Abstract
Falls are a major risk factor for older adults, increasing morbidity and healthcare costs. Video-based fall-detection systems offer crucial real-time monitoring and assistance. Yet, their deployment faces challenges such as maintaining privacy, reducing false alarms, and providing understandable outputs for healthcare providers. This paper introduces an innovative automated fall-detection framework that includes a Gaussian blur module for privacy preservation, an OpenPose module for precise pose estimation, a short-time Fourier transform (STFT) module to capture frames with significant motion selectively, and a computationally efficient one-dimensional convolutional neural network (1D-CNN) classification module designed to classify these frames. Additionally, integrating a gradient-weighted class activation mapping (GradCAM) module enhances the system’s explainability by visually highlighting the movement of the key points, resulting in classification decisions. Modular flexibility in our system allows customization to meet specific privacy and monitoring needs, enabling the activation or deactivation of modules according to the operational requirements of different healthcare settings. This combination of STFT and 1D-CNN ensures fast and efficient processing, which is essential in healthcare environments where real-time response and accuracy are vital. We validated our approach across multiple datasets, including the Multiple Cameras Fall Dataset (MCFD), the UR fall dataset, and the NTU RGB+D Dataset, which demonstrates high accuracy in detecting falls and provides the interpretability of results.
1. Introduction
Falls pose a significant risk to the elderly, leading to hospitalizations, increased morbidity, and substantial healthcare expenses. According to the World Health Organization (WHO), falls are the second leading cause of accidental or unintentional injury deaths worldwide, with adults over 65 being the most vulnerable group [1]. The statistics are alarming: more than 37.3 million falls requiring medical attention occur annually, and this number is expected to rise with the global increase in the elderly population [2]. Early recognition and timely intervention are crucial in mitigating the consequences of falls, prompting extensive research and development efforts in fall-detection systems [3].
The research community has explored various approaches to automate fall detection, aiming to provide real-time assistance and enable prompt medical interventions. Wearable sensors, such as accelerometers and gyroscopes, have been extensively utilized [4]. These sensors capture movement patterns and acceleration changes associated with falls. Radar-based systems have also been employed to detect falls using Doppler-based signal-processing techniques [5]. These systems offer privacy preservation advantages since they do not rely on visual information. However, challenges such as the bulkiness of wearable devices, the need for regular recharging, and limitations in distinguishing falls from other activities must be addressed for widespread adoption [6].
Video-based fall-detection algorithms have gained significant attention due to their potential for real-time assistance and comprehensive monitoring capabilities. Using video datasets allows one to capture detailed spatiotemporal information and enables the development of advanced machine learning models [7]. Recent research has shown promising results in using video-based approaches, including deep-learning-based methods [8] and ensemble learning techniques [9], to improve accuracy and robustness in fall detection. However, researchers must address several challenges to ensure video-based fall-detection systems’ widespread acceptance and effectiveness.
Privacy preservation is critical when working with video data as they often contain sensitive information about individuals [10]. Data protection regulations, such as the General Data Protection Regulation (GDPR), impose strict requirements for collecting, storing, and processing personal data [11]. Ensuring privacy while maintaining the effectiveness of fall-detection algorithms is challenging. Integrating privacy-preserving techniques, such as video obfuscation or blurring, becomes essential to balance privacy and fall-detection accuracy [12].
Another drawback of traditional machine learning models is their lack of transparency, operating as “black boxes” where the decision-making process is not easily interpretable [13]. This lack of interpretability can be a significant challenge, particularly in medical applications such as fall detection, where healthcare professionals need to understand the reasoning behind the detection outcomes to trust the system [14]. Healthcare professionals must have insight into how the algorithm arrives at its decisions in healthcare settings as this helps them validate and understand the results. The explainability of fall-detection algorithms is essential for building trust, ensuring patient safety, and facilitating effective collaboration between the algorithm and healthcare providers.
Existing fall-detection solutions face several challenges. While direct and personal, wearable sensors often suffer from discomfort, leading to non-compliance, limited battery life requiring frequent recharges, and the inability to accurately differentiate between actual falls and daily activities like sitting. Although video-based systems offer comprehensive monitoring, they raise significant privacy concerns and are subject to environmental factors such as poor lighting and obstructions, which can hinder their effectiveness. Additionally, these systems and other technologies, such as radar or acoustic sensors, can be costly and complex, posing barriers to widespread adoption. These limitations underscore the need for developing more adaptable, efficient, and privacy-conscious fall-detection systems.
In addressing the challenges associated with video-based fall detection, our proposed approach integrates advanced machine learning techniques adapted to the specific needs of medical healthcare. This comprehensive architecture comprises several modular components: a Gaussian module for video obfuscation, the OpenPose library for pose estimation, a short-time Fourier transform (STFT) module for capturing motion-induced frames and generating temporal dynamics spectrograms, a classification module utilizing convolutional and dense layers, and a gradient-weighted class activation mapping (GradCAM) module for providing visual explanations of decision-making processes.
The application of STFT in fall detection, particularly within video datasets, is relatively novel despite its extensive use in audio and speech analysis [15,16]. STFT’s ability to analyze the frequency content of signals across short time intervals allows for the detection of temporal changes, offering valuable insights into the dynamics and movement patterns associated with falls. Integrating STFT enhances the understanding of fall events. It is a crucial tool for healthcare professionals, helping them identify and analyze patterns and behaviors that lead to falls and improving patient care.
Furthermore, our system incorporates the GradCAM technique, renowned for its explainability capabilities within computer vision. GradCAM effectively highlights the areas within an input image that significantly influence the decisions made by the neural network. By deploying GradCAM, we provide visual explanations that enhance the transparency of the fall-detection process, thereby allowing healthcare professionals to validate and trust the system’s accuracy and reliability in detecting fall events.
By integrating STFT and GradCAM, our approach merges the benefits of capturing detailed temporal dynamics and visualizing influential key points during falls. This dual integration facilitates a deeper understanding of the dynamics surrounding fall incidents and enables the precise analysis of crucial moments leading to falls. Additionally, the visual explanations provided by GradCAM significantly enhance the interpretability of the model’s decisions, fostering trust and collaboration between healthcare providers and the fall-detection system.
Our system’s modular design allows customized configurations to meet diverse operational needs. For instance, in environments where privacy is not a primary concern, the Gaussian module can be deactivated to provide unobstructed video analysis. Conversely, in settings requiring continuous and comprehensive monitoring, the STFT module can be bypassed to allow uninterrupted data analysis. This flexibility ensures the system can be optimized for specific scenarios, enhancing its applicability and effectiveness.
Key contributions of our approach include:
- STFT-Based Motion Analysis: We introduce an innovative STFT application for fall detection that selectively processes only frames exhibiting significant motion. This targeted approach reduces the incidence of false alarms, a common challenge in continuous monitoring scenarios, thereby enhancing system reliability and efficiency. The system optimizes processing power and storage by focusing computational resources on moments of potential falls, making it ideal for extended use in healthcare facilities.
- Explanatory Visualizations with GradCAM: We employ GradCAM to enhance the transparency and interpretability of our machine learning model. This technique provides visual explanations by highlighting the critical regions within the data that influence the detection outcomes. Such visual insights are invaluable for medical professionals as they provide a clear basis for understanding and trusting the model’s decisions, thereby fostering a deeper integration of AI tools in routine clinical practices.
- Modular System Flexibility: Our system’s architecture is designed for modular flexibility, allowing for customization according to specific operational requirements and privacy concerns. Facilities can deactivate the Gaussian module where privacy is less concerned, offering unfiltered visual monitoring. Alternatively, in environments where constant, comprehensive data collection is required, the STFT module can be bypassed to maintain continuous monitoring without preselecting motion-induced frames. This adaptability ensures that the system can be adapted to the specific needs of different healthcare environments, enhancing its practicality and applicability across various clinical and care settings.
These contributions ensure that our fall-detection system meets the requirements of healthcare applications regarding accuracy, efficiency, and explainability.
The rest of the paper is organized as follows: Section 2 provides some of the related work on automated fall-detection algorithms. Section 3 discusses the preliminaries for a basic understanding of the libraries and models. The proposed architecture is explained in Section 4. The performance analysis and experimental results are demonstrated and discussed in Section 5. Finally, Section 6 concludes the work and discusses the future aspects of the proposed study.
2. Related Work
2.1. Fall Detection with Wearable and Body Sensors
Fall detection has witnessed the development of various techniques that utilize wearable and body sensors to detect falls accurately. For example, the authors of [17] proposed an advanced version of Long Short-Term Memory (LSTM) called Cerebral LSTM, demonstrating improved training and testing accuracy, particularly in time-series prediction. By collecting sensor data from the watch included with Microcontroller Units (MCUs) and utilizing the MobiFall dataset for training and testing validation, they achieved a fall-detection accuracy of approximately 98%.
The authors of [18] presented a low-complexity deep learning model for fall detection, implemented on a microcontroller with limited memory resources. The microcontroller was deployed within a low-power, wide-area network with long-range (LoRa) communication technology. A comparative analysis of various lightweight neural networks and conventional machine learning algorithms demonstrated that the convolutional neural network (CNN) exhibited the highest accuracy of 95.55%.
The authors of [19] presented mmFall, a real-time fall-detection system that utilizes millimeter-wave signals and accomplishes remarkable accuracy while maintaining a low computational complexity. They proposed a spatial–temporal processing method for extracting signal variation related to human activity. They used various data augmentation techniques, such as shifting and interpolating the signals to improve the efficacy and robustness of the system. In addition, they present a lightweight convolutional neural network architecture designed specifically for fall detection in real time. The authors demonstrate through extensive experiments that their proposed system obtains a state-of-the-art performance with minimal computational complexity.
The authors of [20] developed the Patch-Transformer Network (PTN). This novel approach integrates convolutional layers for local feature extraction with transformer-encoding layers to capture global dependencies through self-attention mechanisms. This dual-layer architecture allows for a nuanced understanding of spatiotemporal features, crucial for detecting the complex dynamics of falls. The PTN has been tested on well-known public datasets such as SisFall and UnMib SHAR, achieving exceptionally high accuracies of 99.86% and 99.14%, respectively. This demonstrates the network’s capability to efficiently process sensor data with high precision while maintaining low computational demands, making it ideal for real-time applications.
The authors of [21] introduced an enhanced ensemble deep neural network approach tailored for elderly fall detection using wearable sensors. Their framework combines the strengths of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to create a robust feature extraction and temporal analysis system. The CNN component is responsible for extracting salient features from accelerometer and gyroscope data, while the RNN component models the temporal dynamics of the falling process. This combination allows for a nuanced differentiation between fall, prefall, and non-fall events, with accuracies reaching 95%, 96%, and 98%, respectively. Their ensemble model, which employs separate neural networks for each event class, provides an adaptive approach that enhances accuracy and processing speed across diverse scenarios.
The authors of [22] conducted a feasibility study on real-time fall detection using wearable sensors and deep learning methods. Their research emphasizes the importance of data segmentation and sensor placement, two critical factors in the performance of fall-detection systems. They explored various deep learning architectures, including convolutional layers combined with LSTM and transformer blocks, to handle different aspects of sensor data analysis. The integration of convolutional features with temporal sequence processing significantly enhanced the model performance, highlighting the potential for sophisticated neural architectures in wearable applications. Their study also investigated optimal sensor placements, finding that sensors positioned on the shank provided the best performance, with an F1 score of 0.97, illustrating the practical implications of sensor positioning on the effectiveness of fall-detection systems.
2.2. Fall Detection Based on Video Datasets
The authors of [23] presented ARFDNet, an efficient activity recognition and fall-detection system. The authors proposed extracting skeleton features from raw RGB videos using a pose-estimation network. These coordinates were then preprocessed and fed into specially designed CNNs followed by GRUs to capture the spatiotemporal dynamics. The GRU outputs were passed to fully connected layers for classification. The proposed model was evaluated on the ADLF and UP fall-detection datasets. The authors achieved an accuracy of 89.05% (prepolling) and 89.64% (post-polling) on the ADLF dataset and 96.7% on the UP fall-detection dataset. These results demonstrated the effectiveness of ARFDNet in accurately recognizing activities and detecting falls.
The authors of [24] proposed a fall-detection approach that leverages human body geometry extracted from video frames. They used pose-estimation techniques to identify the facial image’s head centroid and the body’s center hip, calculating the angle and distance between them. These measurements were employed to construct distinctive image features. The authors trained a two-class Support Vector Machine (SVM) classifier and a temporal convolution network (TCN) on these new feature images, and an LSTM network was also trained on sequences of calculated angles and distances to classify fall and non-fall activities. The experiments were conducted on the Le2i FD and URFD datasets, including a cross-dataset evaluation. The results demonstrated the efficiency and effectiveness of the developed approach in accurately detecting falls.
The authors of [25] proposed a methodology that utilized the PoseNet TensorFlow Lite CNN model for the real-time detection of human key points. They employed LSTM to analyze the extracted key points, which enabled the handling of extended data sequences. The system accurately identified human movement by merging two comprehensive fall-detection datasets for training. The model extracted the positions of 17 joint points in the human body and monitored changes in these positions. Integrating these joint point locations into the LSTM model improved training and inference times. Furthermore, this approach mitigated the impact of light sources and shadows on the model’s performance.
The authors of [26] developed a vision-based fall-detection system focusing on skeletal kinematic features. Their proposed feature descriptor analyzes body geometry and dynamic patterns to distinguish falls from non-fall activities effectively. Using AlphaPose to identify key points on the human skeleton, they calculated additional metrics from segmented body parts, enhancing the spatial representation of movements. Their novel feature descriptor preserves spatiotemporal dynamics, making it highly effective for machine learning models like decision trees and gradient boosting. Evaluated on the UP fall dataset, their method showed an excellent performance, marking a significant advancement in vision-based fall detection.
The authors of [27] introduced a robust, automated vision-based system employing 3D multistream CNNs with an image-fusion technique for fall detection. Their system processes live surveillance footage, identifies fall events in real time, and issues instant alerts. This model’s effectiveness was validated on the Le2i dataset, achieving high metrics across accuracy, sensitivity, specificity, and precision, demonstrating its potential to significantly reduce healthcare and productivity loss costs by preventing fall injury complications.
The authors of [28] proposed a dynamic fall-detection system using a graph-based spatial–temporal convolution and attention network (GSTCAN). This system enhances the robustness and accuracy of fall detection by integrating spatial and temporal contextual relationships among body joints, combined with an attention model to focus on the most informative features. Tested across multiple datasets, their system achieved exceptionally high accuracies, showcasing its efficiency and general applicability in medical technology for fall prevention.
2.3. Explainable and Interpretable Fall Detection
In recent years, there has been a growing interest in developing explainable and interpretable approaches in healthcare for human activity recognition. Several studies have proposed innovative techniques to provide insights into the reasoning behind the fall and enhance the trustworthiness of the models for patients and healthcare professionals.
To provide a reliable method for detecting falls, the authors of [29] proposed a strategy involving placing three sensors on the subject’s body in various locations. The information gathered by these sensors was utilized for training purposes. The UMAFall dataset collected sensor readings and trained five distinct models for each sensor. To ascertain the final output, a majority voting classifier was employed. The authors also incorporated LIME, an explainable AI (XAI) technique, to improve the interpretability of the model’s outputs. The proposed method yielded high accuracies for each sensor model and the majority voting classifier. The addition of LIME enhanced the model’s outputs’ interpretability.
The authors of [30] presented a solution, PRF-PIR, which integrates multimodal sensor fusion with passive and interpretable monitoring for long-term monitoring. The system comprised a software-defined radio (SDR) device and a novel passive infrared (PIR) sensor system. The proposed solution utilized the HIAR model, incorporating a recurrent neural network (RNN) to effectively address the captured data’s temporal dependence. The efficacy of the PRF-PIR system was validated by collecting data on various academic office activities performed by human subjects. The system exhibited its capacity as a monitoring system that is non-invasive, resilient, and precise by attaining a high level of accuracy in both human identification and activity recognition. Furthermore, the findings were corroborated by explainable artificial intelligence (XAI) techniques, which further authenticate the supremacy of sensor fusion compared to single-sensor alternatives. The PRF-PIR system exhibited its ability to function as a monitoring system for intricate human activities that are passive, interpretable, and highly precise.
The authors of [31] explored the integration of CNN-based self-attention models to predict fall events by analyzing balance test scores. Their study utilizes a semi-supervised learning approach that leverages data from ankle-mounted IMU sensors (Analog Devices Inc., Wilmington, MA, USA) to detect high-risk fall moments. This method not only anticipates when a fall is likely to occur but also explains which specific moments and movements are most associated with increased fall risk. By highlighting these critical moments, their approach aids in preventive healthcare strategies, enabling interventions before falls occur, thereby enhancing patient safety and reducing the incidence of fall-related injuries.
The authors of [23] introduced XAI-Fall, an advanced explainable AI system tailored for fall detection using wearable devices. The system strategically places multiple sensors across different body locations to capture a comprehensive dataset of user movements. The integration of LIME within their framework makes the AI’s decisions transparent, allowing caregivers and patients to understand why certain movements may be flagged as potential falls. This transparency is crucial for trust and facilitates targeted interventions based on the system’s feedback, potentially leading to more personalized and effective fall-prevention strategies.
The authors of [32] utilized explainable artificial intelligence combined with wearable sensor technology to perform gait analysis aimed at identifying risks of osteopenia and sarcopenia among the elderly. Their approach employs advanced machine learning algorithms such as XGBoost and Random Forest to analyze the statistical parameters of gait data. The study’s findings illuminate the critical gait characteristics linked to these musculoskeletal conditions, offering potential for early detection and intervention. By understanding which aspects of gait are most predictive of health issues, healthcare providers can develop more effective treatments and preventive measures to manage or mitigate these conditions.
The authors of [27] developed a sophisticated vision-based human-fall-detection system employing 3D multistream CNNs coupled with an innovative image-fusion technique. This system processes video data from surveillance cameras to detect fall events with high accuracy and speed. The utilization of 3D CNNs allows the system to understand and interpret complex movements dynamically, enhancing its ability to distinguish between normal activities and falls. The image-fusion technique improves the system’s robustness against varying lighting conditions and obstructions, ensuring reliable fall detection across different environments. Their method demonstrates significant potential for deployment in settings such as elderly care facilities, where timely fall detection can prevent severe injuries and improve overall patient care.
While most research in explainable fall detection focuses on sensor data, a limited amount of work is conducted on video datasets. This gap highlights the need to explore and develop explainable deep learning approaches leveraging video data for accurate fall detection. Incorporating video datasets can provide additional visual cues and context, potentially enhancing the performance and interpretability of fall-detection systems in real-world scenarios.
3. Preliminaries
3.1. Gaussian Blur
The Gaussian blur is a mathematical operation involving the convolution of an image with a Gaussian function to reduce image noise and ensure privacy protection by obscuring image details [16]. Gaussian filters can be formulated using the Gaussian function, where the variables i and j represent the pixel location’s rows and columns, respectively. The parameter represents the standard deviation, determining the breadth of the Gaussian distribution. The normalization factor ensures a constant area under the Gaussian curve:
The specific degree of smoothing provided by a Gaussian filter is determined by the choice of filter size, denoted by the parameter . The relationship between the degree of smoothing and the value of is straightforward: a higher corresponds to a more extensive Gaussian filter, resulting in a higher level of filtration. Large Gaussian filters can enhance privacy preservation without incurring significant computational costs, thanks to the separability of Gaussian functions. A possible approach to achieving two-dimensional Gaussian convolution involves applying a one-dimensional Gaussian filter to an image and convolving the resulting image with another one-dimensional filter orthogonally to the first. This technique reduces the computational complexity of a 2D Gaussian filter, resulting in a linear relationship with the size of the filter mask rather than a quadratic relationship [33]:
is the output; m and n are the width and height of the kernel, respectively; and is the input that convolves with the Gaussian Kernel. As seen in the equation, we can split the Gaussian kernel into two exponents, thus verifying the separability:
3.2. OpenPose
OpenPose [34] is a real-time multiperson key point detection system capable of estimating the 2D skeletal poses of people in images or videos. The OpenPose pipeline consists of several steps, as demonstrated in Figure 1:
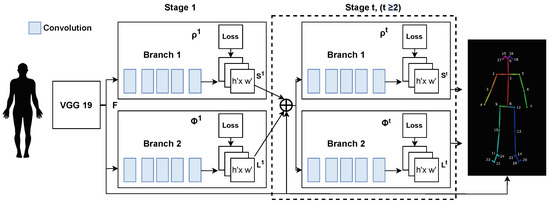
Figure 1.
Schematic diagram of OpenPose network structure [35].
3.2.1. Baseline CNN
The input image is fed into a baseline convolutional neural network (CNN) and extracts the feature maps F from the input image. The first ten layers of the VGG-19 network are employed as the feature extractor.
3.2.2. Multistage CNN
The feature map F is fed into a series of convolutions in a neural network pipeline that generates Part Confidence Maps and Part Affinity Fields.
Confidence maps are graphical representations of 2D heatmaps that indicate the probability of a particular body joint or key point at every pixel location within an image. First, the individual confidence maps are generated, where j represents the body part and k represents the person. Suppose is the ground truth position. Then, the value at location in the confidence map can be defined as:
The spread of the peak is controlled by a parameter .
Part Affinity Fields (PAFs) are vector fields in two dimensions that depict the correlation or association between two body key points. Every vector in the field represents the direction and magnitude of the linkage between a pair of key points. We take an example of a limb belonging to an individual denoted as ’k’ within the input image. We denote the actual locations of anatomical features and along the limb as and , respectively. If a point p is situated on the limb, the quantity denoted by denotes a unit vector that indicates the direction from to . In the case of all other points, the vector is equivalent to a value of zero:
During testing, we check how well the predicted PAF matches the limb that could be formed by joining the detected body parts. To perform this, we take two candidate part locations, and , and measure the confidence of their association by sampling the predicted PAF along the line segment connecting these two points:
where represents the interpolated position of the two body parts and .
3.2.3. Parsing and Pose Estimation
The parsing step involves executing a series of bipartite matchings to establish associations between candidates for different body parts. The methodology uses a greedy algorithm to establish correspondences between features with the highest confidence scores. Subsequently, these correspondences are subjected to iterative refinement until no further matches can be ascertained. The final process to assemble body part candidates into complete body poses for all individuals in the image is called pose estimation. The process involves aggregating interconnected components through Part Affinity Fields with high confidence then validating the resultant postures using part confidence maps.
3.3. Short-Time Fourier Transform (STFT)
Short-time Fourier transform (STFT) [36] is a technique for time–frequency analysis that decomposes a signal into its frequency components over brief time intervals. STFT is based on dividing the signal into overlapping short-time segments and applying Fourier transform to each segment. The resulting time–frequency representation provides information regarding the signal’s frequency components and the temporal variation in those frequency components in spectrograms:
where is the window, is the signal, and represents the phase and magnitude of the signal over time and frequency.
STFT can be applied to velocity components of the extracted key points from video frames along the temporal axis for motion detection. The resulting time–frequency representation can disclose the motion properties. Moving objects, for instance, may generate distinct spectral signatures that can be detected using STFT.
3.4. Convolutional Neural Network (CNN)
Convolutional neural networks (CNNs) represent a specialized type of artificial neural network (ANN) that closely mimics the structure and functionality of the mammalian visual cortex [37]. These networks, particularly 2D-CNNs, have found extensive applications in computer vision tasks, such as image categorization and object recognition, owing to their ability to extract image features hierarchically. However, when it comes to classifying time-series data, 2D-CNNs are not the most suitable choice. In contrast, the effectiveness of 1D-CNNs has been demonstrated in various time-series-related domains, including electrocardiogram (ECG) analysis [38], structural damage identification through vibration analysis [39], and motor fault detection [40]. 1D-CNNs excel in time-series regression and classification tasks by automatically extracting features from one-dimensional time-series data. One notable advantage of 1D-CNNs is their capability to perform feature extraction directly on single-dimensional time-series data. This attribute makes them highly suitable for regression and classification in the time-series domain. Additionally, training one-dimensional convolutional neural networks for time-series regression can benefit from utilizing large labeled datasets of time-series signals without requiring prior feature extraction [41].
The 1D forward propagation (1D-FP) is expressed in each CNN layer as follows [42]:
where is the intermediate output obtained by feeding the input through an activation function . is the neuron output at layer and is the bias.
3.5. Gradient-Weighted Class Activation Mapping (GradCAM)
GradCAM [43] is an enhancement to the conventional class activation map (CAM) and is used to generate visual explanations by highlighting the regions in the input most emphasized when generating the final result. GradCAM uses a gradient score to generate CAMs, as illustrated in the equations below.
The CAM for a specific class c is the weighted sum of activation maps (, , …, ) generated by n convolution filters given by:
In addition, global average pooling is applied to each activation map, which is illustrated as follows:
The following represents a general vector form for CAM:
where is the features map, is the global average pooling, and is the class feature weights.
By substituting the global average pooling output by , the CAM computes the final score as
According to GradCAM, the weights of the classes are determined by the gradients of the last layer in the NN model. By taking the gradient score of the class to feature map , we obtain
Summing both sides of the equation over all pixels (i, j),
We can rearrange the above equation as follows:
Using the gradient flowing from the output class into the activation maps of the final convolutional layer as weight () to class c eliminates the need for retraining the networking [44].
4. Proposed Architecture
As illustrated in Figure 2, the proposed architecture consists of five main modules, each playing a crucial role in the fall-detection system. First, the Gaussian module ensures the protection of individual privacy by applying a video obfuscation technique to the video input. Next, the OpenPose module utilizes the OpenPose network to extract key points from the video. The STFT module serves a dual purpose. It optimizes computational resources and provides insights into the contextual information regarding fall events. This contextual information helps understand the sequence of events and detect any unusual motions or patterns preceding the sudden fall. The extracted frames are then fed into the classification module, which learns and identifies key point patterns associated with falls and non-fall movements. Lastly, the GradCAM module employs convolution layers to generate sequence heat visualization. This visualization aids in understanding the reasoning behind the fall-detection outcomes. It highlights the temporal variation in the key points contributing to the classification decisions. Further details on each module are discussed in the subsequent section.
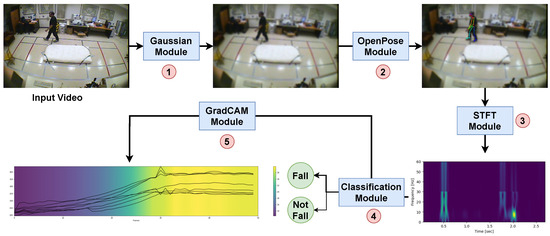
Figure 2.
Overall pipeline of our proposed architecture, demonstrating (1) Gaussian module, (2) OpenPose module, (3) STFT module, (4) classification module, and (5) GradCAM module.
4.1. Gaussian Module
In the Gaussian module, we implemented Gaussian blur, which was discussed in detail in Section 3.1. In addition, we used a large kernel size of (21 × 21), resulting in more significant filtering. The size of the kernel was set with experimentation so that the filtering does not significantly impact the performance of the OpenPose module in extracting the key points. Once the video is obfuscated, we send it to the OpenPose module to extract the key points.
4.2. OpenPose Module
The OpenPose module integrates the OpenPose library, a real-time multiperson key point detection tool. It extracts 25 key points with x and y coordinates. For this study, we utilize only a subset of four key points: the neck, left shoulder, right shoulder, and hip. This selection primarily serves two purposes.
Firstly, these key points demonstrate minimal data loss across various datasets, ensuring robustness in data processing. An example from the MCFD dataset illustrates this particular selection, as shown in Figure 3, where these key points show significantly fewer missing values than others. Similar results have been demonstrated in other datasets as well. This preservation makes the subset not just reliable but a robust choice for training the network and improving model performance.
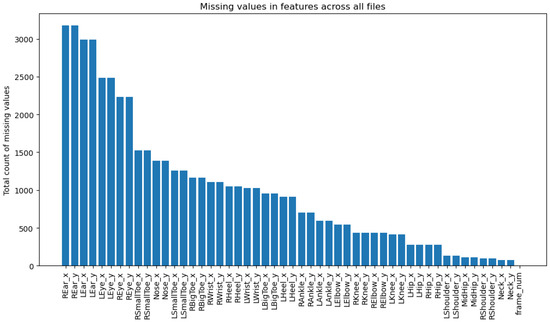
Figure 3.
This figure demonstrates the total count of missing values for each key point from MCFD dataset, with the Y-axis displaying the missing data count and the X-axis listing the key points. The prefixes L and R indicate left and right sides, respectively.
Secondly, by focusing on this subset, the network achieves improved cost-effectiveness and precision due to a substantial reduction in the calculations required. Following the selection of this subset, the velocities of these four key points are computed along the X and Y axes using the formula below:
where represents the velocity at frame i, k denotes the key point, and j is the number of frames over which the velocity is calculated.
Reducing the number of key points from twenty-five to four significantly decreases the amount of data that need to be processed. This streamlined approach enhances the computational efficiency and reduces the processing time required for key point extraction and subsequent analysis. By focusing on the most relevant key points, the system can quickly and accurately detect falls without being bogged down by unnecessary calculations associated with less critical key points.
This optimization is particularly advantageous in real-time applications where rapid response times are essential. For instance, in a healthcare setting where real-time monitoring is crucial, the ability to quickly process and analyze video data can make a significant difference in the timely detection of falls and the provision of immediate assistance. Moreover, the reduced computational load translates to lower power consumption and resource usage, making the system not just efficient but also practical and scalable for widespread deployment.
4.3. STFT Module
The STFT module, a fundamental part of our fall-detection system, demonstrates its precision by providing crucial capabilities for distinguishing between fall and non-fall patterns through careful frame analysis. By calculating the velocities of key points from the OpenPose module, the STFT module transforms these time-based measurements into the frequency domain with utmost accuracy. This transformation is key in revealing the subtle differences between transient, abrupt movements characteristic of falls and more sustained, regular motions associated with normal activities.
The process begins with the segmentation of video data into overlapping frames. This step is vital to ensure that the continuity of motion is preserved, which helps accurately capture events that may lead to falls without missing any sudden movements due to temporal gaps. Following segmentation, each frame is treated with a window function, typically a Hamming window, to reduce spectral leakage and enhance the Fourier transform’s resolution. This windowing is crucial as it helps maintain the integrity of the signal edges, thereby ensuring that the frequency analysis is accurate and reliable.
Subsequently, the STFT is applied to each windowed frame, converting the velocity signals from the time domain to the frequency domain. This conversion allows us to construct a spectrogram that visualizes the intensity and frequency of motion data over time. In the spectrogram, some visible patterns often correspond to vigorous activities, which may indicate a fall or some motion activities. Such visual representation is helpful as it allows for the easy identification of high-motion activities such as falls by highlighting sudden increases in frequency. Conversely, low-motion activity like sleeping or sitting manifests differently in the spectrogram as they do not produce patterns. This visualization helps differentiate falls from low-motion activities and high-motion activities, thus enhancing the fall-detection system’s reliability and accuracy.
Furthermore, the STFT module’s adaptability demonstrates its robustness. By optimizing parameters such as the size and overlap of the window function in the STFT, the module’s sensitivity and specificity can be finely tuned to respond to different types of movements. This adaptability is a key factor in ensuring the module performs accurately across a variety of real-world scenarios, where the nature of movements can vary significantly, providing a sense of reassurance about its performance.
The STFT module strengthens the technical foundation of our fall-detection system and enhances its interpretability and utility. Capturing detailed motion patterns and transforming them into an analyzable format provides critical insights that are used for robust fall detection. When significant motion is detected, the module extracts a sequence of 50 frames that encapsulate the event, which are then forwarded to the classification module to determine whether a fall has occurred. This sequence of operations underscores the module’s integral role in the overall effectiveness and reliability of our fall-detection mechanism.
4.4. Classification Module
After extracting the sequence of frames exhibiting substantial motion from the input videos, the respective sequence comprising a subset of key points is fed into the classification module, aiming to discern the occurrence of a fall event. As depicted in Figure 4, the classification module encompasses various vital components, including the convolution layer, MaxPool layer, Flatten layer, and dense units. The computational pipeline commences with applying the convolution layer, effectively capturing essential spatiotemporal features from the input key points. Subsequently, the MaxPool layer is employed to reduce the dimensionality of the extracted features while preserving crucial information. As a subsequent step, the Flatten layer is introduced to transform the output of the MaxPool layer into a one-dimensional vector representation. Finally, the compressed and structured representation is fed into a fully connected layer comprising dense units to facilitate the detection and identification of instances of fall events. The network structure and parameters of the classification module are presented in Table 1.
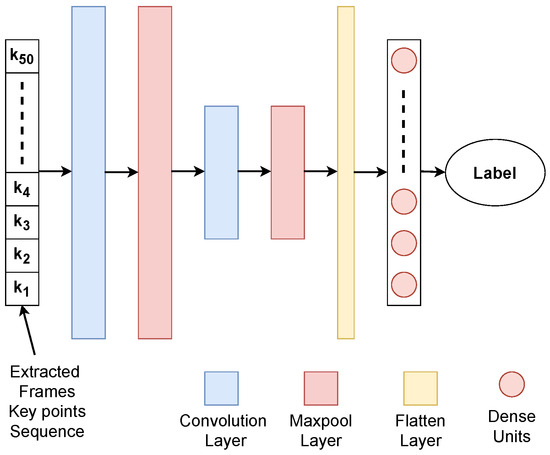
Figure 4.
Detailed architecture of the classification module. The sequence of 50 frames, each containing key point data extracted from the STFT module, serves as the input to the CNN. This sequence is processed through a series of layers, including convolution, MaxPool, Flatten, and dense units, to classify each sequence as ‘Fall’ or ‘Not Fall’.

Table 1.
Classification module network architecture and parameters.
4.5. GradCAM Module
By employing the GradCAM module discussed in Section 3.5, we highlight the key regions within the key points sequence that significantly contribute to the classification decision, enhancing the understanding and trustworthiness of our model’s predictions. GradCAM enables the identification of temporal variations in the sequence most indicative of fall events. The resulting GradCAM heat map effectively provides visual cues, indicating the areas of the sequence with significant variations between fall and not fall events. By visualizing these salient regions, medical professionals gain profound insights into the decision-making process of our model, empowering them to validate the accuracy and reliability of its fall-event-detection capabilities.
5. Experimental Results
5.1. Dataset Description
This study employs multiple datasets to enhance the robustness and applicability of the proposed fall-detection system. Below are descriptions of the datasets used:
- NTU RGB+D Dataset (NTU): This dataset [45] is renowned for its extensive collection of human activities captured through high-resolution videos. Researchers selected a subset of activities specifically relevant to medical conditions, focusing on critical actions for assessing health-related incidents. This subset includes activities such as sneezing/coughing, staggering, falling, headache, chest pain, back pain, neck pain, nausea/vomiting, and fan self, providing a rich resource for analyzing fall-related events.
- Multiple Cameras Fall Dataset (MCFD): Auvinet et al. [46] developed the MCFD, which consists of 192 video recordings captured from 24 different scenarios using eight synchronized cameras with a resolution of 720 × 480. This dataset uniquely includes a wide variety of fall scenarios (22) and activities of daily living (2), such as moving boxes, dressing, and room cleaning, recorded from multiple viewpoints. This diversity aids in simulating more realistic fall situations.
- UR Fall Dataset (URFD): The Computational Modeling Discipline Centre at the University of Rzeszow [47] created the UR fall-detection dataset (URFD), which includes 70 videos—30 depicting falls and 40 showing non-fall activities such as walking, sitting, and squatting. The videos capture performers exhibiting a range of fall-related behaviors, including backward leaning and sudden descents to the ground. The videos are recorded in RGB format with a resolution of 640 × 480.
Each dataset provides unique insights and challenges, offering a comprehensive platform for testing and improving the proposed fall-detection algorithms.
5.2. Evaluation Approach and Metrics
We assess the effectiveness of our classification model through a rigorous evaluation methodology that incorporates k-fold cross-validation and various metrics, including the confusion matrix and classification report. The k-fold cross-validation technique is a crucial part of our methodology as it ensures a robust evaluation of the model’s performance. This methodology divides the dataset into k partitions or folds, enabling multiple training rounds and testing on distinct data subsets. We conduct five-fold cross-validation to assess the model’s performance, deliberately choosing a value of k as five. Each fold is the testing set, while the remaining folds constitute the training set. We iterate this process five times to ensure that each fold is used as the testing set precisely once. Within each iteration of k-fold cross-validation, the model undergoes training on the training set, which encompasses 80 percent of the available data. Subsequently, we evaluate the model on the corresponding testing set to assess its performance on previously unseen data.
We employ metrics such as accuracy, F1 score, sensitivity, and specificity to assess the model’s performance thoroughly.
The accuracy metric evaluates the model’s prediction accuracy, estimating its overall performance, and is computed as
where
- TP (True Positive) is when the predicted and actual output is true.
- FP (False Positive) is when the predicted output is true but the actual output is false.
- TN (True Negative) is when the predicted output is false and the actual output is also false.
- FN (False Negative) is when the predicted output is false but the actual output is true.
The F1 score is a statistical measure that combines precision and recall in a balanced manner, calculated as the harmonic mean of the two metrics. It offers a comprehensive assessment of the model’s performance by simultaneously considering precision and recall, which proves advantageous in evaluating classification models and is given by
and
Sensitivity, also known as recall, measures the proportion of actual positives correctly identified by the model and is computed as
Specificity measures the proportion of actual negatives correctly identified by the model and is computed as
5.3. Performance Analysis for Multiple Cameras Fall Dataset (MCFD)
5.3.1. Result from Gaussian Module
We employed Gaussian blur in the module with an optimally chosen kernel size through experimentation to effectively obfuscate the individual’s identity. The results are demonstrated in Figure 5. The top row displays frames without blurring, while the bottom row shows frames with blurring. This approach ensures that the video remains sufficiently blurred to the naked eye, making deblurring exceedingly challenging, even with recent advancements in deblurring techniques. Using a large kernel size results in a significant loss of information, posing a substantial challenge for any regenerative deblurring techniques.

Figure 5.
The figure demonstrates frames before (top row) and after (bottom row) the blurring using the Gaussian module. A large Gaussian kernel of size 21 × 21 was implemented to obfuscate the video significantly.
5.3.2. Result from OpenPose Module
The effectiveness of the OpenPose module in capturing and analyzing body poses, even in the presence of blurring, is demonstrated in Figure 6. These results showcase the key points extracted from subjects in various videos, providing valuable insights into body movements and postures. Such accurate extraction enables further analysis and the subsequent prediction of falls. Although the OpenPose module successfully extracted most of the key points from the frames, there were instances where it failed to detect the person or generated key points randomly within the frames. To address this issue, we applied data preprocessing techniques and employed linear interpolation to manage these occurrences.

Figure 6.
The figure demonstrates the result of the OpenPose module for different subjects in different videos, showcasing its effectiveness even when blurring the videos.
5.3.3. Result from STFT Module
The selection of STFT parameters such as window type, segment size, overlap ratio, FFT length, scaling, and mode was crucial for accurately capturing and analyzing significant movements indicative of falls. We employed a Hann window for its smooth tapering, which minimizes spectral leakage. A segment size of 16 and an FFT length of 256 were chosen to balance time and frequency resolutions effectively. The overlap ratio was 93.75%, ensuring motion continuity is preserved without sacrificing computational efficiency. Density scaling was applied to normalize the spectrogram by the signal’s power, assisting in the consistent interpretation of spectral density. Meanwhile, the PSD mode focused on the power distribution within the frequency spectrum.
These parameters were not arbitrarily chosen but were determined through an extensive empirical approach, including trials with various settings. This rigorous evaluation allowed us to identify a parameter set that optimally balances sensitivity to motion with computational efficiency. Initially, the effectiveness of these parameters was confirmed through the manual verification of 112 sequences derived from high-motion events captured across two camera angles. This initial test ensured the STFT settings were accurately capturing significant motion events.
Following the successful manual verification, the STFT module was applied to a broader dataset, extracting high-motion sequences from 448 sequences recorded across eight different cameras. This extensive application demonstrates the module’s capability to consistently identify and analyze significant motion across diverse settings, as shown in Figure 7.
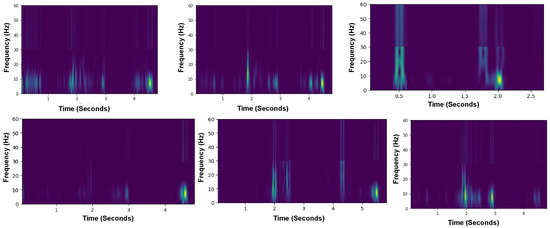
Figure 7.
The spectrogram generated by the STFT module for different subjects, highlighting regions with substantial motion.
To ensure the statistical reliability of our findings from the STFT module, we conducted a power analysis using G*Power as shown in Figure 8. Based on an effect size of 0.5, an error probability of 0.05, and a desired power of 0.8, the analysis determined that a total sample size of 102 sequences would be necessary for robust results. With our initial manual testing covering 112 sequences and the STFT module effectively analyzing 448 sequences, our study significantly exceeds the recommended sample size.
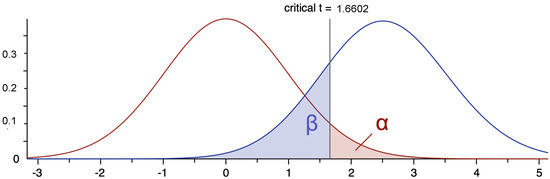
Figure 8.
G*Power analysis results illustrating the critical t-distribution and the calculated power for the study.
5.3.4. Result from Classification Module
The classification reports in Table 2 and Table 3 offer detailed insights into the performance of the classification module, enabling a thorough assessment of the system’s accuracy.
Table 2.
Classification report of all the key points for Multiple Cameras Fall Dataset (MCFD).
Table 3.
Classification Report of subset of key points for Multiple Cameras Fall Dataset (MCFD).
We observed that utilizing a subset of key points consisting of the neck, left shoulder, right shoulder, and hip yielded significantly improved results than using all the key points. The subset achieved an impressive accuracy of 98%, outperforming the accuracy of 91% obtained when using all the key points. This finding suggests two things. The first is that the other key points contain a lot of missing data, and the second one is that the selected subset contains key anatomical landmarks that are particularly informative for fall detection. Focusing on these key points could capture essential body movements and orientations strongly indicative of falls.
However, it is crucial to note that there were some misclassifications within the detection system, particularly in scenarios where falls did not conform to typical patterns, such as when an individual fell onto a sofa instead of the floor. These instances, which often involve softer, more gradual descents that may not generate the distinct motion signatures expected from a fall, were sometimes incorrectly labeled as non-falls. Such nuanced scenarios underscore the complexity of accurately detecting falls across diverse real-world environments. The variability in how falls occur is affected by factors such as the individual’s interaction with surrounding furniture and the nature of the fall itself, which presents substantial challenges in automating reliable fall detection.
The environment in which a fall occurs plays a significant role in detection accuracy. For instance, objects like sofas can cushion a fall, significantly altering the fall’s dynamics and the associated sensory data captured by the system. This can obscure critical visual and motion cues necessary for accurate classification. Additionally, the effectiveness of fall detection can be influenced by the camera placement. The current system utilizes eight different cameras positioned around the room to capture multiple angles of potential falls. However, optimal placement and improved sensitivity may enhance the system’s ability to capture subtle movements associated with atypical falls, such as those partially obstructed by furniture.
5.3.5. Result from GradCAM Module
The GradCAM module is pivotal in enhancing the interpretability of our fall-detection model. By generating heatmaps highlighting the temporal variance of key points within sequences where a fall occurs, GradCAM offers visual insights into the specific features and areas that the model considers most relevant for making its decisions. This visualization not only helps identify the critical areas of interest for fall identification but also clarifies the decision-making process of the model, which is particularly useful in complex, real-world scenarios where multiple factors influence the outcome.
The heatmaps produced by GradCAM effectively illustrate how certain patterns of movement and specific key points are emphasized during fall events compared to non-fall activities as seen in Figure 9. For instance, during a fall, significant key points such as the neck, shoulders, and hips might show synchronized and rapid movements, which are captured and emphasized in the heatmap. These patterns are critical for distinguishing falls from other activities like sitting or bending, where movements are more gradual and less coordinated.
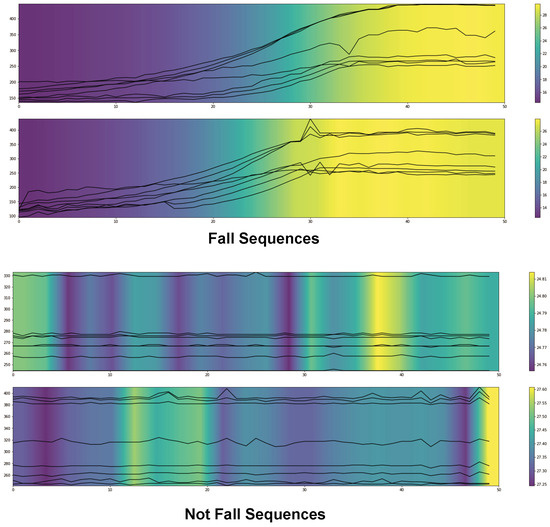
Figure 9.
This figure displays the results from the GradCAM module, highlighting random regions during not fall sequences and continuous regions of key points during fall sequences. The X-axis denotes the frame number from 1 to 50 in the sequence, and the Y-axis represents the temporal variance.
Moreover, the ability of GradCAM to visually demonstrate these differences enhances trust in the model’s predictive capabilities. Medical practitioners and caregivers can use these insights to understand the model’s reasoning better, potentially leading to more informed decisions about patient safety measures and interventions. For example, knowing which movements or positions most commonly lead to falls can inform targeted exercises or changes in the living environment to prevent such incidents.
From a practical standpoint, the interpretability provided by GradCAM serves as a vital link between the raw data processed by the model and the human understanding of that data. This connection is particularly crucial in healthcare settings, where the ability to explain AI systems is not just a convenience but a necessity for user acceptance and trust. By offering clear, intuitive visual explanations, GradCAM demystifies the model’s operations, making its insights more accessible and actionable for healthcare professionals.
The interpretability provided by GradCAM is not only beneficial for understanding the model’s decisions but also for iterative model improvement. Developers and clinicians can scrutinize cases where the model’s output deviates from expected results, pinpointing potential areas for enhancement. For example, if the GradCAM heatmap consistently highlights incorrect regions during fall events, this could signal a need to adjust the model’s focus or augment the training dataset to better reflect the intricacy of various fall types.
In conclusion, integrating GradCAM into our fall-detection system enhances the system’s transparency and effectiveness. The clear visual feedback provided by GradCAM not only validates the model’s decisions but also fosters continuous improvement and cultivates user trust. This makes GradCAM an invaluable asset in the development of dependable and explainable AI solutions for healthcare.
5.4. Impact of Gaussian Blur on Fall-Detection Performance
In our fall-detection system, Gaussian blur is employed to ensure privacy protection and test the OpenPose module’s resilience in key point detection under varying levels of image obfuscation. We conducted detailed experiments with different Gaussian blur kernel sizes to find the optimal balance between these requirements—privacy and detection accuracy.
The following table demonstrates how the performance of the fall-detection system varies with the degree of Gaussian blur applied:
As the data in Table 4 illustrates, smaller kernel sizes like 5 × 5 offer the highest performance in terms of precision, recall, and overall accuracy. With an increase in kernel size, there is a notable trend towards reduced precision and accuracy, though recall remains relatively high. This trend is attributed to the blurring effect obscuring key points, making it challenging for the OpenPose module to detect and classify key points accurately. Particularly with a kernel size of 31 × 31, there is a noticeable drop in performance metrics, indicating significant difficulty in key point detection due to excessive blurring.
Table 4.
Impact of Gaussian blur on fall-detection performance.
The kernel size of 21 × 21 represents a compromise, providing adequate privacy while maintaining reasonable accuracy in fall detection. However, as the kernel size increases to 31 × 31, the decline in performance underscores the critical trade-off faced. While stronger blurring enhances privacy, it significantly impairs the system’s ability to effectively detect and analyze fall incidents.
This analysis clearly demonstrates the need to carefully select the degree of Gaussian blur. It ensures that while the privacy of the individuals in the video footage is protected, the fall-detection capabilities of the system are not unduly compromised. The findings highlight the delicate balance between obscuring sensitive information and retaining sufficient image clarity for accurate fall detection, which is crucial for practical applications in environments where privacy and security are paramount.
5.5. Performance Analysis for Other Datasets
We evaluated the performance of our fall-detection framework on several additional datasets, each offering unique challenges and providing valuable insights. Below is a summary of the classification performance for each dataset.
5.5.1. UR Fall Dataset (URFD)
The UR fall dataset (URFD) included 30 fall event videos captured by two cameras, resulting in 60 instances of fall events. In addition, the dataset comprised 40 videos depicting other activities. We utilized the STFT to extract instances with a significant motion for both fall and non-fall events. For non-fall activities that did not exhibit significant motion, we randomly selected 50 frames for classification to ensure robustness in varied scenarios. Notably, the Gaussian blur module was not employed in this evaluation to maintain consistency with state-of-the-art algorithms for a direct comparison.
The results demonstrate that the framework effectively distinguishes between fall and non-fall events with high accuracy as seen in Table 5, supporting its potential utility in real-world scenarios where precise and reliable fall detection is crucial.
Table 5.
Classification report for UR fall dataset (URFD).
5.5.2. NTU RGB+D Dataset (NTU)
The NTU RGB+D dataset includes 946 videos labeled as falling under medical conditions. For this dataset, we applied STFT to extract 50 frames, specifically at moments when a fall occurred. We randomly extracted frames from videos without significant motion or fall events to simulate the lack of subtle movement typically associated with non-fall scenarios. This approach aimed to challenge the model’s ability to discern true falls from low-activity states.
The retraining of our model on this dataset excluded the use of the Gaussian module, focusing solely on the capabilities of STFT and the classification framework to evaluate its performance against sophisticated activities and subtle motions.
The classification report indicates a slight misclassification rate in the fall category, primarily due to incomplete fall actions in some videos, which pose challenges in detecting definitive fall patterns as seen in Table 6. Nonetheless, the high precision and recall rates affirm the model’s robustness and capability to handle complex scenarios in medical monitoring applications.
Table 6.
Classification Report for NTU RGB+D dataset (NTU).
5.6. Comparison with Other State-of-the-Art Methods
To validate our proposed fall-detection system, we conducted extensive comparisons against several state-of-the-art methods across three distinct datasets: MCFD, URFD, and NTU, as detailed in Table 7. Our system consistently achieved higher sensitivity and specificity across all tested scenarios, demonstrating its robustness and accuracy in detecting fall events.
Table 7.
Performance of the proposed method and comparison with SOTA.
In the MCFD dataset, our method outperformed traditional techniques such as PCANet-SVM [48], HLC-SVM [49], and a conventional CNN approach [50]. Moreover, it excelled over the DSM [51] and OpenPose-SVM [52], the latter of which, while not explicitly labeled as ’real-time’ in its documentation, has been demonstrated to possess characteristics suitable for real-time applications due to its computational efficiency. Our system achieved a perfect sensitivity of 1.00 and a specificity of 0.963, accurately detecting all fall events while maintaining a high True Negative rate.
For the URFD dataset, our system’s performance notably excelled compared to methods like GLR-FD [53], Dense-OF-FD [54], and I3D-FC-NN [56]. We also included newer methods such as GrassManifold [57] and HCAE [58], which are recognized for their robust performance and potential for real-time processing. Our approach achieved a sensitivity of 1.00 and a specificity of 0.975, proving its efficacy in accurately distinguishing between fall and non-fall events, a critical factor in reducing false alarms and ensuring timely medical responses.
Lastly, in the NTU dataset, our proposed method showcased an exemplary specificity of 1.00 and a sensitivity of 0.980. This performance underscores our system’s ability to handle varied and complex scenarios effectively, proving its suitability for real-world applications. Our comparative analysis highlights our method’s state-of-the-art performance and applicability in real-time settings.
5.7. System Configuration and Real-Time Performance Analysis
We conducted fall-detection experiments on a high-performance Linux platform, utilizing an NVIDIA DGX Server Version 4.6.0 equipped with a GNU Linux 4.15.0-121-generic x86 operating system (Dell Inc., Round Rock, TX, USA). The deep learning models, including the CNN for fall detection, leveraged an NVIDIA Tesla V100 SXM3 GPU (Santa Clara, CA, USA) with 32 GB of memory. This setup ensures substantial computational efficiency, which is critical for real-time processing.
The real-time efficiency of our system is primarily attributed to the CNN classification module, which is optimized to utilize the robust capabilities of the NVIDIA Tesla V100 GPU. This configuration allows for the rapid processing of video frames. Each frame undergoes preprocessing, pose estimation via the OpenPose module, and STFT analysis within approximately 50 ms. The CNN module processes each frame in about 16.7 ms. Consequently, the entire sequence of 50 frames is analyzed in about 833 ms, demonstrating the system’s ability to operate effectively under real-time constraints. This processing speed is crucial for scenarios requiring a timely fall-incident response, enabling prompt detection and intervention.
To highlight our system’s real-time capabilities, we compared its frame processing speed with other contemporary methods, as summarized in the Table 8. This comparative analysis underscores our system’s suitability for real-time applications by demonstrating its processing efficiency relative to other methods in the field.
Table 8.
Comparative real-time performance analysis.
Our proposed method processes 60 frames per second on the GPU, providing a competitive processing rate in fall detection. This capability demonstrates our system’s efficiency and applicability in scenarios where quick response and low latency are critical, such as monitoring elderly individuals to prevent fall-related injuries. This processing speed supports the real-time capability of our system, positioning it as a reliable solution in fall detection for urgent care scenarios.
6. Conclusions and Future Work
This paper presented a comprehensive and modular fall-detection framework designed to enhance the accuracy, efficiency, and explainability of monitoring systems for elderly care. At the core of our approach is the novel integration of short-time Fourier transform (STFT) for dynamic frame extraction, significantly reducing false alarms by focusing on frames exhibiting substantial motion. This targeted frame extraction is particularly beneficial in environments where continuous monitoring is essential yet computational efficiency is also a requirement. The framework includes a lightweight 1D convolutional neural network (CNN) optimized for low computational demand while maintaining high accuracy, making the system suitable for real-time applications in resource-constrained settings. Moreover, integrating gradient-weighted class activation mapping (GradCAM) provides valuable insights into the model’s decision-making process, enhancing transparency and offering trustworthy feedback to caregivers and medical professionals.
Despite these advancements, the system faces limitations, particularly in environments with complex dynamics, such as varying lighting conditions or physical obstructions that can obscure fall events. To address these challenges, future work will explore the integration of multimodal data inputs, such as combining visual data with other sensors like infrared or depth cameras. This approach aims to integrate more complex deep learning models to enhance detection robustness across diverse operational settings. Additionally, future studies will expand the dataset to include a broader spectrum of fall-related scenarios and diverse demographics to test the system’s efficacy more comprehensively. We also plan to refine the GradCAM module to deliver more detailed visual explanations, facilitating a deeper understanding of the model’s predictive behaviors.
Overall, the proposed modular fall-detection framework represents a significant step forward in applying advanced machine learning techniques to elderly care. By enhancing the system’s accuracy, reliability, and user trust, we aim to contribute to safer living environments for the elderly, ultimately reducing the incidence and impact of falls worldwide.
Author Contributions
All phases of this study, including conceptualization, methodology, software development, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation, and visualization, were primarily executed by M.D. Supervision, writing—review and editing, and project administration were collaboratively handled by A.G., M.G. and C.W.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Norges Forskningsråd, grant number 310278.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are the Multiple Cameras Fall Dataset (MCFD), available at https://www.iro.umontreal.ca/~labimage/Dataset/ (accessed on 10 January 2024); the UR fall-detection dataset, available at http://fenix.ur.edu.pl/~mkepski/ds/uf.html (accessed on accessed on 10 January 2024); and the Action Recognition Datasets “NTU RGB+D” and “NTU RGB+D 120”, available at https://rose1.ntu.edu.sg/dataset/actionRecognition/ (accessed on accessed on 10 January 2024). These are publicly available datasets, including the videos recorded, which were used to develop and validate our fall-detection approach.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
List of symbols and their meanings:
| Symbol | Definition | Context |
| Pixel location indices (rows and columns) | Gaussian blur, image processing | |
| Standard deviation, spread of Gaussian function | Gaussian blur, OpenPose | |
| F | Feature map from baseline CNN | OpenPose module |
| p | Position vector in 2D space | OpenPose, Part Affinity Fields |
| v | Velocity of key points | OpenPose module |
| k | Key point | OpenPose module |
| Confidence map value at position p for person k and joint j | OpenPose confidence maps | |
| Part Affinity Field value at position p for limb c | Part Affinity Fields | |
| Candidate locations of body parts for connection | OpenPose Part Affinity Fields | |
| E | Line integral of PAF along the line connecting two key points | OpenPose module, testing phase |
| Activation map values at indices | GradCAM | |
| Weights associated with class c for feature map k | GradCAM | |
| Output score for class c | GradCAM | |
| Z | Normalization factor (size of feature map) | GradCAM, global average pooling |
| Signal | STFT | |
| Window function | STFT | |
| Kernel indices | Gaussian blur | |
| K | Kernel size | Gaussian blur |
| Input image being convolved | Gaussian blur | |
| Actual locations of anatomical features along a limb | OpenPose | |
| Time and frequency variables | STFT |
References
- Stampfler, T.; Elgendi, M.; Fletcher, R.R.; Menon, C. Fall detection using accelerometer-based smartphones: Where do we go from here? Front. Public Health 2022, 10, 996021. [Google Scholar] [CrossRef] [PubMed]
- Parmar, R.; Trapasiya, S. A Comprehensive Survey of Various Approaches on Human Fall Detection for Elderly People. Wirel. Pers. Commun. 2022, 126, 1679–1703. [Google Scholar] [CrossRef]
- Robinovitch, S.N.; Feldman, F.; Yang, Y.; Schonnop, R.; Leung, P.M.; Sarraf, T.; Loughin, M. Video capture of the circumstances of falls in elderly people residing in long-term care: An observational study. Lancet 2013, 381, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Jitpattanakul, A. Wearable fall detection based on motion signals using hybrid deep residual neural network. In Proceedings of the Multi-Disciplinary Trends in Artificial Intelligence: 15th International Conference, MIWAI 2022, Virtual Event, 17–19 November 2022; Springer Nature: Berlin/Heidelberg, Germany, 2022; Volume 13651, p. 216. [Google Scholar]
- Rashmi, N.; Mamatha, K.R. Doppler radar technique for geriatric fall detection. In Smart Data Intelligence: Proceedings of ICSMDI 2022; Springer Nature: Singapore, 2022; pp. 343–350. [Google Scholar]
- Karar, M.E.; Shehata, H.I.; Reyad, O. A survey of IoT-based fall detection for aiding elderly care: Sensors, methods, challenges and future trends. Appl. Sci. 2022, 12, 3276. [Google Scholar] [CrossRef]
- De, A.; Saha, A.; Kumar, P.; Pal, G. Fall detection method based on spatio-temporal feature fusion using combined two-channel classification. Multimed. Tools Appl. 2022, 81, 26081–26100. [Google Scholar] [CrossRef]
- Butt, A.; Narejo, S.; Anjum, M.R.; Yonus, M.U.; Memon, M.; Samejo, A.A. Fall detection using LSTM and transfer learning. Wirel. Pers. Commun. 2022, 126, 1733–1750. [Google Scholar] [CrossRef]
- Hadjadji, B.; Saumard, M.; Aron, M. Multi-oriented run length based static and dynamic features fused with Choquet fuzzy integral for human fall detection in videos. J. Vis. Commun. Image Represent. 2022, 82, 103375. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, B.; Zhu, T.; Zhou, A.; Zhou, W. Visual privacy attacks and defenses in deep learning: A survey. Artif. Intell. Rev. 2022, 55, 4347–4401. [Google Scholar] [CrossRef]
- Voigt, P.; Von dem, B.A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 1978; Volume 10, pp. 5510–5555. [Google Scholar]
- Aleksic, S.; Colonna, L.; Dantas, C.; Fedosov, A.; Florez-Revuelta, F.; Fosch-Villaronga, E.; Tamò-Larrieux, A. State of the art in privacy preservation in video data. In CA19121 GoodBrother COST Action; COST: Pittsburgh, PA, USA, 2022. [Google Scholar]
- Quinn, T.P.; Jacobs, S.; Senadeera, M.; Le, V.; Coghlan, S. The three ghosts of medical AI: Can the black-box present deliver? Artif. Intell. Med. 2022, 124, 102158. [Google Scholar] [CrossRef]
- Kute, S.S.; Tyagi, A.K.; Aswathy, S.U. Security, privacy and trust issues in internet of things and machine learning based e-healthcare. In Intelligent Interactive Multimedia Systems for e-Healthcare Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 291–317. [Google Scholar]
- Fu, Q.; Teng, Z.; White, J.; Powell, M.E.; Schmidt, D.C. Fastaudio: A learnable audio front-end for spoof speech detection. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3693–3697. [Google Scholar]
- Kadiri, S.R.; Alku, P.; Yegnanarayana, B. Analysis of Instantaneous Frequency Components of Speech Signals for Epoch Extraction. Comput. Speech Lang. 2023, 78, 101443. [Google Scholar] [CrossRef]
- Jagedish, S.A.; Ramachandran, M.; Kumar, A.; Sheikh, T.H. Wearable devices with recurrent neural networks for real-time fall detection. In International Conference on Innovative Computing and Communications: Proceedings of ICICC 2022; Springer Nature: Singapore, 2022; Volume 2, pp. 357–366. [Google Scholar]
- Salah, O.Z.; Selvaperumal, S.K.; Abdulla, R. Accelerometer-based elderly fall detection system using edge artificial intelligence architecture. Int. J. Electr. Comput. Eng. 2022, 12, 4430. [Google Scholar]
- Li, W.; Zhang, D.; Li, Y.; Wu, Z.; Chen, J.; Zhang, D.; Chen, Y. Real-time fall detection using mmWave radar. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 16–20. [Google Scholar]
- Wang, S.; Wu, J. Patch-Transformer Network: A Wearable-Sensor-Based Fall Detection Method. Sensors 2023, 23, 6360. [Google Scholar] [CrossRef]
- Mohammad, Z.; Anwary, A.R.; Mridha, M.F.; Shovon, M.S.H.; Vassallo, M. An Enhanced Ensemble Deep Neural Network Approach for Elderly Fall Detection System Based on Wearable Sensors. Sensors 2023, 23, 4774. [Google Scholar] [CrossRef] [PubMed]
- Yhdego, H.; Paolini, C.; Audette, M. Toward Real-Time, Robust Wearable Sensor Fall Detection Using Deep Learning Methods: A Feasibility Study. Appl. Sci. 2023, 13, 4988. [Google Scholar] [CrossRef]
- Mankodiya, H.; Jadav, D.; Gupta, R.; Tanwar, S.; Alharbi, A.; Tolba, A.; Raboaca, M.S. XAI-Fall: Explainable AI for Fall Detection on Wearable Devices Using Sequence Models and XAI Techniques. Mathematics 2022, 10, 1990. [Google Scholar] [CrossRef]
- Yuan, L.; Andrews, J.; Mu, H.; Vakil, A.; Ewing, R.; Blasch, E.; Li, J. Interpretable Passive Multi-Modal Sensor Fusion for Human Identification and Activity Recognition. Sensors 2022, 22, 5787. [Google Scholar] [CrossRef]
- Mamchur, N.; Shakhovska, N. Person fall detection system based on video stream analysis. Procedia Comput. Sci. 2022, 198, 676–681. [Google Scholar] [CrossRef]
- Inturi, A.R.; Manikandan, V.M.; Kumar, M.N.; Wang, S.; Zhang, Y. Synergistic Integration of Skeletal Kinematic Features for Vision-Based Fall Detection. Sensors 2023, 23, 6283. [Google Scholar] [CrossRef] [PubMed]
- Alanazi, T.; Babutain, K.; Muhammad, G. A Robust and Automated Vision-Based Human Fall Detection System Using 3D Multi-Stream CNNs with an Image Fusion Technique. Appl. Sci. 2023, 13, 6916. [Google Scholar] [CrossRef]
- Egawa, R.; Miah, A.S.M.; Hirooka, K.; Tomioka, Y.; Shin, J. Dynamic Fall Detection Using Graph-Based Spatial Temporal Convolution and Attention Network. Electronics 2023, 12, 3234. [Google Scholar] [CrossRef]
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl.-Based Syst. 2022, 239, 107948. [Google Scholar]
- Beddiar, D.R.; Oussalah, M.; Nini, B. Fall detection using body geometry and human pose estimation in video sequences. J. Vis. Commun. Image Represent. 2022, 82, 103407. [Google Scholar] [CrossRef]
- El Marhraoui, Y.; Bouilland, S.; Boukallel, M.; Anastassova, M.; Ammi, M. CNN-Based Self-Attention Weight Extraction for Fall Event Prediction Using Balance Test Score. Sensors 2023, 23, 9194. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.-K.; Bae, M.-N.; Lee, K.; Kim, J.-C.; Hong, S.G. Explainable Artificial Intelligence and Wearable Sensor-Based Gait Analysis to Identify Patients with Osteopenia and Sarcopenia in Daily Life. Biosensors 2022, 12, 167. [Google Scholar] [CrossRef] [PubMed]
- Basu, M. Gaussian-based edge-detection methods—A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2002, 32, 252–260. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Zhu, L. Computer vision-driven evaluation system for assisted decision-making in sports training. Wirel. Commun. Mob. Comput. 2021, 2021, 1865538. [Google Scholar] [CrossRef]
- Pachori, R.B. Time-Frequency Analysis Techniques and Their Applications; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Namatēvs, I. Deep convolutional neural networks: Structure, feature extraction and training. Inf. Technol. Manag. Sci. 2017, 20, 40–47. [Google Scholar] [CrossRef]
- Li, D.; Zhang, J.; Zhang, Q.; Wei, X. Classification of ECG signals based on 1D convolution neural network. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; pp. 1–6. [Google Scholar]
- Jiang, C.; Zhou, Q.; Lei, J.; Wang, X. A Two-Stage Structural Damage Detection Method Based on 1D-CNN and SVM. Appl. Sci. 2022, 12, 10394. [Google Scholar] [CrossRef]
- Ozcan, I.H.; Devecioglu, O.C.; Ince, T.; Eren, L.; Askar, M. Enhanced bearing fault detection using multichannel, multilevel 1D CNN classifier. Electr. Eng. 2022, 104, 435–447. [Google Scholar] [CrossRef]
- Chadha, G.S.; Krishnamoorthy, M.; Schwung, A. Time series based fault detection in industrial processes using convolutional neural networks. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 173–178. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Dutt, M.; Redhu, S.; Goodwin, M.; Omlin, C.W. SleepXAI: An explainable deep learning approach for multi-class sleep stage identification. Appl. Intell. 2022, 53, 16830–16843. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Auvinet, E.; Multon, F.; Saint-Arnaud, A.; Rousseau, J.; Meunier, J. Fall detection with multiple cameras: An occlusion-resistant method based on 3-D silhouette vertical distribution. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 290–300. [Google Scholar] [CrossRef] [PubMed]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Chen, L.; Zhou, Z.; Sun, X.; Dong, J. Human fall detection in surveillance video based on PCANet. Multimed. Tools Appl. 2016, 75, 11603–11613. [Google Scholar] [CrossRef]
- Wang, K.; Cao, G.; Meng, D.; Chen, W.; Cao, W. Automatic fall detection of human in video using combination of features. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Shenzhen, China, 15–18 December 2016. [Google Scholar]
- Gunale, K.G.; Mukherji, P.; Motade, S.N. Convolutional Neural Network-Based Fall Detection for the Elderly Person Monitoring. J. Adv. Inf. Technol. 2023, 14, 1169–1176. [Google Scholar] [CrossRef]
- Fan, Y.; Levine, M.D.; Wen, G.; Qiu, S. A deep neural network for real-time detection of falling humans in naturally occurring scenes. Neurocomputing 2017, 260, 43–58. [Google Scholar] [CrossRef]
- Chen, Y.; Du, R.; Luo, K.; Xiao, Y. Fall detection system based on real-time pose estimation and SVM. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021. [Google Scholar]
- Zhao, F.; Cao, Z.; Xiao, Y.; Mao, J.; Yuan, J. Real-time detection of fall from bed using a single depth camera. IEEE Trans. Autom. Sci. Eng. 2018, 16, 1018–1032. [Google Scholar] [CrossRef]
- Carlier, A.; Peyramaure, P.; Favre, K.; Pressigout, M. Fall detector adapted to nursing home needs through an optical-flow based CNN. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020. [Google Scholar]
- Dentamaro, V.; Donato, I.; Giuseppe, P. Fall detection by human pose estimation and kinematic theory. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Wu, L.; Huang, C.; Zhao, S.; Li, J.; Zhao, J.; Cui, Z.; Zhang, M. Robust fall detection in video surveillance based on weakly supervised learning. Neural Netw. 2023, 163, 286–297. [Google Scholar] [CrossRef]
- Soni, P.K.; Choudhary, A. Grassmann manifold based framework for automated fall detection from a camera. Image Vis. Comput. 2022, 122, 104431. [Google Scholar] [CrossRef]
- Cai, X.; Li, S.; Liu, X.; Han, G. Vision-based fall detection with multi-task hourglass convolutional auto-encoder. IEEE Access 2020, 8, 44493–44502. [Google Scholar] [CrossRef]
- Feng, Q.; Gao, C.; Wang, L.; Zhao, Y.; Song, T.; Li, Q. Spatio-temporal fall event detection in complex scenes using attention guided LSTM. Pattern Recognit. Lett. 2020, 130, 242–249. [Google Scholar] [CrossRef]
- Xu, Q.; Huang, G.; Yu, M.; Guo, Y. Fall prediction based on key points of human bones. Phys. A Stat. Mech. Appl. 2020, 540, 123205. [Google Scholar] [CrossRef]
- Shojaei-Hashemi, A.; Nasiopoulos, P.; Little, J.J.; Pourazad, M.T. Video-based human fall detection in smart homes using deep learning. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Tsai, T.H.; Hsu, C.W. Implementation of fall detection system based on 3D skeleton for deep learning technique. IEEE Access 2019, 7, 153049–153059. [Google Scholar] [CrossRef]
- Chen, Z.; Yiye, W.; Wankou, Y. Video based fall detection using human poses. In Proceedings of the CCF Conference on Big Data, Nanjing, China, 8–10 September 2022; Springer: Singapore, 2022. [Google Scholar]
- Kondratyuk, D.; Yuan, L.; Li, Y.; Zhang, L.; Tan, M.; Brown, M.; Gong, B. Movinets: Mobile video networks for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Action recognition using optimized deep autoencoder and CNN for surveillance data streams of non-stationary environments. Future Gener. Comput. Syst. 2019, 96, 386–397. [Google Scholar] [CrossRef]
- Yu, S.; Xie, L.; Liu, L.; Xia, D. Learning long-term temporal features with deep neural networks for human action recognition. IEEE Access 2019, 8, 1840–1850. [Google Scholar] [CrossRef]
- Zhang, Z.; Lv, Z.; Gan, C.; Zhu, Q. Human action recognition using convolutional LSTM and fully-connected LSTM with different attentions. Neurocomputing 2020, 410, 304–316. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Del Ser, J.; Baik, S.W.; de Albuquerque, V.H.C. Activity recognition using temporal optical flow convolutional features and multilayer LSTM. IEEE Trans. Ind. Electron. 2018, 66, 9692–9702. [Google Scholar] [CrossRef]
- Song, X.; Lan, C.; Zeng, W.; Xing, J.; Sun, X.; Yang, J. Temporal–spatial mapping for action recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 748–759. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).