Abstract
The crack detection of concrete bridges is an important link in the safety evaluation of bridge structures, and the rapid and accurate identification and detection of bridge cracks is a prerequisite for ensuring the safety and long-term stable use of bridges. To solve the incomplete crack detection and segmentation caused by the complex background and small proportion in the actual bridge crack images, this paper proposes a coarse–fine combined bridge crack detection method of “double detection + single segmentation” based on deep learning. To validate the effect and practicality of fine crack detection, images of old civil bridges and viaduct bridges against a complex background and images of a bridge crack against a simple background are used as datasets. You Only Look Once V5(x) (YOLOV5(x)) was preferred as the object detection network model (ODNM) to perform initial and fine detection of bridge cracks, respectively. Using U-Net as the optimal semantic segmentation network model (SSNM), the crack detection results are accurately segmented for fine crack detection. The test results showed that the initial crack detection using YOLOV5(x) was more comprehensive and preserved the original shape of bridge cracks. Second, based on the initial detection, YOLOV5(x) was adopted for fine crack detection, which can determine the location and shape of cracks more carefully and accurately. Finally, the U-Net model was used to segment the accurately detected cracks and achieved a maximum accuracy (AC) value of 98.37%. The experiment verifies the effectiveness and accuracy of this method, which not only provides a faster and more accurate method for fine detection of bridge cracks but also provides technical support for future automated detection and preventive maintenance of bridge structures and has practical value for bridge crack detection engineering.
1. Introduction
Bridges are an important part of road, rail and other transport links, and their construction and maintenance are essential for the smooth flow of traffic and the development of industry. Cracks are the most common form of bridge deterioration. During operation, bridges are susceptible to cracking caused by excessive loads, poor material quality, foundation deformation, concrete shrinkage, temperature changes and other factors [1,2,3,4]. The safe use and service life of bridges are severely compromised by cracking and can result in significant economic losses and casualties in the event of an accident [5,6,7]. Therefore, accurate detection and timely treatment of bridge cracks is the first task of bridge maintenance [8], which is of significant value in the management of bridge maintenance and the prolongation of the service life of bridges [7].
The main common methods for detecting and identifying cracks in bridges are manual inspection, structural health monitoring and image processing identification. Manual inspection methods, which require manual measurement on the bridge and recording of the locations and sizes of cracks, are simple and flexible but have drawbacks such as inefficiency and risk of working at height [9]. The structural health monitoring method, which is easily adapted for continuous monitoring by installing sensors at positions where the bridges have cracked or are expected to crack [10,11,12], has a limited monitoring range and may be subject to omission and misjudgement. Image processing detection methods mainly use image greyscale information for threshold segmentation to segment cracks from the background. Alternatively, using methods such as morphology [13,14], cracks in bridge images are detected by edge detection [15], and the recognition results are too dependent on the selection of some specific parameters, which cannot ensure the reliability and stability of the crack detection results.
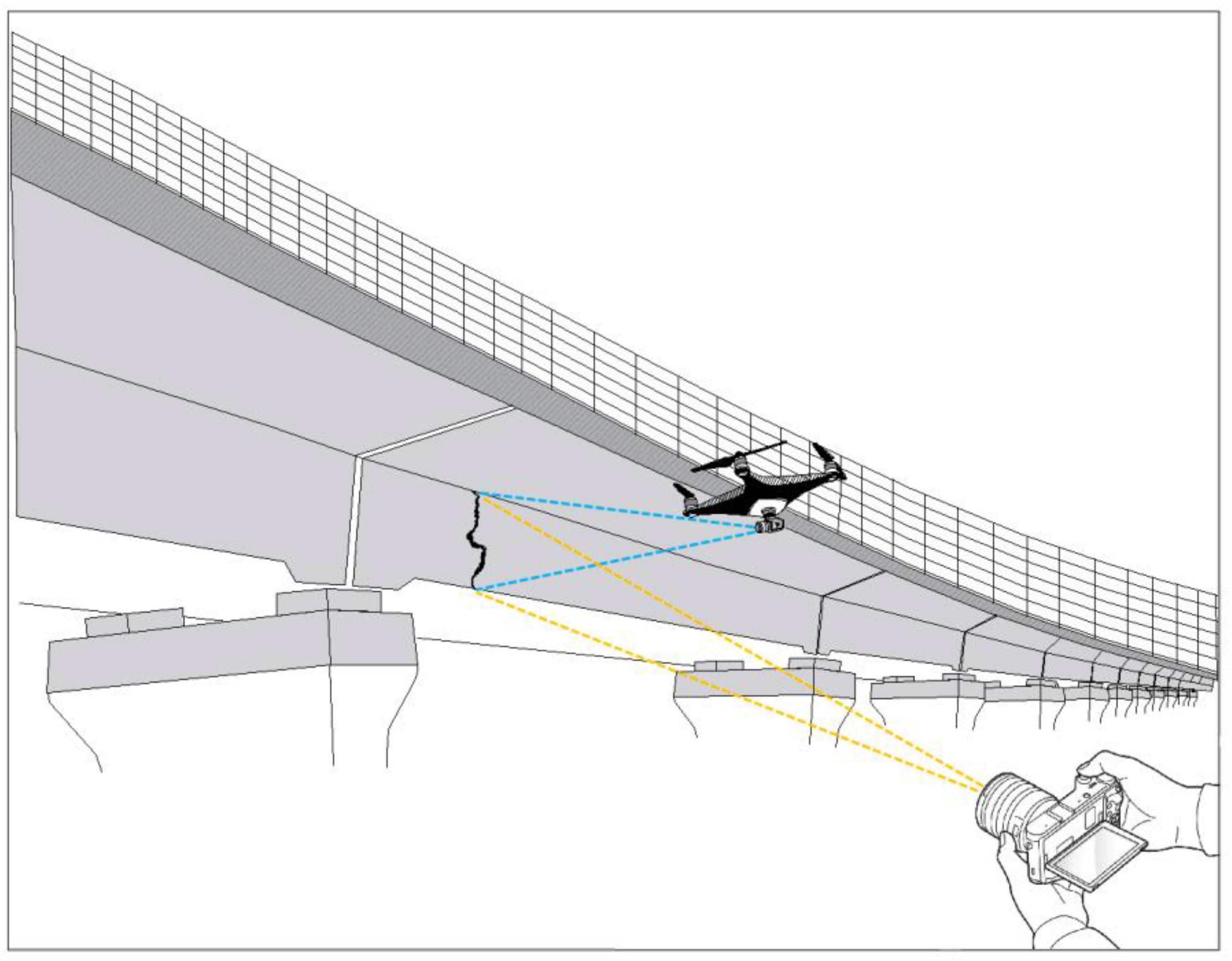
With the fast evolution of deep learning, various intelligent auxiliary bridge crack detection technologies have emerged one after another. For specific research topics, the selection of datasets to be used must meet certain criteria and pertinence [16]. For example, the image acquisition of the bridge surface is carried out by an unmanned aerial vehicle (UAV) or a handheld camera, as shown in Figure 1. In this way, detection efficiency can be improved while maintaining safety, and the size and location of bridge cracks can be more accurately recorded. Recently, some researchers have applied deep learning based on object detection [17,18,19,20,21,22,23], semantic segmentation [24,25] and instance segmentation [26,27] to automate bridge crack detection, and remarkable progress has been made. By learning the mapping in the image, cracks can be accurately and efficiently identified, extracted and segmented from the complex background, providing technical support for fast and accurate bridge crack detection. At the same time, for the interpretation of the experimental results, it is possible to highlight a specific defect type in a given image almost perfectly by adopting Class Activation Map (CAM) approaches within the available eXplainable Artificial Intelligence (XAI) techniques, which allow the observation of the active region [28]. In contrast, the evaluation of the quality of the test results in this paper uses other evaluation metrics, as described in Section 2.3 of the text.

Figure 1.
Detection of bridge cracks by UAV or ground photography.
Cha et al. [29] were the first to apply deep learning technology to building damage detection. In the experiment, 332 original images were used; 277 images were cropped and trained as a training set, and 55 images were used as a test set. Concrete cracks were detected using the CNN, and the resulting detection accuracy reached 98%, demonstrating the high application potential of deep learning in building damage detection. Lin et al. [30] used CNN to detect damage in bridge structures. It can automatically extract features from low-level waveform signals and uses CNN to achieve high-precision identification of bridge damage locations with high detection accuracy, verifying the feasibility of deep learning technology for structural damage detection. Fang et al. [31] proposed a new model-driven clustering method based on Faster R-CNN [32]. It is used to solve the problem of a low percentage of slender target area, thus improving the detection accuracy, effectively ensuring the integrity of the target area and avoiding leakage and false detection. Liao et al. [33] employed the enhanced single-phase object detection algorithm from YOLOV3 [34], and the detection accuracy reached 93.02%, which was 1.37% higher than that of the original YOLOV3. The method had high real-time accuracy and could be used to detect different types of building damage. BaniMustafa et al. [35] used a Sequential Convolutional Neural Network (SCNN), ResNet50 and Xception, respectively, to detect concrete cracks. The accuracy rates of SCNN, ResNet50 and Xception were 90.2%, 86.3% and 70%, respectively. Yadav et al. [36] proposed a multiscale feature fusion method of 3SCNet+LBP+SLIC, where 3SCNet performs crack detection, SLIC forms clusters of similar pixels and LBP finds the texture in the crack image, which improved the performance of CNN with accuracies of 99.47%, 99.75% and 99.69%, respectively, which could be applied to construct a real-time crack detection system. Wan et al. [37] proposed a new method combining the Single Shot MultiBox Detector (SSD) and the eight-neighbourhood method to identify and detect bridge cracks. It used more than 300 crack images of the Beijing–Hangzhou Grand Canal Bridge and more than 1500 crack images collected as datasets and achieved good detection results for all four types of cracks, with an accuracy of more than 95% and a recall rate of more than 75%. The performance of this method in crack detection was significantly improved. Installation on the portable device provided an opportunity to extend its application to automatically detect cracks on concrete bridges. Chen et al. [38] used deep CNNs to classify and recognise multicategory damage images of reinforced concrete bridges, using 150 images each of cracks, corrosion, defects and background as a dataset, and the correct recognition rate of damage images was 86%, with 82% of rebars exposed and 70% of concrete spalling. These studies show that in the field of engineering, the use of deep learning technology to detect and identify structural damage has broad research and application prospects, which will help to detect damage to buildings, bridges and other engineering structures more quickly and accurately and ensure the safety of people’s lives and property.
Ji et al. [39] proposed a two-step strategy for detecting cracking in concrete bridges. First, the deep bridge crack classification (DBCC)-Net was used to implement the coarse extraction of crack locations in concrete bridges based on image slice classification. The complete crack shape of the concrete bridge was then extracted from the locations suggested by the SSNM. This method can quickly achieve crack detection and crack shape extraction in high-resolution images. However, it does not consider the influence of a complex background or a small percentage of the crack region present in the image on the accuracy of crack detection. Based on this, a fine detection method of “double detection + single segmentation” with a coarse–fine combination under a complex background is proposed. In order to verify its effectiveness in bridge crack detection, a training dataset was constructed by collecting and labelling a portion of bridge crack images. The ODNM and the SSNM were selected as the basic networks of the refined detection method, and the “double detection + single segmentation” method was realised in the fine detection of bridge cracks. It provides an important practical basis for damage detection in bridge structures and a powerful reference to solve other related problems.
2. Methodology
2.1. Object Detection Network Models (ODNMs)
2.1.1. Faster R-CNN
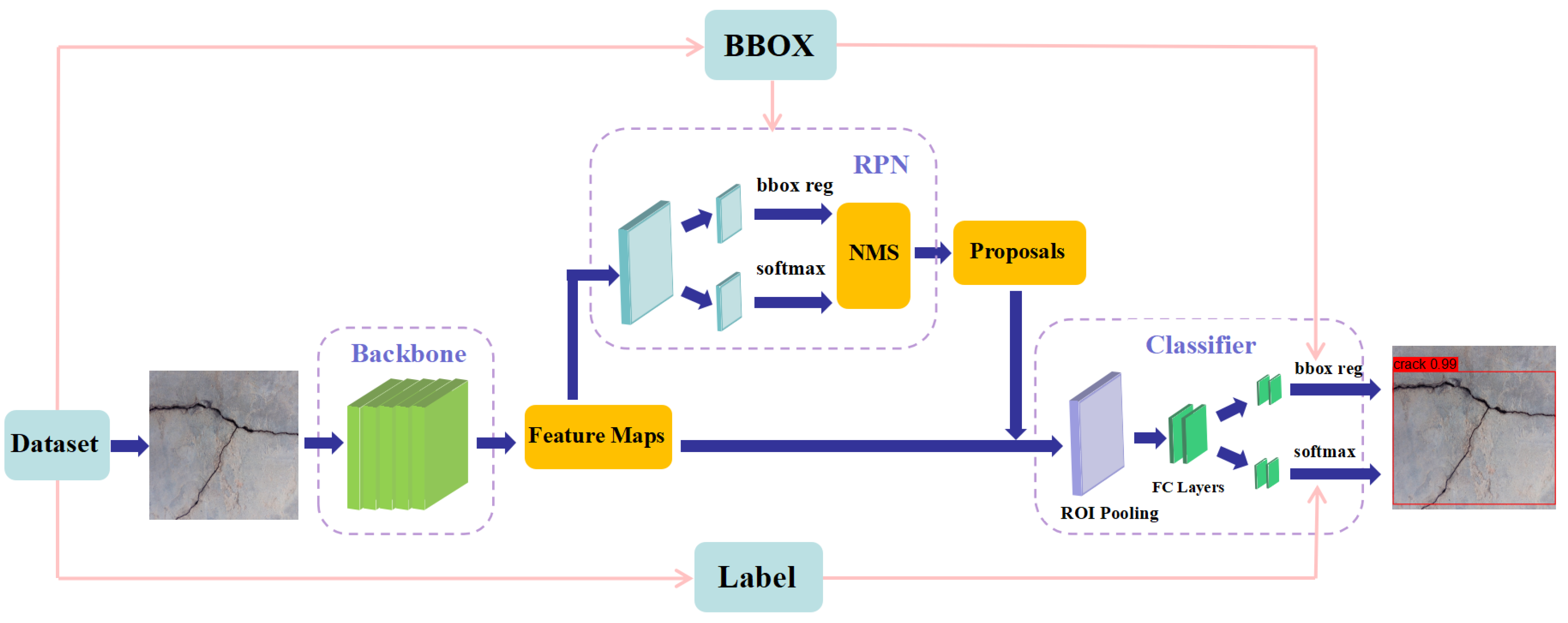
As shown in Figure 2, Faster R-CNN is a typical representative of the two-stage ODNM proposed by He et al. [40] in 2015. Fast R-CNN uses a small Region Proposal Network (RPN) as opposed to the Selective Search algorithm to extract candidate frames on the feature map by sliding windows and scores these candidate frames by classification and regression. Areas with high object performance are screened out, greatly reducing the number of candidate frames and making the whole object detection process more efficient [41]. Faster R-CNN has become a popular object recognition model in the industry due to its high-performance object recognition, end-to-end training approach, multiscale feature optimisation, flexibility, versatility and portability.
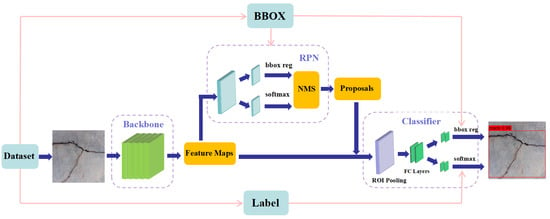
Figure 2.
Faster R-CNN model.
2.1.2. SSD
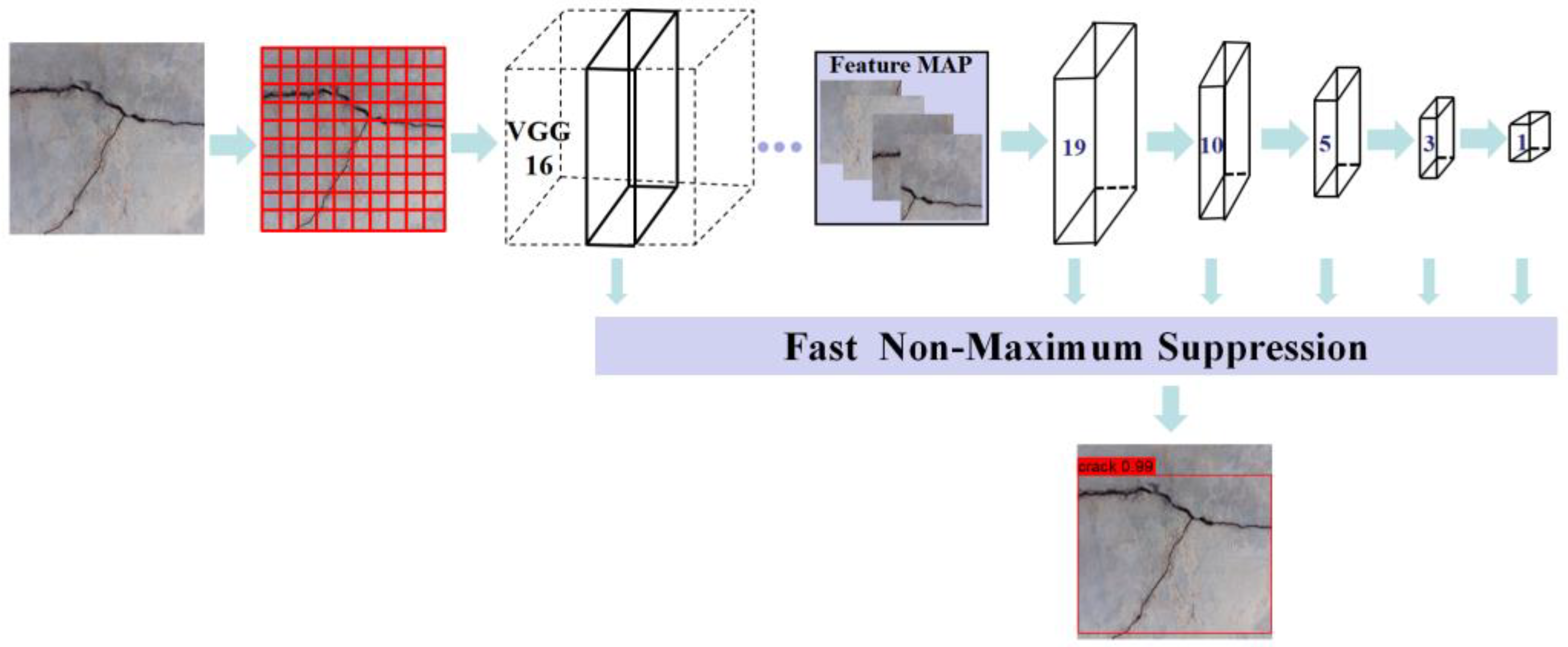
As shown in Figure 3, the Single Shot MultiBox Detector (SSD) was proposed by Liu et al. [42] in 2016. The core idea is to transform object detection into a regression problem. It adopts the anchor concept from the Faster R-CNN algorithm and uses a priori frame detection to identify the object. In the neural network structure, the algorithm modifies the classical VGG16 network, removes the terminal fully connected layer, adds the auxiliary convolution layer and the pooling layer and makes the prediction through 6 feature maps of different sizes. Meanwhile, the feature pyramid-based detection is added to realise object recognition on feature maps of different scales [43]. Due to the end-to-end structure of the SSD model, the algorithm completes the classification while generating the object pre-selection boxes, which significantly reduces the time cost and computational resources.

Figure 3.
SSD model.
2.1.3. YOLOV4
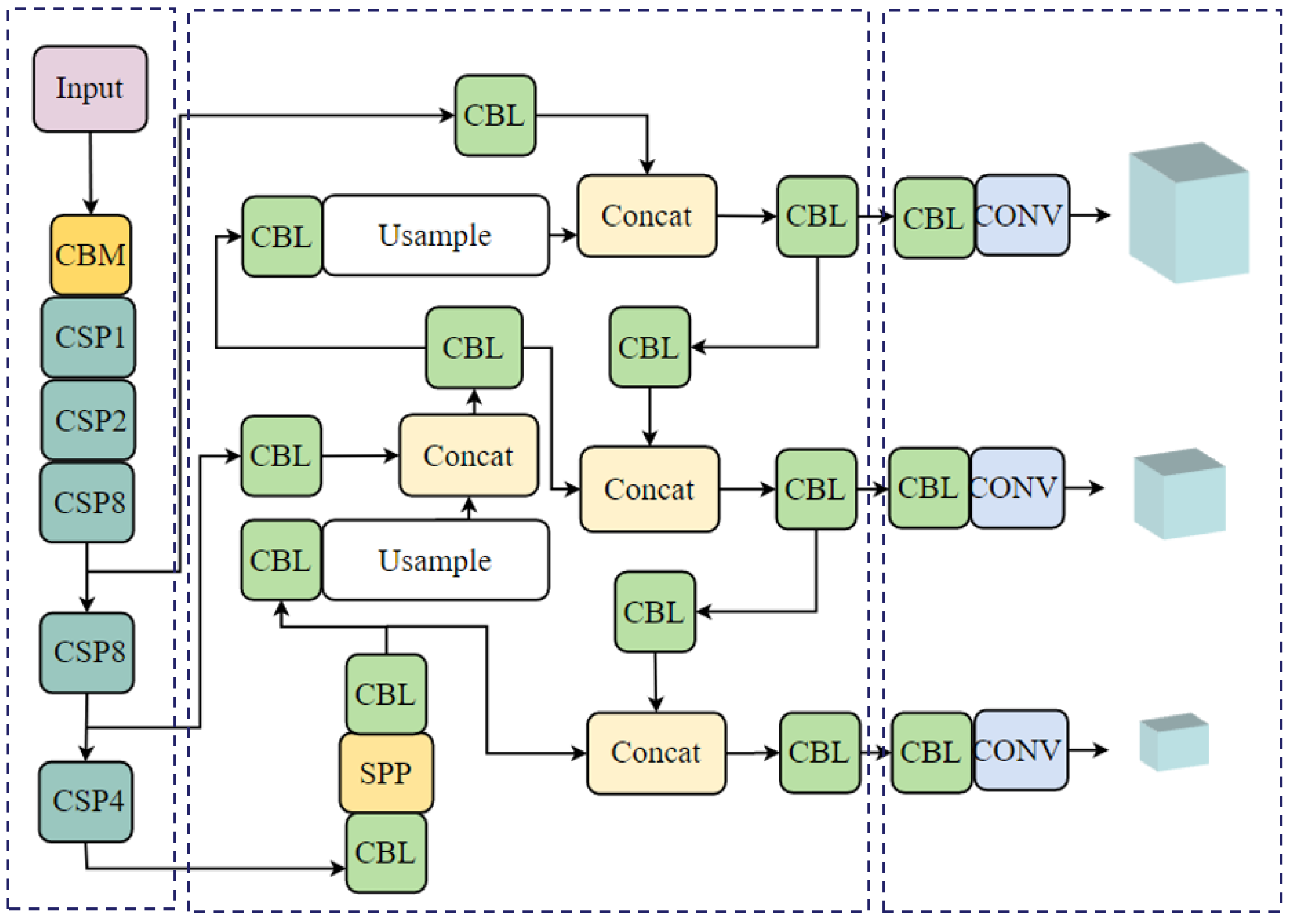
As shown in Figure 4, You Only Look Once Version 4 (YOLOV4) is also a single-stage object detection model [44] that aims to achieve real-time accuracy and robustness and is deeply optimised and innovated on the basis of YOLOV3. The model uses CSPDarknet53 as its backbone network to improve feature richness and complexity by incrementally generating and processing feature maps [45]. Similar to previous versions, YOLOV4 uses FPN to construct multiscale feature pyramids. And the PAN structure is added after the FPN layer to achieve efficient aggregation of strong semantic features and strong localisation features to enhance the recognition performance for different-scale objects. Meanwhile, the attention mechanism is integrated to make the model attend more to key areas and enhance recognition power in complex environments and dense object contexts. In addition, for efficient deployment, the model considers techniques such as model quantification, pruning and mixed precision training to improve inference speed and save computational resources. YOLOV4 is an upgraded version of the YOLO family, with new network structures and optimisation strategies that deliver significant improvements in object detection performance.
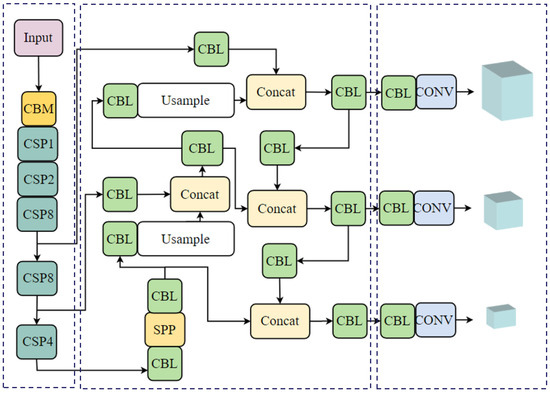
Figure 4.
YOLO V4 model.
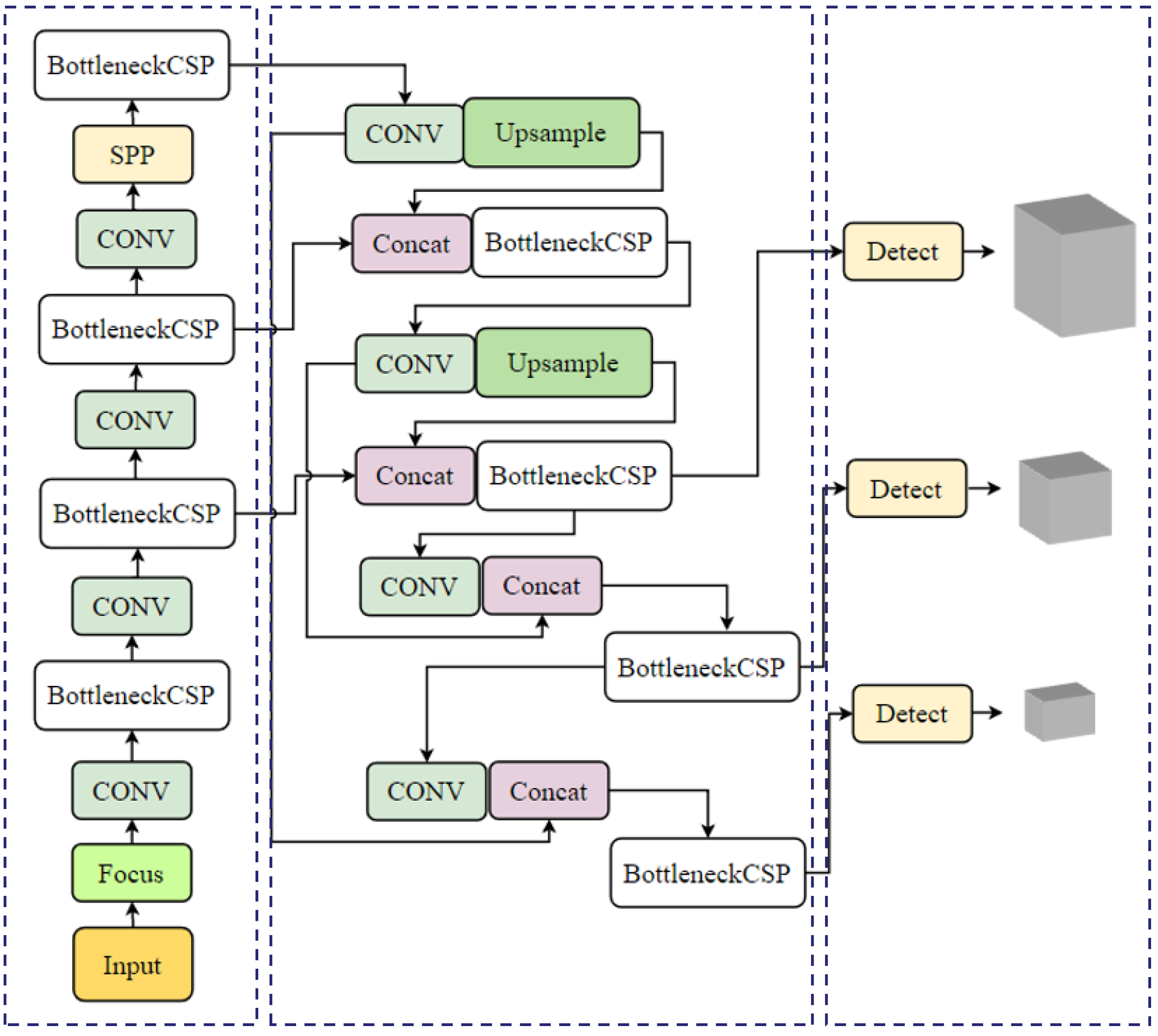
2.1.4. YOLOV5
As shown in Figure 5, You Only Look Once Version 5 (YOLOV5) is a single-stage object detection algorithm [46]. YOLOv5 uses New CSPDarknet53 as a backbone and adds the Focus structure as a benchmark network to extract rich feature information from the input image. The improved FPN+PAN structure is used to further improve the propagation of low-level features and strengthen the ability of network feature fusion to effectively process the performance of objects at different image scales [47]. In terms of hardware acceleration and optimisation, YOLOV5 emphasises model lightness and supports techniques such as model quantification and pruning for efficient deployment on multiple hardware.
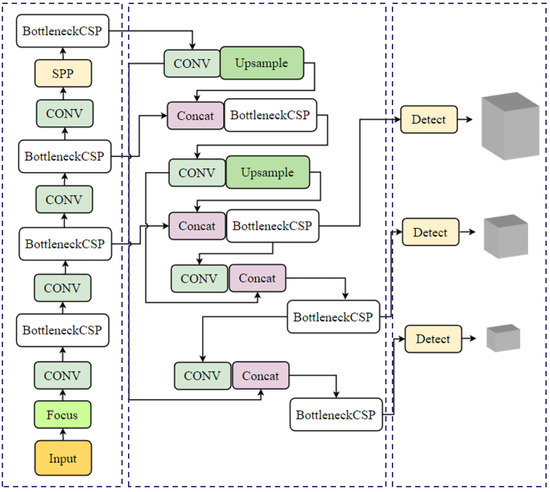
Figure 5.
YOLOV5 model.
2.2. Semantic Segmentation Network Models (SSNMs)
2.2.1. U-Net
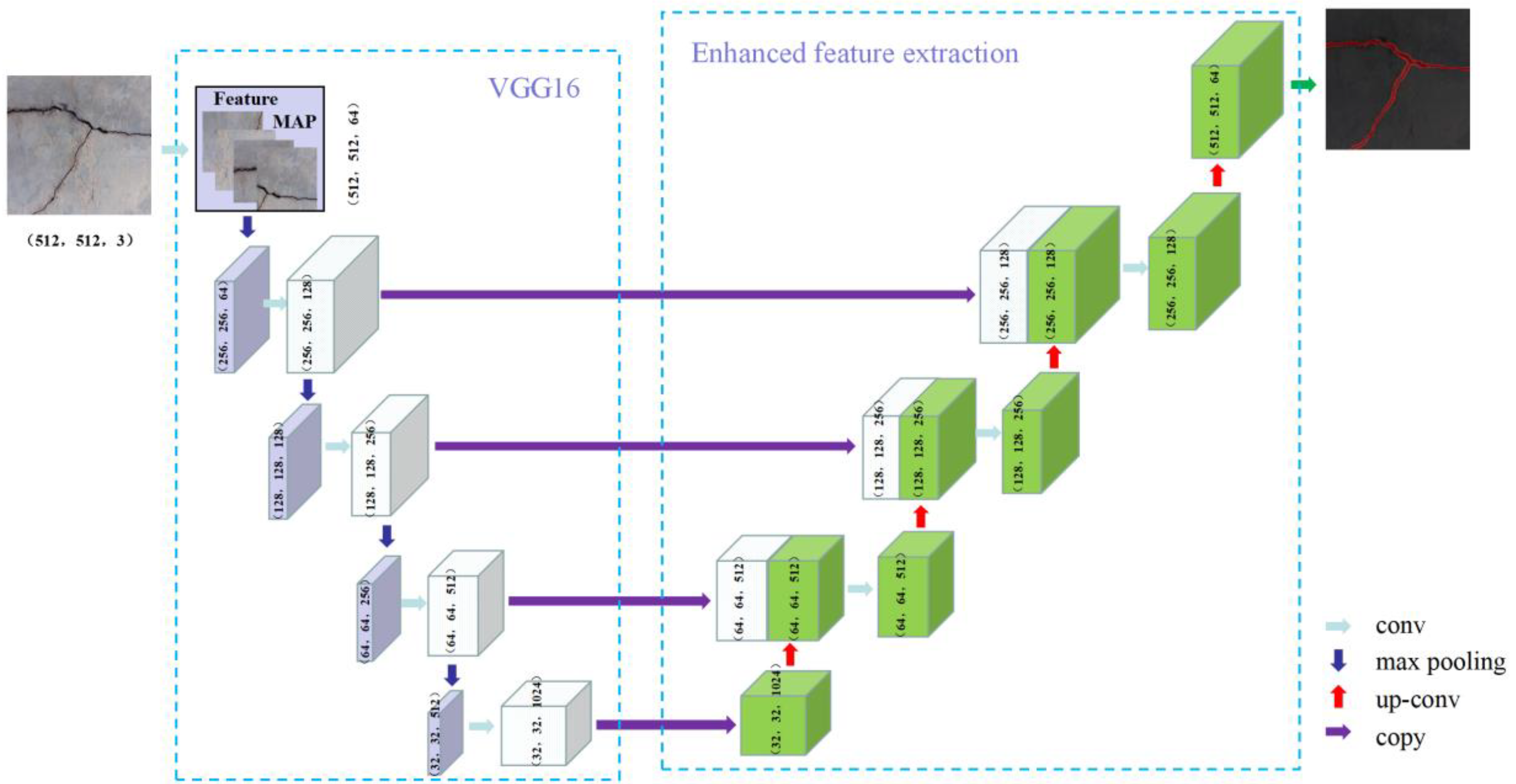
As shown in Figure 6, U-Net is a traditional coding and decoding model proposed in 2015 by Ronneberger et al. [48], originally designed mainly for medical image segmentation. The U-Net network structure consists of three components: encoder, decoder and same-layer hopper link. The encoder consists of multiple layers of convolution and pooling to create a map of features that contain location and semantic information. In order to recover the lost spatial dimension and location information, the decoder consists of a deconvolution and deconpooling layer [49]. The key to this model is the introduction of jump connections using feature splicing, which significantly improves the quality of feature segmentation [24].
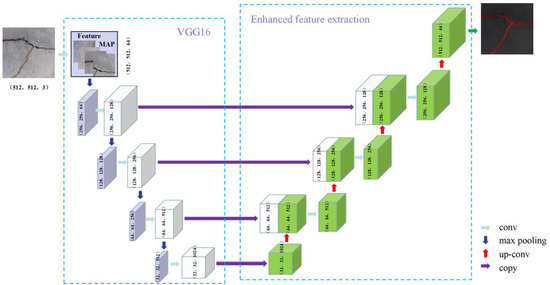
Figure 6.
U-Net model.
2.2.2. PSPNet
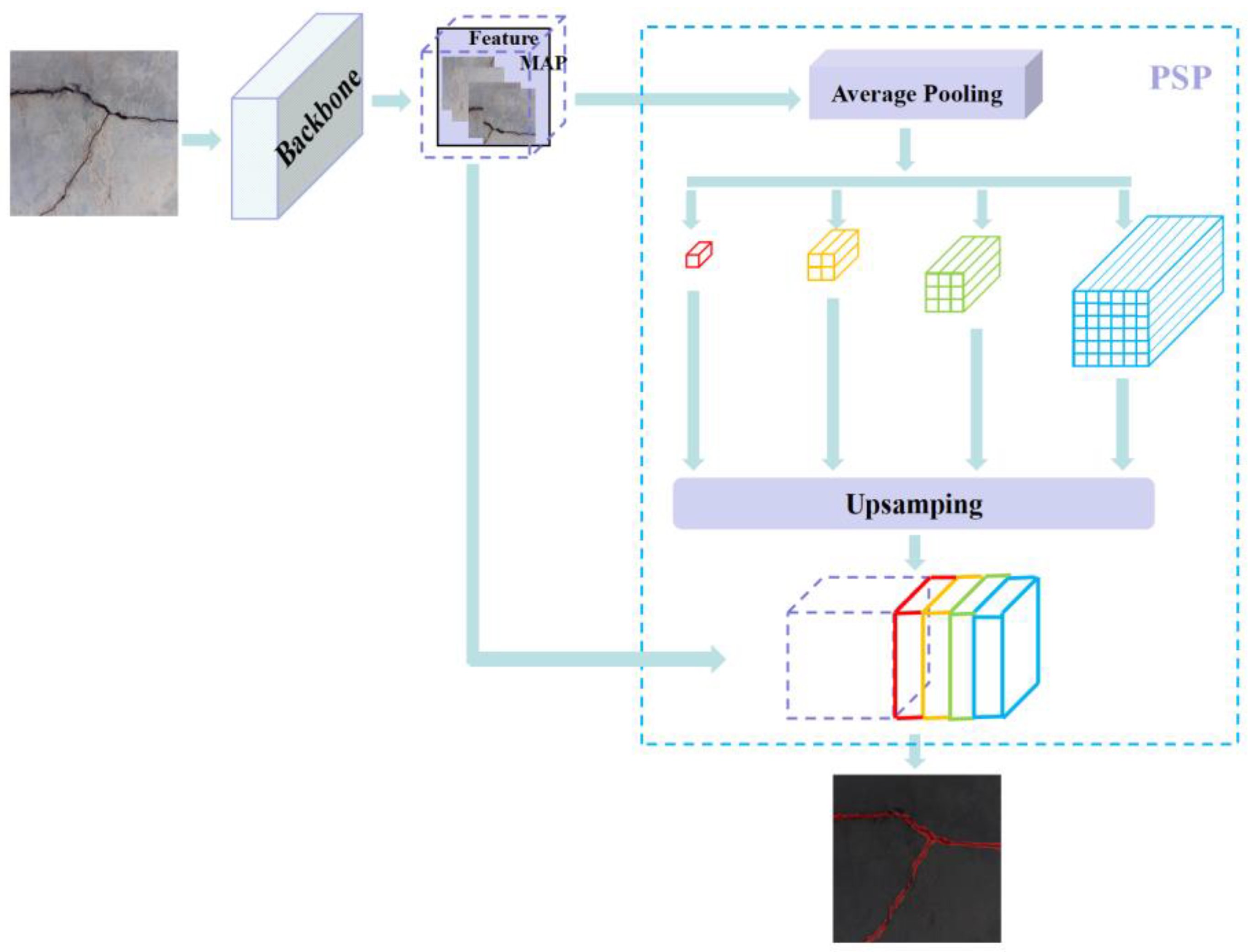
As shown in Figure 7, the Pyramid Scene Parsing Network (PSPNet) was proposed by Zhao et al. [50] in 2017. PSPNet has three main parts: feature extraction, pyramid pooling and output [51]. PSPNet’s pyramid pooling module can produce four different levels of feature maps. The feature maps of the different layers are then up-sampled to their pre-pooling size and spliced with the pre-pooling features. Finally, the final prediction map is generated by a convolution process [19]. In this way, PSPNet can make effective use of local and global contextual information by combining features of different scales, effectively improving the performance of semantic segmentation.
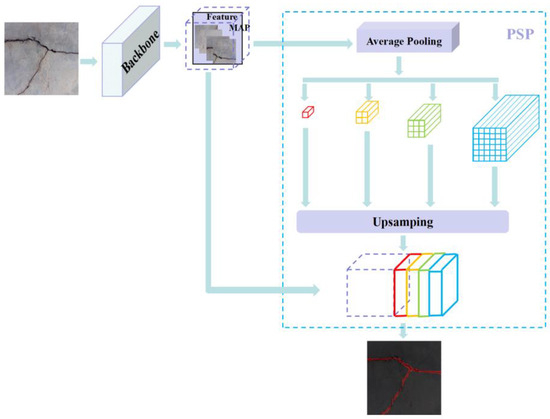
Figure 7.
PSPNet model.
2.2.3. DeepLabV3+
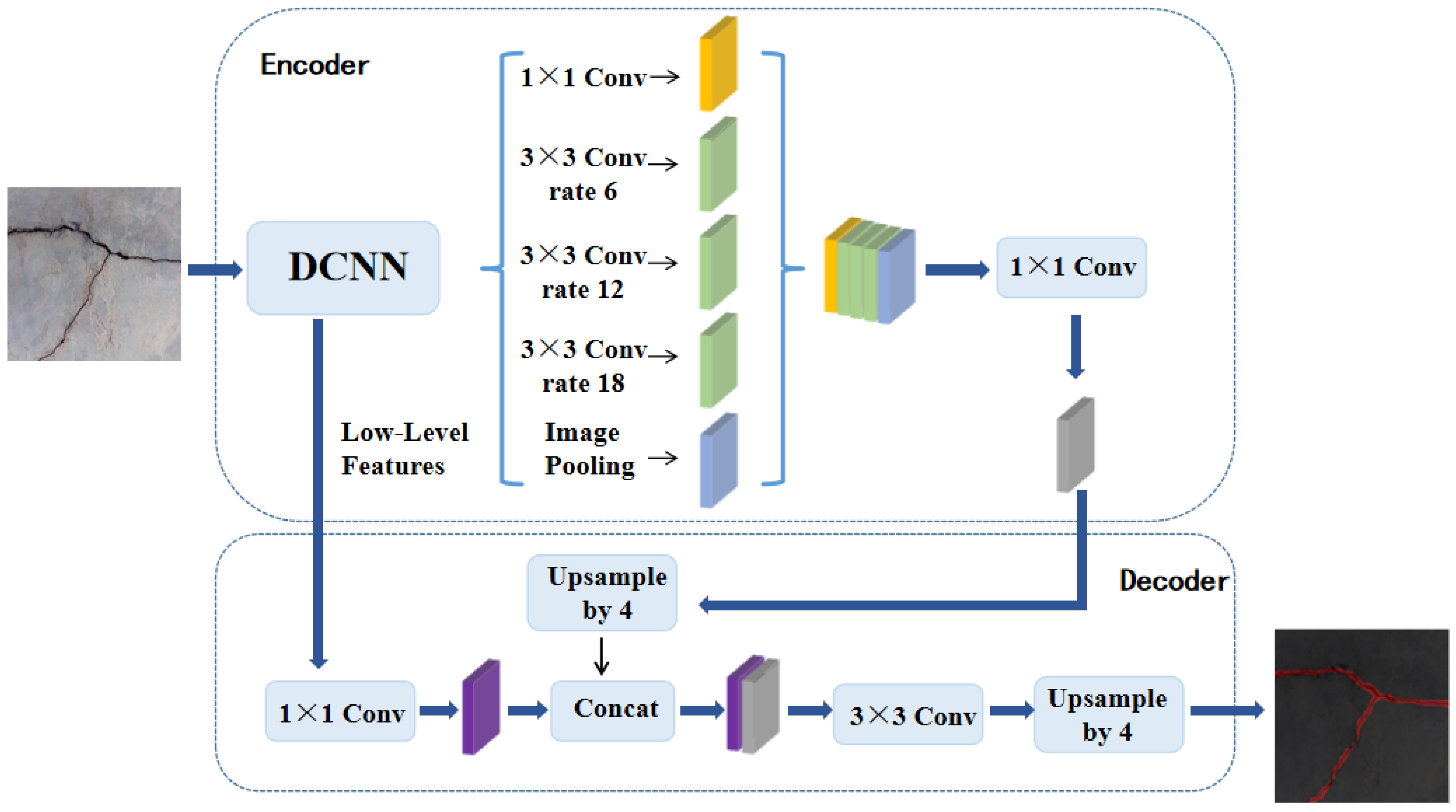
As shown in Figure 8, DeepLabV3+, proposed by the Google research team in 2018, combines the advantages of hollow convolution and multiscale models. Based on deep CNNs, this model expands the receptive field through hollow convolution to improve the ability to perceive the context of images [52]. At the same time, multiscale information fusion and decoder modules are introduced to effectively integrate global context information and underlying features, thereby enhancing adaptability to objects of different scales [53]. Trained on a large-scale labelled semantic segmentation dataset, DeepLabV3+ learns rich semantic representations and demonstrates excellent segmentation results in real-world scenarios, especially in handling boundaries and details. Due to its excellent performance, the model has been widely used in medical image analysis, automated driving, remote sensing image interpretation and other fields.
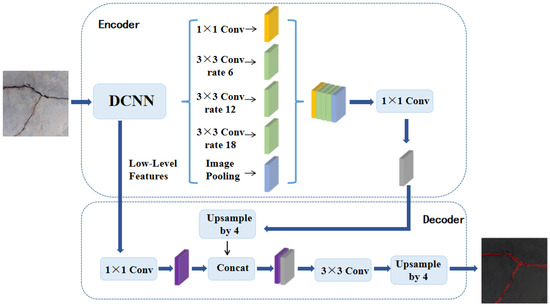
Figure 8.
DeepLabV3+ model.
2.3. Evaluation Indicators
To evaluate the performance of network models in object detection, usual evaluation indicators include precision (P), recall (R), accuracy value (AC) and harmonic mean (F1). The evaluation indicators were calculated using true positives (TPs), true negatives (TNs), false positives (FPs) and false negatives (FNs). For semantic segmentation, TP is the number of positive samples predicted to be positive, TN is the number of negative samples predicted to be negative, FP is the number of negative samples predicted to be positive and FN is the number of positive samples predicted to be negative. For object detection, TP indicates that the intersection over union (IoU) between the predicted bounding box and the ground truth is greater than the specified threshold (e.g., 0.5). If a ground truth has an IoU of multiple predicted bounding boxes all greater than the specified threshold, the largest predicted bounding box of the IoU is a TP and the excess TP is considered to be a FP. FP indicates that the IoU is less than or equal to the specified threshold or that there is no predicted bounding box of the detected object.
- (1)
- Precision value
It is the ratio of correct search results to all actual search results, which can be calculated using the following formula.
- (2)
- Recall value
It represents the proportion of positive data that is actually correctly predicted out of all positive results, calculated using the following formula.
- (3)
- Harmonic mean value
It is the metric that neutralises precision and recall.
- (4)
- Accuracy value
It refers to the proportion of all correct predictions, including positive and negative cases, in the overall testing result.
2.4. Model Effectiveness Experiment
The dataset used for model training consists of two parts: one is a bridge crack image of old civil bridges and viaducts taken in the field, and the other is a simple background crack image [54]. The dataset contains a total of 2068 crack images with a resolution of 1024 × 1024 pixels. The images in the dataset contain a variety of disturbances such as mud stains, water spots, shadows, blurriness, etc., so the network model can learn the crack characteristics and improve the immunity to background noise. The training set, test set and verification set are randomly divided in a ratio of 8:1:1. In the process of model training, the processor used was DELL Intel(R) Core (TM) i7-8700K CPU @ 3.70 GHz and the learning frameworks adopted were PyTorch1.2.0, TensorFlow2.2.0 and Keras2.1.5, respectively. The stochastic gradient descent (SGD) algorithm is used to optimise the network model, with the momentum parameter set to 0.9 and the weight decay set to 1 × 10−4. The network is trained for a total of 100 epochs, and the training batch size is 4. The maximum learning rate of the network is 1 × 10−2, the minimum learning rate is 1% of the maximum learning rate and the cos decreasing strategy is used to attenuate the learning rate.
2.4.1. Model Training
- (1)
- Training results of the ODNMs
In order to determine the optimal network model for coarse–fine combined object detection, Faster R-CNN, SSD, YOLOV4 and YOLOV5(x) were selected to conduct a comparative experiment for object detection of crack images, and the experimental results are shown in Table 1.

Table 1.
Experimental results of the ODNMs.
The object detection of transverse cracks, vertical cracks, diagonal cracks and network cracks of the bridge was completed through experiments. The results showed the confidence of the Faster R-CNN detection was more than 95%, and the crack information of the detection results was more sensitive and relatively complete. When SSD was used to detect bridge cracks, the confidence of the detection results was more than 80%, and the crack information of the detection results was more sensitive and complete. When YOLOV4 was used to detect bridge cracks, the confidence of the detection results was over 20%. The detection effect of bridge cracks was unstable, and the accuracy and sensitivity of the detection results were low. YOLOV5(x) was used to detect bridge cracks, and the confidence of the detection results was over 30%. The crack detection information was sensitive and the cracks were relatively complete, but the confidence of the detection results was low.
- (2)
- Training results of the SSNMs
To determine the optimal network model for fine segmentation, U-Net, DeepLabV3+ and PSPNet were each selected to perform semantic segmentation experiments on bridge cracks, and the experimental results are shown in Table 2.
Table 2.
Experimental results of the SSNMs.
The semantic segmentation of the transverse, vertical, diagonal and network cracks of the bridge was completed through experiments. The experimental results showed that U-Net was the most sensitive to crack details and could accurately exclude the incompletely hollowed crack segment caused by the presence of sand and gravel debris in the crack (see the transverse crack in Table 2). The U-Net crack segmentation was relatively optimal compared to other models and can meet the requirement for optimal crack segmentation. PSPNet had higher detection and recognition of horizontal, vertical and oblique cracks and better segmentation but a higher false alarm rate for mesh cracks and poorer segmentation. The segmentation effect of DeepLabV3+ for the four types of cracks was between U-Net and PSPNet, and the crack segmentation shape was relatively complete, which meant it could basically meet the requirements of crack segmentation.
2.4.2. Model Evaluation
- (1)
- Evaluation results of the ODNMs
The ODNM was evaluated using precision (p), recall (R) and harmonious mean (F1) as evaluation indicators, and the results are shown in Table 3. According to reference [55], the learning efficiency of the same neural network model based on different deep learning frameworks is different. To ensure the effectiveness of the training of the ODNM, the corresponding learning framework of the model was constructed with reference to [55].
Table 3.
Experimental results of the ODNMs.
Table 3 showed that the Faster R-CNN based on Keras2.1.5 had a better F1-value and R-value of 76.00% and 71.37%, respectively, than the other three models. In SSD based on Keras2.1.5, the F1-value, p-value and R-value of the model accuracy evaluation result were 67.00%, 82.76% and 56.47%, respectively. In YOLOV4 based on TensorFlow2.2.0, the F1-value, p-value and R-value of the model accuracy evaluation results were the lowest at 33.00%, 76.06% and 21.18%, respectively. On the other hand, YOLOV5(x) based on TensorFlow2.2.0 had the highest p-value of 87.50% for the model accuracy evaluation results, and the F1-value and R-value were better than YOLOV4 with 67.00% and 54.90%, respectively. It could be seen that the overall evaluation index values of the Faster R-CNN model were higher and more stable, and the evaluation index values of the YOLOV5(x) model were slightly higher than those of the SSD and YOLOV4. In conclusion, Faster R-CNN and YOLOV5(x) had better learning ability for crack features and could be preferred as network models for coarse–fine combined object detection.
- (2)
- Evaluation results of the SSNMs
Table 4 shows the evaluation results of the SSNMs. Similarly, to guarantee the effectiveness of the training of the SSNMs, the corresponding learning framework of the model was built with reference to [55].
Table 4.
Experimental results of the SSNMs.
From Table 4, the AC-value, p-value and R-value of the model accuracy evaluation results for U-Net based on PyTorch1.2.0 were the highest at 98.37%, 89.11% and 90.28%, respectively. For PSPNet based on TensorFlow2.2.0, the AC-value, p-value and R-value of the model accuracy evaluation results were the lowest at 97.86%, 85.62% and 87.86%, respectively. For DeepLabV3+ based on PyTorch1.2.0, the accuracy evaluation results were between the other two models, and its AC-value, p-value and R-value were 98.20%, 87.58% and 90.12%, respectively. It was observed that the evaluation index values of the U-Net were slightly higher than those of DeepLabV3+ and PSPNet. In summary, it can be concluded that the U-Net has the strongest learning ability for the crack features and could be preferred as a network model for fine segmentation.
3. Coarse–Fine Combined “Double Detection + Single Segmentation” Fine Crack Detection
3.1. Ideas for Fine Crack Detection
To address the problem of incomplete detection and segmentation of bridge cracks due to the complex background and small crack proportion in the actual bridge crack images, an anti-interference “double detection + single segmentation” coarse–fine combined bridge crack detection method based on deep learning was proposed.
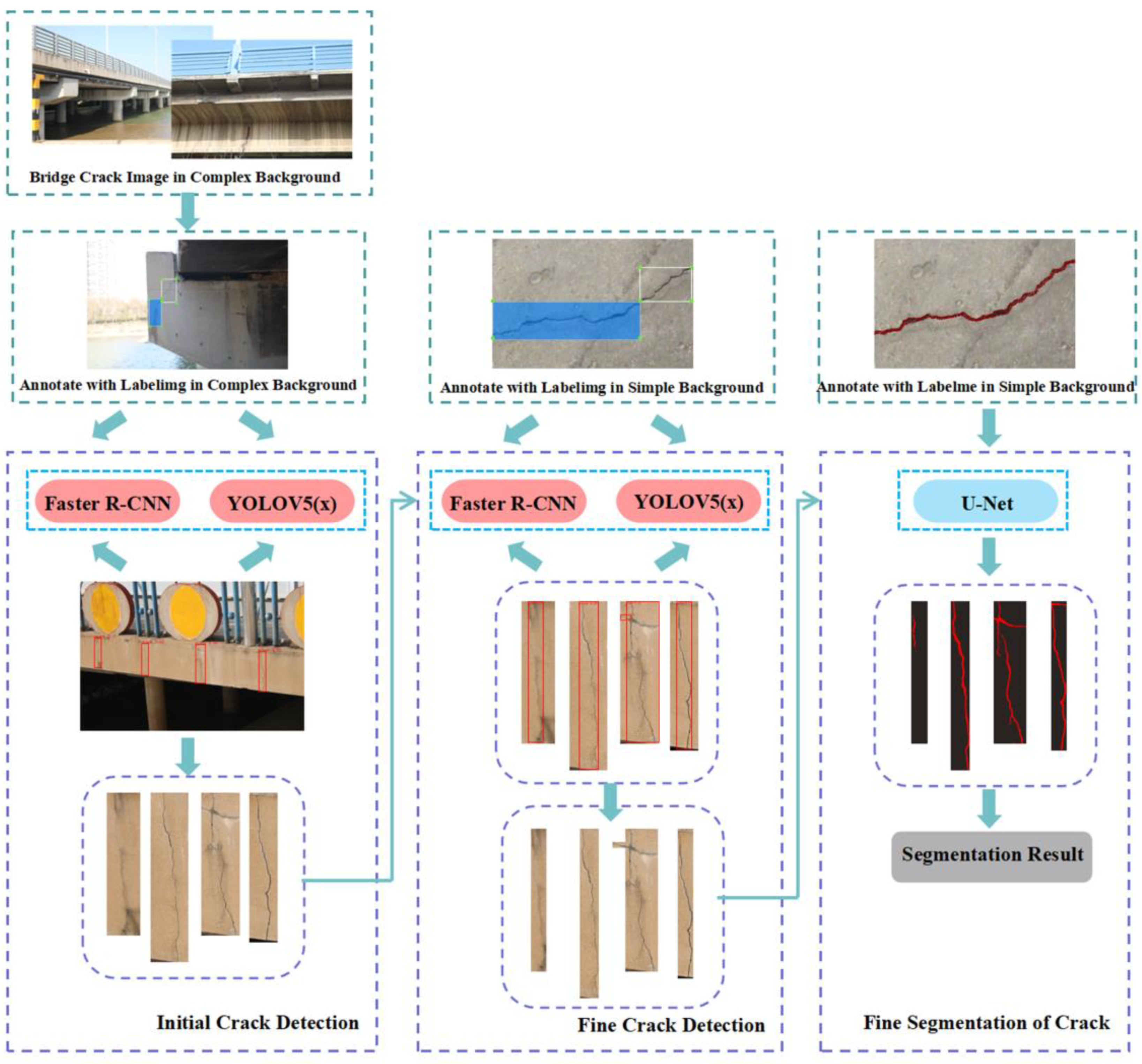
The three-step method of initial crack detection, fine crack detection and fine crack segmentation is adopted to make the detection results more perfect and accurate. It can effectively solve the problems of false detection, missing detection and difficult identification in crack detection and improve measurement accuracy and detection efficiency. First, the initial crack detection network based on deep learning was used to detect the original image and obtain a set of rectangular boxes that could contain cracks. The initial detection could eliminate the influence of the bridge crack background on the crack detection results and quickly screen the areas that could contain cracks, thus reducing the computational effort of the subsequent crack detection. The deep learning-based fine crack detection network was then used in each rectangular box to perform fine crack detection and localisation of the initially detected crack area to obtain a more accurate crack location. Fine crack detection could further identify the crack accurately, eliminate false detection and missing detection and improve crack detection accuracy. Finally, the fine-detected cracks were segmented using image semantic segmentation. This completed the fine detection of the cracks. The fine segmentation of the bridge cracks could accurately segment and extract the crack contour of the accurately identified crack area and provide accurate data for quantifying the crack width, which was conducive to improving the measurement accuracy of the crack width and facilitating further safety analysis and evaluation of the bridge structure. The specific technical route is shown in Figure 9. Through the “double detection + single segmentation” coarse–fine combined detection of bridge cracks, the method can resist some complex background interference, has good anti-interference performance and can improve the detection accuracy of cracks.
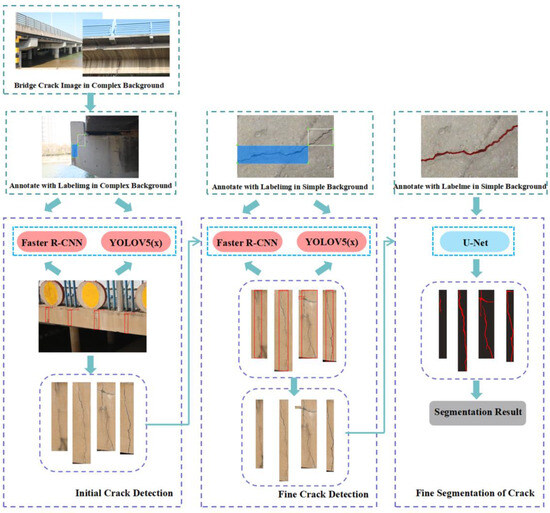
Figure 9.
Technical route to fine crack detection in concrete bridges.
3.2. Example of Fine Crack Detection
Based on the above experimental results, the Faster R-CNN model and the YOLOV5(x) model were used for initial and fine crack detection in bridge cases, respectively. The U-Net model was used for fine crack segmentation by combining shallow and deep features in a meaningful way. The technical process and results are shown in Figure 10. Among them, “F-F-U” means that Faster R-CNN is used for initial and fine crack detection, respectively, and U-Net is used for fine crack segmentation. Similarly, “F-V5-U” means that Faster R-CNN is used for initial crack detection, YOLOV5(x) for fine crack detection and U-Net for fine crack segmentation. “V5-F-U” means that YOLO V5(x) is used for initial crack detection, Faster R-CNN for fine crack detection and U-Net for fine crack segmentation. “V5-V5-U” means that YOLOV5(x) is used for initial and fine crack detection and U-Net for fine crack segmentation.

Figure 10.
Fine detection results of bridge cracks: (a) breakdown diagram of crack detection; (b) the location of the bridge crack detection results (V5-V5-U).
From the experimental results in Figure 10a, the following could be seen: (1) The combined F-F-U model is used to detect cracks in bridges with high-resolution and complex backgrounds. The Faster R-CNN model locates three crack regions in the image in the initial detection stage and further detects the initially located crack region in the fine detection stage to obtain a series of smaller rectangular regions containing crack information. Through the above two detection steps, the interfering factors such as the fence and road surface on the image are completely eliminated, and the excess background information around the crack is further reduced, which greatly reduces the difficulty of the U-Net model in the fine segmentation stage. However, due to the lack of detection in the fine detection stage, the final crack detection results are not complete. (2) The combined F-V5-U mode was adopted to detect the bridge crack image under a high-resolution and complex background. Compared with the Faster R-CNN model, the YOLOV5(x) model only filtered and divided the background into both sides of the entire crack in the fine detection stage to ensure the integrity of the crack but still caused a lack of detection. It also misdetected the shadow under the bridge as a crack. However, the U-Net model can effectively discriminate the false detection information in the fine segmentation stage and finally obtain the crack profile information with high accuracy. (3) The combined V5-F-U mode is used to detect the bridge crack images under high-resolution and complex backgrounds. The YOLOV5(x) model has better anti-interference for the complex background information in the image and locates four crack regions in the image at the initial detection stage. However, the Faster R-CNN model has both false detections and missing detections at the fine detection stage, resulting in poor connectivity of the crack detection results obtained by fine segmentation. (4) The combined V5-V5-U model is used to detect the bridge crack images in high-resolution and complex backgrounds. The YOLOV5(x) model also has better anti-interference for the complex background formation in the image and locates four crack regions in the image at the initial detection stage. In the fine detection stage, the YOLOV5(x) model performs a more accurate detection of the crack region according to the rectangular crack region found in the preliminary detection so as to reduce the interference of the background around the crack on the fine segmentation of the crack and ensure the integrity of the crack as much as possible. Thus, the U-Net model can obtain the most comprehensive crack contour information and the most accurate segmentation results in the fine segmentation stage.
It could also be seen from Figure 10b that the application of the V5-V5-U combined mode in bridge crack detection could reflect the comprehensive, refined and strong anti-interference performance of the crack detection results of “double detection + single segmentation”, which had important guiding significance for the practical application of crack detection technology.
4. Discussion
The instance segmentation algorithm represented by Mask R-CNN [56] could perform the dual tasks of object detection and semantic segmentation simultaneously. However, as the FCN segmentation algorithm was applied to the R-CNN algorithm, its computational efficiency was low. For the object with complex crack contour information in particular, its crack segmentation accuracy was far from the practical engineering requirements. Inspired by the idea of Mask R-CNN, Ji et al. [39] proposed a two-stage crack-detecting scheme for concrete bridges. First, the DBCC-Net model was used to realise the coarse detection of cracks in concrete bridges based on image slice classification. The complete crack shape of the concrete bridge is then extracted from the locations suggested by the SSNM. Yue et al. [57] proposed a multitask integrated crack detection algorithm. First, the crack feature was extracted using the object detection algorithm and the feature information was passed to the classification, regression and segmentation network modules, respectively. Then, using the results of classification and localisation, a crack object detection localisation map was generated, and this localisation map was calibrated against the concatenated domain of the semantic segmentation results. By calibrating the submodule, only the connected domains containing cracks were retained. The aforementioned methods enhance the performance of crack segmentation to some extent, but it is still difficult to obtain high-performance crack detection in the presence of factors such as the complicated background, the small percentage of cracks themselves and the variable topology.
In this paper, a coarse–fine combined bridge crack detection method of “double detection + single segmentation” based on deep learning was proposed. The initial detection of the crack image was first performed by a deep learning-based initial crack detection network, and a set of rectangular boxes containing cracks was obtained. Then, a deep learning-based fine crack detection network was used within each rectangular box to fine-detect and locate the initially detected crack areas to obtain more accurate crack locations. Finally, image semantic segmentation technology was used for fine segmentation of the detected cracks to complete the fine detection of the bridge cracks. Among them, the coarse detection stage could exclude the influence of the complex background of the bridge cracks on the crack detection results, and it could quickly screen out the areas that might contain cracks, reduce the computational effort of the subsequent fine detection and improve the effectiveness of crack detection. In the fine detection stage, the coarse detection results of bridge cracks could be further accurately identified, false detection could be eliminated and the detection accuracy of bridge cracks could be improved. In the fine segmentation stage of bridge cracks, the features of the detected cracks could be accurately segmented and extracted, and the highly accurate contour information of the cracks could be obtained, providing accurate data for the subsequent quantification of the bridge crack width.
5. Conclusions
To solve the incomplete crack detection and segmentation caused by the complex background and small proportion in the actual bridge crack images, this paper proposed a coarse–fine combined bridge crack detection method of “double detection + single segmentation” based on deep learning. The images of old civil bridges and viaduct bridges against a complex background and the images of a bridge crack against a simple background were used as datasets. By setting up model effectiveness evaluation experiments, the efficient Faster R-CNN and YOLOV5(x) and U-Net were selected as the basic networks for fine crack detection, the bridge crack refined detection was realised, and the effectiveness and practicality of the selected network model for crack refined detection were verified.
In the experiment, the YOLOV5(x) model was preferred for the initial and fine detection of bridge cracks, as it could preserve the original shape of the cracks and had a strong anti-interference capability. The detected crack information was accurate, detailed and complete. The preferred U-Net model was applied for fine crack segmentation; the AC-value of its crack segmentation results was as high as 98.37%, and the crack segmentation effect was fine and complete.
The “double detection + single segmentation” coarse–fine combined bridge crack detection method based on deep learning can realise the high efficiency and fine detection of bridge cracks and can provide help for future bridge crack detection. It also has a certain reference value for high-quality image processing and application in AI intelligent detection of construction damage in real time.
Author Contributions
Conceptualization, K.M. and M.H.; methodology, K.M. and X.M.; validation, X.M.; formal analysis, M.H.; investigation, J.L. and J.M.; resources, J.M.; data curation, X.M. and M.H.; writing—original draft preparation, X.M. and M.H; writing—review and editing, K.M.; visualization, J.L.; supervision, Y.X.; project administration, K.M.; funding acquisition, Y.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Henan Provincial Science and Technology Research Project (Grant No. 222102220035).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data will be made available on request.
Acknowledgments
The authors would like to thank the team for sharing the crack image dataset and the reviewers for their insightful comments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lu, J.; Yao, Z. A concrete crack recognition method based on progressive cascade convolution neural network. Ind. Constr. 2021, 51, 30–36. [Google Scholar]
- Ren, J.; Zhao, G.; Ma, Y.; Zhao, D.; Liu, T.; Yan, J. Automatic pavement crack detection fusing attention mechanism. Electronics 2022, 11, 3622. [Google Scholar] [CrossRef]
- Zhou, S.; Pan, Y.; Huang, X.; Yang, D.; Ding, Y.; Duan, R. Crack texture feature identification of fiber reinforced concrete based on deep learning. Materials 2022, 15, 3940. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Kurian, B.; Zhang, W.; Cai, C.S.; Liu, Y. Fatigue damage prognosis of steel bridges under traffic loading using a time-based crack growth method. Eng. Struct. 2021, 237, 112162. [Google Scholar] [CrossRef]
- Liang, X.; Cheng, Y.; Zhang, R.; Zhao, F. Bridge crack classification and measurement method based on deep convolution neural network. J. Comput. Appl. 2020, 40, 1056–1061. [Google Scholar]
- Liu, X.; Chen, Y.; Zhu, A.; Yang, J.; He, G. Tunnel crack identification based on deep learning. J. Guangxi Univ. 2018, 43, 2243–2251. [Google Scholar]
- Huyan, J.; Li, W.; Tighe, S.; Zhai, J.; Xu, Z.; Chen, Y. Detection of sealed and unsealed cracks with complex backgrounds using deep convolutional neural network. Autom. Constr. 2019, 107, 102946. [Google Scholar] [CrossRef]
- Li, F.; Lan, Z.; Cao, J. Acquirement and analysis of bridge crack images. Intell. Autom. Soft Comput. 2010, 16, 687–694. [Google Scholar] [CrossRef]
- He, Z.; Jiang, S.; Zhang, J.; Wu, G. Automatic damage detection using anchor-free method and unmanned surface vessel. Autom. Constr. 2022, 133, 104017. [Google Scholar] [CrossRef]
- Song, G.; Gu, H.; Mo, Y.L.; Hsu, T.T.C.; Dhonde, H. Concrete structural health monitoring using embedded piezoceramic transducers. Smart Mater. Struct. 2007, 16, 959–968. [Google Scholar] [CrossRef]
- Han, Q.; Xu, J.; Carpinteri, A.; Lacidogna, G. Localization of acoustic emission sources in structural health monitoring of masonry bridge. Struct. Control Health Monit. 2015, 22, 314–329. [Google Scholar] [CrossRef]
- Xu, J.; Dong, Y.; Zhang, Z.; Li, S.; He, S.; Li, H. Full scale strain monitoring of a suspension bridge using high performance distributed fiber optic sensors. Meas. Sci. Technol. 2016, 27, 124017. [Google Scholar] [CrossRef]
- Cheng, H.; Miyojim, M. Automatic pavement distress detection system. Inform. Sci. 1998, 108, 219–240. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, Y. Research on pavement crack recognition methods based on image processing. In Proceedings of the Third International Conference on Digital Image Processing (ICDIP 2011), Chengdu, China, 15–17 April 2011. [Google Scholar]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Leggieri, V.; Uva, G. View VULMA: Data set for training a machine-learning tool for a fast vulnerability analysis of existing buildings. Data 2022, 7, 4. [Google Scholar] [CrossRef]
- Jiang, Y.; Pang, D.; Li, C. A deep learning approach for fast detection and classification of concrete damage. Autom. Constr. 2021, 128, 103785. [Google Scholar] [CrossRef]
- Ochoa-Ruiz, G.; Angulo-Murillo, A.A.; Ochoa-Zezzatti, A.; Aguilar-Lobo, L.M.; Vega-Fernández, J.A.; Natraj, S. An asphalt damage dataset and detection system based on retinanet for road conditions assessment. Appl. Sci. 2020, 10, 3974. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Zhang, Z.; Shen, J.; Wang, H. Real-time water surface object detection based on improved Faster R-CNN. Sensors 2019, 19, 3523. [Google Scholar] [CrossRef]
- Jia, J.; Fu, M.; Liu, X.; Zheng, B. Underwater object detection based on improved EfficientNet. Remote Sens. 2022, 14, 4487. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Yu, P.; Wang, H.; Zhao, X.; Ruan, G. An algorithm for target detection of engineering vehicles based on improved centernet. Comput. Mater. Contin. 2022, 73, 4261–4276. [Google Scholar] [CrossRef]
- Yu, P.; Wang, H.; Zhao, X.; Ruan, G. A research on an improved Unet-based concrete crack detection algorithm. Struct. Health Monit. 2021, 20, 1864–1879. [Google Scholar]
- Fu, H.; Meng, D.; Li, W.; Wang, Y. Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+. J. Mar. Sci. Eng. 2021, 9, 671. [Google Scholar] [CrossRef]
- Amo-Boateng, M.; Ekow Nkwa Sey, N.; Ampah Amproche, A.; Kyereh Domfeh, M. Instance segmentation scheme for roofs in rural areas based on Mask R-CNN. Egypt. J. Remote Sens. Space Sci. 2022, 25, 569–577. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, B.; Wang, H.; Xu, L.; Li, Y.; Liu, Z. Detection of the drivable area on high-speed road via YOLACT. Signal Image Video Process. 2022, 16, 1623–1630. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Nettis, A.; Renò, V.; Uva, G. Physical interpretation of machine learning-based recognition of defects for the risk management of existing bridge heritage. Eng. Fail. Anal. 2023, 149, 107237. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Lin, Y.; Nie, Z.; Ma, H. Structural damage detection with automatic feature-extraction through deep learning. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 1025–1046. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.H. Combining Faster R-CNN and Model-Driven Clustering for elongated object detection. IEEE Trans. Image Process. 2020, 29, 2052–2065. [Google Scholar] [CrossRef]
- Nguyen, H. Improving Faster R-CNN framework for fast vehicle detection. Math. Probl. Eng. 2019, 3, 3808064. [Google Scholar] [CrossRef]
- Liao, Y.; Li, W. Bridge crack detection method based on convolution neural network. Comput. Eng. Des. 2021, 4, 2366–2372. [Google Scholar]
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck target recognition in side-scan sonar images by improved YOLOv3 model based on transfer learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar] [CrossRef]
- BaniMustafa, A.; AbdelHalim, R.; Bulkrock, O.; Al-Hmouz, A. Deep learning for assessing severity of cracks in concrete structures. Int. J. Comput. Commun. 2023, 18, 4977. [Google Scholar] [CrossRef]
- Yadav, D.P.; Kishore, K.; Gaur, A.; Kumar, A.; Singh, K.U.; Singh, T.; Swarup, C. A novel multi-scale feature fusion-based 3SCNet for building crack detection. Sustainability 2022, 14, 16179. [Google Scholar] [CrossRef]
- Wan, C.; Xiong, X.; Wen, B.; Gao, S.; Fang, D.; Yang, C.; Xue, S. Crack detection for concrete bridges with imaged based deep learning. Sci. Prog. 2022, 105, 368504221128487. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Chen, W.; Wang, L.; Zhai, C.; Hu, X.; Sun, L.; Tian, Y.; Huang, X.; Jiang, L. Convolutional neural networks (CNNs)-based multi-category damage detection and recognition of high-speed rail (HSR) reinforced concrete (RC) bridges using test images. Eng. Struct. 2023, 276, 115306. [Google Scholar] [CrossRef]
- Ji, K.; Zhang, Z.; Yu, J.; Dang, J. A deep learning-based method for pixel-level crack detection on concrete bridges. IET Image Process. 2022, 16, 2609–2622. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Li, R.; Yu, J.; Li, F.; Yang, R.; Wang, Y.; Peng, Z. Automatic bridge crack detection using unmanned aerial vehicle and Faster R-CNN. Constr. Build. Mater. 2023, 362, 129659. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference, Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Yan, K.; Zhang, Z. Automated asphalt highway pavement crack detection based on deformable single shot multi-box detector under a complex environment. IEEE Access 2021, 9, 150925–150938. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, N.; Yu, M.; Ren, H.; Tao, R.; Zhao, L. YOLO-v4 small object detection algorithm fused whith L-α. J. Harbin Univ. 2023, 28, 37–45. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Xie, T.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; Abrahim, V. Ultralytics/yolov5: v6.0—YOLOv5n “Nano” Models, Roboflow Integration, Tensor, Flow Export, Open, CV DNN Support; Zenodo Technical Report; Zenodo: Geneva, Switzerland, 2021. [Google Scholar]
- Yu, G.; Zhou, X. An improved YOLOv5 crack detection method combined with a bottleneck transformer. Mathematics 2023, 11, 2377. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In U-Net: Convolutional Networks for Biomedical Image Segmentation, Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, 18th International Conference, Munich, Germany, 5–9 October 2015; Ronneberger, O., Fischer, P., Brox, T., Eds.; Springer: Berlin/Heidelberg, Germany; pp. 234–241.
- Su, H.; Wang, X.; Han, T.; Wang, Z.; Zhao, Z.; Zhang, P. Research on a U-Net bridge crack identification and feature-calculation methods based on a CBAM attention mechanism. Buildings 2022, 12, 1561. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Li, G.; Fang, Z.; Mohammed, A.M.; Liu, T.; Deng, Z. Automated bridge crack detection based on improving encoder–decoder network and strip pooling. J. Infrastruct. Syst. 2023, 29, 04023004. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, X.; Yuan, J.; Yue, X.; Zhang, W. Research on crack segmentation and feature quantification of concrete beams based on optimized DeepLabv3+. Sci. Technol. Eng. 2023, 23, 3794–3803. [Google Scholar]
- Li, L.; Ma, W.; Li, L.; Lu, C. Research on detection algorithm for bridge cracks based on deep learning. Acta Autom. Sin. 2019, 45, 1727–1742. [Google Scholar]
- Ma, K.; Meng, X.; Hao, M.; Huang, G.; Hu, Q.; He, P. Research on the efficiency of bridge crack detection by coupling deep learning frameworks with convolutional neural networks. Sensors 2023, 23, 7272. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yue, Q.; Xu, G.; Liu, X. Crack intelligent recognition and bridge monitoring methods. China J. Highw. Transp. 2024, 37, 16–28. [Google Scholar]



































Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).