
Enhanced Solar Coronal Imaging: A GAN Approach with Fused Attention and Perceptual Quality Enhancement


Abstract
:1. Introduction
2. Data and Methods
2.1. Data Set
2.2. Image Registration
2.3. Image Normalization
2.4. Network Structure of SAFCSRGAN
2.5. Residual in Residual Concatenation Attention Block (RRCAB)
2.5.1. Residual Concatenation Attention Block (RCAB)
2.5.2. Residual Concatenation Fusion Attention Block (RCFAB)
2.5.3. Spatial Attention of Fused Channels (SAFC)
2.6. Loss Function
3. Results and Analysis
3.1. Training Details
3.2. Evaluation Index
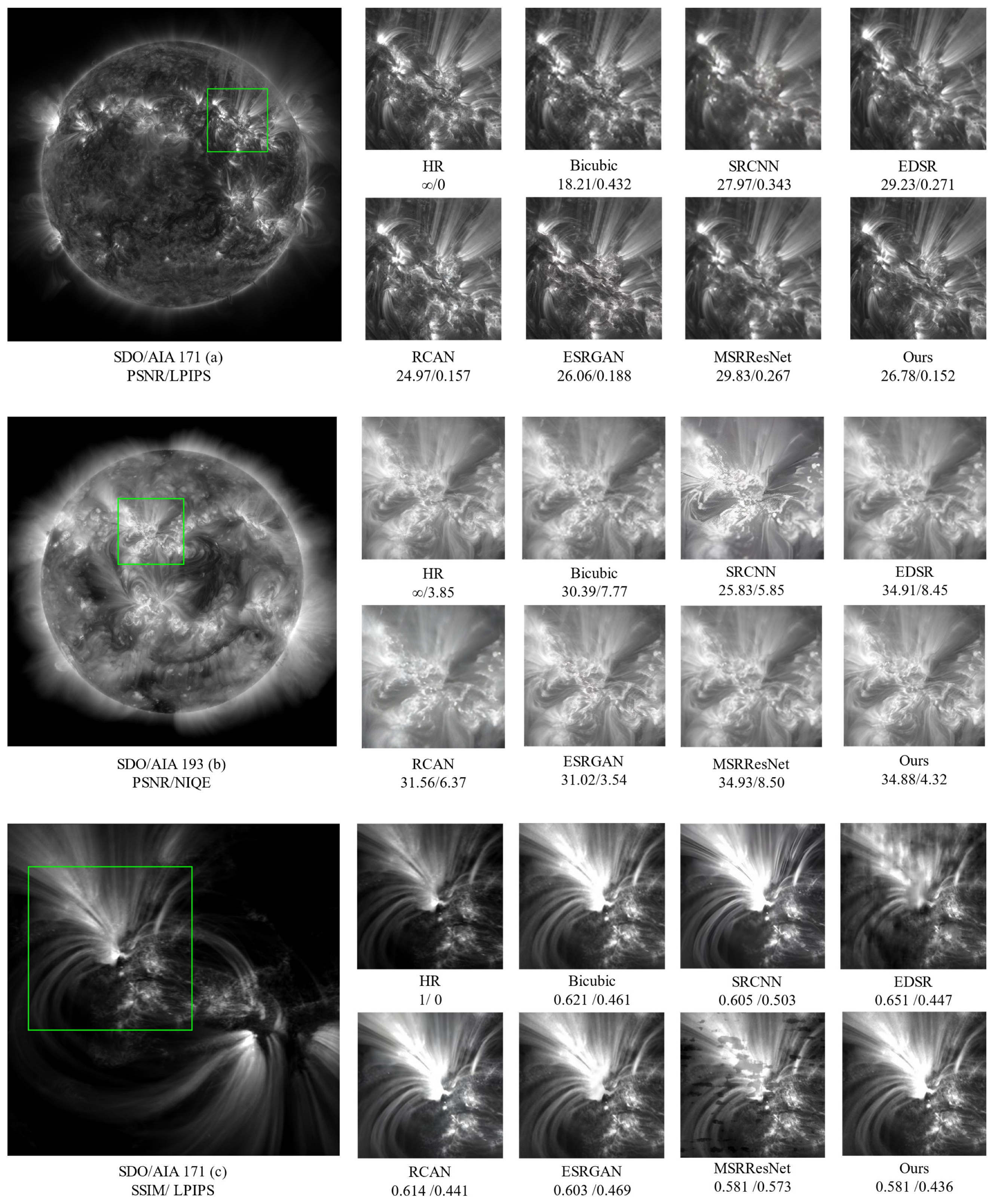
3.3. Experimental Results
3.4. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lockwood, M. Solar Influence on Global and Regional Climates. Surv. Geophys. 2012, 33, 503–534. [Google Scholar] [CrossRef]
- Schwenn, R. Space Weather: The Solar Perspective. Living Rev. Sol. Phys. 2006, 3, 2. [Google Scholar] [CrossRef]
- Lemen, J.R.; Title, A.M.; Akin, D.J.; Boerner, P.F.; Chou, C.; Drake, J.F.; Duncan, D.W.; Edwards, C.G.; Friedlaender, F.M.; Heyman, G.F.; et al. The Atmospheric Imaging Assembly (AIA) on the Solar Dynamics Observatory (SDO). Sol. Phys. 2012, 275, 17–40. [Google Scholar] [CrossRef]
- Pesnell, W.D.; Thompson, B.J.; Chamberlin, P.C. The Solar Dynamics Observatory (SDO). In The Solar Dynamics Observatory; Chamberlin, P., Pesnell, W.D., Thompson, B., Eds.; Springer: New York, NY, USA, 2012; pp. 3–15. ISBN 978-1-4614-3673-7. [Google Scholar]
- Ma, S.; Raymond, J.C.; Golub, L.; Lin, J.; Chen, H.; Grigis, P.; Testa, P.; Long, D. Observations and interpretation of a low coronal shock wave observed in the EUV by the SDO/AIA. Astrophys. J. 2011, 738, 160. [Google Scholar] [CrossRef]
- Yang, R.; Wang, W. Comparison of Super-Resolution Reconstruction Algorithms Based on Texture Feature Classification. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 306–310. [Google Scholar]
- Xue, Z.; Yan, X.; Cheng, X.; Yang, L.; Su, Y.; Kliem, B.; Zhang, J.; Liu, Z.; Bi, Y.; Xiang, Y.; et al. Observing the Release of Twist by Magnetic Reconnection in a Solar Filament Eruption. Nat. Commun. 2016, 7, 11837. [Google Scholar] [CrossRef] [PubMed]
- Berghmans, D.; Auchère, F.; Long, D.M.; Soubrié, E.; Mierla, M.; Zhukov, A.N.; Schühle, U.; Antolin, P.; Harra, L.; Parenti, S.; et al. Extreme-UV Quiet Sun Brightenings Observed by the Solar Orbiter/EUI. Astron. Astrophys. 2021, 656, L4. [Google Scholar] [CrossRef]
- Cirtain, J.W.; Golub, L.; Winebarger, A.R.; De Pontieu, B.; Kobayashi, K.; Moore, R.L.; Walsh, R.W.; Korreck, K.E.; Weber, M.; McCauley, P.; et al. Energy Release in the Solar Corona from Spatially Resolved Magnetic Braids. Nature 2013, 493, 501–503. [Google Scholar] [CrossRef] [PubMed]
- Regnier, S.; Alexander, C.E.; Walsh, R.W.; Winebarger, A.R.; Cirtain, J.; Golub, L.; Korreck, K.E.; Mitchell, N.; Platt, S.; Weber, M.; et al. Sparkling EUV Bright Dots Observed with Hi-C. Astrophys. J. 2014, 784, 134. [Google Scholar] [CrossRef]
- Kuznetsov, V.D. Space Solar Research: Achievements and Prospects. Phys.-Uspekhi 2015, 58, 621. [Google Scholar] [CrossRef]
- Barczynski, K.; Peter, H.; Savage, S.L. Miniature Loops in the Solar Corona. Astron. Astrophys. 2017, 599, A137. [Google Scholar] [CrossRef]
- Williams, T.; Walsh, R.W.; Winebarger, A.R.; Brooks, D.H.; Cirtain, J.W.; Pontieu, B.D.; Golub, L.; Kobayashi, K.; McKenzie, D.E.; Morton, R.J.; et al. Is the High-Resolution Coronal Imager Resolving Coronal Strands? Results from AR 12712. Astrophys. J. 2020, 892, 134. [Google Scholar] [CrossRef]
- Rahman, S.; Moon, Y.-J.; Park, E.; Siddique, A.; Cho, I.-H.; Lim, D. Super-Resolution of SDO/HMI Magnetograms Using Novel Deep Learning Methods. Astrophys. J. Lett. 2020, 897, L32. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, Z.; Tang, R.; Deng, X.; Wang, J. Image Super-Resolution Methods for FY-3E X-EUVI 195 Å Solar Images. Astrophys. J. Suppl. Ser. 2023, 265, 36. [Google Scholar] [CrossRef]
- Bi, Y.; Yang, J.-Y.; Qin, Y.; Qiang, Z.-P.; Hong, J.-C.; Yang, B.; Xu, Z.; Liu, H.; Ji, K.-F. Morphological Evidence for Nanoflares Heating Warm Loops in the Solar Corona. Astron. Astrophys. 2023, 679, A9. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Ariav, I.; Cohen, I. Fully Cross-Attention Transformer for Guided Depth Super-Resolution. Sensors 2023, 23, 2723. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Barron, J.T. A General and Adaptive Robust Loss Function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-Scale Residual Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR↑ | SSIM↑ | NIQE↓ | LPIPS↓ |
|---|---|---|---|---|
| Bicubic | 29.0103 | 0.7328 | 10.8501 | 0.3964 |
| ESRGAN (Baseline) | 32.9796 | 0.8762 | 5.9583 | 0.1835 |
| SRCNN | 30.0458 | 0.7891 | 9.9584 | 0.3781 |
| EDSR | 36.9069 | 0.9132 | 9.8624 | 0.3538 |
| RCAN | 36.4203 | 0.9030 | 9.7381 | 0.3562 |
| SRGAN | 28.5083 | 0.7796 | 7.2463 | 0.2954 |
| MSRResNet | 36.8074 | 0.9114 | 9.5365 | 0.3514 |
| Ours | 36.9125 | 0.9183 | 5.3158 | 0.1812 |
| Method | Choice | ||||
|---|---|---|---|---|---|
| Dense concat | w | w/o | w/o | w/o | w/o |
| RCAB | w/o | w/o | w | w/o | w |
| RCFAB | w/o | w/o | w/o | w | w |
| PSNR | 32.97 | 33.23 | 35.78 | 35.12 | 36.91 |
| SSIM | 0.87 | 0.84 | 0.89 | 0.88 | 0.91 |
| NIQE | 5.95 | 5.92 | 5.54 | 5.76 | 5.31 |
| LPIPS | 0.1835 | 0.1833 | 0.1821 | 0.1823 | 0.1812 |
| Parameters (M) | 16.69 | 13.02 | 13.11 | 13.06 | 13.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, Z.; Li, R. Enhanced Solar Coronal Imaging: A GAN Approach with Fused Attention and Perceptual Quality Enhancement. Appl. Sci. 2024, 14, 4054. https://doi.org/10.3390/app14104054
Shang Z, Li R. Enhanced Solar Coronal Imaging: A GAN Approach with Fused Attention and Perceptual Quality Enhancement. Applied Sciences. 2024; 14(10):4054. https://doi.org/10.3390/app14104054
Chicago/Turabian StyleShang, Zhenhong, and Ruiyao Li. 2024. "Enhanced Solar Coronal Imaging: A GAN Approach with Fused Attention and Perceptual Quality Enhancement" Applied Sciences 14, no. 10: 4054. https://doi.org/10.3390/app14104054
APA StyleShang, Z., & Li, R. (2024). Enhanced Solar Coronal Imaging: A GAN Approach with Fused Attention and Perceptual Quality Enhancement. Applied Sciences, 14(10), 4054. https://doi.org/10.3390/app14104054