | Green |
| Anomaly 5 L3 | Air-water | Dot | Red |
| Anomaly 6 L3 | Water | Dot | Purple |
| Anomaly 7 L3 | Air | Dot | Brown |
| Anomaly 8 L3 | Air | Cross | Pink |
| Anomaly 9 L3 | Air | Line | Gray |
| Anomaly 10 L3 | Tank | Rhombus | Yellow |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Transient of Steady State | 0.79 | 0.75 | 0.77 | 848 |
| Steady State | 0.72 | 1.00 | 0.84 | 717 |
| Anomaly 3 | 0.98 | 0.81 | 0.89 | 301 |
| Anomaly 5 | 1.00 | 0.98 | 0.99 | 168 |
| Anomaly 6 | 0.98 | 0.75 | 0.85 | 328 |
| Anomaly 7 | 1.00 | 0.95 | 0.97 | 238 |
| Anomaly 8 | 1.00 | 0.98 | 0.99 | 918 |
| Anomaly 9 | 0.97 | 0.97 | 0.97 | 755 |
| Anomaly 10 | 0.98 | 0.91 | 0.94 | 1048 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Anomaly 3 | 0.00 | 0.00 | 0.00 | 1195 |
| Anomaly 5 | 0.95 | 0.48 | 0.63 | 913 |
| Anomaly 6 | 0.80 | 0.31 | 0.45 | 709 |
| Anomaly 7 | 0.00 | 0.00 | 0.00 | 949 |
| Anomaly 8 | 0.83 | 0.38 | 0.52 | 1737 |
| Anomaly 9 | 0.00 | 0.00 | 0.00 | 1550 |
| Anomaly 10 | 0.48 | 0.23 | 0.31 | 1541 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Concetti, L.; Mazzuto, G.; Ciarapica, F.E.; Bevilacqua, M. An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector. Appl. Sci. 2023, 13, 3725. https://doi.org/10.3390/app13063725
Concetti L, Mazzuto G, Ciarapica FE, Bevilacqua M. An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector. Applied Sciences. 2023; 13(6):3725. https://doi.org/10.3390/app13063725
Chicago/Turabian StyleConcetti, Lorenzo, Giovanni Mazzuto, Filippo Emanuele Ciarapica, and Maurizio Bevilacqua. 2023. "An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector" Applied Sciences 13, no. 6: 3725. https://doi.org/10.3390/app13063725
APA StyleConcetti, L., Mazzuto, G., Ciarapica, F. E., & Bevilacqua, M. (2023). An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector. Applied Sciences, 13(6), 3725. https://doi.org/10.3390/app13063725