
The Limits of Words: Expanding a Word-Based Emotion Analysis System with Multiple Emotion Dictionaries and the Automatic Extraction of Emotive Expressions

 ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- Investigate how to update and extend the affect lexicon of ML-Ask in a way of manual expansion, proposing a scientific and heuristic method for manually adding Japanese emotive expressions through some available Japanese dictionaries of emotive expressions which have different classifications of emotion categories from that of the affect lexicon in ML-Ask.
- Propose a method for automatically extracting new emotive expressions to update the dictionary periodically.
- Improve the performance of ML-Ask after the expansion of the lexicon database.
2. Literature Review
2.1. Lexicon-Based Emotion Analysis Systems
2.2. Rule-Based Emotion Analysis Systems
2.3. Machine Learning-Based Emotion Analysis Systems
3. Materials and Methods for Manual Expansion
3.1. Differences in Emotion Categories in Hiejima’s Dictionary and Nakamura’s Dictionary
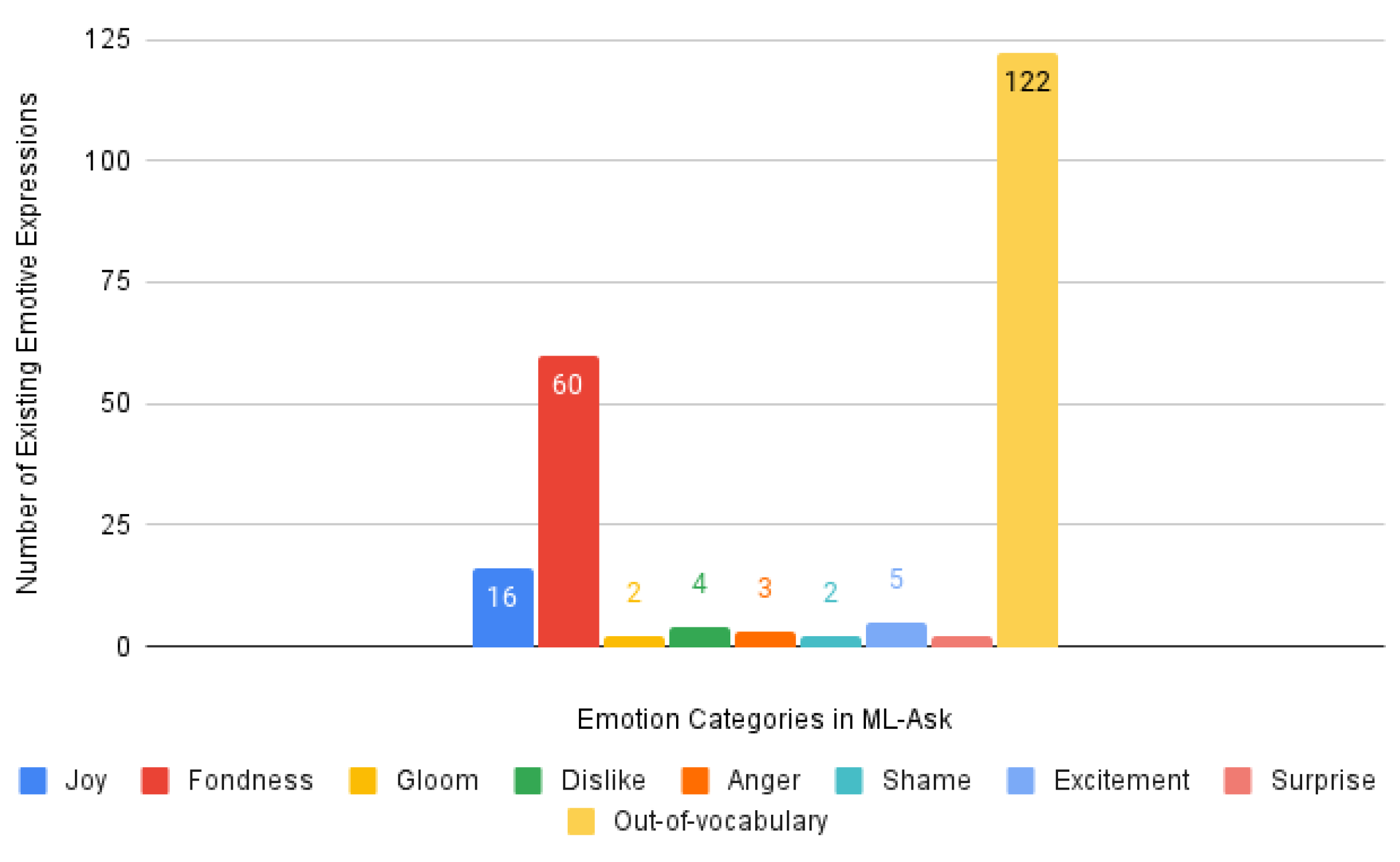
3.2. Checking for Existing Emotive Expressions in Hiejima’s Dictionary
3.3. Processing OOV Expressions in Hiejima’s Dictionary
3.3.1. Reducing Number of OOV Expressions in Hiejima’s Dictionary
3.3.2. Questionnaire Survey 1
- YACIS Large-scale Japanese Blog CorpusThe YACIS blog corpus is currently the largest Japanese blog corpus with 5.6 billion words [22]. The YACIS corpus, made in 2010, was collected from the Ameba blogs, and when it was created, it included roughly one-third of the Ameba blog. Furthermore, the YACIS corpus has been applied to several studies about affect analysis [23,24,25]. Therefore, we considered it to be suitable for application to this study.
3.3.3. Preparation of Example Sentence Dataset for the Questionnaire
3.3.4. Questionnaire Setup
3.3.5. Initial Results of Questionnaire
3.3.6. Improvement of the Questionnaire
3.3.7. Final Results and Summary of Both Surveys
3.4. Differences in Emotion Categories in Murakami’s Dictionary and Nakamura’s Dictionary
3.5. Checking for Existing Emotive Expressions in Murakami’s Dictionary
3.6. Processing OOV Expressions in Murakami’s Dictionary
3.6.1. Basic Concept
3.6.2. Word2vec and fastText Models
3.6.3. Weblio Thesaurus
3.6.4. Synonym Query Matching
3.7. Questionnaire Survey 2
4. Materials and Methods for Automatic Expansion
4.1. On Preparing Datasets for Emotive Expression Extraction
4.1.1. Emotional Information in the YACIS Corpus
4.1.2. Preparation of Dataset for Emotive Expression Extraction
4.2. Emotive Expression Extraction Method
4.3. Investigation of Parts of Speech Appearing in Emotive Expressions
4.4. On the Segmentation Process and Word Weight Coefficients
- Segmentation ProcessThe segmentation process is a method of separating and segmenting individual words in a sentence. The following three types of processing were used in this study.
- Word SegmentationWord segmentation is a method of splitting a given sentence into the smallest units (morphemes) of meaningful words. Word segmentation is the simplest and most representative segmentation method that does not use any other post-processing. In this study, MeCab was used for word segmentation.
- Prototype ProcessingPrototype processing is a method of dividing an input sentence into morphemes, which are the smallest units of the final meaningful word group, and returning the words to their prototype (or dictionary type). The prototype processing is used in this experiment because it unifies grammaticalized words (e.g., した “Shi Ta“, している “Shi Te I Ru”) into the lexical form (e.g., する “Su Ru”), which reduces the number of word types but makes important words more noticeable. This time, MeCab was used for prototype processing.
- Chunk ProcessingIn chunk processing, the input sentence is not divided into morphemes but into phrases. This enables the extraction of not only words but also long phrases consisting of multiple words, and was used in this study. This time, CaboCha (https://taku910.github.io/cabocha/ (accessed on 19 May 2024), [41]) was used for chunk processing.
- Weighting CoefficientsThe weighting coefficients used in this study are coefficients that indicate the importance of words in a sentence. In this study, two types of weighting coefficients are used:
- tf*idftf*idf (also tf-idf) is the value obtained by multiplying tf (word frequency) [42] by idf (inverse document frequency) [43]. Specifically, tf is the frequency of occurrence of each word per sentence, df is the total number of times the word appears in a document (e.g., dataset), and idf is the inverse of df.
- OkapiBM25OkapiBM25 [44] was used as the weighting coefficient for the other type of word importance. OkapiBM25 is a method that introduces the total number of words in a document into the tf*idf approach to calculating word importance. The weighting coefficients are calculated by taking into account the values of the number of words in the document and the average number of words, which are not taken into account in tf*idf, thus limiting the weight of unimportant words in the document more than in tf*idf. For this reason, we used it in this case for comparison with tf*idf.
4.5. Extraction Results
5. Experiments and Results
5.1. Evaluation Experiment 1: Coverage of Hiejima’s Dictionary and Murakami’s Dictionary
5.1.1. Experimental Setup
5.1.2. Results and Discussion of Experiment 1
5.2. Evaluation Experiment 2: Expansion of the Affect Lexicon
Results and Discussion of Experiment 2
5.3. Evaluation Experiment 3: Automatic Expansion of Affect Lexicon
5.3.1. Experimental Setup
- Six combinations of each preprocessing and weighting coefficient (three types of segmentation times two types of weighting coefficient) were used to create a list of candidate emotive expressions.
- Evaluated with test data using ML-Ask baseline model.
- Added each of the lists prepared in (1), above, to the ML-Ask affect lexicon, evaluated each combination with test data, and confirmed changes in the results.
- Word Segmentation + tf*idf;
- Word Segmentation + BM25;
- Prototype Processing + tf*idf;
- Prototype Processing + BM25;
- Chunk Processing + tf*idf;
- Chunk Processing + BM25.
5.3.2. Results and Discussion of Experiment 3
5.4. Evaluation Experiment 4: Improvement of the Auto-Expanded Affect Lexicon
Results and Discussion of Experiment 4
5.5. Additional Experiment
Results and Discussion of Additional Experiment
6. Discussion
6.1. Main Findings
6.2. Theoretical and Practical Implications
6.3. Originality of the Study
6.4. Study Limitations
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CVS | Contextual Valence Shifters |
| MeCab | Yet Another Part-of-Speech and Morphological Analyzer |
| ML-Ask | eMotive eLement and Expression Analysis system |
| NLP | Natural Language Processing |
| OkapiBM25 | Term weighting for Okapi information retrieval system with Best Matching 25 |
| OOV | Out-of-Vocabulary |
| POS | Part-of-Speech |
| SNS | Social Networking Services |
| TF*IDF | Term weighting using Term Frequency with Inverse Document Frequency |
| TF-IDF | See TF*IDF |
| YACIS | Yet Another Corpus of Internet Sentences |
References
- Beigi, G.; Hu, X.; Maciejewski, R.; Liu, H. An Overview of Sentiment Analysis in Social Media and Its Applications in Disaster Relief. In Sentiment Analysis and Ontology Engineering: An Environment of Computational Intelligence; Springer: Cham, Switzerland, 2016; pp. 313–340. [Google Scholar]
- Jain, V.K.; Kumar, S.; Fernandes, S.L. Extraction of emotions from multilingual text using intelligent text processing and computational linguistics. J. Comput. Sci. 2017, 21, 316–326. [Google Scholar] [CrossRef]
- Gaind, B.; Syal, V.; Padgalwar, S. Emotion detection and analysis on social media. arXiv 2019, arXiv:1901.08458. [Google Scholar]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. A survey of sentiment analysis in social media. Knowl. Inf. Syst. 2019, 60, 617–663. [Google Scholar] [CrossRef]
- Avasthi, S.; Chauhan, R.; Acharjya, D.P. Information Extraction and Sentiment Analysis to Gain Insight into the COVID-19 Crisis. In Proceedings of the International Conference on Innovative Computing and Communications: ICICC 2021, Delhi, India, 20–21 February 2021; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 343–353. [Google Scholar]
- Ptaszynski, M.; Dybala, P.; Rzepka, R.; Araki, K.; Masui, F. ML-Ask: Open source affect analysis software for textual input in Japanese. J. Open Res. Softw. 2017, 5, 16. [Google Scholar] [CrossRef]
- Nakamura, A. Kanjo Hyogen Jiten [Dictionary of Emotive Expressions]; Tokyodo Publishing: Tokyo, Japan, 1993. (In Japanese) [Google Scholar]
- Sharma, S.; Kumar, P.; Kumar, K. LEXER: Lexicon Based Emotion Analyzer. In Proceedings of the International Conference on Pattern Recognition and Machine Intelligence, Kolkata, India, 5–8 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 373–379. [Google Scholar]
- Toçoğlu, M.A.; Alpkocak, A. Lexicon-based emotion analysis in Turkish. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1213–1227. [Google Scholar] [CrossRef]
- Kamal, R.; Shah, M.A.; Maple, C.; Masood, M.; Wahid, A.; Mehmood, A. Emotion classification and crowd source sensing—A lexicon based approach. IEEE Access 2019, 7, 27124–27134. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Bibi, A.; Kundi, F.M.; Ahmad, H. Sentence-level emotion detection framework using rule-based classification. Cogn. Comput. 2017, 9, 868–894. [Google Scholar] [CrossRef]
- Gao, K.; Xu, H.; Wang, J. A rule-based approach to emotion cause detection for Chinese micro-blogs. Expert Syst. Appl. 2015, 42, 4517–4528. [Google Scholar] [CrossRef]
- Nasir, A.F.A.; Nee, E.S.; Choong, C.S.; Ghani, A.S.A.; Majeed, A.P.A.; Adam, A.; Furqan, M. Text-based emotion prediction system using machine learning approach. IOP Conf. Ser. Mater. Sci. Eng. 2020, 769, 012022. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Gupta, M.R.; Bengio, S.; Weston, J. Training highly multiclass classifiers. J. Mach. Learn. Res. 2014, 15, 1461–1492. [Google Scholar]
- Hejima, I. A Short Dictionary of Feelings and Emotions in English and Japanese; Tokyodo Shuppan: Tokyo, Japan, 1995. [Google Scholar]
- Murakami, M. Love, Hate and Everything in Between: Expressing Emotions in Japanese; Kodansha International: Tokyo, Japan, 2002. [Google Scholar]
- Kobayashi, T.; Ishii, K.; Edani, N.; Kondo, Y.; Adachi, Y. Kanjogo Jisho to Kanjo Bunseki Shisutemu EEAS [Dictionariy of Emotion Expression and Emotion Analysis System EEAS]. In Proceedings of the 83rd National Convention of IPSJ, Online, 18–20 March 2021; Volume 2021, pp. 47–48. (In Japanese). [Google Scholar]
- Tatsuya, T.; Masafumi, H. A Proposal of Emotion Estimation Method for Words and Construction of Word-Emotion Dictionary. Trans. Jpn. Soc. Kansei Eng. 2019, 18, 273–278. [Google Scholar]
- Minato, J.; Bracewell, D.B.; Ren, F.; Kuroiwa, S. Statistical Analysis of a Japanese Emotion Corpus for Natural Language Processing. In Computational Intelligence; Huang, D.S., Li, K., Irwin, G.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 924–929. [Google Scholar]
- Sakai, T.; Ptaszynski, M.; Masui, F. Kao Moji Patsu ni Motozui ta Kao Moji no Jido Seisei no Kano Sei ni Kansuru Chosa [Study on Potential of Automatic Emotion Generation based on Emoticon Parts]. In Proceedings of the 33rd Annual Conference of the Japanese Society for Artificial Intelligence, Tokyo, Japan, 4–7 June 2019; Volume JSAI2019, p. 2E4OS903. (In Japanese). [Google Scholar] [CrossRef]
- Ptaszynski, M.; Dybala, P.; Rzepka, R.; Araki, K.; Momouchi, Y. YACIS: A Five-Billion-Word Corpus of Japanese Blogs Fully Annotated with Syntactic and Affective Information. In Proceedings of the AISB/IACAP World Congress, Birmingham, UK, 2–6 July 2012; pp. 40–49. [Google Scholar]
- Vo, B.K.H.; Collier, N. Twitter emotion analysis in earthquake situations. Int. J. Comput. Linguist. Appl. 2013, 4, 159–173. [Google Scholar]
- Steinborn, V.; Maronikolakis, A.; Schütze, H. Politeness Stereotypes and Attack Vectors: Gender Stereotypes in Japanese and Korean Language Models. arXiv 2023, arXiv:2306.09752. [Google Scholar]
- Ptaszynski, M.; Rzepka, R.; Araki, K.; Momouchi, Y. Automatically annotating a five-billion-word corpus of Japanese blogs for sentiment and affect analysis. Comput. Speech Lang. 2014, 28, 38–55. [Google Scholar] [CrossRef]
- Kudo, T. Mecab: Yet Another Part-of-Speech and Morphological Analyzer. 2005. Available online: http://mecab.sourceforge.net/ (accessed on 19 May 2024).
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Ptaszynski, M.; Masui, F.; Ishii, N. A method for automatic estimation of meaning ambiguity of emoticons based on their linguistic expressibility. Cogn. Syst. Res. 2020, 59, 103–113. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- Manabe, H.; Oka, T.; Umikawa, S.; Takaoka, K.; Uchida, Y.; Asahara, M. Fukusu Ryudo no Bunkatsu Kekka ni Motozuku Nihongo Tango Bunsan Hyogen [Japanese Word Distributed Representation Based on Multi-Granular Segmentation Results]. In Proceedings of the 25th Annual Conference of the Association for Natural Language Processing (NLP2019), Nagoya, Japan, 12–15 March 2019; The Association for Natural Language Processing: Tokyo, Japan, 2019; p. NLP2019-P8-5. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Short Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 2, pp. 427–431. [Google Scholar]
- Ptaszynski, M.; Momouchi, Y.; Maciejewski, J.; Dybala, P.; Rzepka, R.; Araki, K. Annotating Japanese Blogs with Syntactic and Affective Information. In Mining User Generated Content; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014; pp. 229–262. [Google Scholar]
- Leonova, V. Review of Non-English Corpora Annotated for Emotion Classification in Text. In Proceedings of the Databases and Information Systems: 14th International Baltic Conference, DB&IS 2020, Tallinn, Estonia, 16–19 June 2020; Proceedings 14. Springer: Berlin/Heidelberg, Germany, 2020; pp. 96–108. [Google Scholar]
- Ihasz, P.L.; Van, T.H.; Kryssanov, V.V. A Computational Model for Conversational Japanese. In Proceedings of the 2015 International Conference on Culture and Computing (Culture Computing), Kyoto, Japan, 17–19 October 2015; pp. 64–71. [Google Scholar]
- Nasser, A. Large-Scale Arabic Sentiment Corpus and Lexicon Building for Concept-Based Sentiment Analysis Systems. Ph.D. Thesis, Graduate School of Science and Engineering of Hacettepe University, Ankara, Turkey, 2018. [Google Scholar]
- Barbaresi, A. Efficient Construction of Metadata-Enhanced Web Corpora. In Proceedings of the 10th Web as Corpus Workshop, Berlin, Germany, 12 August 2016; pp. 7–16. [Google Scholar]
- Ptaszynski, M.; Rzepka, R.; Araki, K.; Momouchi, Y. A Robust Ontology of Emotion Objects. In Proceedings of the Eighteenth Annual Meeting of The Association for Natural Language Processing (NLP-2012), Silchar, India, 16–19 December 2012; pp. 719–722. [Google Scholar]
- Taku Kudo, Y.M. Japanese Dependency Analysis using Cascaded Chunking. In Proceedings of the CoNLL 2002: 6th Conference on Natural Language Learning 2002 (COLING 2002 Post-Conference Workshops), Taipei, Taiwan, 31 August–1 September 2002; pp. 63–69. [Google Scholar]
- Luhn, H.P. A statistical approach to mechanized encoding and searching of literary information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Robertson, S.E.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.M.; Gatford, M. Okapi at TREC-3; NIST Special Publications (SPs); NIST: Gaithersburg, MD, USA, 1995; Volume 109, p. 18. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | Nakamura’s Dictionary | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Categories | Joy | Fondness | Relief | Gloom | Dislike | Anger | Fear | Shame | Excitement | Surprise | OOV | |
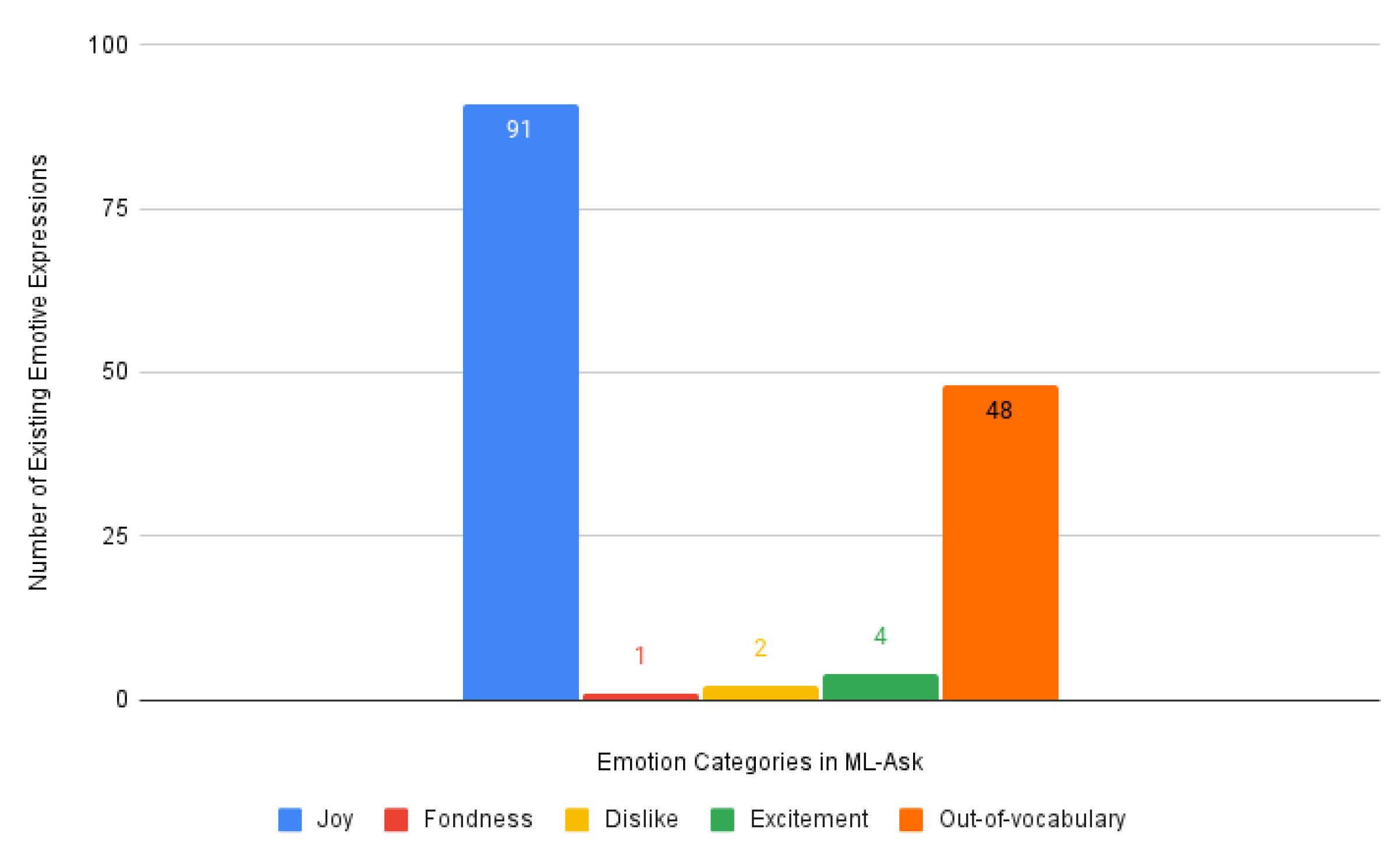
| Hiejima’s dictionary | Joy | 91 (62.33%) | 1 (0.68%) | 2 (1.37%) | 4 (2.74%) | 48 (32.88%) | ||||||
| Love | 1 (0.58%) | 41 (23.84%) | 4 (2.33%) | 8 (4.65%) | 1 (0.58%) | 1 (0.58%) | 116 (67.44%) | |||||
| Anger | 23 (12.17%) | 49 (25.93%) | 3 (1.59%) | 7 (3.70%) | 107 (56.61%) | |||||||
| Suffering | 1 (0.68%) | 4 (2.70%) | 74 (50.00%) | 2 (1.35%) | 8 (5.41%) | 5 (3.38%) | 54 (36.49%) | |||||
| Sadness | 28 (23.53%) | 48 (40.34%) | 1 (0.84%) | 1 (0.84%) | 41 (34.45%) | |||||||
| Blame | 4 (2.08%) | 16 (8.33%) | 3 (1.56%) | 4 (2.08%) | 4 (2.08%) | 161 (83.85%) | ||||||
| Enjoyment | 64 (45.71%) | 5 (3.57%) | 1 (0.71%) | 70 (50.00%) | ||||||||
| Surprise | 3 (3.57%) | 2 (2.38%) | 34 (40.48%) | 45 (53.57%) | ||||||||
| Emotion | Nakamura’s Dictionary | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Categories | Joy | Fondness | Relief | Gloom | Dislike | Anger | Fear | Shame | Excitement | Surprise | OOV | |
| Hiejima’s dictionary | Joy | 115 (82.73%) | 4 (2.88%) | 4 (2.88%) | 4 (2.88%) | 12 (8.63%) | ||||||
| Love | 4 (2.45%) | 59 (36.20%) | 11 (6.75%) | 8 (4.91%) | 4 (2.45%) | 1 (0.61%) | 76 (46.63%) | |||||
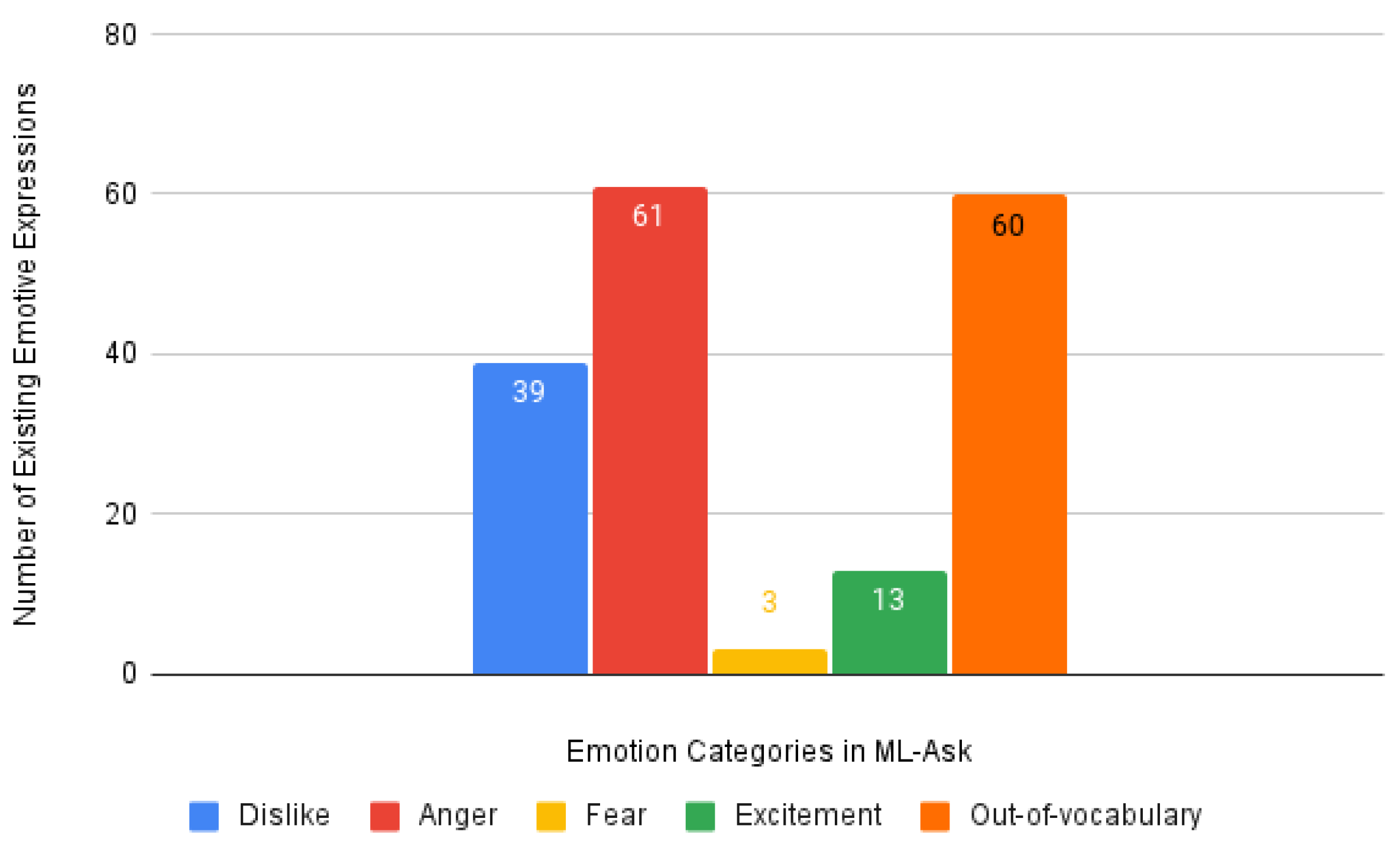
| Anger | 39 (22.16%) | 61 (34.66%) | 3 (1.70%) | 13 (7.39%) | 60 (34.09%) | |||||||
| Suffering | 1 (0.68%) | 4 (2.72%) | 101 (68.71%) | 2 (1.36%) | 9 (6.12%) | 10 (6.80%) | 20 (13.61%) | |||||
| Sadness | 36 (31.03%) | 59 (50.86%) | 1 (0.86%) | 4 (3.45%) | 16 (13.79%) | |||||||
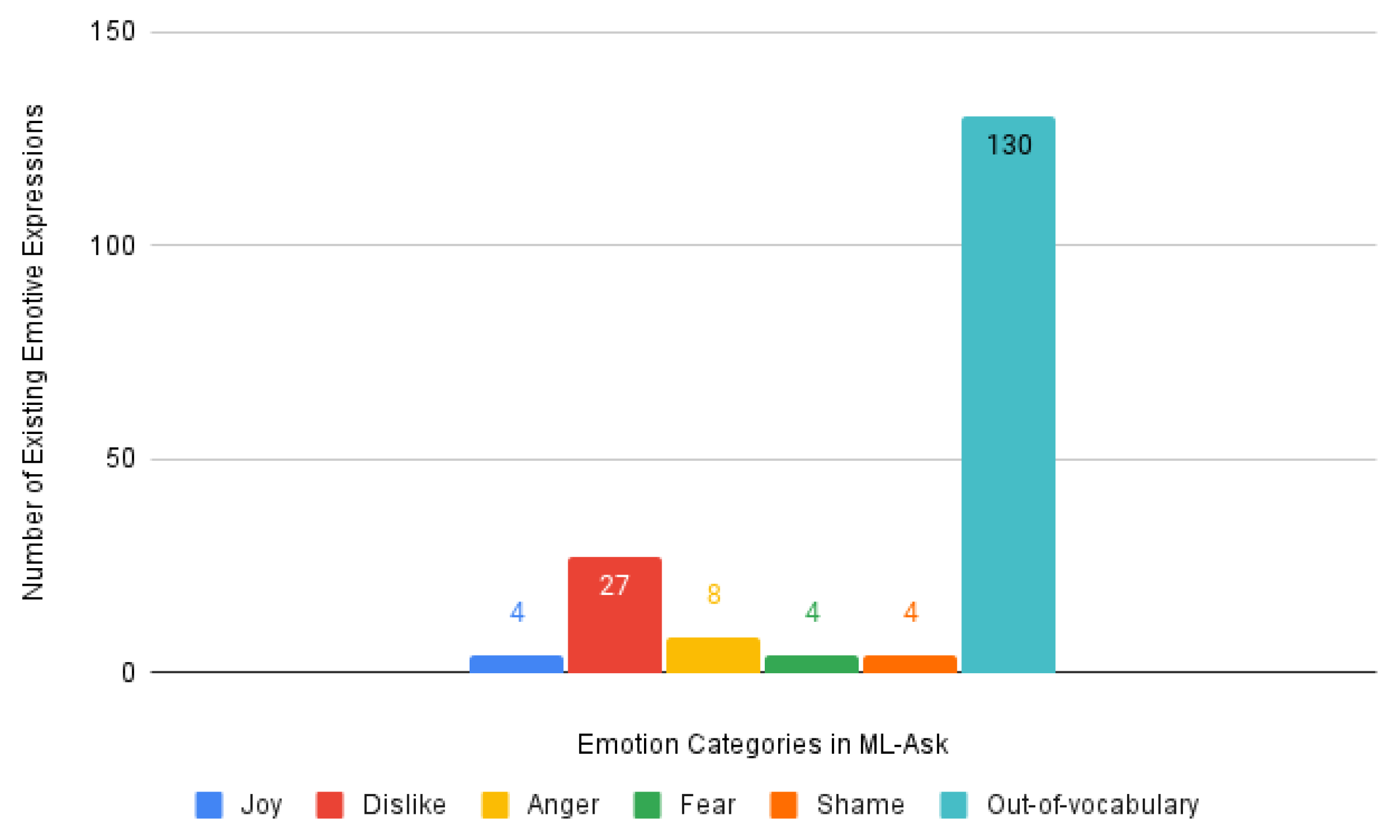
| Blame | 4 (2.26%) | 27 (15.25%) | 8 (4.52%) | 4 (2.26%) | 4 (2.26%) | 130 (73.45%) | ||||||
| Enjoyment | 83 (64.34%) | 6 (4.65%) | 4 (3.10%) | 36 (27.91%) | ||||||||
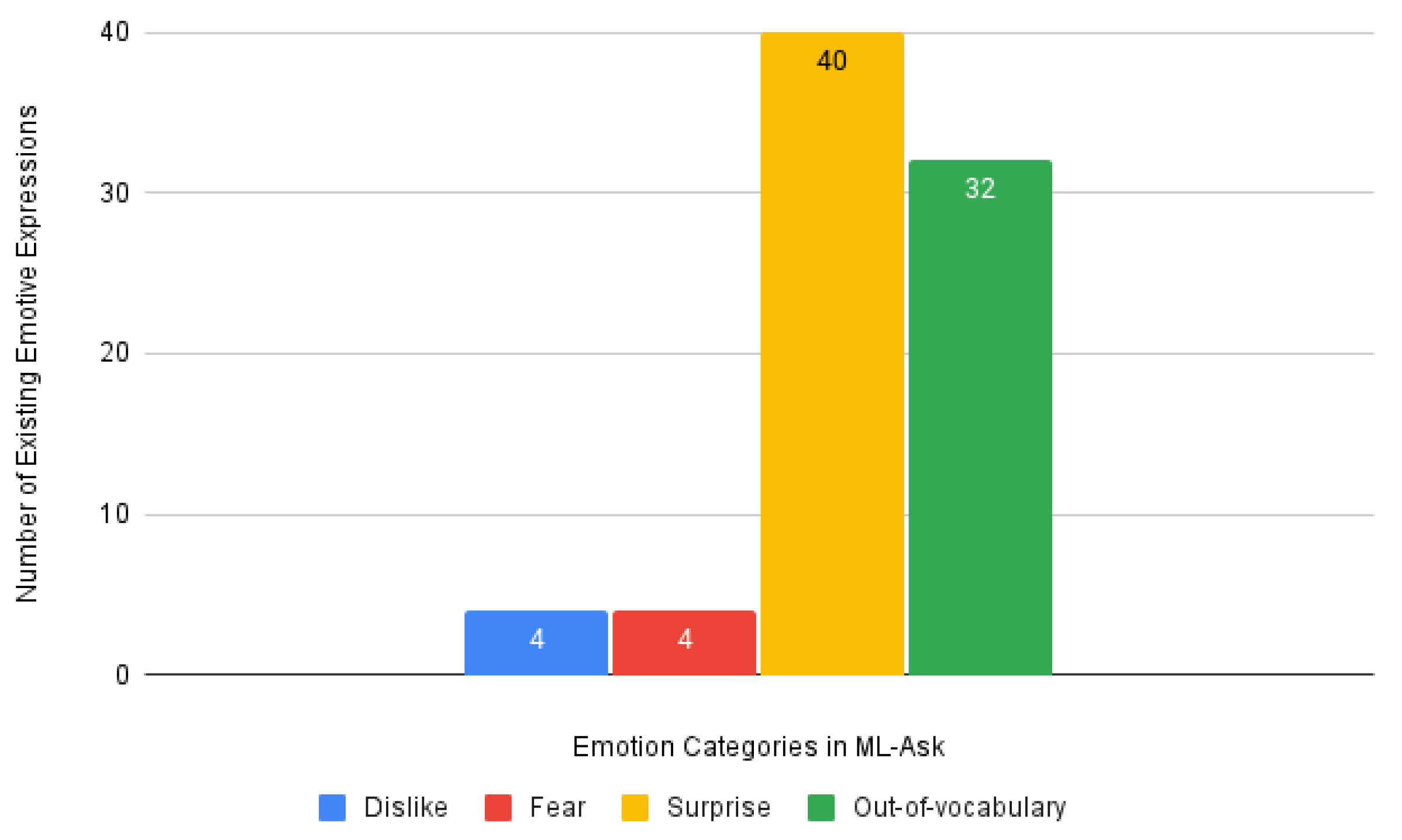
| Surprise | 4 (5.00%) | 4 (5.00%) | 40 (50.00%) | 32 (40.00%) | ||||||||
| Set | Number of Respondents | Age (Generations/%) | Percentage by Gender | |||||
|---|---|---|---|---|---|---|---|---|
| 10s | 20s | 30s | 40s | 50s | Male | Female | ||
| 1 | 8 | 12.5% | 75% | 0% | 0% | 12.5% | 87.5% | 12.5% |
| 2 | 6 | 16.7% | 66.7% | 0% | 0% | 16.7% | 83.3% | 16.7% |
| 3 | 4 | 0% | 100% | 0% | 0% | 0% | 100% | 0% |
| 4 | 3 | 0% | 100% | 0% | 0% | 0% | 100% | 0% |
| Set | Number of Respondents | Age (Generations/%) | Percentage by Gender | |||||
|---|---|---|---|---|---|---|---|---|
| 10s | 20s | 30s | 40s | 50s | Male | Female | ||
| 1 | 7 | 0% | 100% | 0% | 0% | 0% | 100% | 0% |
| 2 | 10 | 0% | 100% | 0% | 0% | 0% | 90% | 10% |
| 3 | 12 | 0% | 100% | 0% | 0% | 0% | 83.3% | 16.7% |
| 4 | 15 | 0% | 100% | 0% | 0% | 0% | 100% | 0% |
| Emotion Category | Number of Sentences |
|---|---|
| Surprise | 83 |
| Anger | 75 |
| Dislike | 72 |
| Excitement | 63 |
| Fear | 70 |
| Joy | 84 |
| Fondness | 83 |
| Relief | 67 |
| Gloom | 69 |
| Shame | 55 |
| Total | 721 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 11 | 6 | 36 |
| Verbs | 16 | 1 | 11 |
| Adverbs | 1 | 0 | 10 |
| Auxiliaries | 7 | 0 | 0 |
| Auxiliary verbs | 4 | 0 | 0 |
| Pre-noun adjectival | 3 | 0 | 0 |
| Adjectives | 1 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 11 | 6 | 60 |
| Verbs | 16 | 1 | 39 |
| Adverbs | 11 | 0 | 14 |
| Adjectives | 3 | 0 | 2 |
| Auxiliaries | 11 | 0 | 0 |
| Pre-noun adjectival | 4 | 0 | 0 |
| Auxiliary verbs | 2 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 9 | 1 | 20 |
| Verbs | 14 | 1 | 10 |
| Adjectives | 1 | 3 | 5 |
| Adverbs | 5 | 0 | 2 |
| Auxiliaries | 11 | 0 | 0 |
| Auxiliary verbs | 3 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Interjection | 1 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 11 | 5 | 185 |
| Verbs | 10 | 1 | 92 |
| Adjectives | 2 | 1 | 54 |
| Adverbs | 5 | 0 | 20 |
| Auxiliaries | 14 | 0 | 0 |
| Auxiliary verbs | 3 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Interjection | 0 | 0 | 3 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 9 | 6 | 93 |
| Verbs | 13 | 3 | 46 |
| Adjectives | 2 | 1 | 8 |
| Adverbs | 3 | 0 | 4 |
| Auxiliaries | 9 | 0 | 0 |
| Auxiliary verbs | 3 | 0 | 0 |
| Pre-noun adjectival | 1 | 0 | 0 |
| Conjunction | 1 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 6 | 5 | 92 |
| Verbs | 15 | 3 | 36 |
| Adverbs | 2 | 0 | 13 |
| Auxiliaries | 11 | 0 | 0 |
| Auxiliary verbs | 1 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Adjectives | 3 | 1 | 19 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 10 | 6 | 86 |
| Verbs | 16 | 2 | 67 |
| Adverbs | 1 | 0 | 16 |
| Adjectives | 0 | 1 | 8 |
| Auxiliaries | 8 | 0 | 0 |
| Pre-noun adjectival | 1 | 0 | 0 |
| Auxiliary verbs | 4 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 14 | 1 | 103 |
| Verbs | 17 | 0 | 33 |
| Adjectives | 3 | 2 | 16 |
| Adverbs | 2 | 0 | 15 |
| Auxiliaries | 5 | 0 | 0 |
| Auxiliary verbs | 3 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 10 | 3 | 39 |
| Verbs | 15 | 1 | 18 |
| Adverbs | 5 | 0 | 8 |
| Adjectives | 3 | 0 | 4 |
| Auxiliaries | 10 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Auxiliary verbs | 2 | 0 | 0 |
| Part-of-Speech | Non-Emotive | Emotive Expression | Emotive Expression |
|---|---|---|---|
| Expression | Candidate Words | (ML-Ask) | |
| Nouns | 15 | 1 | 96 |
| Verbs | 15 | 2 | 37 |
| Adjectives | 1 | 2 | 19 |
| Adverbs | 2 | 1 | 13 |
| Auxiliaries | 7 | 0 | 0 |
| Pre-noun adjectival | 2 | 0 | 0 |
| Auxiliary verbs | 3 | 0 | 0 |
| Word Segmentation | Prototype Processing | Chunk Processing | |
|---|---|---|---|
| tf*idf | 23% | 21% | 25% |
| OkapiBM25 | 19% | 20% | 28% |
| Word Segmentation | Prototype Processing | Chunk Processing | |
|---|---|---|---|
| tf*idf | 5.0% | 2.4% | 28% |
| OkapiBM25 | 7.5% | 13% | 51% |
| ML-Ask | Hiejima’s | Murakami’s | Integration | |
|---|---|---|---|---|
| Baseline | Dict. | Dict. | ||
| partial match rate | 66% | 19% | 1% | 68% |
| exact match rate | 40% | 11% | 0% | 40% |
| polarity dimension match rate | 65% | 21% | 2% | 64% |
| activity dimension match rate | 58% | 18% | 2% | 59% |
| incorrect extraction rate | 3% | 2% | 0% | 3% |
| Partial Match Rate | Exact Match Rate | |
|---|---|---|
| ML-Ask | 66% | 41% |
| baseline | ||
| Word Segmentation | 76% | 19% |
| +tf*idf | (+10%) * | (−22%) |
| Word Segmentation | 72% | 23% |
| +BM25 | (+6%) | (−18%) |
| Prototype Processing | 74% | 15% |
| +tf*idf | (+8%) | (−26%) |
| Prototype Processing | 72% | 23% |
| +BM25 | (+6%) | (−18%) |
| Chunk Processing | 75% | 26% |
| +tf*idf | (+9%) | (−15%) |
| Chunk Processing | 66% | 35% |
| +BM25 | (+0%) | (−6%) |
| Polarity Dimension Match Rate | Activity Dimension Match Rate | Incorrect Extraction Rate | |
|---|---|---|---|
| ML-Ask | 65% | 58% | 2% |
| baseline | |||
| Word Segmentation | 72% | 62% | 7% |
| +tf*idf | (+7%) * | (+4%) | (+5%) |
| Word Segmentation | 70% | 64% | 6% |
| +BM25 | (+5%) | (+6%) | (+4%) |
| Prototype Processing | 71% | 59% | 8% |
| +tf*idf | (+6%) | (+1%) | (+6%) |
| Prototype Processing | 70% | 64% | 6% |
| +BM25 | (+5%) | (+6%) | (+4%) |
| Chunk Processing | 74% | 70% | 3% |
| +tf*idf | (+9%) | (+12%) | (+1%) |
| Chunk Processing | 73% | 66% | 3% |
| +BM25 | (+8%) | (+8%) | (+1%) |
| Partial Match Rate | Exact Match Rate | |
|---|---|---|
| ML-Ask | 66% | 41% |
| baseline | ||
| Word Segmentation | 67% | 40% |
| +tf*idf | (+1%) * | (−1%) |
| Word Segmentation | 67% | 40% |
| +BM25 | (+1%) | (−1%) |
| Prototype Processing | 65% | 39% |
| +tf*idf | (−2%) | (−2%) |
| Prototype Processing | 67% | 39% |
| +BM25 | (+1%) | (−2%) |
| Chunk Processing | 67% | 38% |
| +tf*idf | (+1%) | (−3%) |
| Chunk Processing | 67% | 40% |
| +BM25 | (+1%) | (−1%) |
| Polarity Dimension Match Rate | Activity Dimension Match Rate | Incorrect Extraction Rate | |
|---|---|---|---|
| ML-Ask | 65% | 58% | 2% |
| baseline | |||
| Word Segmentation | 72% | 65% | 2% |
| +tf*idf | (+7%) * | (+7%) | (+0%) |
| Word Segmentation | 72% | 66% | 2% |
| +BM25 | (+7%) | (+8%) | (+0%) |
| Prototype Processing | 72% | 65% | 2% |
| +tf*idf | (+7%) | (+7%) | (+0%) |
| Prototype Processing | 72% | 66% | 2% |
| +BM25 | (+7%) | (+8%) | (+0%) |
| Chunk Processing | 72% | 66% | 2% |
| +tf*idf | (+7%) | (+8%) | (+0%) |
| Chunk Processing | 72% | 66% | 2% |
| +BM25 | (+7%) | (+8%) | (+0%) |
| ML-Ask Baseline | Integration | |
|---|---|---|
| partial match rate | 93.28% | 93.38% |
| number of sentences correctly analyzed | 944 | 945 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Isomura, S.; Ptaszynski, M.; Dybala, P.; Urabe, Y.; Rzepka, R.; Masui, F. The Limits of Words: Expanding a Word-Based Emotion Analysis System with Multiple Emotion Dictionaries and the Automatic Extraction of Emotive Expressions. Appl. Sci. 2024, 14, 4439. https://doi.org/10.3390/app14114439
Wang L, Isomura S, Ptaszynski M, Dybala P, Urabe Y, Rzepka R, Masui F. The Limits of Words: Expanding a Word-Based Emotion Analysis System with Multiple Emotion Dictionaries and the Automatic Extraction of Emotive Expressions. Applied Sciences. 2024; 14(11):4439. https://doi.org/10.3390/app14114439
Chicago/Turabian StyleWang, Lu, Sho Isomura, Michal Ptaszynski, Pawel Dybala, Yuki Urabe, Rafal Rzepka, and Fumito Masui. 2024. "The Limits of Words: Expanding a Word-Based Emotion Analysis System with Multiple Emotion Dictionaries and the Automatic Extraction of Emotive Expressions" Applied Sciences 14, no. 11: 4439. https://doi.org/10.3390/app14114439
APA StyleWang, L., Isomura, S., Ptaszynski, M., Dybala, P., Urabe, Y., Rzepka, R., & Masui, F. (2024). The Limits of Words: Expanding a Word-Based Emotion Analysis System with Multiple Emotion Dictionaries and the Automatic Extraction of Emotive Expressions. Applied Sciences, 14(11), 4439. https://doi.org/10.3390/app14114439