Abstract
As social robots become more prevalent, they often employ non-speech sounds, in addition to other modes of communication, to communicate emotion and intention in an increasingly complex visual and audio environment. These non-speech sounds are usually tailor-made, and research into the generation of non-speech sounds that can convey emotions has been limited. To enable social robots to use a large amount of non-speech sounds in a natural and dynamic way, while expressing a wide range of emotions effectively, this work proposes an automatic method of sound generation using a genetic algorithm, coupled with a random forest model trained on representative non-speech sounds to validate each produced sound’s ability to express emotion. The sounds were tested in an experiment wherein subjects rated the perceived valence and arousal. Statistically significant clusters of sounds in the valence arousal space corresponded to different emotions, showing that the proposed method generates sounds that can readily be used in social robots.
1. Introduction
Non-speech sounds play a crucial role in robot-to-human communication, enabling the conveyance of affective information, which is useful when robots need to interact with individuals from diverse cultural and linguistic backgrounds [1]. The potential for non-speech sounds to express emotion has been explored since non-speech sounds were popularized in media, where fictional robots like R2D2 from Star Wars use squeaks, beeps, and whirrs to communicate emotion and intention [2,3].
Yilmazyildiz et al. [4] studied semantic-free utterances, which include gibberish Speech, paralinguistic utterances, and non-linguistic utterances (NLUs), and explained that, while NLUs are commonly employed as signals in environments such as train stations and airports, they differ from music and speech in that they lack semantic content and consist solely of affective signals. In this study, the focus is on NLUs, not music or speech sounds.
NLUs have been used to convey information, affect, or facilitate communication, with their acoustic parameters derived from natural language or from real-world sources. NLUs are characterized by sounds that do not contain discernible words, are not specifically musical, and exclude laughter or onomatopoeic elements. Having been popularized in movies where fictional robots such as R2D2 and WallE have used them, NLUs’ most obvious application is robots. Characters like R2D2 and WallE are loved by audiences [1], who can interpret the emotions conveyed by them when watching them, even when they do not exactly decode the meaning of the NLUs themselves. Sound designers and Foley artists utilize NLUs to evoke specific sentiments within scenes. As robots and social robots become a bigger part of society, both in industrial and daily life settings, the necessity of maintaining a harmonious relationship with them and being able to understand them in all possible situations is important [1]. To this end, sounds can form part of multi-modal communication channels including gestures, actions, expressions, movements, colors, and normal speech.
This work presents a method of generating NLUs that is different from previous work in the area. Researchers [1,3,5,6] have used varying methods to create NLUs, sometimes in consultation with professional sound designers [7], and some using musical notation schemes or similar abstractions [1,5]. To ensure that social robots can dynamically generate sounds in any given interaction scenario, a new type of method is needed that does away with manual sound creation in favor of a systematic method of sound generation. This work presents a scheme that uses a MIDI note framework and a genetic algorithm (GA) to generate sounds for use by social robots. The method generates many sounds very rapidly. Experiments proved that people perceived sounds as being able to express emotion. This method of sound generation could be implemented in a system that operates in a social robot that actively and dynamically interacts with users in the real world. This system can create many sounds for each type of emotion, as opposed to previous work in the area which usually only proposed a few sounds for each emotion. In some applications, for example, elderly assistance or alarms, we may want a system that uses only a few different sounds that can be easily learned by users, but in others, where more natural and human-like behavior is desired from the social robot, it would be better to have a system that is capable of producing a wide range of sounds in a dynamic and context-sensitive way. Human-like behavior in robots interacting with humans has been found to improve the perception of competence and warmth of the robots [8]. In this work, we automatically generate many sounds and validate their ability to communicate distinct emotions, through machine learning methods, experiments with human subjects, and statistical analyses.
While GAs have been used together with a multi-layer perceptron to produce music, going as far back as 1995 [9], the current study concerns non-speech sounds, and the application of that method, together with other mentioned machine learning methods to validate the emotional meaning of the sounds, for use in social robots has not been applied before.
1.1. Related Work on Interpretation of NLUs
Researchers have demonstrated the usefulness of NLUs for social robots. They can be applied to simple robots, robot pets, or toys that do not require complex speech [2], or even to location-tracking devices [10]. NLUs can also function independently of any specific language and are able to convey simple sentiments very rapidly [11]. Researchers [1,3,5,6] have developed various methods of NLU generation for the expression of intention, emotion, and sometimes dialogue parts. Most have stopped after assessing the recognition rate of emotions from the sounds. This study introduces an automated technique for generating a broad array of NLU sounds that social robots can use naturally and dynamically to convey a wide spectrum of emotions. The method employs a genetic algorithm alongside a random forest model, which has been trained on a selection of representative non-speech sounds, to assess and ensure that each generated sound effectively communicates the intended emotion.
Read [12] found that adults and children could interpret NLUs that conveyed four basic emotions: happiness, sadness, anger, and fear. The authors suggested that NLUs be used as an additional modality with visual cues and speech, rather than a replacement for them. The same authors [11] also discovered that children could easily interpret NLUs in terms of affect, such as happiness, sadness, anger, or fear, but they were not always consistent with each other. On the other hand, adults interpreted NLUs categorically and did not distinguish subtle differences between NLUs. Subsequently, Read [13] investigated how situational context influenced the interpretation of NLUs and found that it overrode NLU interpretation. The same NLU could be interpreted differently depending on the situational context, and when the situational context and NLU aligned, the interpretation was intensified.
Latupeirissa et al. [14] carried out a study to analyze the sounds from popular fictional robot characters from movies to determine key features that enable them to convey emotion. They defined specific important categorizations of sounds including the robot’s inner workings, communication of movement, and conveying of emotion. They also suggested that the sounds used in films, having been designed for that purpose, inevitably lead to expectations from the audience regarding how robots should sound in the real world. The authors found that the long-term average spectrum (LTAS) effectively characterized robot sounds and the sonic characteristics of robots in films varied with their movements and physical appearance. Lastly, they observed that the sounds of the robots they studied used a wider range of frequencies than humans do when speaking. Jee et al. [1] also studied the sounds of robots featured in popular films, namely R2D2 and WallE, with the aim of identifying the fundamental factors employed in conveying emotions and intentions. To accomplish this, the researchers devised a set of seven musical sounds, five for intentions, and two for emotions, which were evaluated using their English teaching robot Silbot. Among the parameters examined, intonation, pitch, and timbre emerged as the most prominent in effectively expressing emotions and intentions. The study established standard intonation and pitch contours while emphasizing the importance of crafting non-linguistic sounds that possess a universal quality, transcending any specific culture or language. Notably, the recognition rate experiment demonstrated that a combination of five sounds effectively conveyed intentions, while two sounds sufficed for emotions. The findings indicated that R2D2 relied on intonation and pitch to communicate emotion and intention, whereas WallE used pitch variation, intonation, and timbre to accentuate its communicative intentions. The timbre component represented the character of the speaker, with R2D2’s metallic beeping nature symbolizing an honest, trustworthy persona. The pitch range of the sounds spanned from 100 Hz to 1500 Hz, aligning with the typical range for human communication. Overall, the study concluded that non-verbal sounds (NLUs) hold promise for effective human–robot communication, with 55% of participants successfully recognizing the sounds for intentions, and 80% recognizing the sounds for emotions.
Khota et al. [15] developed a model to infer the valence and arousal of 560 NLUs extracted from popular movies, TV shows, and video games. Three sets of audio features, which included combinations of spectral energy, spectral spread, zero-crossing rate (ZCR), mel frequency cepstral coefficients (MFCCs), audio chroma, pitch, jitter, formant, shimmer, loudness, and harmonics-to-noise ratio, were used. These features were extracted from the sounds and, after feature reduction where applicable, the best-performing models used a random forest regressor and inferred emotional valence with a mean absolute error (MAE) of 0.107 and arousal with an MAE of 0.097. The correlation coefficients between predicted and actual valence and arousal were 0.63 and 0.75, respectively. This random forest regression model is used in the current work as well and is referred to repeatedly in this paper. Korcsok et al. [16] applied coding rules based on animal calls and vocalizations in the design of NLUs for social robots. They synthesized their sounds using sine waves as a basis and progressively altered the pitch, duration, harmonics, and timbre to modify them. They carried out experiments where they verified that humans could recognize the emotions conveyed by the sounds. They also suggested that sounds with higher frequencies corresponded to higher arousal, while shorter sounds corresponded to a positive valence. The researchers used a linear mixed model to infer the valence and arousal of the sounds and obtained correlation coefficients between 0.5 and 0.6 for both.
Komatsu [17] showed that NLUs could convey positive and negative affect using simple sine tones with rising, falling, or flat frequency gradients. Rising frequency gradients corresponded to positive emotions while falling frequency gradients corresponded to negative emotions. The same patterns were reported in studies on sounds known as earcons, which are everyday tones and sounds used in computers, mobile phones, and other machines to signal basic feedback to the user, such as task completion, notifications, or warnings [18]. Komatsu [19] also suggested that NLUs help to manage the expectations of users of social robots.
Savery et al. [20] explored the effect of musical prosody on interactions between humans and groups of robots. They introduced the concept of entitativity, meaning the perception of the group as being a single entity, and found that alterations of prosodic features of musical sounds increased both the likeability and trust of the robots as well as the entitativity. The results of this study suggest that NLUs can also improve interactions between humans and groups of robots.
These studies demonstrate the potential of NLUs in expressing emotions and affect for social robotics. NLUs hold promise for applications involving uncomplicated robots, robotic companions, or toys that do not need intricate speech capabilities, instead relying on endearing or subtle sounds made feasible by NLUs. Furthermore, NLUs possess language-agnostic qualities, allowing for swift and efficient communication of messages. They can be understood by both children and adults, effectively conveying fundamental emotions such as joy, sadness, anger, and fear. The interpretation of NLUs can be influenced by situational context, and they can function as an additional modality of communication alongside speech and visual cues [12,13,21]. Insights into the expressive capacities of emotions have been gleaned from analyzing the sounds and speech of robots featured in popular films. When designing NLUs for social robots, crucial factors to consider encompass intonation, pitch, timbre, and communicative movements. Various experiments and studies have consistently affirmed the efficacy of NLUs in conveying emotions, underscoring their role in managing user expectations and enhancing human–robot interaction.
1.2. Related Work on Design Methods, Models, and Systems for Producing NLUs
Researchers [16,22,23] have drawn inspiration from human speech, music, and animal sounds when studying and generating NLUs. Compared to these sounds, NLUs are abstract, lack defined rules, and are not as easily recognizable. They are more open to interpretation and can originate from a wide variety of existing and imaginary sources.
Jee et al. [23] used music theory and notation to design NLUs for happiness, sadness, fear, and disgust. Experiments were conducted to test emotion recognizability when using facial expressions, and NLUs together with facial expressions. Fernandez et al. [5] suggested that the use of NLUs in some form or other as part of the communication system of a social robot would enhance its expressiveness. They developed a novel approach to the creation of NLUs, which was based on a “sonic expression system”. They used a dynamic approach involving the modulation of parameters based on the context of the interaction between the robot and the user. The researchers proposed a concept called the quason, which they defined as “the smallest sound unit that holds a set of indivisible psycho-acoustic features that makes it perfectly distinguishable from other sounds, and whose combinations generate a more complex individual sound unit”. The main parameters of the quason are amplitude, frequency, and duration. Individual quasons combine to form sonic expressions. Such expressions were created for communicative acts including agreement, hesitation, denial, questioning, hush, summon, encouragement, greeting, and laughter. Each sonic expression, made with the help of a sound designer, was made at three intensity levels, and was evaluated by 51 subjects in an experiment. The results of the experiment showed that, while most sounds were categorized correctly, some categories, such as agreement, encouragement, and greeting, were easily confused with each other. They also noted that deny, laughing, question, summon, and hush were more easily distinguishable. The researchers recommended integrating their Sonic Expression System into a full, multi-modal, communication system for robot agents. In addition, they determined that fundamental frequency, pauses, volume contour, rhythm, articulation, and speech rate affected the perceived emotion.
Khota et al. [6,24] modeled NLUs in terms of dialogue parts using DAMSL (Dialogue Act Markup in Several Layers). A total of 53 sounds were created using PureData [25] and combining and modulating sine, saw, and square waveforms, in a similar way to Luengo et al. [5] while randomly varying the number of notes and frequencies of each note. A total of 31 subjects evaluated the sounds based on communicative dialogue acts including greeting, reject, question, thanking, accept, apology, non-understanding, and exclamation. Analysis including factor analysis showed that the pitch, timbre, and duration of the sounds had important effects on how participants interpreted them.
1.3. Paper Overview
The work described in this paper concerns the development of a novel method of generating NLUs, using a genetic algorithm (GA) to synthesize sounds and random forest model to infer their valence and arousal. This paper also details an experiment where people listen to and assess the sounds generated by the GA. These evaluations are then compared with predictions made by the random forest model to check the accuracy of the model and the effectiveness of the GA in producing sounds. Section 2.1 explains how the GA method works. Section 2.2 discusses how the trained random forest model predicts the emotional valence and arousal of the sounds created by the GA. Following this, Section 3 reports on the results of the experiment where participants rated the emotional content of the GA sounds, as well as statistical and clustering analyses.
This work presents a robust method of automatic emotionally expressive sound generation that is intended to be used in social robots. While the experiments conducted in this study did not involve physical robots, the generated sounds are specifically designed for application to social robots with the goal of improving their interactive capabilities. This intention is represented in the work by the use of sounds sampled from social robots to help infer the valence and arousal of the generated sounds. Although the method and the experiment can be extended to almost any other use case for which sounds are being developed, the methodology and findings presented here lay the groundwork for future applications where these sounds can be dynamically utilized by social robots in real-world settings. Application of this method to social robots would enable them to effectively convey emotions through sound.
2. NLU Generation Using GA and Valence and Arousal Model
In this work, sounds intended to function as NLUs were generated using MIDI encoding and a genetic algorithm (GA). The objectives of this work were to model the valence and arousal of the generated sounds and to use a previously trained random forest model [15] on generated sounds to infer their valence and arousal. This information would then be used to provide sound design and selection support to use the sounds in social robots or other applicable applications. This method is intended to be used to design sounds for social robots, characters and robots in media, industrial robots, or other machines and objects that require them.
2.1. Genetic Algorithm (GA) Methodology
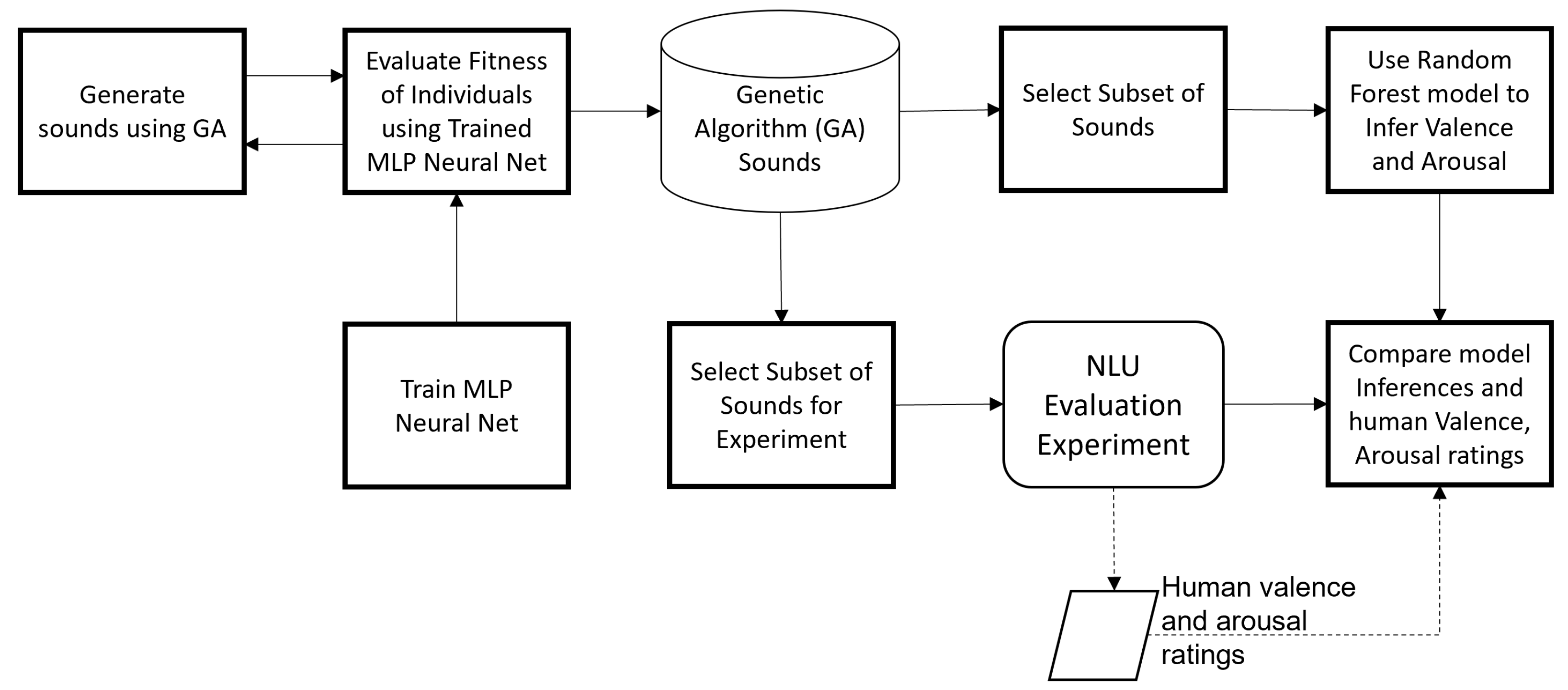
The process followed in this work is shown in Figure 1. Python 3.6 MIDI packages Mido and MIDIUTIL from Pypi (pypi.org, n.d.) can generate MIDI data using defined variables for pitch, duration, time, instrument, pitch-bend, and other parameters. Using this scheme, MIDI notes are strung together and played back as audio according to a set beats-per-minute tempo and instrument sound contained in the General MIDI 2.0 specification (“General MIDI level 2”, 2023). A genotype using binary bits is used in a GA to generate NLUs. The genotype design is shown in Figure 2. In the figure, the numbers in each block are the number of bits used for that part of the genotype. Each of the four sequential sections represents a note, with the instrument contained in an additional bit at the end of the note sequence. In each note, the first 5 bits are assigned to pitch. A range of 32 pitches was selected from those available in the general MIDI 2.0 standard to ensure that sounds did not contain very low-pitched or high-pitched notes. After deciding on a minimum and maximum pitch value, pitches were spread out almost evenly. The duration of each note, measured in beats, is encoded into 3 bits, and an extra beat is added to the total so that the smallest note duration is 1 beat, and the largest 8 beats. Using a bpm of 480, 1 beat is 125 ms and 8 beats are 1 s, so a sound has a minimum duration of 500 ms and a maximum of 4 s. The next 2 bits of each note are for pitch bend. Pitch bend modifies the pitch of a note over a short time in the semitonal range. There are four possible states of pitch bend, (1) 00—no pitch bend, (2) 01—pitch bend down–up, (3) 10—pitch bend up–down, (4) 11—no pitch bend. The state "no pitch bend" was repeated to bias it in the sound generation process. The down–up and up–down pitch bend states involve bending the pitch in the first direction, before reversing it and bending it the other way. The last bit per note is for volume, where 0 represents a volume of 0 to include the possibility of silent segments in the sounds, and 1 represents a volume of 100. All four notes are joined together to form a complete sound. The last bit of the sound (bit 45) is for the instrument, for which two are used from the general MIDI 2.0 specification, 80—square lead, and 85—synth vox, selected as they closely resemble the timbre of typical robotic voices sampled in previous work, such as R2D2, WallE, and BB8.
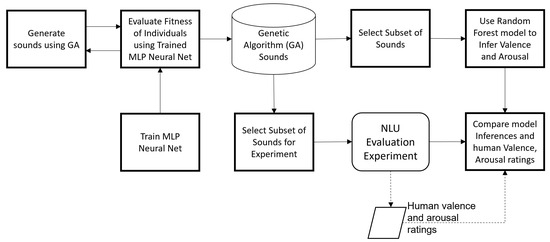
Figure 1.
Genetic algorithm NLU generation and valence arousal modeling process flow.

Figure 2.
Genetic algorithm genotype specification.
A total of 3000 sounds were generated randomly, using the described genotype scheme, and evaluated by a single subject on a scale of 1 to 5 for their suitability as NLUs. The following criteria were used to determine the rating, with the primary guideline being that sounds that more closely resembled observed NLUs were rated higher than those that sounded more abstract:
- Duration and syllable count—sounds that were too short or contained one syllable (discernable pitch) were rated 1. Sounds containing multiple notes and/or syllables were rated higher.
- Pitch dynamic range—sounds that contained high pitch dynamic ranges, very low and very high pitches, were rated low. Observed NLUs did not contain wide pitch ranges. Sounds with very low pitch ranges were rated low.
- Pitch pattern—sounds with a significant amount of variation in their pitch pattern were rated lower than sounds that followed a more consistent and harmonious pattern such as a steady increase or decrease in pitch. Sounds with less dramatic variation in pitch and sounds with pitch bend were also rated higher since they were more like the observed NLUs.
One subject rated 3000 randomly generated sounds. The data were used to train a multi-layer perceptron (neural network) to infer the rating of a sound using its 45-bit genotype as the input data. The input data are strings of length 45 that were converted to arrays of integers with 45 elements. This is followed by a dense fully connected layer containing 90 neurons and using the rectified linear activation function. Following this dense layer, a batch normalization layer and a dropout layer are included to reduce over-fitting. The same over-fitting precautions are added after the following dense layer containing 180 neurons and using a rectified linear activation function. Finally, a single output layer using a linear activation function is used to predict a continuous variable.
Training loss is measured using mean squared error (MSE) and the Adam optimizer. The neural network was trained using 10-fold cross-validation and achieved an average mean absolute error (MAE) of 0.136 and an average correlation between predicted and actual rating values of 0.725. An MAE of 0.136 represents less than one rating point difference on the original 5-point rating scale used to rate the sounds for the training data. The correlation value when considered for the fold size of 3000/10 = 300 results in a p-value for significance of <0.00001. The training loss and validation loss decreased steadily, and minimal over-fitting was observed. The neural network is applied to the GA to automatically evaluate the fitness of individuals through successive generations.
The GA starts with a population of randomly generated individuals. A population size of 400 is selected to ensure genetic variation. The fitness of the population of individuals is evaluated in a batch by the trained neural network. The GA then selects parents from the population based on the tournament selection method with a tournament size of 16, chosen to strike a balance between promoting fit individuals and maintaining some level of genetic diversity in the mating pools [26]. Once the mating pool is populated with parents equal to the population size, the parents are chosen at random to reproduce in pairs using the two-point crossover method followed by a mutation step which applies mutation according to a probability of
As shown by [27], higher rates of mutation (above 0.05) result in the search becoming too random, while a convention is also to use [28],
which was multiplied by 2 to increase the chances of mutation while staying under 0.05. Once a new population is produced, it replaces the old population and the process repeats until convergence is reached, the fitness of successive populations stops improving or changing significantly, and a suitable amount of genetic diversity or sample space has been explored, at which point the GA is manually stopped.
After the GA has finished, binary strings are used to generate and save MIDI files, which are converted to WAV files to be used as sounds. The sounds are input into the random forest model which was trained on 560 NLU sounds extracted from movies, TV shows, and video games [15], to obtain valence and arousal inferences. Audio features, openSMILE LLDs [29], are extracted from the sounds, and the data are used by the random forest model to infer the valence and arousal of the sounds. Finally, the valence and arousal inferences of the sounds used in the experiment are compared to the human ratings of valence and arousal of the same sounds.
2.2. GA and Valence and Arousal Inference Results
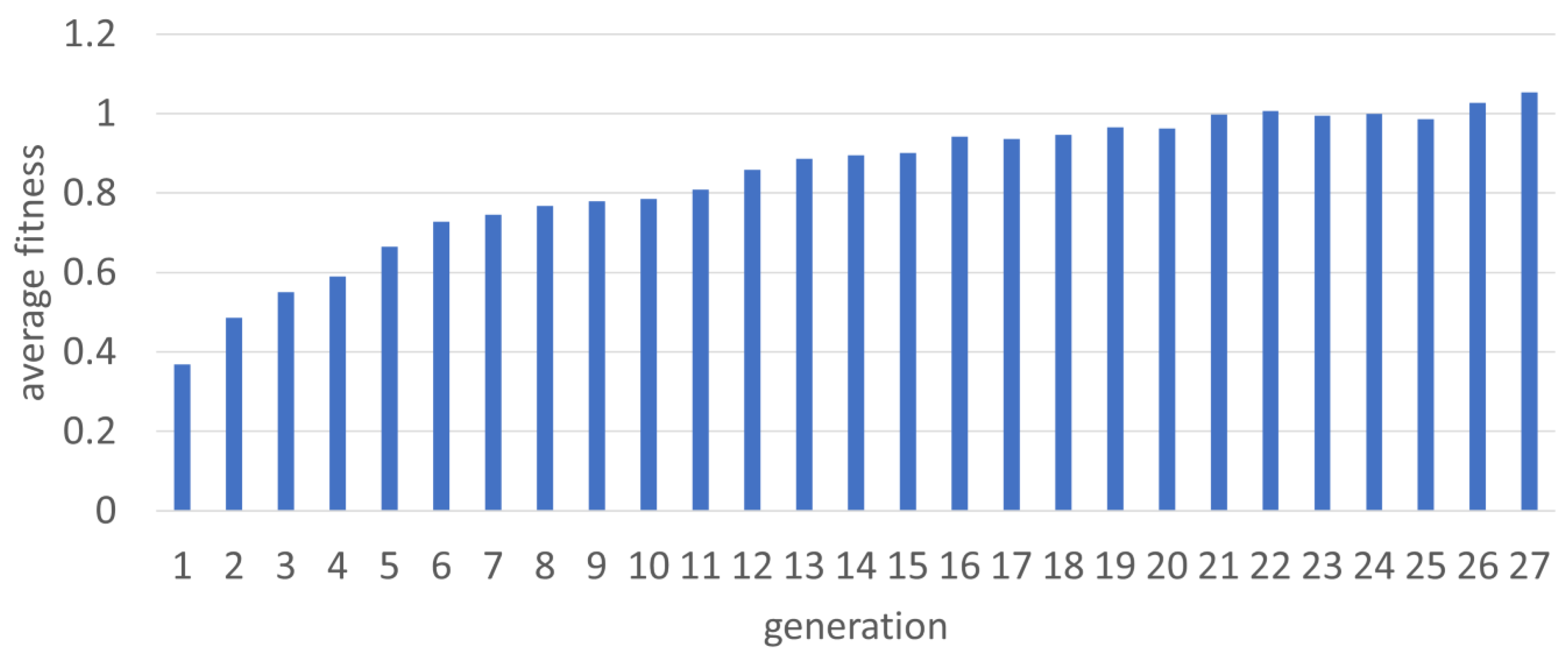
The GA converged to a stable average fitness after 27 generations. The average fitness per generation is in the bar graph in Figure 3.
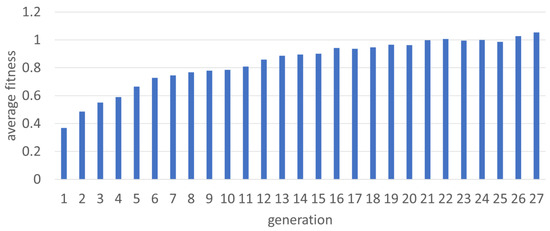
Figure 3.
Fitness per generation of the GA over successive generations.
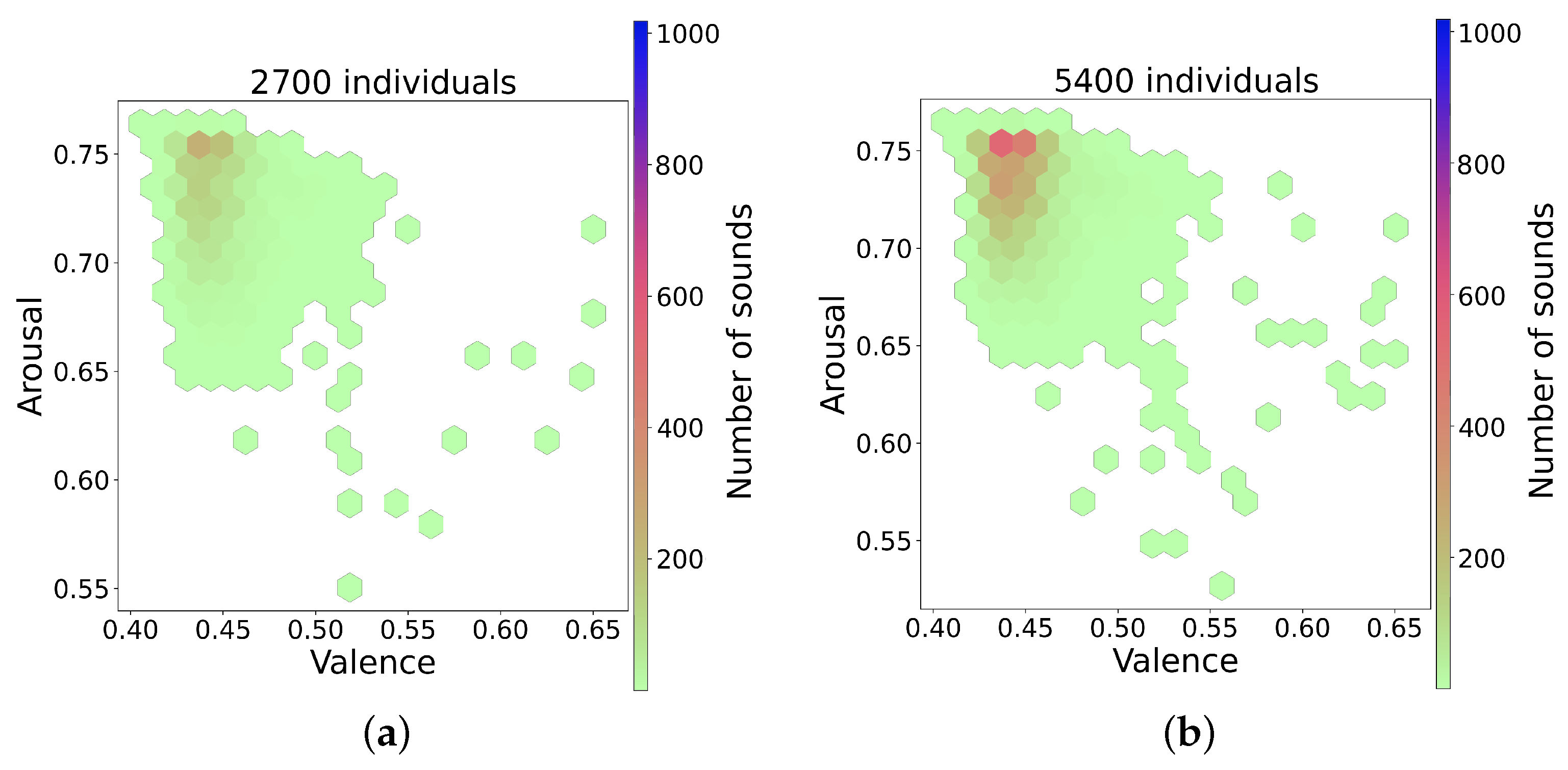
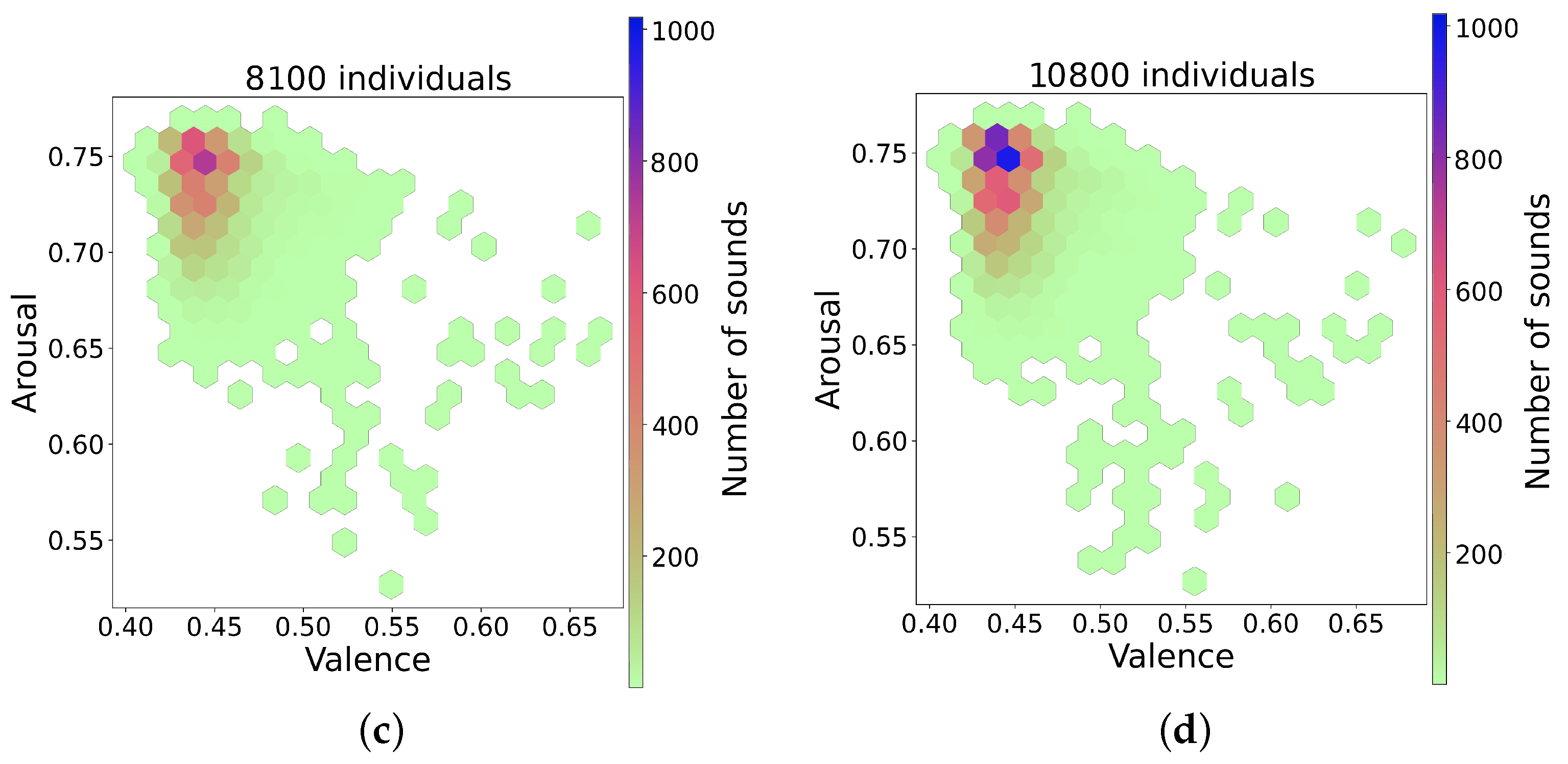
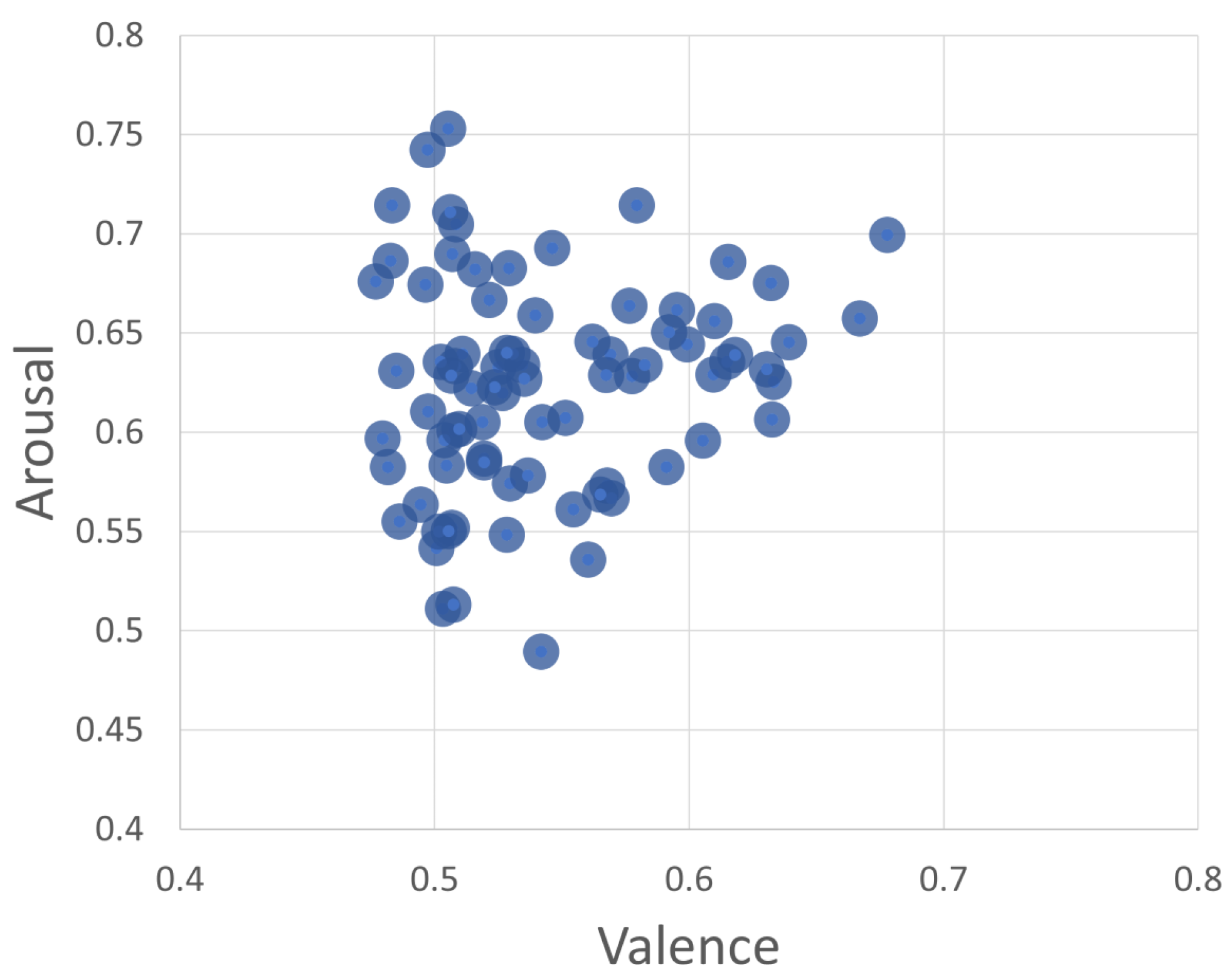
The series of figures shown in Figure 4 shows selected snapshots of the progression of the GA over time, and after using the trained random forest model [15] to infer the valence and arousal of the generated sounds. These figures show how the space of the valence/arousal plane is populated by individuals produced by the GA as it progresses through generations of evolution. The figures show the data cumulatively as the GA progresses, and since the average fitness increases as the generations increase, the GA finds more fit individuals in the area with valence between 0.41 and 0.45 and arousal between 0.7 and 0.76. These valence and arousal scales are normalized such that values less than 0.5 are negative, and values greater than 0.5 are positive. The GA also starts to find fit individuals spread out over a wider range as it progresses. This is evident if we compare Figure 4a,b with Figure 4c,d, which contain more hexagons outside the densest region. The points outside the dense region had higher fitness values in general and, since they also covered a wider range of the valence and arousal space, these were the sounds selected for use in the experiment. A scatterplot of the valence and arousal values for the 80 sounds used in the experiment is shown in Figure 5. The chosen sounds spanned a wider range than the dense regions shown in Figure 4 and all had high fitness as evaluated by the neural network used in the GA.
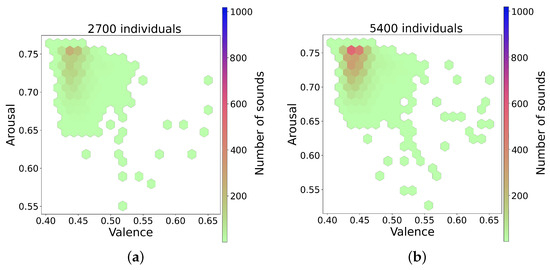
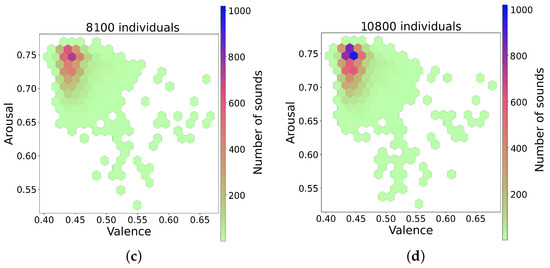
Figure 4.
Snapshots over time of the GA over the valence arousal plane. (a) GA progress after 2700 individuals, (b) GA progress after 5400 individuals, (c) GA progress after 8100 individuals, (d) GA progress after 10,800 individuals.
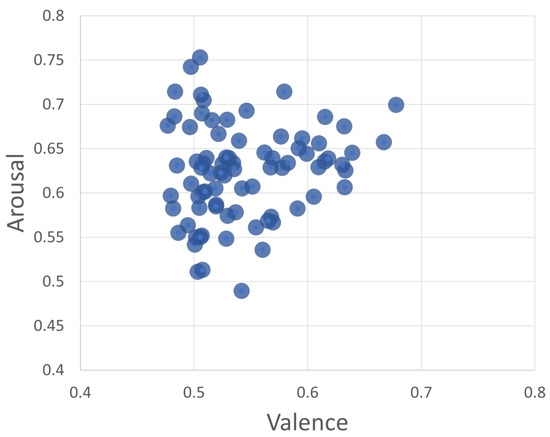
Figure 5.
Scatterplot of the valence and arousal of the 80 sounds used in the experiment.
3. GA Generated Sounds Valence and Arousal Evaluation Experiment
A subset of 80 sounds was selected from those with high fitness from the GA, and evaluated by a single subject for use in the experiment.
In the experiment, subjects are presented with each sound in random order and asked to choose the valence and arousal rating of the sound on a 7-point scale ranging from −3 to 3 in increments of 1. They repeat this process until they have completed all 80 sounds. Russell’s circumplex model of affect was used to measure emotions in a two-dimensional plane using the valence and arousal ratings [30]. A total of 14 subjects evaluated 80 NLU sounds generated from the GA. The subjects were aged from 21 to 37 years old and all except one were university students. Subjects were from a mixed background, including people from Indonesia, China, Korea, Japan, Mexico, India, and South Africa.
3.1. NLU Evaluation Experiment Results
To assess inter-rater reliability, the inter-class correlation (ICC) [31,32] was used. The inter-class correlation coefficient is appropriate for this data as it was compiled from multiple raters rating items (sounds) on a 7-point continuous ordinal Likert scale. The reliability of all raters working as a group using the mean of all raters’ values (ICC3k) was used since the mean of all raters’ ratings was used in subsequent analyses in the rest of the paper. The guidelines are described by Koo and Li [32].
The equation used to determine ICC is the two-way mixed effects, consistency-seeking, multiple raters/measurements version shown below.
where is the mean square for rows, and is the mean square for error.
The ICC results are shown in Table 1 below:

Table 1.
Summary of ICC, F statistics, degrees of freedom, p-values, and confidence intervals.
The values of 0.83 for valence and 0.75 for arousal indicate very good reliability from the group of raters. The result means that there is consistency between the raters as a group and that the average of all the raters’ ratings can be reliably used in the further analyses presented in this work.
The subject ratings were compared with the inferred valence and arousal from the random forest model. The mean absolute error (MAE) for valence was 0.117 and for arousal it was 0.067. The correlation coefficient for inferred vs experiment values was 0.22 for valence and 0.63 for arousal. FOne-way t-tests were applied to determine the statistical significance of the MAE results. The p-value for the valence MAE (0.117) was which was significant based on an alpha of 0.05. The p-value for the arousal MAE (0.067) was 0.612, which was not significant based on an alpha of 0.05.
To verify the significance of the correlations, firstly the distributions of the valence and arousal ratings as well as those of the inferences were assessed to check their distributions. The results are shown in Table 2.
Table 2.
Distributions of valence and arousal ratings and inferences.
For data that are not normally distributed, the Spearman Rank Correlation may be used instead of the Pearson Correlation. The Spearman Rank Correlation Coefficient for valence was 0.23 with a p-value of 0.038, which is significant based on an alpha of 0.05. Since the arousal ratings and inferences were both normally distributed, the Pearson Correlation coefficient of 0.63 may be used. However, the p-value based on an alpha of 0.05 was 0.473, which was not significant.
These results show that the subjects were generally in agreement with the model in terms of their ratings for valence and arousal. The low correlation for valence suggests that there was some difficulty in interpreting the valence of the sounds while the relatively high correlation for arousal suggests that subjects found it easier to assess the arousal of the sounds.
3.2. Clustering and Statistical Analysis
K-means clustering analysis was carried out to determine meaningful groupings of valence and arousal values for the 80 sounds used in the experiment. Firstly, the average values from all subjects for valence and arousal were normalized to be between 0 and 1, so that they could be compared to the predicted values from the random forest model which were themselves normalized between 0 and 1. Next, for each sound, the absolute difference between the normalized average valence and the predicted valence from the random forest model was computed. The same was done for arousal. This value was subtracted from 1 to obtain the inverse error value to use as sample weights in the K-means analysis.
The weight is given by the equation:
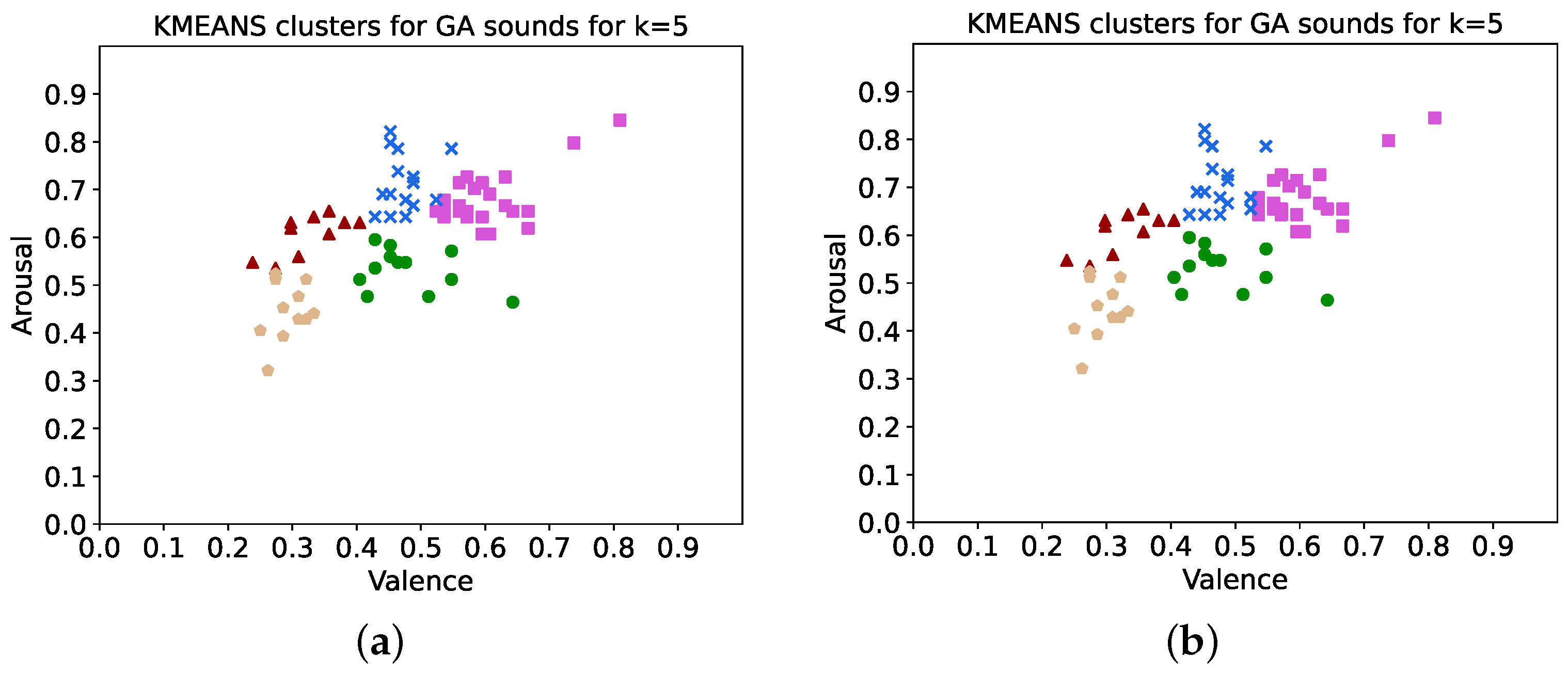
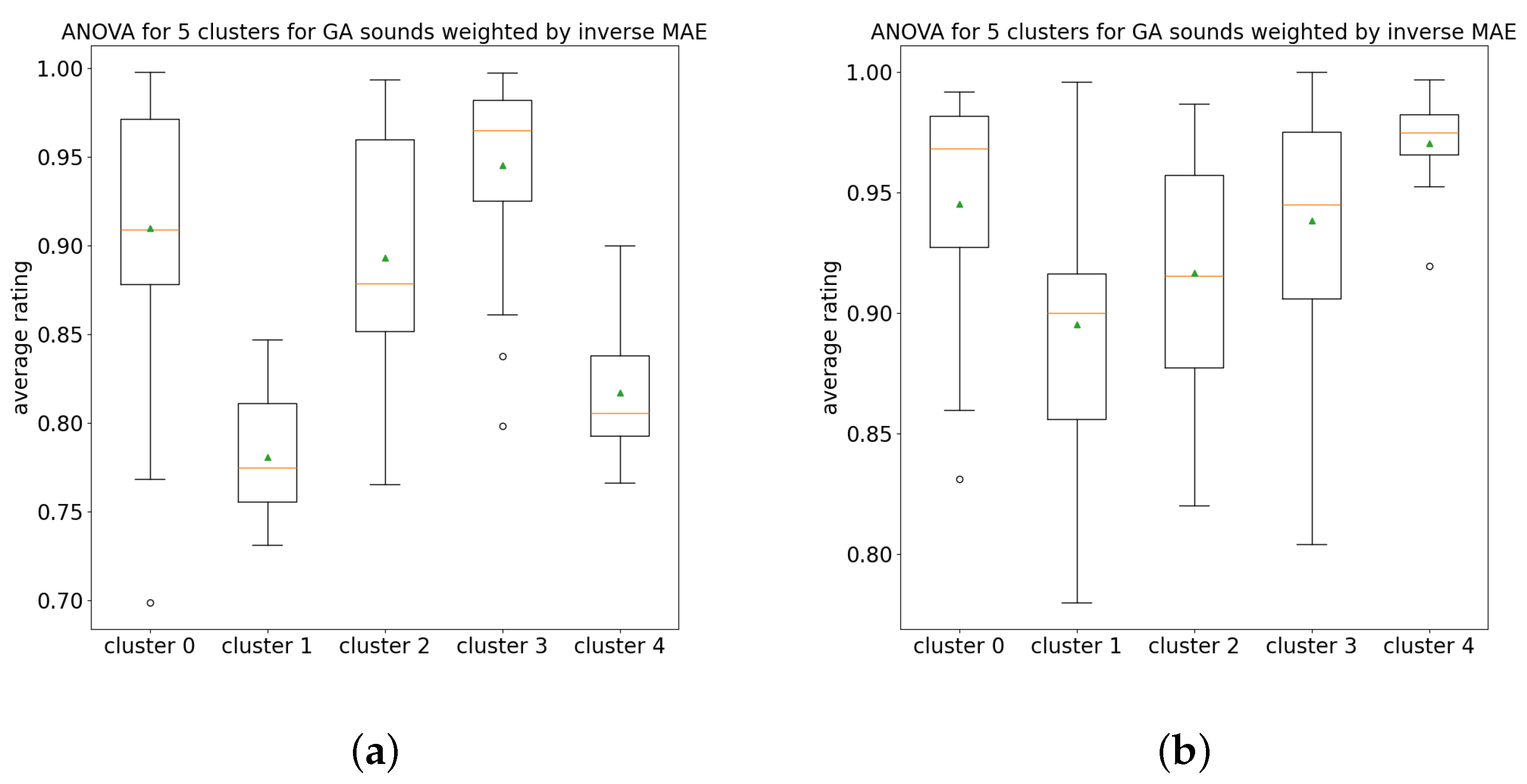
K-means was then carried out for k values between 2 and 8 using sample weights of both the inverse error of valence and inverse error of arousal, respectively, and the best result, such that it was significant when either the valence inverse errors or arousal inverse errors were used as sample weights, was found using k = 5. ANOVA was performed using the clusters produced and resulted in statistically significant differences between the clusters. The clusters are shown in Figure 6a,b for inverse valence error and inverse arousal error, respectively. Note that the values of valence and arousal shown in these cluster plots (used as x and y values for each sound) are from the average human ratings, rather than the inferences from the random forest model. These two cluster plots are nearly identical to each other. ANOVA box plots shown in Figure 7a,b for inverse valence error and inverse arousal error, respectively, indicate the distributions of data within each cluster. A summary of the statistical results is shown in Table 3.
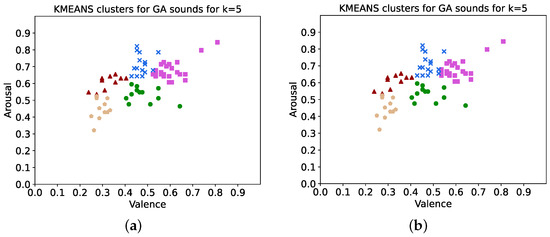
Figure 6.
Kmeans clusters for GA sounds with k = 5 clusters. (a) Weighted by inverse valence error, (b) weighted by inverse arousal error.
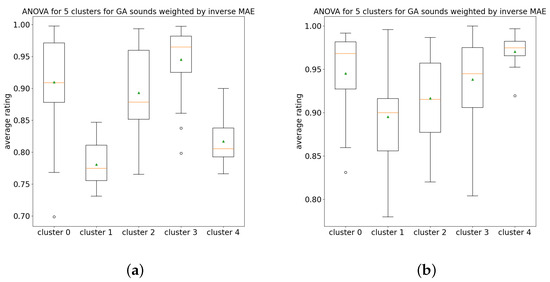
Figure 7.
ANOVA box-plots for GA sounds with k = 5 clusters. (a) Weighted by inverse valence error, (b) weighted by inverse arousal error.
Table 3.
Statistical tests summary.
Following this, the clusters were labeled according to their valence and arousal ranges using Russell’s Circumplex model of emotions to determine an appropriate emotion label, as shown in Table 4. The distribution of each cluster was checked first, as only normally distributed clusters can be considered meaningful for Tukey’s test for Honest Significant Difference, which was carried out to better understand the differences between individual clusters/emotions. The results are shown in Table 5, where the cells with ones show which normally distributed clusters differ significantly from each other.
Table 4.
Cluster analysis of emotion labels based on valence and arousal.
Table 5.
Relationship matrix of emotional states.
4. Discussion
This work introduced a novel method for creating non-speech sounds, for use in social robots or other applicable devices, using a genetic algorithm (GA), and validated by a random forest model, and corroborated through human ratings. The approach uniquely combines MIDI-encoded sound generation with machine learning to dynamically produce sounds that social robots and other devices can use to express a wide range of emotions effectively. Unlike previous methods, which largely relied on manual creation or were limited in emotional range, our GA-based system demonstrated the capability to explore a broad spectrum of valence and arousal, generating sounds that humans consistently rated as expressive of specific emotions. This method’s ability to produce a wide range of sounds rapidly and its validation through a machine learning model and human subject ratings make it uniquely applicable to sound design for human-robot interaction.
The clusters identified through the analysis exhibit a diverse emotional spectrum, spanning from Activated/Alert to Sadness, reflecting the GA’s ability to capture complex emotional states through sound. These clusters were carefully examined for their distribution, and the application of Tukey’s Honest Significant Difference test provided insights into the significant differences between the clusters, further elucidating the method’s capacity to distinguish between nuanced emotional states.
- Activated/Alert (Cluster 1): Sounds in this cluster are characterized by higher arousal and moderate-to-high valence, indicating a state of alertness or activation. This cluster’s sounds effectively evoke feelings of attentiveness or readiness, resembling emotions that may be used in scenarios requiring immediate attention or action from the robot or the user.
- Tense/Fearful/Angry (Cluster 2): This cluster, with lower valence and medium arousal, captures emotions associated with tension, fear, or anger. The method’s ability to generate sounds that distinctly convey these emotions is crucial for situations where a robot may need to express urgency, discomfort, or disapproval without resorting to language.
- Neutral/Calm (Cluster 3): Representing a balanced emotional state with moderate valence and arousal, the sounds in this cluster can be seen as calm or neutral. This demonstrates the GA’s capability to produce sounds for everyday interactions where a serene or neutral emotional tone is desired, facilitating a comfortable ambiance for interaction.
- Happy/Excited (Cluster 4): High valence and arousal mark this cluster, indicating joy or excitement. The clear differentiation of these sounds from others underscores the system’s effectiveness in creating NLUs that could be used to express positive feedback, success, or greeting, enhancing social robots’ ability to engage in positively perceived interactions.
- Sad (Cluster 5): The lower valence and arousal levels in this cluster signify sadness. The ability to generate sounds that are significantly recognized as sad by participants points to the system’s nuanced understanding of emotional expression, allowing for a broadened communicative capacity in scenarios requiring empathy or consolation.
Significant differences were found between clusters representing the emotions of Activated/Alert and Tense/Fearful/Angry, Activated/Alert and Sad, Tense/Fearful/Angry and Neutral/Calm, Tense/Fearful/Angry and Happy/Excited, Neutral/Calm and Sad, and Happy/Excited and Sad. No significant differences were found between the clusters representing the emotions of Activated/Alert and Neutral/Calm, Tense/Fearful/Angry and Sad, and Neutral/Calm and Happy/Excited. Considering these results, the significant differences were found to be between the most different emotions, or the clusters farthest apart in the Valence Arousal space, whereas those closer together or more similar, with overlapping valence and/or arousal, were harder to differentiate. It is also notable that the method was able to differentiate between Neutral/Calm and Sad, emotions that are closer together on the valence arousal plane and would normally be easily confused. This suggests that the method can also effectively navigate the subtle nuances between a lack of strong emotional expression and the expression of negative emotions. This method was able to differentiate and represent specific emotions effectively, which is crucial for designing social robots that can express a wide range of emotions, from alertness or excitement to sadness, thereby enhancing their ability to engage with humans in a more meaningful and contextually appropriate manner.
The findings indicate that, while the system effectively covers a wide area of the valence arousal space, particularly emotions associated with tension, fear, happiness, and excitement, it also reveals areas for improvement in capturing the full range and nuance of human emotions. This could be achieved with more than just the 80 sounds used in this analysis. The experiment’s results, revealing the challenges participants faced in accurately interpreting the valence of sounds, point to the complexity of designing sounds that convey intended emotional cues clearly. The success in generating sounds that span a significant portion of the emotional spectrum, however, supports the utility of our approach for creating more nuanced and expressive interactions between robots and humans.
The current work has used a GA to synthesize NLUs, starting from a genotype specification designed to correspond to existing NLUs, but allowing the algorithm to develop NLUs starting from random samples and exploring the available sample space. The sounds were validated using a random forest regressor trained on extracted NLUs [15]. Jee et al. [1] sampled sounds from R2D2 and WallE, while Luengo et al. [5] designed sounds with the help of professional sound designers and musicians. Khota et al. [6] used similar methods to Luengo et al. [5] to create random NLUs. Read [3] created an automatic NLU generation system using a neural network. These all used categorical labels including intentions, emotions, and dialogue parts, whereas the current work, as well as parts of Read’s Ph.D. work [3], used dimensional measures of affect. In all the mentioned research, pitch, timbre, amplitude, and time were varied to create NLUs. Only Read [3] and the current work take advantage of machine learning methods in the creation and validation of NLUs, while the current work offers a more detailed statistical validation of the capability of the system to represent different emotions, as opposed to the other research that stops at measurements of subject recognition of intention or emotion from the NLUs. When comparing the current work to related work, the most novel aspects are the automatic generation of NLUs using the GA, validation using the random forest model, and measurement of emotions using valence and arousal as per Russell’s circumplex model of affect. Also, the fact that the current method can produce many sounds in a short time is unique and useful for future applications that use NLUs for social robots, devices, or other applicable machines.
5. Conclusions and Future Work
The current work used a GA to produce NLUs and used a random forest model that was previously trained on NLUs extracted from movies, TV shows, and video games [15] to infer their valence and arousal. An experiment was conducted to compare human ratings of valence and arousal of the GA sounds to the inferred values. Using a GA to create NLUs allows for many sounds to be created very rapidly. Using the previously trained random forest model and human rating experiment, the sounds were validated, and subject interpretations of their valence and arousal and the model inferences corresponded closely. This study successfully combines MIDI-encoded sound generation with machine learning techniques to dynamically produce a broad spectrum of emotionally expressive non-linguistic utterances (NLUs). The capability of this GA-based system to generate a diverse range of sounds that are recognized by humans as indicative of specific emotions highlights its potential for enhancing human–robot interaction. Our method distinguishes itself from previous work by its efficiency in sound production and the application of machine learning for sound validation, offering a new paradigm for sound design in interactive technologies. The proposed method generates a wide variety of ready-to-use sounds for social robots, which represent major emotions well, including Tense/Fearful, Sad, Happy/Excited, Activated/Alert, and Neutral/Calm. Furthermore, the findings of this study, particularly the significant differences and similarities between emotional clusters, offer insights into the method’s capacity to navigate the subtleties of emotional expression. The ability to differentiate closely related emotions such as Neutral/Calm and Sad provides evidence of the method’s refined understanding of the valence arousal space. This precision in emotional representation opens up new possibilities for creating robots that can more accurately mimic human emotional expressions, enhancing their integration into everyday life.
This method and result are unique compared to other work in the field. Most other work used designed sounds or sampled sounds, which could not be produced as rapidly and abundantly. Also, most other work has not used machine learning methods to model and validate sounds. The GA was able to produce NLUs covering an area of the valence and arousal plane corresponding to emotions of tension, fear, happiness, and excitement. A more complex genotype design or other optimization methods could result in sounds that cover a wider range of emotions. When the inferences were compared to subject ratings, MAE values of 0.117 for valence and 0.067 for arousal were obtained, indicating that subject ratings agreed with the model. Subjects had some difficulty assessing the valence of the sounds since the correlation coefficient for valence was low. The GA sounds were comparable to sounds extracted from movies, TV shows, and video games that were designed by experts, and the random forest model can be used to support sound design for NLUs, social robots, machines, or devices that use such sounds.
This work has laid the groundwork for a new approach to generating NLUs for social robots, demonstrating the potential of combining genetic algorithms with machine learning and human feedback to create emotionally expressive sounds. The success in generating a wide variety of sounds that can effectively convey a range of emotions marks a significant step forward in the field of human–robot interaction.
In future work, the aim is to create a wider variety of sounds that cover more types of emotions. Furthermore, real-life social robot-to-human interaction scenarios should be constructed to test the application of NLUs in a more realistic setting. Larger-scale experiments should be carried out to establish the significance of both valence and arousal in subject interpretations of the generated sounds. In addition, in future experiments, discrete emotion labels should be tested with subjects as these labels may be more understandable to subjects than valence and arousal, which can sometimes come across as too abstract. Lastly, this work will be integrated into a full end-to-end system that takes in percepts from the environment based on the current interaction and generates an appropriate sound. A new model will be needed to use the percept data to generate the required emotion label and then to use the method presented in this work to generate the corresponding sound.
Author Contributions
Conceptualization, A.K., E.W.C. and Y.Y.; Data curation, A.K.; Formal analysis, A.K.; Funding acquisition, E.W.C.; Investigation, A.K.; Methodology, A.K.; Project administration, E.W.C. and Y.Y.; Resources, A.K.; Software, A.K.; Supervision, E.W.C. and Y.Y.; Validation, A.K.; Visualization, A.K.; Writing—original draft, A.K.; Writing—review and editing, A.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The code used for the Genetic Algorithm and MLP, as well as the random forest model, can be found at the following link on Github: https://github.com/AhmedKhota/GA-sound-generation (accessed on 23 April 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| NLU | Non-Linguistic Utterance |
| MIDI | Musical Instrument Digital Interface |
| GA | Genetic Algorithm |
| MLP | Multi-Layer Perceptron |
References
- Jee, E.S.; Cheong, Y.J.; Kim, C.H.; Kobayashi, H. Sound design for emotion and intention expression of socially interactive robots. Intell. Serv. Robot. 2010, 3, 199–206. [Google Scholar] [CrossRef]
- Bethel, C.; Murphy, R. Auditory and other non-verbal expressions of affect for robots. In Proceedings of the 2006 AAAI Fall Symposium, Washington, DC, USA, 13–15 October 2006. [Google Scholar]
- Read, R. The Study of Non-Linguistic Utterances for Social Human-Robot Interaction. Ph.D. Thesis, University of Plymouth, Plymouth, UK, 2014. [Google Scholar]
- Yilmazyildiz, S.; Read, R.; Belpeame, T.; Verhelst, W. Review of Semantic-Free Utterances in Social Human-Robot Interaction. Int. J. Hum. Comput. Interact. 2016, 32, 63–85. [Google Scholar] [CrossRef]
- Fernandez De Gorostiza luengo, J.; Alonso Martin, F.; Castro-Gonzalez, Á.; Salichs, M.Á. Sound Synthesis for Communicating Nonverbal Expressive Cues. IEEE Access 2017, 5, 1941–1957. [Google Scholar] [CrossRef]
- Khota, A.; Kimura, A.; Cooper, E. Modelling Synthetic Non-Linguistic Utterances for Communication in Dialogue. Int. J. Affect. Eng. 2019, 19, 93–99. [Google Scholar] [CrossRef]
- Chun, K.; Jee, E.S.; Kwon, D.S. Novel musical notation for emotional sound expression of interactive robot. In Proceedings of the 2012 9th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Daejeon, Republic of Korea, 26–28 November 2012; pp. 88–89. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.; Song, B.; Shi, Z.; Wang, C. How Human-like Behavior of Service Robot Affects Social Distance: A Mediation Model and Cross-Cultural Comparison. Behav. Sci. 2022, 12, 205. [Google Scholar] [CrossRef] [PubMed]
- Müller, B.; Reinhardt, J.; Strickland, M.T. NEUROGEN: Using Genetic Algorithms to Train Networks. In Neural Networks: An Introduction; Springer: Berlin/Heidelberg, Germany, 1995; pp. 303–306. [Google Scholar] [CrossRef]
- Ledvina, B.; Eddinger, Z.; Detwiler, B.; Polatkan, S.P. Detecting Unwanted Location Trackers; Technical Report, Internet-Draft Draft-Detecting-Unwanted-Location-Trackers-00; Internet Engineering Task Force: Fremont, CA, USA, 2023; Available online: https://datatracker.ietf.org/doc/draft-detecting-unwanted-location-trackers/01/ (accessed on 11 December 2023).
- Read, R.; Belpaeme, T. How to use non-linguistic utterances to convey emotion in child-robot interaction. In Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction, Boston, MA, USA, 5–8 March 2012. [Google Scholar] [CrossRef]
- Read, R.G.; Belpaeme, T. Interpreting non-linguistic utterances by robots: Studying the influence of physical appearance. In Proceedings of the 3rd International Workshop on Affective Interaction in Natural Environments, AFFINE ’10, Firenze, Italy, 29 October 2010; pp. 65–70. [Google Scholar] [CrossRef]
- Read, R.; Belpaeme, T. Situational context directs how people affectively interpret robotic non-linguistic utterances. In Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’14, Bielefeld, Germany, 3–6 March 2014; pp. 41–48. [Google Scholar] [CrossRef]
- Latupeirissa, A.B.; Frid, E.; Bresin, R. Sonic characteristics of robots in films. In Proceedings of the Sound and Music Computing Conference (SMC), Malaga, Spain, 28–31 May 2019; pp. 1–6. [Google Scholar]
- Khota, A.; Cooper, E.K.; Yan, Y.; Kovács, M. Modelling emotional valence and arousal of non-linguistic utterances for sound design support. In Proceedings of the 9th International Conference on Kansei Engineering and Emotion Research, KEER2022, Proceedings, Barcelona, Spain, 6–8 September 2022. [Google Scholar]
- Korcsok, B.; Farago, T.; Ferdinandy, B.; Miklosi, A.; Korondi, P.; Gacsi, M. Artificial sounds following biological rules: A novel approach for non-verbal communication in HRI. Sci. Rep. 2020, 10, 7080. [Google Scholar] [CrossRef]
- Komatsu, T. Toward making humans empathize with artificial agents by means of subtle expressions. In Proceedings of the First International Conference on Affective Computing and Intelligent Interaction, ACII’05, Beijing, China, 22–24 October 2005; pp. 458–465. [Google Scholar] [CrossRef]
- Blattner, M.M.; Sumikawa, D.A.; Greenberg, R.M. Earcons and icons: Their structure and common design principles. Hum.-Comput. Interact. 1989, 4, 11–44. [Google Scholar] [CrossRef]
- Komatsu, T.; Kobayashi, K.; Yamada, S.; Funakoshi, K.; Nakano, M. Can users live with overconfident or unconfident systems? A comparison of artificial subtle expressions with human-like expression. In Proceedings of the CHI ’12 Extended Abstracts on Human Factors in Computing Systems, CHI EA ’12, Austin, TX, USA, 5–10 May 2012; pp. 1595–1600. [Google Scholar] [CrossRef]
- Savery, R.; Rogel, A.; Weinberg, G. Emotion Musical Prosody for Robotic Groups and Entitativity. In Proceedings of the 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN), Vancouver, BC, Canada, 8–12 August 2021; pp. 440–446. [Google Scholar] [CrossRef]
- Read, R.; Belpaeme, T. Non-linguistic utterances should be used alongside language, rather than on their own or as a replacement. In Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’14, Bielefeld, Germany, 3–6 March 2014; pp. 276–277. [Google Scholar] [CrossRef]
- Juslin, P.; Laukka, P. Communication of Emotions in Vocal Expression and Music Performance: Different Channels, Same Code? Psychol. Bull. 2003, 129, 770–814. [Google Scholar] [CrossRef]
- Jee, E.S.; Kim, C.H.; Park, S.Y.; Lee, K.W. Composition of Musical Sound Expressing an Emotion of Robot Based on Musical Factors. In Proceedings of the RO-MAN 2007, 16th IEEE International Symposium on Robot and Human Interactive Communication, Jeju Island, Republic of Korea, 26–29 August 2007; pp. 637–641. [Google Scholar] [CrossRef]
- Khota, A.; Kimura, A.; Cooper, E. Modelling of Non-Linguistic Utterances for Machine to Human Communication in Dialogue. In Proceedings of the 5th International Symposium on Affective Science and Engineering, ISASE2019, Tokyo, Japan, 17–18 March 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Puckette, M. Pure Data. 1997. Available online: https://puredata.info/ (accessed on 23 April 2024).
- Fang Y, L.J. A Review of Tournament Selection in Genetic Programming. In Proceedings of the Advances in Computation and Intelligence, 2010, Wuhan, China, 22–24 October 2010; pp. 181–192, ISBN 978-3-642-16492-7. [Google Scholar] [CrossRef]
- De Jong, K.A. An Analysis of the Behavior of a Class of Genetic Adaptive Systems. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 1975. AAI7609381. [Google Scholar]
- Mühlenbein, H.; Schlierkamp-Voosen, D. Optimal Interaction of Mutation and Crossover in the Breeder Genetic Algorithm. In Proceedings of the 5th International Conference on Genetic Algorithms, Urbana-Champaign, IL, USA, 17–21 July 1993; p. 648. [Google Scholar]
- Eyben, F.; Schuller, B. openSMILE:): The Munich open-source large-scale multimedia feature extractor. SIGMultimedia Rec. 2015, 6, 4–13. [Google Scholar] [CrossRef]
- Russell, J. A Circumplex Model of Affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Cicchetti, D. Guidelines, Criteria, and Rules of Thumb for Evaluating Normed and Standardized Assessment Instrument in Psychology. Psychol. Assess. 1994, 6, 284–290. [Google Scholar] [CrossRef]
- Koo, T.K.; Li, M.Y. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).