

A Novel Dataset for Multi-View Multi-Player Tracking in Soccer Scenarios

 ,
,  ,
, 
Abstract
:1. Introduction
- We designed and installed based multi-view video recording systems in four soccer fields for continuous data collection.
- We designed a novel MVMOT annotation strategy based on the systems.
- We constructed the largest densely annotated multi-view multi-player tracking dataset and provided a total of min of multi-view videos to encourage research in automatic tracking of players in soccer scenarios.
- We evaluated four state-of-the-art tracking models to understand the challenges and characteristics of our dataset.

2. Related Works
2.1. Datasets
2.2. Methods
2.2.1. Object Detection
2.2.2. Feature Extraction
2.2.3. Data Association
3. The System and The Datasets
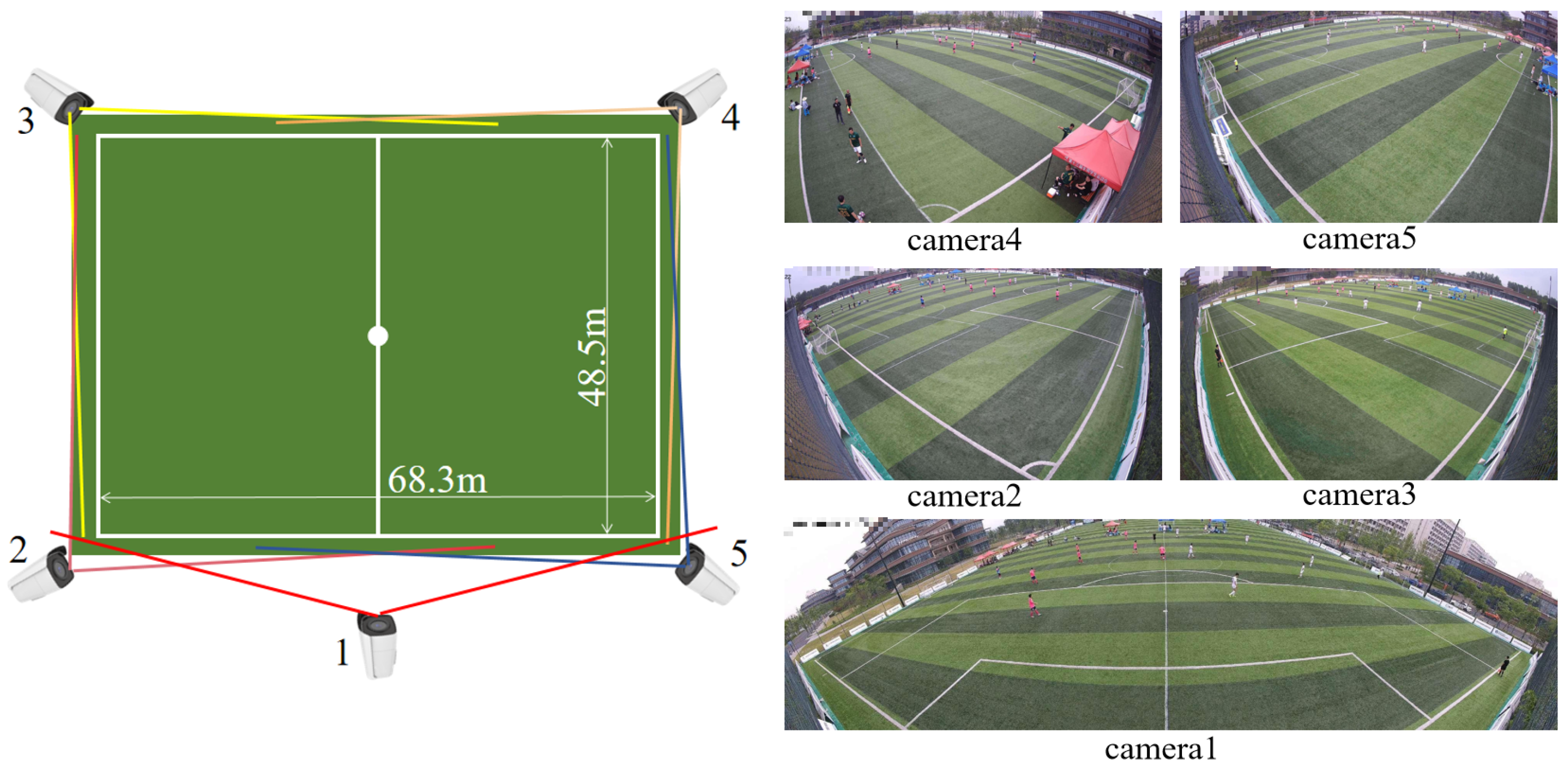
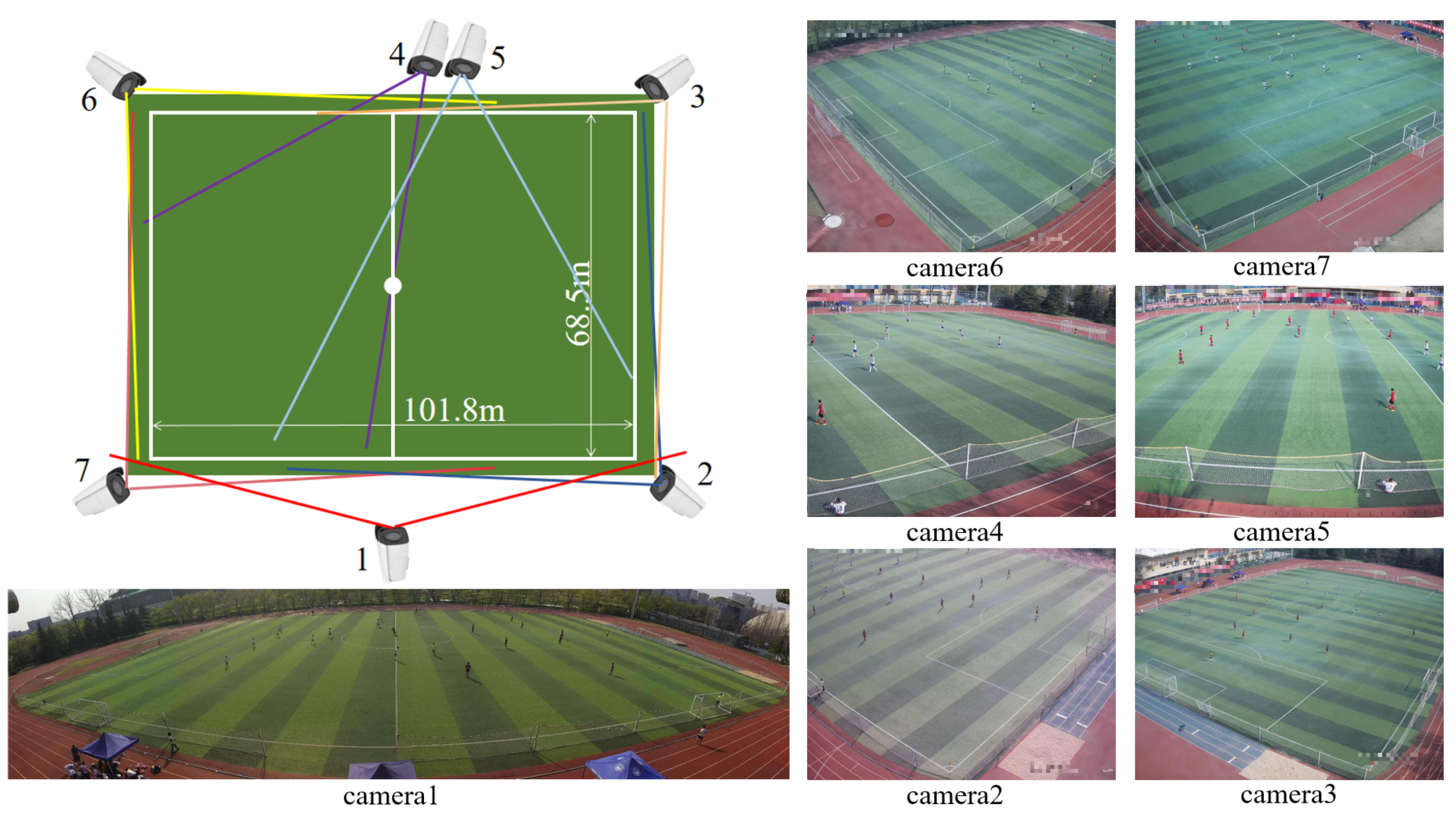
3.1. Hardware and Data Acquisition
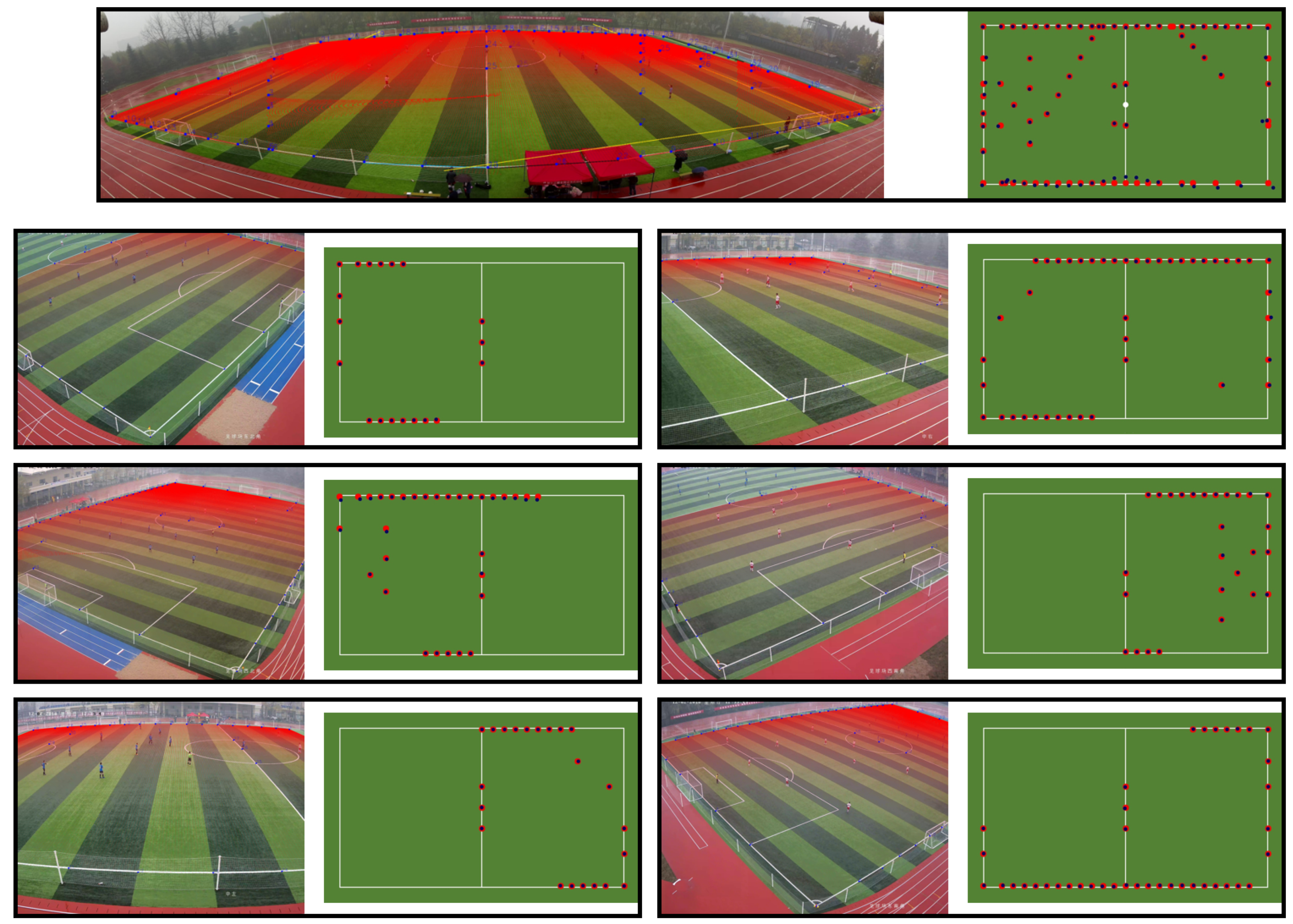
3.2. Calibration of the Cameras
3.3. Annotations Process
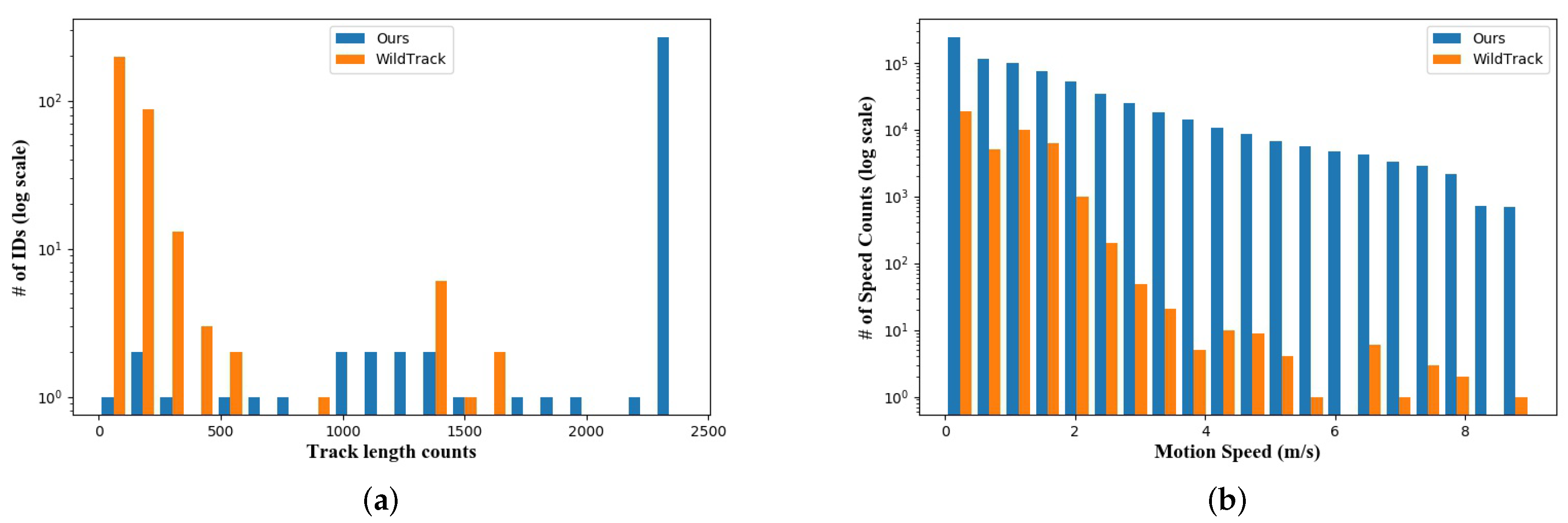
3.4. Statistics
4. Benchmark
4.1. Evaluation Protocol
4.2. Evaluated Methods
5. Results Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Niu, Z.; Gao, X.; Tian, Q. Tactic analysis based on real-world ball trajectory in soccer video. Pattern Recognit. 2012, 45, 1937–1947. [Google Scholar] [CrossRef]
- D’Orazio, T.; Leo, M. A review of vision-based systems for soccer video analysis. Pattern Recognit. 2010, 43, 2911–2926. [Google Scholar] [CrossRef]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See more, know more: Unsupervised video object segmentation with co-attention siamese networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3623–3632. [Google Scholar]
- Wang, W.; Shen, J.; Porikli, F.; Yang, R. Semi-supervised video object segmentation with super-trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 985–998. [Google Scholar] [CrossRef] [PubMed]
- Bornn, L.; Dan, C.; Fernandez, J. Soccer analytics unravelling the complexity of “the beautiful game”. Significance 2018, 15, 26–29. [Google Scholar] [CrossRef]
- Fernandez, J.; Bornn, L. Wide open spaces: A statistical technique for measuring space creation in professional soccer. In Proceedings of the Sloan Sports Analytics Conference, Boston, MA, USA, 23–24 February 2018; Volume 2018. [Google Scholar]
- Narizuka, T.; Yamazaki, Y.; Takizawa, K. Space evaluation in football games via field weighting based on tracking data. Sci. Rep. 2021, 11, 1–8. [Google Scholar] [CrossRef]
- Dave, A.; Khurana, T.; Tokmakov, P.; Schmid, C.; Ramanan, D. Tao: A large-scale benchmark for tracking any object. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 436–454. [Google Scholar]
- Huang, W.; He, S.; Sun, Y.; Evans, J.; Song, X.; Geng, T.; Sun, G.; Fu, X. Open dataset recorded by single cameras for multi-player tracking in soccer scenarios. Appl. Sci. 2022, 12, 7473. [Google Scholar] [CrossRef]
- Pappalardo, L.; Cintia, P.; Rossi, A.; Massucco, E.; Ferragina, P.; Pedreschi, D.; Giannotti, F. A public data set of spatio-temporal match events in soccer competitions. Sci. Data 2019, 6, 1–15. [Google Scholar] [CrossRef]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A.; Leibe, B. Mots: Multi-object tracking and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7942–7951. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Sun, P.; Cao, J.; Jiang, Y.; Zhang, R.; Xie, E.; Yuan, Z.; Wang, C.; Luo, P. Transtrack: Multiple object tracking with transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Xu, Y.; Ban, Y.; Delorme, G.; Gan, C.; Rus, D.; Alameda-Pineda, X. Transcenter: Transformers with dense queries for multiple-object tracking. arXiv 2021, arXiv:2103.15145. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 474–490. [Google Scholar]
- Yang, Y.; Zhang, R.; Wu, W.; Peng, Y.; Xu, M. Multi-camera sports players 3d localization with identification reasoning. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 4497–4504. [Google Scholar]
- Bae, S.-H.; Yoon, K.-J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Fang, K.; Xiang, Y.; Li, X.; Savarese, S. Recurrent autoregressive networks for online multi-object tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, CA, USA, 12–15 March 2018; pp. 466–475. [Google Scholar]
- Fleuret, F.; Berclaz, J.; Lengagne, R.; Fua, P. Multicamera people tracking with a probabilistic occupancy map. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 267–282. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Li, G.; Yan, Z.; Li, Y.; Lu, M.; Xu, P.; Gu, Y.; Bai, B.; Zhang, Y.; Chuxing, D. Spatio-temporal consistency and hierarchical matching for multi-target multi-camera vehicle tracking. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 222–230. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple people tracking by lifted multicut and person re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3539–3548. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Yoon, K.; Song, Y.; Jeon, M. Multiple hypothesis tracking algorithm for multi-target multi-camera tracking with disjoint views. Iet Image Process. 2018, 12, 1175–1184. [Google Scholar] [CrossRef]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. Poi: Multiple object tracking with high performance detection and appearance feature. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–42. [Google Scholar]
- Zhou, Z.; Xing, J.; Zhang, M.; Hu, W. Online multi-target tracking with tensor-based high-order graph matching. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1809–1814. [Google Scholar]
- Bredereck, M.; Jiang, X.; Körner, M.; Denzler, J. Data association for multi-object-tracking-by-detection in multi-camera networks. In Proceedings of the 2012 Sixth International Conference on Distributed Smart Cameras (ICDSC), Hong Kong, China, 30 October–2 November 2012; pp. 1–6. [Google Scholar]
- Hou, Y.; Zheng, L.; Gould, S. Multiview Detection with Feature Perspective Transformation; Computer Vision—ECCV, 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–18. [Google Scholar]
- Hsu, H.-M.; Huang, T.-W.; Wang, G.; Cai, J.; Lei, Z.; Hwang, J.-N. Multi-camera tracking of vehicles based on deep features re-id and trajectory-based camera link models. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 416–424. [Google Scholar]
- Ong, J.; Vo, B.; Vo, B.-N.; Kim, D.Y.; Nordholm, S. A bayesian filter for multi-view 3d multi-object tracking with occlusion handling. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2246–2263. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Liu, X.; Liu, Y.; Zhu, S.-C. Multi-view people tracking via hierarchical trajectory composition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4256–4265. [Google Scholar]
- Alameda-Pineda, X.; Staiano, J.; Subramanian, R.; Batrinca, L.; Ricci, E.; Lepri, B.; Lanz, O.; Sebe, N. Salsa: A novel dataset for multimodal group behavior analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1707–1720. [Google Scholar] [CrossRef]
- Chavdarova, T.; Baqué, P.; Bouquet, S.; Maksai, A.; Jose, C.; Bagautdinov, T.; Lettry, L.; Fua, P.; Gool, L.V.; Fleuret, F. Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5030–5039. [Google Scholar]
- Chavdarova, T.; Fleuret, F. Deep multi-camera people detection. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 848–853. [Google Scholar]
- Ferryman, J.; Shahrokni, A. Pets2009: Dataset and challenge. In Proceedings of the 2009 Twelfth IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Snowbird, UT, USA, 7–9 December 2009; pp. 1–6. [Google Scholar]
- De Vleeschouwer, C.; Chen, F.; Delannay, D.; Parisot, C.; Chaudy, C.; Martrou, E.; Cavallaro, A. Distributed video acquisition and annotation for sport-event summarization. Nem Summit 2008, 8, 1010–1016. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar]
- Krumm, J.; Harris, S.; Meyers, B.; Brumitt, B.; Hale, M.; Shafer, S. Multi-camera multi-person tracking for easyliving. In Proceedings of the Third IEEE International Workshop on Visual Surveillance, Dublin, Ireland, 1 July 2000; pp. 3–10. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X. Joint deep learning for pedestrian detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 536–551. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware r-cnn: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Chen, L.; Ai, H.; Shang, C.; Zhuang, Z.; Bai, B. Online multi-object tracking with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 645–649. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Li, Y.; Yao, H.; Duan, L.; Yao, H.; Xu, C. Adaptive feature fusion via graph neural network for person re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2115–2123. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep affinity network for multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 104–119. [Google Scholar] [CrossRef]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1077–1085. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese cnn for robust target association. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 33–40. [Google Scholar]
- Iqbal, U.; Milan, A.; Gall, J. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2011–2020. [Google Scholar]
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3029–3037. [Google Scholar]
- Wan, X.; Wang, J.; Kong, Z.; Zhao, Q.; Deng, S. Multi-object tracking using online metric learning with long short-term memory. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 788–792. [Google Scholar]
- Kuhn, H.W. The hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Hou, Y.; Zheng, L.; Wang, Z.; Wang, S. Locality aware appearance metric for multi-target multi-camera tracking. arXiv 2019, arXiv:1911.12037. [Google Scholar]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6036–6046. [Google Scholar]
- Tesfaye, Y.T.; Zemene, E.; Prati, A.; Pelillo, M.; Shah, M. Multi-target tracking in multiple non-overlapping cameras using constrained dominant sets. arXiv 2017, arXiv:1706.06196. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, J.; Zhang, X.; Zhang, C. a Multi-target, multi-camera tracking by hierarchical clustering: Recent progress on dukemtmc project. arXiv 2017, arXiv:1712.09531. [Google Scholar]
- Yoo, H.; Kim, K.; Byeon, M.; Jeon, Y.; Choi, J.Y. Online scheme for multiple camera multiple target tracking based on multiple hypothesis tracking. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 454–469. [Google Scholar] [CrossRef]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef]
- Jiang, N.; Bai, S.; Xu, Y.; Xing, C.; Zhou, Z.; Wu, W. Online inter-camera trajectory association exploiting person re-identification and camera topology. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1457–1465. [Google Scholar]
- He, Y.; Han, J.; Yu, W.; Hong, X.; Wei, X.; Gong, Y. City-scale multi-camera vehicle tracking by semantic attribute parsing and cross-camera tracklet matching. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 14–19 June 2020; pp. 576–577. [Google Scholar]
- He, Y.; Wei, X.; Hong, X.; Shi, W.; Gong, Y. Multi-target multi-camera tracking by tracklet-to-target assignment. IEEE Trans. Image Process. 2020, 29, 5191–5205. [Google Scholar] [CrossRef]
- Hofmann, M.; Wolf, D.; Rigoll, G. Hypergraphs for joint multi-view reconstruction and multi-object tracking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3650–3657. [Google Scholar]
- Jiang, X.; Rodner, E.; Denzler, J. Multi-person tracking-by-detection based on calibrated multi-camera systems. In Proceedings of the International Conference on Computer Vision and Graphics, Moscow, Russia, 1–5 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 743–751. [Google Scholar]
- Zamir, A.R.; Dehghan, A.; Shah, M. Gmcp-tracker: Global multi-object tracking using generalized minimum clique graphs. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 343–356. [Google Scholar]
- Chen, W.; Cao, L.; Chen, X.; Huang, K. An equalized global graph model-based approach for multicamera object tracking. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2367–2381. [Google Scholar] [CrossRef]
- Gan, Y.; Han, R.; Yin, L.; Feng, W.; Wang, S. Self-supervised multi-view multi-human association and tracking. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 282–290. [Google Scholar]
- Han, R.; Wang, Y.; Yan, H.; Feng, W.; Wang, S. Multi-view multi-human association with deep assignment network. IEEE Trans. Image Process. 2022, 31, 1830–1840. [Google Scholar] [CrossRef]
- You, Q.; Jiang, H. Real-time 3d deep multi-camera tracking. arXiv 2020, arXiv:2003.11753. [Google Scholar]
- Engilberge, M.; Liu, W.; Fua, P. Multi-view tracking using weakly supervised human motion prediction. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 1582–1592. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Estimating people flows to better count them in crowded scenes. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 723–740. [Google Scholar]
- Tanaka, Y.; Iwata, T.; Kurashima, T.; Toda, H.; Ueda, N. Estimating latent people flow without tracking individuals. In Proceedings of the 32nd International Joint Conference on Artificial Intelligence, Macao, China, 19–25 August 2023; pp. 3556–3563. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Zach, C. Robust bundle adjustment revisited. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 772–787. [Google Scholar]
- Dark Programmer. Dark Programmer. Darklabel. Available online: https://github.com/darkpgmr/DarkLabel (accessed on 11 February 2023).
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. Hota: A higher order metric for evaluating multi-object tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. Mot16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Cameras | FPS | IDs | Annotations | Size/Duration | Scenarios | Field Size |
|---|---|---|---|---|---|---|---|---|
| KITTI [12] | 1392 × 480 | 4 | 10 | 10 | 7 min | campus roads | ||
| Laboratory [21] | 320 × 240 | 4 | 25 | 6 | 264 (1 fps) | 4.4 min | laboratory | 5.5 × 5.5 m |
| Terrace [21] | 320 × 240 | 4 | 25 | 9 | 1023 (1 fps) | 3.5 min | terrace | 10 × 10 m |
| Passageway [21] | 320 × 240 | 4 | 25 | 13 | 226 (1 fps) | 20 min | square | 10 × 6 m |
| Campus [32] | 1920 × 1080 | 4 | 30 | 25 | 240 (1 fps) | 16 min | gargen | |
| CMC * [31] | 1920 × 1080 | 4 | 4 | 15 | 11,719 (4 fps) | 1494 frames | laboratory | 7.67 × 3.41 m |
| SALSA [33] | 1024 × 768 | 4 | 15 | 18 | 1200 (0.3 fps) | 60 min | lobby | |
| EPFL-RLC [35] | 1920 × 1080 | 3 | 60 | - | 6132 | 8000 frames | lobby | |
| PETS-2009 [36] | 768 × 576 720 × 576 | 7 | 7 | 19 | 4650 (7 fps) | 795 frames | campus roads | |
| WildTrack [34] | 1920 × 1080 | 7 | 60 | 313 | 66,626 (2 fps) | 60 min | square | 36 × 12 m |
| APIDIS [37] | 1600 × 1200 | 7 | 22 | 12 | 86,870 (25 fps) | 1 min | Basketball Court | 28 × 15 m |
| LH0 * [17] | 1920 × 1080 | 8 | 25 | 26 | 26,000 (2 fps) | 1.3 min | soccer field | 38 × 7 m |
| Ours | 3840 × 2160 4736 × 1400 5950 × 1152 | 6 5 5 7 | 20 | 316 | 727,179 (20 fps) +137,846 (1 fps) | 1100 min | soccer field | 40 × 20 m 40 × 20 m 68.3 × 48.5 m 101.8 × 68.5 m |
| Game Type | Game ID | Cameras | Players | Length/Fps | Resolution (Main) | Resolution (Auxiliary) | Field Size | Split Type |
|---|---|---|---|---|---|---|---|---|
| 5-A-Side Figure A1 | 1 | 6 | 16 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 40 × 20 m | train |
| 2 | 6 | 12 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 40 × 20 m | train | |
| 3 | 6 | 13 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 40 × 20 m | train | |
| 4 | 6 | 15 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 40 × 20 m | test | |
| 7-A-Side Figure A2 | 5 | 5 | 15 | 120s/20 | 3840 × 2160 | 3840 × 2160 | 44 × 35 m | train |
| 6 | 5 | 16 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 44 × 35 m | train | |
| 7 | 5 | 16 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 44 × 35 m | train | |
| 8 | 5 | 17 | 120 s/20 | 3840 × 2160 | 3840 × 2160 | 44 × 35 m | test | |
| 8-A-Side Figure A3 | 9 | 5 | 19 | 120 s/20 | 5120 × 1400 | 3840 × 2160 | 68.3 × 48.5 m | train |
| 10 | 5 | 20 | 120 s/20 | 5120 × 1400 | 3840 × 2160 | 68.3 × 48.5 m | train | |
| 11 | 5 | 12 | 120 s/20 | 5120 × 1400 | 3840 × 2160 | 68.3 × 48.5 m | train | |
| 12 | 5 | 12 | 120 s/20 | 5120 × 1400 | 3840 × 2160 | 68.3 × 48.5 m | train | |
| 13 | 5 | 12 | 120 s/20 | 5120 × 1400 | 3840 × 2160 | 68.3 × 48.5 m | test | |
| 11-A-Side Figure A4 | 14 | 7 | 25 | 120 s/20 | 5950 × 1450 | 4000 × 3000 | 101.8 × 68.5 m | train |
| 15 | 7 | 25 | 120 s/20 | 5950 × 1450 | 4000 × 3000 | 101.8 × 68.5 m | train | |
| 16 | 7 | 25 | 120 s/20 | 5950 × 1450 | 4000 × 3000 | 101.8 × 68.5 m | train | |
| 17 | 7 | 25 | 120 s/20 | 5950 × 1450 | 4000 × 3000 | 101.8 × 68.5 m | test |
| GameType | Algorithms | HOTA ↑ | DetA ↑ | MOTA ↑ | IDF1 ↑ | IDSW ↓ |
|---|---|---|---|---|---|---|
| 5-A-Side | TRACTA | 57.42 | 72.77 | 90.12 | 70.30 | 155 |
| MvMHAT | 58.87 | 71.65 | 91.27 | 71.97 | 143 | |
| DAN4Ass | 60.75 | 73.38 | 92.68 | 74.28 | 137 | |
| MVFlow | 62.52 | 75.95 | 93.08 | 74.11 | 124 | |
| 7-A-Side | TRACTA | 70.33 | 80.89 | 94.27 | 80.41 | 79 |
| MvMHAT | 75.91 | 82.55 | 95.02 | 82.50 | 70 | |
| DAN4Ass | 77.52 | 82.29 | 95.26 | 83.97 | 51 | |
| MVFlow | 76.82 | 81.89 | 94.83 | 82.89 | 46 | |
| 8-A-Side | TRACTA | 67.33 | 80.26 | 90.99 | 77.71 | 101 |
| MvMHAT | 68.80 | 80.98 | 91.57 | 80.75 | 89 | |
| DAN4Ass | 70.22 | 85.75 | 93.50 | 81.87 | 80 | |
| MVFlow | 72.57 | 87.31 | 94.89 | 83.75 | 76 | |
| 11-A-Side | TRACTA | 60.75 | 79.59 | 81.89 | 62.33 | 111 |
| MvMHAT | 60.62 | 80.11 | 80.25 | 64.35 | 107 | |
| DAN4Ass | 63.27 | 82.86 | 79.75 | 63.71 | 102 | |
| MVFlow | 64.89 | 83.77 | 85.73 | 69.92 | 93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Huang, W.; Sun, Y.; Zhu, X.; Evans, J.; Song, X.; Geng, T.; He, S. A Novel Dataset for Multi-View Multi-Player Tracking in Soccer Scenarios. Appl. Sci. 2023, 13, 5361. https://doi.org/10.3390/app13095361
Fu X, Huang W, Sun Y, Zhu X, Evans J, Song X, Geng T, He S. A Novel Dataset for Multi-View Multi-Player Tracking in Soccer Scenarios. Applied Sciences. 2023; 13(9):5361. https://doi.org/10.3390/app13095361
Chicago/Turabian StyleFu, Xubo, Wenbin Huang, Yaoran Sun, Xinhua Zhu, Julian Evans, Xian Song, Tongyu Geng, and Sailing He. 2023. "A Novel Dataset for Multi-View Multi-Player Tracking in Soccer Scenarios" Applied Sciences 13, no. 9: 5361. https://doi.org/10.3390/app13095361
APA StyleFu, X., Huang, W., Sun, Y., Zhu, X., Evans, J., Song, X., Geng, T., & He, S. (2023). A Novel Dataset for Multi-View Multi-Player Tracking in Soccer Scenarios. Applied Sciences, 13(9), 5361. https://doi.org/10.3390/app13095361