1. Introduction
Object detection is a crucial task within the domain of deep learning computer vision, which aims to recognize a particular object within an image or video, pinpointing both its location and category [
1].
Notably, significant progress has been achieved in object detection through convolutional neural networks (CNNs), especially in visible light conditions where the algorithm performs exceptionally well. Nevertheless, under conditions of low visibility and extreme weather, object detection is inevitably affected by various factors, which interfere with the identification and localization of the target object, suffering from problems such as missed detection and false alarms in practical applications. This leads to a sharp decline in performance. To tackle this puzzle, infrared detection technology has emerged, finding widespread use in diverse domains like cellular tumor diagnosis [
2], privacy preservation [
3], marine rescue [
4,
5], UAV navigation [
6,
7], and autonomous driving [
8,
9]. As a result, detecting infrared objects in real time with precision within low-contrast conditions has become a challenge to solve.
Traditional infrared target detection algorithms exhibit instability under such extreme conditions, making infrared detection complicated and elusive. Researchers have made efforts to overcome these difficulties, and some advanced research results have been achieved in the field of infrared target detection based on deep learning [
10]. Luo et al. [
11] proposed guided attention to color thermal infrared images in a richer semantic encoding way to enable the perception of the environment at night. However, this novel colorization strategy has insufficient generalization ability for different scenes and lighting conditions. Colorization may distort the colors in the image, creating confusion and thus reducing accuracy. Chen et al. [
12] attempted to use optical images to compensate for the missing information in infrared images by proposing an integrated detector to fuse the features of thermal and multiple RGB modalities. This competitive approach, however, introduces noise and inconsistency among the data from different modalities, which diminishes the quality of the integrated information. Chen et al. [
13] achieved the fusion of encoding and decoding features of input features by using the features generated by a deconvolution scaling decoder, but, in fact, the use of deconvolution layers leads to the loss of spatial information. Zhao et al. [
14] introduced a contrast enhancement coefficient as the weighted part of the loss function, aiming to boost the accuracy of small infrared targets. Yet, such adjustment creates a more complicated loss function, which relies too much on prior assumptions and is effective in some specific scenarios but cannot adapt to all intricate scenarios. Although the above methods have achieved leading results in some environments, distinguishing between target and background in realistic, involved, and diverse scenes where color and texture information are lacking in infrared images is still a difficult task, and the performance o the developed methods is often unsatisfactory in practical applications. For this reason, in the face of complex scenes of infrared target detection, it is urgent to establish a powerful and robust model to advance the ability of feature expression and create new breakthroughs for infrared exploration in intricate environments.
In general, object detection can be achieved through two primary detection strategies. The first strategy follows a two-stage approach, with faster R-CNN [
15] serving as an example. This approach comprises two key phases: initially, potential object regions are generated by the algorithm, and then the generated candidate regions are classified and adjusted more finely by the CNN. While this strategy offers heightened accuracy, it tends to be time-consuming and not suitable for practical scenarios like unmanned driving. The other is an end-to-end single-stage strategy, including YOLO series [
16,
17,
18], SSD [
19], RetinaNet [
20], etc., which tries to solve the problem of object boundary box localization using regression methods and completes object detection and localization simultaneously without the need for additional region proposal steps. It significantly surpasses the two-stage model in speed and can provide real-time detection, making it particularly well suited for scenarios with stringent real-time requirements, like running on edge devices [
21]. Hence, more and more scholars focused on single-stage detection algorithms and developing more robust and efficient network models to design detectors. This trend indicates that the demand for accuracy, reliability, and efficiency is constantly increasing, which also means that object detection algorithms need to be continuously optimized to meet these new requirements.
The one-stage object detection model generally comprises three key components: a fundamental backbone, a feature-enhanced fusion network in the neck, and a parallel head. These three components collaboratively capture elements from the feature map, ensuring precise object detection [
22]. The backbone captures the encoding of features in the input image at different levels. The enhanced feature fusion network acts as a bridge between the backbone network and the head to further refine features. Through upsampling and downsampling operations, the features of diverse dimensions are obtained, and features of diverse scales are fused and compressed to optimize the overall performance of object detection. The prediction network performs object classification and regression of bounding box positions to generate object detection results employing enhanced features. This means that the quality of the feature extraction plays a pivotal role in determining the outcome of the ultimate prediction. Wen et al. [
23] used lightweight PConv to replace the original convolutional layer to reduce parameters and introduced coordinate attention in the backbone to enhance the ability to position the target. Du et al. [
24] introduced BIFPN to improve the fusion network so that it could capture and utilize multiscale features more effectively, thus enhancing the performance of the object detector. Wei et al. [
25] proposed the use of a radius-aware loss function to consider the radius between the prediction result and the target to better evaluate the accuracy of the prediction. Regarding architecture, the head can be categorized into two main methods: anchor-based and anchor-free detection approaches [
26]. Among them, the former has stable training, accurate target position regression, and is advantageous when dealing with dense target distribution. In contrast, the anchor-free detection method has higher detection speed, lower computational complexity, but may behave unstably when the target is occluded. Since there is no predefined anchor box, the algorithm may have difficulty in handling cases of occluded targets, resulting in decreased detection accuracy. It is worth mentioning that the current one-stage model YOLOv5, which achieves a flawless blend of accuracy and pace, uses an anchor-based detection method.
To ensure the stability and adaptability of an infrared detection model in complex scenes, this study selected the lightweight YOLOv5 framework as the benchmark model for infrared detection. This study identified three areas where the model needs improvement: (1) Due to the complexity of the real environment and the very weak characteristics of infrared targets, there are still problems such as weak anti-interference ability in the face of multi-scale targets. For example, in the verification of some occluded targets, the model cannot accurately identify them, resulting in reduced accuracy. (2) The fusion feature map is not weighted by the prediction network, which leads to the neglect of important information; yet, in real-life scenes, there is often intricate and abundant contextual information around the object to be detected. (3) Enhancements are required for feature extraction in the model’s backbone. Fine-grained features, including basic contour and texture, are crucial for object detection. However, the current model has shortcomings in low-level feature extraction, resulting in the omission of part of the crucial information about the target. This inadequacy prevents the accurate expression of features for the target to be detected, consequently reducing the detection precision. To tackle these issues, through a series of experiments, it was proven that the improved model significantly optimizes the average precision while maintaining the original running speed. Notably, improving these points proves advantageous in achieving more accurate detection, especially in the case of small infrared targets that are easily occluded in complex scenes. The following are the contributions of this paper:
We propose a novel interval sampling weighting module in the neck-strengthening feature fusion network; the ISW module converts the feature information from the plane dimension to the channel dimension through interval sampling, which helps to retain more comprehensive positional information. Furthermore, a multidimensional collaborative attention mechanism is introduced to screen and strengthen the features before dimensionality reduction, so that the network focuses on the regions related to the target in the image, thereby expanding the perception range, improving the accuracy, and reducing unnecessary information.
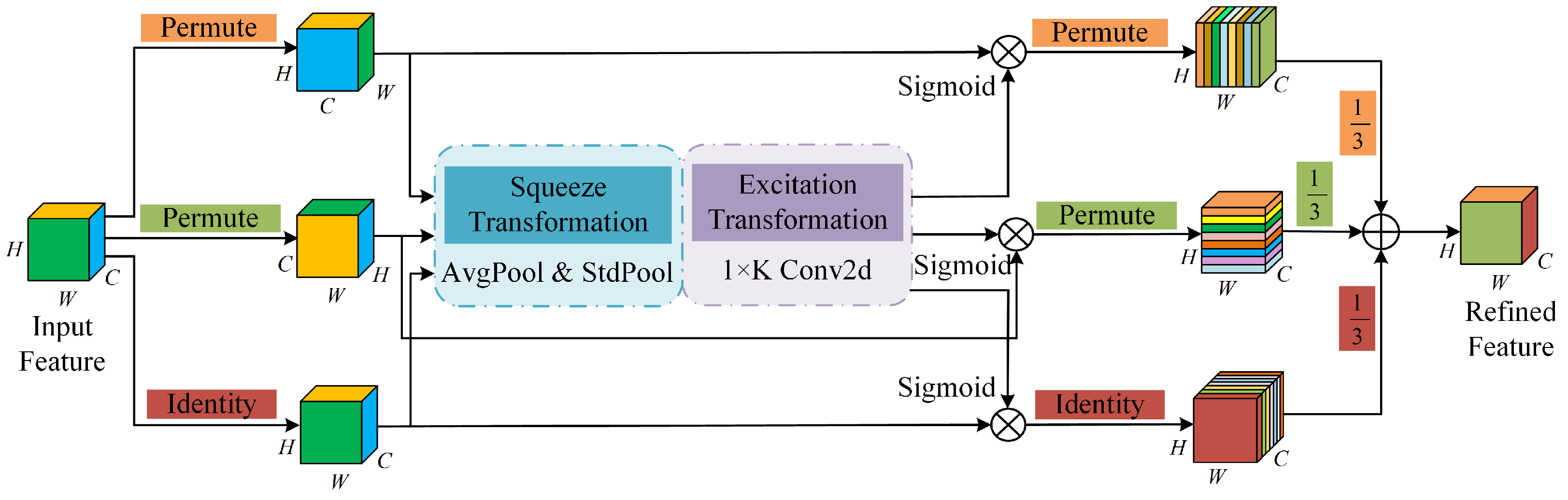
A 3D-attention-based detection head is proposed. TAHNet boosts model target sensitivity, so that the model may correctly locate and recognize the target. Especially in the face of complex scenes or occlusion, it is helpful for weakening the interference of background noise and optimizing the precision in model detection.
The C2f is employed as the core feature extraction module of the model. By paralleling more gradient flow branches, the model can obtain more plentiful and hierarchical feature representations, which can accelerate the speed of feature extraction and effectively handle objects of diverse scales and shapes, thereby improving the model’s resilience.
4. Experiment and Analysis
4.1. Dataset and Experimental Environment
In this study, we chose the FLIR and KAIST datasets for the exploitation of thermal infrared target detecting and the evaluation of algorithm performance.
FLIR dataset: The FLIR dataset mainly contains thermal infrared images, which are images captured by thermal infrared cameras to capture the heat distribution of objects in the scene, making it able to provide unique information at night and in low-light conditions. The acquisition of infrared data was completed on streets and highways in California during both day and night, covering a range of scenes, involving but not confined to outdoor environments, day and night changes, buildings, and traffic scenes. We selected 10,228 frames of infrared images with annotated resolution in the dataset, which included the categories person, bicycle, and car. To increase the diversity of the dataset and balance the sample distribution, we repartitioned the training dataset and the testing dataset, where the quantity of samples was 8862 and 1366, respectively. In addition, negative samples were introduced in the training phase to help the network study the background information of the object more accurately, increase the model’s generalization capacity, and make the detecting model better-adapted to a variety of different scenarios in the testing phase.
KAIST dataset [
36]: The KAIST dataset contains 95,328 aligned thermal infrared and visible images, each with a resolution of
. With the intent of improving the training efficiency and reducing the risk of overfitting, the original dataset was cleaned to remove redundant or unnecessary samples. When training a model, a cleaner dataset can speed up the convergence process and reduce the overfitting of the model to noisy and abnormal conditions. The cleaned version of the dataset contained 9858 thermal infrared images with a 9:1 training and test set partition ratio, and we labeled the category “pedestrian”. We experimentally verified that cleaning data increased the overall quality of the data, ensured that the dataset met the requirements of the task, and helped with more accurately evaluating model performance.
Table 1 shows the configuration of the specific hardware devices used for model training and the evaluation framework of the software platform that provided environmental support.
Hyperparameter initialization holds a key position in object detecting tasks, and setting the appropriate intensity can make the model learn more efficiently. The hyperparameter configuration in this study is shown in
Table 2. The input sample size of the network was set to
; the learning rate and momentum were 0.01 and 0.9; the selection of regularization technology weight attenuation and batch size was 0.005 and 16, respectively; and the training cycle length of the model was 100 epochs.
4.2. Performance Evaluation Metrics
Intending to analyze a model’s results for different categories and the overall performance, precision (P) is utilized to evaluate the veracity of the model predicting positive samples, recall (R) is employed to evaluate a model’s power to identify all positive samples, whereas the F1 score thinks about the overall performance of precision and recall. The average precision (AP) characterizes the area under the PR curve, representing the average of the model’s predicting precision over different classes, and the mean average precision (mAP) is the average of the average accuracy over all classes. These metrics enable a thorough evaluation of an object-detecting system’s performance in predicting both positive and negative classes and provide an overall insight into the effect of the model. Specifically, the expressions for precision and recall are:
where TP (true positive) stands for the quantity of true positive examples, FP (false positive) reflects the quantity of negative examples that are misjudged as positive examples, and FN (false negative) presents the quantity of positive examples that are misjudged as negative examples.
The F1 score is a comprehensive evaluation index, which is the harmonic mean between [recision and recall, and is suitable for the comparison of different model performances. Its equation is expressed as follows:
In object detection tasks, the average accuracy is evaluated by quantifying the area beneath the precision–recall (PR) curve. For each category, the values of the precision and recall under that category are calculated, and then the average accuracy is calculated based on the PR curve. The average accuracy mean provides a comprehensive performance assessment of the model over the entire dataset, taking into account multiple categories of prediction accuracy. The AP and mAP expressions are shown in Equations (18) and (19).
4.3. Analysis of Ablation Experiment
Ablation contrast experiments are scientific research methods designed to help researchers understand the effects of different components of a target detection model on its overall performance. This means that by modifying certain components, settings, or the model’s parameters, the contribution of these factors to the model’s performance can be fully deduced from the findings of the experiment. In this section, the detection performance effects of ISW, TAHNet, and C2f modules when used alone and in different combinations are discussed in detail. This experiment was verified on the public FLIR dataset, and a series of comparative tests were conducted based on the framework of the YOLOv5n model.
As illustrated in
Table 3, when the three proposed modules act on the network at the same time, the model performance is the best. However, the interaction between modules is not all shared facilitation; for example, the recall of ISW+TAH modules combined in a stack is 0.7% lower than that of TAH modules alone. The reason for this phenomenon is that when two modules are used at the same time, if there is a lack of complementarity, involving overlapping information or trying to deal with conflicting information, information disharmony occurs, resulting in performance degradation. The optimal incremental order of different module combinations is given and the growth curve of its mAP is intuitively displayed in
Figure 7.
Benchmark module + TAH: First, select the detection header of the optimized network to increase the positioning ability of the model. When the improved TAH policy is applied to the network alone, the weight value is obtained via function mapping, and the new parameter number and complexity are not introduced. Compared to the benchmark model, the precision, recall, F1, and mAP of the improved detection head increase by 0.7%, 2.0%, 1.0%, and 1.1%, respectively, reducing the problem of missing detection targets.
Benchmark module + TAH + C2f: Secondly, to strengthen the feature extraction capability of the backbone, the C2f strategy is proposed to introduce more abundant gradient information. On the basis of TAH, C2f is added to network training to further improve the model’s detection effect. The test outcomes showed that the recall increased by 3.3%, mAP increased by 1.9%, and the generalization capacity of the network increased.
Benchmark module + TAH + C2f + ISW: In the end, to develop the feature fusion power of the network for multiscale targets, the ISW module was developed to capture spatial semantic information more comprehensively. The recall, precision, F1, and mAP of the overall model increased by 4.4%, 1.3%, 3.0%, and 3.1%, respectively, indicating that the detecting performance of the network on easily blocked infrared objects was effectively improved. Therefore, the experiment verified that these three modules have good complementarity and can make up for the defects of different modules to improve the overall performance and achieve optimal performance.
4.4. Comparison of Diverse Models on FLIR Dataset
To further verify the efficacy of the proposed method, several different single-stage target detection algorithms were selected by utilizing the uniform equipment and infrared dataset and setting the uniform experimental arguments. The performance of the infrared target detection algorithm in a complex environment was compared using various detection and evaluation indices.
Figure 8 includes the visual effect presentation of the original label, YOLOv5, YOLOv7-tiny, and the method proposed in this study. Obviously, our proposed model has excellent performance in detecting easily occluded infrared objects in intricate conditions, which improves the model’s resistance to noise and interference. For example, on account of the low contrast of infrared images in a real environment, the distinction between the target and the backdrop becomes blurred, increasing the difficulty of detection. During the detection using YOLOv5 and YOLOv7-tiny, there was a situation of missing detection, and no distant infrared small target was identified. However, the green circle marked in
Figure 8 indicates that the network proposed in this paper could comprehensively identify all objects and avoid missing detection, indicating that the improved model has certain universality and adaptability, not limited to specific types of targets, provides a reliable solution for application in actual scenes, and can better maintain detection performance even in the case of intricate conditions or occlusion.
The data in
Table 4 clearly reveal that compared with the most advanced target-detecting models at present, the method in this study provides leading improvements in several indicators, with mAP, precision, and F1 scores reaching 84%, 86.8%, and 81%, respectively. Specifically, the proposed algorithm achieves mAP and F1 that are 16.1% and 13% higher than those of the SSD algorithm, while the model size is only one-fortieth, demonstrating improved detection results. In addition, our method mAP outperforms the latest lightweight YOLOv7-tiny algorithm by 5.2% in terms of precision. The above analysis illustrates that the method in this study has a strong feature expression ability, which is more in line with real needs and is more stable and reliable for practical use.
Figure 9 concisely and intuitively illustrates the overall trend in the model across diverse metrics to better understand the holistic performance characteristics of the model.
Within the realm of infrared detection, on account of the open source and data diversity of the FLIR dataset, many scholars have explored of infrared object detection with a basis in this public resource in recent years. Therefore, aiming at the three categories of AP and mAP indicators, this study selected the most popular and excellent infrared image detection methods to carry out a succession of comparative analyses. In addition to the YOLO series, the comparison method also included MMTOD-CG, TermalDet, CMPD, and other multimode detectors based upon the complementary information fusion of visible and infrared images.
Table 5 lists the experimental results of all the above models.
The superiority of the presented strategy is clearly observable in
Table 5, where mAP reaches the highest level of 84% of all comparison models. Specifically, the latest multispectral pedestrian detection CMPD method achieves more reliable multimodal feature fusion by attaching a confidence subnetwork; BU(AT, T) adopts a domain adaptation strategy to retain more visible domain feature information; and these methods achieve good results. However, the average -recision in the Person category is 15.5% and 9% lower than ours, respectively. Among the other methods, the highest mAP value was achieved by the most advanced multistage detector Cascade R-CNN and anchor-free detection algorithm YOLOX; and our method achieved values 3.5% and 2.8% higher than theirs. The contrasting results of the data mentioned above prove the validity and rationality of the module presented in this study. In addition,
Figure 10 displays the F1 score curve and the PR curve for each category of our model.
4.5. Comparison of Various Models on KAIST Dataset
For the sake of evaluating the universality and reliability of the algorithm, the model’s performance was further verified on the cleaned KAIST pedestrian dataset in this study. The results, as displayed in
Table 6, in comparison with the most progressive YOLO series models, the algorithm’s performance presented in this study is better, achieving ideal results in various evaluation indicators. This demonstrates that our model boasts a powerful capacity to generalize and can be flexible given the detecting requirements of various environments. Specifically, our precision, recall, F1 score, and mAP are as high as 96.6%, 92.2%, 94%, and 97.5%, outperforming the baseline model by 2.4%, 2.5%, 2%, and 2.7%, respectively. In general, our mAP is 2.7 to 17.9% higher than that of other methods, and the running time is reduced by 50 to 84%, confirming that our model is highly adaptable to different datasets and reduces the risk of performing well on a single dataset while having sufficient generalization ability.
Figure 11 provides a more intuitive and clear data comparison trend to fully assess the overall effectiveness of the method as well as visually demonstrate the excellent performance of our approach on various performance indicators.
From the visual detection effect diagram in
Figure 12, it is observable that our model’s detecting efficacy in complex scenes perfectly coincides with the detection target box of the original mark. Even with interference in the vicinity or unsatisfactory conditions, the method maintains highly accurate detection, indicating that the proposed model has excellent target information feature transmission ability and generalization ability and can correctly identify and locate infrared targets in practical applications with excellent performance.
5. Conclusions
To create an innovative solution to the challenges of background noise interference and target occlusion loss information in thermal infrared images, this study proposed an infrared object detecting algorithm with a basis in deep learning with efficient feature extraction in complex scenes. With superior accuracy and robustness compared to other mainstream models in this field, this algorithm effectively overcomes some of the obstacles posed by thermal infrared images. To achieve these results, our proposed method utilizes an ISW module to expand the perception field of the fusion network for input data, which is beneficial for dealing with different sizes and occluded targets in infrared images. Additionally, TAHNet enables the detection head to better handle various shapes and poses, further enhancing the model’s robustness. Finally, the C2f module optimizes the feature extraction process, comprehensively capturing different features in the image and more accurately identifying the infrared target.
Infrared target detection remains a dynamic research area with vast potential for exploration. The algorithm presented in this study has strong feature expression capacity; in the future, our primary research emphasis will be on developing a lightweight network framework, aiming to attain a harmonious balance between exceptional precision and swift computation. Simultaneously, we intend to validate the detection performance across a broader spectrum of infrared target datasets. With advancing technology and the development of more practical applications, we expect to see increasingly advanced systems that accurately detect infrared targets in real time.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}