
Research on Hierarchical Knowledge Graphs of Data, Information, and Knowledge Based on Multiple Data Sources


Abstract
1. Introduction
- (a)
- The characteristics of different medical data sources are used to improve the generalization of medical knowledge graphs;
- (b)
- According to the commonality of medical data, a two-step data fusion strategy was proposed, which is beneficial to improve the effective data fusion between different data sources;
- (c)
- According to the DIKW system, a construction method of the DIK medical knowledge graph applicable to the medical field was proposed.
2. Related Work
3. Medical Data Sources
3.1. Date Source Classification
- (a)
- Medical Dictionary
- (b)
- Chinese electronic medical record
- (c)
- Online medical community
- (a)
- There are plentiful medical data resources available for mining;
- (b)
- Medical data are originated from the real situation of users;
- (c)
- These data have better timeliness and can update faster.
3.2. Data Strategy
3.2.1. Data Source Selection Strategy
- (a)
- Firstly, considering that the publicly available medical dictionaries possess expertise, they were used as the base data to provide standards for medical knowledge graphs, for example, standards for disease entity names and coding rules;
- (b)
- Secondly, clinical experience data have higher authority and validity, so using electronic medical records as the core data of a medical database facilitates improving the accuracy of intelligent diagnosis, for example, detailed symptom narratives, clinical manifestations, drug effects, and treatment;
- (c)
- Finally, medical community data sources can not only greatly enrich the diversity of medical databases, but also guarantee the timeliness of medical knowledge using the Web. However, considering the quality of the data, they are used as supplementary data to the medical database, for example, dietary issues, usage, dosage, precautions of drugs, medical science, etc.
3.2.2. Two-Step Data Fusion Strategy
4. The DIK Architecture
4.1. The Definition of DIK Medical Resources
4.2. The Architecture of the DIK Three-Layer Knowledge Graph
4.2.1. Data Layer
4.2.2. Information Layer
4.2.3. Knowledge Layer
4.3. Implementation
4.3.1. Medical Knowledge Extraction Method
4.3.2. Two-Step Data Fusion Implementation
- (a)
- The first step is the data processing operation. The processing objects were for entity-type data that were obtained from different data sources using different methods. The data were processed using entity alignment methods to eliminate redundancy, remove errors, and perform alignment operations on entity terms with the same meaning and different names extracted from the data sources. When there was an entity alignment conflict, the entity in the medical data source was used as the standard, avoiding the incorrect operation of fusing similar disease entities into the same entity;
- (b)
- The second step is the fusion operation of medical data characteristics. In medical data, the role of disease entities was more central than that of various entities such as symptoms, treatments, drugs, departments, etc. Therefore, this paper utilized the characteristics of the “disease hub” to fuse medical entities from different data sources according to the developed medical relationship type, oriented by the names of disease entities. For example, the disease entity “tuberculosis” in the electronic medical record is firstly combined with the “A15.001” data in the medical dictionary through the “disease code” relationship type to form triplet data. Then, the relationship types of “symptoms”, “department”, “examination” and “treatment” are combined with the corresponding data in the electronic medical record. Finally, the relationship types of “food” and “medicine” are combined with the corresponding data in the medical community.
4.3.3. Construction of the DIK Medical Knowledge Graph
5. The Application and Experiment
5.1. The Application of Question and Answer
5.2. Experiment
- (1)
- The comparison of methods for the construction of knowledge graphs (KG, KGDIK);
- (2)
- The comparison of the data fusion strategies with and without (KG, KG (two-step) and KGDIK, KGDIK (two-step)).
6. Discussion
7. Conclusions
- (a)
- Inaccuracy of entity correspondence. The main challenge in the medical knowledge fusion phase is to achieve accurate entity linkage. The possible causes are that the diversity of medical knowledge sources leads to serious multi-source referencing problems of medical entities in different data sources [30,31,32]. Therefore, how to link the extracted entities accurately and correctly to the medical knowledge base in a context-constrained manner is a common concern in the current academic community;
- (b)
- Storage method for the knowledge graph. The ternary representation is widely used and accepted. However, it suffers from problems such as low computational efficiency as the data volume grows. Therefore, representing the semantic information in medical entities as dense low-dimensional real-valued vector methods will be the next research direction [33,34];
- (c)
- (d)
- The imperfection of the architecture of DIK. Originally, the DIKW was a complete architecture, but due to the planning of the research work, the three-layer architecture of the DIK was adopted in this paper. In order to use the complete DIKW architecture, it is necessary to consider how to proceed from the knowledge level to a higher level of abstracted knowledge [37].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hou, M.; Wei, R.; Lu, L.; Lan, X.; Cai, H. Research Review of Knowledge Graph and Its Application in Medical Domain. J. Comput. Res. Dev. 2018, 55, 2587–2599. [Google Scholar]
- Huang, M.; Li, M.; Han, H. Research on entity recognition and knowledge graph construction based on electronic medical records. Comput. Appl. Res. 2019, 36, 3735–3739. [Google Scholar]
- Yuan, K.-Q.; Deng, Y.; Chen, D.; Zhang, B.; Lei, K. Construction techniques and research development of medical knowledge graph. Appl. Res. Comput. 2018, 35, 1929–1936. [Google Scholar]
- Liu, C. Reseach of the Medical Knowledge Based on Knowledge Graph. Master’s Thesis, Zhejiang Sci-Tech Univeristy, Hangzhou, China, 2017. [Google Scholar]
- Zhou, M. The Research and Development of Question Answering System Based on Knowledge Graphs; Beijing University of Posts and Telecommunications: Beijing, China, 2017. [Google Scholar]
- Wang, H.; Zhang, J.; Cheng, X. Construction of Chinese Open Link Medical Data. China Digit. Med. 2013, 8, 5–8+15. [Google Scholar]
- Han, P.; Ma, J.; Zhang, J.M.; Liu, Y.Z. The framework Construction of Medical Knowledge Graph Based on Multi-data source Fusion. J. Mod. Inf. 2019, 39, 81–90. [Google Scholar]
- Shao, L.X.; Duan, Y.C.; Sun, X.B.; Gao, H.; Zhu, D.; Miao, W. Answering who/when, what, how, why through constructing data graph, information, knowledge graph and wisdom graph. In Proceedings of the 29th International Conference on Software Engineering and Knowledge Engineering, Pittsburgh, PA, USA, 5–7 July 2017; KSI Research Inc.: Pittsburgh, PA, USA, 2017; pp. 1–6. [Google Scholar]
- Wu, Y.; Yin, A.; Lin, K.; Yu, X.; Lai, G. Research on Knowledge Graph Construction Method Based on Multi-Data Source. J. Fuzhou Univ. (Nat. Sci. Ed.) 2017, 45, 329–335. [Google Scholar]
- Hu, F.H. Chinese Knowledge Graph Construction Method Based on Multiple Data Sources; East China University of Science and Technology: Shanghai, China, 2015. [Google Scholar]
- Cowie, J.; Lehnert, W. Information Extraction; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Shao, L.; Duan, Y.; Zhou, C.; Gao, H.; Chen, S. Design of Recommendation Services Based on Data, Information and Knowledge Graph Architecture. J. Front. Comput. Sci. Technol. 2019, 13, 214–225. [Google Scholar]
- Jagannatha, A.N.; Yu, H. Structured prediction models for RNN based sequence labeling in clinical text. In Proceedings of the 2016 Conference on Empirical labeling Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; ACL: New York, NY, USA, 2016; pp. 856–865. [Google Scholar]
- Li, M.; Zhang, Y.; Huang, M.; Chen, J.; Feng, W. Named Entity Recognition in Chinese Electronic Medical Record Using Attention Mechanism. In Proceedings of the 12th IEEE International Conference on Cyber Physical and Social Computing, Atlanta, GA, USA, 14–17 July 2019. [Google Scholar]
- Feng, L.; Huang, L.; Zeng, L.; Zhu, Q. Research on Web Spatial Data Acquisition Based on Distributed Web Crawler. J. Guizhou Univ. (Nat. Sci.) 2019, 36, 33–36. [Google Scholar]
- Pang, F. Design and Implementation of Distributed Web Crawler System Based on Python. Electron. Technol. Softw. Eng. 2018, 23, 6. [Google Scholar]
- Dong, X.L.; Cabrilovich, E.; Heitz, G.; Horn, W.; Murphy, K.; Sun, S.; Zhang, W. From data fusion to knowledge fusion. Proceeding VLDB Endow. 2014, 7, 881–892. [Google Scholar] [CrossRef]
- Carcia-Cresp Rodriguez, A.; Mencke, M.; Gómez-Berbís, J.M.; Colomo-Palacios, R. ODDIN: Ontology-driven differential diagnosis based on logical inference and probabilistic refinements. Expert Syst. Appl. 2010, 37, 2621–2628. [Google Scholar]
- Huang, C.C.; Liu, Z. Exploring query expansion for entity searches in PubMed. In Proceedings of the 7th International Workshop on Health Text Mining and Information Analysis, Austin, TX, USA, 5 November 2016; pp. 106–112. [Google Scholar]
- Terol, R.M.; Martinez-Barco, P.; Palomar, M. A knowledge based method for the medical question answering problem. Comput. Biol. Med. 2007, 37, 1511–1521. [Google Scholar] [CrossRef]
- Mou, D.; Ju, Y.; Dai, W.; Huang, L. Knowledge Discovery Strategy and Model of Virtual Health Community Text Data. Libr. Inf. Serv. 2018, 62, 125–130. [Google Scholar]
- Abacha, A.B.; Zweigenbaum, P. MEANS: A medical question-answering system combing NLP techniques and semantic Web technologies. Inf. Process. Manag. 2015, 51, 570–594. [Google Scholar] [CrossRef]
- Ruan, T.; Sun, C.; Wang, H.; Fang, Z.; Yin, Y. Construction of traditional Chinese medicine knowledge graph and its application. J. Med. Inform. 2016, 37, 8–13. [Google Scholar]
- Mu, Y.Z. Research on Chinese Electronic Medical Record Entities Recognition and Entity Relation Extraction Based on Semi-Supervised Learning; Hainan University: Haikou, China, 2018. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3060–3066. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Yang, P.; Yang, Z.; Luo, L.; Lin, H.; Wang, J. An Attention-Based Approach for Chemical Compound and Drug Named Entity Recognition. J. Comput. Res. Dev. 2018, 55, 1548–1556. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; Volume 2, pp. 207–212. [Google Scholar]
- Fang, T. Medical Knowledge Map Construction Based on Chinses Language Processing and Deep Learning; Henan Normal University: Xinxiang, China, 2018. [Google Scholar]
- Zhong, L. Research on the Construction Method of Chemical Knowledge Map for Baidu Encyclopedia. Softw. Guide 2017, 16, 168–170. [Google Scholar]
- Azeem, M.; Jamil, M.K.; Shang, Y. Notes on the Localization of Generalized Hexagonal Cellular Networks. Mathematics 2023, 11, 844. [Google Scholar] [CrossRef]
- Nadeem, M.F.; Azeem, M. The fault-tolerant beacon set of hexagonal Möbius ladder network. Math. Meth. Appl. Sci. 2023, 1–15. [Google Scholar] [CrossRef]
- Zhang, X.; Kanwal, M.; Azeem, M.; Jamil, M.; Mukhtar, M. Finite vertex-based resolvability of supramolecular chain in dialkyltin. Main Group Met. Chem. 2022, 45, 255–264. [Google Scholar] [CrossRef]
- Raza, H.; Sharma, S.K.; Azeem, M. On Domatic Number of Some Rotationally Symmetric Graphs. J. Math. 2023, 2023, 3816772. [Google Scholar] [CrossRef]
- Azeem, M.; Imran, M.; Nadeem, M.F. Sharp bounds on partition dimension of hexagonal Möbius ladder. J. King Saud Univ.-Sci. 2022, 34, 101779. [Google Scholar] [CrossRef]
- Shabbir, A.; Azeem, M. On the Partition Dimension of Tri-Hexagonal α-Boron Nanotube. IEEE Access 2021, 9, 55644–55653. [Google Scholar] [CrossRef]
- Azeem, M.; Nadeem, M.F. Metric-based resolvability of polycyclic aromatic hydrocarbons. Eur. Phys. J. Plus 2021, 136, 395. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
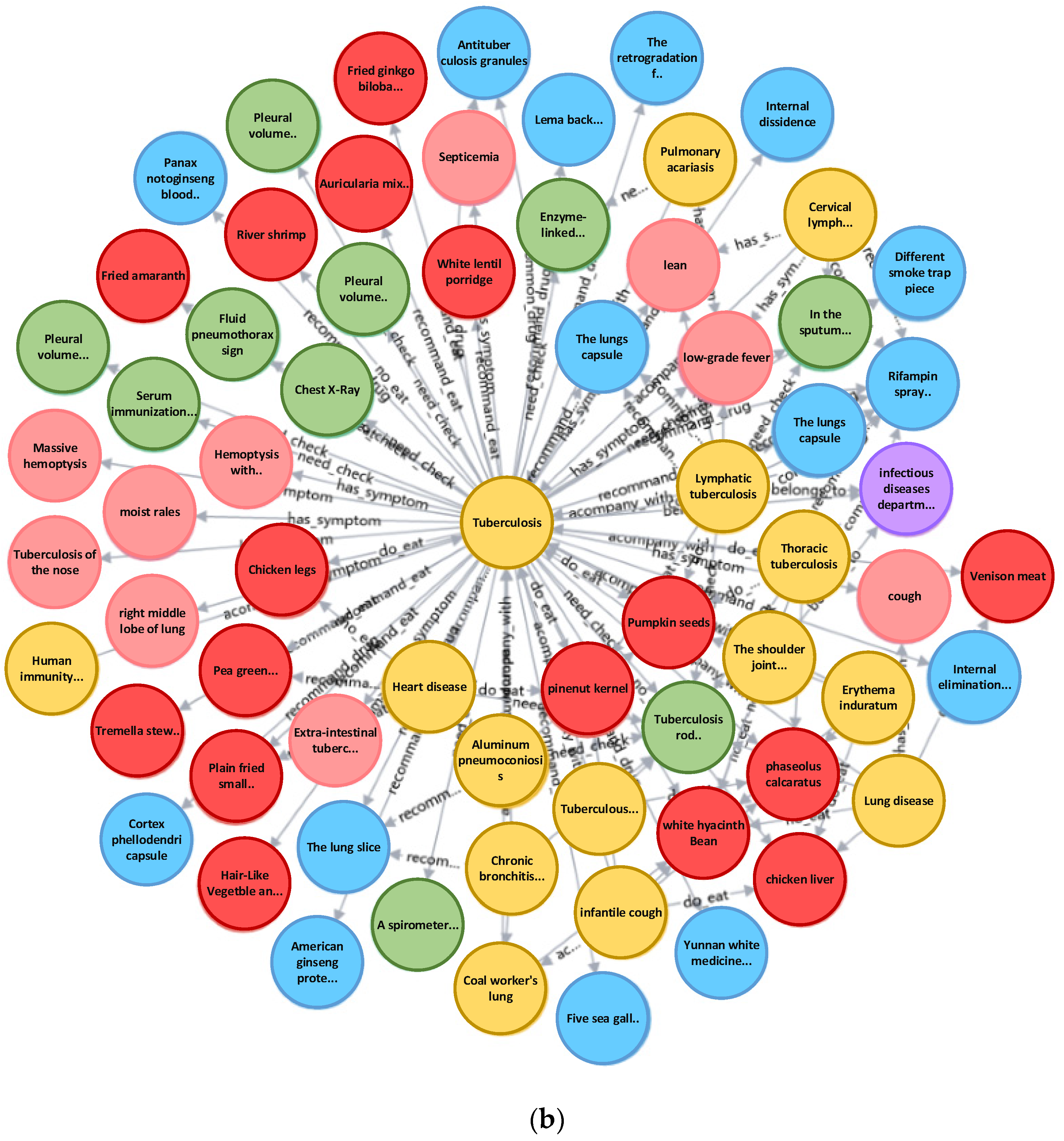{kind=link}
{kind=link}
| Medical Category | Entity | ||||
|---|---|---|---|---|---|
| Body Parts | Symptom | Examination | Disease | Treatment | |
| Outpatient Clinic | 1810 | 3750 | 10 | 720 | 0 |
| Medical History | 39,200 | 41,230 | 34,680 | 3520 | 400 |
| Treatment | 4900 | 2970 | 3290 | 1590 | 4893 |
| Discharged From Hospital | 31,900 | 21,730 | 29,400 | 80 | 98 |
| Total | 77,810 | 69,680 | 67,380 | 5910 | 5391 |
| Medical Entity | Disease | Drug | Food | Doctor |
|---|---|---|---|---|
| Quantity | 8807 | 4828 | 4870 | 100 |
| Resource Element | DataDIK | InformationDIK | KnowledgeDIK |
|---|---|---|---|
| form | Discrete Resource Elements | concept portfolio | Classification and Abstraction |
| Resource Answers | Who/When | what | why/how |
| map type | DGDIK | IGDIK | KGDIK |
| use | Identify resource existence | Interaction and Collaboration | Inference and Prediction |
| Method | Number of Disease Entities | Number of Medical Entities |
|---|---|---|
| Solid Alignment (General method) | 1275 | 39,359 |
| Entity Alignment (This paper’s method) | 1912 | 41,271 |
| Type | Quantity |
|---|---|
| Question | 54,000 |
| Answer | 101,743 |
| Knowledge Graph Type | Number of Replies (Pieces) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| KG | 26,894 | 49.80 | 47.90 | 49.13 |
| KGDIK | 36,352 | 85.84 | 84.72 | 85.27 |
| KG (two-step) | 42,744 | 58.47 | 54.92 | 56.60 |
| KGDIK (two-step) | 76,082 | 85.70 | 86.05 | 85.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Ni, Z.; Tian, L.; Hu, Y.; Shen, J.; Wang, Y. Research on Hierarchical Knowledge Graphs of Data, Information, and Knowledge Based on Multiple Data Sources. Appl. Sci. 2023, 13, 4783. https://doi.org/10.3390/app13084783
Li M, Ni Z, Tian L, Hu Y, Shen J, Wang Y. Research on Hierarchical Knowledge Graphs of Data, Information, and Knowledge Based on Multiple Data Sources. Applied Sciences. 2023; 13(8):4783. https://doi.org/10.3390/app13084783
Chicago/Turabian StyleLi, Menglong, Zehao Ni, Le Tian, Yuxiang Hu, Juan Shen, and Yu Wang. 2023. "Research on Hierarchical Knowledge Graphs of Data, Information, and Knowledge Based on Multiple Data Sources" Applied Sciences 13, no. 8: 4783. https://doi.org/10.3390/app13084783
APA StyleLi, M., Ni, Z., Tian, L., Hu, Y., Shen, J., & Wang, Y. (2023). Research on Hierarchical Knowledge Graphs of Data, Information, and Knowledge Based on Multiple Data Sources. Applied Sciences, 13(8), 4783. https://doi.org/10.3390/app13084783