Abstract
Researchers are studying CNN (convolutional neural networks) in various ways for image classification. Sometimes, they must classify two or more objects in an image into different situations according to their location. We developed a new learning method that colored objects from images and extracted them to distinguish the relationship between objects with different colors. We can apply this method in certain situations, such as pedestrians in a crosswalk. This paper presents a method for learning pedestrian situations on CNN using Mask R-CNN (Region-based CNN) and CDA (Crosswalk Detection Algorithm). With this method, we classified the location of the pedestrians into two situations: safety and danger. We organized the process of preprocessing and learning images into three stages. In Stage 1, we used Mask R-CNN to detect pedestrians. In Stage 2, we detected crosswalks with the CDA and placed colors on detected objects. In Stage 3, we combined crosswalks and pedestrian objects into one image and then, learned the image to CNN. We trained ResNet50 and Xception using images in the proposed method and evaluated the accuracy of the results. When tested experimentally, ResNet50 exhibited 96.7% accuracy and Xception showed 98.7% accuracy. We then created an image that simplified the situation with two colored boxes of crosswalks and pedestrians. We confirmed that the learned CNN with the images of colored boxes could classify the same test images applied in the previous experiment with 96% accuracy by ResNet50. This result indicates that the proposed system is suitable for classifying pedestrian safety and dangerous situations by accurately dividing the positions of the two objects.
1. Introduction
Researchers initially used CNN [1] to classify objects in images. Later, they found a way to differentiate and detect each object in the image. In addition, they conducted their studies on object relationships or situation recognition between detected objects. Our research aimed to perform situation recognition between objects by detecting pedestrians and crosswalk objects in images, respectively. Through deep learning training, our system can distinguish whether a pedestrian in a crosswalk is safe from the driver’s point of view. Many researchers studied object detection and object relationships. Hu et al. [2] devised the object relationship module using original and geometric weights to understand the dependence between objects for object detection [3]. Redmon et al. [4,5] used YOLO (You Only Live Once) for object detection. Yatskar et al. [6] suggested extracting objects and labeling visual semantic roles in the image using VGG (Visual Geometry Group) for situation recognition. Dai et al. [7] developed a system for situation recognition in the image that applied the object detection stage using Fast R-CNN and a mutual recognition stage combining the pair filtering system for a subject feature and DR-Net. Li et al. [8] proposed GNN (Graphic Neural Network) that predicted the relationship between objects in images. They achieved this by analyzing the objects in the image on a graph. Furthermore, Shi et al. [9] recently suggested a new gait recognition system with a deep learning network. They used multimodal inertial sensors for their system.
Díaz-Cely et al. [10], Bianco et al. [11], and Geirhos et al. [12] proposed that color was an essential factor in CNN learning. Therefore, we devised a new method to color objects extracted from the image to distinguish the relationship between two objects of different colors. After learning the objects’ colors, we demonstrated that our new method accurately classified the relationship between the objects. Therefore, we aimed to classify the location of the pedestrian on the crosswalk with the method. We trained CNN by extracting the image’s crosswalks and pedestrians in different colors. We classified the pedestrian as safe when their feet were inside the crosswalk but dangerous outside. When tested experimentally, these learned CNN could accurately classify test images.
For the safety of pedestrians, it is critical to determine whether a pedestrian is walking inside or outside the crosswalk area. According to the National Highway Traffic Safety Administration of the U.S.A. [13], among the different types of traffic accidents, there are many fatal ones involving pedestrians at crosswalks. We detected a pedestrian on the crosswalk using Mask R-CNN [14]. We then developed and applied the CDA to detect crosswalks. We colored pedestrians extracted in red and crosswalks in black. Among CNNs [15,16,17,18,19], we trained Xception [18] and ResNet50 [19] using the image data created in colors. Through experiments, we achieved 96–98% accuracy in classifying whether the test data were safe or dangerous with learned CNN. The contributions of this paper are as follows:
Firstly, we proposed a CNN-based crosswalk-pedestrian situation recognition system that detects crosswalks and pedestrians in images and determines whether people are safe or in danger, depending on their location. We present further details of the method in Section 3.
Secondly, we developed and applied the CDA to the system to detect crosswalks in images. We provide further details of the algorithm in Section 3.2.
Thirdly, we created colored simple box shapes and used them for CNN learning. The experiment showed little difference in accuracy between actual field photo images and simplified boxes. We expect that somebody can prepare training datasets with efficient time and economic cost to train CNN. We present further details about simple box shapes in Section 4.2.
2. Related Works
The first object detection network using deep learning was the R-CNN [20], announced in 2014. Object detection since developed into networks such as Fast R-CNN [21] and Faster R-CNN [22]. Mask R-CNN is a network that adds a fully convolutional network (FCN) based on Faster R-CNN. It consists of two stages, and the first is the region proposal network (RPN) which is a stage for extracting the object’s location. The second stage is a parallel prediction of the binary mask, box offset, and class for each region of instance (RoI). Mask R-CNN added an FCN to the Faster R-CNN and applied FCN to the RoI extracted by the RPN. Therefore, it became possible to predict an M*M-sized mask without losing information. Faster R-CNN cannot split instances on a pixel basis, whereas Mask R-CNN does so. Furthermore, Mask R-CNN is capable of efficient computation, surpassing the performance of existing state-of-the-art (SOTA) networks.
Larson et al. [23] proposed and evaluated a dynamic passive pedestrian detection system (DPPD) over crosswalks using optical and thermal sensors. Their image analysis system with sensors determined the pedestrian’s location in real time. Consequentially, an average accuracy of 89% and a standard deviation of 10% were exhibited in determining the location of pedestrians using thermal sensors. In addition, 82% average accuracy and a standard deviation of 8% were exhibited in establishing the location of pedestrians using optical sensors. Their system can also detect atypical pedestrians. This expression refers to unstructured pedestrians, such as pedestrians pulling strollers and those using umbrellas. Thus, Larson et al. enabled further system improvement by creating and evaluating two new systems.
In 2020, Zhang et al. [24] proposed a system for judging pedestrian traffic laws. They used the LSTM (Long Short Term Memory) neural network to predict pedestrian behavior. In their paper, the situation of the crosswalk was judged by predicting the pedestrian’s behavior when a red light was displayed. They used nine characteristics, such as gender, walking direction, group behavior, etc. Their proposed system applied deep learning to predict pedestrians’ unexpected behavior on crosswalks, consequentially exhibiting 91.6% accuracy. Their system allows for the prevention of collisions between pedestrians and vehicles on crosswalks.
Other works that detect pedestrians include studies by Prioletti et al. [25], Hariyono et al. [26], Hariyono and Jo [27], Keller and Gavrila [28], and Keller et al. [29]. Prioletti et al.’s system distinguished whether pedestrians were on the road using the cascade classifier and histogram-of-oriented-gradient (HOG). Hariyono and Jo developed an algorithm that extracted edges by Hough line detection and color-based extraction, recognized crosswalks, and detected whether there were pedestrians in crosswalk areas using three classifiers. However, they did not apply deep learning in their system. Furthermore, Dow et al. [30] applied YOLO to detect pedestrians, and Zhang et al. [31] used YOLOv5 for crosswalk detection. Using Mask R-CNN, Malbog [32] suggested pedestrian crosswalk detection. However, Malbog did not investigate the relationship between pedestrians and crosswalks. Thus far, the research focused on simple image analysis or prediction of pedestrians’ positions within the crosswalk using devices such as thermal and optical sensors.
Additionally, detection using YOLO has the disadvantage of not accurately representing the locations of pedestrians and crosswalks in pixels. Thus, we tested a new method using Mask R-CNN and the CDA. Our trained CNN enabled us to classify danger and safety based on the location of pedestrians and crosswalks.
Table 1 compares previous studies on crosswalk pedestrian situation recognition with our study on five items and shows actual detected sample images: accuracy of detecting a pedestrian and a crosswalk, use of deep learning, detect crosswalk, the sight of the car driver, method of detecting crosswalk. Our system showed the highest accuracy and satisfied all other items, showing superior results to the systems presented in previous research. When we tried to detect the crosswalk with YOLO, we did not make an exact crosswalk shape but only a simple box shape. Additionally, with Mask R-CNN, we cannot satisfy detecting crosswalks when crosslines are invisible according to the road condition. So, we developed our CDA, which can draw the crosswalk shape even if some parts of zebra cross lines are erased.

Table 1.
Comparison of our system to others; Accuracy and CDA.
3. Proposed Method
Figure 1 depicts our proposed overall process. Our system consists of three stages. Stage 1 uses Mask R-CNN to detect and extract pedestrians in the original images in red. Stage 2 uses the CDA to detect and extract crosswalks in original images in black. In Stage 3, we train CNN using training images that combine the images created in stages 1 and 2. We trained pedestrian situations with safety (in) when a person walked inside a crosswalk and danger (out) when walking outside. Subsequently, we evaluated the performance with test images different from the training images used for trained CNN. We created the test images in the same process as the training images through stages 1, 2, and 3.
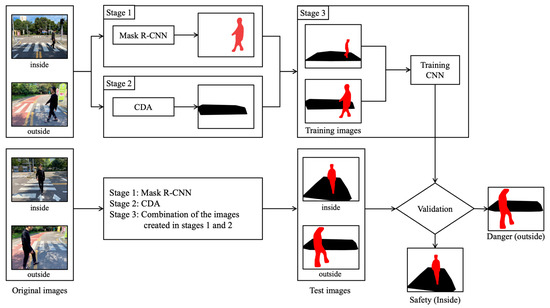
Figure 1.
Overall process: CNN-based crosswalk-pedestrian situation recognition system using Mask-R-CNN.
3.1. Stage 1: Pedestrian Detection Using Mask R-CNN
Mask R-CNN is a segmentation model that localizes objects in pixel units. It uses RoIAlign to distinguish objects in pixels in an image. The RoIAlign technique prevents the loss of object location information and allows accurate feature maps. Figure 2 describes the Mask R-CNN framework, for instance, segmentation. Bakr et al. [33] showed that Mask R-CNN could distinguish an object’s shadow from an object with 98.09% accuracy.
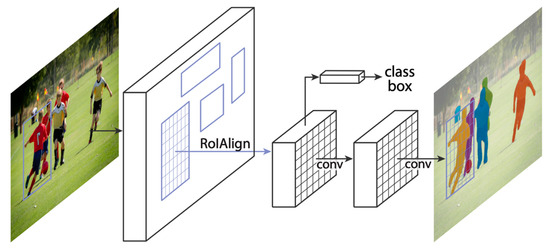
Figure 2.
The Mask R-CNN framework for instance segmentation [14].
Figure 3 presents the process of Stage 1, which uses Mask R-CNN to detect pedestrians in original images. We extracted the masks of pedestrians detected by Mask R-CNN in red. We used Mask R-CNN because it can extract pedestrian objects on a pixel basis from the images. Additionally, selected pedestrian pixels were colored in red uniformly to learn CNN.
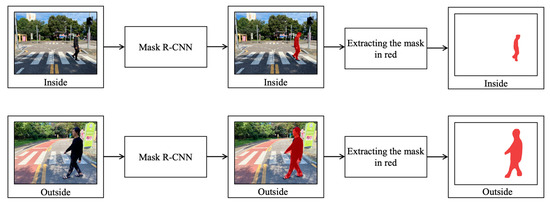
Figure 3.
Detecting a pedestrian using Mask R-CNN.
3.2. Stage 2: Crosswalk Detection Using the Crosswalk Detection Algorithm (CDA)
Figure 4 depicts the process of Stage 2, which uses the CDA to detect crosswalks in original images. Usually, the area of crosswalks is colored white, and several white rectangles are drawn on the road. So, first, the images are made to be black and white. If the white area is more than the specific size pixels, it would be a part of the crosswalk image. Additionally, the CDA draws polylines and connects all crosswalk parts. Finally, we extract the crosswalk area detected by the CDA in black. The color of the crosswalk area is designated uniformly to learn CNN.
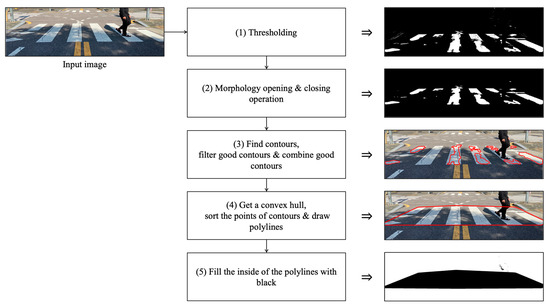
Figure 4.
Detecting a crosswalk using the crosswalk detection algorithm (CDA).
Algorithm 1 presents the CDA, the process of which is as follows:
- (1)
- Thresholding: make the white crosswalk visible by making it clear what is white and what is not;
- (2)
- Morphology opening and closing operation: reduce noise by erosion and expansion in areas other than crosswalks. Make the crosswalk area clear;
- (3)
- Find contours, filter good contours, and combine good contours: obtain crosswalk contours and extract multiple contents from one image. If the content is larger than a pixel area (e.g.,170, pixels) of a specific size, it is judged by the crosswalk image. Combine the values of the good contours array;
- (4)
- Obtain a convex hull, sort the points of contours and draw polylines: convex hull function combines the good contour image with the original image to make a small square into an entire large square. Sort the points of contours combined by x-coordinate (in case of a tie, sort by y-coordinate). Draw polylines in red;
- (5)
- Fill the inside of the polylines with black.
| Algorithm 1: The Crosswalk Detection Algorithm (CDA) |
| Input: Original Image (β1…βw), #w is the number of pixels in the crosswalk image. Output: Extracted Image M; #Full image of the crosswalk area 01: # (1) Thresholding 02: for j ← 1 to w do { 03: If βj > RGB (255,255,255) then βj = RGB (255,255,255) 04: Else if βj < RGB (125,125,125) then βj = RGB (0,0,0). 05: } 06: # (2) Morphology opening & closing operation 07: β ← erode & dilate (β) 08: # Morphology Closing 09: β ← dilate & erode (β) 10: # (3) Find contours, filter good contours & combine good contours 11: contours ← FindContours (β) 12: goodContours ← Empty list 13:# Filter good contours: larger than a pixel area (170 pixels) of a certain size 14: for i ← 1 to contours do { 15: area ← contourArea(contoursi) 16: if area > 170 then { 17: drawContours (β,contoursi) 18: goodContours.append (contoursi). 19: } 20: } 21: # Combine good contours: combine the values of the good contours array. 22: contoursCombined ← Combine (goodContours) 23: # (4) Get convex hull, sort & draw polylines 24: convexhull (contoursCombined) 25: Sort (contoursCombined). # Sort the points of contours combined by x-coordinate 26: U ← Empty list 27: L ← Empty list 28: for i ← 1 to n do { 29: contoursCombined.append (Li) 30: } 31: for i ← n to 1 do { 32: contoursCombined.append (Ui) 33: } 34: M ← polylines (contoursCombined) # Draw polylines in red 35: # (5) Fill the inside of the polylines with black 36: M ← fillPoly (M) 37: return M |
3.3. Stage 3: Training Using CNN
Stage 3 combines the images created using Mask R-CNN and the CDA. When the image of the crosswalk overlaps with the image of the pedestrian, it must not invade this image. Subsequently, training images are applied to learn images of the pedestrian’s safe situation (inside) and the pedestrian’s dangerous situation (outside) on CNN. Finally, we confirmed the performance by creating different test images from the training images used to test the learned CNN.
4. Experiments
We performed experiments to test whether the proposed method recognized the situation of pedestrians on the crosswalk. Table 2 presents the experimental details. The dataset configuration consisted of safety (inside) and danger (outside). We constructed two pedestrian situations on the crosswalk into 510 cases. Regarding the number of datasets, there were 510 sheets for each of the original and processed images. From 510 sheets, we used 360 sheets as training images and 150 sheets as test images. The total number of box images for experiment II was 600 sheets. So, we used 600 box images as training data and 150 processed images of experiment I as the test data. We trained ResNet50 and Xception and tested them with our datasets on Google Colaboratory online environment. Their learning rate was 0.001 and training epochs were 100.
Table 2.
Experimental details for Training CNN; ResNet50 and Xception.
Figure 5 depicts the images of the datasets used. Figure 5a presents the original images, and Figure 5b shows the processed images created through the proposed method. Figure 5a,b images are training and test images of Experiment I. We displayed the training images of Experiment II in Figure 5c. We applied ResNet50 and Xception to training images in 100 epochs in a Google Colaboratory learning environment. The source of our dataset is available on GitHub [34].

Figure 5.
Three types of datasets of the experiments; (a) Original Images and (b) Processed Images applied for Experiment I, and (c) Box Images applied for Experiment II.
4.1. Experiment I
Figure 6 presents the result of training CNNs using the data of Figure 5a,b. Figure 6a depicts the case of Xception trained with the original images, which yielded a test accuracy of 68.8%. Figure 6b displays the case of ResNet50 trained with original images, which yielded a test accuracy of 70%. However, training CNNs with processed images resulted in a significant improvement in accuracy. Figure 6c presents the case of Xception trained with the processed image, which yielded an accuracy of 98.7%. Figure 6d displays the case of ResNet50 trained with the processed image, which yielded an accuracy of 96.7%. These results reveal that CNN can judge pedestrian situations when trained using our proposed method.
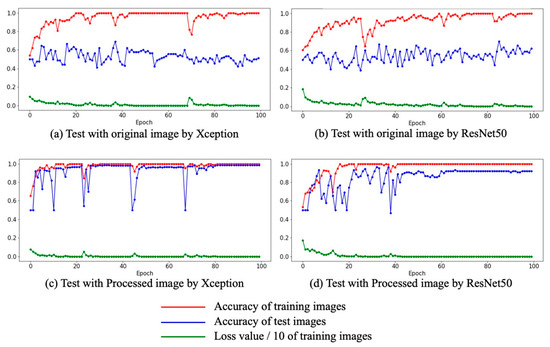
Figure 6.
Results of Experiment I: (a) training and testing with original images using Xception; (b) training and testing with original images using ResNet50; (c) training and testing with processed images using Xception; (d) training and testing with processed images using ResNet50.
4.2. Experiment II
We named the images of Figure 5c applied in the experiment as box images. Figure 7 presents the overall process of the proposed system using box images. These use color and box shapes to create the training images. Hence, the red box denotes a pedestrian and the black box indicates a crosswalk. In addition, the experimental environments were the same as in Experiment I.
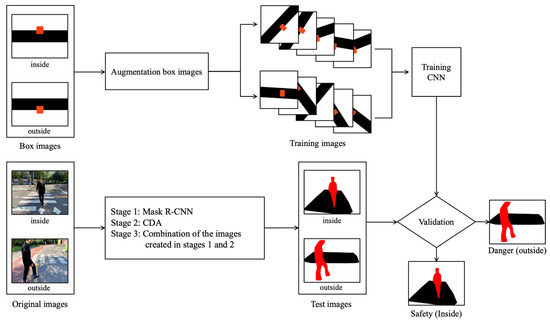
Figure 7.
Overall Process: CNN-based crosswalk-pedestrian situation recognition system using box images.
Figure 8 shows the result of training CNNs using the data of Figure 5c. Figure 8a depicts the case of Xception trained with box images which yielded a test accuracy of 94.5%. Figure 8b displays the case of ResNet50 trained with box images which yielded a test accuracy of 96%. Table 3 presents the accuracy (%) of experiments I & II tested by ResNet50 and Xception. These results reveal that learning CNNs with images created by coloring simple shapes is as accurate as the method used in Experiment I. There was just a 0.7 difference between the two experiments with ResNet50. If somebody can train an AI with box images for a specific purpose, as in our case, efficient time and economic cost are possible to prepare training datasets.
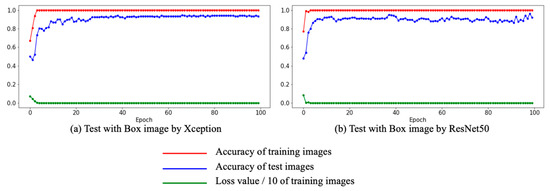
Figure 8.
Results of Experiment II: (a) train and test with box images using Xception; (b) train and test with box images using ResNet50.
Table 3.
Test accuracy (%) of Experiments I & II with ResNet50 and Xception.
5. Conclusions
In this paper, we processed images with Mask R-CNN and the CDA, a self-developed algorithm, and increased the accuracy in classifying whether pedestrians were safe or dangerous situations. We trained and tested the method on CNN using preprocessed images. We achieved 98.7% accuracy for Xception and 96.7% for ResNet50. Therefore, our proposed system is suitable for classifying pedestrian situations. Furthermore, we trained CNN with box images. This result achieved 94.5% accuracy for Xception and 96% for ResNet50 with the same test data. We expect that somebody can train CNN with efficient time and economic cost because they easily prepare box images as training data.
Author Contributions
Conceptualization, J.H. (Jinho Han); methodology, S.L.; investigation, J.H. (Jaemin Hwang); software, S.L. and J.H. (Jaemin Hwang).; CDA algorithm, J.K.; validation, J.H. (Jinho Han); formal analysis, S.L.; data curation, J.H. (Jaemin Hwang); writing, S.L.; review and editing, J.H. (Jinho Han); supervision, J.H. (Jinho Han). All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. arXiv 2019, arXiv:1809.02165. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242 394. [Google Scholar]
- Yatskar, M.; Zettlemoyer, L.; Farhadi, A. Situation Recognition: Visual Semantic Role Labeling for Image Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5534–5542. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting Visual Relationships with Deep Relational Networks. arXiv 2017, arXiv:1704.03114. [Google Scholar]
- Li, R.; Tapaswi, M.; Liao, R.; Jia, J.; Urtasun, R.; Fidler, S. Situation Recognition with Graph Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4183–4192. [Google Scholar]
- Shi, L.-F.; Liu, Z.-Y.; Zhow, K.-J.; Shi, Y.; Jing, X. Novel Deep Learning Network for Gait Recognition Using Multimodal Inertial Sensors. Sensor 2023, 23, 849. [Google Scholar] [CrossRef] [PubMed]
- Diaz-Cely, J.; Arce-Lopera, C.; Mena, J.C.; Quintero, L. The Effect of Color Channel Representations on the Transferability of Convolutional Neural Networks. Adv. Intell. Syst. Comput. 2019, 943, 27–38. [Google Scholar]
- Bianco, S.; Cusano, C.; Napoletano, P.; Schettini, R. Improving CNN-Based Texture Classification by Color Balancing. J. Imaging 2017, 3, 33. [Google Scholar] [CrossRef]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-Trained CNNs Are Biased towards Texture; Increasing Shape Bias Improves Accuracy and Robustness. arXiv 2019, arXiv:1811.12231. [Google Scholar]
- National Highway Traffic Safety Administration. Older Population. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/813121 (accessed on 25 February 2023).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-V4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2017; Volume 31. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Larson, T.; Wyman, A.; Hurwitz, D.S.; Dorado, M.; Quayle, S.; Shetler, S. Evaluation of Dynamic Passive Pedestrian Detection. Transp. Res. Interdiscip. Perspect. 2020, 8, 100268. [Google Scholar] [CrossRef]
- Zhang, S.; Abdel-Aty, M.; Yuan, J.; Li, P. Prediction of Pedestrian Crossing Intentions at Intersections Based on Long Short-Term Memory Recurrent Neural Network. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 57–65. [Google Scholar] [CrossRef]
- Prioletti, A.; Mogelmose, A.; Grisleri, P.; Trivedi, M.M.; Broggi, A.; Moeslund, T.B. Part-Based Pedestrian Detection and Feature-Based Tracking for Driver Assistance: Real-Time, Robust Algorithms, and Evaluation. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1346–1359. [Google Scholar] [CrossRef]
- Hariyono, J.; Hoang, V.-D.; Jo, K.-H. Location Classification of Detected Pedestrian. In Proceedings of the 14th International Conference on Control, Automation and Systems (ICCAS 2014), Gyeonggi, Republic of Korea, 22–25 October 2014. [Google Scholar]
- Hariyono, J.; Jo, K.-H. Detection of Pedestrian Crossing Road. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Keller, C.G.; Gavrila, D.M. Will the Pedestrian Cross? A Study on Pedestrian Path Prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 494–506. [Google Scholar] [CrossRef]
- Keller, C.G.; Dang, T.; Fritz, H.; Joos, A.; Rabe, C.; Gavrila, D.M. Active Pedestrian Safety by Automatic Braking and Evasive Steering. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1292–1304. [Google Scholar] [CrossRef]
- Dow, C.; Ngo, H.; Lee, L.; Lai, P.; Wang, K.; Bui, V. A Crosswalk Pedestrian Recognition System by Using Deep Learning and Zebra-Crossing Recognition Techniques. Softw. Pract. Exp. 2020, 50, 630–644. [Google Scholar] [CrossRef]
- Zhang, Z.-D.; Tan, M.-L.; Lan, Z.-C.; Liu, H.-C.; Pei, L.; Yu, W.-X. CDNet: A Real-Time and Robust Crosswalk Detection Network on Jetson Nano Based on YOLOv5. Neural Comput. Appl. 2022, 34, 10719–10730. [Google Scholar] [CrossRef]
- Malbog, M.A. MASK R-CNN for Pedestrian Crosswalk Detection and Instance Segmentation. In Proceedings of the 2019 IEEE 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Bakr, H.; Hamad, A.; Amin, K. Mask R-CNN for moving shadow detection and segmentation. IJCI. Int. J. Comput. Inf. 2021, 8, 1–18. [Google Scholar] [CrossRef]
- GitHub. Available online: https://github.com/toast-ceo/CNN-Based-Crosswalk-Pedestrian-Situation-Recognition-System-Using-Mask-R-CNN-and-CDA (accessed on 14 March 2023).













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).