

Precision Diagnosis of Glaucoma with VLLM Ensemble Deep Learning


Abstract
1. Introduction
- The proposal of a novel glaucoma diagnosis method utilizing optic nerve cells. Previous research has utilized retina fundus or ROI images but has not provided enough features. This new research method additionally incorporates the surrounding vasculature and the structural morphology of the optic nerve cells. As it accounts for the structural features of glaucoma, this approach holds significant importance.
- Addressing the data imbalance issue in medical data by using a modified loss function. It is common to use data augmentation or mix multiple datasets to address data imbalance issues in medical data. However, we have mitigated this problem by modifying the loss function. This approach is highly effective when the classification accuracy of certain classes is low due to data imbalance.
- A new ensemble model utilizing the vision large language model (VLLM). Traditional ensemble models typically employ methods such as voting, bagging, and boosting. The method we propose uses the predicted probabilities from four types of input data and their similarity to the actual answers to determine weights for each input data type for the ensemble. By reflecting the unique characteristics most similar to the correct answers among the input data types, this technique is a new ensemble approach that can enhance the final accuracy.
2. Related Work
2.1. Glaucoma Diagnosis Using Fundus Imaging
2.2. Data Imbalance
2.3. Color Mapping of Thermal Camera

3. Proposed Method
3.1. ROI and VROI
3.2. Color Palette
3.3. Loss Function
3.4. Ensemble
| Algorithm 1 Ensemble Weights |
| 1: Inputs: 2: Q: Before Softmax Probability (batch_size, num_queries, ) 3: K: True label (batch_size, num_keys, ) 4: V: Ensemble Score (batch_size, num_keys, ) 5: Output: 6: Binary Classification 7: procedure Ensemble Weights() 8: 9: 10: 11: 12: return 13: end procedure |
4. Experiment Implementation
4.1. Data Argumentation
4.2. Deep Learning Model
4.3. Datasets
4.4. Environment and Metrics
5. Results
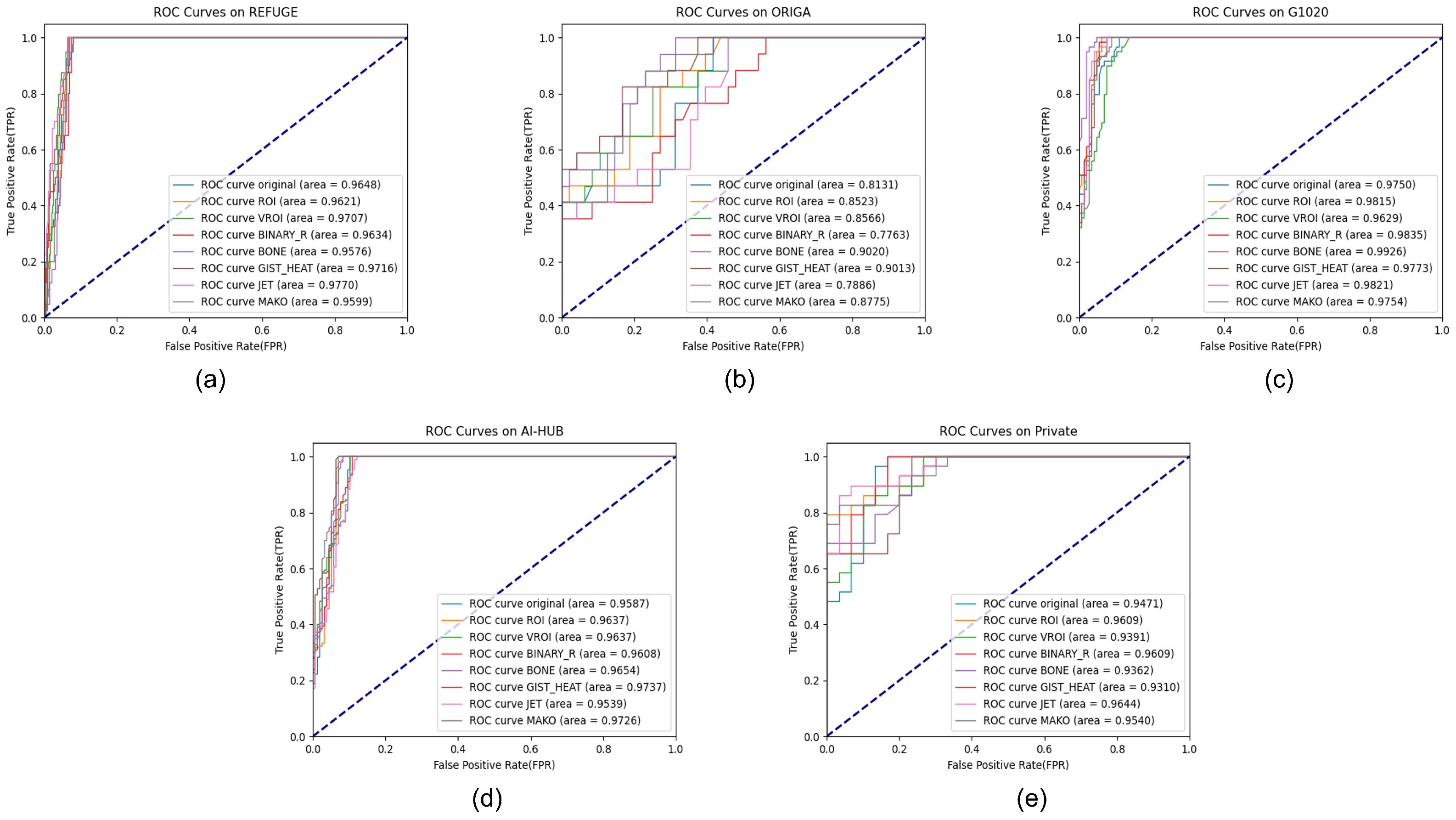
5.1. REFUGE Dataset
5.2. ORIGA Dataset
5.3. G1020 Dataset
5.4. AI-HUB Dataset
5.5. Private Dataset
6. Limitation and Future Work
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ROI | Region of interest |
| VROI | Vascular region of interest |
| OD | Optic disc |
| OC | Optic cup |
| CDR | Cup-disk ratio |
| ISNT | Inferior superior nasal temporal |
| VLLM | Vision Large language model |
| OCT | Optical coherence tomography |
| SE | Squeeze and excitation |
| MBConv | Mobile inverted bottleneck convolution |
| AG | Attention gate |
References
- Yamamoto, T.; Kitazawa, Y. Vascular pathogenesis of normal-tension glaucoma: A possible pathogenetic factor, other than intraocular pressure, of glaucomatous optic neuropathy. Prog. Retin. Eye Res. 1998, 17, 127–143. [Google Scholar] [CrossRef] [PubMed]
- Nath, M.K.; Dandapat, S. Techniques of glaucoma detection from color fundus images: A review. IJ Image Graph. Signal Process. 2012, 4, 44–51. [Google Scholar] [CrossRef]
- Barros, D.M.; Moura, J.C.; Freire, C.R.; Taleb, A.C.; Valentim, R.A.; Morais, P.S. Machine learning applied to retinal image processing for glaucoma detection: Review and perspective. Biomed. Eng. Online 2020, 19, 20. [Google Scholar] [CrossRef] [PubMed]
- Phasuk, S.; Poopresert, P.; Yaemsuk, A.; Suvannachart, P.; Itthipanichpong, R.; Chansangpetch, S.; Manassakorn, A.; Tantisevi, V.; Rojanapongpun, P.; Tantibundhit, C. Automated Glaucoma Screening from Retinal Fundus Image Using Deep Learning. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 904–907. [Google Scholar] [CrossRef]
- Cheng, J.; Yin, F.; Wong, D.W.K.; Tao, D.; Liu, J. Sparse dissimilarity-constrained coding for glaucoma screening. IEEE Trans. Biomed. Eng. 2015, 62, 1395–1403. [Google Scholar] [CrossRef] [PubMed]
- Chakravarty, A.; Sivaswamy, J. Glaucoma classification with a fusion of segmentation and image-based features. In Proceedings of the 2016 IEEE 13th international symposium on biomedical imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; IEEE: New York, NY, USA, 2016; pp. 689–692. [Google Scholar]
- Mohamed, N.A.; Zulkifley, M.A.; Zaki, W.M.D.W.; Hussain, A. An automated glaucoma screening system using cup-to-disc ratio via simple linear iterative clustering superpixel approach. Biomed. Signal Process. Control 2019, 53, 101454. [Google Scholar] [CrossRef]
- Selvathi, D.; Prakash, N.; Gomathi, V.; Hemalakshmi, G. Fundus image classification using wavelet based features in detection of glaucoma. Biomed. Pharmacol. J. 2018, 11, 795–805. [Google Scholar] [CrossRef]
- Maheshwari, S.; Pachori, R.B.; Acharya, U.R. Automated diagnosis of glaucoma using empirical wavelet transform and correntropy features extracted from fundus images. IEEE J. Biomed. Health Inform. 2016, 21, 803–813. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Cheng, J.; Xu, Y.; Zhang, C.; Wong, D.W.K.; Liu, J.; Cao, X. Disc-aware ensemble network for glaucoma screening from fundus image. IEEE Trans. Med. Imaging 2018, 37, 2493–2501. [Google Scholar] [CrossRef] [PubMed]
- Guo, F.; Mai, Y.; Zhao, X.; Duan, X.; Fan, Z.; Zou, B.; Xie, B. Yanbao: A mobile app using the measurement of clinical parameters for glaucoma screening. IEEE Access 2018, 6, 77414–77428. [Google Scholar] [CrossRef]
- Diaz-Pinto, A.; Morales, S.; Naranjo, V.; Köhler, T.; Mossi, J.M.; Navea, A. CNNs for automatic glaucoma assessment using fundus images: An extensive validation. Biomed. Eng. Online 2019, 18, 29. [Google Scholar] [CrossRef]
- Li, A.; Cheng, J.; Wong, D.W.K.; Liu, J. Integrating holistic and local deep features for glaucoma classification. In Proceedings of the 2016 38th annual international conference of the IEEE engineering in medicine and biology society (EMBC), Orlando, FL, USA, 16–20 August 2016; IEEE: New York, NY, USA, 2016; pp. 1328–1331. [Google Scholar]
- Bock, R.; Meier, J.; Nyúl, L.G.; Hornegger, J.; Michelson, G. Glaucoma risk index: Automated glaucoma detection from color fundus images. Med. Image Anal. 2010, 14, 471–481. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, M.M.R.; Faust, O. Automated glaucoma detection using hybrid feature extraction in retinal fundus images. J. Mech. Med. Biol. 2013, 13, 1350011. [Google Scholar] [CrossRef]
- Al-Bander, B.; Al-Nuaimy, W.; Al-Taee, M.A.; Zheng, Y. Automated glaucoma diagnosis using deep learning approach. In Proceedings of the 2017 14th International Multi-Conference on Systems, Signals & Devices (SSD), Marrakech, Morocco, 28–31 March 2017; IEEE: New York, NY, USA, 2017; pp. 207–210. [Google Scholar]
- Christopher, M.; Belghith, A.; Bowd, C.; Proudfoot, J.A.; Goldbaum, M.H.; Weinreb, R.N.; Girkin, C.A.; Liebmann, J.M.; Zangwill, L.M. Performance of deep learning architectures and transfer learning for detecting glaucomatous optic neuropathy in fundus photographs. Sci. Rep. 2018, 8, 16685. [Google Scholar] [CrossRef] [PubMed]
- Gómez-Valverde, J.J.; Antón, A.; Fatti, G.; Liefers, B.; Herranz, A.; Santos, A.; Sánchez, C.I.; Ledesma-Carbayo, M.J. Automatic glaucoma classification using color fundus images based on convolutional neural networks and transfer learning. Biomed. Opt. Express 2019, 10, 892–913. [Google Scholar] [CrossRef]
- Chaudhary, P.K.; Pachori, R.B. Automatic diagnosis of glaucoma using two-dimensional Fourier-Bessel series expansion based empirical wavelet transform. Biomed. Signal Process. Control 2021, 64, 102237. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: New York, NY, USA, 2008; pp. 1322–1328. [Google Scholar]
- Mukherjee, M.; Khushi, M. SMOTE-ENC: A novel SMOTE-based method to generate synthetic data for nominal and continuous features. Appl. Syst. Innov. 2021, 4, 18. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V.; Krasser, S. SVMs modeling for highly imbalanced classification. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2008, 39, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Siringoringo, R. Klasifikasi data tidak Seimbang menggunakan algoritma SMOTE dan k-nearest neighbor. J. Inf. Syst. Dev. (ISD) 2018, 3, 1. [Google Scholar]
- Sundin, P. Intuitive Colorization of Temperature in Thermal Cameras. KTH, School of Engineering Sciences (SCI), Applied Physics. 2015. Available online: https://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-162233 (accessed on 22 May 2024).
- Olalia, R.L., Jr.; Olalia, J.A.; Carse, M.G.F. Evaluating infrared thermal image’s color palettes in hot tropical area. J. Comput. Commun. 2021, 9, 37–49. [Google Scholar]
- ATN Corp. 1995–2024. Available online: https://www.atncorp.com/blog/black-and-white-thermal-imaging-vs-color-palettes-in-heat-vision-cameras (accessed on 22 May 2024).
- DRIVE. DRIVE 2012–2024. Available online: https://drive.grand-challenge.org/ (accessed on 22 May 2024).
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. IterNet: Retinal Image Segmentation Utilizing Structural Redundancy in Vessel Networks. arXiv 2019, arXiv:1912.05763. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research. 2021; Volume 139, pp. 10096–10106. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Orlando, J.I.; Fu, H.; Breda, J.B.; Van Keer, K.; Bathula, D.R.; Diaz-Pinto, A.; Fang, R.; Heng, P.A.; Kim, J.; Lee, J.; et al. Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med. Image Anal. 2020, 59, 101570. [Google Scholar] [CrossRef]
- Zhang, Z.; Yin, F.S.; Liu, J.; Wong, W.K.; Tan, N.M.; Lee, B.H.; Cheng, J.; Wong, T.Y. Origa-light: An online retinal fundus image database for glaucoma analysis and research. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; IEEE: New York, NY, USA, 2010; pp. 3065–3068. [Google Scholar]
- Bajwa, M.N.; Singh, G.A.P.; Neumeier, W.; Malik, M.I.; Dengel, A.; Ahmed, S. G1020: A benchmark retinal fundus image dataset for computer-aided glaucoma detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–7. [Google Scholar]
- Agrawal, V.; Kori, A.; Alex, V.; Krishnamurthi, G. Enhanced optic disk and cup segmentation with glaucoma screening from fundus images using position encoded CNNs. arXiv 2018, arXiv:1809.05216. [Google Scholar]
- Sreng, S.; Maneerat, N.; Hamamoto, K.; Win, K.Y. Deep learning for optic disc segmentation and glaucoma diagnosis on retinal images. Appl. Sci. 2020, 10, 4916. [Google Scholar] [CrossRef]
- Chen, X.; Xu, Y.; Wong, D.W.K.; Wong, T.Y.; Liu, J. Glaucoma detection based on deep convolutional neural network. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 715–718. [Google Scholar]
- Saxena, A.; Vyas, A.; Parashar, L.; Singh, U. A glaucoma detection using convolutional neural network. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; IEEE: New York, NY, USA, 2020; pp. 815–820. [Google Scholar]
- Bajwa, M.N.; Malik, M.I.; Siddiqui, S.A.; Dengel, A.; Shafait, F.; Neumeier, W.; Ahmed, S. Two-stage framework for optic disc localization and glaucoma classification in retinal fundus images using deep learning. BMC Med. Inform. Decis. Mak. 2019, 19, 136. [Google Scholar]
- Ajitha, S.; Akkara, J.D.; Judy, M. Identification of glaucoma from fundus images using deep learning techniques. Indian J. Ophthalmol. 2021, 69, 2702–2709. [Google Scholar] [PubMed]
- Aziz-ur-Rehman; Taj, I.A.; Sajid, M.; Karimov, K.S. An ensemble framework based on Deep CNNs architecture for glaucoma classification using fundus photography. Math. Biosci. Eng. 2021, 18, 5321. Available online: https://link.gale.com/apps/doc/A686823558/AONE?u=anon~7c0fcd94&sid=googleScholar&xid=9729d182 (accessed on 25 May 2024). [CrossRef] [PubMed]
- Fan, R.; Alipour, K.; Bowd, C.; Christopher, M.; Brye, N.; Proudfoot, J.A.; Goldbaum, M.H.; Belghith, A.; Girkin, C.A.; Fazio, M.A.; et al. Detecting glaucoma from fundus photographs using deep learning without convolutions: Transformer for improved generalization. Ophthalmol. Sci. 2023, 3, 100233. [Google Scholar] [CrossRef]
- Shoukat, A.; Akbar, S.; Hassan, S.A.; Iqbal, S.; Mehmood, A.; Ilyas, Q.M. Automatic Diagnosis of Glaucoma from Retinal Images Using Deep Learning Approach. Diagnostics 2023, 13, 1738. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Healthy (Normal) | Glaucoma (Abnormal) | Resolution |
|---|---|---|---|
| REFUGE | 1440 | 160 | 2124 × 2056 (train), 1634 × 1634 (test) |
| ORIGA | 482 | 165 | 3072 × 2048 |
| G1020 | 625 | 296 | 3004 × 2423 |
| AI-HUB 1 | 1566 | 1806 | 2796 × 2848 (Healthy), 1964 × 2000 (Glaucoma) |
| Private 2 | 299 | 284 | 1270 × 793 |
| Image | Confusion Matrix | Accuracy | Sensitivity | Specificity | Precision | |
|---|---|---|---|---|---|---|
| RAW | 33 | 7 | 0.9725 | 0.8250 | 0.9889 | 0.8919 |
| 4 | 356 | |||||
| ROI | 31 | 9 | 0.9575 | 0.7750 | 0.9778 | 0.7949 |
| 8 | 352 | |||||
| VROI | 34 | 6 | 0.9600 | 0.8500 | 0.9722 | 0.7727 |
| 10 | 350 | |||||
| COLORMAP (BINARY_R) | 32 | 8 | 0.9750 | 0.8000 | 0.9944 | 0.9412 |
| 2 | 358 | |||||
| COLORMAP (BONE) | 33 | 7 | 0.9675 | 0.8250 | 0.9833 | 0.8462 |
| 6 | 354 | |||||
| COLORMAP (GIST_HEAT) | 30 | 10 | 0.9575 | 0.7500 | 0.9806 | 0.8108 |
| 7 | 353 | |||||
| COLORMAP (JET) | 35 | 5 | 0.9775 | 0.8750 | 0.9889 | 0.8974 |
| 4 | 356 | |||||
| COLORMAP (MAKO) | 25 | 15 | 0.9625 | 0.6250 | 1.0000 | 1.0000 |
| 0 | 360 | |||||
| Ensemble | 36 | 4 | 0.9875 | 0.9000 | 0.9972 | 0.9730 |
| 1 | 359 | |||||
| Image | Confusion Matrix | Accuracy | Sensitivity | Specificity | Precision | |
|---|---|---|---|---|---|---|
| RAW | 8 | 9 | 0.7231 | 0.4706 | 0.8125 | 0.4706 |
| 9 | 39 | |||||
| ROI | 9 | 8 | 0.7846 | 0.5294 | 0.8750 | 0.6000 |
| 6 | 42 | |||||
| VROI | 7 | 10 | 0.7231 | 0.4118 | 0.8333 | 0.4667 |
| 8 | 40 | |||||
| COLORMAP (BINARY_R) | 6 | 11 | 0.6462 | 0.3529 | 0.7500 | 0.3333 |
| 12 | 36 | |||||
| COLORMAP (BONE) | 12 | 5 | 0.8000 | 0.7059 | 0.8333 | 0.6000 |
| 8 | 40 | |||||
| COLORMAP (GIST_HEAT) | 13 | 4 | 0.8030 | 0.7647 | 0.8163 | 0.5909 |
| 9 | 40 | |||||
| COLORMAP (JET_MPL) | 9 | 8 | 0.7231 | 0.5294 | 0.7917 | 0.4737 |
| 10 | 38 | |||||
| COLORMAP (MAKO) | 8 | 9 | 0.6923 | 0.4706 | 0.7708 | 0.4211 |
| 11 | 37 | |||||
| Ensemble | 13 | 4 | 0.8308 | 0.7647 | 0.8542 | 0.6500 |
| 7 | 41 | |||||
| Image | Confusion Matrix | Accuracy | Sensitivity | Specificity | Precision | |
|---|---|---|---|---|---|---|
| RAW | 52 | 7 | 0.9461 | 0.8814 | 0.9724 | 0.9286 |
| 4 | 141 | |||||
| ROI | 51 | 8 | 0.9314 | 0.8644 | 0.9586 | 0.8947 |
| 6 | 139 | |||||
| VROI | 54 | 5 | 0.9265 | 0.9153 | 0.9310 | 0.8438 |
| 10 | 135 | |||||
| COLORMAP (BINARY_R) | 54 | 5 | 0.9608 | 0.9153 | 0.9793 | 0.9474 |
| 3 | 142 | |||||
| COLORMAP (BONE) | 57 | 2 | 0.9755 | 0.9661 | 0.9793 | 0.9500 |
| 3 | 142 | |||||
| COLORMAP (GIST_HEAT) | 50 | 9 | 0.9265 | 0.8475 | 0.9586 | 0.8929 |
| 6 | 139 | |||||
| COLORMAP (JET_MPL) | 56 | 3 | 0.9608 | 0.9492 | 0.9655 | 0.9180 |
| 5 | 140 | |||||
| COLORMAP (MAKO) | 55 | 4 | 0.9657 | 0.9322 | 0.9793 | 0.9483 |
| 3 | 142 | |||||
| Ensemble | 58 | 1 | 0.9853 | 0.9831 | 0.9862 | 0.9667 |
| 2 | 143 | |||||
| Image | Confusion Matrix | Accuracy | Sensitivity | Specificity | Precision | |
|---|---|---|---|---|---|---|
| RAW | 170 | 10 | 0.9405 | 0.9444 | 0.9359 | 0.9444 |
| 10 | 146 | |||||
| ROI | 173 | 7 | 0.9435 | 0.9611 | 0.9231 | 0.9351 |
| 12 | 144 | |||||
| VROI | 169 | 11 | 0.9345 | 0.9389 | 0.9295 | 0.9389 |
| 11 | 145 | |||||
| COLORMAP (BINARY_R) | 172 | 8 | 0.9554 | 0.9556 | 0.9551 | 0.9609 |
| 7 | 149 | |||||
| COLORMAP (BONE) | 170 | 10 | 0.9464 | 0.9444 | 0.9487 | 0.9551 |
| 8 | 148 | |||||
| COLORMAP (GIST_HEAT) | 176 | 4 | 0.9613 | 0.9778 | 0.9423 | 0.9514 |
| 9 | 147 | |||||
| COLORMAP (JET_MPL) | 168 | 12 | 0.9375 | 0.9333 | 0.9423 | 0.9492 |
| 9 | 147 | |||||
| COLORMAP (MAKO) | 176 | 4 | 0.9702 | 0.9778 | 0.9615 | 0.9670 |
| 6 | 150 | |||||
| Ensemble | 175 | 5 | 0.9702 | 0.9722 | 0.9679 | 0.9722 |
| 5 | 151 | |||||
| Image | Confusion Matrix | Accuracy | Sensitivity | Specificity | Precision | |
|---|---|---|---|---|---|---|
| RAW | 26 | 3 | 0.8305 | 0.7879 | 0.8846 | 0.8966 |
| 7 | 23 | |||||
| ROI | 27 | 2 | 0.8644 | 0.8182 | 0.9231 | 0.9310 |
| 6 | 24 | |||||
| VROI | 25 | 4 | 0.7797 | 0.7353 | 0.8400 | 0.8621 |
| 9 | 21 | |||||
| COLORMAP (BINARY_R) | 27 | 2 | 0.8475 | 0.7941 | 0.9200 | 0.9310 |
| 7 | 23 | |||||
| COLORMAP (BONE) | 27 | 2 | 0.8475 | 0.7941 | 0.9200 | 0.9310 |
| 7 | 23 | |||||
| COLORMAP (GIST_HEAT) | 26 | 3 | 0.8136 | 0.7647 | 0.8800 | 0.8966 |
| 8 | 22 | |||||
| COLORMAP (JET) | 26 | 3 | 0.8983 | 0.8966 | 0.9000 | 0.8966 |
| 3 | 27 | |||||
| COLORMAP (MAKO) | 26 | 3 | 0.8136 | 0.7647 | 0.8800 | 0.8966 |
| 8 | 22 | |||||
| Ensemble | 27 | 2 | 0.9322 | 0.9310 | 0.9333 | 0.9310 |
| 2 | 28 | |||||
| Author | Method | Database | Performance |
|---|---|---|---|
| VRT [33] | custom CNN | REFUGE | AUC: 0.9885 |
| SDSAIRC [33] | ResNet-50 | REFUGE | AUC: 0.9817 |
| CUHKMED [33] | - | REFUGE | AUC: 0.9644 |
| NKSG [33] | SENet | REFUGE | AUC: 0.9587 |
| Mammoth [33] | ResNet18, CatGAN | REFUGE | AUC: 0.9555 |
Vismay et al. [36] | DenseNet201, ResNet18 ResNet18 | REFUGE DRISHTI-GS1 | Specificity: 0.75 AUC: 0.856, Sensitivity: 0.85 |
| SRENG et al. [37] | Pretrained CNN SVM | REFUGE REFUGE | ACC: 0.9559 AUC: 0.9510 |
| CHEN et al. [38] | 6 layers CNN | ORIGA, SCES | AUC: 0.831 |
| LI et al. [13] | VGG CNN | ORIGA | AUC: 0.8384 |
| Saxena et al. [39] | CNN | ORIGA, SCES | AUC: 0.822 |
| BAJWA et al. [40] | CNN | ORIGA | ACC: 0.7967 AUC: 0.8487 |
| Ajitha et al. [41] | CNN | HRF, ORIGA, DRISHTI-GS1 | ACC: 93.86 |
| Rehman et al. [42] | Custom CNN | ACRIMA, ORIGA, RIM-ONE | ACC: 99.5 |
| Chaudhary et al. [19] | Ensemble ResNet | RIM-ONE, ORIGA, DRISHTI-GS1 | ACC: 0.91 AUC: 83.3 |
| Fan et al. [43] | CNN | ORIGA | ACC: 0.55 |
| Ayesha et al. [44] | ResNet50 | G1020 | ACC: 0.9848 AUC: 0.97 |
| ORIGA | ACC: 0.9259, Sensitivity: 0.9839 | ||
| Proposed | EfficientNetV2 | REFUGE | ACC: 0.9875 AUC: 0.9880 Sensitivity: 0.9 |
| ORIGA | ACC: 0.8308 AUC: 0.8452 Sensitivity: 0.7647 | ||
| G1020 | ACC: 0.9853 AUC: 0.9846 Sensitivity: 0.9831 | ||
| AI-HUB | ACC: 0.9702 AUC: 0.9759 Sensitivity: 0.9722 | ||
| Private | ACC: 0.9322 AUC: 0.9827 Sensitivity: 0.9310 |
| Database | Cross Entropy | Focal Loss |
|---|---|---|
| REFUGE | ACC: 0.9775, Sensitivity: 0.7500 | ACC: 0.9875, Sensitivity: 0.9000 |
| ORIGA | ACC: 0.7423, Sensitivity: 0.6042 | ACC: 0.8308, Sensitivity: 0.7647 |
| G1020 | ACC: 0.9784, Sensitivity: 0.8644 | ACC: 0.9853, Sensitivity: 0.9831 |
| AI-HUB | ACC: 0.9554, Sensitivity: 0.9356 | ACC: 0.9702, Sensitivity: 0.9722 |
| Private | ACC: 0.8644, Sensitivity: 0.8042 | ACC: 0.9322, Sensitivity: 0.9310 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Kim, B.; Kang, J.; Eom, D.-S. Precision Diagnosis of Glaucoma with VLLM Ensemble Deep Learning. Appl. Sci. 2024, 14, 4588. https://doi.org/10.3390/app14114588
Wang S, Kim B, Kang J, Eom D-S. Precision Diagnosis of Glaucoma with VLLM Ensemble Deep Learning. Applied Sciences. 2024; 14(11):4588. https://doi.org/10.3390/app14114588
Chicago/Turabian StyleWang, Soohyun, Byoungkug Kim, Jiheon Kang, and Doo-Seop Eom. 2024. "Precision Diagnosis of Glaucoma with VLLM Ensemble Deep Learning" Applied Sciences 14, no. 11: 4588. https://doi.org/10.3390/app14114588
APA StyleWang, S., Kim, B., Kang, J., & Eom, D.-S. (2024). Precision Diagnosis of Glaucoma with VLLM Ensemble Deep Learning. Applied Sciences, 14(11), 4588. https://doi.org/10.3390/app14114588