

Automatic Tumor Identification from Scans of Histopathological Tissues

Abstract
:1. Introduction
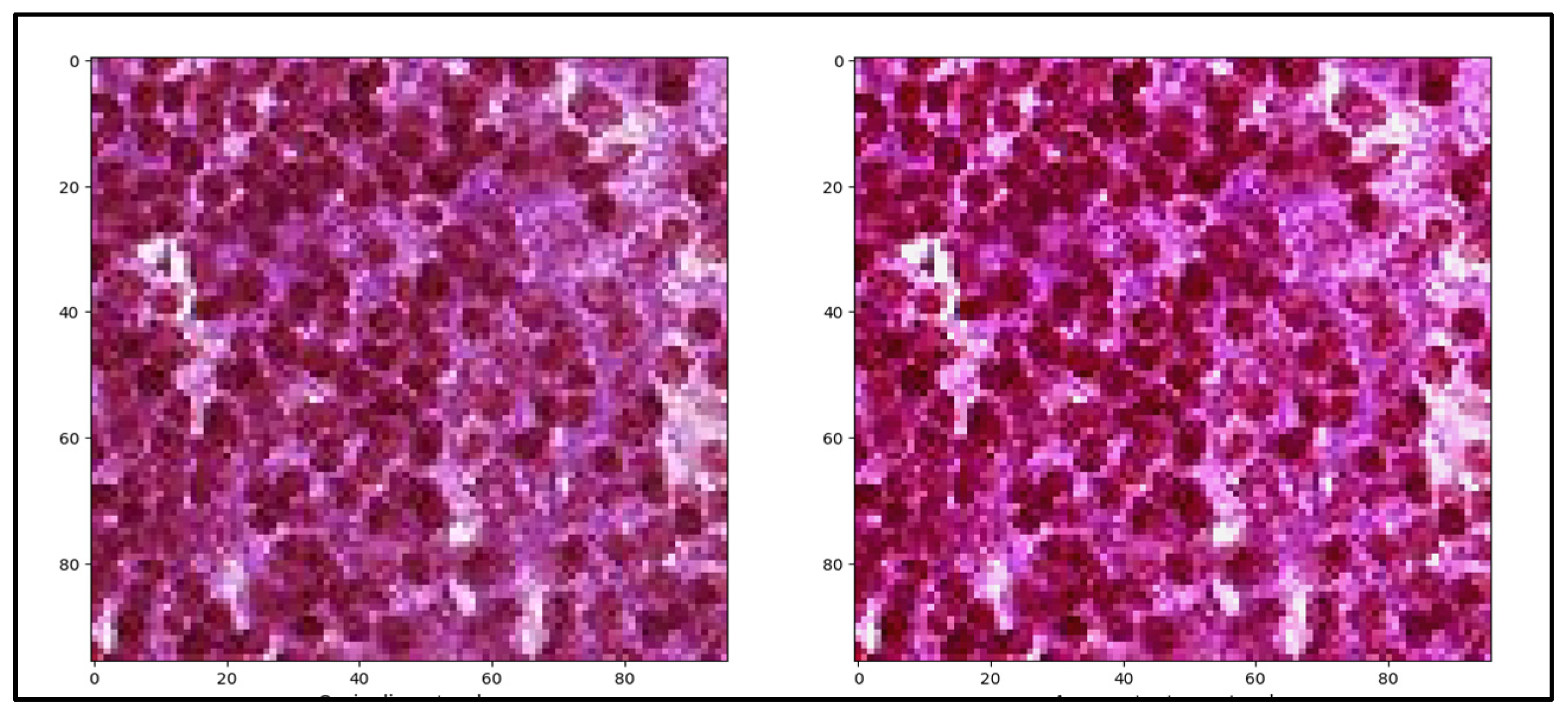
- Modern augmentation and image preprocessing methods to analyze WSIs,
- Creating an adaptive U-Net model architecture,
- Adding different optimizers for best outcoming result in AUC.
- In Section 2, we did a review of machine learning models, architectures, algorithms, and other techniques that can be used for histopathological WSIs,
- Section 3 outlines the methodology, that step by step describes the machine learning model, dataset, and accuracy requirements for further experiments,
- Section 4 consists of the design of the experiments, the main values, graphical and statistical results,
- In Section 5, we list the major accomplishments and talk about the outcomes,
- In Section 6, we conclude our work and identify potential work directions.
2. Related Work
2.1. Medical Imaging
2.2. Machine Learning Models
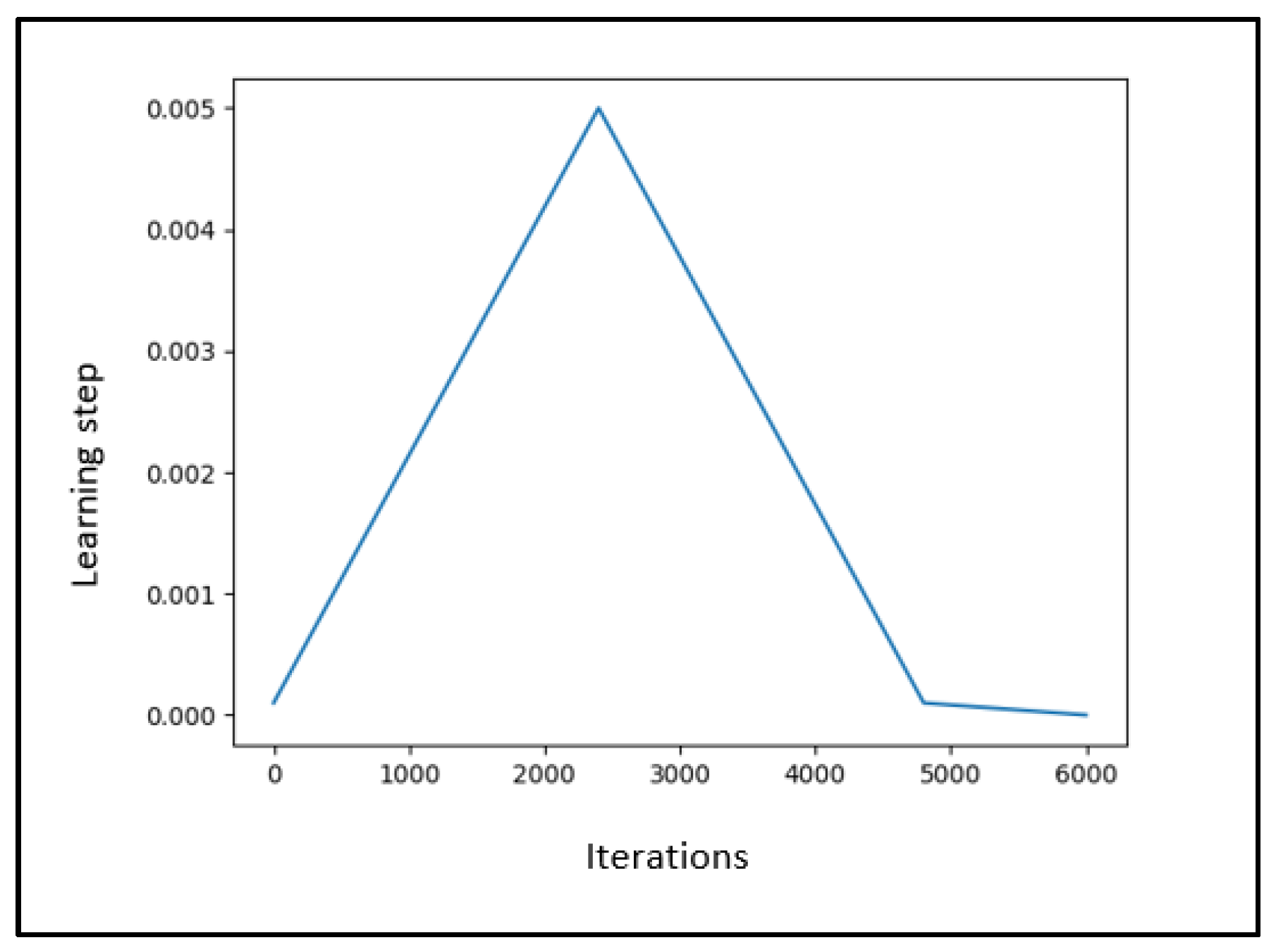
Learning Rate and Planning Algorithms
3. Materials and Methods
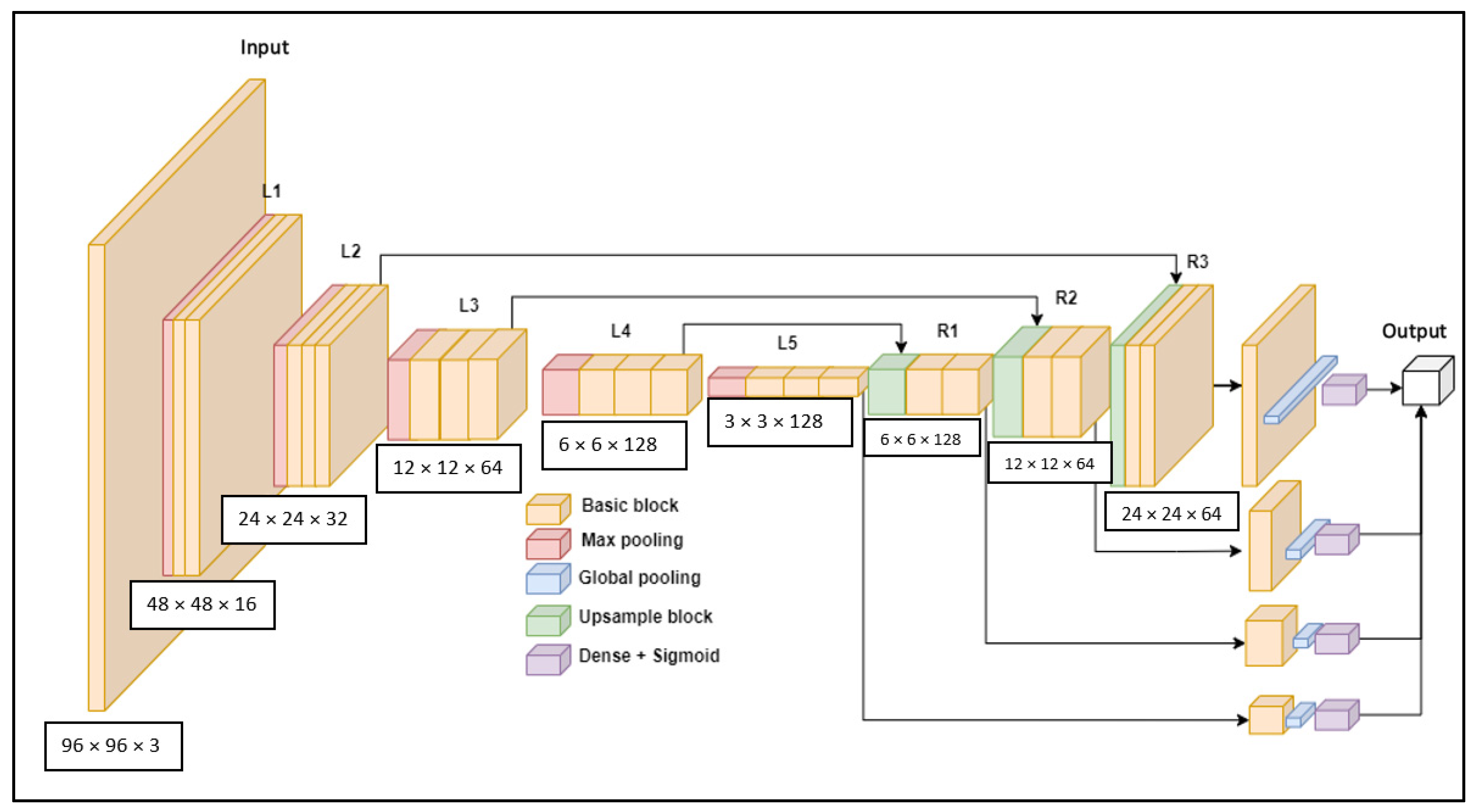
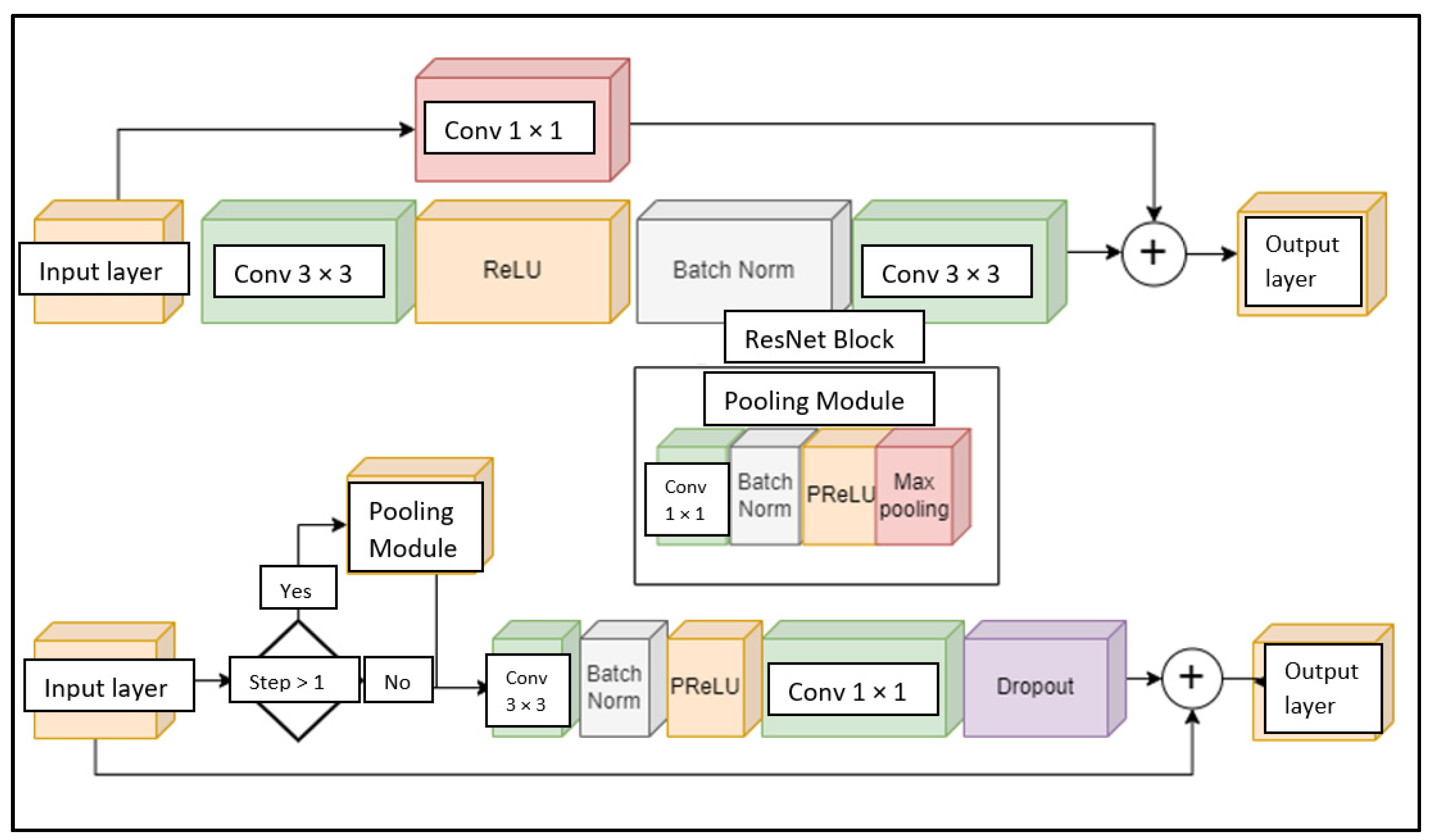
3.1. Proposed Model
3.2. Dataset
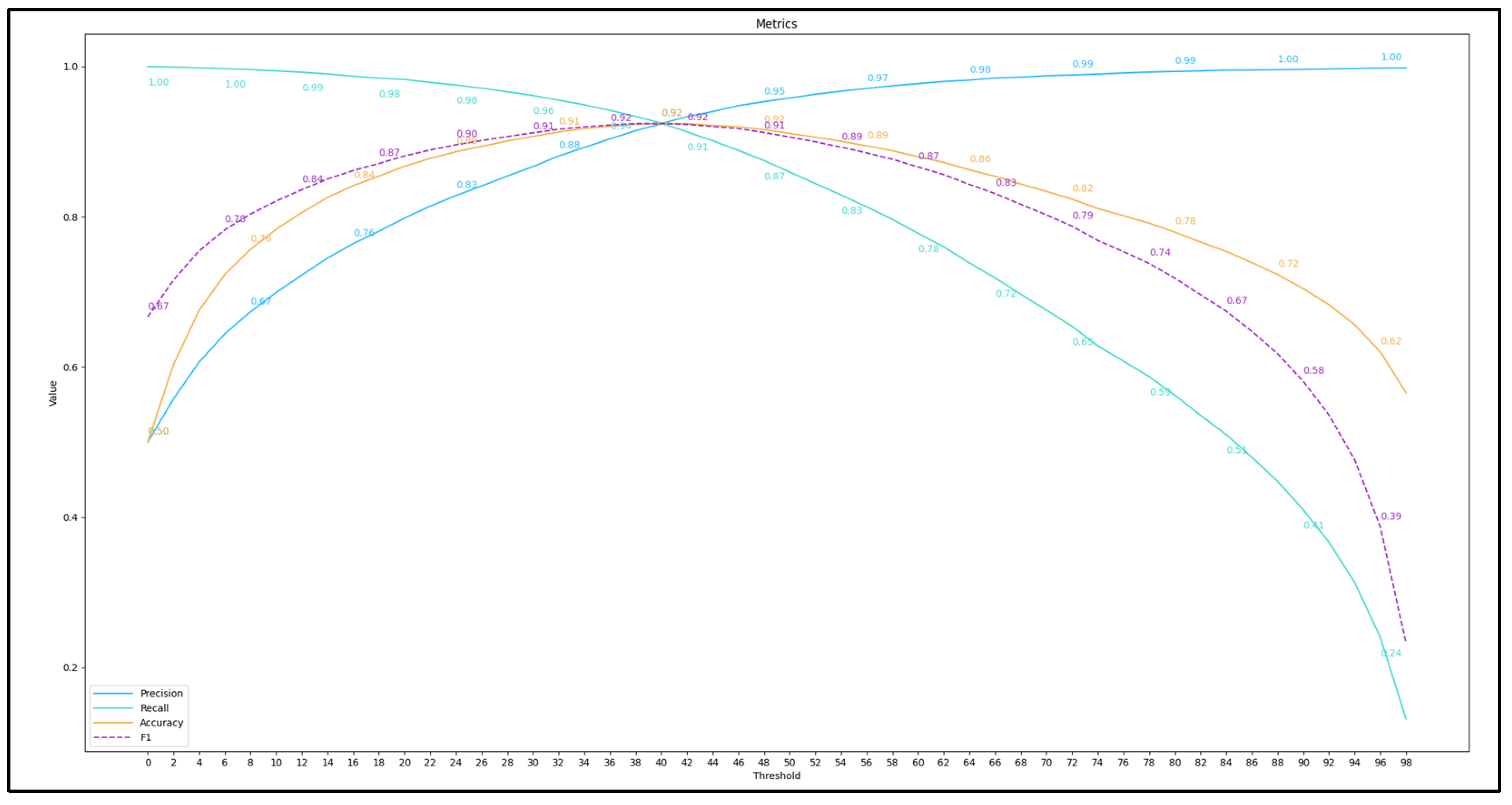
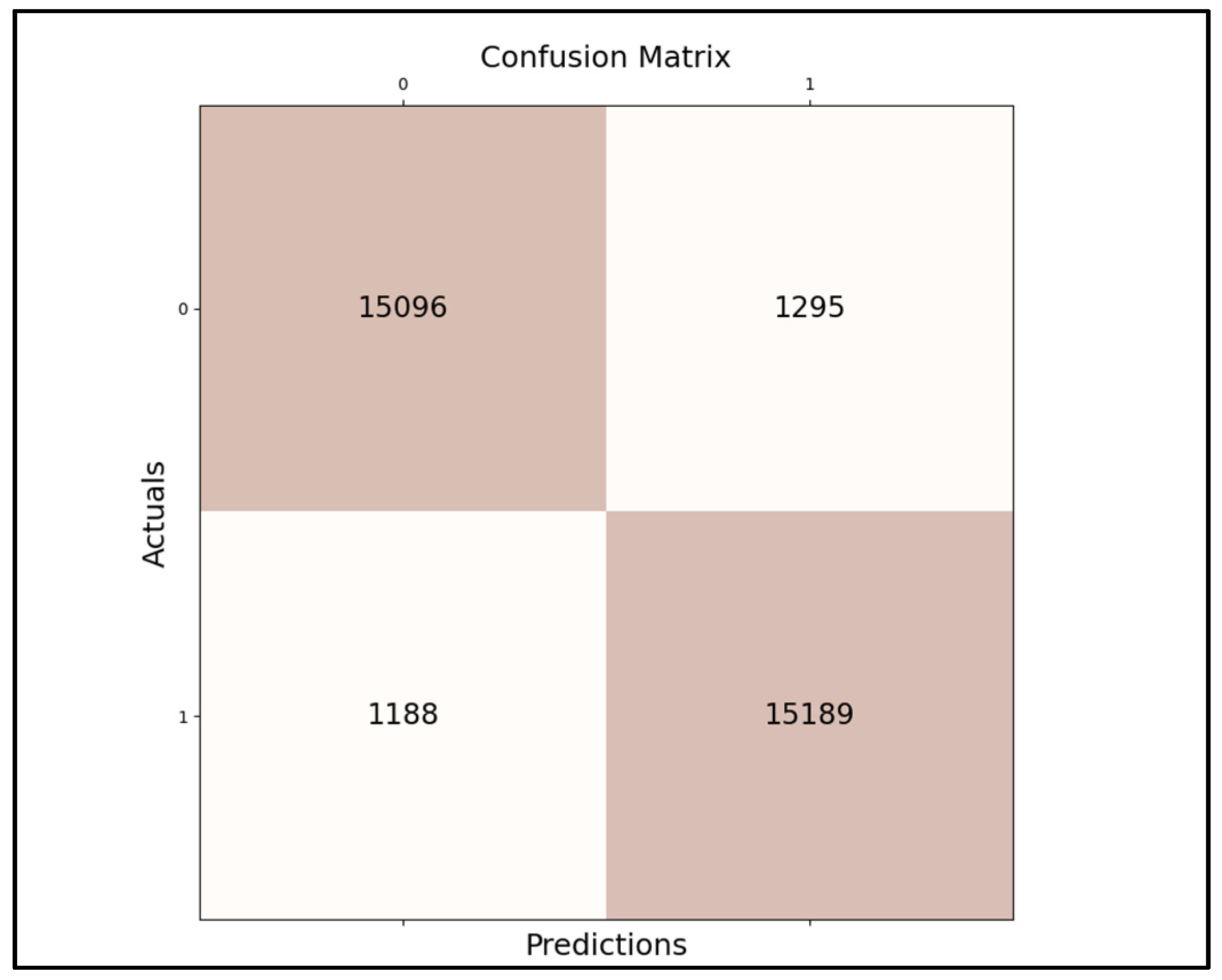
3.3. Accuracy Calculation
- Precision using Equation (2),
- Recall using Equation (3),
- F1-score using Equation (4),
- AUC. Measures the quality of the model in terms of sensitivity and accuracy over the entire set of limits.
4. Experiments and Results
4.1. Experimental Setup
- Number of filters (5):
- Number of blocks (6):
- Exclusion factor (7):
- L2 regularization (8):where f is the base number of filters, F is the filter multiplier, s is the filter multiplier, h is the height of the network in pixels, g is the number of convolutional groups of the network. The number of blocks indicates how many internal blocks will make up the mesh module after each decrease or increase in height and width of the mesh. Exclusion factor—indicates how many neurons will be turned off in percentage in each block, where m indicates the maximum possible number of filters. The L2 regularization [77,78] specifies the value of the L2 regularization constant for all network convolutions.
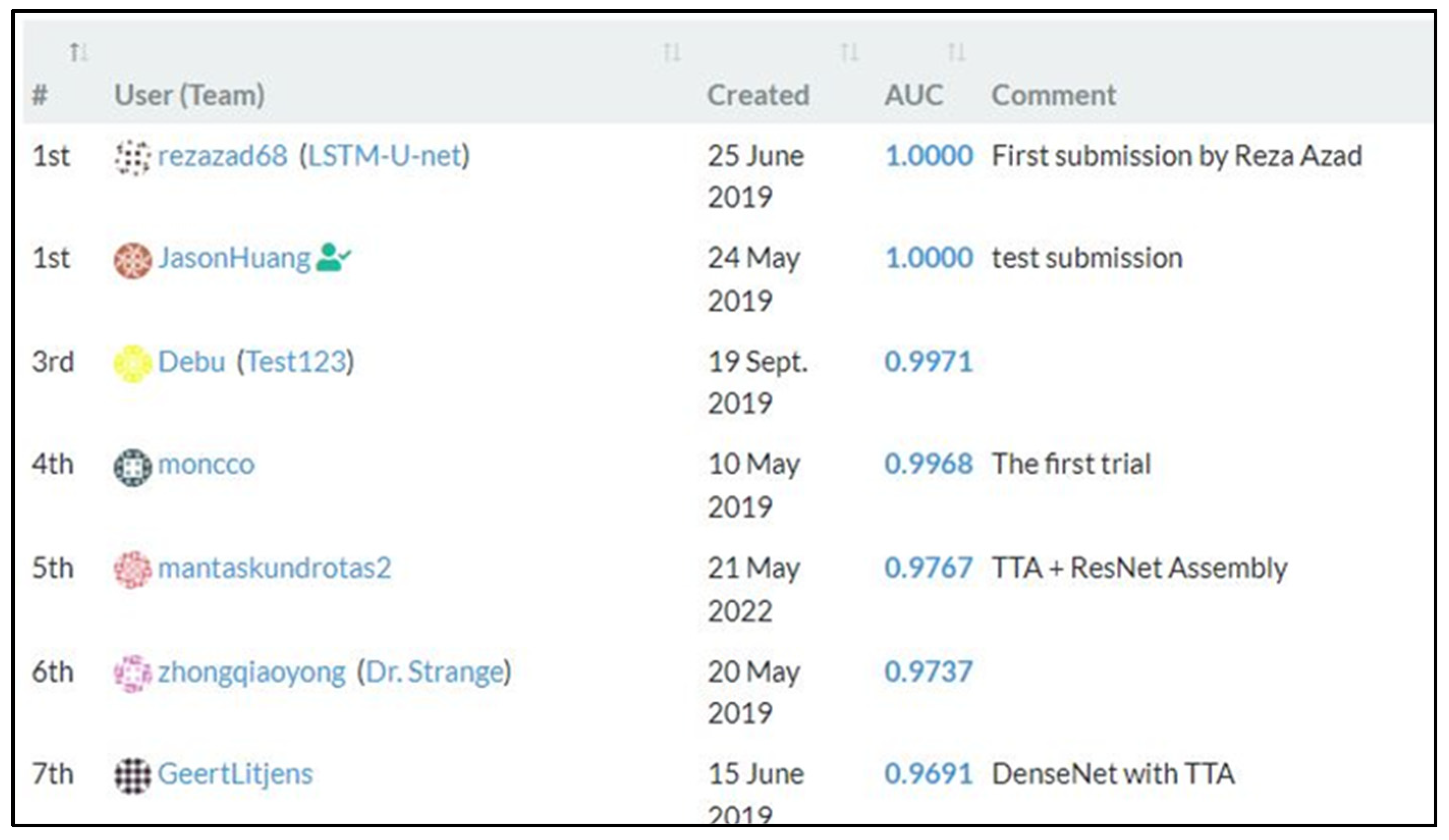
4.2. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmed, S.; Shaikh, A.; Alshahrani, H.; Alghamdi, A.; Alrizq, M.; Baber, J.; Bakhtyar, M. Transfer learning approach for classification of histopathology whole slide images. Sensors 2021, 21, 5361. [Google Scholar] [CrossRef]
- Pantanowitz, L.; Dickinson, K.; Evans, A.J.; Hassell, L.A.; Henricks, W.H.; Lennerz, J.K.; Lowe, A.; Parwani, A.V.; Riben, M.; Smith, C.D.; et al. American Telemedicine Association clinical guidelines for telepathology. J. Pathol. Inform. 2014, 5, 39. [Google Scholar] [CrossRef]
- Helin, H.; Tolonen, T.; Ylinen, O.; Tolonen, P.; Napankangas, J.; Isola, J. Optimized JPEG 2000 compression for efficient storage of histopathological whole-slide images. J. Pathol. Inform. 2018, 9, 20. [Google Scholar] [CrossRef]
- Kim, I.; Kang, K.; Song, Y.; Kim, T.J. Application of Artificial Intelligence in Pathology: Trends and Challenges. Diagnostics 2022, 12, 2794. [Google Scholar] [CrossRef]
- Van der Laak, J.; Litjens, G.; Ciompi, F. Deep learning in histopathology: The path to the clinic. Nat. Med. 2021, 27, 775–784. [Google Scholar] [CrossRef]
- Saba, T. Journal of Infection and Public Health. 13 Recent advancement in cancer detection using machine learning: Systematic survey of decades, comparisons, and challenges. J. Infect. Public Health 2020, 13, 1274–1289. [Google Scholar] [CrossRef]
- Lansdowne, L.E. Tumor Biology. Cancer Research from Technology Networks. Accessed August 16, 2022. Available online: http://www.technologynetworks.com/cancer-research/infographics/tumor-biology-359548 (accessed on 1 October 2021).
- Azhari, E.E.M.; Hatta, M.M.M.; Htike, Z.Z.; Win, S.L. Tumor detection in medical imaging: A survey. Int. J. Adv. Inf. Technol. 2014, 4, 21. [Google Scholar]
- Díaz-Pernas, F.J.; Martínez-Zarzuela, M.; Antón-Rodríguez, M.; González-Ortega, D. A deep learning approach for brain tumor classification and segmentation using a multiscale convolutional neural network. Healthcare 2021, 9, 153. [Google Scholar] [CrossRef]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef]
- Litjens, G.; Sánchez, C.I.; Timofeeva, N.; Hermsen, M.; Nagtegaal, I.; Kovacs, I.; Hulsbergen-van de Kaa, C.; Bult, P.; Van Ginneken, B.; Van Der Laak, J. Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Sci. Rep. 2016, 6, 26286. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Long, L.R.; Antani, S.; Thoma, G.R. Histology image analysis for carcinoma detection and grading. Comput. Methods Programs Biomed. 2012, 107, 538–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pandian, A.P. Identification and classification of cancer cells using capsule network with pathological images. J. Artif. Intell. 2019, 1, 37–44. [Google Scholar]
- Ehteshami, B. Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women With Breast Cancer. J. Am. Med. Assoc. 2017, 318, 2199–2210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of machine learning for anomaly based intrusion detection systems in the CICIDS2017 dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Senkamalavalli, R.; Bhuvaneswari, T. Improved classification of breast cancer data using hybrid techniques. Int. J. Adv. Eng. Res. Sci. 2017, 5, 237467. [Google Scholar] [CrossRef]
- Jiang, P.; Peng, J.; Zhang, G.; Cheng, E.; Megalooikonomou, V.; Ling, H. Learning-based automatic breast tumor detection and segmentation in ultrasound images. In Proceedings of the 2012 9th IEEE International Symposium on Biomedical Imaging (ISBI), Barcelona, Spain, 2–5 May 2012; pp. 1587–1590. [Google Scholar]
- Parmar, S.; Gondaliya, N. A Survey on Detection and Classification of Brain Tumor from MRI Brain Images using Image Processing Techniques. Int. Res. J. Eng. Technol. IRJET 2018, 5, 162–166. [Google Scholar]
- Jayade, S.; Ingole, D.T.; Ingole, M.D. MRI brain tumor classification using hybrid classifier. In Proceedings of the 2019 International Conference on Innovative Trends and Advances in Engineering and Technology (ICITAET), Shegoaon, India, 27–28 December 2019; pp. 201–205. [Google Scholar]
- Peter, R.; Korfiatis, P.; Blezek, D.; Oscar Beitia, A.; Stepan-Buksakowska, I.; Horinek, D.; Flemming, K.D.; Erickson, B.J. A quantitative symmetry-based analysis of hyperacute ischemic stroke lesions in noncontrast computed tomography. Med. Phys. 2017, 44, 192–199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seetha, J.; Raja, S.S. Brain tumor classification using convolutional neural networks. Biomed. Pharmacol. J. 2018, 11, 1457. [Google Scholar] [CrossRef]
- Yu, J.; Li, Q.; Zhang, H.; Meng, Y.; Liu, Y.F.; Jiang, H.; Ma, C.; Liu, F.; Fang, X.; Li, J.; et al. Contrast-enhanced computed tomography radiomics and multilayer perceptron network classifier: An approach for predicting CD20+ B cells in patients with pancreatic ductal adenocarcinoma. Abdom. Radiol. 2022, 47, 242–253. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505. [Google Scholar] [CrossRef] [Green Version]
- Khajuria, R.; Quyoom, A.; Sarwar, A. A comparison of deep reinforcement learning and deep learning for complex image analysis. J. Multimed. Inf. Syst. 2020, 7, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Tyagi, A.K.; Chahal, P. Artificial intelligence and machine learning algorithms. In Research Anthology on Machine Learning Techniques, Methods, and Applications; IGI Global: Hershey, PA, USA, 2022; pp. 421–446. [Google Scholar]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Rossi, F.; Conan-Guez, B. Functional Multi-Layer Perceptron: A Nonlinear Tool for Functional Data Analysis. Neural Netw. Off. J. Int. Neural Netw. Soc. 2005, 18, 45–60. [Google Scholar] [CrossRef] [Green Version]
- Wahab, N.; Khan, A. Multifaceted fused-CNN based scoring of breast cancer whole-slide histopathology images. Appl. Soft Comput. 2020, 97, 106808. [Google Scholar] [CrossRef]
- Zainudin, Z.; Shamsuddin, S.M.; Hasan, S. Deep layer CNN architecture for breast cancer histopathology image detection. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Cham, Switzerland, 2019; pp. 43–51. [Google Scholar]
- Dabeer, S.; Khan, M.M.; Islam, S. Cancer diagnosis in histopathological image: CNN based approach. Inform. Med. Unlocked 2019, 16, 100231. [Google Scholar] [CrossRef]
- Graziani, M.; Lompech, T.; Müller, H.; Andrearczyk, V. Evaluation and comparison of CNN visual explanations for histopathology. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 195–201. [Google Scholar]
- Zhang, L.; Wu, Y.; Zheng, B.; Su, L.; Chen, Y.; Ma, S.; Hu, Q.; Zou, X.; Yao, L.; Yang, Y.; et al. Rapid histology of laryngeal squamous cell carcinoma with deep-learning based stimulated Raman scattering microscopy. Theranostics 2019, 9, 2541. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lauande, M.G.M.; Teles, A.M.; da Silva, L.L.; Matos, C.E.F.; Junior, G.B.; de Paiva, A.C.; de Almeida, J.S.; Oliveira, R.; Brito, H.; Nascimento, A.; et al. Classification of Histopathological Images of Penile Cancer using DenseNet and Transfer Learning. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 4: VISAPP, Online, 6–8 February 2022; pp. 976–983. [Google Scholar]
- Reenadevi, R.; Sathiya, T.; Sathiyabhama, B. Breast cancer histopathological image classification using augmentation based on optimized deep ResNet-152 structure. Ann. Rom. Soc. Cell Biol. 2021, 25, 5866–5874. [Google Scholar]
- Wang, C.-W.; Lee, Y.-C.; Chang, C.-C.; Lin, Y.-J.; Liou, Y.-A.; Hsu, P.-C.; Chang, C.-C.; Sai, A.-K.; Wang, C.-H.; Chao, T.-K. A weakly supervised deep learning method for guiding ovarian cancer treatment and identifying an effective biomarker. Cancers 2022, 14, 1651. [Google Scholar] [CrossRef]
- Samee, N.A.; Atteia, G.; Meshoul, S.; Al-antari, M.A.; Kadah, Y.M. Deep Learning Cascaded Feature Selection Framework for Breast Cancer Classification: Hybrid CNN with Univariate-Based Approach. Mathematics 2022, 10, 3631. [Google Scholar] [CrossRef]
- Allegra, A.; Tonacci, A.; Sciaccotta, R.; Genovese, S.; Musolino, C.; Pioggia, G.; Gangemi, S. Machine learning and deep learning applications in multiple myeloma diagnosis, prognosis, and treatment selection. Cancers 2022, 14, 606. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Fu, C.C.; Lv, L.; Ye, Q.; Yu, Y.; Fang, Q.; Zhang, L.; Hou, L.; Wu, C. Deep convolutional neural network-based classification of cancer cells on cytological pleural effusion images. Mod. Pathol. 2022, 35, 609–614. [Google Scholar] [CrossRef] [PubMed]
- Gadermayr, M.; Koller, L.; Tschuchnig, M.; Stangassinger, L.M.; Kreutzer, C.; Couillard-Despres, S.; Oostingh, J.G.; Hittmair, A. MixUp-MIL: Novel Data Augmentation for Multiple Instance Learning and a Study on Thyroid Cancer Diagnosis. arXiv 2022, arXiv:2211.05862. [Google Scholar]
- Jimenez-del-Toro, O.; Otálora, S.; Andersson, M.; Eurén, K.; Hedlund, M.; Rousson, M.; Müller, H.; Atzori, M. Analysis of histopathology images: From traditional machine learning. In Biomedical Texture Analysis; Academic Press: Cambridge, MA, USA, 2017; pp. 281–314. [Google Scholar]
- Komura, D.; Ishikawa, S. Machine learning methods for histopathological image analysis. Comput. Struct. Biotechnol. J. 2018, 16, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Warner, E.; Shaikhouni, S.; Bitzer, M.; Kretzler, M.; Gipson, D.; Pennathur, S.; Bellovich, K.; Bhat, Z.; Gadegbeku, C.; et al. Unsupervised machine learning for identifying important visual features through bag-of-words using histopathology data from chronic kidney disease. Sci. Rep. 2022, 12, 4832. [Google Scholar] [CrossRef] [PubMed]
- Ahamed, S.B.; Shamsudheen, S.; Balobaid, A.S. Deep Learning Approaches, Algorithms, and Applications in Bioinformatics. In Applications of Machine Learning and Deep Learning on Biological Data; Taylor & Francis: Abingdon, UK, 2023; p. 1. [Google Scholar]
- Bilal, M.; Nimir, M.; Snead, D.; Taylor, G.S.; Rajpoot, N. Role of AI and digital pathology for colorectal immuno-oncology. Br. J. Cancer 2022, 128, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Banerji, S.; Mitra, S. Deep learning in histopathology: A review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1439. [Google Scholar] [CrossRef]
- Lu, Z.; Xu, S.; Shao, W.; Wu, Y.; Zhang, J.; Han, Z.; Feng, Q.; Huang, K. Deep-learning–based characterization of tumor-infiltrating lymphocytes in breast cancers from histopathology images and multiomics data. JCO Clin. Cancer Inform. 2020, 4, 480–490. [Google Scholar] [CrossRef]
- Subramanian, H.; Subramanian, S. Improving diagnosis through digital pathology: Proof-of-concept implementation using smart contracts and decentralized file storage. J. Med. Internet Res. 2022, 24, e34207. [Google Scholar] [CrossRef]
- Han, Z.; Wei, B.; Zheng, Y.; Yin, Y.; Li, K.; Li, S. Breast cancer multi-classification from histopathological images with structured deep learning model. Sci Rep. 2017, 7, 4172. [Google Scholar] [CrossRef]
- Ahmedt-Aristizabal, D.; Armin, M.A.; Denman, S.; Fookes, C.; Petersson, L. A survey on graph-based deep learning for computational histopathology. Comput. Med. Imaging Graph. 2022, 95, 102027. [Google Scholar] [CrossRef] [PubMed]
- Bouteldja, N.; Klinkhammer, B.M.; Bülow, R.D.; Droste, P.; Otten, S.W.; von Stillfried, S.F.; Moellmann, J.; Sheehan, S.M.; Korstanje, R.; Menzel, S.; et al. Deep learning–based segmentation and quantification in experimental kidney histopathology. J. Am. Soc. Nephrol. 2021, 32, 52–68. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Zhang, B.; Topatana, W.; Cao, J.; Zhu, H.; Juengpanich, S.; Mao, Q.; Yu, H.; Cai, X. Classification and mutation prediction based on histopathology H&E images in liver cancer using deep learning. NPJ Precis. Oncol. 2020, 4, 14. [Google Scholar] [PubMed]
- Schaer, R.; Otálora, S.; Jimenez-del-Toro, O.; Atzori, M.; Müller, H. Deep learning-based retrieval system for gigapixel histopathology cases and the open access literature. J. Pathol. Inform. 2019, 10, 19. [Google Scholar] [CrossRef]
- Chaunzwa, T.L.; Hosny, A.; Xu, Y.; Shafer, A.; Diao, N.; Lanuti, M.; Christiani, D.C.; Mak, R.H.; Aerts, H.J. Deep learning classification of lung cancer histology using CT images. Sci. Rep. 2021, 11, 5471. [Google Scholar] [CrossRef]
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. IJSR 2020, 9, 381–386. [Google Scholar]
- Sari, C.T.; Gunduz-Demir, C. Unsupervised feature extraction via deep learning for histopathological classification of colon tissue images. IEEE Trans. Med. Imaging 2018, 38, 1139–1149. [Google Scholar] [CrossRef] [Green Version]
- Huss, R.; Coupland, S.E. Software-assisted decision support in digital histopathology. J. Pathol. 2020, 250, 685–692. [Google Scholar] [CrossRef] [Green Version]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2022, 7, 100198. [Google Scholar] [CrossRef]
- Byra, M.; Jarosik, P.; Szubert, A.; Galperin, M.; Ojeda-Fournier, H.; Olson, L.; O’Boyle, M.; Comstock, C.; Andre, M. Breast mass segmentation in ultrasound with selective kernel U-Net convolutional neural network. Biomed. Signal Process. Control. 2020, 61, 102027. [Google Scholar] [CrossRef]
- Jiang, Y.; Sui, X.; Ding, Y.; Xiao, W.; Zheng, Y.; Zhang, Y. A semi-supervised learning approach with consistency regularization for tumor histopathological images analysis. Front. Oncol. 2022, 12, 7200. [Google Scholar] [CrossRef]
- Nugroho, A.; Suhartanto, H. Hyper-parameter tuning based on random search for densenet optimization. In Proceedings of the 2020 7th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Semarang, Indonesia, 24–25 September 2020; pp. 96–99. [Google Scholar]
- Khanam, J.J.; Foo, S.Y. A comparison of machine learning algorithms for diabetes prediction. ICT Express 2021, 7, 432–439. [Google Scholar] [CrossRef]
- Li, Y.; Wei, C.; Ma, T. Towards explaining the regularization effect of initial large learning rate in training neural networks. In Proceedings of the NIPS’19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chikontwe, P.; Sung, H.J.; Jeong, J.; Kim, M.; Go, H.; Nam, S.J.; Park, S.H. Weakly supervised segmentation on neural compressed histopathology with self-equivariant regularization. Med. Image Anal. 2022, 80, 102482. [Google Scholar] [CrossRef]
- Buddhavarapu, V.G. An experimental study on classification of thyroid histopathology images using transfer learning. Pattern Recognit. Lett. 2020, 140, 1–9. [Google Scholar] [CrossRef]
- Kumar, S.K. On weight initialization in deep neural networks. arXiv 2017, arXiv:1704.08863. [Google Scholar]
- Zhang, H.; Feng, L.; Zhang, X.; Yang, Y.; Li, J. Necessary conditions for convergence of CNNs and initialization of convolution kernels. Digit. Signal Process. 2022, 123, 103397. [Google Scholar] [CrossRef]
- Singh, P.; Muchahari, M.K. Solving multi-objective optimization problem of convolutional neural network using fast forward quantum optimization algorithm: Application in digital image classification. Adv. Eng. Softw. 2023, 176, 103370. [Google Scholar] [CrossRef]
- Srikantamurthy, M.M.; Rallabandi, V.P.; Dudekula, D.B.; Natarajan, S.; Park, J. Classification of benign and malignant subtypes of breast cancer histopathology imaging using hybrid CNN-LSTM based transfer learning. BMC Med. Imaging 2023, 23, 19. [Google Scholar] [CrossRef]
- Gour, M.; Jain, S.; Shankar, U. Application of Deep Learning Techniques for Prostate Cancer Grading Using Histopathological Images. In Computer Vision and Image Processing: 6th International Conference, CVIP 2021, Rupnagar, India, December 3–5, 2021, Revised Selected Papers, Part I; Springer International Publishing: Cham, Switzerland, 2022; pp. 83–94. [Google Scholar]
- Krishna, S.; Krishnamoorthy, S.; Bhavsar, A. Stain normalized breast histopathology image recognition using convolutional neural networks for cancer detection. arXiv 2022, arXiv:2201.00957. [Google Scholar]
- Uthatham, A.; Yodrabum, N.; Sinmaroeng, C.; Titijaroonroj, T. Automatic Lymph Node Classification with Convolutional Neural Network. In Proceedings of the 2022 14th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 18–19 October 2022; pp. 1–6. [Google Scholar]
- Li, X.; Cen, M.; Xu, J.; Zhang, H.; Xu, X.S. Improving feature extraction from histopathological images through a fine-tuning ImageNet model. J. Pathol. Inform. 2022, 13, 100115. [Google Scholar] [CrossRef]
- Wu, C.T.; Lin, P.H.; Huang, S.Y.; Tseng, Y.J.; Chang, H.T.; Li, S.Y.; Yen, H.W. Revisiting alloy design of low-modulus biomedical β-Ti alloys using an artificial neural network. Materialia 2022, 21, 101313. [Google Scholar] [CrossRef]
- Wright, L.; Demeure, N. Ranger21: A synergistic deep learning optimizer. arXiv 2021, arXiv:2106.13731. [Google Scholar]
- Wang, P.; Li, P.; Li, Y.; Wang, J.; Xu, J. Histopathological image classification based on cross-domain deep transferred feature fusion. Biomed. Signal Process. Control. 2021, 68, 102705. [Google Scholar] [CrossRef]
- Akossi, A.; Wang, F.; Teodoro, G.; Kong, J. Image registration with optimal regularization parameter selection by learned auto encoder features. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 702–705. [Google Scholar]
- Moshkov, N.; Mathe, B.; Kertesz-Farkas, A.; Hollandi, R.; Horvath, P. Test-time augmentation for deep learning-based cell segmentation on microscopy images. Sci. Rep. 2020, 10, 5068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, C.P.; Vo, A.H.; Nguyen, B.T. Breast cancer histology image classification using deep learning. In Proceedings of the 2019 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 366–370. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AUC (Area under the Curve) | ||
|---|---|---|
| Model | Using Augmentation | Not Using Augmentation |
| ResNet50 | 0.95001 | 0.93988 |
| DenseNet121 | 0.95511 | 0.93780 |
| AUC (Area under the Curve) | ||
|---|---|---|
| Model | Using Augmentation | Not Using Augmentation |
| ResNet50 | 0.96501 | 0.99297 |
| DenseNet121 | 0.98891 | 0.99971 |
| AUC (Area under the Curve) | ||
|---|---|---|
| Model | ImageNet Weights | Xavier Initialization Weights |
| DenseNet121 | 0.95672 | 0.94560 |
| ResNet50 | 0.95078 | 0.94380 |
| ResNet50 V2 | 0.95078 | 0.94380 |
| MobileNetV1 | 0.94954 | 0.93855 |
| MobileNetV2 | 0.95065 | 0.95395 |
| Inception | 0.94697 | 0.94608 |
| EfficientNetB0 | 0.95121 | 0.94608 |
| EfficientNetB1 | 0.93876 | 0.94608 |
| EfficientNetB0 V2 | 0.94570 | 0.75981 |
| EfficientNetB1 V2 | 0.94287 | 0.79871 |
| Learning Iteration | AUC |
|---|---|
| Reusing weights | 0.95501 |
| New initialization 1 | 0.95498 |
| New initialization 2 | 0.95508 |
| New initialization 3 | 0.95505 |
| Learning Iteration | AUC |
|---|---|
| SGD | 0.95510 |
| Adam | 0.95475 |
| AdamW | 0.95515 |
| Ranger | 0.95500 |
| AUC (Area under the Curve) | ||
|---|---|---|
| Ensemble Type | AUC | Difference |
| DenseNet121 | 0.95672 | - |
| M-model training 5 outputs together | 0.95405 | −0.267% |
| M-model training 5 outputs separately | 0.95491 | −0.1891% |
| MS-model | 0.95508 | −0.164% |
| MS-model with AdamW | 0.95515 | −0.157% |
| MS-model with repeated training | 0.95911 | 0.239% |
| MS-model TTA | 0.96870 | 1.198% |
| MS-model ensemble | 0.96592 | 0.920% |
| MS-model connecting weights | 0.96240 | 0.568% |
| TTA + weights and models ensemble | 0.96922 | 1.250% |
| MS-model after corrections | 0.96147 | 0.475% |
| MS-model after corrections with repeated training | 0.96675 | 1.003% |
| Group of ensembles from all experiments | 0.96977 | 1.305% |
| Optimized ensemble based on the best model | 0.97673 | 2.001% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kundrotas, M.; Mažonienė, E.; Šešok, D. Automatic Tumor Identification from Scans of Histopathological Tissues. Appl. Sci. 2023, 13, 4333. https://doi.org/10.3390/app13074333
Kundrotas M, Mažonienė E, Šešok D. Automatic Tumor Identification from Scans of Histopathological Tissues. Applied Sciences. 2023; 13(7):4333. https://doi.org/10.3390/app13074333
Chicago/Turabian StyleKundrotas, Mantas, Edita Mažonienė, and Dmitrij Šešok. 2023. "Automatic Tumor Identification from Scans of Histopathological Tissues" Applied Sciences 13, no. 7: 4333. https://doi.org/10.3390/app13074333
APA StyleKundrotas, M., Mažonienė, E., & Šešok, D. (2023). Automatic Tumor Identification from Scans of Histopathological Tissues. Applied Sciences, 13(7), 4333. https://doi.org/10.3390/app13074333