
CVMan: A Framework for Clone-Incurred Vulnerability Management


Abstract
1. Introduction
- Type 1: exact clones. In this case, one piece of code is entirely copy-and-pasted from another piece of code, without modifications.
- Type 2: renamed clones. In this case, one piece of code is syntactically identical to another piece of code, with possible differences in the variable types, identifiers, comments, and/or whitespace.
- Type 3: restructured clones. In this case, one piece of code may be obtained from another piece of code by somewhat modifying program structures, such as deleting, inserting, or rearranging some statements.
- Type 4: semantic clones. In this case, two pieces of code may differ in syntax but have the same functionality (i.e., semantic equivalence).
2. Related Work
2.1. Characterizing Clones
2.2. Leveraging Clones to Detect Bugs and Vulnerabilities
3. The Clone-Incurred Vulnerability Management (CVMan) Framework
3.1. Motivation: Practitioners’ Questions (PQs)
- PQ1: What does the intuitive notion of the clone landscape of an enterprise network look like? Although the term clone landscape is intuitive, we need to define it precisely.
- PQ2: How does the clone landscape evolve with time? Answering this question allows the requester to keep track of the dynamic clone landscape and manage the dynamic situational awareness of the clone landscape.
- PQ3: What are the clone-incurred vulnerability landscapes (e.g., which clones are associated with what vulnerabilities)? Addressing this question allows the requester to keep track of clone-incurred vulnerabilities.
- PQ4: How should a requester leverage the clone and/or vulnerability landscape to manage the risks of clone-incurred vulnerabilities? For example, what should the requester do when a new vulnerability becomes known (e.g., disclosed by a software vendor)?
3.2. Framework Overview
3.3. The Clone Management Component
3.3.1. Detecting Clone Relations
3.3.2. Constructing a Clone Landscape
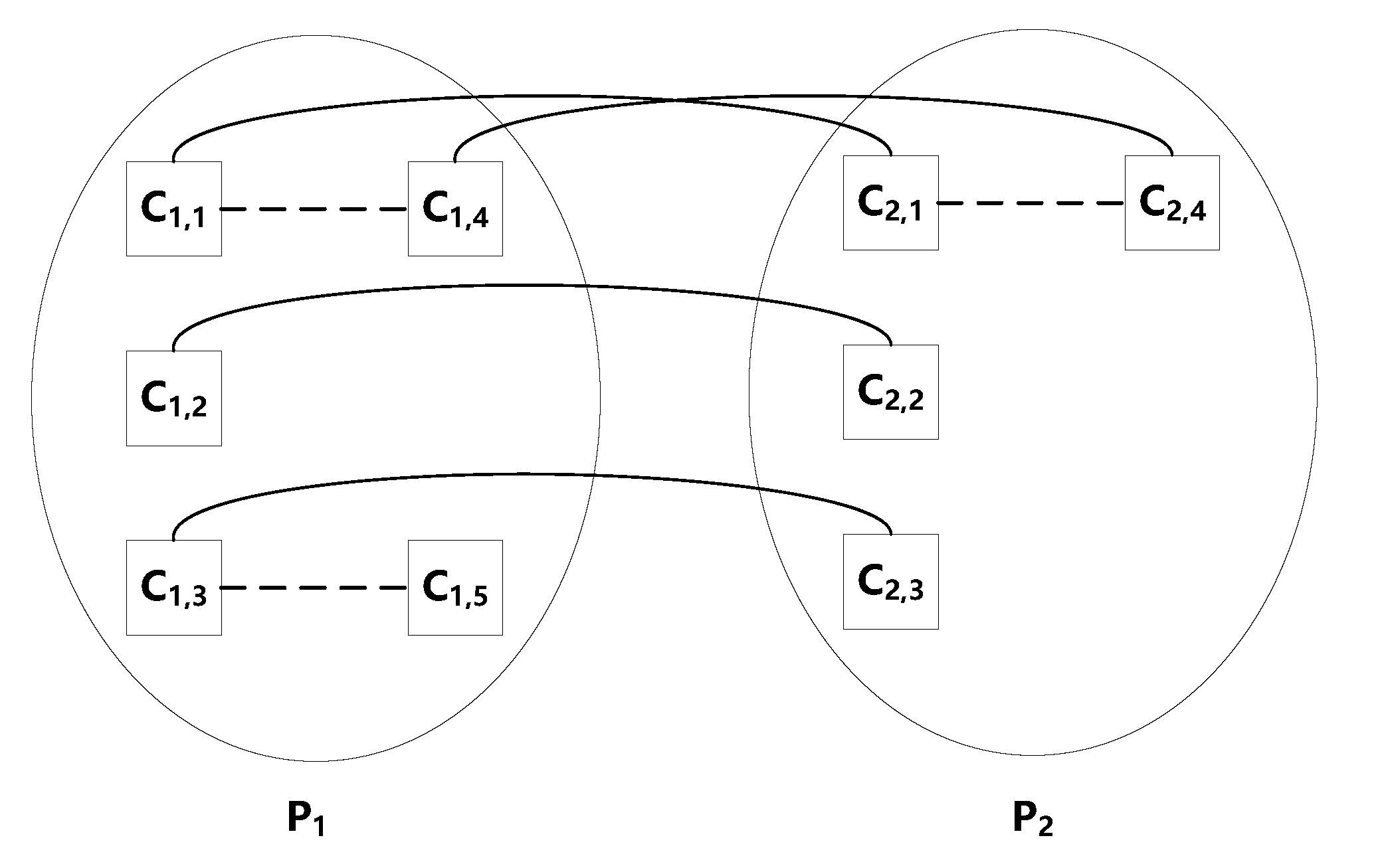
- Spatial Clone-Relation Graph (SCG): Given programs , we can derive a SCG to describe the clone relations between a pair of programs , where and . Intuitively, a SCG describes the clone landscape from given snapshots of programs, which may run in an enterprise network. In the case , the resulting SCG would capture the clone relations between the code fragments that are extracted from a given program; whereas means that the resulting SCG captures not only the clones within each program but also the clones between two programs.
- Temporal Clone-Relation Graph (TCG): Given a sequence of programs , which correspond to n versions of a program (e.g., n versions of Firefox), we can derive a TCG to describe the clone relations in a single version of the program and the clone relations between two versions of the program. Intuitively, a TCG additionally captures, when compared with SCG, the evolution of clones with time.
- For each where , there is a SCG corresponding to it, denoted by , which captures the clone relation between the code fragments of .
- For each pair of programs where and , there is a SCG corresponding to it, denoted by , which captures the clone relation between the code fragments of and the code fragments of . Note that consists of two sets of nodes, namely one set that corresponds to the code fragments in and another set that corresponds to the code fragments in . We denote the former set by and the later set by . It is possible that and/or , meaning that some code fragment is not only cloned in a single version (say ) but also cloned in another version (say ).
- Let , for , which is the set of code fragments that belong to and have been cloned in or another version . This leads to a layer- graph , where the edges only describe the clone-relation between the code fragments in . The resulting clone-relation graph is an n-layer network , where , and , meaning that the edges additionally capture the clone relations between code fragments in different versions of the program.
- The SCG that is derived from these programs when no temporal information about the programs is provided (i.e., the programs are for different applications/purposes or provided by different vendors).
- The TCG that is derived from these programs when temporal information about the programs is provided (e.g., some or all of the programs are different versions of the programs).
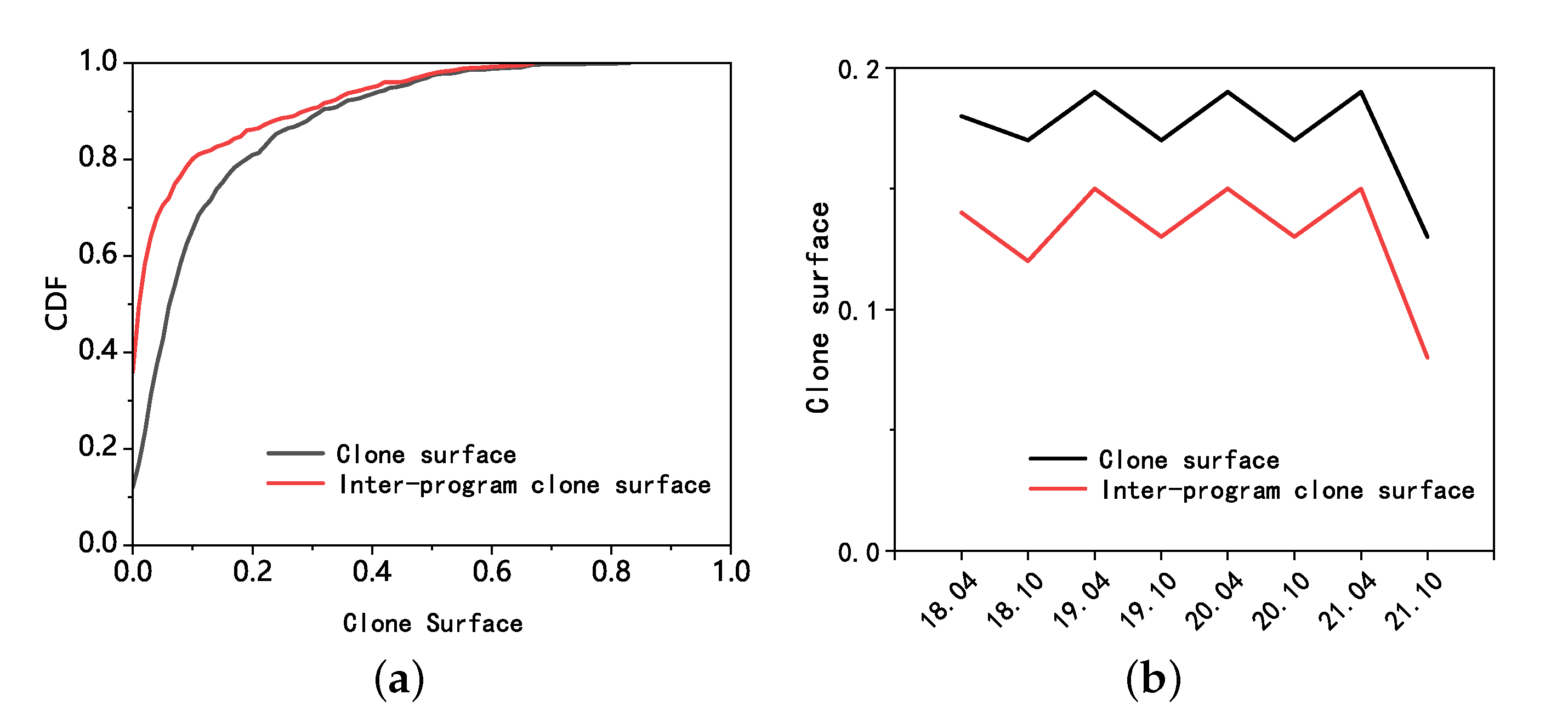
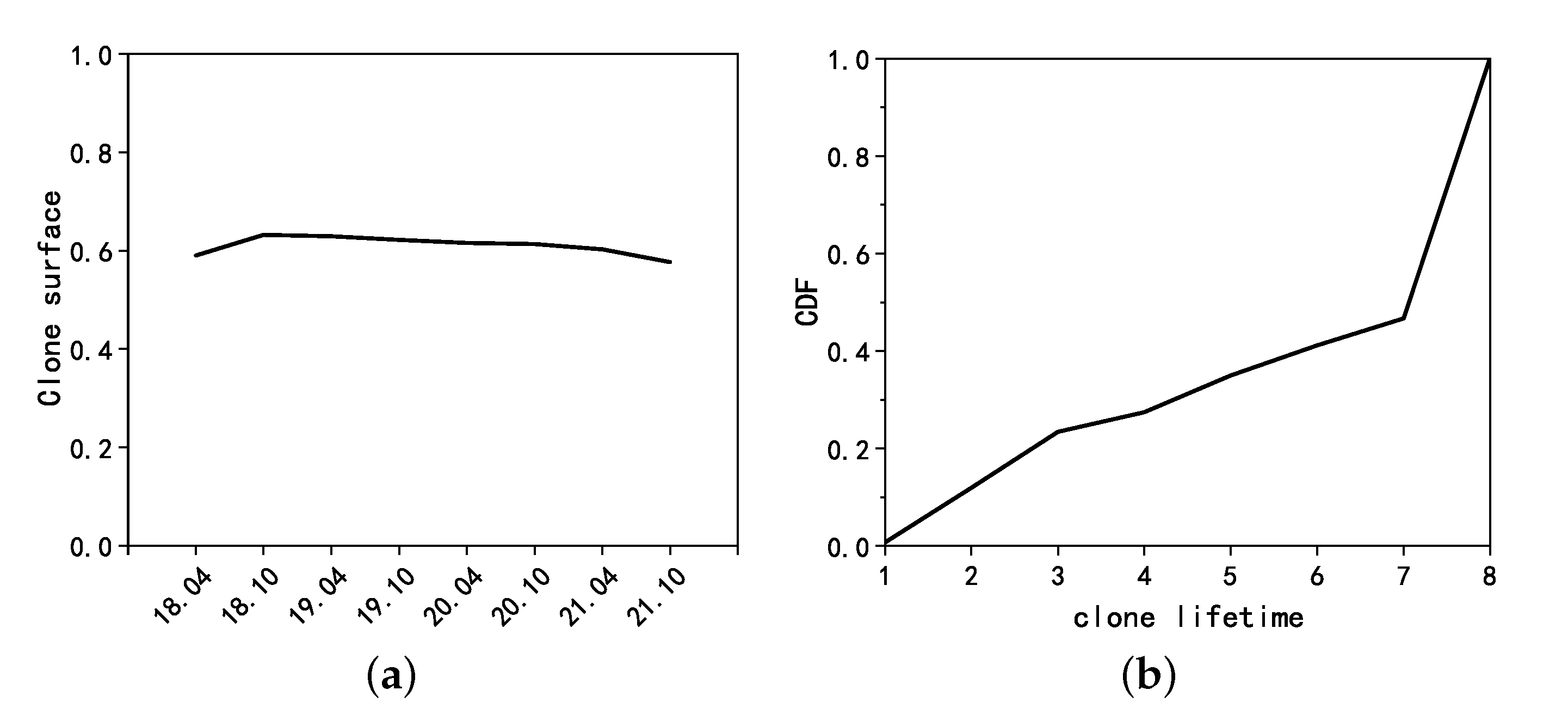
- Clone surface: This metric measures the fraction of code in a program that is cloned, either from another program or by another program. Specifically, for a program , this metric describes the percentage of cloned LoCs in , namely .
- Clone prevalence: This metric measures how prevalent clones are in a set of programs. Specifically, for a given code fragment C, this metric is defined as the number of clones of C in programs .
- Clone lifetime: This metric measures the lifecycle from a cloned code fragment. Suppose a given code fragment C appears in the given set of programs at time at the earliest and at time at the latest. Then, the lifetime of C with respect to is defined as .
3.4. The Vulnerability Management Component
3.4.1. Extracting Vulnerabilities
3.4.2. Constructing Clone-Incurred Vulnerability Landscape
- Clone-incurred vulnerability surface: This metric measures the fraction of code in a program that is cloned and vulnerable. Specifically, for a program , this metric describes the percentage of cloned LoCs in where the clone is also vulnerable, namely .
- Clone-incurred vulnerability prevalence: This metric measures how prevalent clones are in a set of programs. Specifically, for a given vulnerable code fragment C, this metric is defined as the number of clones of C in the programs .
- Clone-incurred vulnerability lifetime: This metric measures the lifecycle from a cloned vulnerable code fragment. Suppose that a given vulnerable code fragment C appeared in the given set of programs at time at the earliest and at time at the latest. Then, the lifetime of vulnerable clone code fragment C with respect to is defined as .
3.5. The Service Interface
4. Implementing CVMan Prototype System
4.1. The Clone Management Component
4.2. The Vulnerability Management Component
4.3. The Service Interface
5. Case Study: Applying CVMan to Analyze Clones in Ubuntu
5.1. Experiment with the Ubuntu System
The Programs That Are Analyzed in the Experiments: Ubuntu Repository
5.2. Answering PQ1
5.2.1. Clone Surface
5.2.2. Clone Prevalence
5.3. Answering PQ2
5.3.1. Clone Surface
5.3.2. Clone Prevalence
5.3.3. Clone Lifetime
5.4. Answering PQ3
5.4.1. Clone-Incurred Vulnerability Surface
5.4.2. Clone-Incurred Vulnerability Prevalence
5.4.3. Clone-Incurred Vulnerability Lifetime
5.5. Answering PQ4
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sonatype. 2022 Open Source Security and Risk Analysis Report; Technical Report; Sonatype: Fulton, MD, USA, 2022. [Google Scholar]
- Shi, Z.; Tang, J.; Yu, H.; Xing, Y.; Liu, Z.; Bai, W.; Li, T. A quantitative benefit evaluation of code search platform for enterprises. Sci. China Inf. Sci. 2020, 63, 1–3. [Google Scholar] [CrossRef]
- Lopes, C.V.; Maj, P.; Martins, P.; Saini, V.; Yang, D.; Zitny, J.; Sajnani, H.; Vitek, J. DéjàVu: A map of code duplicates on GitHub. Proc. ACM Program. Lang. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Python Software Foundation. PyPI · The Python Package Index. Available online: https://pypi.org/ (accessed on 27 February 2023).
- Ruby Community. RubyGems.org. Available online: https://rubygems.org/ (accessed on 27 February 2023).
- npm, Inc. npm. Available online: https://www.npmjs.com/ (accessed on 27 February 2023).
- The PHP Group. PEAR—PHP Extension and Application Repository. Available online: https://pear.php.net/ (accessed on 27 February 2023).
- The PHP Group. PECL: The PHP Extension Community Library. Available online: https://pecl.php.net (accessed on 27 February 2023).
- Debian. Debian—Packages. Available online: https://www.debian.org/distrib/packages (accessed on 27 February 2023).
- Canonical Ltd. Ubuntu—Ubuntu Packages Search. Available online: https://packages.ubuntu.com (accessed on 27 February 2023).
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and evaluation of clone detection tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef]
- Roy, C.K.; Cordy, J.R.; Koschke, R. Comparison and evaluation of code clone detection techniques and tools: A qualitative approach. Sci. Comput. Program. 2009, 74, 470–495. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Qi, H.; Hu, J. Vulpecker: An automated vulnerability detection system based on code similarity analysis. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Angeles, CA, USA, 5–8 December 2016; pp. 201–213. [Google Scholar]
- Kim, S.; Woo, S.; Lee, H.; Oh, H. Vuddy: A scalable approach for vulnerable code clone discovery. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 595–614. [Google Scholar]
- Liu, Z.; Wei, Q.; Cao, Y. Vfdetect: A vulnerable code clone detection system based on vulnerability fingerprint. In Proceedings of the 2017 IEEE third Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 3–5 October 2017; pp. 548–553. [Google Scholar]
- Jang, J.; Agrawal, A.; Brumley, D. ReDeBug: Finding unpatched code clones in entire os distributions. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 48–62. [Google Scholar]
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef]
- Li, Z.; Lu, S.; Myagmar, S.; Zhou, Y. CP-Miner: Finding copy-paste and related bugs in large-scale software code. IEEE Trans. Softw. Eng. 2006, 32, 176–192. [Google Scholar] [CrossRef]
- Sajnani, H.; Saini, V.; Svajlenko, J.; Roy, C.K.; Lopes, C.V. Sourcerercc: Scaling code clone detection to big-code. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 1157–1168. [Google Scholar]
- Yamaguchi, F.; Lottmann, M.; Rieck, K. Generalized vulnerability extrapolation using abstract syntax trees. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 359–368. [Google Scholar]
- Wu, Y.; Zou, D.; Dou, S.; Yang, S.; Yang, W.; Cheng, F.; Liang, H.; Jin, H. SCDetector: Software Functional Clone Detection Based on Semantic Tokens Analysis. In Proceedings of the 2020 35th IEEE/ACM International Conference on Automated Software Engineering (ASE), Virtual, 21–25 December 2020; pp. 821–833. [Google Scholar]
- Zou, Y.; Ban, B.; Xue, Y.; Xu, Y. CCGraph: A PDG-based code clone detector with approximate graph matching. In Proceedings of the 2020 35th IEEE/ACM International Conference on Automated Software Engineering (ASE), Virtual, 21–25 December 2020; pp. 931–942. [Google Scholar]
- Jiang, L.; Misherghi, G.; Su, Z.; Glondu, S. Deckard: Scalable and accurate tree-based detection of code clones. In Proceedings of the 29th International Conference on Software Engineering (ICSE’07), Minneapolis, MN, USA, 20–26 May 2007; pp. 96–105. [Google Scholar]
- Sasaki, Y.; Yamamoto, T.; Hayase, Y.; Inoue, K. Finding file clones in FreeBSD ports collection. In Proceedings of the 2010 seventh IEEE Working Conference on Mining Software Repositories (MSR 2010), Cape Town, South Africa, 2–3 May 2010; pp. 102–105. [Google Scholar]
- Mockus, A. Large-scale code reuse in open source software. In Proceedings of the First International Workshop on Emerging Trends in FLOSS Research and Development (FLOSS’07: ICSE Workshops 2007), Minneapolis, MN, USA, 20–26 May 2007; p. 7. [Google Scholar]
- Roy, C.K.; Cordy, J.R. Near-miss function clones in open source software: An empirical study. J. Softw. Maint. Evol. Res. Pract. 2010, 22, 165–189. [Google Scholar] [CrossRef]
- Heinemann, L.; Deissenboeck, F.; Gleirscher, M.; Hummel, B.; Irlbeck, M. On the extent and nature of software reuse in open source java projects. In Proceedings of the International Conference on Software Reuse; Springer: Berlin/Heidelberg, Germany, 2011; pp. 207–222. [Google Scholar]
- Koschke, R.; Bazrafshan, S. Software-clone rates in open-source programs written in C or C++. In Proceedings of the 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Osaka, Japan, 14–18 March 2016; Volume 3, pp. 1–7. [Google Scholar]
- Lozano, A.; Wermelinger, M. Assessing the effect of clones on changeability. In Proceedings of the 2008 IEEE International Conference on Software Maintenance, Beijing, China, 28 September 2008–4 October 2008; pp. 227–236. [Google Scholar]
- Hotta, K.; Sano, Y.; Higo, Y.; Kusumoto, S. Is duplicate code more frequently modified than non-duplicate code in software evolution? An empirical study on open source software. In Proceedings of the Joint ERCIM Workshop on Software Evolution (EVOL) and International Workshop on Principles of Software Evolution (IWPSE), Antwerp, Belgium, 20–21 September 2010; pp. 73–82. [Google Scholar]
- Lozano, A.; Wermelinger, M.; Nuseibeh, B. Evaluating the harmfulness of cloning: A change based experiment. In Proceedings of the Fourth International Workshop on Mining Software Repositories (MSR’07: ICSE Workshops 2007), Minneapolis, MN, USA, 20–26 May 2007; p. 18. [Google Scholar]
- Mondal, M.; Roy, C.K.; Schneider, K.A. An empirical study on clone stability. ACM SIGAPP Appl. Comput. Rev. 2012, 12, 20–36. [Google Scholar] [CrossRef]
- Krinke, J. Is cloned code more stable than non-cloned code? In Proceedings of the 2008 Eighth IEEE International Working Conference on Source Code Analysis and Manipulation, Beijing, China, 28–29 September 2008; pp. 57–66. [Google Scholar]
- Göde, N.; Koschke, R. Frequency and risks of changes to clones. In Proceedings of the 33rd International Conference on Software Engineering, Honolulu, HI, USA, 21–28 May 2011; pp. 311–320. [Google Scholar]
- Kim, M.; Sazawal, V.; Notkin, D.; Murphy, G. An empirical study of code clone genealogies. In Proceedings of the tenth European Software Engineering Conference Held Jointly with 13th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Lisbon, Portugal, 5–9 September 2005; pp. 187–196. [Google Scholar]
- Aversano, L.; Cerulo, L.; Di Penta, M. How clones are maintained: An empirical study. In Proceedings of the 11th European Conference on Software Maintenance and Reengineering (CSMR’07), Amsterdam, Netherlands, 21–23 March 2007; pp. 81–90. [Google Scholar]
- Saha, R.K.; Asaduzzaman, M.; Zibran, M.F.; Roy, C.K.; Schneider, K.A. Evaluating code clone genealogies at release level: An empirical study. In Proceedings of the 2010 Tenth IEEE Working Conference on Source Code Analysis and Manipulation, Timisoara, Romania, 12–13 September 2010; pp. 87–96. [Google Scholar]
- Zibran, M.F.; Saha, R.K.; Roy, C.K.; Schneider, K.A. Evaluating the conventional wisdom in clone removal: A genealogy-based empirical study. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1123–1130. [Google Scholar]
- Thongtanunam, P.; Shang, W.; Hassan, A.E. Will this clone be short-lived? Towards a better understanding of the characteristics of short-lived clones. Empir. Softw. Eng. 2019, 24, 937–972. [Google Scholar] [CrossRef]
- Sajnani, H.; Saini, V.; Lopes, C.V. A comparative study of bug patterns in java cloned and non-cloned code. In Proceedings of the 2014 IEEE 14th International Working Conference on Source Code Analysis and Manipulation, Victoria, BC, Canada, 28–29 September 2014; pp. 21–30. [Google Scholar]
- Rahman, F.; Bird, C.; Devanbu, P. Clones: What is that smell? Empir. Softw. Eng. 2012, 17, 503–530. [Google Scholar] [CrossRef]
- Li, J.; Ernst, M.D. CBCD: Cloned buggy code detector. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 310–320. [Google Scholar]
- Islam, J.F.; Mondal, M.; Roy, C.K. Bug replication in code clones: An empirical study. In Proceedings of the 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Osaka, Japan, 14–18 March 2016; Volume 1, pp. 68–78. [Google Scholar]
- Islam, M.R.; Zibran, M.F. A comparative study on vulnerabilities in categories of clones and non-cloned code. In Proceedings of the 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Osaka, Japan, 14–18 March 2016; Volume 3, pp. 8–14. [Google Scholar]
- Islam, M.R.; Zibran, M.F.; Nagpal, A. Security vulnerabilities in categories of clones and non-cloned code: An empirical study. In Proceedings of the 2017 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Toronto, ON, Canada, 9–10 November 2017; pp. 20–29. [Google Scholar]
- Cybersecurity, Critical Infrastructure. Framework for Improving Critical Infrastructure Cybersecurity. 2018. Available online: https://nvlpubs.Nist.Gov/nistpubs/CSWP/NIST.CSWP (accessed on 27 February 2023).
- National Institute of Standards and Technology. NVD—Vulnerabilities. Available online: https://nvd.nist.gov/vuln (accessed on 27 February 2023).
- Ctags. Universal Ctags. Available online: https://github.com/universal-ctags/ctags (accessed on 27 February 2023).
- Mozilla. Mozilla Foundation Security Advisories. Available online: https://www.mozilla.org/en-US/security/advisories/ (accessed on 27 February 2023).
- Canonical. Ubuntu Security Notices. Available online: https://ubuntu.com/security/notices (accessed on 27 February 2023).
- Ubuntu. Ubuntu CVE Tracker. Available online: https://people.canonical.com/~ubuntu-security/cve/ (accessed on 27 February 2023).
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable graph-based bug search for firmware images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 480–491. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 896–899. [Google Scholar]
- Duan, Y.; Li, X.; Wang, J.; Yin, H. Deepbindiff: Learning program-wide code representations for binary diffing. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | # C/C++ Programs | # Lines of C/C++ Code |
|---|---|---|
| 18.04 | 704 | 100,985,002 |
| 18.10 | 708 | 98,274,202 |
| 19.04 | 714 | 103,083,366 |
| 19.10 | 714 | 101,017,066 |
| 20.04 | 721 | 109,634,409 |
| 20.10 | 727 | 109,208,168 |
| 21.04 | 735 | 113,759,907 |
| Program | LoC | Clone LoC | Clone Surface |
|---|---|---|---|
| Fftw3 | 264,365 | 219,272 | 0.83 |
| M2300w | 2260 | 1685 | 0.75 |
| Libffi | 25,498 | 17,070 | 0.67 |
| Libart-lgpl | 10,754 | 7245 | 0.67 |
| Bzip2 | 5837 | 3824 | 0.66 |
| SuiteSparse | 539,437 | 358,110 | 0.66 |
| Libogg | 2637 | 1588 | 0.60 |
| Ldb | 67,599 | 39,641 | 0.59 |
| Libvpx | 296,977 | 166,979 | 0.56 |
| Hunspell | 18,520 | 10,362 | 0.56 |
| CVE | Program | Vulnerable Procedure | Clone-Incurred Vulnerability Prevalence | Clone-Incurred Vulnerability Lifetime |
|---|---|---|---|---|
| CVE-2019-15214 | Linux, Alsa-driver | snd_card_disconnect | 10 | 5 |
| CVE-2019-10638 | Linux | __ipv6_select_ident | 3 | 3 |
| CVE-2019-11487 | Linux | buffer_pipe_buf_get | 3 | 3 |
| CVE-2020-8648 | Linux | paste_selection | 5 | 5 |
| CVE-2020-9383 | Linux | set_fdc | 5 | 5 |
| CVE-2020-7053 | Linux | context_idr_cleanup | 3 | 3 |
| CVE-2018-15471 | Linux | xenvif_set_hash_mapping | 2 | 2 |
| CVE-2018-14625 | Linux | __vhost_vsock_get | 2 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Zou, D.; Xu, S.; Jin, H. CVMan: A Framework for Clone-Incurred Vulnerability Management. Appl. Sci. 2023, 13, 4948. https://doi.org/10.3390/app13084948
Shi J, Zou D, Xu S, Jin H. CVMan: A Framework for Clone-Incurred Vulnerability Management. Applied Sciences. 2023; 13(8):4948. https://doi.org/10.3390/app13084948
Chicago/Turabian StyleShi, Jian, Deqing Zou, Shouhuai Xu, and Hai Jin. 2023. "CVMan: A Framework for Clone-Incurred Vulnerability Management" Applied Sciences 13, no. 8: 4948. https://doi.org/10.3390/app13084948
APA StyleShi, J., Zou, D., Xu, S., & Jin, H. (2023). CVMan: A Framework for Clone-Incurred Vulnerability Management. Applied Sciences, 13(8), 4948. https://doi.org/10.3390/app13084948