
Federated Learning-Based Service Caching in Multi-Access Edge Computing System


Abstract
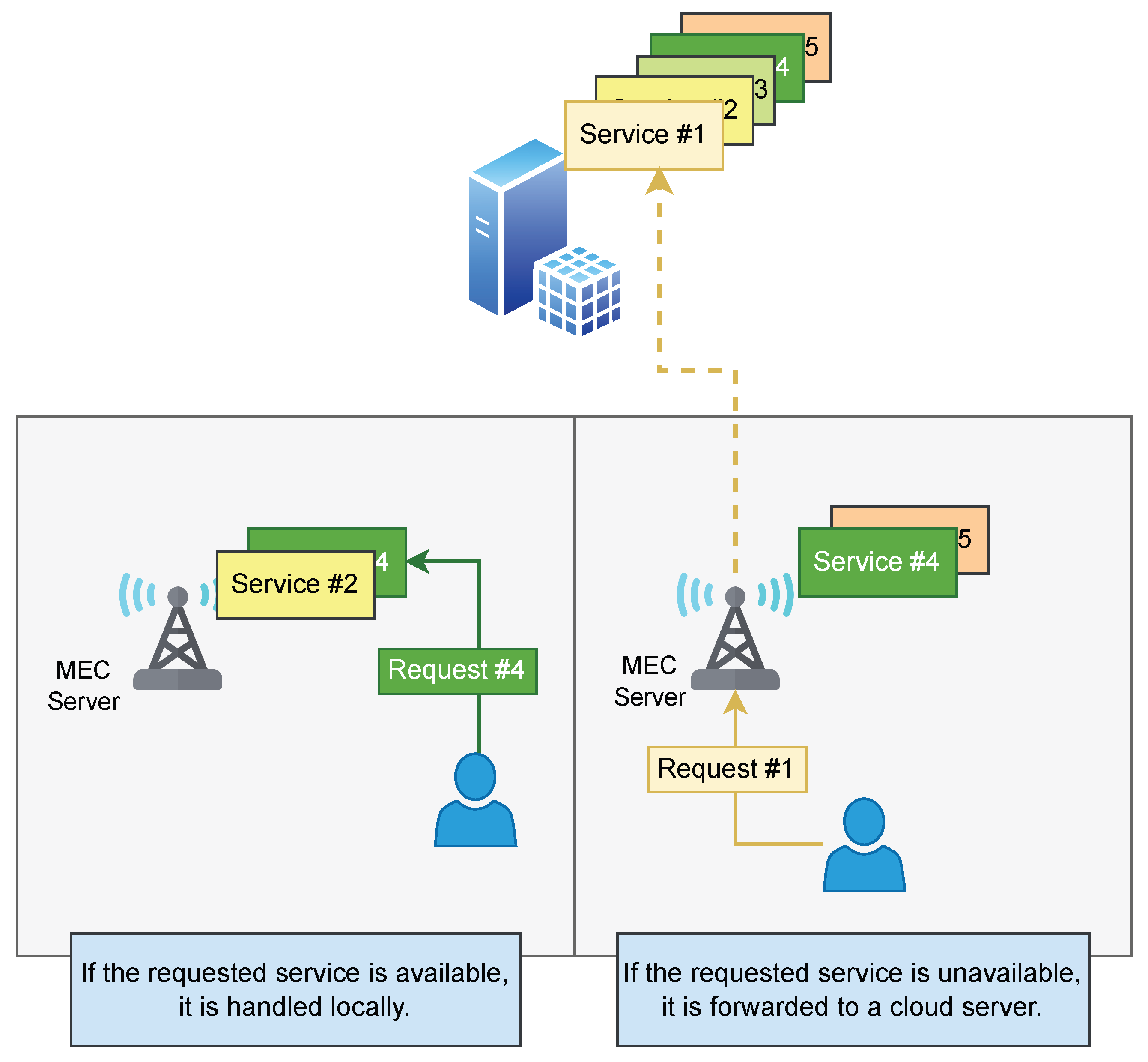
:1. Introduction
- We propose a FL framework system enabling MEC servers to determine, independently, service caching. Specifically, each MEC server utilizes its user data locally rather than sharing it with others. In addition, using FL enables each MEC server to acquire data characteristics corresponding to the entire system.
- We adopt the AAE for the distributed service caching problem. In particular, AAE efficiently extracts complicated distributions of distributed user data within the FL framework. The proposed method efficiently addresses the challenge of the dynamic nature of MEC systems by using both local and global knowledge.
- We conduct extensive experiments to determine the effectiveness of the model. Experiments that use both simulated and real-world mobility data are examined across multiple scenarios. The service hit ratio and service delay are used as key metrics to evaluate the performance of the service caching framework. The experimental results show that the proposed model increases the service hit ratio from to 5 times, while service latency is reduced by 15– compared to its counterparts.
2. Related Work
2.1. Centralized Service Caching
2.2. Distributed Service Caching
3. System Model
3.1. System Architecture
3.2. Problem Formulation
4. Proposed Service Caching Framework
4.1. Overview
- The individual MEC servers accept user requests and consolidate them into local data. It should be noted that the local data are not shared with any other server.
- The popularity score of each service is determined by each MEC server using its local data and knowledge acquired from FL.
- Each MEC server calculates the caching score for each service based on its popularity score and the availability of resources. The caching scores are ranked to identify the most ideal services.
- The decision-making process of each MEC server determines the replacement of service caches. Redundant services are eliminated, while underemployed services are replicated from the cloud server.
4.2. FL-Based Service Popularity Score
4.2.1. Distributed Training Phase
4.2.2. Distributed Inference Phase
4.3. Service Caching Policies
| Algorithm 1 Adaptive Service Cache Replacement |
|
5. Experiment and Evaluation
5.1. Experimental Setup
5.2. Metric
5.3. Counterpart
- Random Caching (RC) [31]: This approach employs a random selection process for determining the service types deployed on the MEC server.
- Least Recently Used (LRU) [22]: The prioritization in service deployment on MEC servers is based on the recency of their requests.
- Least Frequently Used (LFU) [22]: This approach leverages historical statistical data from past time slots to replace the services that have received the lowest requests.
- Federated Learning with AE (FLAE): This method employs the traditional autoencoder model to extract data features that are then used to select the appropriate service.
5.4. Performance Evaluation
5.4.1. Comparison of Service Hit Ratio
5.4.2. Comparison of Service Delay
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| The set of MEC servers | |
| The set of mobile users | |
| The number of all services | |
| S | Number of deployed services in MEC server |
| User time slot and Operation time slot | |
| Require computing resource for service i | |
| Computing resource capacity of MEC server m | |
| Latent representation | |
| Encoder network | |
| Decoder network | |
| Discriminative network | |
| Prior distribution | |
| Latent space distribution | |
| The weight of global model | |
| The weight of local model at MEC server m | |
| The number of service request at MEC server m | |
| Local processed data at MEC server m | |
| Inference data at MEC server m | |
| The popularity scores at MEC server m | |
| The service scores at MEC server m |
References
- Bisio, I.; Delfino, A.; Lavagetto, F.; Sciarrone, A. Enabling IoT for in-home rehabilitation: Accelerometer signals classification methods for activity and movement recognition. IEEE Internet Things J. 2016, 4, 135–146. [Google Scholar] [CrossRef]
- Sun, W.; Liu, J.; Zhang, H. When smart wearables meet intelligent vehicles: Challenges and future directions. IEEE Wirel. Commun. 2017, 24, 58–65. [Google Scholar] [CrossRef]
- Araniti, G.; Bisio, I.; De Sanctis, M.; Orsino, A.; Cosmas, J. Multimedia content delivery for emerging 5G-satellite networks. IEEE Trans. Broadcast. 2016, 62, 10–23. [Google Scholar] [CrossRef]
- Sabella, D.; Sukhomlinov, V.; Trang, L.; Kekki, S.; Paglierani, P.; Rossbach, R.; Li, X.; Fang, Y.; Druta, D.; Giust, F.; et al. Developing software for multi-access edge computing. ETSI White Pap. 2019, 20, 1–38. [Google Scholar]
- Wei, H.; Luo, H.; Sun, Y.; Obaidat, M.S. Cache-Aware Computation Offloading in IoT Systems. IEEE Syst. J. 2020, 14, 61–72. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Ni, Q.; El-Ghazawi, T. Online Service Migration in Mobile Edge with Incomplete System Information: A Deep Recurrent Actor-Critic Learning Approach. IEEE Trans. Mob. Comput. 2022, 22, 6663–6675. [Google Scholar] [CrossRef]
- Tabatabaee Malazi, H.; Chaudhry, S.R.; Kazmi, A.; Palade, A.; Cabrera, C.; White, G.; Clarke, S. Dynamic Service Placement in Multi-Access Edge Computing: A Systematic Literature Review. IEEE Access 2022, 10, 32639–32688. [Google Scholar] [CrossRef]
- He, S.; Lyu, X.; Ni, W.; Tian, H.; Liu, R.P.; Hossain, E. Virtual Service Placement for Edge Computing under Finite Memory and Bandwidth. IEEE Trans. Commun. 2020, 68, 7702–7718. [Google Scholar] [CrossRef]
- Wang, L.; Jiao, L.; He, T.; Li, J.; Bal, H. Service Placement for Collaborative Edge Applications. IEEE/ACM Trans. Netw. 2021, 29, 34–47. [Google Scholar] [CrossRef]
- Poularakis, K.; Llorca, J.; Tulino, A.M.; Taylor, I.; Tassiulas, L. Service Placement and Request Routing in MEC Networks with Storage, Computation, and Communication Constraints. IEEE/ACM Trans. Netw. 2020, 28, 1047–1060. [Google Scholar] [CrossRef]
- Zhao, T.; Hou, I.H.; Wang, S.; Chan, K. Red/LeD: An Asymptotically Optimal and Scalable Online Algorithm for Service Caching at the Edge. IEEE J. Sel. Areas Commun. 2018, 36, 1857–1870. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Wang, S.; Hu, X.; Guo, S.; Qiu, T.; Hu, B.; Kwok, R.Y. Distributed and dynamic service placement in pervasive edge computing networks. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1277–1292. [Google Scholar] [CrossRef]
- Kalakanti, A.K.; Rao, S. Computational Challenges and Approaches for Electric Vehicles. ACM Comput. Surv. 2023, 55, 311. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Luo, Y. A Federated Learning-Based Edge Caching Approach for Mobile Edge Computing-Enabled Intelligent Connected Vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3360–3369. [Google Scholar] [CrossRef]
- Jie, X.; Liu, T.; Gao, H.; Cao, C.; Wang, P.; Tong, W. A DQN-Based Approach for Online Service Placement in Mobile Edge Computing. In Proceedings of the Collaborative Computing: Networking, Applications and Worksharing, Shanghai, China, 16–18 October 2020; Gao, H., Wang, X., Iqbal, M., Yin, Y., Yin, J., Gu, N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 169–183. [Google Scholar]
- Li, L.; Zhang, H. Delay Optimization Strategy for Service Cache and Task Offloading in Three-Tier Architecture Mobile Edge Computing System. IEEE Access 2020, 8, 170211–170224. [Google Scholar] [CrossRef]
- Wu, M.; Yu, F.R.; Liu, P.X. Intelligence Networking for Autonomous Driving in Beyond 5G Networks with Multi-Access Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 5853–5866. [Google Scholar] [CrossRef]
- Fan, W.; Li, S.; Liu, J.; Su, Y.; Wu, F.; Liu, Y. Joint Task Offloading and Resource Allocation for Accuracy-Aware Machine-Learning-Based IIoT Applications. IEEE Internet Things J. 2023, 10, 3305–3321. [Google Scholar] [CrossRef]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Yan, J.; Bi, S.; Duan, L.; Zhang, Y.J.A. Pricing-Driven Service Caching and Task Offloading in Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2021, 20, 4495–4512. [Google Scholar] [CrossRef]
- Maia, A.M.; Ghamri-Doudane, Y.; Vieira, D.; de Castro, M.F. A Multi-Objective Service Placement and Load Distribution in Edge Computing. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Barrios, C.; Kumar, M. Service Caching and Computation Reuse Strategies at the Edge: A Survey. ACM Comput. Surv. 2023, 56, 43. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Jang, K.; Hong, S.; Kim, M.; Na, J.; Moon, I. Adversarial Autoencoder Based Feature Learning for Fault Detection in Industrial Processes. IEEE Trans. Ind. Inform. 2022, 18, 827–834. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Do, H.M.; Tran, T.P.; Yoo, M. Deep Reinforcement Learning-Based Task Offloading and Resource Allocation for Industrial IoT in MEC Federation System. IEEE Access 2023, 11, 83150–83170. [Google Scholar]
- Somesula, M.K.; Mothku, S.K.; Annadanam, S.C. Cooperative Service Placement and Request Routing in Mobile Edge Networks for Latency-Sensitive Applications. IEEE Syst. J. 2023, 17, 4050–4061. [Google Scholar] [CrossRef]
- Cao, V.L.; Nicolau, M.; McDermott, J. A Hybrid Autoencoder and Density Estimation Model for Anomaly Detection. In Proceedings of the Parallel Problem Solving from Nature—PPSN XIV, Edinburgh, UK, 17–21 September 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 717–726. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Qian, Y.; Hu, L.; Chen, J.; Guan, X.; Hassan, M.M.; Alelaiwi, A. Privacy-aware service placement for mobile edge computing via federated learning. Inf. Sci. 2019, 505, 562–570. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of MEC servers | 64 |
| Number of users | 300 |
| Number of all services | 500 |
| Computational capacity of MEC server | 36 GHz |
| User time slot | 2 min |
| Operation time slot | 60 min |
| Backhaul network bandwidth | 150 Mbps |
| Request data size | Mb |
| Required computational resource of service | GHz |
| Skewness parameter | |
| Input layer of AE | 500 |
| Latent space of AE | 23 |
| Learning rate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, T.P.; Tran, A.H.N.; Nguyen, T.M.; Yoo, M. Federated Learning-Based Service Caching in Multi-Access Edge Computing System. Appl. Sci. 2024, 14, 401. https://doi.org/10.3390/app14010401
Tran TP, Tran AHN, Nguyen TM, Yoo M. Federated Learning-Based Service Caching in Multi-Access Edge Computing System. Applied Sciences. 2024; 14(1):401. https://doi.org/10.3390/app14010401
Chicago/Turabian StyleTran, Tuan Phong, Anh Hung Ngoc Tran, Thuan Minh Nguyen, and Myungsik Yoo. 2024. "Federated Learning-Based Service Caching in Multi-Access Edge Computing System" Applied Sciences 14, no. 1: 401. https://doi.org/10.3390/app14010401
APA StyleTran, T. P., Tran, A. H. N., Nguyen, T. M., & Yoo, M. (2024). Federated Learning-Based Service Caching in Multi-Access Edge Computing System. Applied Sciences, 14(1), 401. https://doi.org/10.3390/app14010401