
A Scheduling Method for Heterogeneous Signal Processing Platforms Based on Quantum Genetic Algorithm


Abstract
:1. Introduction
1.1. Research Status
1.2. Main Work and Contribution
- Quantum bits are mapped to the “0” and “1” codes in the binary. We transform the task scheduling problem in the macro to the optimization problem in the micro. The chromosome encoded by quantum bits is mapped to the serial number of the processor, and each individual represents a processor scheduling strategy.
- According to the quantum coherence, a new type of crossover is introduced—the “full- interference crossover”. It achieves crossover operations for all individuals in the population and solves the problem of getting stuck in a local optimum solution.
- Based on the data flow of the components in the task scheduling model, we have designed a task pre-sorting stage. The initial chromosome is encoded in conjunction with the task scheduling strategy in task preordering. It reduces the search space of the solution and improves performance.
1.3. Paper Organization
2. Platform Scheduling Model
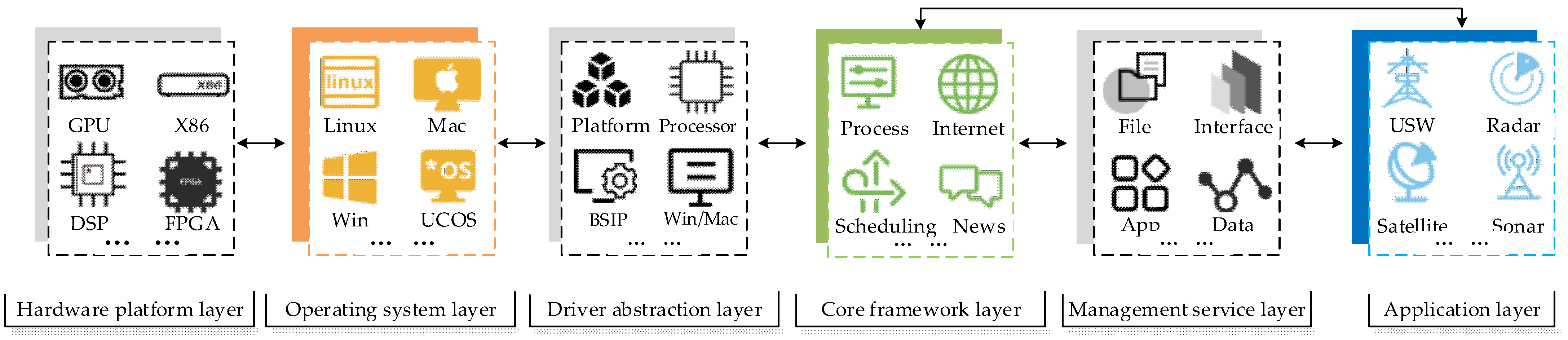
2.1. Heterogeneous Signal Processing Platform
2.2. Platform Task Model
3. HSP-QGA Algorithm Design
3.1. Algorithm Analysis
3.2. Algorithm Design
3.2.1. Chromosome Coding
3.2.2. Chromosome Decoding
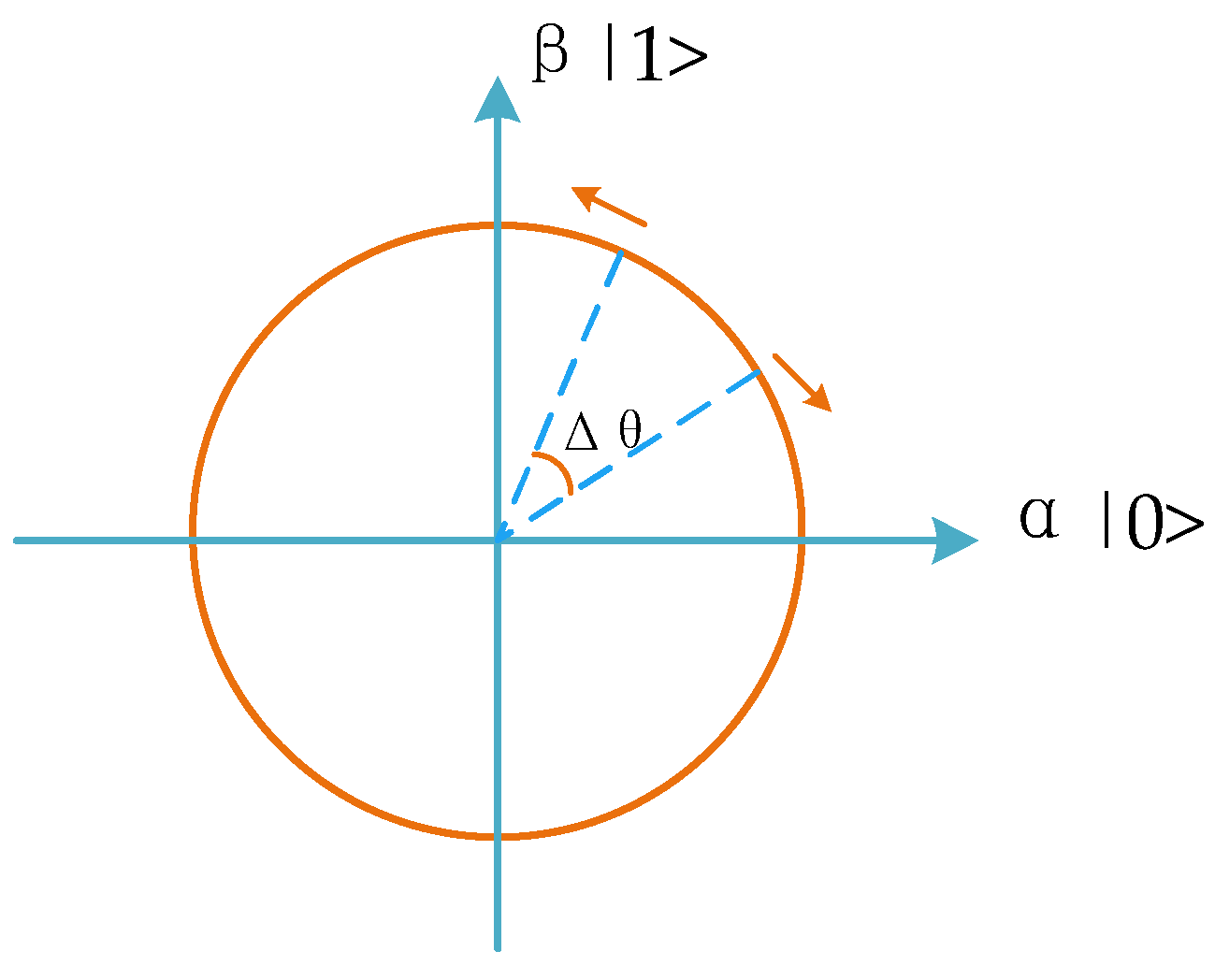
3.2.3. Full-Interference Crossover
3.2.4. Variation Operations
3.3. HSP-QGA Algorithm
| Algorithm 1: Main operation process of the HSP-QGA. |
| Input: DAG graph, population size, iteration times, and binary length Output: Makespan, speedup, efficiency, and scheduling policy 1: Calculate the rank of each task 2: Generate processor scheduling strategy 3: Population initialization 4: While i < Iteration times: 5: decoding the chromosomes of each individual in the population 6: decode qubits into binary strings according to the scheduling strategy 7: calculate the corresponding real number according to the binary string 8: form a decoded population 9: calculate the fitness of each individual 10: if fitness(current individual) > fitness(best): 11: fitness(best) = fitness(current individual) 12: full-interference crossover operation 13: quantum rotation gate operation 14: i ± 1 15: Record the best fitness in each cycle 16: end. |
4. Simulation Experiment and Results Analysis
4.1. Experimental Parameter Setting
4.2. Performance Evaluation Indicators
- A task is assigned to work on one processor;
- The execution cost of all tasks on each processor cannot be greater than the maximum processing capacity of the processor itself;
- Tasks on the processor are not allowed to terminate until execution is complete.
4.3. Experimental Analysis and Summary
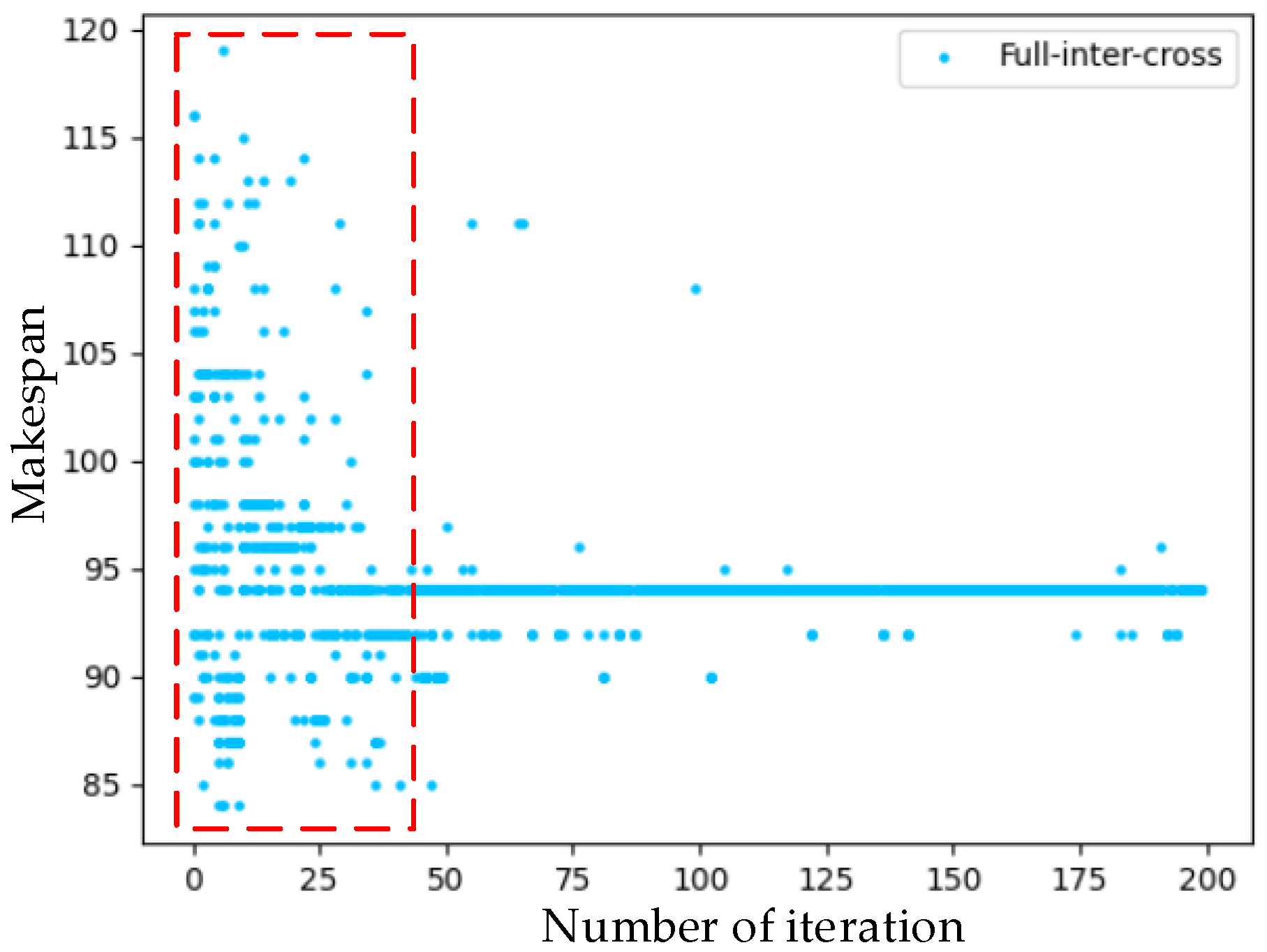
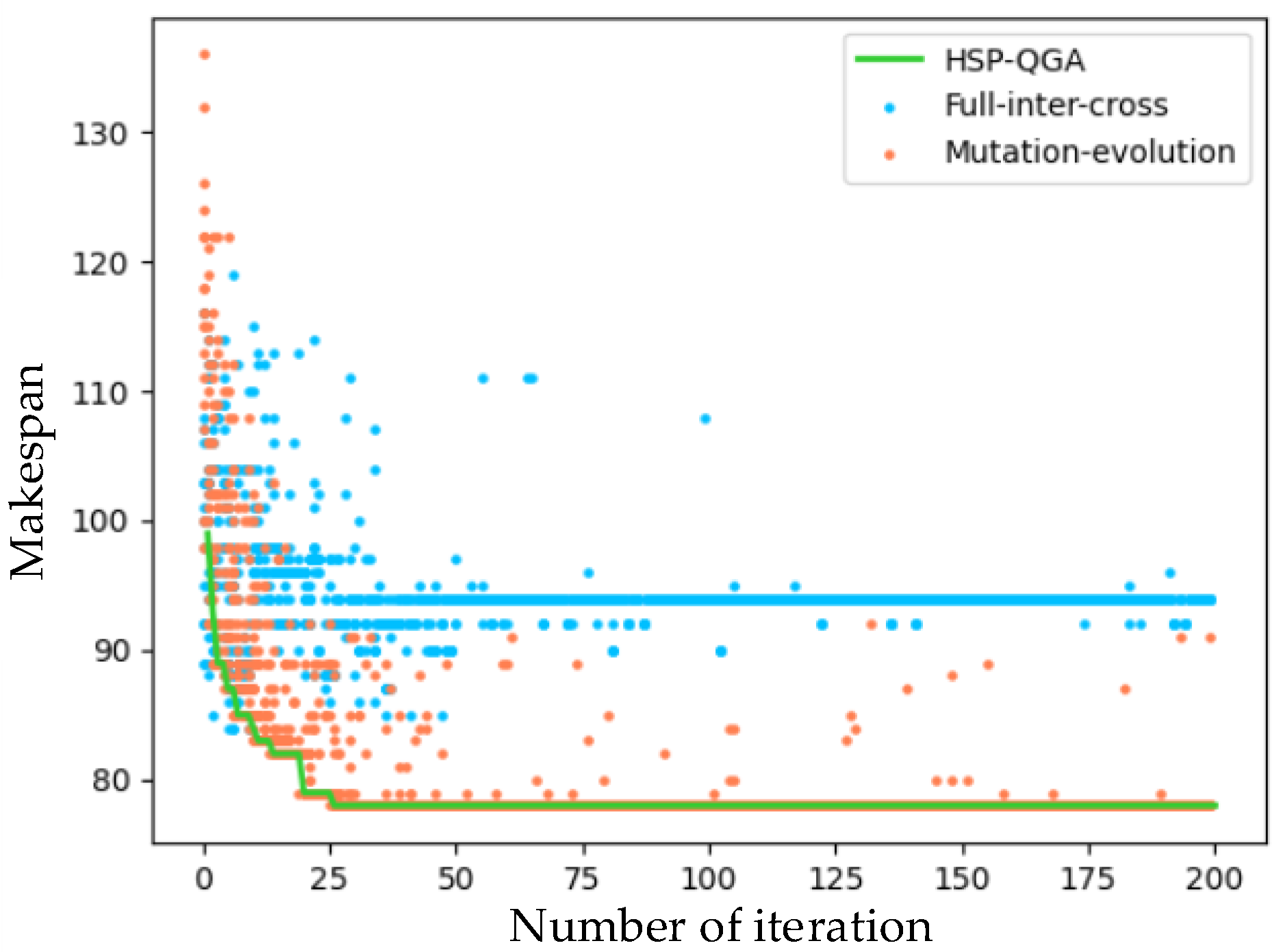
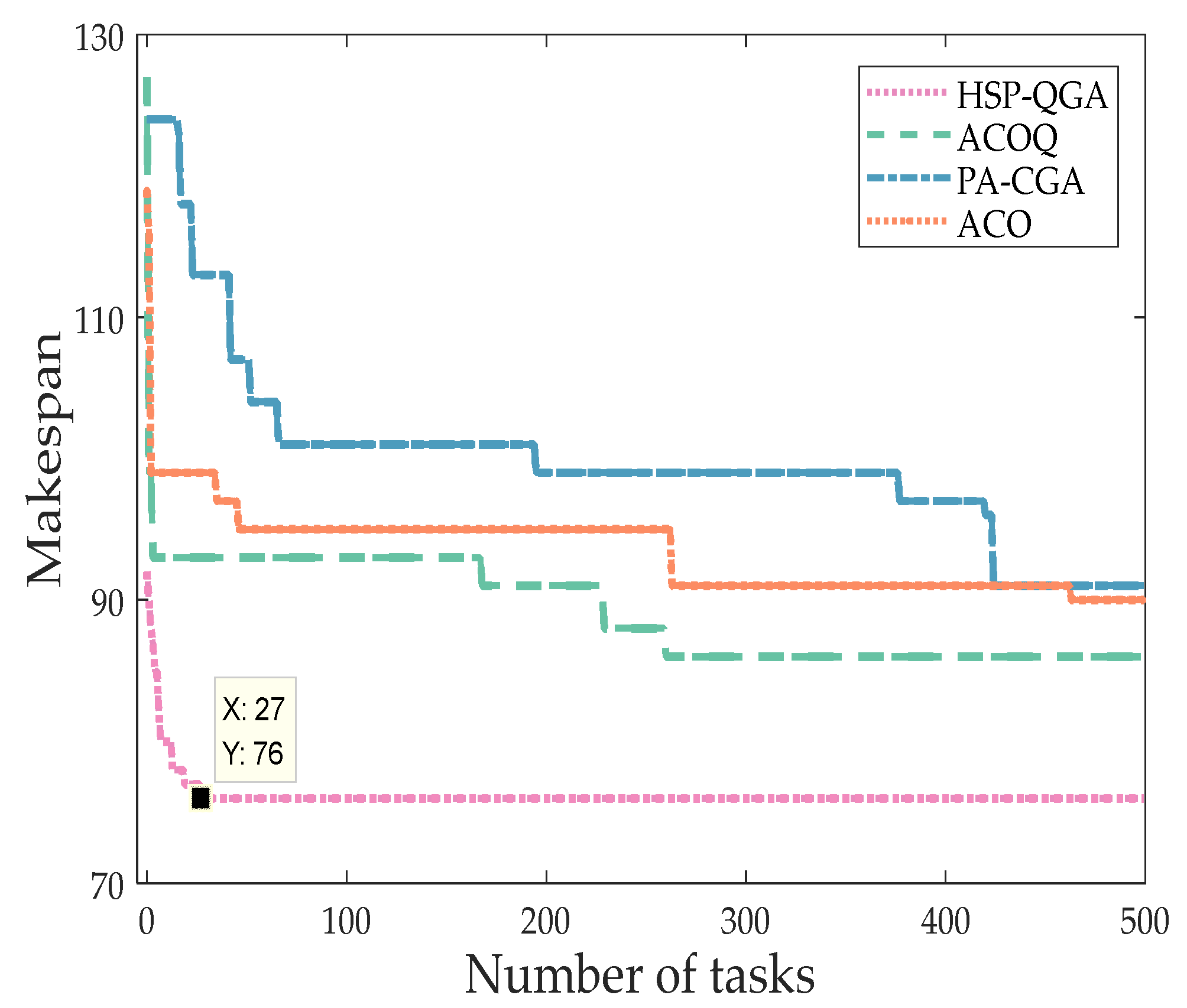
4.3.1. Comparison Experiment of Algorithm Convergence Speed and Scheduling Length under the Same Number of Tasks
4.3.2. Comparison Experiment of Scheduling Length of Algorithms under Different Task Numbers
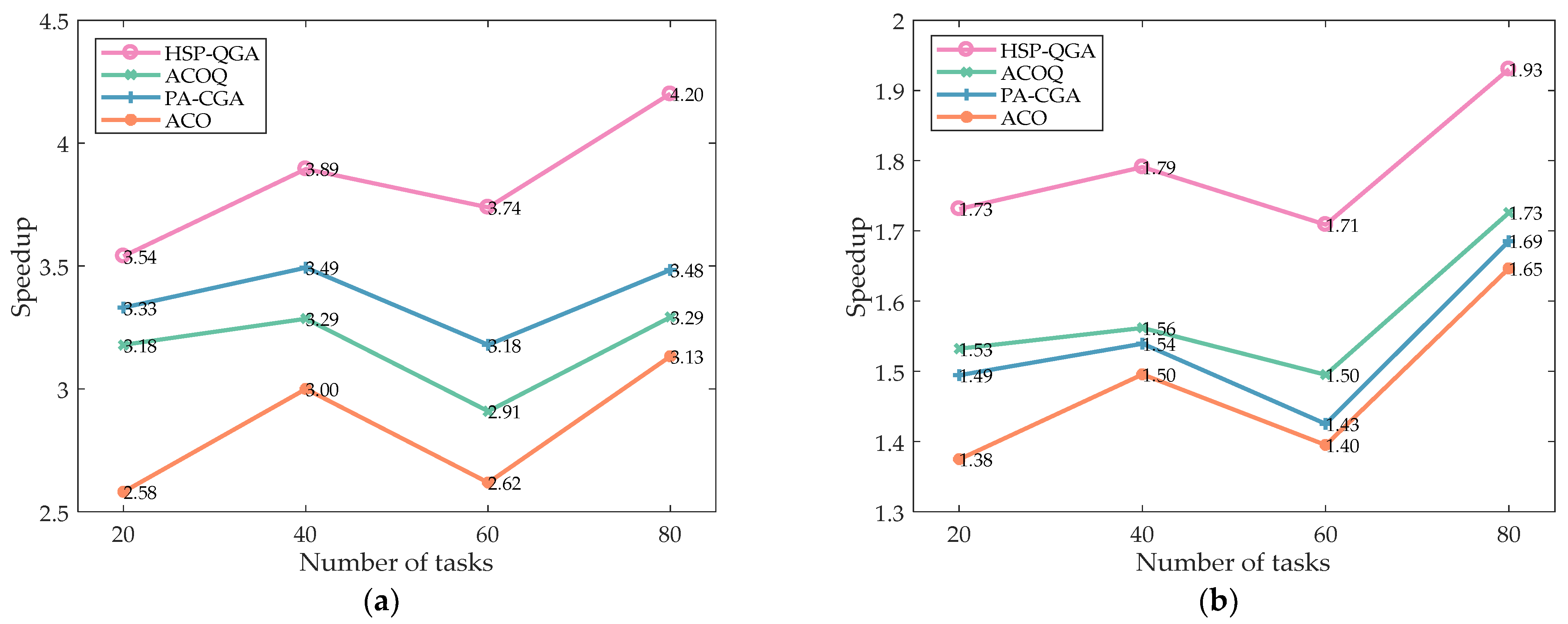
4.3.3. Experiment on the Effect of Different Tasks on Speedup
4.3.4. Experiment on the Effect of Different CCRs on Speedup
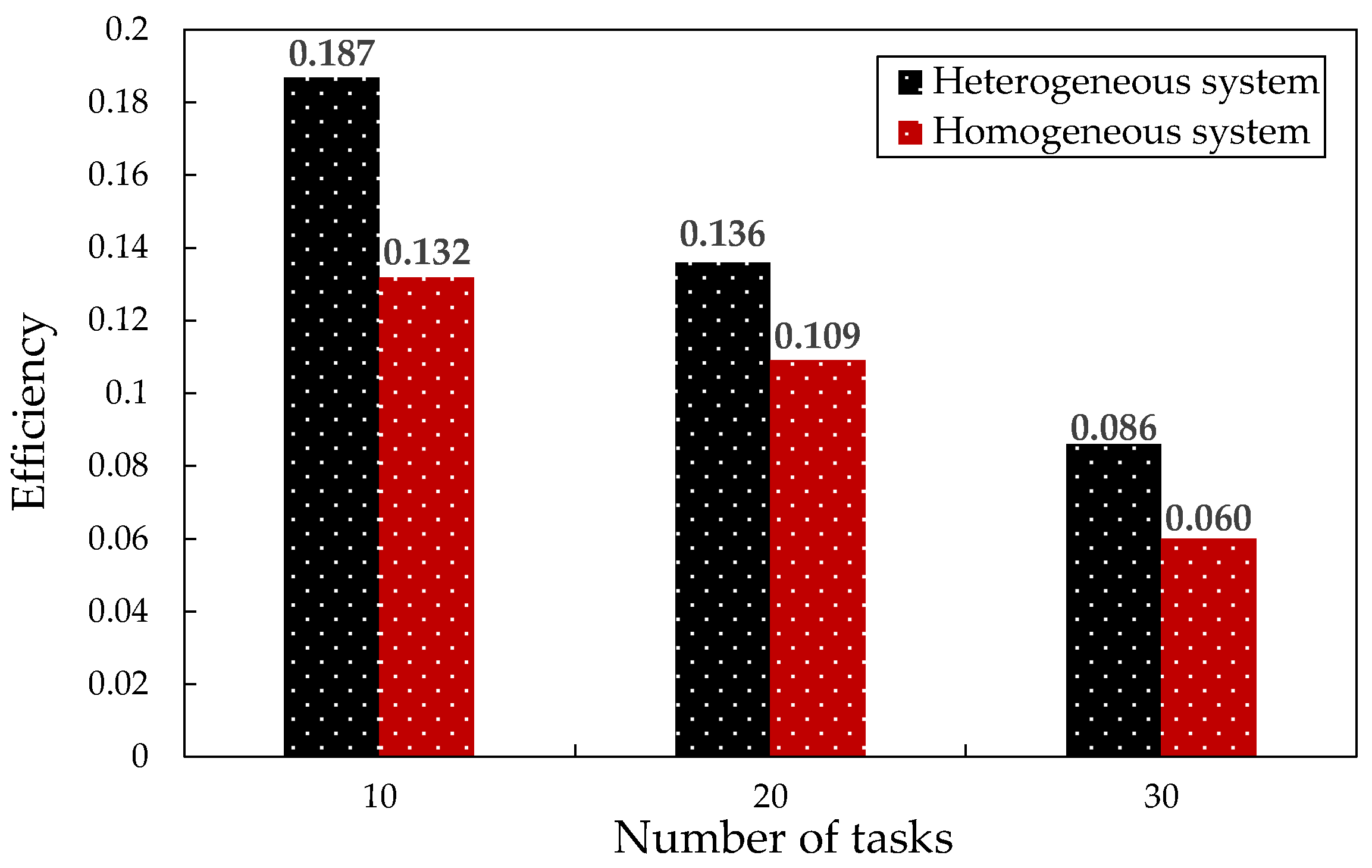
4.3.5. Comparison Experiment of Applicability of HSP-QGA in Heterogeneous and Homogeneous Systems
5. Conclusions
- (1)
- When modeling the hardware structure, this paper set the communication transmission between heterogeneous processors as an ideal state, without considering the problem of communication competition. However, in the actual platform application, the transmission bandwidth between processors or boards is different, and the communication competition during data transmission may cause delays. The next step is to improve and perfect the DAG model and hardware architecture model.
- (2)
- The algorithm proposed in this paper used a large number of binary matrices in encoding and decoding, which increased the time complexity of the algorithm and the running time of the system. To solve this problem, we can map the processor scheduling policy to the vector set. In decoding, the quantum individual is mapped to a vector, thus a vector set is obtained, which corresponds to a processor scheduling strategy. Or we can use algorithms that specifically calculate matrix operations, such as the CORDIC (coordinated rotation digital computer) algorithm instead of quantum rotation gate operation.
- (3)
- The algorithm proposed in this paper was mainly aimed at computation-intensive task scheduling, but there are also communication-intensive tasks in signal processing. We can reduce the communication overhead by task clustering or task duplication.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness, 2nd ed.; W.H. Freeman & Co., Ltd.: New York, NY, USA, 1979. [Google Scholar]
- Li, Y.; Ma, J.; Xie, Z.; Shen, X. Research on Task Scheduling of Heterogeneous Platform Signal Processing. Electron. Sci. Technol. 2022, 37, 24–34. [Google Scholar] [CrossRef]
- Haluk, T.; Salim, H.; Min-You, W. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef] [Green Version]
- Sih, G.C.; Lee, E.A. A compile-time scheduling heuristic for interconnection-constrained heterogeneous processor architectures. IEEE Trans. Parallel Distrib. Syst. 1993, 4, 175–187. [Google Scholar] [CrossRef] [Green Version]
- Fuxi, Z.; Yanxiang, Z. Theory and Design of Scheduling Algorithm in Parallel Distributed Computing, 1st ed.; Wuhan University Press: Wuhan, China, 2003. [Google Scholar]
- Paprocka, I.; Krenczyk, D.; Burduk, A. The Method of Production Scheduling with Uncertainties Using the Ants Colony Optimisation. Appl. Sci. 2020, 11, 171. [Google Scholar] [CrossRef]
- Sanabria, P.; Tapia, T.F.; Toro Icarte, R.; Neyem, A. Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning. Appl. Sci. 2022, 12, 7137. [Google Scholar] [CrossRef]
- Fang, G. Research on Parallelization of Machine Learning Algorithms for On-Chip Heterogeneous Multi-core Systems. Ph.D. Thesis, Beijing University of Technology, Beijing, China, 2017. [Google Scholar]
- Aziz, R.M.; Mahto, R.; Goel, K.; Das, A.; Kumar, P.; Saxena, A. Modified Genetic Algorithm with Deep Learning for Fraud Transactions of Ethereum Smart Contract. Appl. Sci. 2023, 13, 697. [Google Scholar] [CrossRef]
- Raji, M.; Nikseresht, M. UMOTS: An uncertainty-aware multi-objective genetic algorithm-based static task scheduling for heterogeneous embedded systems. J. Supercomput. 2021, 78, 279–314. [Google Scholar] [CrossRef]
- Fekih, A.; Hadda, H.; Kacem, I.; Hadj-Alouane, A.B. A Random-key based genetic algorithm for the flexible job-shop scheduling minimizing total completion time. In Proceedings of the 2021 14th International Conference on Developments in eSystems Engineering (DeSE), Sharjah, United Arab Emirates, 7–10 December 2021; pp. 443–447. [Google Scholar]
- Basahel, S.B.; Yamin, M. A Novel Genetic Algorithm for Efficient Task Scheduling in Cloud Environment. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 23–25 March 2022; pp. 30–34. [Google Scholar]
- Hui, C.; Zhang, J.; Chao, Z. Chaos updating rotated gates quantum-inspired genetic algorithm. In Proceedings of the 2004 International Conference on Communications, Circuits and Systems, Chengdu, China, 27–29 June 2004; pp. 1108–1112. [Google Scholar]
- Gandhi, T.; Nitin; Alam, T. Quantum genetic algorithm with rotation angle refinement for dependent task scheduling on distributed systems. In Proceedings of the 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–5. [Google Scholar]
- Alam, T.; Raza, Z. Quantum genetic algorithm based scheduler for batch of precedence constrained jobs on heterogeneous computing systems. J. Syst. Softw. 2018, 135, 126–142. [Google Scholar] [CrossRef]
- Konar, D.; Bhattacharyya, S.; Sharma, K.; Sharma, S.; Pradhan, S.R. An improved Hybrid Quantum-Inspired Genetic Algorithm (HQIGA) for scheduling of real-time task in multiprocessor system. Appl. Soft Comput. 2017, 53, 296–307. [Google Scholar] [CrossRef]
- Guo, J.; Sun, L.-J.; Wang, R.-C.; Yu, Z.-G. An Improved Quantum Genetic Algorithm. In Proceedings of the 2009 Third International Conference on Genetic and Evolutionary Computing, Guilin, China, 14–17 October 2009; pp. 14–18. [Google Scholar]
- Teng, H.; Zhao, B.; Yang, B. An Improved Mutative Scale Chaos Optimization Quantum Genetic Algorithm. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; pp. 301–305. [Google Scholar]
- Chang, Y.-F.; Xie, H.; Huang, W.-C.; Zeng, L. An Improved Multi-objective Quantum Genetic Algorithm Based on Cellular Algorithm. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 342–345. [Google Scholar]
- Zhu, X.-Q.; Gui, Y.; Gao, X.-H. A novel multi-subpopulation quantum genetic algorithm. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 3530–3534. [Google Scholar]
- Ni, H.-M.; Wang, W.-G. A Niche Quantum Genetic Algorithm Used In Multi-peak Funktion Optimization. In Proceedings of the 2010 Sixth International Conference on Natural Computation, Yantai, China, 10–12 August 2010; pp. 2239–2242. [Google Scholar]
- Zhao, Z.; Zhen, S.; Shang, J.; Kong, X. Research on Cognitive Radio Decision Engine Based On Quantum Genetic Algorithm. Acta Phys. Sin. 2007, 56, 6760–6766. [Google Scholar] [CrossRef]
- Pitchai, A.; Reddy, A.V.; Savarimuthu, N. Quantum walk based Genetic Algorithm for 0-1 Quadratic Knapsack Problem. In Proceedings of the 2015 International Conference on Computing and Network Communications (CoCoNet), Trivandrum, India, 16–19 December 2015; pp. 283–287. [Google Scholar]
- Chatterjee, N.; Paul, S.; Mukherjee, P.; Chattopadhyay, S. Deadline and energy aware dynamic task mapping and scheduling for Network-on-Chip based multi-core platform. J. Syst. Archit. 2017, 74, 61–77. [Google Scholar] [CrossRef]
- Saad, H.M.H.; Chakrabortty, R.K.; Elsayed, S.; Ryan, M.J. Quantum-Inspired Genetic Algorithm for Resource-Constrained Project-Scheduling. IEEE Access 2021, 9, 38488–38502. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y. A Novel Quantum Genetic Algorithm for TSP. Chin. J. Comput. 2007, 30, 748–755. [Google Scholar]
- Yang, S.; Jiao, L.; Liu, F. Quantum Evolutionary Algorithm. Chin. J. Eng. Math. 2006, 23, 235–246. [Google Scholar]
- Li, L.; Cui, G.; Lv, X.; Sun, X.; Wang, H. An Improved Quantum Rotation Gate in Genetic Algorithm for Job Shop Scheduling Problem. In Proceedings of the 2018 International Conference on Information Systems and Computer Aided Education (ICISCAE), Changchun, China, 6–8 July 2018; pp. 322–325. [Google Scholar]
- Dorronsoro, B.; Pinel, F. Combining Machine Learning and Genetic Algorithms to Solve the Independent Tasks Scheduling Problem. In Proceedings of the 2017 3rd IEEE International Conference on Cybernetics (CYBCONF), Exeter, UK, 21–23 June 2017; pp. 1–8. [Google Scholar]
- Xiang, B.; Zhang, B.; Zhang, L. Greedy-Ant: Ant Colony System-Inspired Workflow Scheduling for Heterogeneous Computing. IEEE Access 2017, 5, 11404–11412. [Google Scholar] [CrossRef]
- Li, N.; Gao, B.; Xie, Z.; Zhang, F.; Wan, J. Q-learning Based Intelligent Ant Colony Scheduling Algorithm in Heterogeneous System. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1020–1025. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | v1 | v2 | v3 | v4 | v5 | v6 | v7 | v8 | v9 | v10 |
| Rank | 94 | 64 | 45 | 67 | 70 | 65 | 46 | 35 | 42 | 15 |
| Order | 1 | 5 | 7 | 3 | 2 | 4 | 6 | 9 | 8 | 10 |
| Method of Operation | Method of Encoding |
|---|---|
| Qubit encoding | |
| Binary encoding | |
| Real to binary conversion | |
| Scheduling strategy 1 | 1 3 1 0 2 |
| Scheduling strategy 2 | 2 0 2 3 1 |
| Example | Individual | Chromosome | ||||
|---|---|---|---|---|---|---|
| First | Second | Third | Fourth | Fifth | ||
| Before full interference crossover | 1 | I (1) | I (2) | I (3) | I (4) | I (5) |
| 2 | II (1) | II (2) | II (3) | II (4) | II (5) | |
| 3 | III (1) | III (2) | III (3) | III (4) | III (5) | |
| 4 | IV (1) | III (2) | IV (3) | IV (4) | IV (5) | |
| 5 | V (1) | V (2) | V (3) | V (4) | V (5) | |
| Afore full interference crossover | 1 | I (1) | V (2) | IV (3) | III (4) | II (5) |
| 2 | II (1) | I (2) | V (3) | IV (4) | III (5) | |
| 3 | III (1) | II (2) | I (3) | V (4) | IV (5) | |
| 4 | IV (1) | III (2) | II (3) | I (4) | V (5) | |
| 5 | V (1) | IV (2) | III (3) | II (4) | I (5) | |
| 0 | 0 | NO | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | YES | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | NO | 0.04π | +1 | −1 | 0 | ±1 |
| 0 | 1 | YES | 0.04π | −1 | +1 | ±1 | 0 |
| 1 | 0 | NO | 0.04π | −1 | +1 | ±1 | 0 |
| 1 | 0 | YES | 0.04π | +1 | −1 | 0 | ±1 |
| 1 | 1 | NO | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | YES | 0 | 0 | 0 | 0 | 0 |
| Algorithm | Parameter | Numerical Value |
|---|---|---|
| HSP-QGA | population size | 40 |
| iterations | 500 | |
| PA-CGA | population size | 40 |
| iterations | 500 | |
| crossover probability | 0.35 | |
| mutation probability | 0.1 | |
| ACO | population size | 40 |
| iterations | 500 | |
| α | 0.1 | |
| β | 1 | |
| ρ | 0.3 | |
| Q | 1 | |
| Q-learning | learning rate α | 0.1 |
| discount factor γ | 0.8 | |
| exploration factor ε | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Ma, J.; Xie, Z.; Hu, Z.; Shen, X.; Zhang, K. A Scheduling Method for Heterogeneous Signal Processing Platforms Based on Quantum Genetic Algorithm. Appl. Sci. 2023, 13, 4428. https://doi.org/10.3390/app13074428
Li Y, Ma J, Xie Z, Hu Z, Shen X, Zhang K. A Scheduling Method for Heterogeneous Signal Processing Platforms Based on Quantum Genetic Algorithm. Applied Sciences. 2023; 13(7):4428. https://doi.org/10.3390/app13074428
Chicago/Turabian StyleLi, Yudong, Jinquan Ma, Zongfu Xie, Zeming Hu, Xiaolong Shen, and Kun Zhang. 2023. "A Scheduling Method for Heterogeneous Signal Processing Platforms Based on Quantum Genetic Algorithm" Applied Sciences 13, no. 7: 4428. https://doi.org/10.3390/app13074428
APA StyleLi, Y., Ma, J., Xie, Z., Hu, Z., Shen, X., & Zhang, K. (2023). A Scheduling Method for Heterogeneous Signal Processing Platforms Based on Quantum Genetic Algorithm. Applied Sciences, 13(7), 4428. https://doi.org/10.3390/app13074428