
Uncertainty Quantification for MLP-Mixer Using Bayesian Deep Learning



Abstract
:1. Introduction
2. Methodology
- Token mixing: The token mixing layer applies a fully connected MLP to each patch vector, which generates a set of token vectors. These tokens represent the local information within each patch, and the MLP learns to transform the tokens to extract significant features, as mathematically given in Equation (1).where is the output of the token mixing layer, is the layer normalization for each token vector, and are weight and biases for the first dense layer in token mixing, and are weight and biases for the second dense layer in token mixing, with a (GELU) nonlinearity activation function between the two dense layers. Finally, the at the end represents the skip connection;
- Channel mixing: The channel mixing layer applies another MLP to the set of token vectors generated by the token mixing layer. This MLP is applied across the tokens of each patch, allowing global information to be captured across the entire image. The output of the channel mixing layer is a new set of token vectors that are then fed to the next mixer layer. This is defined mathematically in Equation (2).where is the output of the channel mixing layer, is the layer normalization for each channel vector, and are weight and biases for the first dense layer in channel mixing, and are weight and biases for the second dense layer in channel mixing, with a (GELU) nonlinearity activation function between the two dense layers. Finally, the at the end represents the skip connection.
2.1. Datasets
2.1.1. Acute Lymphoblastic Leukemia (ALL)
2.1.2. Breast Cancer
2.2. Data Preparation
2.3. Uncertainty Quantification
3. Experiments and Results
4. Discussion
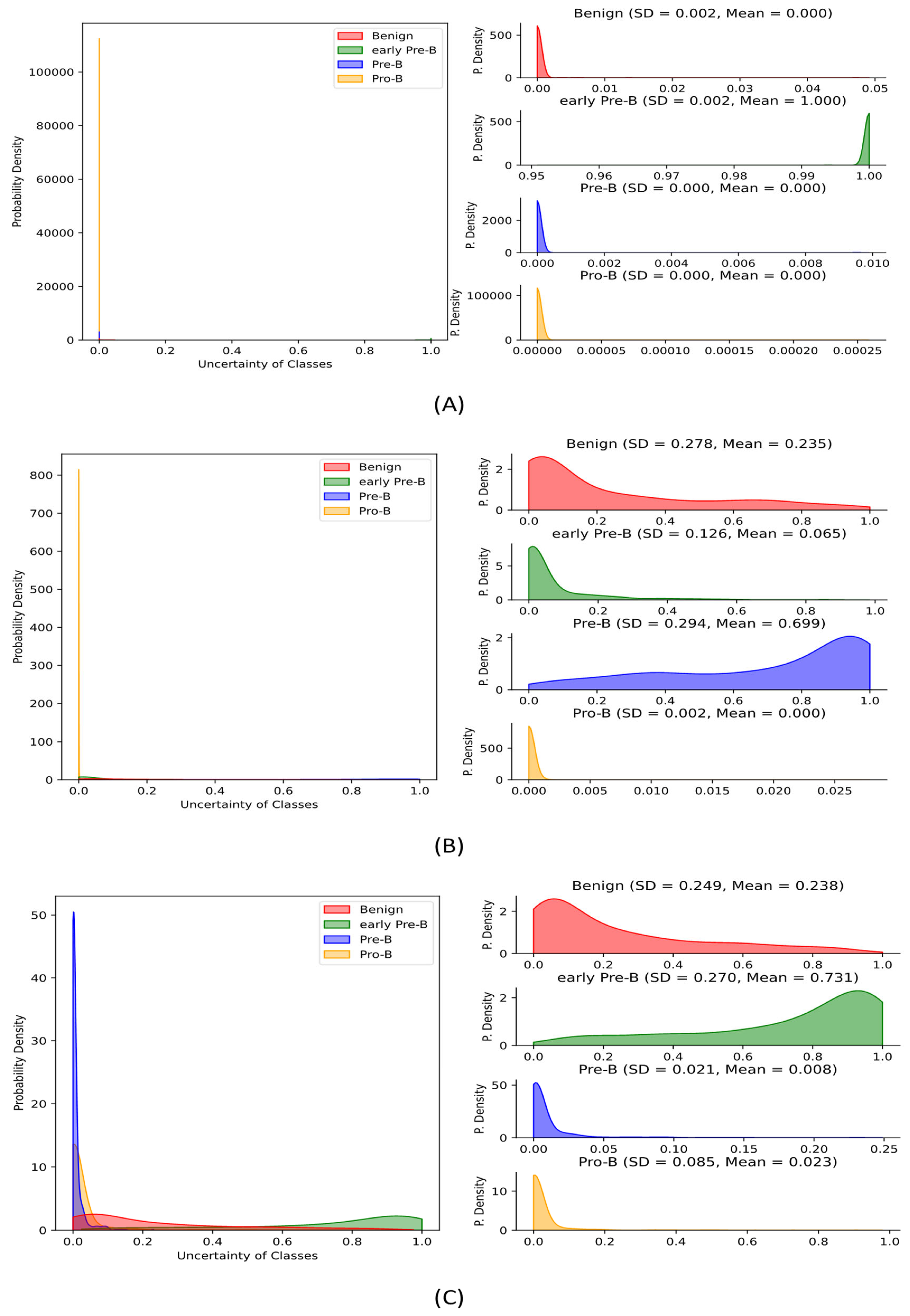
- In the context of BDL, it is frequently observed that a model’s performance declines when the mean of the predicted true classes falls below a certain threshold, which in this study’s datasets was around 50%. This situation is characterized by a decrease in the model’s standard deviation, indicating a failure to capture the associated uncertainty. It is worth noting that this observation does not necessarily imply a failure of the BDL, but rather indicates that the model has failed to effectively generalize the results and predict each class accurately. In such cases, it is recommended to explore alternative methods or models that may be more suitable to the data and task at hand. This approach may involve adjusting the model’s hyperparameters or selecting a different model architecture altogether. Additionally, it may be necessary to reconsider the data preprocessing steps or feature engineering techniques used in the model development process. Therefore, it is important to note that the identification of poor-performing models and the subsequent exploration of alternative approaches are crucial steps in the iterative model development process. It is through this iterative process that one can gain a better understanding of the data, model, and associated uncertainties, ultimately leading to improved model performance and increased confidence in the resulting predictions;
- In BDL, when a model is presented with unfamiliar data, the associated posterior distributions become more uncertain, resulting in higher uncertainty estimates. This increased uncertainty indicates that the network is less confident in its predictions, and it can serve as a useful tool for identifying abnormal or unusable data that significantly deviate from the training dataset. By utilizing the model uncertainty estimates to identify such data, BDL models, particularly MLP-Mixer models, can deliver improved performance and more reliable results across various applications. This approach to leveraging uncertainty estimates to detect abnormal data aligns with the wider concept of model-based anomaly detection, which has proven successful in various applications. Additionally, by quantifying the associated uncertainty, BDL models can provide a valuable tool for identifying data points that are on the edge of the model’s training distribution. This can serve as a foundation for further exploring the data-generating process and improving the model’s overall generalization ability;
- It is important to understand that a perfect score on a dataset does not necessarily imply perfect confidence or zero uncertainty in a model’s predictions. Our research findings, as presented in Table 1 and Table 2, demonstrate this fact. However, some publications have misinterpreted the relationship between a perfect score and uncertainty. It is important to note that the likelihood of a model having zero uncertainty or standard deviation is extremely low and that this situation can only occur under extreme circumstances. This highlights the fact that even when a model performs exceptionally well on a dataset, some degree of uncertainty remains in its predictions due to various factors such as model bias, incomplete information, and data variability. It is, therefore, essential to consider the uncertainty associated with a model’s predictions, as it can provide valuable insights into the reliability of its results and potential areas for improvement. Failure to account for such uncertainty can lead to overconfidence in a model’s predictions, which can be detrimental in critical applications such as healthcare. Researchers and practitioners must be aware of the presence of uncertainty and focus on developing methods to quantify and account for it. By doing so, we can improve the overall reliability and robustness of deep learning models and ensure their effective application across a wide range of fields;
- In the field of machine learning, it is commonly held that using fully Bayesian methods in deep learning might not always lead to better results compared to approximate methods. This is due to the fact that fully Bayesian methods may not be effective with all types of data, particularly in the case of image data, where images can vary significantly from one another. In addition, using fully Bayesian methods can be computationally demanding, especially with models that have a large number of parameters to learn. Therefore, when deciding between fully Bayesian and approximate methods, it is important to consider factors such as the size of the data, the computing resources available, and the desired level of model complexity. Considering these factors can aid in selecting the most appropriate method for each specific task. Consequently, full BDL has not received widespread acceptance among machine learning researchers, particularly in the field of computer vision;
- The MLP-Mixer is known for its relatively limited interaction with neighboring neurons compared to CNNs. This limited interaction can result in decreased performance when working with smaller datasets, as the model may struggle to capture the complex patterns and relationships present in the data. However, for very large datasets, MLP-Mixer can perform equally well as CNN models while being more computationally efficient. Therefore, it is important to carefully consider the strengths and limitations of MLP-Mixers when choosing an architecture for a given task, especially when working with smaller datasets or in environments with limited computational resources. Researchers have developed different versions of MLP-Mixer to increase interaction between neighboring regions while decreasing interaction between further away regions [10]. Our findings suggest that incorporating uncertainty quantification using BDL can significantly enhance the performance of MLP-Mixers, particularly for small and medium-sized datasets;
- Unlike CNN models that use filters for uncertainty quantification, MLP-Mixers utilize regions of images or feature maps, offering a more comprehensive analysis of the data. This approach provides a more accurate representation of uncertainty, which can lead to better performance in certain applications;
- Although BDL often results in high estimated uncertainty for incorrectly assigned classes, it may also produce high uncertainty for correctly assigned classes as well. This phenomenon is particularly common among classes that are closely related. For example, in the context of cancer classification (Table 2), the normal and benign classes may both have high uncertainty, while the malignant class has low uncertainty. Alternatively, the benign and malignant classes may both exhibit high uncertainty, while the normal class has low uncertainty. However, it is less common for both the normal and malignant classes to show high uncertainty, while the benign class has low uncertainty, as these two classes possess noticeably distinct features that distinguish them from each other. Therefore, understanding the underlying factors that contribute to the uncertainty estimates of a model is crucial for interpreting and evaluating its performance. Additionally, taking into account the inherent uncertainty associated with a model’s predictions can provide valuable insights into the reliability and robustness of its results, especially in applications where misclassification can have severe consequences.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. arXiv 2021, arXiv:2106.11342. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An All-MLP Architecture for Vision. Adv. Neural Inf. Process Syst. 2021, 34, 24261–24272. [Google Scholar]
- Liu, R.; Li, Y.; Tao, L.; Liang, D.; Zheng, H.-T. Are We Ready for a New Paradigm Shift? A Survey on Visual Deep MLP. Patterns 2022, 3, 100520. [Google Scholar] [CrossRef]
- Song, B.; Sunny, S.; Li, S.; Gurushanth, K.; Mendonca, P.; Mukhia, N.; Patrick, S.; Gurudath, S.; Raghavan, S.; Tsusennaro, I.; et al. Bayesian Deep Learning for Reliable Oral Cancer Image Classification. Biomed. Opt. Express. 2021, 12, 6422. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges. Information Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Abdullah, A.A.; Hassan, M.M.; Mustafa, Y.T. A Review on Bayesian Deep Learning in Healthcare: Applications and Challenges. IEEE Access 2022, 10, 36538–36562. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML, New York, NY, USA, 20–22 June 2016; pp. 1050–1059. [Google Scholar]
- Wu, A.; Nowozin, S.; Meeds, E.; Turner, R.E.; Hernández-Lobato, J.M.; Gaunt, A.L. Deterministic Variational Inference for Robust Bayesian Neural Networks. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Aria, M.; Ghaderzadeh, M.; Bashash, D.; Abolghasemi, H.; Asadi, F.; Hosseini, A. Acute Lymphoblastic Leukemia (ALL) Image Dataset. Kaggle 2021. [Google Scholar] [CrossRef]
- Mahmood, N.; Shahid, S.; Bakhshi, T.; Riaz, S.; Ghufran, H.; Yaqoob, M. Identification of Significant Risks in Pediatric Acute Lymphoblastic Leukemia (ALL) through Machine Learning (ML) Approach. Med. Biol. Eng. Comput. 2020, 58, 2631–2640. [Google Scholar] [CrossRef]
- Hafeez, M.U.; Ali, M.H.; Najib, N.; Ayub, M.H.; Shafi, K.; Munir, M.; Butt, N.H. Ophthalmic Manifestations of Acute Leukemia. Cureus 2019, 11, e3837. [Google Scholar] [CrossRef] [Green Version]
- Rafei, H.; Kantarjian, H.M.; Jabbour, E.J. Recent Advances in the Treatment of Acute Lymphoblastic Leukemia. Leuk. Lymphoma 2019, 60, 2606–2621. [Google Scholar] [CrossRef]
- Ghaderzadeh, M.; Asadi, F.; Hosseini, A.; Bashash, D.; Abolghasemi, H.; Roshanpour, A. Machine Learning in Detection and Classification of Leukemia Using Smear Blood Images: A Systematic Review. Sci. Program. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Ghaderzadeh, M.; Aria, M.; Hosseini, A.; Asadi, F.; Bashash, D.; Abolghasemi, H. A Fast and Efficient CNN Model for B-ALL Diagnosis and Its Subtypes Classification Using Peripheral Blood Smear Images. Int. J. Intelligent Syst. 2022, 37, 5113–5133. [Google Scholar] [CrossRef]
- Atteia, G.; Alhussan, A.; Samee, N. BO-ALLCNN: Bayesian-Based Optimized CNN for Acute Lymphoblastic Leukemia Detection in Microscopic Blood Smear Images. Sensors 2022, 22, 5520. [Google Scholar] [CrossRef]
- Billah, M.E.; Javed, F. Bayesian Convolutional Neural Network-Based Models for Diagnosis of Blood Cancer. Appl. Artif. Intell. 2022, 36, 2011688. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2022. CA Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Fahmy, A. Dataset of Breast Ultrasound Images. Data Brief 2020, 28, 104863. [Google Scholar] [CrossRef]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Afadar, Y.; Elgendy, O. Breast Cancer Detection Using Artificial Intelligence Techniques: A Systematic Literature Review. Artif. Intell. Med. 2022, 127, 102276. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Mean Class Confidence & Standard Deviation | Classes | Accuracy of Model | ||||
|---|---|---|---|---|---|---|---|
| Benign | Early Pre-B | Pre-B | Pro-B | Base Model | Sampling | ||
| Custom CNN + MC-Dropout | Mean | 0.9031 | 0.9356 | 0.9809 | 0.9978 | 0.8973 | 0.8973 |
| SD | 0.1546 | 0.1210 | 0.0778 | 0.0178 | |||
| Custom CNN + VI | Mean | 0.8442 | 0.7915 | 0.9246 | 0.9178 | 0.8603 | 0.9178 |
| SD | 0.1509 | 0.1369 | 0.0741 | 0.0432 | |||
| Inception + MC-Dropout | Mean | 0.9388 | 0.9167 | 0.9837 | 0.9661 | 0.9425 | 0.9404 |
| SD | 0.1237 | 0.1357 | 0.0644 | 0.1038 | |||
| Inception + VI | Mean | 0.8511 | 0.8856 | 0.9202 | 0.9081 | 0.8829 | 0.9404 |
| SD | 0.1472 | 0.1081 | 0.0969 | 0.0983 | |||
| DenseNet + MC-Dropout | Mean | 0.9825 | 0.9764 | 0.9949 | 0.9871 | 0.9774 | 0.9712 |
| SD | 0.0600 | 0.0795 | 0.0307 | 0.0508 | |||
| DenseNet + VI | Mean | 0.9263 | 0.9141 | 0.9078 | 0.9551 | 0.9445 | 0.9568 |
| SD | 0.0994 | 0.1185 | 0.1122 | 0.0525 | |||
| ResNet + MC-Dropout | Mean | 0.7680 | 0.8986 | 0.9415 | 0.9552 | 0.6201 | 0.9507 |
| SD | 0.1973 | 0.1393 | 0.1220 | 0.1148 | |||
| ResNet + VI | Mean | 0.4873 | 0.5966 | 0.6924 | 0.6944 | 0.4065 | 0.7351 |
| SD | 0.1238 | 0.1388 | 0.1749 | 0.1545 | |||
| MLP-Mixer + MC-Dropout | Mean | 0.8448 | 0.9179 | 0.9664 | 0.9542 | 0.8706 | 0.9507 |
| SD | 0.1683 | 0.1425 | 0.0936 | 0.1037 | |||
| MLP-Mixer + VI | Mean | 0.7626 | 0.8844 | 0.9671 | 0.8852 | 0.8603 | 0.9466 |
| SD | 0.2252 | 0.1346 | 0.0867 | 0.0952 | |||
| Model | Mean Class Confidence & Standard Deviation | Classes | Accuracy of Model | |||
|---|---|---|---|---|---|---|
| Normal | Benign | Malignant | Base Model | Sampling | ||
| Custom CNN + MC-Dropout | Mean | 0.9192 | 0.9178 | 0.9569 | 0.7264 | 0.7179 |
| SD | 0.1481 | 0.1217 | 0.0570 | |||
| Custom CNN + VI | Mean | 0.8927 | 0.9011 | 0.8921 | 0.7350 | 0.7778 |
| SD | 0.1511 | 0.1264 | 0.1363 | |||
| Inception + MC-Dropout | Mean | 0.9019 | 0.9034 | 0.9383 | 0.7777 | 0.7692 |
| SD | 0.1511 | 0.1455 | 0.1418 | |||
| Inception + VI | Mean | 0.8882 | 0.8223 | 0.8279 | 0.7521 | 0.7435 |
| SD | 0.1411 | 0.1739 | 0.1642 | |||
| DenseNet + MC-Dropout | Mean | 0.9337 | 0.9245 | 0.9330 | 0.8290 | 0.8547 |
| SD | 0.1151 | 0.0993 | 0.1078 | |||
| DenseNet + VI | Mean | 0.9061 | 0.8418 | 0.8801 | 0.7692 | 0.7607 |
| SD | 0.1447 | 0.1685 | 0.1327 | |||
| ResNet + MC-Dropout | Mean | 0.8951 | 0.7149 | 0.8194 | 0.5299 | 0.7009 |
| SD | 0.1420 | 0.1812 | 0.1466 | |||
| ResNet + VI | Mean | 0.8313 | 0.7645 | 0.7947 | 0.6324 | 0.7692 |
| SD | 0.1299 | 0.1451 | 0.1578 | |||
| MLP-Mixer + MC-Dropout | Mean | 0.7566 | 0.7925 | 0.7880 | 0.6239 | 0.6923 |
| SD | 0.2068 | 0.2069 | 0.2333 | |||
| MLP-Mixer + VI | Mean | 0.6598 | 0.6795 | 0.7417 | 0.5384 | 0.6325 |
| SD | 0.2188 | 0.1467 | 0.1803 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah, A.A.; Hassan, M.M.; Mustafa, Y.T. Uncertainty Quantification for MLP-Mixer Using Bayesian Deep Learning. Appl. Sci. 2023, 13, 4547. https://doi.org/10.3390/app13074547
Abdullah AA, Hassan MM, Mustafa YT. Uncertainty Quantification for MLP-Mixer Using Bayesian Deep Learning. Applied Sciences. 2023; 13(7):4547. https://doi.org/10.3390/app13074547
Chicago/Turabian StyleAbdullah, Abdullah A., Masoud M. Hassan, and Yaseen T. Mustafa. 2023. "Uncertainty Quantification for MLP-Mixer Using Bayesian Deep Learning" Applied Sciences 13, no. 7: 4547. https://doi.org/10.3390/app13074547
APA StyleAbdullah, A. A., Hassan, M. M., & Mustafa, Y. T. (2023). Uncertainty Quantification for MLP-Mixer Using Bayesian Deep Learning. Applied Sciences, 13(7), 4547. https://doi.org/10.3390/app13074547