1. Introduction
Automatic music genre classification is a well-established task in the field of machine learning [
1]. Its objective is to accurately classify given music tracks into a specific genre or set of genres [
2,
3]. The potential applications of music genre classification in music recommendation systems [
4] and music streaming services [
5] have led to extensive research in this area.
Music genre classification typically involves two steps: acoustic feature extraction and classification. As a critical component of music genre classification, acoustic feature extraction extracts meaningful characteristics from music tracks. Traditional music features include loudness, rhythm [
1], beat [
1,
6], a zero-crossing rate [
6], and Mel-frequency cepstral coefficients (MFCCs) [
7,
8,
9]. In addition, researchers have also explored spectrograms based on Fourier transform [
10,
11], wavelet transform [
12], or constant-Q [
13] transform, which contain rich time-frequency information (e.g., temporal information, periodic beat, rhythm, etc.) and can achieve a more satisfactory performance.
The other critical component of music genre classification is designing classification algorithms to handle acoustic features. Classic machine learning algorithms include statistical methods, such as naive Bayes classifiers [
14], random forests [
15], and support vector machines (SVMs) [
7,
8]. Meanwhile, some studies have revealed that classic machine learning models may not be suitable for large-scale data with diverse data distribution [
4,
5]. With the advancement of deep learning [
16] and computing resources, classification algorithms based on deep neural networks continue to grow in popularity. Most researchers choose recurrent neural networks (RNNs) [
17], convolutional neural networks (CNNs) [
18,
19], or Transformers [
9] as the classification backbone for music genre classification. Such deep learning-based methods could capture the latent information in acoustic features (e.g., timbre information and semantic information ), thus achieving a better performance in real-world applications.
However, there are still some limitations to the existing methods. Based on the analysis of the music signals, we observe that the genre of music is a very broad concept [
20]. Music tracks belonging to the same genre may have diverse acoustic characteristics, such as the rhythm and beats.
Figure 1 illustrates the significant variation in spectrograms of music tracks belonging to the “blues” genre.
The drawback of the existing methods is that they are not good at dealing with such diverse data distributions with large intra-class differences. To correctly classify Blues A and Blues C into the same genre, the model needs to further capture deep latent information. However, when the amount of data is insufficient for “deeper digging,” it can lead to false inductive bias and adversely affect the classification accuracy.
In this work, we specifically address the difficult problem of music genre classification with large differences in intra-class data distribution. We propose the locally activated gated neural network (LGNet) for music genre classification. LGNet includes multiple multi-layer perceptrons (MLPs) [
21] and a gated routing layer [
22] on the backbone of the classification network. We design several MLPs and employ them as multi-learners, focusing on knowledge in different aspects. The gated routing layer is applied to determine the allocation of inputs by calculating the matching degree between the input representations and each MLP. When the model encounters a certain sample, only the MLP with a high matching degree is activated, while the remaining MLPs are deactivated. In this manner, the model can adaptively allocate the most appropriate network layer according to the input samples. Taking
Figure 1 as an example, LGNet can dispatch the MLP layer specialized in processing periodic beats and rhythms to Blues A while dispatching the MLP layer specialized in processing low-frequency line spectra to Blues C. Such a locally activated structure introduces more parameters for complex modeling, and due to its locally activated property, additional parameters do not reduce the training and inference speed. Thereby, LGNet can alleviate the problem of large intra-class differences in an efficient manner.
According to our experimental results and analysis, we demonstrate that LGNet is highly effective for music genre classification with large intra-class differences. The locally activated gated network can achieve a satisfactory performance on the GTZAN dataset [
1]. The contributions of our work are summarized as follows:
We reveal the intra-class differences problem in music genre classification, which impedes the progress of recognition performance.
We propose the locally activated gated network, which can adaptively dispatch the most appropriate network layer based on inputs.
Our experimental results demonstrate that LGNet outperforms the existing methods on the filtered GTZAN dataset.
3. Materials and Methods
In this section, we give a detailed introduction to our LGNet, including our used acoustic features, the neural network backbone, and the complete training flow.
3.1. Acoustic Feature Extraction
According to the literature, the acoustic features based on the spectrogram contain rich time-frequency information. In recent years, applying neural networks to learn from the time-frequency spectrograms has become the most popular paradigm in automatic music genre classification. In this work, we perform three spectrogram-based acoustic features to verify the generalizability of our proposed strategy. We describe the feature extraction process in detail as follows:
STFT spectrogram: First, the input signal is windowed (e.g., using the Hanning window function) to reduce the effect of spectral leakage, which can cause the spectral components of the signal to spread beyond their actual frequency range. Next, the windowed signal is partitioned into short segments with overlapping (this operation is referred to as “framing”). For each segment, the Fourier transform is computed, resulting in a frequency-domain representation of the segment. Finally, the modulo frames are assembled into the STFT spectrogram, with time on the x-axis and frequency on the y-axis. The length of the Fourier transform determines the frequency resolution of the spectrogram, while the length of the segment determines its temporal resolution.
Mel spectrogram: The Mel spectrogram is a variation of the traditional spectrogram that emphasizes frequencies according to the perceptual characteristics of the human ear. As mentioned above, we can obtain the FFT spectrum by windowing, framing, and Fourier transform. The next step involves applying Mel filter banks to the spectrum. The Mel filter bank is a set of triangular bandpass filters that are spaced according to the Mel scale, which is a non-linear perceptual scale of frequency (as depicted in Equation (
1)). Each filter in the bank is centered at a particular Mel frequency and has a bandwidth that varies according to the Mel scale. Finally, the filtered spectrum is transformed using a logarithmic scale to obtain the Mel spectrogram.
CQT spectrogram: Constant-Q transform (CQT) is a popular tool for analyzing nonstationary signals with varying frequency content over time, such as musical signals. After obtaining the FFT spectrum, the CQT is computed by convolving the FFT spectrum of each windowed frame with a bank of bandpass filters that are logarithmically spaced in frequency (CQT kernel). Denote the maximum or minimum frequency to be processed as
.
represents the frequency of the
component, and
b is the number of spectral lines contained in an octave (e.g.,
b = 36).
can be formalized as
Then, the magnitude of the filtered spectrum is used to represent the CQT spectrogram. CQT obtains different frequency resolutions by using different window widths so that the frequency amplitude of each semitone can be obtained.
3.2. Neural Network Backbone
In this work, we adopt the deep residual network (ResNet-18) [
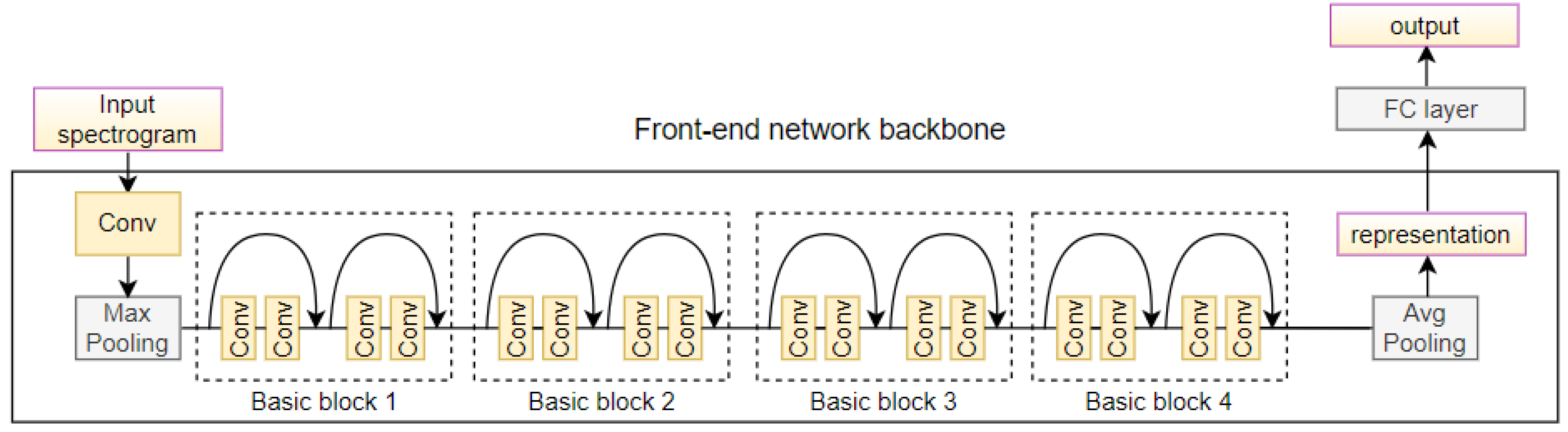
25] as our network backbone. As shown in
Figure 2, ResNet begins with convolving and pooling the input spectrogram to extract low-level features. This is followed by four basic blocks consisting of multiple convolutional layers, each with the skip connection that allows the input to bypass the block and flow directly to the output.
The basic block in ResNet-18 is called a “residual block”, which is designed to solve the problem of vanishing gradients in deep neural networks. The residual block takes inputs and passes them through a series of convolutional layers, batch normalization, and activation functions—ReLU (we omit the ReLU and batch normalization in
Figure 2 for brevity). The outputs from this series of layers is then added to the inputs, creating a “shortcut connection”. The purpose of the shortcut connection is to preserve the gradient information from the inputs, which can be lost as it passes through the convolutional layers. By adding the inputs to the outputs, the residual block allows the network to learn residual functions, which are easier to optimize than the original functions. The convolutional layers in the basic blocks have a filter size of 3 × 3 and a stride of 1, with padding used to keep the spatial dimensions of the inputs and outputs the same. The batch normalization layer normalizes the outputs from the convolutional layers, helping to reduce the effects of internal covariate shift and improve the stability and speed of the training process. The activation function used in the residual block is a rectified linear unit (ReLU), which helps to introduce non-linearity into the model and increase its capacity to learn complex representations.
ResNet also includes several pooling layers that downsample the feature maps to reduce the dimensionality of the input. The last adaptive pooling layer will pool the feature map into 512 × 1 × 1, and the representation vector can be obtained after the flatten operation. The classic ResNet is followed by a fully connected layer to output the classification result, while our LGNet uses this representation for subsequent locally gated activation and assignment. We refer to this ResNet-based network architecture that transforms the input spectrograms into one-dimensional representations as “Front-end network backbone”.
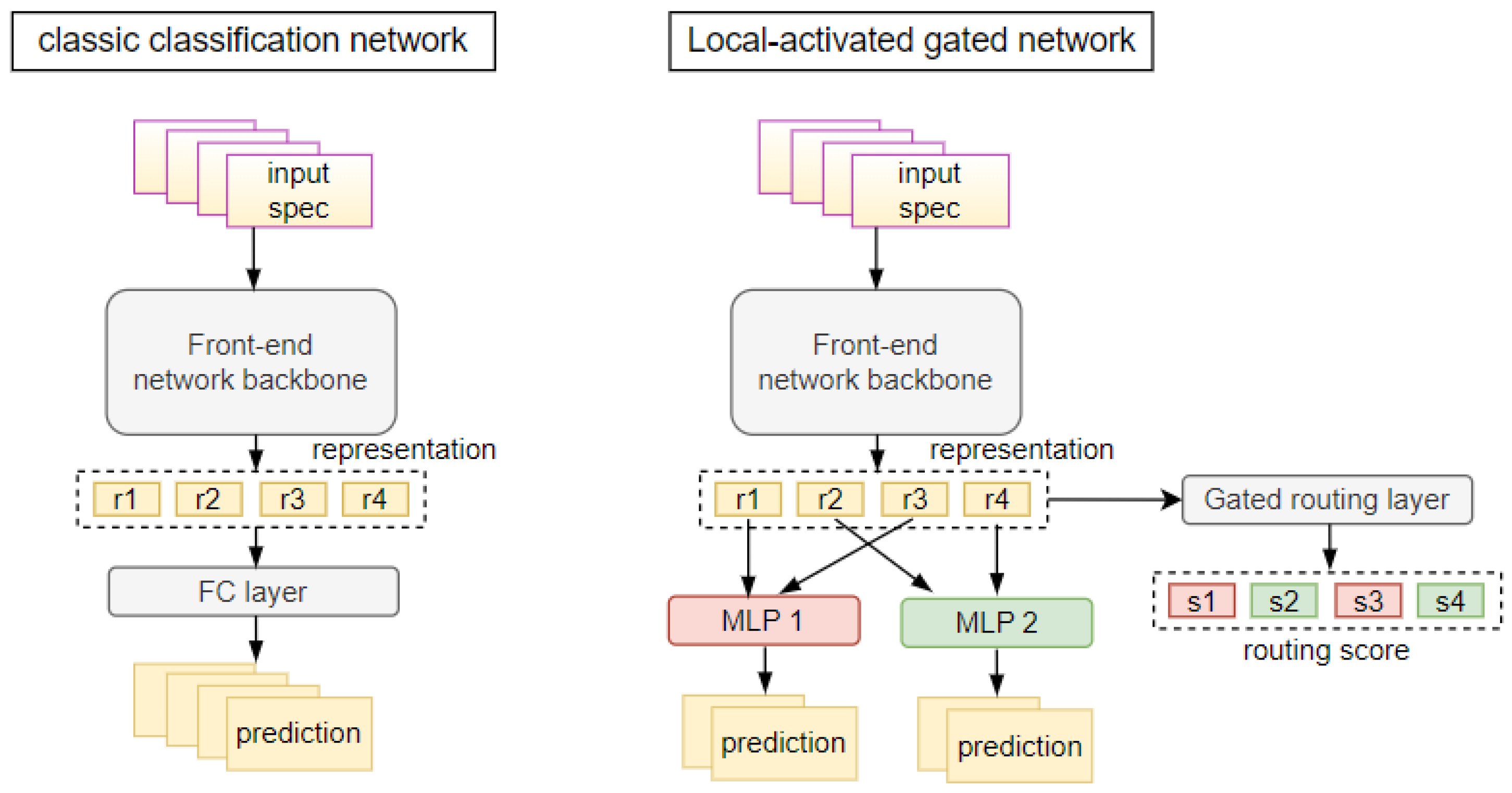
3.3. Framework of Locally Activated Gated Network
Figure 3 illustrates the framework of our proposed LGNet and its comparison with the classic classification network. Our proposed LGNet shares the same front-end network backbone as the classic classification network. Classic classification network directly feeds the representations into the linear fully connected layer and outputs the predictions. Such a method is not good at dealing with data distributions with large intra-class differences.
For our proposed LGNet, we feed the representations into the gated routing network to compute the routing score. Denote the batch size as n, input spectrograms as , and the corresponding label as (i = 1, 2…n). The front-end network takes as input and outputs the representations . We use a linear gated routing layer to learn the latent characteristics contained in the representations, and then output the routing score . Next, the activation function transforms the routing scores into the routing probabilities , whose value represents the probability of being assigned to the corresponding MLP layer. Take a structure composed of two MLPs as an example, when = (0.75, 0.25), the representation will be sent to the first MLP layer. The model computes routing probabilities for all representations and assigns them to the best-matched MLP layer based on . MLP layers finally make predictions on the samples assigned to them.
Additionally, in order to pursue the stability of the model, we fix the parameters of the gated routing network after training for several epochs so that they will no longer be updated. This prevents changes in the parameters of the gated routing network from causing the allocation strategy to remain unfixed. The overall training flow for LGNet is detailed in Algorithm 1.
| Algorithm 1: The overall training flow for LGNet. |
![Applsci 13 05010 i001]() |
4. Experiment Setup
4.1. Dataset
We choose filtered GTZAN [
1] as the dataset for this task, which contains 1000 tracks of 30-second length. There are 10 categories of music genres in GTZAN (blues, classical, country, disco, hip-hop, jazz, metal, pop, reggae, and rock), and each genre contains 100 tracks with a sampling rate of 22,050 Hz. In consideration of several annotation errors on the dataset, we adopt the “fault-filtered” split [
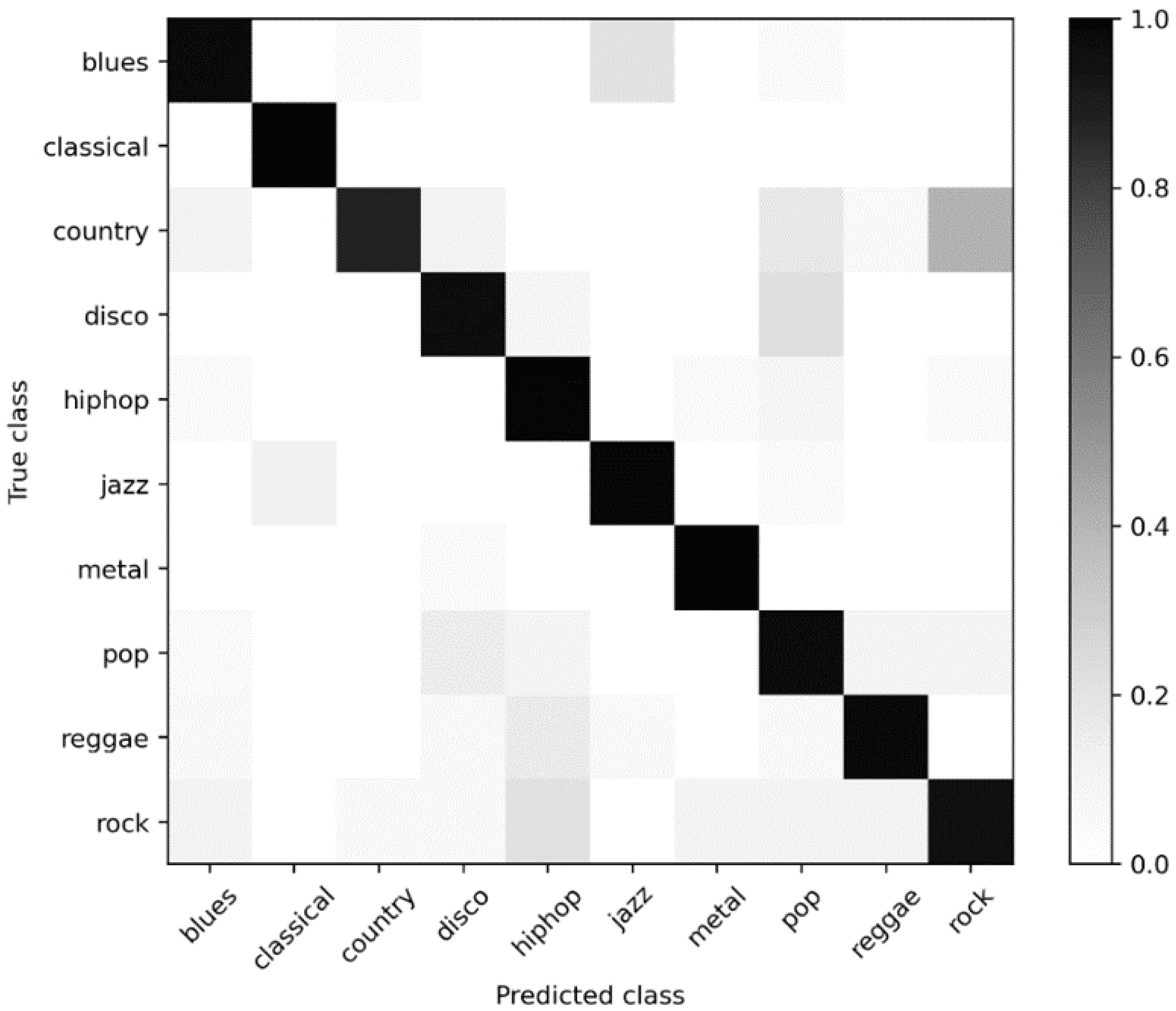
26] to minimize the impact of error labels. For the fault-filtered dataset, the total number of audio clips is reduced to 930 as a result of filtering out mislabeled samples. The training, validation, test set, respectively, include 443, 197, 290 tracks. Given that it possesses more precise labels, we believe the fault-filtered split can better reflect the performance of the recognition model than the original split.
4.2. Baseline Methods
In this work, we perform several widely used pattern recognition techniques as baseline methods, including naive Bayes, Support Vector Machines (SVM), Long Short-Term Memory (LSTM), Bidirectional LSTM (Bi-LSTM), fully convolutional networks (FCN), FCN-LSTM, and residual networks (ResNet).
Naive Bayes is a probabilistic algorithm based on Bayes’ theorem, which assumes that features are conditionally independent given the class label. SVM is a powerful algorithm that constructs a hyperplane to separate different classes in the feature space, often using a kernel trick to implicitly map the data to a high-dimensional space. LSTM is a type of recurrent neural network (RNN) that utilizes a memory cell to selectively forget or remember information over time, allowing it to handle long-term dependencies in sequential data. Bi-LSTM is an extension of LSTM that includes a backward pass through the sequence, enabling the network to capture information from both past and future inputs. FCN is a neural network architecture that consists entirely of convolutional layers. FCN-LSTM is a hybrid model that combines the strengths of FCN and LSTM and has been shown to effectively model spatio-temporal data. Finally, ResNet is a deep neural network architecture that utilizes residual connections to enable the training of very deep networks and has achieved promising performance on a wide range of computer vision tasks and audio pattern recognition tasks.
4.3. Parameters Setup
During framing, this work sets the frame length as 30 ms and the frameshift as 15 ms. In addition, we set the number of Mel filter banks to 128 as default. During training, we use the AdamW optimizer with a weight decay of . The initial learning rate is set to . All models are trained for 300 epochs on a single V 100 GPU. The batch size is set to 64 as default.
6. Conclusions
This paper focuses on automatic music genre classification and reveals that the current methods are not good at dealing with diverse data distributions with large intra-class differences. Based on the issue, we propose an effective and parameter-efficient structure—the locally activated gated neural network. We employ multiple MLPs and employ them as multi-learners, focusing on knowledge in different aspects. In addition, our LGNet can adaptively allocate the most appropriate network layer according to the gated routing layer. According to our experimental results and analysis, we demonstrate that LGNet is very effective for music genre classification. It can achieve a superior performance on the filtered GTZAN dataset.
In the future, we plan to dig deeper into the potential of gating networks based on such local activations. We want to try a more complex routing layer and introduce an attention mechanism to control the weight of different MLP layers. Meanwhile, we are interested in exploring whether there is a more optimal alternative to the structure of the MLP layers.







{kind=link}
{kind=link}
{kind=link}
{kind=link}