1. Introduction
Currently, data have become something within people’s reach, and more and more people are becoming aware of the ownership and usage of their data. What is “data confirmation”? The purpose of data confirmation is to legally establish ownership of the data and the right of the data owner to determine who can have access to the data. Data confirmation requires determining the type of rights, how they will be acquired, and how they will be distributed. With the popularity of cloud computing, people have begun to share data. There are many ways to share data, such as uploading to third-party trading platforms, cloud servers, Github [
1], etc., resulting in the inability to ensure the privacy of users. Many scholars have begun to study data sharing, privacy issues [
2,
3], and how data are uploaded. In addition, the speed of data dissemination is extremely fast. Meng et al. [
4] modeled network public opinion data to predict public opinion crisis warnings. Cao et al. [
5] proposed a more comprehensive recommendation scheme based on real-world shared mobile data. The proposal of ciphertext-policy attribute-based encryption provides a good answer to these problems. CP-ABE allows the data owner to specify that only those who conform to the access policy can access the data.
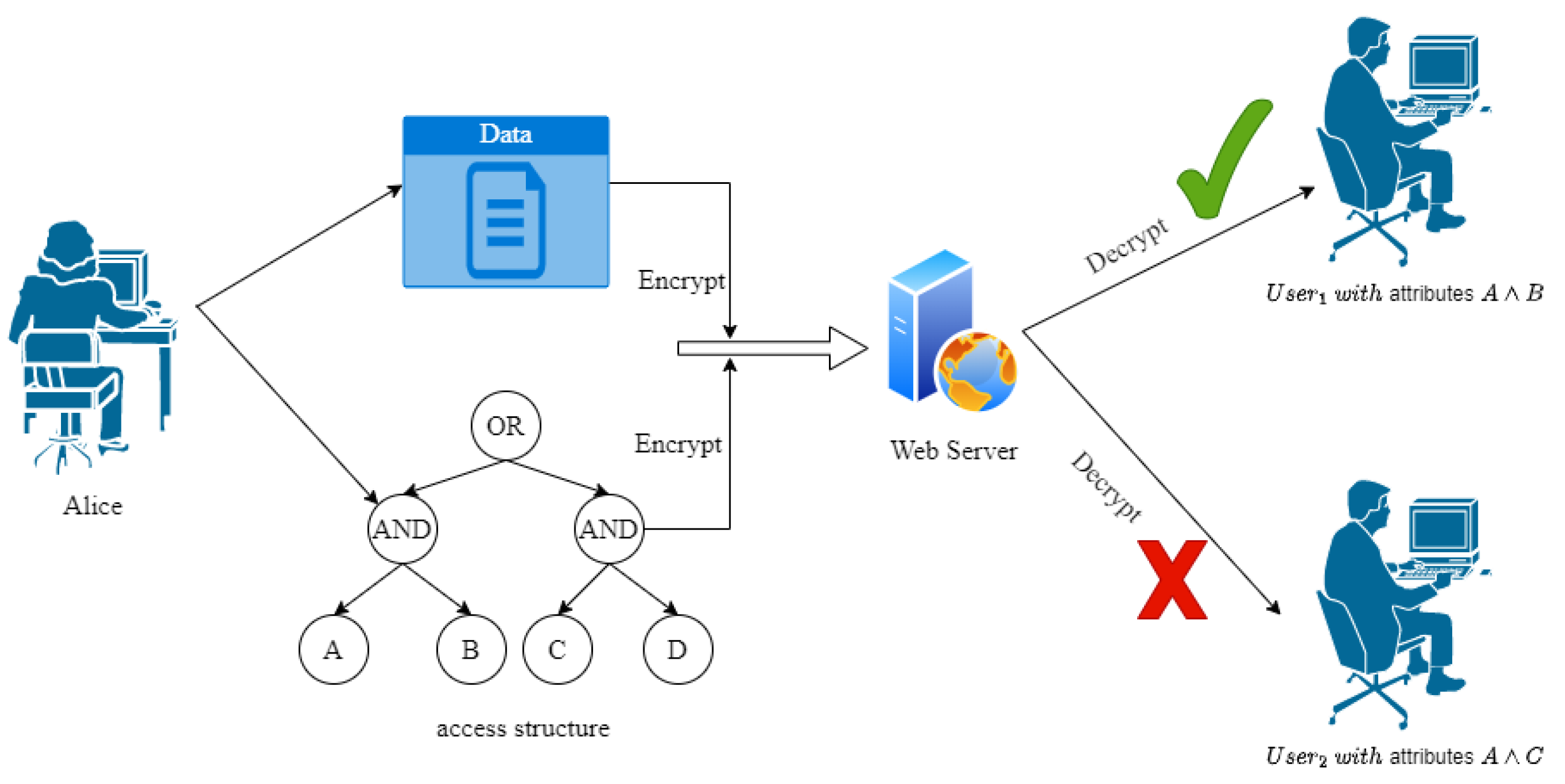
Figure 1 shows the execution process of CP-ABE. The data owner Alice has some data
, and she sets a set of access policies (
in the figure) according to the potential user subjectively, and combines
with access policies to encrypt and upload to the server. At this time, there are two users
and
in the system;
has attributes
A and
B, and
has attributes
A and
C, then according to the access policies in the ciphertext,
can decrypt and access the data, but
fails to decrypt. However, due to the replicability of the data, ownership of the data cannot be determined. The development of blockchain [
6,
7,
8] has brought the possibility of data rights confirmation. Due to its immutability and traceability, the information of the data owner cannot be tampered with once it is on the chain, and it can be easily traced back to the source and destination of the data. However, as a result of the decentralized and public nature of blockchain technology, the privacy of the data owner cannot be guaranteed. Using traditional third-party hosting or issuing certificates of ownership does not guarantee that the data owner’s source data will not be leaked. Therefore, there is the need of a scheme that solves the above problems.
Consider the following scenario: Alice wants to store her data on the cloud and share them with others, but she only wants a specific group of people to access the data. Therefore, she specifies an access policy and encrypts the data using CP-ABE before uploading it. Bob is a member of Alice’s designated group, and he retrieves and decrypts the data from the cloud. Smith is Bob’s friend, but he is not a part of the designated group. Smith contacts Bob and obtains a copy of the data. One day, Alice discovers that Smith is using her data and wants to seek compensation. However, Smith claims that the data are his own. How can Alice prove that the data belong to her?
In 2005, Sahai and Waters [
9] introduced the notion of fuzzy identity-based encryption. which was later extended to attribute-based encryption (ABE). In an ABE system, the ciphertext and key are associated with the attribute set and access structure, and decryption only succeeds when the attribute set satisfies the access structure. Goyal et al. [
10] suggested correlating the access policy with the ciphertext and key, respectively, and divided ABE for the first time into ciphertext-policy attribute-based encryption (CP-ABE) and key-policy attribute-based encryption (KP-ABE) in 2006. Bethencourt et al. [
11] introduced the first CP-ABE system in 2007, embedding the access tree structure within ciphertext; however, it is challenging to deploy in practice. Waters et al. [
12] built on Bethencourt et al.’s work in the following year and proposed a CP-ABE system with an efficient general access structure while also proving selection security under the standard model. In 2012, Lewko and Waters [
13] developed a broad strategy for converting the standard model’s concept of selection security into adaptive security. In today’s cloud computing, CP-ABE has a significant influence. In 2015, Ning et al. [
14] proposed a traceable and auditable CP-ABE scheme in cloud computing to address key abuse by dishonest users in the cloud storage environment [
15], but it does not provide key revocation. Yu et al. [
16] proposed a traceable and undeniable CP-ABE scheme based on Ning’s work to solve the problem of semi-honest institutions illegally selling keys.
Under the big data environment [
17], data can be used to verify the validity of the protocol [
18] and can also be used to train the robot [
19]. However, these web data have no real ownership. Yun Peng et al. [
20] investigated the basic challenges surrounding data confirmation in 2016. Bing Guo et al. [
21] presented a service system to defend the property rights of personal data in 2017. Shuaiyu Wang et al. [
22] suggested a large data correct confirmation technique based on blockchain technology in the same year, but the issue is that the data source cannot be verified. In 2018, Hailong Wang and his colleagues [
23] introduced a novel approach for verifying big data using blockchain and digital watermarking technology, but the authority agency can access the data owner’s source data. Although this solution can be applied to the environment of cloud storage, due to the limitation of its form of plaintext confirmation, the privacy of users cannot be guaranteed. Zhao et al. [
24] developed a smart contract-based big data property right confirmation system the following year. In 2021, Zhou et al. [
25] proposed a data ownership confirmation scheme based on consortium blockchain in IoT environments [
26], with a focus on controlling the flow of data. However, the scheme cannot be applied to one-to-many environments such as cloud storage. Professors Jintai Ding and Ke Tang from Tsinghua University announced their plans to develop an innovative solution for managing large-scale data transactions. Their approach involves leveraging cutting-edge cryptography techniques and advanced mechanisms for economic design to create a robust and effective system for processing and exchanging data. By combining these two technologies, they aim to address the unique challenges associated with managing and securing large volumes of data, ultimately providing a reliable and efficient solution for businesses and organizations worldwide. This technique assures data transaction security while also increasing transaction efficiency. In 2022, Liu et al. [
27] proposed a data ownership confirmation scheme based on the Ethereum blockchain and smart contracts. The parties authenticate their identities through a protocol for generating data fingerprints based on smart contracts. However, the article did not address the issue of user privacy protection on the public blockchain.
Based on the research status above, we propose a new data confirmation scheme in the cloud storage environment, focusing on user privacy protection and preventing the leakage of original plaintext data. The scheme can effectively protect the privacy of data owners while ensuring data confirmation, and in the process of confirmation, no one can access plaintext, thus reducing the risk of data leakage. We embed the data owner’s identification information into CP-ABE using Paillier encryption and change the plaintext confirmation form to the ciphertext confirmation form. An audit phase is introduced at the end of the confirmation process.
Our contributions are as follows:
- (1)
User privacy protection. We propose a new data confirmation scheme based on CP-ABE in the cloud storage environment. Users only need to embed the information with their own identity into the ciphertext after Paillier encryption and upload it to the cloud. They do not need to worry about revealing their identity.
- (2)
Prevent original plaintext data leakage. During the entire right confirmation process, the authority can only access the ciphertext and only needs to process the ciphertext. This greatly reduces the risk of plaintext data leakage during the right confirmation process.
- (3)
The scheme is safe and efficient. We reduce the scheme to the three-prime subgroup decision problem and prove that the scheme is safe, and through experimental analysis, our scheme is almost as efficient as the scheme proposed by Allison et al. [
21] in terms of system setup, key generation, encryption, and encryption algorithms.
Table 1 shows the comparison between our scheme and other data confirmation schemes.
Section 2 will present a formal definition and explanation of several fundamental concepts.
Section 3 will focus on constructing the scheme, which will include defining the security requirements, implementing the scheme, and providing a security proof. In
Section 4, we will conduct experiments and analysis to evaluate the effectiveness of the scheme. Finally,
Section 5 will summarize the scheme and its contributions.
3. Construction
3.1. Membership
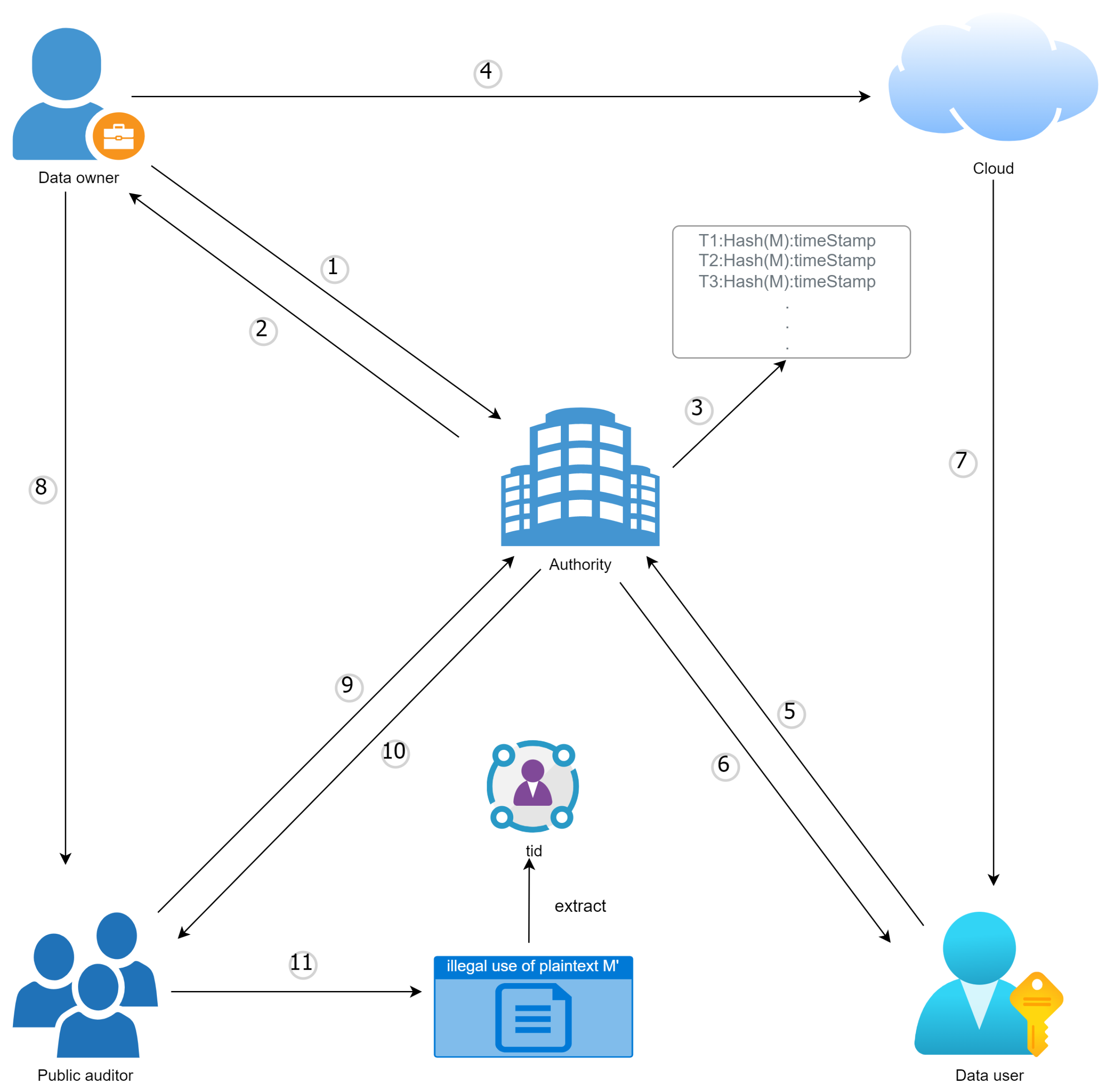
Our system consists of five parties (as shown in
Figure 2). The data owner
is in charge of data encryption and uploading. The data user
is responsible for retrieving and decrypting the data submitted by the data owner from the cloud. The authority
is in charge of giving decryption keys to data users, participating in the ciphertext’s signature, and storing the credentials of the data owner. The public auditor
is in charge of publicly auditing the ciphertext and extracting the information of the ciphertext owner from credentials. Finally, the cloud server
is responsible for storing the ciphertext uploaded by the data owner.
3.2. Security
3.2.1. IND-CPA Security
We can rephrase the description of the
security game process for our proposed scheme, which is equivalent to the one proposed by Allison et al. [
21], as follows:
- –
: The adversary is given the public parameter after the challenger calls the algorithm.
- –
: Adversary can dynamically request the decryption keys associated with attribute sets from the challenger . In response, executes the key generation algorithm to generate and sends it to .
- –
: Adversary provides two equal-length messages and and a generator matrix that corresponds to an access structure that does not satisfy to the challenger . Then randomly chooses a bit and generates the ciphertext by calling the encryption algorithm with , , , and . Finally, sends to adversary .
- –
: Adversary keeps asking for decryption keys corresponding to attribute sets , where each set cannot satisfy the access structure . Upon each request, calls the key generation algorithm and sends to adversary .
- –
: outputs a guess .
The advantage of the adversary in this game is defined as:
Definition 7. If we assume that any adversary with polynomial time has only a negligible advantage in winning the aforementioned game, we can confidently assert that our scheme is secure.
3.2.2. Dishonest User Game (Non-Replicability of Ciphertext)
The dishonest user game of this scheme is defined as follows: A user attempts to confuse the auditor by forging the authority’s signature and republishing a ciphertext. The game is played by a challenger and an adversary.
–: Challenger starts the algorithm and sends the public parameters and to the attacker .
: Challenger generates the ciphertext through the algorithm and sends it to ; generates a new ciphertext according to the initial ciphertext .
:
If and then we say that the attacker successfully copies the ciphertext.
The adversary’s advantage in the dishonest user game is defined as
Definition 8. If the probability of a polynomial-time adversary winning the game described above is negligible, then we consider the ciphertext of our scheme to be secure and irreproducible.
In order to satisfy the requirement of data confirmation, the conventional CP-ABE scheme is insufficient. To ensure auditing capabilities in our CP-ABE scheme, we have developed a method that involves incorporating the data owner’s unique identifier (such as an address or ID number) into the ciphertext using Paillier encryption. The process of our scheme is illustrated in
Figure 3.
3.3. Implementation
: In the setup phase of our system, we provide the security parameter
and the user attribute universe
U as inputs to the setup algorithm. This algorithm then generates a group
G of order
, a mapping
e, an integer group
, and a hash function
. This setup process establishes the necessary parameters and functions to enable secure and efficient cryptographic operations in our system. The resulting setup allows us to implement our system in a manner that satisfies our security and performance requirements. Then the system proceeds to select random parameters
, and the generator
. For each attribute
, the system randomly selects a corresponding value
. The system global parameter is set as
( and is a generator) and is sent to the authority ; performs the following steps locally: randomly selecting two safe large primes p and q, which satisfy , calculating , and then randomly selecting a positive integer that is less than . Next, AT computes and randomly selects a value . The public parameter is generated, whereas the private key is stored locally.
: The unique identifier (e.g., ID number, address, mailbox, etc.) is hashed by data owner
and mapped to an integer in
, denoted as
After mapping the data owner’s unique identifier to an integer in
,
chooses a value
and employs Paillier encryption to generate the encrypted output
. The Algorithm 1 is as follows (here we assume the unique identifier string is
):
| Algorithm 1 Encrypt |
| Input:
|
- 1:
← Convert to a byte array after hashing; - 2:
- 3:
- 4:
|
| Output: |
|
= 79847630022358710946125273965671104052858 065717629025639108307113838327353
|
: To encode the access structure for the data, the owner of the data,
, creates a shared generator matrix
A with dimensions
l by
n using the LSSS. First, a secret number
is randomly selected. Then,
random numbers
are selected to generate a vector
. Finally, random numbers
are chosen for each row
of matrix
A(
that represents the entire set of
),
is obtained by taking a hash of the plaintext
M and mapping it to
to generate ciphertext:
: Both
and
T are sent to the authority
for decryption. The decryption process begins with
decrypting
using the following method:
After successfully decrypting
, the authority
checks if it already has a record of
in its database. If a record already exists, the application is rejected; otherwise,
utilizes their private key
to sign the message and generates
and stores the data credentials of
in the local database in the form of
. By following this process, it is guaranteed that there is only one legitimate owner associated with the original data source. This measure also serves as a safeguard against any attempts by malicious actors to produce ciphertext and assert false ownership over the data. Furthermore, this also serves to prevent
from directly accessing the plaintext, which enhances the security of the system. Finally,
is sent back to the data owner
for further processing. The user credentials setting Algorithm 2 is as follows:
| Algorithm 2 Store user credentials |
| Input:
, , T |
- 1:
Divide by to get ; - 2:
if Retrieving locally is empty then - 3:
Element P = ; - 4:
Date = Get the current time through the time function; - 5:
← (T,,); - 6:
end if - 7:
return ;
|
:
first calculates
after receiving
, afterwards, the ciphertext is assigned the value
and uploads
to the cloud.
Note: A notable characteristic of this scheme is the possibility of having multiple owners for a given , which is made feasible by the additive homomorphism property of Paillier encryption. For example, in a scenario where the data are jointly owned by two parties, denoted as and , they can both hash their unique identifiers and use them to generate separate ciphertexts and using different random numbers, then calculate , let .
During the entire encryption stage, we have realized data confirmation. Hash the plaintext and map it to for encryption() and send it to ; only needs to perform division and signature operations on , and store user ID T locally as a certificate. Therefore, cannot touch the plaintext.
- 3.
The generation of the decryption key in this scheme is a collaborative process between
and
;
first chooses a random number
as a parameter. Next,
forwards their personal set of attributes
S and the value
to “
as part of its request to generate a key. Then,
selects random numbers
and
to generate part of the decryption key
Finally,
transmits the decryption key
and a collection of values labeled as
to
, and
generates the decryption key locally using these values:
- 4.
The decryption key allows
to decrypt the ciphertext and obtain access to the data. The decryption algorithm searches for a vector
such that
, if the attributes of
do not satisfy the access policy, then there is only one vector
, such that
and
, the plaintext
M is obtained by the following formula:
- 5.
: If the data owner suspects that his data have been infringed upon or abused, he can prove his ownership by interacting with the public auditor and the authority . This interaction serves two purposes:
- (a)
To demonstrate that was the first to upload the data;
- (b)
To prove that the ciphertext corresponding to the data is indeed generated by .
: To prove that is the first to upload the data, the source data M and are sent by to the public auditor . obtains the hash value of the source data M by applying the hash function and sends it to the authority to identify the owner of the plaintext.
: First, PA carries out a comparison:
If they are equal, enter the extraction process using n, , defines , calculates , then by to extract the .
:
is needed to verify whether the given equation is valid or false.
Assuming the equation is satisfied, we can conclude that the data belong to the user
. Let us take the unique identifier
during encryption as an example: the decryption Algorithm 3 and the decrypted
are as follows:
| Algorithm 3 Decrypt |
- 1:
; - 2:
- 3:
|
| Output: |
| = 79847630022358710946125273965671104052858 065717629025639108307113838327353 |
If the data are generated by multiple users, then , verifies .
During the entire audit phase, needs to do two things:
- (1)
Compare whether the leaked plaintext is the same as that owned by and calculate whether the ciphertext is generated by through the formula ;
- (2)
Obtain the user credential T corresponding to the plaintext in the ’s database and obtain the owner of the plaintext through Paillier decryption.
3.5. IND-CPA Security
Suppose there is an adversary
who can eavesdrop on the channel between the user and the data owner, and he can obtain the ciphertext corresponding to the plaintext within a limited time, so as to crack the key and gain unlimited access to the ciphertext. Our scheme’s
security is analogous to the
security of the
scheme proposed by Allison and his colleagues in [
33], and we only prove Assumption 1 here. To begin with, we create a semi-functional ciphertext (defined as SF-C) and a semi-functional key (defined as SF-K) in the following format:
SF-C: We define as the generator element of the group . It randomly selects , for each attribute, selects , then selects for each row of the shared generator matrix and two random vectors , SF-C is defined as follows:
SF-K: We can create two types of SF-K by randomly selecting the parameters as follows:
(let )
Upon decrypting an SF-C with an SF-K, an additional term is introduced into the plaintext due to the semi-functional properties of the key and ciphertext:
where
represents the first item of the vector
. We will now introduce a series of games to analyze the security of our proposed scheme:
: In this game, both the ciphertext and the decryption key are valid, and the security of the scheme is not compromised.
: We define a game where all keys are normal, but the challenge ciphertext is SF-C. Let q be the number of times the attacker requests the key. For , we define:
: The challenge ciphertext is SF-C, the first keys requested by the adversary are SF-K of Type 2, the kth key is SF-K of Type 1, and the rest are normal. We define a game where the challenge ciphertext is SF-C, the first k keys are SF-K of Type 2, and the remaining keys are normal.
At the end of the game, we play the game’s last round (): all the keys are Type 2 SF-K, and the ciphertext is generated by semi-functionally encrypting random messages without using the two messages supplied by the adversary.
Lemma 1. Assume the existence of a polynomial-time algorithmsuch that. where ϵ is a non-negligible value. We can find a polynomial-time algorithm to break Assumption 1 by ϵ.
Proof. Sending
to
,
will simulate
or
with adversary
;
randomly selects
, and selects a random exponent
for each attribute in the system, then randomly selects two safe large prime numbers
such that
, calculates
, then randomly selects a positive integer
less than
, and
, the public parameter
and public key
are sent to
. □
Next,
sends two equal-length messages
,
T generated by his own unique identity and a shared generator matrix
to
,
implicitly sets
to the part of
(and possibly
element). Then,
flips a coin and pick
and sets:
then randomly selects
, sets the vector
, then sets
. We implicitly set
to
,
, so when
, it is a correctly distributed normal ciphertext.
If
, let
be the
part of
X (
), so
. Let
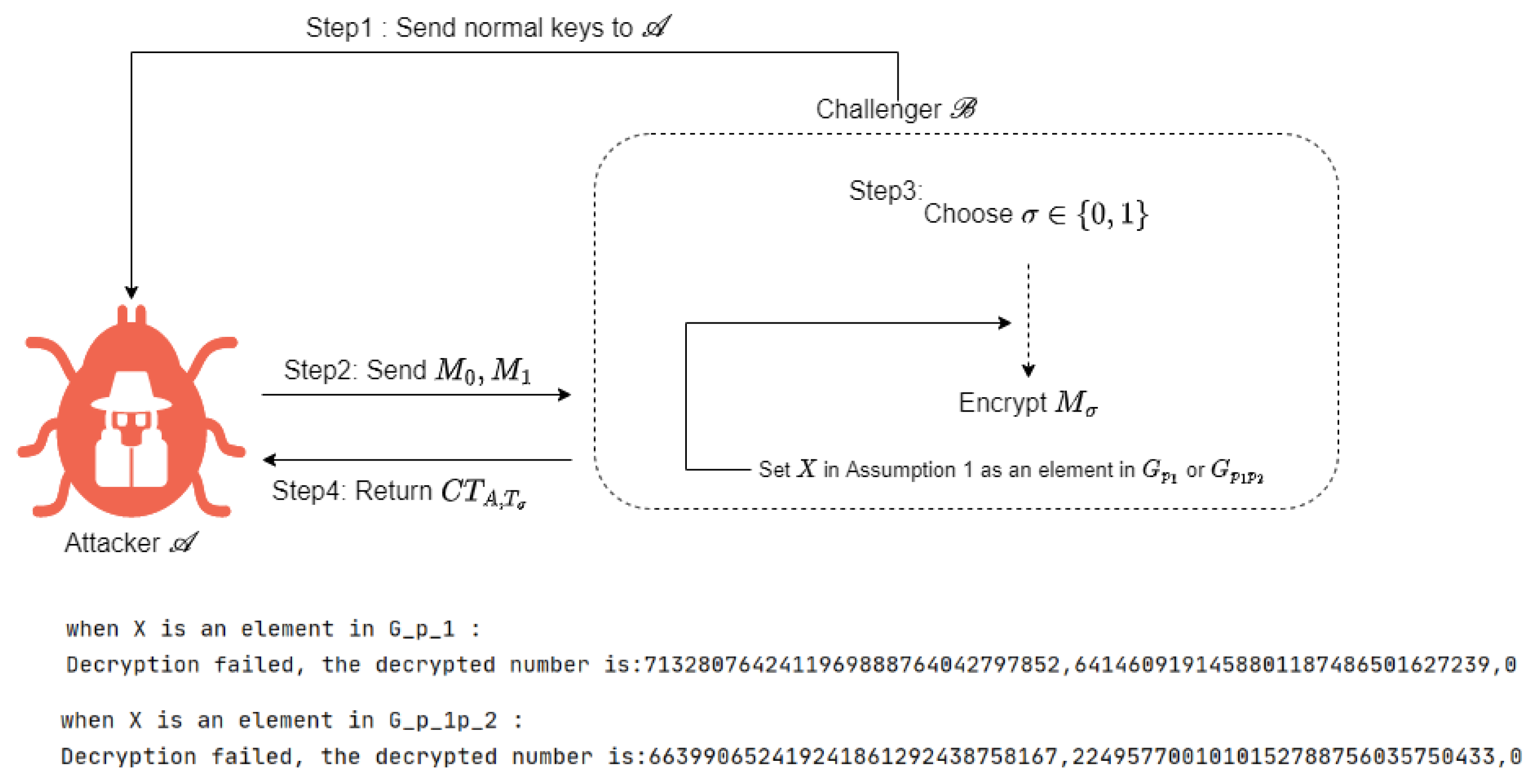
this is a correctly distributed semi-functional ciphertext. We simulated and ran local experiments to test our scheme against Choose Plaintext Attack, and in both
and
scenarios, attacker
was unable to decrypt the data.
Figure 4 illustrates the process of a chosen plaintext attack and the experimental results obtained by the attacker. Therefore,
can break Assumption 1 with the advantage of
.
Assumptions 2 and 3 can be proved by similar constructions above; see Allison’s scheme [
33] for details.
3.6. Ciphertext Non-Replicability
Suppose there is an adversary who can eavesdrop on the channel between the data owner and . The purpose of in this game is to obtain the signature of and embed its own in the ciphertext and replace the identity of the data owner in the ciphertext data with its own identity, so as to obtain the ownership of the data. We assume that the adversary will not send his identity information to without being able to copy the ciphertext (even if sent, it does not pass authentication).
Lemma 2. Assume that there is a polynomial-time algorithm that can break the CDH Assumption with the advantage of ϵ in the polynomial time, then we can construct a polynomial-time algorithm that falsifies ciphertext with the advantage of ϵ.
Proof. first runs the algorithm, and are sent to the adversary . □
Ciphertext generation: first interacts with to generate the ciphertext , and sends to . The adversary has two ways to generate its own ciphertext:
Case 1: After the adversary (dishonest user) decrypts the ciphertext and obtains the plaintext M, it regenerates the ciphertext by itself. This method is obviously not advisable, because even if the original decryption key of the ciphertext is generated, it is unable to decrypt and has been stored locally in the authority.
Case 2: The adversary obtains the signature and generates the ciphertext by eavesdropping on the channel between the data owner and , and sending information that is beneficial to to ; randomly selects , hashes the plaintext M and maps it to , and are sent to .
The adversary
attempts to generate a random number
such that
, so he can send
and his own identity
to obtain the signature of
, and then according to
algorithm to generate ciphertext and publishes it,
can obtain
after eavesdropping on the channel, by calculating
, he can get
, that is, the adversary
knows
and
, wants to calculate
. This is a
problem, there is no polynomial time algorithm to break it, so
4. Experiments and Analysis
In this section, we mainly analyze the efficiency of our scheme and compared it with the Fully secure CP-ABE scheme proposed by Allison et al. [
33] in setup, key generation, encryption, decryption, and memory consumption. The experiment is in the win10, 16GB, AMD Ryzen 5 R2600 Six -Core 3.40GHz platform. We choose to use the JPBC library of JAVA to build the environment and generate a composite order group with a size of 512 bits and an integer cyclic group with a size of 258 bits through an 83-bit elliptic curve. The data were obtained by running the experiments on a locally set up environment and were saved in a text file in “.xlsx” format. The figures were generated by comparing the data using MATLAB plotting.
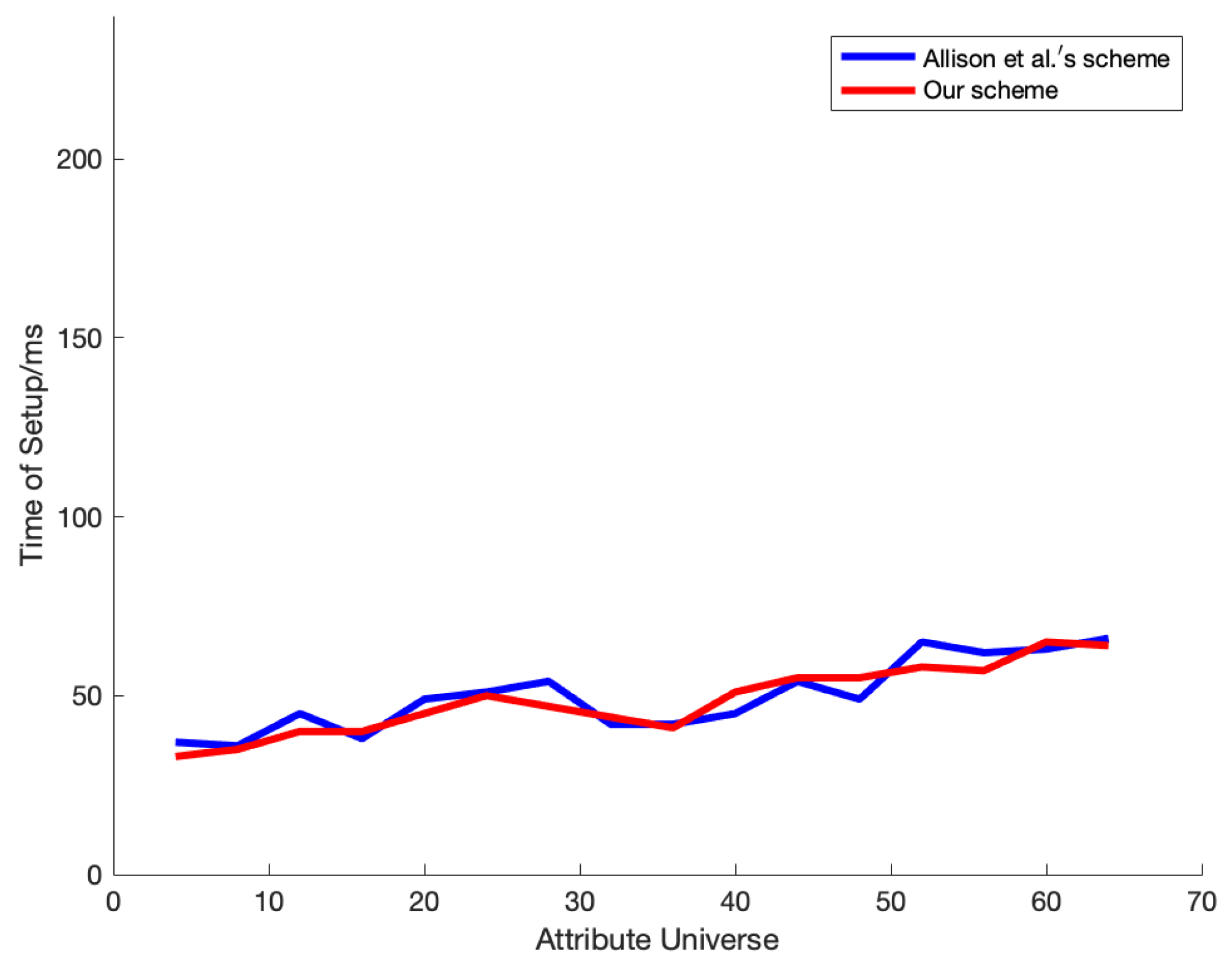
Figure 5 shows the setup comparison between our scheme and Allison et al.’s scheme. Since the complexity of the setup is
(
N represents the number of attributes in the attribute universe), the time efficiency is almost the same except for computer errors.
The master key is in the form of a key–value pair:
MSK:
alpha:210810353108659863024409106247517618452769941479846636980134442864523125 |
| 95818033429445987282464226795828802774079330 |
| |
| g3:507123706182628610741111547764849270218939290666858116887669480037266931236 |
| 6558956079248951460266712797586740186721012,3848333923503209101783513197106326 |
| 835379604308979589246948604032780415086659341351001892795149863403912326337017 |
| 537761,0 |
| |
| beta:3971351897302668818568847385425920497495147741445579066512932780617650627 |
| 246730432329467425793820791111050407589402 |
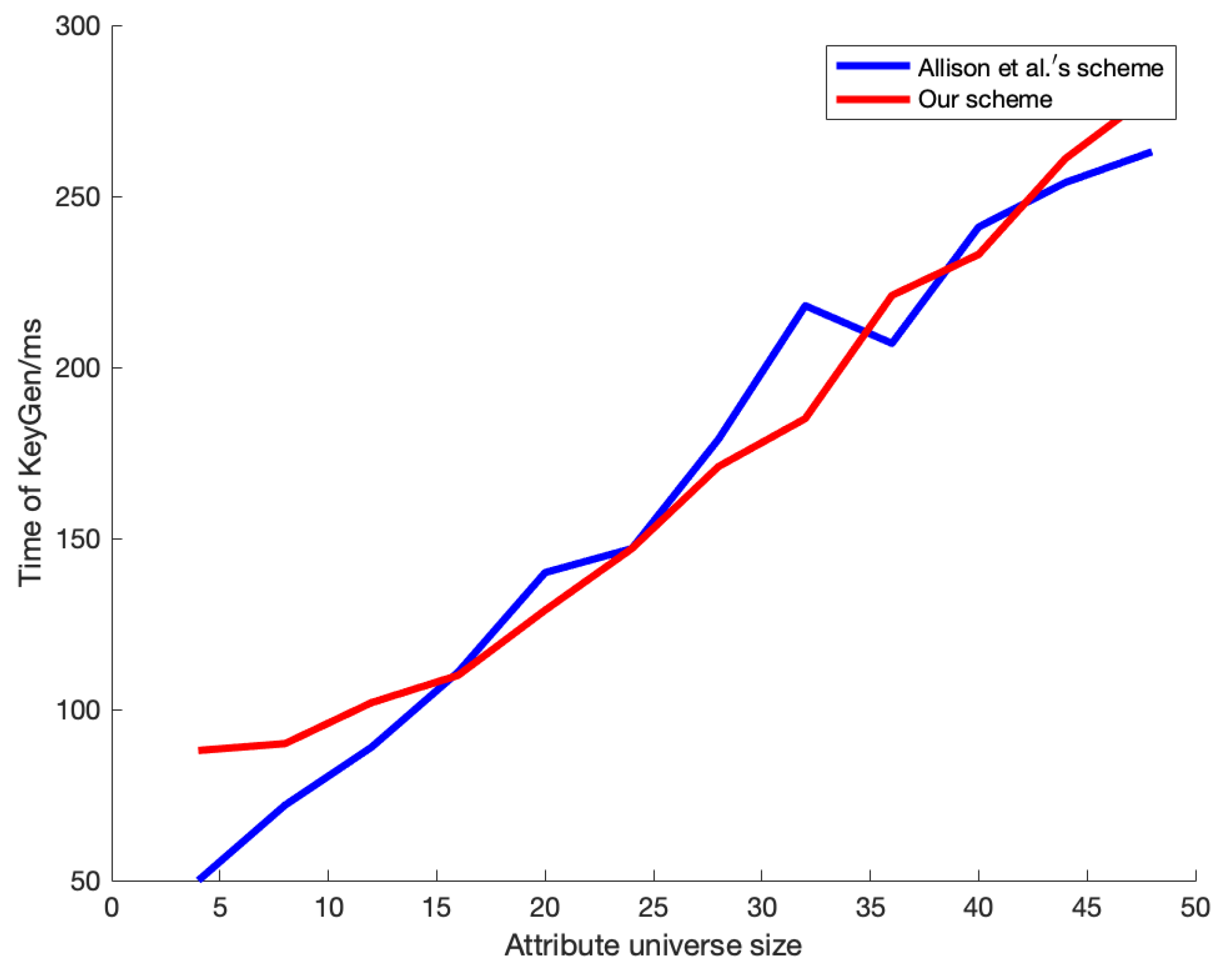
Figure 6 shows a comparison of the key generation time between our scheme and the scheme proposed by Allison et al. Our scheme involves interactive key generation, resulting in higher overhead compared to Allison’s scheme when the attribute space is small. However, as the attribute space grows, the performance gap between the two schemes decreases.
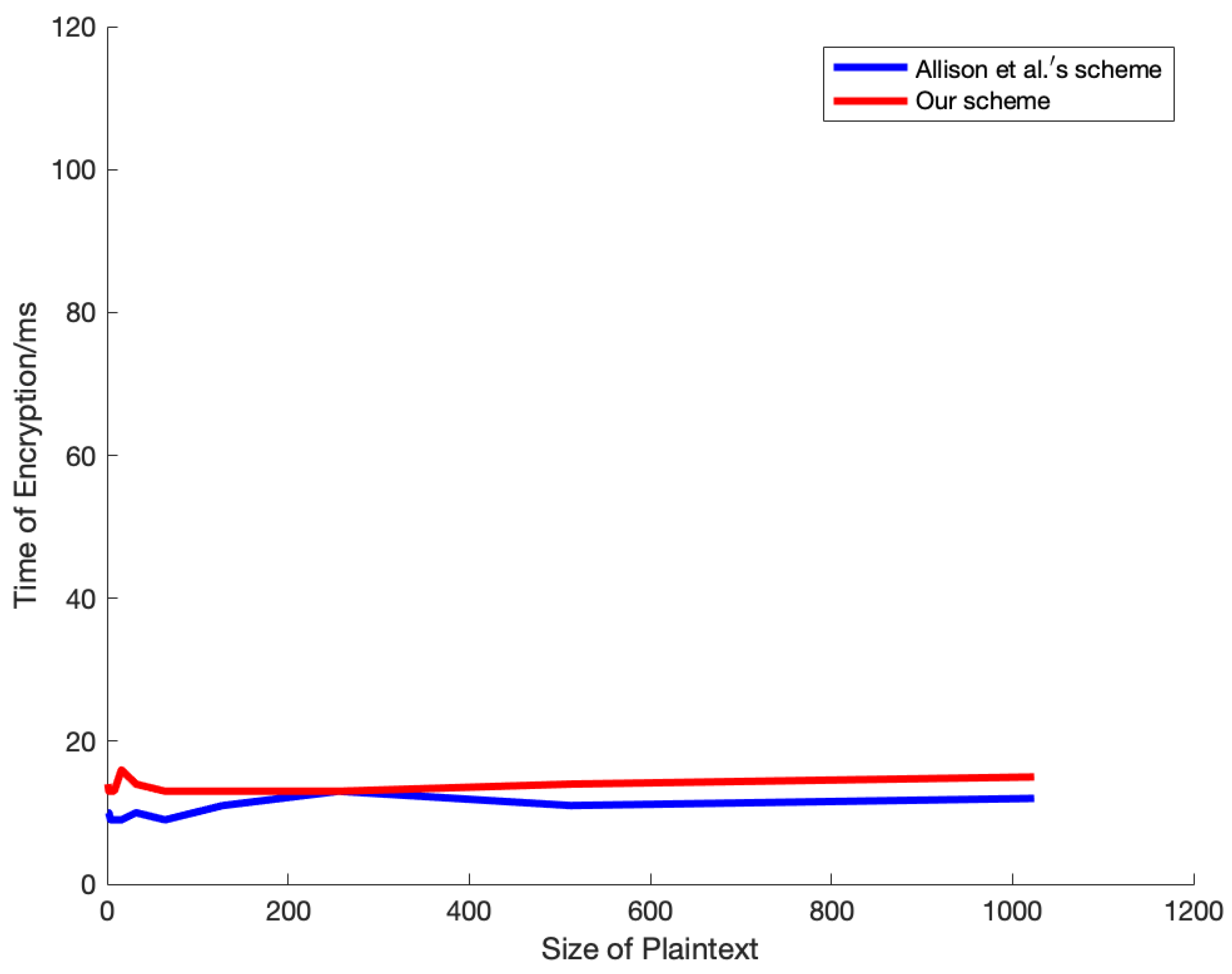
Figure 7 illustrates a comparison of the encryption time between our scheme and the scheme proposed by Allison et al. The ciphertext complexity of Allison et al.’s scheme is
, and the complexity of our scheme is also
, where
C represents the length of the ciphertext and
N represents the number of attributes in the attribute space. In fact, Allison et al.’s scheme involves
terms, whereas ours involves
terms, which results in a small difference in overhead.
The generated ciphertext is also stored in the form of key–value pairs. We take plaintext “
” as an example, and the encrypted
format is as follows:
| CT_AT: |
| C0_0:{x=18512619911661450195327750867443546794232624419671207238173221146535506 |
| 95552872207298169171836981828215064641158984234,y=70592147653957222146120442588 |
| 2624722810944092606551932879619145643069907176528665887436471753185725971617607 |
| 9123508797} |
| |
| C0_1:{x=10305743198129175737055428555819461127421625147813759967731163938926816 |
| 650740214215836427503578249751830703585598710737,y=9864469019751328170985532932 |
| 3260154136345304295214862269824474212174107344885351182673330718902818130451275 |
| 75927761095} |
| |
| C0_2:{x=85627632985010802758634299337508008509965737271381026168608890332725357 |
| 51769387446114503063186080075196481905182611275,y=69157043429120428487195645886 |
| 4787393452354723338419697486692137357841812076088296305720924512144895097136125 |
| 4706491542} |
| |
| C0_3:{x=85627632985010802758634299337508008509965737271381026168608890332725357 |
| 51769387446114503063186080075196481905182611275,y=69157043429120428487195645886 |
| 4787393452354723338419697486692137357841812076088296305720924512144895097136125 |
| 4706491542} |
| |
| C0_4:{x=10828209153804955834077646467569440299821102129146337294704720899926979 |
| 6582045437576244731444812151580842960742884772,y=411045008855643689234607591514 |
| 8105748998457729928230076680665408791706458037634503664240890763024397642409757 |
| 902239244} |
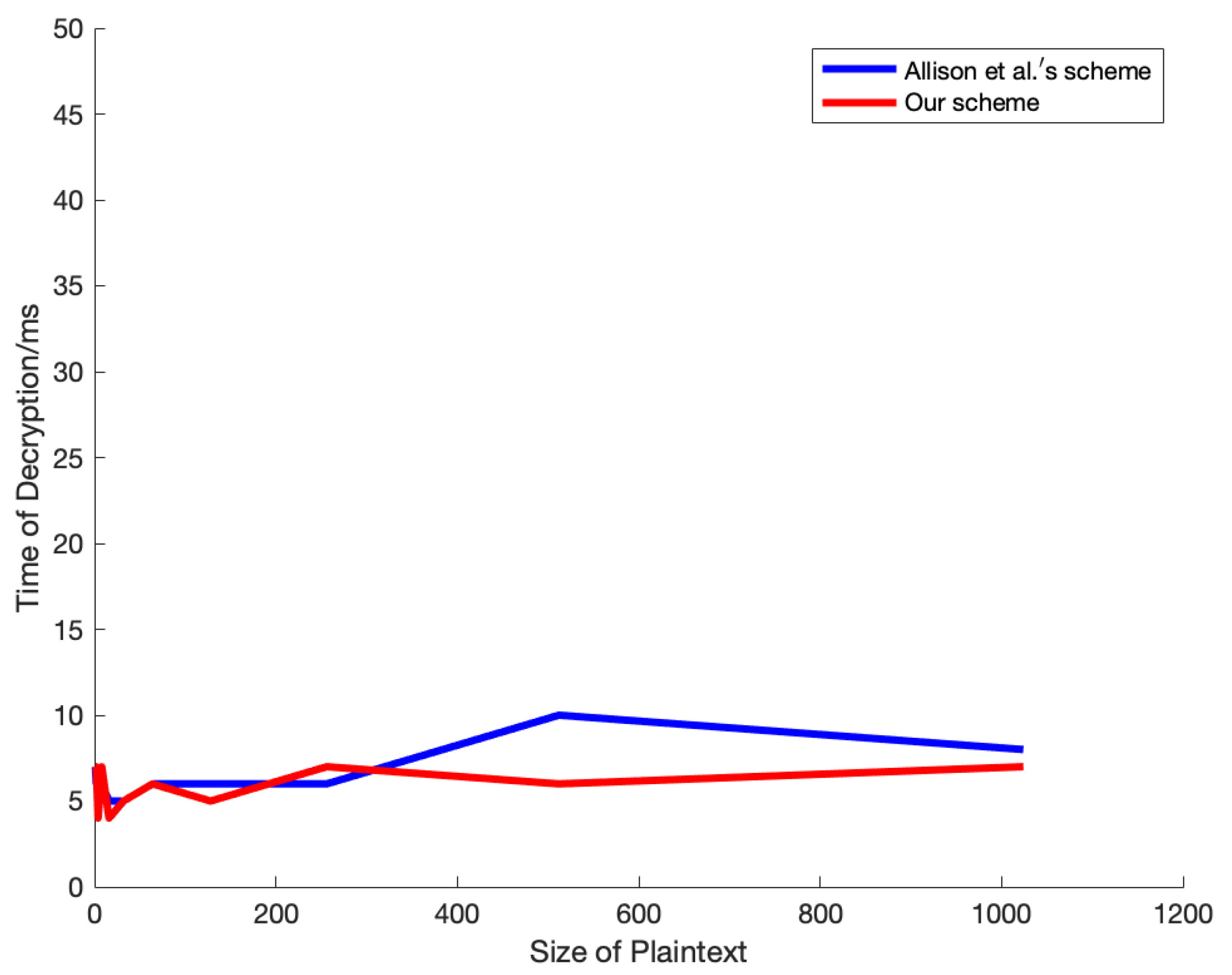
Figure 8 presents a comparison of the decryption time between our scheme and the scheme proposed by Allison et al. The time overhead is mainly focused on computing the secret
s, so apart from computational errors, there is no difference in overhead.
The plaintext obtained by decrypting the above ciphertext is as follows:
| ourScheme.Decrypt(“file/Key”,“file/CT_AT”); |
| The plaintext after decryption is:hello |
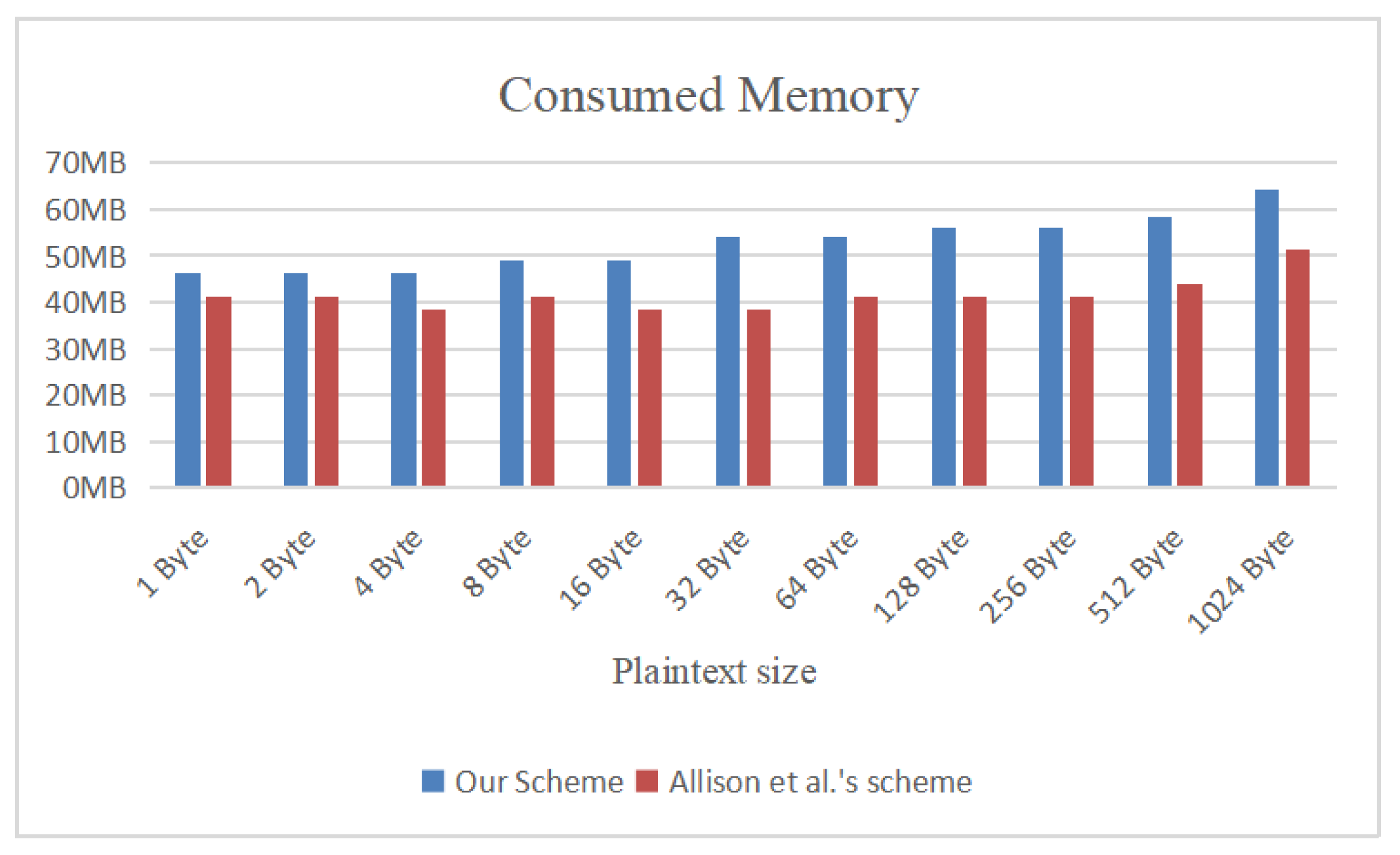
Finally,
Figure 9 shows a comparison of the memory overhead between our scheme and the scheme proposed by Allison et al. Due to the involvement of our scheme’s interactive functions, such as
,
, and
extraction function
, our scheme incurs a higher memory overhead than Allison et al.’s scheme.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}