1. Introduction
With the advancement of Internet technology, people can obtain lots of information by using computers or cell phones. It is difficult for people to quickly access the information they seek when faced with such a large amount of information, which leads to the problem of information overload [
1,
2], i.e., users cannot easily access the information they are searching for. On the other hand, providers of Internet content are facing a long-tail problem [
3,
4,
5].
In response to the above problems, recommendation systems have become a solution. These systems have attracted much attention and have developed applications in academia and industry as they provide personalized items to meet users’ interests and alleviate the problem of information explosion [
6,
7,
8]. A recommendation system analyzes users’ historical behaviors, preferences and interests to recommend content that meets their needs. It greatly reduces the time and cost of finding and selecting content and improves user experience and satisfaction. At the same time, it also provides Internet content providers with a more accurate target audience and higher revenue.
Early recommendation systems were mostly based on content-based recommendation algorithms [
9,
10], i.e., recommendations using the degree of similarity in content. The user’s interests are modeled by analyzing the features and attributes of the items. The user’s preferences are evaluated by calculating the similarity between their preferred items and other items. Although content-based recommendation algorithms have good explanatory power, they may suffer from “information filtering”, i.e., if the user’s history is too small or too homogeneous, the recommendation results may not be diverse enough.
Most subsequent work has focused on traditional collaborative filtering-based recommendation algorithms [
11,
12,
13,
14,
15,
16,
17,
18], which do not require prior feature extraction or modeling of items. Collaborative filtering-based recommendation algorithms are mainly divided into two types of algorithms: user-based [
19,
20], which recommends products of interest to similar users, and item-based [
21,
22], which recommends items to users of similar items. However, such algorithms generally suffer from user–item interaction data sparsity [
23,
24] (i.e., unsatisfactory recommendations when user history interaction data are sparse) and cold starts [
25,
26] (i.e., it is difficult to recommend products to new users while also recommending brand new items that have not been explored in depth).
To alleviate the shortcomings of the above algorithm problem, other information sources can be introduced, such as users’ personal information [
27], user comments [
28,
29], item attribute information [
30] or knowledge graphs [
31,
32,
33,
34,
35,
36,
37,
38]. There is a large amount of auxiliary information that can be used by the recommendation algorithm, and the recommendation system can filter or sort the recommendation results based on this auxiliary information, so as to improve the diversity, real-time nature and accuracy of recommendations and meet the personalized needs of users.
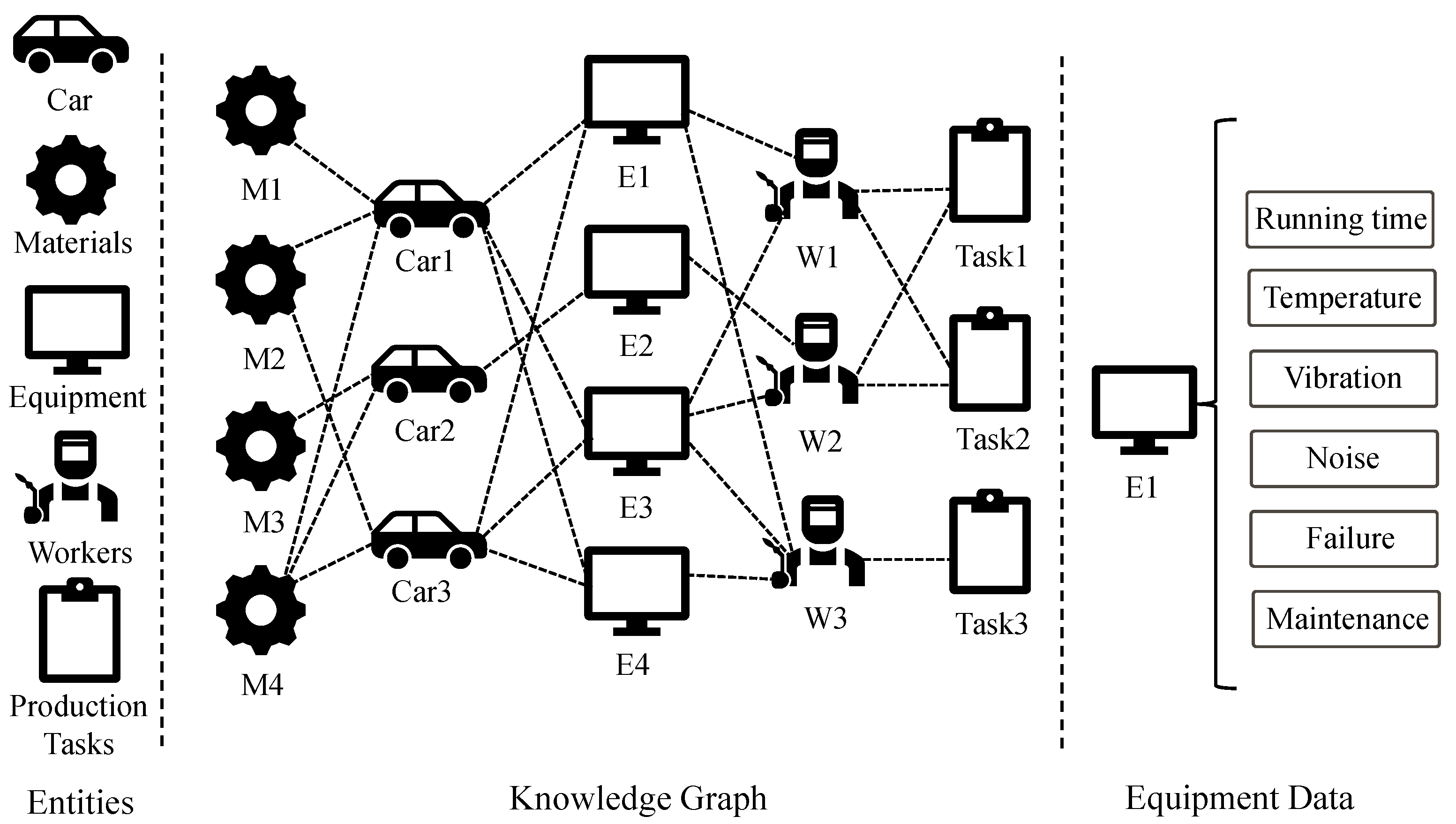
A knowledge graph is essentially a semantic network graph information structure that consists of a set of entities and relationships between entities (which can also be called nodes and edges between nodes), and can be used to represent any type of knowledge [
32]. As shown in
Figure 1, the car manufacturing recommendation is used as an example. Different types of cars are considered as users and other entities as items. The knowledge graph stores various information on the production line, including cars, equipment, personnel, materials and production tasks, etc. Car1 and Car3 both prefer to use E1, E2 and E3 in their respective production lines, and they both use M2 and M3 in the selection of materials, which indicates that Car1 and Car3 have some correlation. The recommendation system can analyze this data and provide production planning and scheduling suggestions for the company. When the production demand of Car1 suddenly increases, the recommendation system can suggest shifting some production tasks to the production line of Car3 to reduce the pressure. It can also analyze equipment operation data, such as temperature, vibration and noise, to predict the health of the equipment. If a piece of equipment is about to break down, the recommendation system will send an early alert and schedule repairs. This helps reduce equipment downtime and production losses. In terms of human resources, the recommendation system can provide companies with reasonable personnel allocation suggestions based on production tasks and the equipment that workers can operate. W1 and W2 are similar in production tasks, and W1 and W3 can operate similar equipment. According to different relationships, different weights are assigned as a way to decide which relationship is more important.
Users, items and their attributes can be mapped to a knowledge graph in a recommendation task, which can be used to further explore the potential relationship between users and items [
33]. Feature learning through knowledge graphs can represent low-dimensional features of users and items [
34], be useful for mining potential information at a deeper level of item granularity [
36], and distinguish different levels of importance among items in a user’s history [
35], etc. Liang et al. proposed a Power Fault Retrieval and Recommendation Model (PF2RM) [
39], where they use the graph-neighbor cluster polymerization method to update the cold-start prediction sequence for the power knowledge graph. Wang et al. proposed RippleNet [
33], an end-to-end click-through prediction model using knowledge graphs as a source of auxiliary information, to continuously explore the potential interests of users by simulating the process of propagation of their interests. Users’ interests are centered on their history records and, layer-by-layer, extend to other items or entities on the knowledge graph to achieve the propagation of users’ interests. However, RippleNet is unable to distinguish the importance of items or entities within the propagation range. Wang et al. proposed the Knowledge Graph Convolutional Network (KGCN) [
34], a recommendation method based on graph convolutional neural networks that can automatically capture higher-order structural and semantic information in the knowledge graph. Unlike RippleNet, which focuses more on the expansion of user history, KGCN focuses more on the expansion of item entities. Since users have different purchase intentions and items have different attributes, it is easy to ignore different aspects of user and item information, so the obtained embedding representation is suboptimal. Traditional recommendation algorithms assume that all user–item interactions are undifferentiated, which leads to learned user representations that contain only coarse-grained user–item interaction intent, i.e., the intent is coupled. Existing knowledge graph-based recommendation algorithms suffer from the problem that when modeling users using their histories, they do not mine information at the item granularity and cannot distinguish the importance of different items in the histories.
In response to the above limitations of existing recommendation algorithms, this paper proposes an end-to-end KG-based recommendation model named AKGP (attentive knowledge graph perceptual propagation for recommendation). The framework uses knowledge graphs as auxiliary information to obtain the embedded representations of users and items, and through a multilayer propagation method, the extended entity sets and triples with different distances from the initial entity sets are obtained; these can effectively extend the potential vector representations of users and items. A knowledge-aware attention mechanism is used to generate different attention weights for tail entities to reveal their different meanings when different head entities and relationships are available. Knowledge graph embedding representations from propagation layer users and items are aggregated, and the predicted user preferences are output by the inner product. The model is further optimized using a stratified sampling strategy to retain entity features while reducing sample bias.
In summary, the contributions of this paper are as follows.
This article proposes an end-to-end algorithmic framework, AKGP, that uses knowledge graphs as auxiliary information, fusing structured knowledge with contextual information to build fine-grained knowledge models.
This article proposes an attention network that emphasizes the influence of different relationships between entities and explores users’ higher-order interests through perceptual propagation methods. Moreover, a stratified sampling strategy is used to retain entity features and reduce sample bias.
Extensive experiments are conducted on three datasets, and the experimental results demonstrate the effectiveness of the model in solving the sparsity and cold-start problems.
3. Preliminaries
This section explains the notation used in the framework and introduces the flow of the recommendation task as a way to better represent our AKGP model.
This paper adopts the same setup as most knowledge graph-based recommendation system approaches, and uses
to denote the set of users and
to denote the set of items, where
and
denote the total number of users and items. In the recommendation scenario, the user–item interaction is recorded in the form of an interaction matrix, denoted as
, where
is denoted as the element of the
row and the
column of the interaction matrix. When
, an interaction has been recorded between user
and item
, such as a click or a purchase. When
, no interaction has been recorded between the
th user and the
th item. The formula is as follows.
In addition, this section introduces knowledge graphs as additional auxiliary information in the recommendation system. A knowledge graph is a method of organizing knowledge, such as entities, concepts, relationships and attributes into a graphical structure. It is a semantic network for representing and storing knowledge, similar to human thought patterns, in a collection of triples consisting of , representing a knowledge graph in which two entities can be related to each other. The knowledge graph is denoted by , and generally, , and are used to denote the head entities, relationships and tail entities in the knowledge graph triad, respectively, where denotes the set of entities and denotes the set of relationships. The alignment between items and entities is denoted by , i.e., every item in the item set has an entity element with which it is mapped in the entity set.
In this paper, the user–item interaction matrix and the knowledge graph are used as inputs, and the aim of the recommendation task is to predict whether the user is interested in an item with which they have not interacted, i.e., the probability of user clicking on item . The prediction value will be a real number between 0 and 1, and a value closer to 1 means that the user is more interested in the item. In the recommendation scenario, after obtaining the predicted value of the user’s preference for the item, the item is recommended to the user in descending order according to the predicted value, which completes the recommendation task.
4. Methodology
This section provides an overview of the AKGP framework and describe, in detail, each of the components, including user–item initial embedding representation, the multilayer perceptual propagation and attention network, aggregated prediction and hierarchical sampling optimization. The overall schematic of the framework is shown in
Figure 2.
AKGP takes the user–item historical interaction information and the user–item related knowledge information in the knowledge graph as input, and models the structured knowledge at a fine-grained level using the TransD [
44] and hierarchical modeling methods. The user–item information is projected onto multiple vector spaces to obtain multifaceted fine-grained embedding vectors. To explore the higher-order interests of users, item
is associated with entity
in the knowledge graph, and user preferences are propagated on the knowledge graph through correspondence between the user embedding representation and entity
in the knowledge graph. In the propagation process, an attention network is used to obtain the weights of different relationships in the knowledge graph that affect the user’s interest, and the relationships are used as propagation factors over a certain number of neighbors to generate user-embedded representations and item-embedded representations. These embedded representations are aggregated for Click-Through Rate (CTR) prediction and Top-K recommendation. Based on the prediction results, the model is optimized using a stratified sampling strategy to reduce sample bias.
4.1. Initial Embedding Representation
The historical user–item interaction data, the specific corresponding set of domain knowledge graph triples, and the mapping relationships of entity items are collected to generate the corresponding embedded representations, which act as the input of this layer.
4.1.1. Knowledge Graph Embedding
Usually, a triple
is used to represent knowledge. Since there are too many entities and relationships with too many dimensions, one-hot vectors cannot capture the similarity when two entities or relationships are very close. Inspired by Wrod2Vec [
45], the entities and relationships in this paper are represented by the distributed representation method. Additionally, the recommendation scenario may encounter a situation whereby user–item interactions are very sparse, in which case, the above method can be combined with user–item interaction information by introducing the knowledge graph as an auxiliary information method to improve the recommendation effect. Knowledge graphs generally contain three types of data: structured knowledge (triples), textual knowledge, and visual knowledge. This paper uses the TransD knowledge graph embedding method to model structured knowledge and learn the structured representation of each item in the knowledge graph.
The aim of the TransD approach is to project the head and tail onto the hyperplane using the same transition matrix, as shown in
Figure 3. However, the head and tail are usually not entities of the same category (e.g., Robert Downey Jr., actor, Iron Man). In the given example, Robert Downey Jr. is an actor and Iron Man is a movie, which are two different categories of entities that should be transformed in different ways. Second, the projection should be related to the entities and their relationships, but the projection matrix is only determined by the relationships. TransD uses two vectors to represent each entity and relationship. The first vector represents the meaning of the entity or relationship, and the projection vector is used to construct the mapping matrix [
44]. The formula is as follows:
where the mapping matrix is defined by entities and relationships,
is the unit matrix, and the generated matrix is used to modify the unit matrix. Like the classical Trans series knowledge graph embedding algorithm, the distance between entities is used to represent the score. The formula is as follows:
Since TransD is calculated on the hyperplane, it is obtained according to the mapping matrix.
The loss function uses a max-margin function with negative sampling. The formula is as follows:
4.1.2. Fine-Grained Hierarchical Modeling
In coarse-grained modeling algorithms, the embedded representations of users and items are usually projected onto only one interest space and one feature space. This modeling approach assumes that there is only a single relationship between the interaction behaviors of users and the items, which cannot reflect the multiple interests and multiple intents of the interactions of users themselves, or the multiple attributes and multiple uses of items. The vector spaces can be defined as the entities and relationships in the knowledge graph (corresponding to mapping matrices , where , , ), thus producing a fine-grained model of the information in the knowledge graph and facilitating subsequent vector computation.
4.1.3. Initial User–Item Embedding Representation
The learned embedding information for individual entities is still limited, and additional contextual information needs to be extracted for each entity in order to help identify the location of the entity in the knowledge graph. As an example of a movie recommendation, a user has seen the movies “Deadpool” and “Green Lantern”. Both movies are linked in the knowledge graph to the actor Ryan Reynolds, and the recommendation system may infer that the user is interested in movies starring Ryan Reynolds. Thus, it can recommend other movies and TV shows to this user that have starred Ryan Reynolds, such as “Free Guy” and “The Hitman’s Bodyguard”. Through the contextual information of entities in the knowledge graph, the recommendation system can identify potential connections between users and items, thus improving the performance of the recommendation system.
Predefined knowledge graphs can be used to associate user and project entities. Based on the identified entities, the subgraphs are constructed separately and all the relational links between them are extracted from the original knowledge graph. Since the relationships between the identified entities may be sparse and lack diversity, the current knowledge subgraph is extended to within one hop of the identified entities.
The user–item interaction information contains users’ overall preferences, and the knowledge graph contains the auxiliary knowledge information related to users and items. The user–item interaction graph and the knowledge graph can be fused through the mapping relationship between items and entities. This paper uses a set
to represent the alignment of items with entities in the knowledge graph, so the initial set of entities for users is defined as follows:
Similarly, the set of composite items
and the set of pairs
, which represent the initial set of entities of item
, are defined as follows:
The order interaction information can most effectively represent the underlying semantics of entities, and the initial embedding layer explicitly encodes it into the initial set of entities to enhance the representation of users and items and improve the recommendation effect. This can also continuously emphasize the information of the original items and reduce bias due to multi-layer propagation.
4.2. Multi-Layer Perceptual Propagation and Attention Networks
This paper designs a multi-layer perceptual propagation method. The neighboring entities in the knowledge graph are always strongly related, so by propagating along the links in the knowledge graph, the extended entity sets and triples with different distances from the initial entity sets can be obtained, which can effectively extend the potential vector representations of users and items, as shown in
Figure 4.
The entity set definition of user
is recursively represented as follows:
Similarly, the entity set definition of item
v is recursively represented as follows:
where
denotes the distance from the initial entity set. In addition, according to the definition of the entity set, the
th ternary set of user
is defined as follows:
Similarly, the
th ternary set of item
is defined as follows:
Using a knowledge graph as a source of edge information can enable us to construct more efficient models, since neighboring entities can be considered uncertain extensions of user preferences and item characteristics. The initial set of entities obtained through the initial embedding layer is similar to a sound wave source that propagates information layer-by-layer, from near to far, in the knowledge graph. Deep propagation based on the knowledge graph successfully acquires the higher-order interaction information features of users and items, which effectively improves the ability of the model to represent users and items under each behavior using potential vectors, thus alleviating the data sparsity and cold-start problems.
When each tail entity has different head entities and relationships in the knowledge graph, each tail entity has a different meaning and potential vector representation. Therefore, this paper proposes a neural network-based attention mechanism to generate different attention weights of tail entities to express their different meanings when they have different head entities and relationships.
The attention embedding of the
th triplet of the
th layer is as follows:
where
is the embedding of the head entity, which is the embedding of the
relationship, and
is the embedding of the tail entity of the
th triplet.
denotes the attention weights generated by the head entity and the relationship between the head and the tail. This section implements the function
by means of a neural network-based attention mechanism. The formula is as follows:
where
and
are trainable weight matrices and deviation values, and their subscripts indicate that they are parameters of different layers;
denotes user
or item
; and
denotes the
th layer triad of user
or item
. This paper chooses
as the nonlinear activation function, uses the
activation function for series operation, and finally, uses the
function to normalize the coefficients of the whole triad. Attention weights can indicate which neighboring tail entities should be given more attention in order to capture the knowledge graph more effectively. The final representation of the
th level triple for user
and item
is obtained as follows:
This yields a set of attention-weighted representations of user
and item
based on the knowledge graph, as follows:
Then, according to the importance of different relationships for user and item , this is used as a propagation factor to continue the propagation of the knowledge graph. Finally, the propagation stops after layers, and the final entity is obtained as the final representation of the user and item .
4.3. Aggregate and Prediction
The knowledge representation in each layer can be understood as the potential impact of different higher-order correlations and preference similarities. This paper uses the aggregator, which aggregates knowledge graph embedding representations of the user and item from the propagation layer, to aggregate multiple entity representations from the equation into a single vector of users and items.
The
aggregator connects the representation vectors in the representation set and uses a nonlinear transformation as follows:
This paper uses
to represent the aggregation vector of users and
to represent the aggregation vector of items. Finally, users’ preference scores for items are obtained using the inner products of the entity representations as follows:
4.4. Stratified Sampling and Iterations
Stratified sampling refers to stratifying a large collection of samples by feature or attribute, and then, randomly sampling each layer. In recommendation systems, the stratified sampling strategy can be used to solve the cold-start problem in migration learning.
Specifically, suppose there are two domain datasets (A and B). Dataset A contains the historical purchase records and rating information of users, while dataset B does not contain the historical records of users. To solve the cold-start problem in B, we can use the stratified sampling strategy to extract a certain number of samples from A for knowledge migration. The users in dataset A are stratified according to their purchase history or ratings, and then, a certain number of users and products are sampled from each layer, and these samples are used to train the recommendation model; then, the trained model is applied to B for recommendation. This method can retain the characteristics of the samples and avoid sample bias, and can also effectively use the historical data in A to carry out knowledge migration and thus improve the effectiveness of recommendations.
In this paper, a stratified sampling strategy is proposed. The data obtained by performing aggregated predictions are used as a sample set. The items are divided into multiple groups according to the user’s degree of preference for the items. Items with similar preference values are grouped into the same group, and the sum of the preference levels of the samples in each group is the same. Then, the items in each group are identified as positive or negative according to the sample labels. In a similar way to supervised learning, the item characteristics are preserved, and sample bias is avoided when using stratified sampling. Additionally, the learning process of the model is continuously iterated, as shown in
Figure 5.
In order to solve the category imbalance problem, this paper ensures the effect of model training by balancing the number of positive and negative samples, and extracting the same number of negative samples as positive samples for each user. The algorithm uses cross-entropy as the loss function of the whole AKGP model. The final loss function is as follows.
where
denotes a regularization term for the AKGP framework, which is added to the basic loss function to prevent overfitting, and
is the regularization parameter.
6. Conclusions and Future Work
To address the data sparsity and cold-start problems of recommendation models, this paper proposes a recommendation algorithm, AKGP, that incorporates attention and knowledge graph-aware propagation. User–item interaction information and a knowledge graph are used as inputs. Using the knowledge graph embedding method, fine-grained modeling and the extraction of contextual information, the interests of users are effectively mined. The weights of entities with different relationships are computed through attention networks and used as propagation factors to propagate information from the knowledge graph, in order to extend domain information on users and items. Domain information is aggregated and preference values predicted using a stratified sampling strategy to retain item information features while avoiding sample bias. Finally, an end-to-end recommendation framework is formed. In this study, we conducted comparative experiments on publicly available datasets for three different scenarios. The results show that the AKGP model achieves significant performance improvement in both CTR prediction and Top-K recommendation compared to the baseline algorithm. The ablation experiments further validated the effectiveness of this method.
In addition, we applied the model to the product design data and historical maintenance records provided by the project partner of this paper (an automotive parts manufacturing company). The knowledge graph is used to store and organize data related to product design, and the entities include parts, materials, manufacturing processes, etc. Based on the product information, the recommendation system predicts the top 10 suitable materials, most of which meet the product requirements. This helps reduce costs and increase productivity. The knowledge graph can also store the historical maintenance records of the equipment, causes of failure and repair methods. The recommendation system analyzes the operating status of the equipment and predicts the top 10 possible failures, most of which match the situation in which the failure occurred. This helps companies quickly identify the cause of failures and reduce unplanned downtime.
Although the recommendation effect of this paper is improved in mitigating the cold-start and data sparsity problems, the performance of the model is yet to be tested in the face of large-scale datasets. Secondly, if the knowledge graph embedding representation is used directly without any constraint, it will easily lead to noise penetration into the underlying information. In future work, we will set constraints for representation learning based on the correlation between nodes. We also plan to introduce other auxiliary information into the recommendation algorithm, such as user reviews and social networks.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}