
An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves



Abstract
:1. Introduction
1.1. Related Work
1.2. Research Gap
- Scalability and Adaptability: It is not well understood how existing architectures perform when dealing with various sizes of curves as well as different levels of security.
- Resource Efficiency versus Speed Trade-off: Balancing computational speed and hardware resource utilization needs further exploration, especially for resource-constrained devices.
- Detailed Performance Metrics: Many studies lack an evaluation of performance metrics including speed, which is crucial when making design choices.
1.3. Contributions
- The first contribution is the effective utilization of BECs for cryptographic computations through the innovative application of the NAF algorithm. It ensures robust security and computational efficiency. The utilization of the NAF technique for point multiplication on BECs successfully fills the research gap concerning scalability and adaptability. The NAF algorithm presents a versatile method that may be applied to different curve sizes and levels of security. Our architecture is adaptable and scalable, as evidenced by achieved results, showing strong performance over a range of curve parameters.
- The second contribution is the optimization of the Arithmetic Logic Unit (ALU) within the hardware design, maximizing ALU efficiency with minimal additional hardware. Moreover, the incorporation of a radix-4 multiplier eliminates resource-intensive divisions and substantially boosts computational speed while reducing hardware complexity. The trade-off between resource efficiency and speed is addressed by the integration of a radix-4 multiplier and the optimization of the Arithmetic Logic Unit (ALU). Our design minimizes the use of hardware resources while carefully balancing processing speed. Rapid cryptographic operations are facilitated by the radix-4 multiplier, which is renowned for its speed benefits, and the optimized ALU, which guarantees efficient operations. Our approach achieves an optimal equilibrium with great progress, especially useful for devices with limited resources.
- Finally, to perform cryptographic operations with precision, our design integrates a Finite State Machine (FSM). This FSM is designed for an optimal control flow, minimizing latency, and managing system resources, thus optimizing overall performance.
1.4. Organization
2. Setting the Stage: Fundamental Mathematics and Knowledge
2.1. Fundamentals of BEC
2.2. Unified Mathematical Formulation
2.3. Computation of the PM Process with the NAF Algorithm
| Algorithm 1: Point Multiplication with NAF |
 |
2.3.1. Initialization
2.3.2. Scalar Conversion to NAF
2.3.3. Primary Loop
- the algorithm performs a “differential addition” operation on points and . This operation, denoted as , modifies these points as required;
- in cases where the current bit within the NAF representation is ‘’1”, an additional “differential addition” operation is executed, involving points and ;
- The algorithm activates an inner loop that handles the windowing approach in order to optimize the procedure. Operation optimization using “double-and-add” operations is part of this method. The inner loop spans previous bits of the NAF representation, covering up to w bits in reverse order. Within this loop,
- –
- points and are updated through the “double-and-add” operation, as represented by , ;
- –
- if the bit corresponding to the current iteration within the inner loop is ‘1’, an additional “differential addition” operation occurs for points and .
2.3.4. End of Loop
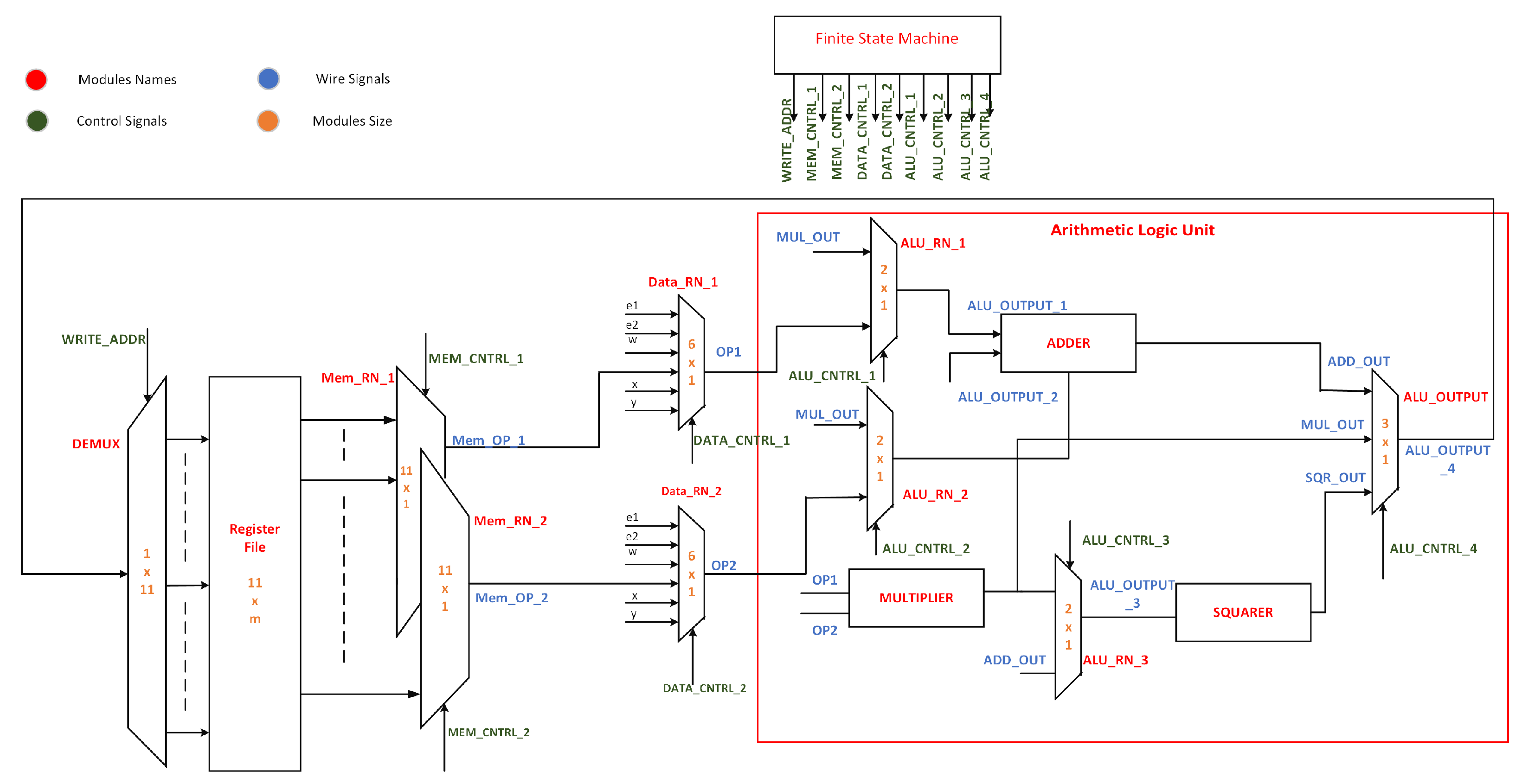
3. Proposed Hardware Architecture
3.1. Memory Unit
3.2. Routing Networks
3.3. Arithmetic Logic Unit
3.3.1. Efficient Data Routing for Enhanced Performance
3.3.2. Radix-4 Multiplier
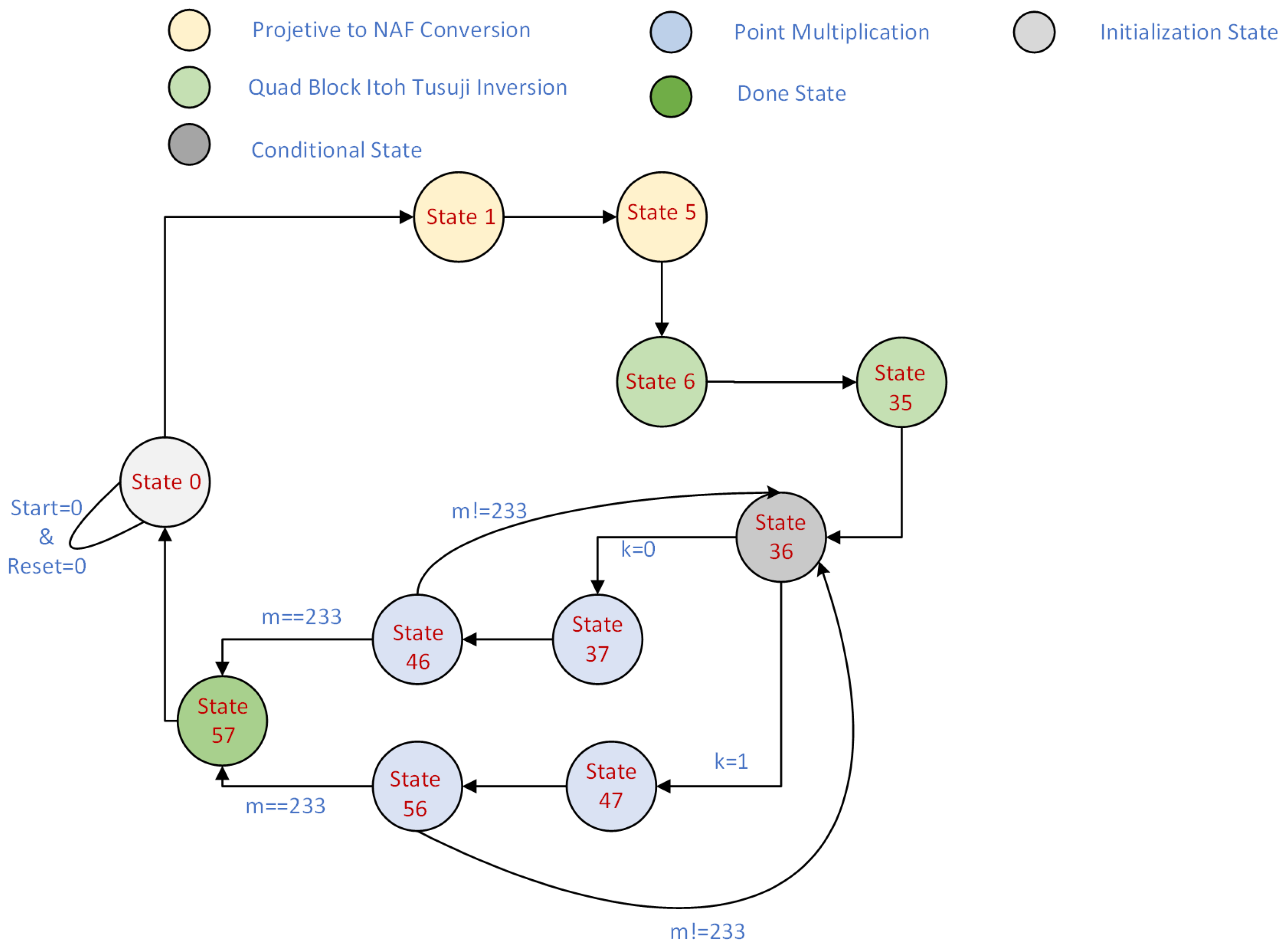
3.4. Control Unit
3.5. Total Computational Requirements
4. Proposed Optimizations
4.1. Optimizing Memory and Instructions for Enhanced Efficiency
4.2. Streamlining Cryptographic Operations for Enhanced Efficiency
5. Achieved Results and Performance Comparison
5.1. Hardware and Software in Experimental Setup
5.2. Performance Metrics and Evaluation
5.3. Performance Comparison
5.3.1. Virtex-4 Platform Comparison
5.3.2. Virtex-5 Platform Comparison
5.3.3. Virtex-6 Platform Comparison
5.3.4. Virtex-7 Platform Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Katz, J.; Lindell, Y. Introduction to Modern Cryptography; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Joseph, D.; Misoczki, R.; Manzano, M.; Tricot, J.; Pinuaga, F.D.; Lacombe, O.; Leichenauer, S.; Hidary, J.; Venables, P.; Hansen, R. Transitioning organizations to post-quantum cryptography. Nature 2022, 605, 237–243. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Li, W.; Zhang, J. Symmetric Cryptography: Recent Advances and Future Directions. IEEE Trans. Inf. Forensics Secur. 2022, 17, 36–53. [Google Scholar]
- Ullah, S.; Zheng, J.; Din, N.; Hussain, M.T.; Ullah, F.; Yousaf, M. Elliptic Curve Cryptography; Applications, challenges, recent advances, and future trends: A comprehensive survey. Comput. Sci. Rev. 2023, 47, 100530. [Google Scholar] [CrossRef]
- Khan, M.A.; Quasim, M.T.; Alghamdi, N.S.; Khan, M.Y. A secure framework for authentication and encryption using improved ECC for IoT-based medical sensor data. IEEE Access 2020, 8, 52018–52027. [Google Scholar] [CrossRef]
- Alkabani, Y.; Samsudin, A.; Alkhzaimi, H. Mitigating Side-Channel Power Analysis on ECC Point Multiplication Using Non-Adjacent Form and Randomized Koblitz Algorithm. IEEE Access 2021, 9, 30590–30604. [Google Scholar]
- Mensah, S.; Appiah, K.; Asare, P.; Asamoah, E. Challenges and Countermeasures for Side-Channel Attacks in Elliptic Curve Cryptography. Secur. Commun. Netw. 2021, 2021, 1–18. [Google Scholar]
- Choi, P. Lightweight ECC Coprocessor with Resistance against Power Analysis Attacks over NIST Prime Fields. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4518–4522. [Google Scholar] [CrossRef]
- Kong, F.; Yu, J.; Cai, Z.; Li, D. Left-to-right generalized nonadjacent form recoding for elliptic curve cryptosystems. In Proceedings of the IEEE International Conference on Hybrid Information Technology (ICHIT2006), Cheju, South Korea, 9–11 November 2006; pp. 299–303. [Google Scholar]
- Rezai, A.; Keshavarzi, P. CCS Representation: A New Non-Adjacent Form and its Application in ECC. J. Basic Appl. Sci. Res. 2012, 2, 4577–4586. [Google Scholar]
- Sajid, A.; Rashid, M.; Jamal, S.; Imran, M.; Alotaibi, S.; Sinky, M. AREEBA: An Area Efficient Binary Huff-Curve Architecture. Electronics 2021, 10, 1490. [Google Scholar] [CrossRef]
- Lopez, J.; Menezes, A.; Oliveira, T.; Rodriguez-Henriquez, F. Hessian Curves and Scalar Multiplication. J. Cryptol. 2019, 32, 955–974. [Google Scholar] [CrossRef]
- Kalaiarasi, M.; Venkatasubramani, V.; Manikandan, M.; Rajaram, S. High performance HITA based Binary Edward Curve Crypto processor for FPGA platforms. J. Parallel Distrib. Comput. 2023, 178, 56–68. [Google Scholar] [CrossRef]
- Chatterjee, A.; Gupta, I.S. FPGA implementation of extended reconfigurable binary Edwards curve based processor. In Proceedings of the 2012 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 211–215. [Google Scholar] [CrossRef]
- Rashidi, B.; Farashahi, R.R.; Sayedi, S.M. High-speed Hardware Implementations of Point Multiplication for Binary Edwards and Generalized Hessian Curves. Cryptol. Eprint Arch. 2017, 2017, 5. Available online: https://eprint.iacr.org/2017/005 (accessed on 14 December 2023).
- Salarifard, R.; Bayat-Sarmadi, S.; Mosanaei-Boorani, H. A Low-Latency and Low-Complexity Point-Multiplication in ECC. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 2869–2877. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.; Kim, J.; Kim, D.K. Low-Complexity Elliptic Curve Cryptography Processor Based on Configurable Partial Modular Reduction Over NIST Prime Fields. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1703–1707. [Google Scholar] [CrossRef]
- Rashidi, B.; Abedini, M. Efficient Lightweight Hardware Structures of Point Multiplication on Binary Edwards Curves for Elliptic Curve Cryptosystems. J. Circuits Syst. Comput. 2019, 28, 1950140. [Google Scholar] [CrossRef]
- Lara-Nino, C.A.; Diaz-Perez, A.; Morales-Sandoval, M. Lightweight elliptic curve cryptography accelerator for internet of things applications. Ad Hoc Netw. 2020, 103, 102159. [Google Scholar] [CrossRef]
- Sajid, A.; Rashid, M.; Imran, M.; Jafri, A. A Low-Complexity Edward-Curve Point Multiplication Architecture. Electronics 2021, 10, 1080. [Google Scholar] [CrossRef]
- Sajid, A.; Sonbul, O.S.; Rashid, M.; Zia, M.Y.I. A Hybrid Approach for Efficient and Secure Point Multiplication on Binary Edwards Curves. Appl. Sci. 2023, 13, 5799. [Google Scholar] [CrossRef]
- Edwards, H. A normal form for elliptic curves. Bull. Am. Math. Soc. 2007, 44, 393–422. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Lange, T.; Rezaeian Farashahi, R. Binary edwards curves. In Cryptographic Hardware and Embedded Systems–CHES 2008: 10th International Workshop, Washington, DC, USA, 10–13 August 2008. Proceedings 10; Springer: Berlin/Heidelberg, Germany, 2008; pp. 244–265. [Google Scholar]
- Oliveira, T.; López, J.; Rodríguez-Henríquez, F. The Montgomery ladder on binary elliptic curves. J. Cryptogr. Eng. 2018, 8, 241–258. [Google Scholar] [CrossRef]
- Agarwal, S.; Oser, P.; Lueders, S. Detecting IoT Devices and How They Put Large Heterogeneous Networks at Security Risk. Sensors 2019, 19, 4107. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, B. Efficient hardware implementations of point multiplication for binary Edwards curves. Int. J. Circuit Theory Appl. 2018, 46, 1516–1533. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instructions | Original Formulas |
|---|---|
| Initial | PA + PD = | Inv | Total Cycles | |
|---|---|---|---|---|
| 233 | 5 | 2784 | 232 | 3021 |
| Clock Cycles | Instri | Addition Law (15 Storage Elements) | Proposed Simplified Formulations ( Storage Elements) |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | = | ||
| 5 | |||
| 6 | |||
| 7 | merged with | ||
| 8 | |||
| 9 | |||
| 10 | - | ||
| 11 | |||
| 12 | |||
| 13 | |||
| 14 | merged with | ||
| 15 |
| References # | Platform | Frequency (in MHz) | Slices | LUTS | Time (in μs) | T/Slices |
|---|---|---|---|---|---|---|
| Virtex-4 Results | ||||||
| GBEC: [20] | Virtex-4 | 127.261 | 17,158 | 2663 | 25.5 | 2.28 |
| BEC [14] | Virtex-4 | 48 | 21,816 | 35,003 | - | - |
| BEC halving [14] | Virtex-4 | 48 | 22,373 | 42,596 | - | |
| GBEC: [19] | Virtex-4 | 255.570 | 29,255 | - | 14.83 | 2.38 |
| GBEC: [19] | Virtex-4 | 257.535 | 12,403 | - | 32.81 | 2.45 |
| GBEC: [21] | Virtex-4 | 195.508 | 3302 | 2723 | 32.1 | 9.43 |
| BEC: [25] | Virtex-4 | 277.681 | 31,702 | - | 13.39 | 2.35 |
| Virtex 5 Results | ||||||
| GBEC: [18] | Virtex-5 | - | 4581 | - | 51.46 | 4.24 |
| BEC: [19] | Virtex-5 | 205.1 | 1397 | 4340 | 4560 | 0.1569 |
| GBEC: [21] | Virtex-5 | 245.669 | 2714 | 2502 | 25.59 | 14.39 |
| GBEC: [26] | Virtex-5 | 337.603 | 9233 | - | 11.22 | 9.67 |
| GBEC: [26] | Virtex-5 | 333.603 | 4019 | - | 25.03 | 9.94 |
| Virtex 6 Results | ||||||
| GBEC: [20] | Virtex-6 | 186.506 | 2664 | 22,256 | 17.39 | 21.5 |
| BEC: [19] | Virtex-6 | 107 | 1245 | 3878 | 6720 | 0.119 |
| GBEC: [21] | Virtex-6 | 290.92 | 1770 | 3597 | 21.61 | 26.14 |
| Virtex 7 Results | ||||||
| GBEC: [20] | Virtex-7 | 179.81 | 2662 | 24,533 | 18.04 | 20.82 |
| GBEC: [21] | Virtex-7 | 320.584 | 1771 | 4470 | 19.61 | 28.79 |
| Our Work | ||||||
| GBEC: | Virtex-4 | 112 | 2502 | 2133 | 26.97 | 14.819 |
| GBEC: | Virtex-5 | 163.119 | 2114 | 2308 | 18.52 | 25.5 |
| GBEC: | Virtex-6 | 198.223 | 1897 | 2797 | 15.24 | 34.58 |
| GBEC: | Virtex-7 | 212.244 | 1895 | 2970 | 14.233 | 37.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajid, A.; Sonbul, O.S.; Rashid, M.; Arif, M.; Jaffar, A.Y. An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves. Appl. Sci. 2024, 14, 54. https://doi.org/10.3390/app14010054
Sajid A, Sonbul OS, Rashid M, Arif M, Jaffar AY. An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves. Applied Sciences. 2024; 14(1):54. https://doi.org/10.3390/app14010054
Chicago/Turabian StyleSajid, Asher, Omar S. Sonbul, Muhammad Rashid, Muhammad Arif, and Amar Y. Jaffar. 2024. "An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves" Applied Sciences 14, no. 1: 54. https://doi.org/10.3390/app14010054
APA StyleSajid, A., Sonbul, O. S., Rashid, M., Arif, M., & Jaffar, A. Y. (2024). An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves. Applied Sciences, 14(1), 54. https://doi.org/10.3390/app14010054