

Robust DOA Estimation Using Multi-Scale Fusion Network with Attention Mask
Abstract
1. Introduction
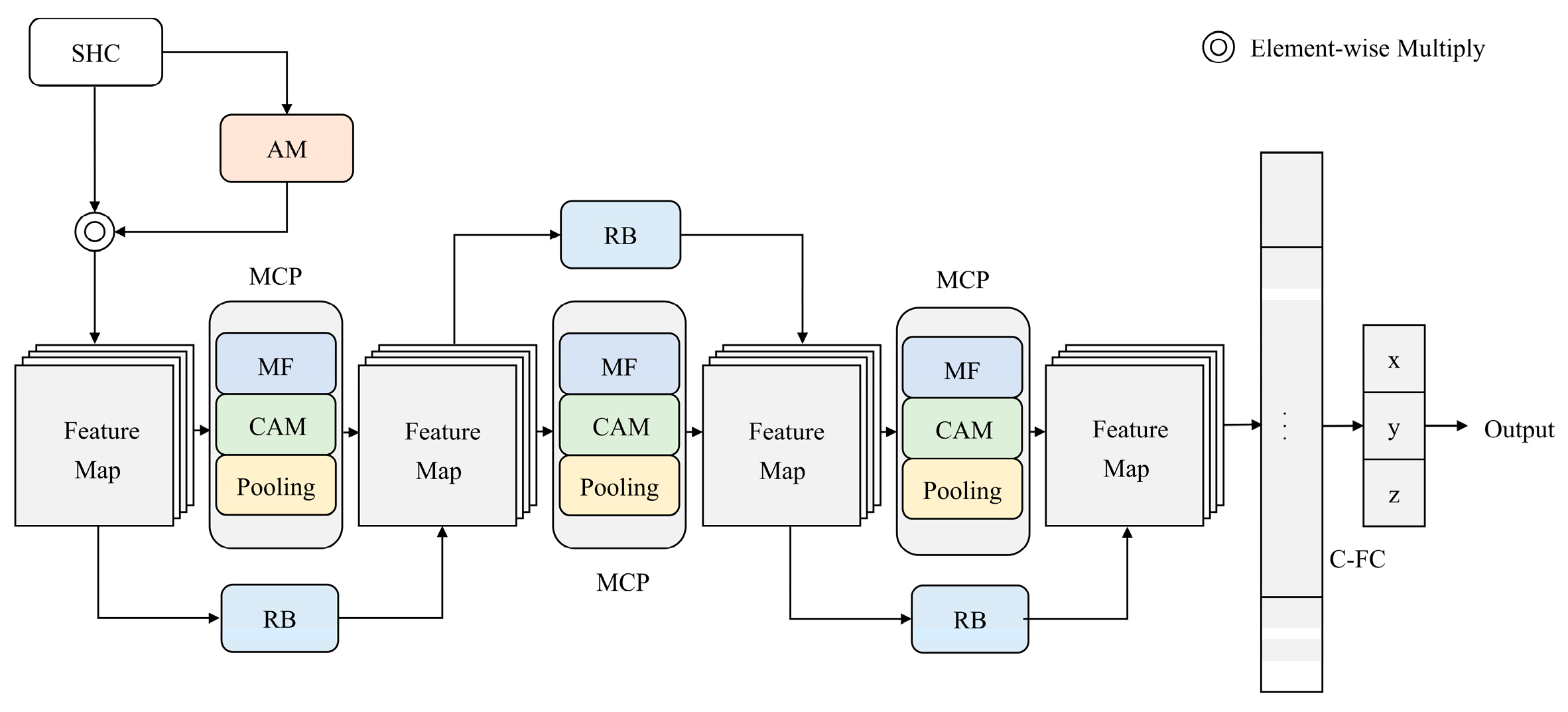
- A robust multi-scale fusion network with attention mask (MF-AMnet) is proposed based on CVNN. By directly handling complex-valued inputs in the spherical harmonic domain, the proposed method preserves the rich information of the original signal, meanwhile minimizing data redundancy caused by data concatenation.
- A low-complexity multi-scale fusion block (MF) is designed to efficiently capture the inherent spatial patterns of the input feature maps by stacking complex-valued convolutional layers with small kernels. The module complexity is effectively reduced by a special branching operation while promoting information flow. Additionally, we adopt an attention mask (AM) module to dynamically assign varying weights to the input features. This enables the network to focus on the relevant information and shield the interference of reverberation and noise.
- Experimental results on both simulated and real datasets demonstrate that our method has significantly enhanced the accuracy and stability of DOA estimation compared with other state-of-the-art methods.
2. Related Work
3. Signal Analysis in the Spherical Harmonic Domain
4. The Proposed Method
5. Experiments and Discussion
5.1. Dataset
5.2. Evaluation Indicators
5.3. Baselines
5.4. Experiments
5.4.1. Performance Comparison
5.4.2. Ablation Experiments
5.4.3. Test on LOCATA Dataset
5.4.4. The Robustness of Methods to Different Noise Types
5.4.5. Inference Time of Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borgström, B.J.; Brandstein, M.S. A Multiscale Autoencoder (MSAE) Framework for End-to-End Neural Network Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 2418–2431. [Google Scholar] [CrossRef]
- Park, H.J.; Shin, W.; Kim, J.S.; Han, S.W. Leveraging Non-Causal Knowledge Via Cross-Network Knowledge Distillation for Real-Time Speech Enhancement. IEEE Signal Process. Lett. 2024, 31, 1129–1133. [Google Scholar] [CrossRef]
- Lee, Y.; Choi, S.; Kim, B.-Y.; Wang, Z.-Q.; Watanabe, S. Boosting Unknown-Number Speaker Separation with Transformer Decoder-Based Attractor. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 446–450. [Google Scholar] [CrossRef]
- Fraś, M.; Kowalczyk, K. Reverberant Source Separation Using NTF With Delayed Subsources and Spatial Priors. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1954–1967. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Wu, Y.; Qian, Y. Unified Cross-Modal Attention: Robust Audio-Visual Speech Recognition and Beyond. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1941–1953. [Google Scholar] [CrossRef]
- Liu, L.; Liu, L.; Li, H. Computation and Parameter Efficient Multi-Modal Fusion Transformer for Cued Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1559–1572. [Google Scholar] [CrossRef]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Palanisamy, P.; Kishore, C. 2-D DOA estimation of quasi-stationary signals based on Khatri-Rao subspace approach. In Proceedings of the 2011 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 3–5 June 2011; pp. 798–803. [Google Scholar] [CrossRef]
- Wang, X.; Amin, M. Design of optimum sparse array for robust MVDR beamforming against DOA mismatch. In Proceedings of the 2017 IEEE 7th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Curacao, The Netherlands, 10–13 December 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Zhu, C.; Wang, W.-Q.; Chen, H.; So, H.C. Impaired Sensor Diagnosis, Beamforming, and DOA Estimation with Difference Co-Array Processing. IEEE Sens. J. 2015, 15, 3773–3780. [Google Scholar] [CrossRef]
- Zaken, O.B.; Kumar, A.; Tourbabin, V.; Rafaely, B. Neural-Network-Based Direction-of-Arrival Estimation for Reverberant Speech—The Importance of Energetic, Temporal, and Spatial Information. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1298–1309. [Google Scholar] [CrossRef]
- Zhang, Z.; Qu, X.; Li, W.; Miao, H.; Liu, F. DOA Estimation Method Based on Unsupervised Learning Network With Threshold Capon Spectrum Weighted Penalty. IEEE Signal Process. Lett. 2024, 31, 701–705. [Google Scholar] [CrossRef]
- Xu, S.; Wang, Z.; Zhang, W.; He, Z. End-to-End Regression Neural Network for Coherent DOA Estimation with Dual-Branch Outputs. IEEE Sens. J. 2024, 24, 4047–4056. [Google Scholar] [CrossRef]
- Cai, R.; Tian, Q. Two-Stage Deep Convolutional Neural Networks for DOA Estimation in Impulsive Noise. IEEE Trans. Antennas Propag. 2024, 72, 2047–2051. [Google Scholar] [CrossRef]
- Labbaf, N.; Oskouei, H.R.D.; Abedi, M.R. Robust DoA Estimation in a Uniform Circular Array Antenna With Errors and Unknown Parameters Using Deep Learning. IEEE Trans. Green Commun. Netw. 2023, 7, 2143–2152. [Google Scholar] [CrossRef]
- Nie, W.; Zhang, X.; Xu, J.; Guo, L.; Yan, Y. Adaptive Direction-of-Arrival Estimation Using Deep Neural Network in Marine Acoustic Environment. IEEE Sens. J. 2023, 23, 15093–15105. [Google Scholar] [CrossRef]
- The Eigenmike Microphone Array. [Online]. 2013. Available online: http://www.mhacoustics.com/ (accessed on 22 May 2024).
- Williams, E.G. Fourier Acoustics: Sound Radiation and Nearfield Acoustical Holography. J. Acoust. Soc. Am. 2000, 108, 1373. [Google Scholar] [CrossRef]
- Zhao, S.; Nguyen, T.H.; Ma, B. Monaural Speech Enhancement with Complex Convolutional Block Attention Module and Joint Time Frequency Losses. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6648–6652. [Google Scholar] [CrossRef]
- Shahhoud, F.; Deeb, A.A.; Terekhov, V.I. PESQ enhancement for decoded speech audio signals using complex convolutional recurrent neural network. In Proceedings of the 2024 6th International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), Moscow, Russia, 29 February–2 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, P.; Yu, M.; Shen, L.; Lin, Z.; An, K.; Wang, J. Single-Channel Blind Source Separation in Wireless Communications: A Complex-Domain Deep Learning Approach. IEEE Wirel. Commun. Lett. 2024; early access. [Google Scholar] [CrossRef]
- Saadati, M.; Toroghi, R.M.; Zareian, H. Multi-Level Speaker-Independent Emotion Recognition Using Complex-MFCC and Swin Transformer. In Proceedings of the 2024 20th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP), Babol, Iran, 21–22 February 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Deb, S.; Dandapat, S. Emotion Classification using Dual-Tree Complex Wavelet Transform. In Proceedings of the 2017 14th IEEE India Council International Conference (INDICON), Roorkee, India, 15–17 December 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Kong, Y.; Wu, J.; Wang, Q.; Gao, P.; Zhuang, W.; Wang, Y.; Xie, L. Multi-Channel Automatic Speech Recognition Using Deep Complex Unet. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 104–110. [Google Scholar] [CrossRef]
- Xiang, Y.; Tian, J.; Hu, X.; Xu, X.; Yin, Z. A Deep Representation Learning-Based Speech Enhancement Method Using Complex Convolution Recurrent Variational Autoencoder. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 781–785. [Google Scholar] [CrossRef]
- Shlomo, T.; Rafaely, B. Blind Localization of Early Room Reflections Using Phase Aligned Spatial Correlation. IEEE Trans. Signal Process. 2021, 69, 1213–1225. [Google Scholar] [CrossRef]
- Khaykin, D.; Rafaely, B. Acoustic analysis by spherical microphone array processing of room impulse responses. J. Acoust. Soc. Am. 2012, 132, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Huleihel, N.; Rafaely, B. Spherical array processing for acoustic analysis using room impulse responses and time-domain smoothing. J. Acoust. Soc. Am. 2013, 133, 3995–4007. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Teutsch, H.; Mabande, E.; Kellermann, W. Robust localization of multiple sources in reverberant environments using EB-ESPRIT with spherical microphone arrays. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 117–120. [Google Scholar] [CrossRef]
- Johnson, B.A.; Abramovich, Y.I.; Mestre, X. MUSIC, G-MUSIC, and Maximum-Likelihood Performance Breakdown. IEEE Trans. Signal Process. 2008, 56, 3944–3958. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, J. Direction of arrival estimation of multiple acoustic sources using a maximum likelihood method in the spherical harmonic domain. Appl. Acoust. 2018, 135, 85–90. [Google Scholar] [CrossRef]
- Nadiri, O.; Rafaely, B. Localization of Multiple Speakers under High Reverberation using a Spherical Microphone Array and the Direct-Path Dominance Test. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1494–1505. [Google Scholar] [CrossRef]
- Hu, Y.; Abhayapala, T.D.; Samarasinghe, P.N. Multiple Source Direction of Arrival Estimations Using Relative Sound Pressure Based MUSIC. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 253–264. [Google Scholar] [CrossRef]
- Pavlidi, D.; Delikaris-Manias, S.; Pulkki, V.; Mouchtaris, A. 3D localization of multiple sound sources with intensity vector estimates in single source zones. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 1556–1560. [Google Scholar] [CrossRef]
- Hafezi, S.; Moore, A.H.; Naylor, P.A. Augmented Intensity Vectors for Direction of Arrival Estimation in the Spherical Harmonic Domain. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1956–1968. [Google Scholar] [CrossRef]
- Varanasi, V.; Gupta, H.; Hegde, R.M. A Deep Learning Framework for Robust DOA Estimation Using Spherical Harmonic Decomposition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1248–1259. [Google Scholar] [CrossRef]
- Huang, Q.; Fang, W. DOA estimation using two independent convolutional neural networks with residual blocks. Digit. Signal Process. 2022, 131, 103765. [Google Scholar] [CrossRef]
- Dwivedi, P.; Routray, G.; Hegde, R.M. Octant Spherical Harmonics Features for Source Localization using Artificial Intelligence based on Unified Learning Framework. IEEE Trans. Artif. Intell. 2024. early access. [Google Scholar] [CrossRef]
- Dong, Z.; He, H. A training algorithm with selectable search direction for complex-valued feedforward neural networks. Neural Netw. 2021, 137, 75–84. [Google Scholar] [CrossRef]
- Costanzo, S.; Flores, A. CVNN-Based Microwave Imaging Approach. In Proceedings of the 2023 IEEE Conference on Antenna Measurements and Applications (CAMA), Genoa, Italy, 15–17 November 2023; pp. 728–731. [Google Scholar] [CrossRef]
- Costanzo, S.; Flores, A. CVNN Approach for Microwave Imaging Applications in Brain Cancer: Preliminary Results. In Proceedings of the 2024 18th European Conference on Antennas and Propagation (EuCAP), Glasgow, UK, 17–22 March 2024; pp. 1–3. [Google Scholar] [CrossRef]
- Gan, J.; Li, Q.; Shao, H.; Wen, Z.; Yang, T.; Pan, Y.; Sun, G. A Zynq-Based Platform With Conditional-Reconfigurable Complex-Valued Neural Network for Specific Emitter Identification. IEEE Trans. Instrum. Meas. 2024, 73, 5502711. [Google Scholar] [CrossRef]
- Hirose, A. Complex-valued neural networks: The merits and their origins. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 1237–1244. [Google Scholar] [CrossRef]
- Nitta, T. Solving the XOR problem and the detection of symmetry using a single complex-valued neuron. Neural Netw. 2003, 16, 1101–1105. [Google Scholar] [CrossRef] [PubMed]
- Roy, R.; Kailath, T. ESPRIT-estimation of signal parameters via rotational invariance techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Chen, W.; Li, Y.; Wang, J. Research on Recognition of Fly Species Based on Improved RetinaNet and CBAM. IEEE Access 2020, 8, 102907–102919. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Tachibana, K.; Otsuka, K. Wind Prediction Performance of Complex Neural Network with ReLU Activation Function. In Proceedings of the 2018 57th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Nara, Japan, 11–14 September 2018; pp. 1029–1034. [Google Scholar] [CrossRef]
- Jarrett, D.P.; Habets, E.A.P.; Thomas, M.R.P.; Naylor, P.A. Rigid sphere room impulse response simulation: Algorithm and applications. J. Acoust. Soc. Am. 2012, 132, 1462–1472. [Google Scholar] [CrossRef] [PubMed]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Kim, J.; Hahn, M. Voice Activity Detection Using an Adaptive Context Attention Model. IEEE Signal Process. Lett. 2018, 25, 1181–1185. [Google Scholar] [CrossRef]
- Löllmann, H.W.; Evers, C.; Schmidt, A.; Mellmann, H.; Barfuss, H.; Naylor, P.A.; Kellermann, W. The LOCATA Challenge Data Corpus for Acoustic Source Localization and Tracking. In Proceedings of the 2018 IEEE 10th Sensor Array and Multichannel Signal Processing Workshop (SAM), Sheffield, UK, 8–11 July 2018; pp. 410–414. [Google Scholar] [CrossRef]
- Loweimi, E.; Yue, Z.; Bell, P.; Renals, S.; Cvetkovic, Z. Multi-Stream Acoustic Modelling Using Raw Real and Imaginary Parts of the Fourier Transform. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 876–890. [Google Scholar] [CrossRef]
- Hu, S.; Zeng, C.; Liu, M.; Tao, H.; Zhao, S.; Liu, Y. Robust DOA Estimation Using Deep Complex-Valued Convolutional Networks with Sparse Prior. In Proceedings of the 2023 6th International Conference on Information Communication and Signal Processing (ICICSP), Xi’an, China, 23–25 September 2023; pp. 234–239. [Google Scholar] [CrossRef]
- Zhang, Y.; Zeng, R.; Zhang, S.; Wang, J.; Wu, Y. Complex-Valued Neural Network with Multistep Training for Single-Snapshot DOA Estimation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Zheng, R.; Sun, S.; Liu, H.; Chen, H.; Soltanalian, M.; Li, J. Antenna Failure Resilience: Deep Learning-Enabled Robust DOA Estimation with Single Snapshot Sparse Arrays. Invited paper for IEEE Asilomar conference 2024. arXiv 2024, arXiv:2405.02788. [Google Scholar] [CrossRef]
- SongGong, K.; Zhang, P.; Zhang, X.; Sun, M.; Wang, W. Multi-Speaker Localization in the Circular Harmonic Domain on Small Aperture Microphone Arrays Using Deep Convolutional Networks. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 8586–8590. [Google Scholar] [CrossRef]
- Habets, E.A.; Gannot, S. Generating sensor signals in isotropic noise fields. J. Acoust. Soc. Am. 2007, 122, 3464–3470. [Google Scholar] [CrossRef]
- Rajguru, C.; Brianza, G.; Memoli, G. Sound localization in web-based 3D environments. Sci. Rep. 2022, 12, 12107. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Acc5° (%) | Acc10° (%) | Acc15° (%) | MAE (°) |
|---|---|---|---|---|
| DPD-MUSIC | 43.65 | 62.39 | 71.73 | 9.972 |
| SHPM-R | 81.34 | 97.13 | 99.31 | 3.467 |
| SHPM-CR | 82.31 | 97.27 | 99.40 | 3.352 |
| MS | 76.30 | 95.74 | 98.94 | 3.769 |
| CV-CNN | 87.45 | 98.19 | 99.77 | 2.819 |
| CVRAEN | 89.21 | 98.06 | 99.68 | 2.690 |
| SADOAnet | 85.97 | 97.55 | 99.49 | 3.821 |
| SDL | 86.71 | 97.69 | 99.49 | 3.809 |
| MF-AMnet | 94.07 | 99.54 | 99.95 | 2.029 |
| Acc5° (%) | Acc10° (%) | Acc15° (%) | MAE (°) | |
|---|---|---|---|---|
| Base CVNN | 82.31 | 97.27 | 99.40 | 3.352 |
| +AM | 84.63 | 96.81 | 99.44 | 3.187 |
| +MF | 91.76 | 99.35 | 99..91 | 2.44 |
| +CAM | 92.36 | 99.03 | 99.81 | 2.285 |
| +RB | 94.07 | 99.54 | 99.95 | 2.029 |
| Mean Deviation (°) | Standard Deviation (°) | |
|---|---|---|
| CV-CNN | 2.82 | 3.14 |
| CVREAN | 2.97 | 3.01 |
| MF-AMnet | 2.02 | 2.58 |
| Acc5° (%) | MAE (°) | RMSE (°) | |
|---|---|---|---|
| CV-CNN | 85.64 | 3.039 | 3.685 |
| CVREAN | 88.78 | 2.779 | 3.693 |
| MF-AMnet | 92.31 | 2.216 | 3.209 |
| Noises | Acc5° (%) | Acc10° (%) | Acc15° (%) | MAE (°) | |
|---|---|---|---|---|---|
| CV-CNN | Gaussian white noise | 94.07 | 99.54 | 99.95 | 2.029 |
| Diffuse noise | 88.08 | 98.92 | 99.85 | 2.986 | |
| Pink noise | 92.56 | 97.42 | 99.38 | 2.676 | |
| CVREAN | Gaussian white noise | 89.21 | 98.06 | 99.68 | 2.690 |
| Diffuse noise | 80.97 | 97.67 | 99.21 | 3.435 | |
| Pink noise | 85.05 | 97.5 | 99.44 | 3.139 | |
| MF-AMnet | Gaussian white noise | 94.07 | 99.54 | 99.95 | 2.029 |
| Diffuse noise | 88.08 | 98.92 | 99.85 | 2.986 | |
| Pink noise | 92.56 | 97.42 | 99.38 | 2.676 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Y.; Huang, Q. Robust DOA Estimation Using Multi-Scale Fusion Network with Attention Mask. Appl. Sci. 2024, 14, 4488. https://doi.org/10.3390/app14114488
Yan Y, Huang Q. Robust DOA Estimation Using Multi-Scale Fusion Network with Attention Mask. Applied Sciences. 2024; 14(11):4488. https://doi.org/10.3390/app14114488
Chicago/Turabian StyleYan, Yuting, and Qinghua Huang. 2024. "Robust DOA Estimation Using Multi-Scale Fusion Network with Attention Mask" Applied Sciences 14, no. 11: 4488. https://doi.org/10.3390/app14114488
APA StyleYan, Y., & Huang, Q. (2024). Robust DOA Estimation Using Multi-Scale Fusion Network with Attention Mask. Applied Sciences, 14(11), 4488. https://doi.org/10.3390/app14114488