
Mapping of Deep Neural Network Accelerators on Wireless Multistage Interconnection NoCs

Abstract
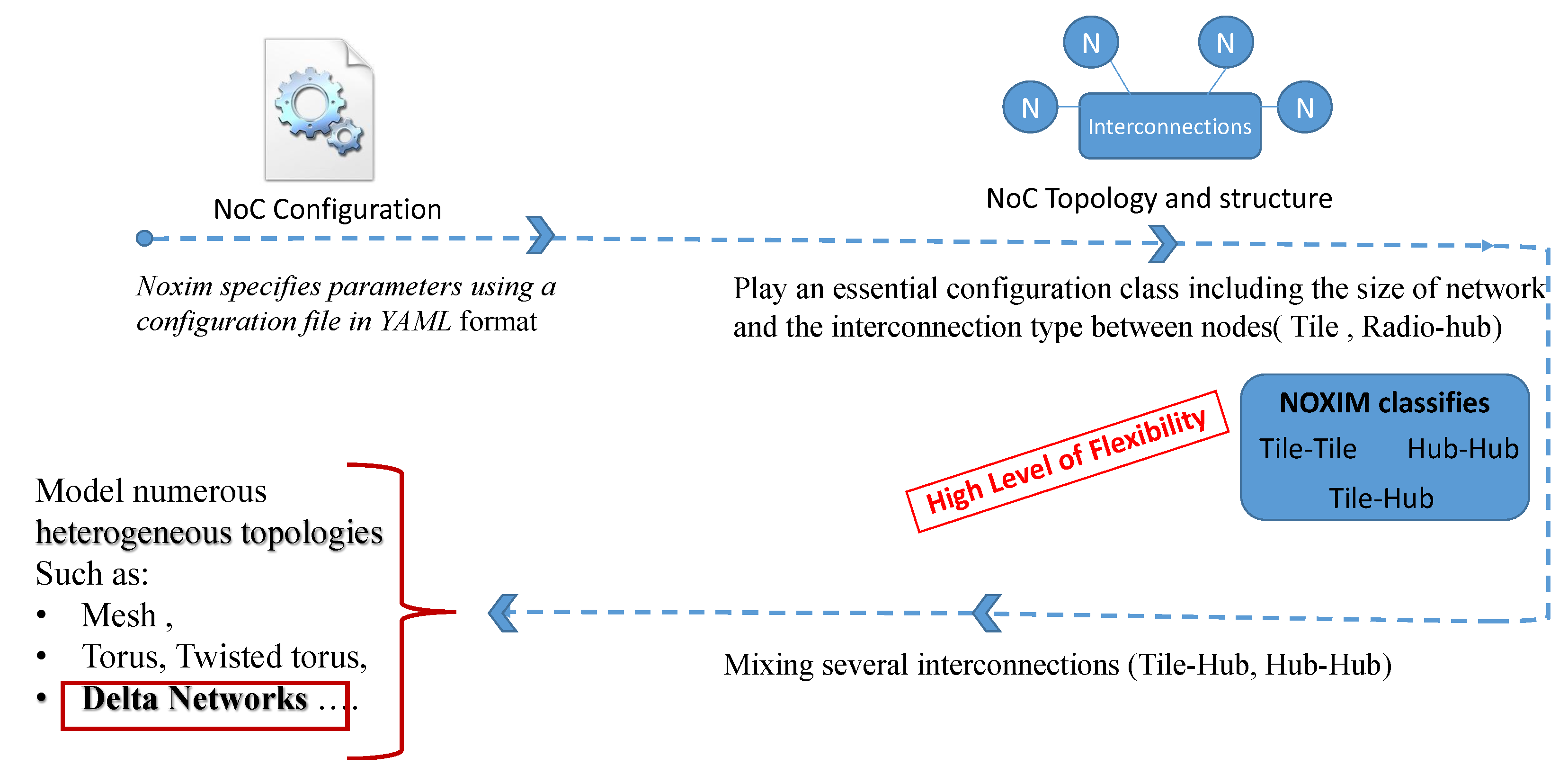
:1. Introduction
2. Taxonomy of Mutistage Interconnection Networks (MINs)
2.1. MIN Graph Cartography
2.2. Banyan Property
2.3. Delta Class MIN
- The perfect shuffle: it is a kind of a bit-shuffling procedure, wherein, the kth bit of an input sequence () is swapped with the .
- The butterfly: permits the kth bit of the input sequence () with the th bit, while preserving the order of the other bits: .
- The baseline: swaps the kth bit of the input sequence ( ) with the th bit, preserving the order of the other bits: .
- The identity: helps maintain the input sequence relevant mapping: .
3. Related Works
4. Design of Hybrid Network-on-Chip Based on Delta MINs
5. Evaluation of DNN Accelerators under Delta-Based MINs
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abeyratn, N.; Das, R.; Li, Q.; Sewell, K.; Giridhar, B.; Dreslinski, R.G.; Blaauw, D.; Mudge, T. Scaling towards kilo-core processors with asymmetric high-radix topologies. In Proceedings of the IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 496–507. [Google Scholar]
- Bohnenstieh, B.; Stillmaker, A.; Pimntel, J.; Andreas, T.; Liu, B.; Tran, A.; Adeagbo, E.; Baas, B. A 5.8 pj/op 115 billion ops/sec, to 1.78 trillion ops/sec 32nm 1000-processor array. In Proceedings of the IEEE Symposium on VLSI Circuits (VLSI-Circuits), Honolulu, HI, USA, 15–17 June 2016; pp. 1–2. [Google Scholar]
- Kel, J.H.; Johnsonn, M.R.; Lumtta, S.S.; Patel, S.J. WayPoint: Scaling coherence to 1000-core architectures. In Proceedings of the 19th International Conference on Parallel Architectures and Compilation Techniques (PACT), Vienna, Austria, 11–15 September 2010; pp. 99–109. [Google Scholar]
- Abada, S.; Mestres, A.; Martinez, R.; Alarcon, E.; Cabellos-Aparicio, A.; Martinez, R. Multicast on-chip traffic analysis targeting manycore NoC design. In Proceedings of the 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–6 March 2015; pp. 370–378. [Google Scholar]
- Abada, S.; Cabellos-Aparicio, A.; Alarcón, E.; Torrellas, J. WiSync: An architecture for fast synchronization through on-chip wireless communication. ACM Sigplan Not. 2016, 51, 3–17. [Google Scholar] [CrossRef]
- Karkar, A.; MakT; Tong, K.F.; Yakovlev, A. A survey of emerging interconnects for on-chip efficient multicast and broadcast in many-cores. IEEE Circuits Syst. Mag. 2016, 16, 58–72. [Google Scholar] [CrossRef]
- Krishna, T.; Peh, L.S.; Beckmnn, B.M.; Reinhardt, S.K. Towards the ideal on-chip fabric for 1-to-many and many-to-1 communication. In Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, Porto Alegre, Brazil, 3–7 December 2011; pp. 71–82. [Google Scholar]
- Mansor, N.; Ganguly, A. Reconfigurable wireless network-on-chip with a dynamic medium access mechanism. In Proceedings of the 9th International Symposium on Networks-on-Chip, Vancouver, BC, Canada, 28–30 September 2015; pp. 1–8. [Google Scholar]
- Siegl, H.J.; Nation, W.G.; Kruskal, C.P.; Napolitano, L.M. Using the multistage cube network topology in parallel supercomputers. Proc. IEEE 1989, 77, 1932–1953. [Google Scholar]
- Blank, T. The maspar mp-1 architecture. In Digest of Papers Compcon Spring’90, Proceedings of the 35th IEEE Computer Society International Conference on Intellectual Leverage, San Francisco, CA, USA, 26 February–2 March 1990; IEEE Computer Society Press: San Francisco, CA, USA, 1990; pp. 20–24. [Google Scholar]
- Cheung, T.; Smith, J.E. A simulation study of the CRAY X-MP memory system. IEEE Trans. Comput. 1986, 35, 613–622. [Google Scholar] [CrossRef]
- Kruskal, C.P.; Snir, M. The performance of multistage interconnection networks for multiprocessors. IEEE Trans. Comput. 1983, 32, 1091–1098. [Google Scholar] [CrossRef]
- Aydi, Y.; Meftali, S.; Dekeyser, J.L.; Abid, M. Design and performance evaluation of a reconfigurable delta MIN for MPSOC. In Proceedings of the Internatonal Conference on Microelectronics, Cairo, Egypt, 29–31 December 2007; pp. 115–118. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, 1409–1556. [Google Scholar]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef]
- Liu, X.; Wen, W.; Qian, X.; Li, H.; Chen, Y. Neu-NoC: A high-efficient interconnection network for accelerated neuromorphic systems. In Proceedings of the 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018; pp. 141–146. [Google Scholar]
- Firuzan, A.; Modarressi, M.; Daneshtalab, M. Reconfigurable communication fabric for efficient implementation of neural networks. In Proceedings of the 10th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC), Bremen, Germany, 29 June–1 July 2015; pp. 1–8. [Google Scholar]
- Choi, W.; Duraisamy, K.; Kim, R.G.; Doppa, J.R.; Pande, P.P.; Marculescu, R.; Marculescu, D. Hybrid network-on-chip architectures for accelerating deep learning kernels on heterogeneous manycore platforms. In Proceedings of the International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Pittsburgh, PA, USA, 1–7 October 2016; pp. 1–10. [Google Scholar]
- Kruskal, C.P.; Snir, M. A unified theory of interconnection network structure. Theor. Comput. Sci. 1986, 48, 75–94. [Google Scholar] [CrossRef]
- Patel, J.H. Performance of processor-memory interconnections for multiprocessors. IEEE Trans. Comput. 1981, 30, 771–780. [Google Scholar] [CrossRef]
- De Micheli, G.; Benini, L. Networks on chips: 15 years later. Computer 2017, 50, 10–11. [Google Scholar]
- Pasricha, S.; Dutt, N. On-Chip Communication Architectures: System on Chip Interconnect; Morgan Kaufmann: Burlington, MA, USA, 2010. [Google Scholar]
- Wentzlaff, D.; Griffin, P.; Hoffmann, H.; Bao, L.; Edwards, B.; Ramey, C.; Mattina, M.; Miao, C.C.; Brown, J.F.; Agarwal, A. On-chip interconnection architecture of the tile processor. IEEE Micro 2007, 27, 15–31. [Google Scholar] [CrossRef]
- Achballah, A.B.; Othman, S.B.; Saoud, S.B. Problems and challenges of emerging technology networks-on-chip: A review. Microprocess. Microsyst. 2017, 53, 1–20. [Google Scholar]
- Aydi, Y.; Baklouti, M.; Abid, M.; Dekeyser, J.L. A multi-level design methodology of multistage interconnection network for mpsocs. Int. J. Comput. Appl. Technol. 2011, 42, 191. [Google Scholar] [CrossRef]
- Baklouti, M.; Aydi, Y.; Marquet, P.; Dekeyser, J.L.; Abid, M. Scalable mpNoC for massively parallel systems–Design and implementation on FPGA. J. Syst. Archit. 2010, 56, 278–292. [Google Scholar] [CrossRef]
- Aydi, Y.; Baklouti, M.; Marquet, P.; Abid, M.; Dekeyser, J.L. A Design Methodology of MIN-Based Network for MPPSoC on Reconfigurable Architecture. In Reconfigurable Embedded Control Systems: Applications for Flexibility and Agility; IGI Global: Hershey, PA, USA, 2011; pp. 209–234. [Google Scholar]
- Md Yunus, N.A.; Othman, M.; Mohd Hanapi, Z.; Lun, K.Y. Reliability review of interconnection networks. IETE Tech. Rev. 2016, 33, 596–606. [Google Scholar] [CrossRef]
- Rajkumar, S.; Goyal, N.K. Review of multistage interconnection networks reliability and fault-tolerance. IETE Tech. Rev. 2016, 33, 223–230. [Google Scholar]
- Wu, R.; Wang, Y.; Zhao, D. A low-cost deadlock-free design of minimal-table rerouted xy-routing for irregular wireless nocs. In Proceedings of the 4th ACM/IEEE International Symposium on Networks-on-Chip, Grenoble, France, 3–6 May 2010; pp. 199–206. [Google Scholar]
- Hammami, O.; M’zah, A.; Hamwi, K. Design of 3D-IC for butterfly NOC based 64 PE-multicore: Analysis and design space exploration. In Proceedings of the IEEE International 3D Systems Integration Conference (3DIC)—2011 IEEE International, Osaka, Japan, 31 January–2 February 2012; pp. 1–4. [Google Scholar]
- Hammami, O.; M’zah, A.; Jabbar, M.H.; Houzet, D. 3D IC Implementation for MPSOC architectures: Mesh and butterfly based NoC. In Proceedings of the 4th Asia Symposium on Quality Electronic Design (ASQED), Penang, Malaysia, 10–11 July 2012; pp. 155–159. [Google Scholar]
- Swaminathan, K.; Thakyal, D.; Nambiar, S.G.; Lakshminarayanan, G.; Ko, S.B. Enhanced Noxim simulator for performance evaluation of Network-on-chip topologies. In Proceedings of the Recent Advances in Engineering and Computational Sciences (RAECS), Chandigarh, India, 6–8 March 2014; pp. 1–5. [Google Scholar]
- Dinh, V.N.; Ho, M.V.; Nguyen, V.C.; Ngo, T.S.; Charles, E. The analyzes of network-on-chip architectures based on the Noxim simulator. In Proceedings of the International Conference on Advances in Information and Communication Technology, Thai Nguyen, Vietnam, 12–13 December 2016; pp. 603–611. [Google Scholar]
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Cycle-accurate Network-on-chip simulation with noxim. ACM Trans. Model. Comput. Simul. TOMACS 2016, 27, 1–25. [Google Scholar] [CrossRef]
- Carrillo, S.; Harkin, J.; McDaid, L.J.; Morgan, F.; Pande, S.; Cawley, S.; McGinley, B. Scalable hierarchical network-on-chip architecture for spiking neural network hardware implementations. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 2451–2461. [Google Scholar] [CrossRef]
- Yasoubi, A.; Hojabr, R.; Takshi, H.; Modarressi, M.; Daneshtalab, M. CuPAN–high throughput on-chip interconnection for neural networks. In Proceedings of the International Conference on Neural Information Processing, Istanbul, Turkey, 9–12 November 2015; pp. 559–566. [Google Scholar]
- McKeown, M.; Lavrov, A.; Shahrad, M.; Jackson, P.J.; Fu, Y.; Balkind, J.; Lim, K.; Zhou, Y.; Wentzlaff, D. Power and Energy Characterization of an Open Source 25-Core Manycore Processor. In Proceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 762–775. [Google Scholar]
- Jeffers, J.; Reinders, J. Intel Xeon Phi Coprocessor High Performance Programming; Newnes: Oxford, UK, 2013. [Google Scholar]
- Wang, Q.; Li, N.; Shen, L.; Wang, Z. A statistic approach for power analysis of integrated GPU. Soft Comput. 2019, 23, 827–836. [Google Scholar] [CrossRef]
- Jiang, N.; Becker, D.U.; Michelogiannakis, G.; Balfour, J.; Towles, B.; Shaw, D.E.; Kim, J.; Dally, W.J. A detailed and flexible cycle-accurate network-on-chip simulator. In Proceedings of the IEEE international symposium on performance analysis of systems and software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 86–96. [Google Scholar]
- Liu, J.; Harkin, J.; Maguire, L.P.; McDaid, L.J.; Wade, J.J.; Martin, G. Scalable networks-on-chip interconnected architecture for astrocyte-neuron networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 2290–2303. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Suda, N.; Lai, L.; Chau, B.; Chandra, V.; Esmaeilzadeh, H. Bit fusion: Bit-level dynamically composable architecture for accelerating deep neural network. In Proceedings of the ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 764–775. [Google Scholar]
- Mnejja, S.; Aydi, Y.; Abid, M.; Monteleone, S.; Catania, V.; Palesi, M.; Patti, D. Delta multi-stage interconnection networks for scalable wireless on-chip communication. Electronics 2020, 9, 913. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.; Kang, S.; Shin, D.; Kim, S.; Yoo, H.J. UNPU: An energy-efficient deep neural network accelerator with fully variable weight bit precision. IEEE J.-Solid-State Circuits 2018, 54, 173–185. [Google Scholar] [CrossRef]
- Hojabr, R.; Modarressi, M.; Daneshtalab, M.; Yasoubi, A.; Khonsari, A. Customizing clos network-on-chip for neural networks. IEEE Trans. Comput. 2017, 66, 1865–1877. [Google Scholar] [CrossRef]
- Kwon, H.; Samajdar, A.; Krishna, T. Rethinking NoCs for spatial neural network accelerators. In Proceedings of the 11th IEEE/ACM International Symposium on Networks-on-Chip, Seoul, Republic of Korea, 19–20 October; pp. 1–8.
- Firuzan, A.; Modarressi, M.; Daneshtalab, M.; Reshadi, M. Reconfigurable network-on-chip for 3D neural network accelerators. In Proceedings of the 12th IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Turin, Italy, 4–5 October 2018; pp. 1–8. [Google Scholar]
- Holanda, P.C.; Reinbrecht, C.R.; Bontorin, G.; Bandeira, V.V.; Reis, R.A. DHyANA: A NoC-based neural network hardware architecture. In Proceedings of the IEEE International Conference on Electronics, Circuits and Systems (ICECS), Monte Carlo, Monaco, 11–14 December 2016; pp. 177–180. [Google Scholar]
- Chen, K.C.; Wang, T.Y. NN-noxim: High-level cycle-accurate NoC-based neural networks simulator. In Proceedings of the 11th International Workshop on Network-on-chip Architectures (NoCArc), Fukuoka, Japan, 20 October 2018; pp. 1–5. [Google Scholar]
- Chen, K.C.J.; Wang, T.Y.G.; Yang, Y.C.A. Cycle-accurate noc-based convolutional neural network simulator. In Proceedings of the International Conference on Omni-Layer Intelligent Systems, Crete, Greece, 5–7 May 2019; pp. 199–204. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. ACM Sigarch Comput. Archit. News 2014, 42, 269–284. [Google Scholar] [CrossRef]
- Ascia, G.; Catania, V.; Monteleone, S.; Palesi, M.; Patti, D.; Jose, J. Networks-on-chip based deep neural networks accelerators for iot edge devices. In Proceedings of the 6th International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Granada, Spain, 22–25 October 2019; pp. 227–234. [Google Scholar]
- Pande, P.P.; Kim, R.G.; Choi, W.; Chen, Z.; Marculescu, D.; Marculescu, R. The (low) power of less wiring: Enabling energy efficiency in many-core platforms through wireless noc. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 165–169. [Google Scholar]
- Kim, R.G.; Choi, W.; Chen, Z.; Pande, P.P.; Marculescu, D.; Marculescu, R. Wireless NoC and dynamic VFI codesign: Energy efficiency without performance penalty. IEEE Trans. Very Large Scale Integr. Vlsi Syst. 2016, 24, 2488–2501. [Google Scholar] [CrossRef]
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Improving energy efficiency in wireless network-on-chip architectures. Acm J. Emerg. Technol. Comput. Syst. JETC 2017, 14, 1–24. [Google Scholar] [CrossRef]
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Energy efficient transceiver in wireless Network-on-chip architectures. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 1321–1326. [Google Scholar]
- Dai, P.; Chen, J.; Zhao, Y.; Lai, Y.H. A study of a wire–wireless hybrid NoC architecture with an energy-proportional multicast scheme for energy efficiency. Comput. Electr. Eng. 2015, 45, 402–416. [Google Scholar] [CrossRef]
- Tavakoli, E.; Tabandeh, M.; Kaffash, S.; Raahemi, B. Multi-hop communications on wireless network-on-chip using optimized phased-array antennas. Comput. Electr. Eng. 2013, 39, 2068–2085. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, Y.; Li, J.; Kikkawa, T. Design of multi-channel wireless NoC to improve on-chip communication capacity. In Proceedings of the 5th ACM/IEEE International Symposium, Pittsburgh, PA, USA, 1–4 May 2011; pp. 177–184. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Links | Stage 0 | Stage | Stage |
|---|---|---|---|
| Baseline | I | I | |
| Omega | I | ||
| Butterfly | I |
| Parameter | Value |
|---|---|
| Network size [cores/(switches × stages)] | 32/, 64/, 128/ |
| 64/256 radio-hubs number | 4, 8, 16 |
| 1024 radio-hubs number | 16, 32, 64 |
| Switching technique | Wormhole |
| Radio Access Control Mechanism | Token Packet |
| Wireless data rate [Gbps] | 16 |
| Packet length [flit] | 8 |
| Flit size [bit] | 64 |
| Router input buffer size [flit] | 4 |
| Radio-hub input, antenna buffer size [flit] | 4 |
| Simulation Time | 100,000 cycles |
| Repetitions | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aydi, Y.; Mnejja, S.; Mohammed, F.Q.; Abid, M. Mapping of Deep Neural Network Accelerators on Wireless Multistage Interconnection NoCs. Appl. Sci. 2024, 14, 56. https://doi.org/10.3390/app14010056
Aydi Y, Mnejja S, Mohammed FQ, Abid M. Mapping of Deep Neural Network Accelerators on Wireless Multistage Interconnection NoCs. Applied Sciences. 2024; 14(1):56. https://doi.org/10.3390/app14010056
Chicago/Turabian StyleAydi, Yassine, Sirine Mnejja, Faraqid Q. Mohammed, and Mohamed Abid. 2024. "Mapping of Deep Neural Network Accelerators on Wireless Multistage Interconnection NoCs" Applied Sciences 14, no. 1: 56. https://doi.org/10.3390/app14010056