1. Introduction
A topic model [
1] is an unsupervised model that statistically discovers potential topics from large corpora for application to downstream tasks in natural language processing, including text classification [
2], sentiment analysis [
3], etc. There are also Bayesian approaches represented by latent semantic analysis (LSA) [
4], probabilistic latent semantic analysis (PLSA) [
5], and hierarchical Dirichlet process (HDP) [
6]. The textual content of the topic model is usually represented by a bag-of-words representation and the generation of the bag-of-words data is modeled using an underlying probabilistic structure. This approach allows the calculation of topic distributions and topic-word distributions for each article. Although traditional Bayesian topic models have been successful, these models often require complex computations and have a poor portability.
The neural topic model (NTM), which includes a neural component (the variational autoencoder [
7]), produces high-quality topics and superior performance compared to the traditional latent Dirichlet allocation model [
8,
9,
10]. The NTM utilizes a multilayer perceptron (MLP) to process the bag-of-words input and then performs a variational inference via a neural network to sample the potential document topic vector. The decoder network then utilizes an MLP to reconstruct the topic-word representation of the original document. The NTM outperforms traditional topic models in terms of topic quality and scalability and is well-suited for mining topics from massive amounts of text without considering the complexity of model computation and scalability. However, these models still have drawbacks, such as using the bag-of-words model representation, which neglects the semantic relevance of the context between words. As the robust representation is determined by the semantics between contexts, neglecting this information can lead to poor results. The development of word embedding and pretrained language models has facilitated the advancement of topic modeling techniques. Specifically, static word embedding techniques such as word2vec [
11] and Glove [
12] have an edge over the bag-of-words model since word embedding captures syntactic and semantic rules by encoding the local context of word co-occurrence patterns. This overcomes the limitations of the bag-of-words model, which cannot reflect the differences and similarities between words and loses sequential information. For instance, the ETM [
13] method is a document generation model that combines the traditional topic model LDA with word embeddings. Specifically, it models each word using a categorical distribution, where the natural parameter of the categorical distribution is the dot product between the word embedding and its given topic embedding. The ETM has a good predictive performance, but it cannot handle issues such as polysemy of words. Moreover, the development of pretrained language model technology has brought great advancements to NLP tasks, such as BERT [
14], RoBERTa [
15], DeBERTa [
16], etc. ZeroShot
TM [
17] replaces the bag-of-words input representation in topic models with pretrained contextualized word embeddings, allowing it to capture contextually relevant semantic information. However, this approach has some limitations. Firstly, due to the sparsity of features and the lack of word co-occurrence patterns, the model often fails to extract high-quality topics from short texts. Secondly, the model’s performance in analyzing semantic information from short texts deteriorates, and it typically fails to extract feature information relevant to the topic in the text, resulting in low-quality topics that are often repetitive and lack coherence.
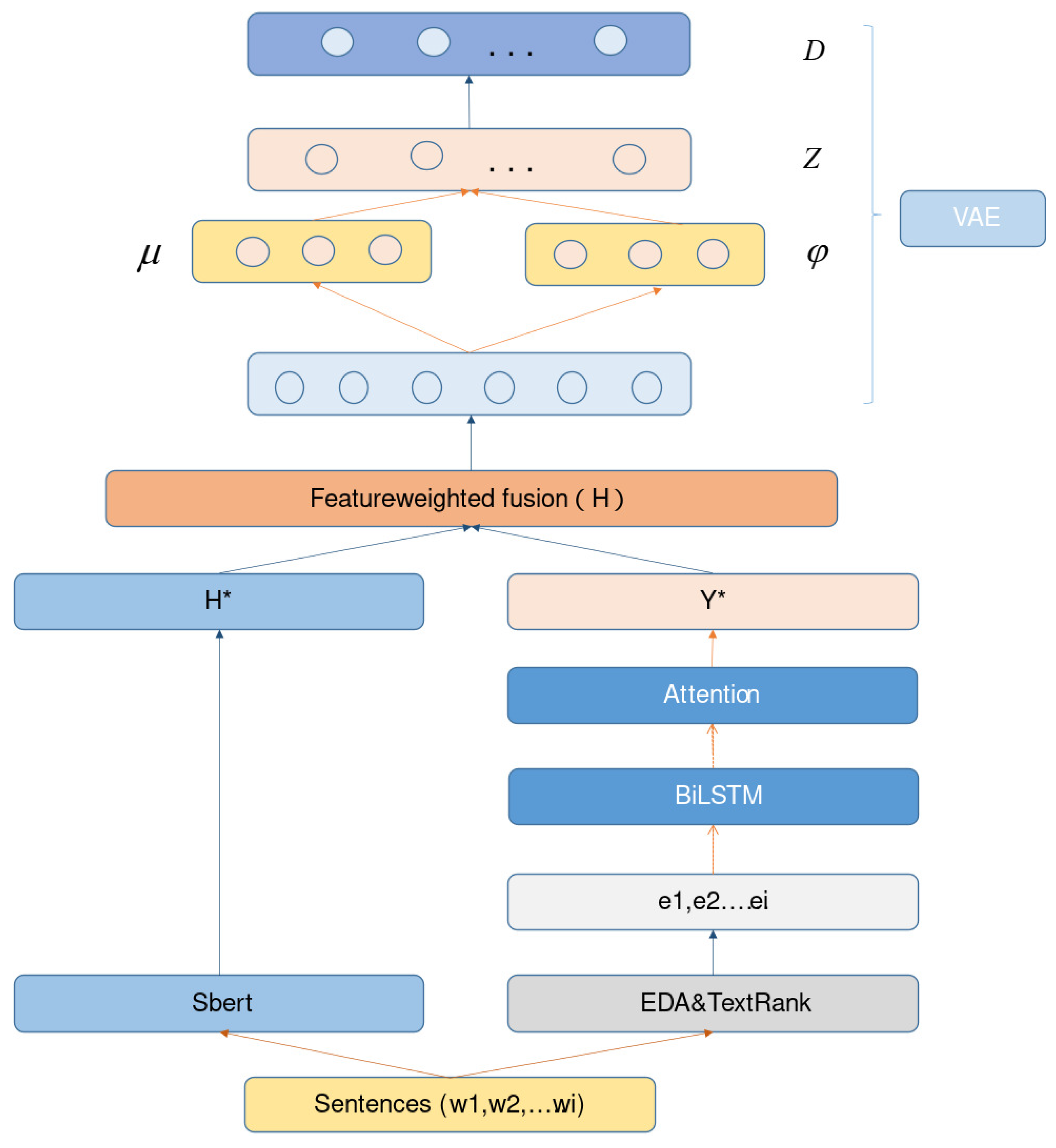
To address the above issues, we propose a neural topic model that integrates SBERT [
18,
19] and data augmentation. Specifically, we introduce a new data augmentation technique that incorporates keyword information. The data augmentation technique [
20] uses simple random replacements, insertions, deletions, and other operations to enhance the robustness of text data. The keyword information is obtained through the TextRank algorithm [
21], which efficiently and quickly extracts important words from a large amount of text or other materials. Therefore, our method combining EDA with keyword data augmentation is beneficial for overcoming the sparsity problem of text features. Next, we vectorize the augmented text data and input them into a BiLSTM-Att module to obtain the long-distance dependency information and overcome the influence of noisy words. Then, although the emergence of BERT has propelled the development of various NLP tasks, they still struggle to produce semantically meaningful embeddings for shorter language units such as sentences and phrases. The most common method for BERT sentence embedding is to take the average of the BERT output layer (referred to as BERT embedding) or use the output of the first token ([CLS] token). This common practice results in relatively poor sentence embeddings that are unsuitable for unsupervised clustering and other tasks [
18]. Therefore, we use SBERT instead of BERT, which takes the entire sentence as the processing unit and uses Siamese networks and triplet networks to update weights, resulting in semantically meaningful sentence embeddings that are more suitable for tasks such as semantic similarity search and clustering. Furthermore, the SBERT model in this paper is trained on a large and diverse dataset and designed as a general-purpose model, achieving superior results compared to the sentence encoder in the baseline model ZeroShot
TM across various tasks. Moreover, our SBERT is capable of generating high-quality semantic embeddings for short texts. Finally, we merge the information that has been enhanced through data augmentation and processed through the attention mechanism with the high-quality semantic feature information. Then, we feed the resulting feature information into a neural topic model to learn high-quality topics. We use the ProdLDA model [
22] as our neural topic model, which is a topic model based on automatic-encoding variational inference. It optimizes the structure of the topic model to be more suitable for tasks such as topic mining. Experimental results show that our model produces coherent and high-quality topics on the English public dataset; specifically, our contributions are as follows:
We use an improved neural topic model combining SBERT and VAE for topic discovery tasks.
We propose a new data augmentation method of fused keywords to overcome the sparsity problem of text and thus learn more accurate topics.
We use the BiLSTM-Att mechanism to obtain context dependencies as well as to reduce the influence of noisy words (words irrelevant to the topic) on the model.
Experimental results show that our approach leads to improved topic coherence and obtains diverse and interpretable topics.
2. Related Work
In recent years, the rise of neural networks and pretrained models has promoted the development of topic modeling. The emergence of neural topic models has helped people discover valuable and important topic information from massive quantity of noisy network data and promoted the development of downstream tasks in natural language processing such as text classification.
Miao et al. [
23] introduced the concept of the neural variational document model (NVDM) based on the variational autoencoder. This early attempt to combine topic modeling and autoencoder utilized a multivariate Gaussian distribution instead of the original model’s prior distribution. Later, Miao et al. were inspired by the NVDM and introduced the Gaussian model [
24]. This model constructed topic distributions by providing parameterizable distributional transformations of topics within a variational inference framework. The ProdLDA topic model [
22] is a variational-autoencoder-based model that uses a logistic Gaussian distribution to approximate the distribution and replaces the mixture model in the topic model with an expert’s product. Card et al. [
25] proposed a stochastic variational inference neural framework that enabled flexible combinations of metadata with various options and allowed the rapid exploration of alternative models. Nan et al. [
26] proposed a model called W-LDA in the autoencoder framework. Unlike existing neural-network-based models, this model could directly execute the Dirichlet prior and outperformed other neural topic models in matching high-dimensional distributions. Additionally, the noise added by that model to the encoder module significantly improved topic consistency without compromising diversity. Lastly, the use of the maximum mean difference instead of ELBO in neural topics allowed the model to produce higher quality topics. Wang et al. [
27] proposed a neural topic modeling approach called a two-way adversarial topic model. That approach employed a generator to learn the distribution of document topics to the distribution of document-words, and a discriminator was used to distinguish between true distribution pairs and pseudodistribution pairs. That technique helped the network (generator and encoder) to better learn article topics and topic-word distributions. Wu et al. [
28] proposed the negative binomial neural topic model, which attempted to combine variational inference with a mixed counting model for a neural variational topic model. That model used a reparameterization of the gamma distribution and a Gaussian approximation of the Poisson distribution. It also developed a neural variational inference algorithm to infer the model parameters, while implicitly introducing non-negative constraints in the topic modeling to improve topic quality. Tian et al. [
29] introduced a model called RRT-VAE, which utilized a rounded reparameterization technique to reparameterize the neural topic model of the Dirichlet distribution. That technique was an effective reparameterization method and extended the applicability of the model to other applications beyond the Dirichlet distribution. Gupta et al. [
30] proposed iDocNADE, a neural autoregressive topic model designed to enhance the context of short texts. Experiments demonstrated that iDocNADE outperformed other topic models.
Topic models and their variants have been widely applied by scholars in various fields. The LB-MMT model [
31] was a new probabilistic topic model used to explore latent topics in multimodal data from social media. It integrated labels, text, and visual information into a unified framework, addressing three key challenges: the top-down relationship from labels to text and images, the one-to-many relationship between labels and topics, and representing visual and textual information in the model. Experimental results showed that LB-MMT outperformed all baseline models in a quantitative evaluation and had significant practical implications. Mishra et al. [
32] discussed the development of a digital tourism recommendation system, which utilized online comments, blogs, and rating data for analysis. A machine-learning-based system was established to achieve three subgoals: predicting star ratings from comments, a feedback model, and a knowledge-based recommendation system. The system used both random forest classifiers and decision tree classifiers to predict star ratings and employed clustering and topic modeling to identify themes from the comments. Due to the majority of work being focused on identifying fake news, it has become difficult to apply these models for news classification in the real world. Therefore, Dauad et al. [
33] utilized machine learning techniques for classifying online news articles, proposing a method based on a hyperparameter optimization of support vector machines and compared it with five other maximum likelihood classification techniques. The results demonstrated that the optimized support vector machine model exhibited better performance than the other models. Finally, the authors used real-world datasets to classify news articles. Past academic work on improving the YouTube learning environment has mainly collected learners’ impressions through interviews and questionnaires. To overcome the above disadvantages, Alawadh et al. [
34] proposed using the YouTube API to collect comments from three randomly selected popular YouTube channels and analyzed the comments using TextBlob and automated latent semantic analysis (LSA) methods to understand global and open discussion topics. Additionally, the authors proposed hypotheses and conclusions about YouTube EFL learning, as well as advice for English learners who hope to use both online and offline learning. Finally, that article highlighted the importance of reviews in order to provide practical information for learning English based on YouTube. The digital novel application Wattpad is one of the most popular apps on the Google Play Store. This research [
35] aimed to conduct topic modeling by analyzing user reviews of the Wattpad app, with data obtained from the Google Play store using web scraping techniques. Unsupervised learning methods such as latent Dirichlet allocation (LDA) were used for topic modeling to effectively identify different themes relevant to Wattpad reviews. That study utilized the LDA method to generate words representing the major themes to provide a better understanding of the latest information about the Wattpad app. Liu et al. [
36] primarily investigated the knowledge structure and evolutionary trends in the field of artificial intelligence. They employed a new latent feature topic model, called New-LDA, for topic recognition research and analyzed the knowledge structure of the field from the perspectives of topic recognition and coword analysis. The authors also introduced a time series model to establish a topic evolution network and conducted a comparative analysis of high-frequency words in three periods to identify the evolutionary patterns of the knowledge structure in AI.
In addition, several models based on word embedding and pretrained language models have emerged. Bianchi et al. [
17] proposed a new topic model, which was a cross-lingual model that utilized the pretraining method. The model acquired knowledge from one language and applied it to predict topics for unseen documents written in different languages. Hoyle et al. [
37] introduced a teacher–student model that utilized knowledge distillation for topic discovery tasks. That model was based on a variational autoencoder and could effectively combine various neural topic models, including the BAT + Scholar model. The BAT + Scholar model could seamlessly integrate the pretrained language model BERT with other neural topic models.
Topic models have been used with networks such as LSTM [
38] networks in order to discover more coherent topics. Ding et al. [
39] used an RNN to detect discontinued words and merged its output with document topic vectors to cluster the same semantic content. Jin et al. [
40] proposed a matrix-decomposition model, LTMF, which integrated long short-term networks and topic modeling for comment understanding. That model showed a better topic clustering capability compared to traditional topic-model-based approaches.
Data augmentation is widely employed in text classification [
41] and text clustering tasks [
42], especially in situations where resources are limited. It has the potential to increase the size and enhance the quality of training data, as well as the robustness of deep neural networks. While data augmentation techniques have mainly been utilized in the image domain, their implementation in the text domain may have unforeseen consequences. This article explores various data enhancement techniques. Wei et al. [
20] applied random swapping, random insertion, random deletion, and synonym replacement to improve text data, but that approach may eliminate useful information from the original text and adversely impact results. To overcome these limitations, Karimi et al. [
43] suggested a straightforward data augmentation method that avoided the removal of information from the source dataset. That method involved the insertion of punctuation marks to alter their position within a sentence, thereby boosting the model’s generalization ability and outperforming the baseline model.
In recent years, scholars have explored ways to improve the models based on a combination of word embedding and topic models. Our approach explores the fusion of data augmentation and the sentence encoder SBERT and neural topic models on this basis and obtains high-quality topics.
4. Experiments
Our task was similar to an unsupervised clustering task, in which we aimed to mine a large amount of text for potential topics for a quick understanding of the text’s thematic content, and we used a neural topic model that incorporated data-enhanced knowledge and a sentence encoder to discover high-quality (relatively coherent and diverse) topics on English data.
4.1. DataSet
We used the M10 dataset in English [
44] as our experimental dataset, which is a short-text dataset. The M10 dataset consists of 8355 documents with a vocabulary size of 1696. We preprocessed the data by converting the text to lowercase, removing punctuation and eliminating stop words and other operations.
4.2. Settings
The model settings in this paper included the following parameters: learning _rate, dropout, batch_size, optimizer, embedding_dim, etc. For more visualization, the settings are shown in
Table 1.
4.3. Baselines
We used the results of the following models run on the M10 dataset as a baseline.
LDA [1]: this method computes a topic distribution for each article (called the article-topic distribution) and approximates each topic to a probability distribution over the vocabulary (called the topic-word distribution); it is a classic method of topic modeling.
ProdLDA [22]: this neural topic model uses a logistic Gaussian distribution to approximate the Dirichlet distribution, optimizes its components, and uses the Adam optimizer, a batch normalization, and other units in the encoder network to avoid AEVB component crashes occurring; ProdLDA is a widely used classical neural topic model.
SBERT + LDA: an approach combining the sentence encoder SBERT and traditional topic models; we used the SBERT + LDA module from the method of Bianchi et al. [
17], where the powerful contextualized embedding of pretrained language models helped the topic models to better mine topics.
ETM [13]: This model is a document-generation model that combines the traditional topic model LDA with word embeddings. The ETM is capable of identifying meaningful topics despite having a vast vocabulary that includes infrequent words and commonly used stop words.
ZeroShotTM [17]: This model uses pretrained contextualized embeddings instead of the bag-of-words input representation in the topic model, which allows it to capture contextually relevant semantic information, and it is a fusion of a sentence encoder and a neural topic model (SBERT + ProdLDA). The method achieves excellent results on topic mining tasks.
4.4. Evaluation Indicator
Topic coherence: Topic coherence refers to the relatedness of words in a topic, i.e., whether the words in a topic share the same thematic characteristics. The purpose of topic coherence evaluation metrics is to assess the relevance and consistency of the topics extracted from a topic model. Topic coherence evaluation metrics commonly use measures such as NPMI and C_V to evaluate topic coherence. The evaluation metrics aim to assess whether the topic model can generate semantically coherent and easily understandable topics. For example, the group of words “apple, banana, orange, grape” is more coherent and aligned with human judgment than “apple, banana, packaging paper, price”.
Evaluating topic coherence is usually calculated using the normalized point mutual information (NPMI) [
45,
46]. The score for each topic is based on the word combinations of the first T words returned for that topic to calculate the co-occurrence, and then the topic coherence score is calculated based on the co-occurrence of the words. By default, the first 10 words of each topic are used to calculate the value of the NPMI. It is defined in Equation (
5):
where
is the probability that the word
appears in a document, and
is the number of times the pair
appears in a document.
In addition, the C_V metric is another method used to evaluate the consistency of topic models, similar to the NPMI approach. C_V can measure both the internal coherence of a topic and the coherence between topics. Specifically, C_V utilizes the co-occurrence information of words to calculate the relevance within a topic and the separation between topics, thus assessing the quality of topics. We followed the approach used by Terragni et al. [
44] to conveniently compute the coherence metrics (NPMI,C_V) for topics.
Topic diversity: The RBO [
47] measure is based on a simple probabilistic user model. It compares the first ten words of two topics. We judged the diversity of topics by the reciprocal of the RBO measure [
44,
48]. For the same topic in a theme, it has a countdown of 0, while for completely different topics, it has a countdown of 1. The better the topic diversity, the higher the score, indicating a better model extraction.
We show some examples of topics mined by the model to better visually represent the topics proposed by the model in this paper and to view the coherence of the topics in a human-compatible way. When the semantics of the words of a set of topics are similar, we can consider them as semantically coherent and high-quality topics. When a set of topics is semantically coherent and the words are not identical, they can be considered as topics with a high diversity.
5. Results and Analysis
First, we evaluated the topic coherence metrics NPMI and C_V values, with the number of topics set to 50. As shown in
Table 2, we can see that LDA performed the worst, with low scores in both NPMI and C_V metrics. LDA is a probabilistic topic model based on statistics. ProdLDA ranked second to last in NPMI and C_V values. It is a neural topic model that uses a variational autoencoder. The C_V value of SBERT + LDA was second only to ZeroShot
TM, but the NPMI value was lower and in the fourth place. The ETM model had a higher NPMI value than LDA and ProdLDA, but its score was relatively low in the C_V metric. ZeroShot
TM ranked second in the model list. Although it scored higher than the previous models in both metrics, it still had its drawbacks, which may be attributed to its lack of consideration for data sparsity issues. Its scores in both metrics were close to our model’s scores. Our model performed the best in both metrics, thanks to our approach that overcame the data sparsity issue in text and enhanced the comprehensive information extraction ability. Thus, our model had a better topic quality.
Then, we evaluated the diversity metrics of different topic models using the reciprocal of the RBO measure as the score, with the number of topics set to 20. The results are shown in
Table 3. From the table, we can see that ProdLDA performed second worst in terms of diversity. Diversity measured the frequency of different words appearing in each topic, and its performance was average. The LDA model had the worst diversity performance due to its high word repetition rate in topics. ZeroShot
TM had a similar diversity to that of our model. Our model exhibited a good diversity in short-text datasets, with the highest diversity metric score.
Then, when the number of topics was set to 50, we compared the topic diversity scores of different models. The results are shown in
Table 4. From the table, it can be seen that LDA performed relatively poorly, as it is a probability-based statistical model that is not as effective as the neural topic model in terms of performance. The topic diversity performance of the ProdLDA model was average, while the ZeroShot
TM model was second only to our model. Our model still demonstrated a good topic diversity, with a higher score in topic diversity than other baseline models.
Then, we performed ablation experiments, as shown in
Table 5; we conducted further ablation experiments and demonstrated the variations in NPMI scores of our model. In this experiment, we employed the model (“distiluse-base-multilingual-cased-v2”) with a dimension of 512 for SBERT(d), while SBERT(a) utilized the other module (“all-mpnet-base-v2”) with a dimension of 768. For more details about the SBERT model, please refer to the paper [
18]. As seen from the table, when a larger SBERT model was employed, the score increased by 0.7%. Furthermore, when we integrated the Keyword Easy Data Augmentation (KEDA) module and the BiLSTM-Att module on top of the SBERT model, the NPMI score increased by 1.9%. This improvement could be attributed to the adoption of the new data augmentation method and the use of the attention mechanism to filter out noisy words. The experimental results demonstrated the effectiveness of our proposed method.
Next, we show some examples of topics extracted by the ZeroShot
TM model in
Table 6. First of all, we observe that in topic_id = 8, the topic should be about science and technology, while the other two topics are not very coherent and cannot be distinguished from the specific topic to be expressed. There is a need to improve the interpretability or coherence of the topics.
Finally, to make the comparison of topics more intuitive, we provide several examples of topics extracted by our model, as shown in
Table 7. It can be observed that when Topic_id = 3 and Topic_id = 12, the instances extracted by the model should reflect topics such as technology and learning, and when Topic_id = 35, the model should extract topics such as the economy. From the table, we can see that the themes generated by our proposed model were more coherent and interpretable. However, there were still themes that did not work well, and this is where we need to improve in the future.
6. Conclusions
In this paper, we proposed a neural topic model that incorporated SBERT and new data enhancement methods, which incorporated data enhancement knowledge such as keywords to help overcome problems such as the sparsity of text, and the attention mechanism was then used to reduce the effect of topic-irrelevant words on the results. We used a new sentence vector encoder to represent meaningful rich sentence information. We merged the information enhanced by the data and processed by the attention mechanism with high-quality semantic feature information (using weighted feature fusion). Finally, the fused feature information was used as the input to the neural topic model encoder, which was processed by the neural topic model to mine high-quality topics, with an average score improvement of 2.5% for topic coherence and 1.2% for topic diversity compared to the baseline model. Thus, our model achieved excellent results in terms of coherence and diversity.
In the future, we plan to explore new pretrained language models, such as Phrase-Bert, which can extract fine-grained feature information, leading to more accurate and richer sentence representations. We will also explore adversarial training techniques to enhance the robustness of the topic model, as well as new neural topic models to improve the quality of topic extraction.





{kind=link}
{kind=link}
{kind=link}