
CNN-Based Crosswalk Pedestrian Situation Recognition System Using Mask-R-CNN and CDA



Abstract
:1. Introduction
2. Related Works
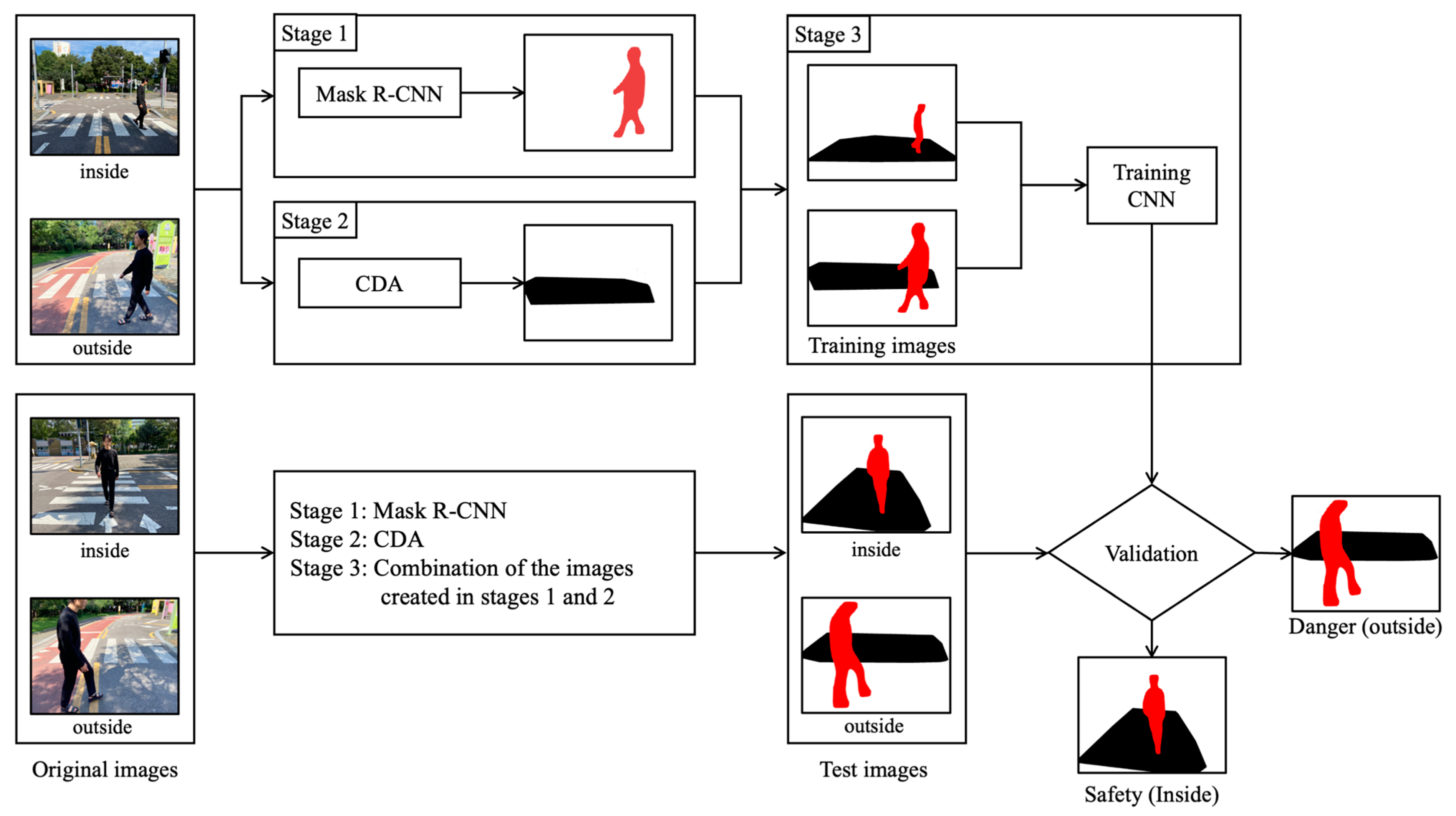
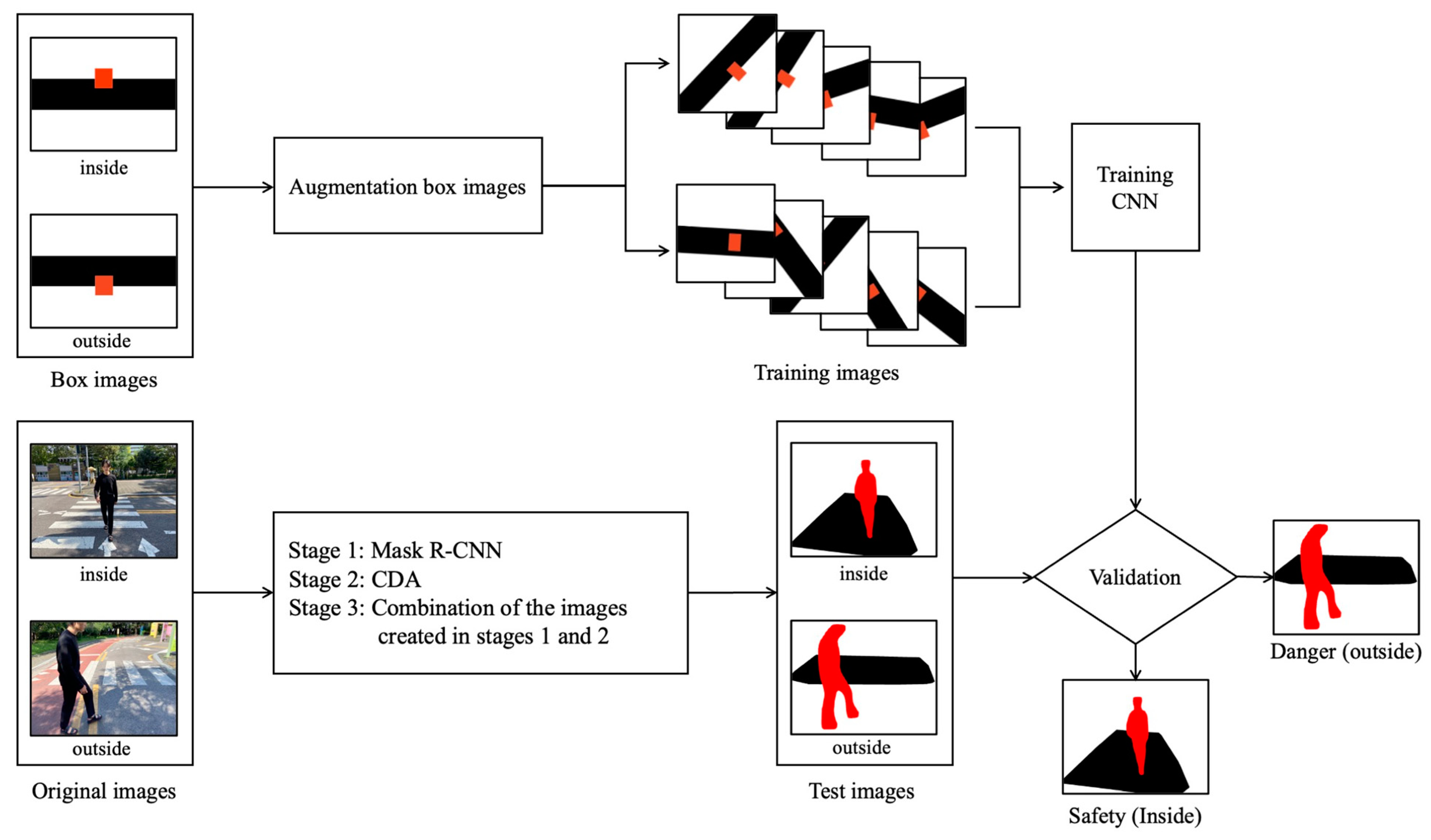
3. Proposed Method
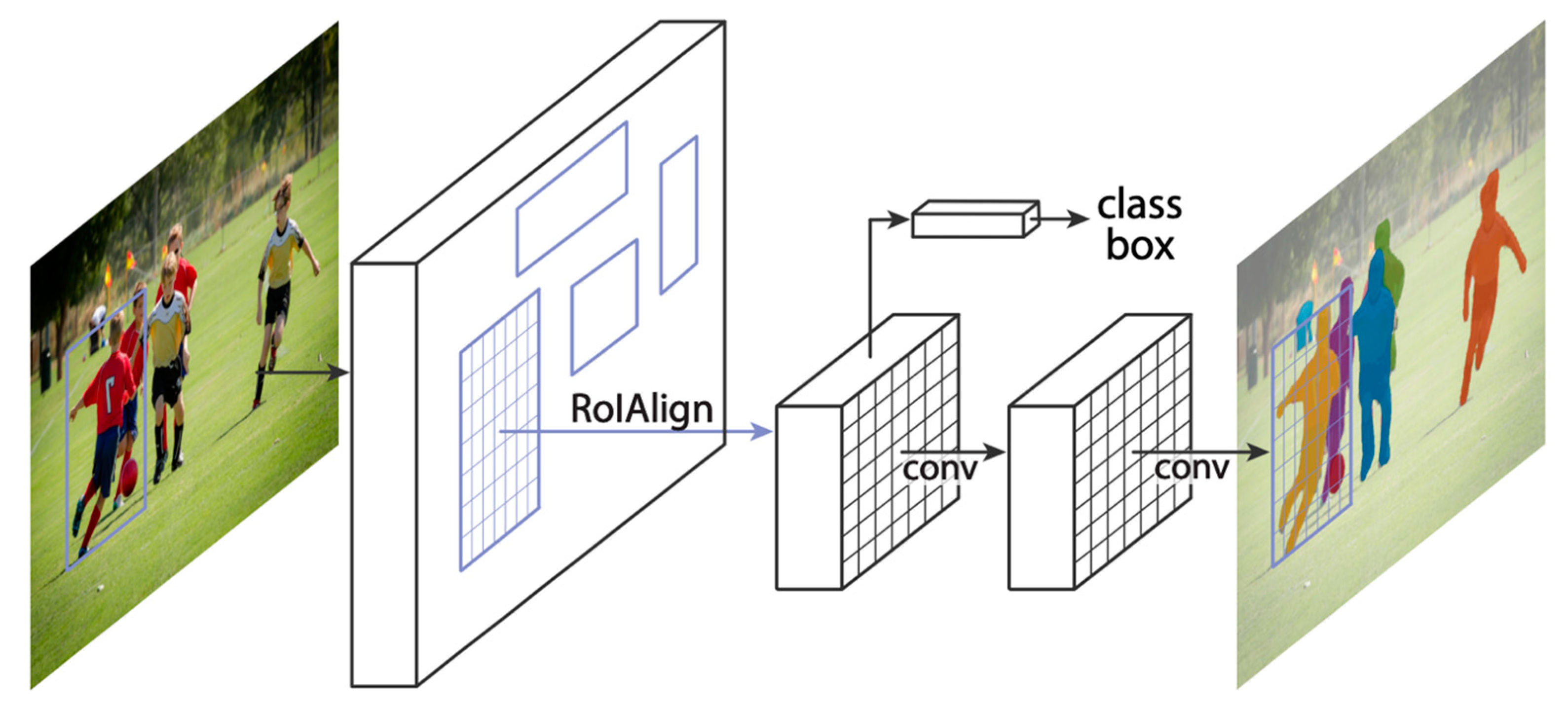
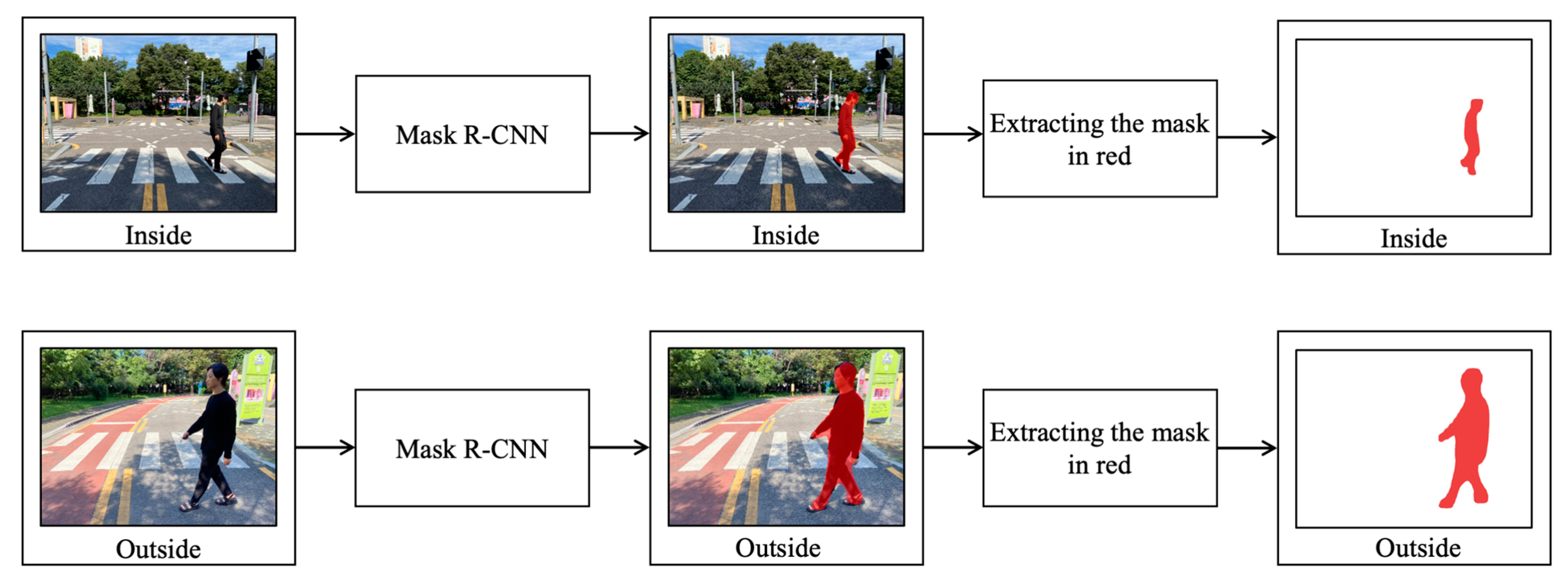
3.1. Stage 1: Pedestrian Detection Using Mask R-CNN
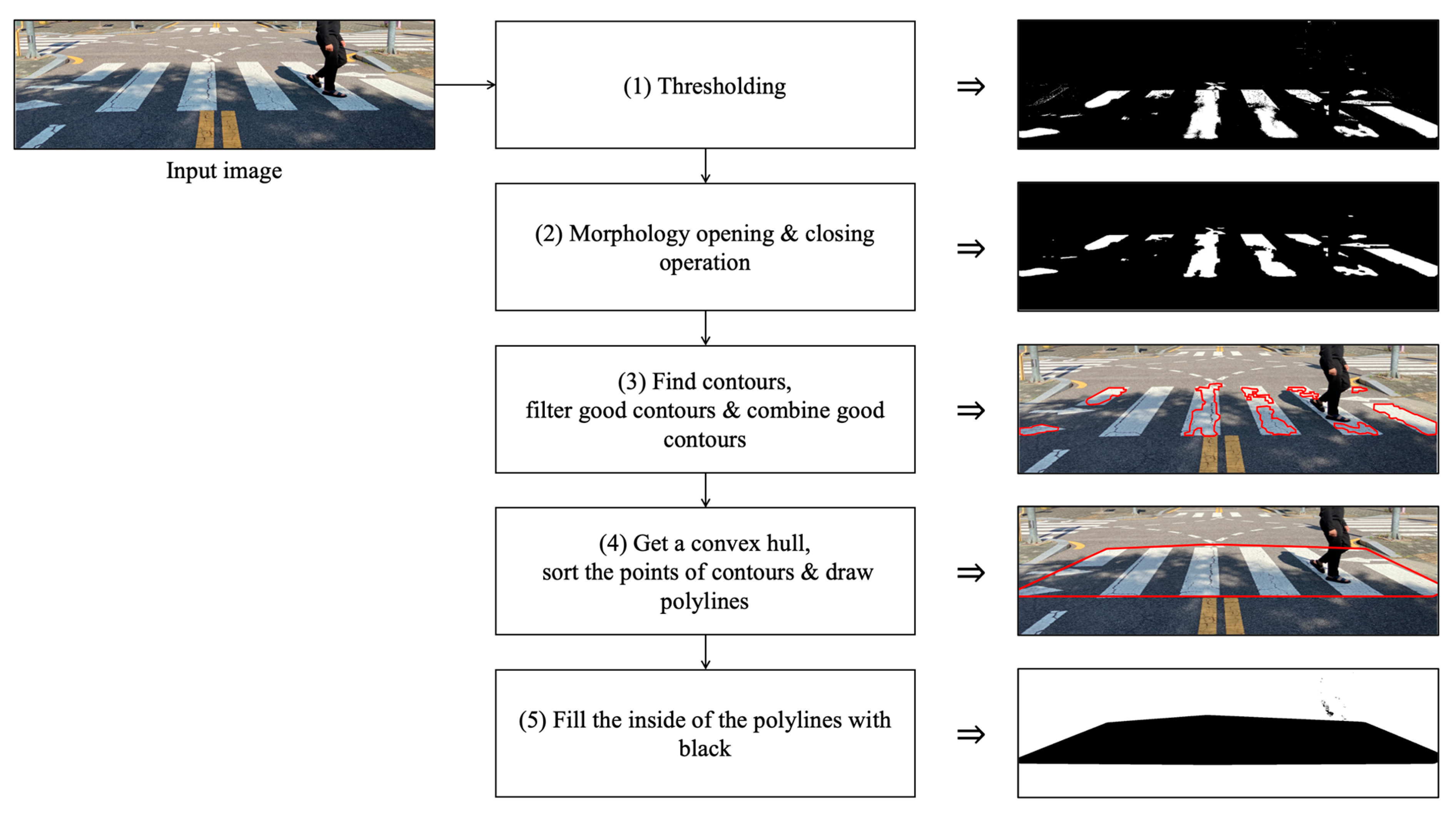
3.2. Stage 2: Crosswalk Detection Using the Crosswalk Detection Algorithm (CDA)
- (1)
- Thresholding: make the white crosswalk visible by making it clear what is white and what is not;
- (2)
- Morphology opening and closing operation: reduce noise by erosion and expansion in areas other than crosswalks. Make the crosswalk area clear;
- (3)
- Find contours, filter good contours, and combine good contours: obtain crosswalk contours and extract multiple contents from one image. If the content is larger than a pixel area (e.g.,170, pixels) of a specific size, it is judged by the crosswalk image. Combine the values of the good contours array;
- (4)
- Obtain a convex hull, sort the points of contours and draw polylines: convex hull function combines the good contour image with the original image to make a small square into an entire large square. Sort the points of contours combined by x-coordinate (in case of a tie, sort by y-coordinate). Draw polylines in red;
- (5)
- Fill the inside of the polylines with black.
| Algorithm 1: The Crosswalk Detection Algorithm (CDA) |
| Input: Original Image (β1…βw), #w is the number of pixels in the crosswalk image. Output: Extracted Image M; #Full image of the crosswalk area 01: # (1) Thresholding 02: for j ← 1 to w do { 03: If βj > RGB (255,255,255) then βj = RGB (255,255,255) 04: Else if βj < RGB (125,125,125) then βj = RGB (0,0,0). 05: } 06: # (2) Morphology opening & closing operation 07: β ← erode & dilate (β) 08: # Morphology Closing 09: β ← dilate & erode (β) 10: # (3) Find contours, filter good contours & combine good contours 11: contours ← FindContours (β) 12: goodContours ← Empty list 13:# Filter good contours: larger than a pixel area (170 pixels) of a certain size 14: for i ← 1 to contours do { 15: area ← contourArea(contoursi) 16: if area > 170 then { 17: drawContours (β,contoursi) 18: goodContours.append (contoursi). 19: } 20: } 21: # Combine good contours: combine the values of the good contours array. 22: contoursCombined ← Combine (goodContours) 23: # (4) Get convex hull, sort & draw polylines 24: convexhull (contoursCombined) 25: Sort (contoursCombined). # Sort the points of contours combined by x-coordinate 26: U ← Empty list 27: L ← Empty list 28: for i ← 1 to n do { 29: contoursCombined.append (Li) 30: } 31: for i ← n to 1 do { 32: contoursCombined.append (Ui) 33: } 34: M ← polylines (contoursCombined) # Draw polylines in red 35: # (5) Fill the inside of the polylines with black 36: M ← fillPoly (M) 37: return M |
3.3. Stage 3: Training Using CNN
4. Experiments
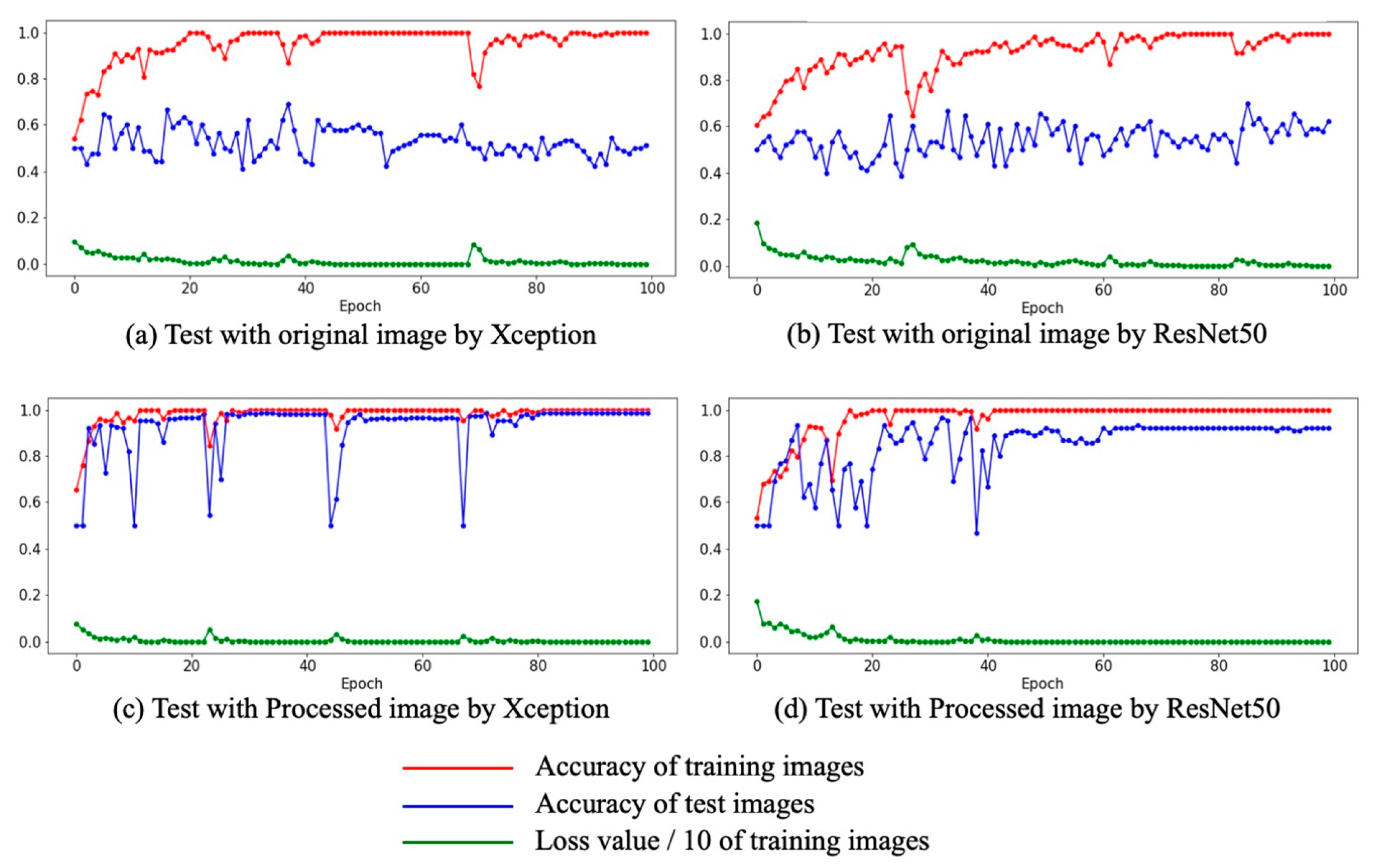
4.1. Experiment I
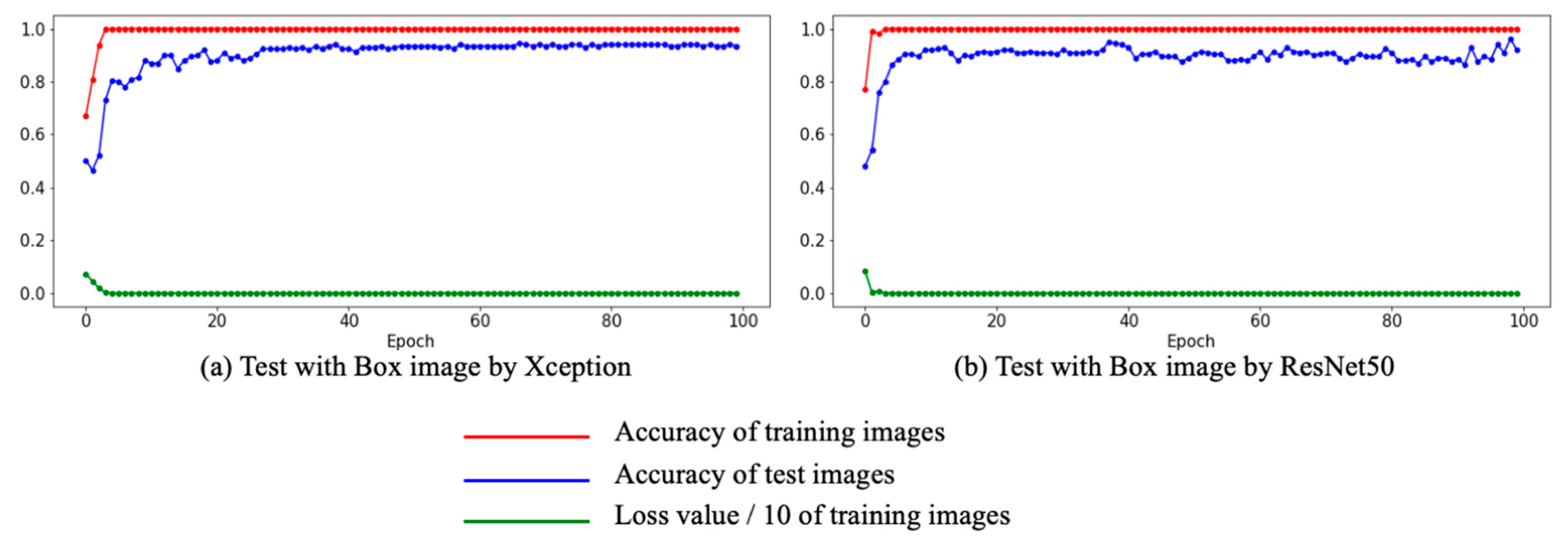
4.2. Experiment II
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. arXiv 2019, arXiv:1809.02165. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242 394. [Google Scholar]
- Yatskar, M.; Zettlemoyer, L.; Farhadi, A. Situation Recognition: Visual Semantic Role Labeling for Image Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5534–5542. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting Visual Relationships with Deep Relational Networks. arXiv 2017, arXiv:1704.03114. [Google Scholar]
- Li, R.; Tapaswi, M.; Liao, R.; Jia, J.; Urtasun, R.; Fidler, S. Situation Recognition with Graph Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4183–4192. [Google Scholar]
- Shi, L.-F.; Liu, Z.-Y.; Zhow, K.-J.; Shi, Y.; Jing, X. Novel Deep Learning Network for Gait Recognition Using Multimodal Inertial Sensors. Sensor 2023, 23, 849. [Google Scholar] [CrossRef] [PubMed]
- Diaz-Cely, J.; Arce-Lopera, C.; Mena, J.C.; Quintero, L. The Effect of Color Channel Representations on the Transferability of Convolutional Neural Networks. Adv. Intell. Syst. Comput. 2019, 943, 27–38. [Google Scholar]
- Bianco, S.; Cusano, C.; Napoletano, P.; Schettini, R. Improving CNN-Based Texture Classification by Color Balancing. J. Imaging 2017, 3, 33. [Google Scholar] [CrossRef] [Green Version]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-Trained CNNs Are Biased towards Texture; Increasing Shape Bias Improves Accuracy and Robustness. arXiv 2019, arXiv:1811.12231. [Google Scholar]
- National Highway Traffic Safety Administration. Older Population. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/813121 (accessed on 25 February 2023).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-V4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2017; Volume 31. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larson, T.; Wyman, A.; Hurwitz, D.S.; Dorado, M.; Quayle, S.; Shetler, S. Evaluation of Dynamic Passive Pedestrian Detection. Transp. Res. Interdiscip. Perspect. 2020, 8, 100268. [Google Scholar] [CrossRef]
- Zhang, S.; Abdel-Aty, M.; Yuan, J.; Li, P. Prediction of Pedestrian Crossing Intentions at Intersections Based on Long Short-Term Memory Recurrent Neural Network. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 57–65. [Google Scholar] [CrossRef]
- Prioletti, A.; Mogelmose, A.; Grisleri, P.; Trivedi, M.M.; Broggi, A.; Moeslund, T.B. Part-Based Pedestrian Detection and Feature-Based Tracking for Driver Assistance: Real-Time, Robust Algorithms, and Evaluation. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1346–1359. [Google Scholar] [CrossRef] [Green Version]
- Hariyono, J.; Hoang, V.-D.; Jo, K.-H. Location Classification of Detected Pedestrian. In Proceedings of the 14th International Conference on Control, Automation and Systems (ICCAS 2014), Gyeonggi, Republic of Korea, 22–25 October 2014. [Google Scholar]
- Hariyono, J.; Jo, K.-H. Detection of Pedestrian Crossing Road. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Keller, C.G.; Gavrila, D.M. Will the Pedestrian Cross? A Study on Pedestrian Path Prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 494–506. [Google Scholar] [CrossRef] [Green Version]
- Keller, C.G.; Dang, T.; Fritz, H.; Joos, A.; Rabe, C.; Gavrila, D.M. Active Pedestrian Safety by Automatic Braking and Evasive Steering. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1292–1304. [Google Scholar] [CrossRef] [Green Version]
- Dow, C.; Ngo, H.; Lee, L.; Lai, P.; Wang, K.; Bui, V. A Crosswalk Pedestrian Recognition System by Using Deep Learning and Zebra-Crossing Recognition Techniques. Softw. Pract. Exp. 2020, 50, 630–644. [Google Scholar] [CrossRef]
- Zhang, Z.-D.; Tan, M.-L.; Lan, Z.-C.; Liu, H.-C.; Pei, L.; Yu, W.-X. CDNet: A Real-Time and Robust Crosswalk Detection Network on Jetson Nano Based on YOLOv5. Neural Comput. Appl. 2022, 34, 10719–10730. [Google Scholar] [CrossRef]
- Malbog, M.A. MASK R-CNN for Pedestrian Crosswalk Detection and Instance Segmentation. In Proceedings of the 2019 IEEE 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Bakr, H.; Hamad, A.; Amin, K. Mask R-CNN for moving shadow detection and segmentation. IJCI. Int. J. Comput. Inf. 2021, 8, 1–18. [Google Scholar] [CrossRef]
- GitHub. Available online: https://github.com/toast-ceo/CNN-Based-Crosswalk-Pedestrian-Situation-Recognition-System-Using-Mask-R-CNN-and-CDA (accessed on 14 March 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Systems | Accuracy of Detecting a Pedestrian & a Crosswalk | Use of Deep Learning | Detect Crosswalk | The Sight of the Car Driver | Method of Detecting Crosswalk | Samples of Detecting Crosswalk |
|---|---|---|---|---|---|---|
| Ours | 96.7~98.7 | O | crosswalk shape | O | CDA |  |
| Larson et al. [23] | 82~89 | X | box shape | X | optical sensors |  |
| Dow et al. [30] | Detect only a pedestrian | O | box shape | X | YOLO |  |
| Zhang et al. [31] | 94.8~98 | O | box shape | O | YOLO5 |  |
| Malbog [32] | Detect only a crosswalk | O | crosswalk shape | O | Mask R-CNN |  |
| Zhang et al. [24] | Detect only a pedestrian | O | X | X | X | |
| Etc. [25,26,27,28,29] | Detect only a pedestrian | X | X | X | X |
| Experimental Details | |
|---|---|
| Dataset configuration | Safety (inside) Danger (outside) |
| Number of original images | Total data: 510 Training data: 360 Test data: 150 |
| Number of processed images | Total data: 510 Training data: 360 Test data: 150 |
| Number of images for experiment II | Total data: 750 Training data (box images): 600 Test data (processed images): 150 |
| CNNs | ResNet50, Xception |
| Learning environment | Google Colaboratory |
| Learning rate | 0.001 |
| Training epochs | 100 epochs |
| Training Data | Xception | ReNet50 | |
|---|---|---|---|
| Experiment I | Original images | 68.8 | 70.0 |
| Processed images | 98.7 | 96.7 | |
| Experiment II | Box images | 94.5 | 96.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Hwang, J.; Kim, J.; Han, J. CNN-Based Crosswalk Pedestrian Situation Recognition System Using Mask-R-CNN and CDA. Appl. Sci. 2023, 13, 4291. https://doi.org/10.3390/app13074291
Lee S, Hwang J, Kim J, Han J. CNN-Based Crosswalk Pedestrian Situation Recognition System Using Mask-R-CNN and CDA. Applied Sciences. 2023; 13(7):4291. https://doi.org/10.3390/app13074291
Chicago/Turabian StyleLee, Sac, Jaemin Hwang, Junbeom Kim, and Jinho Han. 2023. "CNN-Based Crosswalk Pedestrian Situation Recognition System Using Mask-R-CNN and CDA" Applied Sciences 13, no. 7: 4291. https://doi.org/10.3390/app13074291
APA StyleLee, S., Hwang, J., Kim, J., & Han, J. (2023). CNN-Based Crosswalk Pedestrian Situation Recognition System Using Mask-R-CNN and CDA. Applied Sciences, 13(7), 4291. https://doi.org/10.3390/app13074291