

Novel Prognostic Methodology of Bootstrap Forest and Hyperbolic Tangent Boosted Neural Network for Aircraft System

Abstract
:Featured Application
Abstract
1. Introduction
- The various techniques employed in the field of artificial intelligence include neural networks, fuzzy logic, decision trees, support vector machines (SVMs), anomaly detection algorithms, reinforcement learning, classification, clustering, and Bayesian methods.
- Academic research and practical applications commonly employ various conventional numerical techniques, such as wavelets, Kalman filters, particle filters, regression, and statistical methods.
- There are various statistical approaches utilised in research, such as the gamma process, hidden Markov model, regression-based model, relevance vector machine (RVM), and numerous more.
2. Proposed Data-Driven Approaches
2.1. Bootstrap Forest
- In order to enhance the robustness of the analysis, it is advisable to use a bootstrap sampling strategy for the selection of data for each individual tree.
- The individual decision tree is constructed using a recursive partitioning algorithm. To perform each split, a set of predictors is randomly chosen, and the order of the predictors within the set is randomised. The procedure of partitioning should be iterated until a predetermined termination criterion, as delineated in the bootstrap forest configuration, is met.
- The iterative procedure of executing steps one and two will persist until the desired quantity of trees specified is attained, or unless early stopping is activated.
- To begin, it is recommended to apply an initial layer.
- Compute the residuals. The numbers mentioned are obtained by subtracting the expected mean of observations contained inside a leaf from their actual numerical values.
- Employ a layer on the remaining values.
- The construction of the additive tree is necessary. In order to get the total expected value across several layers for a given observation, it is necessary to aggregate the projected values obtained from each individual layer.
- The aforementioned procedure, as outlined in steps two through four, ought to be iteratively replicated until the appropriate quantity of layers has been attained. In the event that a validation measure is utilised, it is advisable to persist with the iterative process until the addition of another layer ceases to result in an enhancement of the validation statistics.
2.2. Hyperbolic Tangent Neural Network
2.3. Hidden Layer Structure
2.4. Prognostic Problem
3. Prediction Dataset and Boosting Process
4. Discussion and Results
- A method was presented by [5] that uses data fusion with stage division to forecast the RUL of a system. This method, called an ensemble RUL prediction method, has been shown to achieve considerable gains in accuracy. The utilisation of bootstrap forests and hyperbolic tangent neural networks in our approach yields similar results while providing increased adaptability and resilience in managing nonlinear deterioration patterns.
- Ref. [2] conducted a comprehensive analysis of predictive maintenance for defence fixed-wing aircraft, emphasising the importance of flexible and precise prognostic models. The hybrid model we have developed successfully integrates numerous prediction algorithms to ensure both high accuracy and reliability.
- Ref. [29] criticised the reliability prediction techniques used in avionics applications, highlighting the constraints of conventional methods in dynamic and intricate settings. The suggested neural boosted model overcomes these constraints by providing a prediction framework that is more dynamic and adaptive.
- The study conducted by [30] investigated the use of multi-task learning to forecast the RUL in different working settings. The results showed that advanced learning approaches have the potential to enhance the accuracy of RUL predictions. The findings of our study demonstrate that the combination of bootstrap forests and neural networks can produce comparable or better performance, especially when dealing with diverse operational scenarios.
- The significance of feature fusion and similarity-based prediction models for precise estimation of RUL was highlighted by [1]. Our suggested model improves upon current approaches by using hyperbolic tangent functions and bootstrap aggregation, resulting in increased prediction accuracy.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Wang, Z.; Li, F.; Li, Y.; Zhang, X.; Shi, H.; Dong, L.; Ren, W. An Ensembled Remaining Useful Life Prediction Method with Data Fusion and Stage Division. Reliab. Eng. Syst. Saf. 2024, 242, 109804. [Google Scholar] [CrossRef]
- Scott, M.J.; Verhagen, W.J.C.; Bieber, M.T.; Marzocca, P. A Systematic Literature Review of Predictive Maintenance for Defence Fixed-Wing Aircraft Sustainment and Operations. Sensors 2022, 22, 7070. [Google Scholar] [CrossRef] [PubMed]
- Pandian, G.P.; Das, D.; Li, C.; Zio, E.; Pecht, M. A Critique of Reliability Prediction Techniques for Avionics Applications. Chin. J. Aeronaut. 2018, 31, 10–20. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, X.; Zio, E.; Li, L. Multi-Task Learning Boosted Predictions of the Remaining Useful Life of Aero-Engines under Scenarios of Working-Condition Shift. Reliab. Eng. Syst. Saf. 2023, 237, 109350. [Google Scholar] [CrossRef]
- Fu, S.; Avdelidis, N.P. Prognostic and Health Management of Critical Aircraft Systems and Components: An Overview. Sensors 2023, 23, 8124. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Teng, W.; Peng, D.; Ma, T.; Wu, X.; Liu, Y. Feature Fusion Model Based Health Indicator Construction and Self-Constraint State-Space Estimator for Remaining Useful Life Prediction of Bearings in Wind Turbines. Reliab. Eng. Syst. Saf. 2023, 233, 109124. [Google Scholar] [CrossRef]
- Lin, Y.H.; Ding, Z.Q.; Li, Y.F. Similarity Based Remaining Useful Life Prediction Based on Gaussian Process with Active Learning. Reliab. Eng. Syst. Saf. 2023, 238, 109461. [Google Scholar] [CrossRef]
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What We Know and What Is Left to Attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Okoh, C.; Roy, R.; Mehnen, J. Predictive Maintenance Modelling for Through-Life Engineering Services. Procedia CIRP 2017, 59, 196–201. [Google Scholar] [CrossRef]
- Chen, J.; Li, D.; Huang, R.; Chen, Z.; Li, W. Aero-Engine Remaining Useful Life Prediction Method with Self-Adaptive Multimodal Data Fusion and Cluster-Ensemble Transfer Regression. Reliab. Eng. Syst. Saf. 2023, 234, 109151. [Google Scholar] [CrossRef]
- Bootstrap Aggregating. Available online: https://en.wikipedia.org/w/index.php?title=Bootstrap_aggregating&oldid=1223807758 (accessed on 11 March 2024).
- Aria, M.; Cuccurullo, C.; Gnasso, A. A Comparison among Interpretative Proposals for Random Forests. Mach. Learn. Appl. 2021, 6, 100094. [Google Scholar] [CrossRef]
- Boosting (Machine Learning). Available online: https://en.wikipedia.org/w/index.php?title=Boosting_(machine_learning)&oldid=1222981999 (accessed on 11 March 2024).
- Chou, Y.-C.; Chuang, H.H.-C.; Chou, P.; Oliva, R. Supervised Machine Learning for Theory Building and Testing: Opportunities in Operations Management. J. Oper. Manag. 2023, 69, 643–675. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3147–3155. [Google Scholar]
- Altman, N.; Krzywinski, M. Points of Significance: Ensemble Methods: Bagging and Random Forests. Nat. Methods 2017, 14, 933–934. [Google Scholar] [CrossRef]
- Zhao, C.; Wu, D.; Huang, J.; Yuan, Y.; Zhang, H.-T.; Peng, R.; Shi, Z. BoostTree and BoostForest for Ensemble Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8110–8126. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.-H.; Ullah, A.; Wang, R. Bootstrap Aggregating and Random Forest. In Macroeconomic Forecasting in the Era of Big Data; Springer: Berlin/Heidelberg, Germany, 2020; pp. 389–429. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Ezzat, D.; Hassanien, A.E.; Darwish, A.; Yahia, M.; Ahmed, A.; Abdelghafar, S. Multi-Objective Hybrid Artificial Intelligence Approach for Fault Diagnosis of Aerospace Systems. IEEE Access 2021, 9, 41717–41730. [Google Scholar] [CrossRef]
- Chong, D.J.S.; Chan, Y.J.; Arumugasamy, S.K.; Yazdi, S.K.; Lim, J.W. Optimisation and Performance Evaluation of Response Surface Methodology (RSM), Artificial Neural Network (ANN) and Adaptive Neuro-Fuzzy Inference System (ANFIS) in the Prediction of Biogas Production from Palm Oil Mill Effluent (POME). Energy 2023, 266, 126449. [Google Scholar] [CrossRef]
- De Ryck, T.; Lanthaler, S.; Mishra, S. On the Approximation of Functions by Tanh Neural Networks. Neural Netw. 2021, 143, 732–750. [Google Scholar] [CrossRef]
- Radhakrishnan, A.; Belkin, M.; Uhler, C. Wide and Deep Neural Networks Achieve Consistency for Classification. Proc. Natl. Acad. Sci. USA 2023, 120, e2208779120. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation Functions in Deep Learning: A Comprehensive Survey and Benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Karniadakis, G.E. How Important Are Activation Functions in Regression and Classification? A Survey, Performance Comparison, and Future Directions. arXiv 2022, arXiv:2209.02681. [Google Scholar] [CrossRef]
- List of Things Named after Carl Friedrich Gauss. Available online: https://en.wikipedia.org/w/index.php?title=List_of_things_named_after_Carl_Friedrich_Gauss&oldid=1223714204 (accessed on 22 March 2024).
- Surucu, O.; Gadsden, S.A.; Yawney, J. Condition Monitoring Using Machine Learning: A Review of Theory, Applications, and Recent Advances. Expert. Syst. Appl. 2023, 221, 119738. [Google Scholar] [CrossRef]
- Chao, M.A.; Kulkarni, C.; Goebel, K.; Fink, O. Aircraft Engine Run-to-Failure Dataset under Real Flight Conditions for Prognostics and Diagnostics. Data 2021, 6, 5. [Google Scholar] [CrossRef]
- Tsui, K.L.; Chen, N.; Zhou, Q.; Hai, Y.; Wang, W. Prognostics and Health Management: A Review on Data Driven Approaches. Math. Probl. Eng. 2015, 2015, 793161. [Google Scholar] [CrossRef]
- Shi, J.; Yu, T.; Goebel, K.; Wu, D. Remaining Useful Life Prediction of Bearings Using Ensemble Learning: The Impact of Diversity in Base Learners and Features. J. Comput. Inf. Sci. Eng. 2020, 21, 021004. [Google Scholar] [CrossRef]
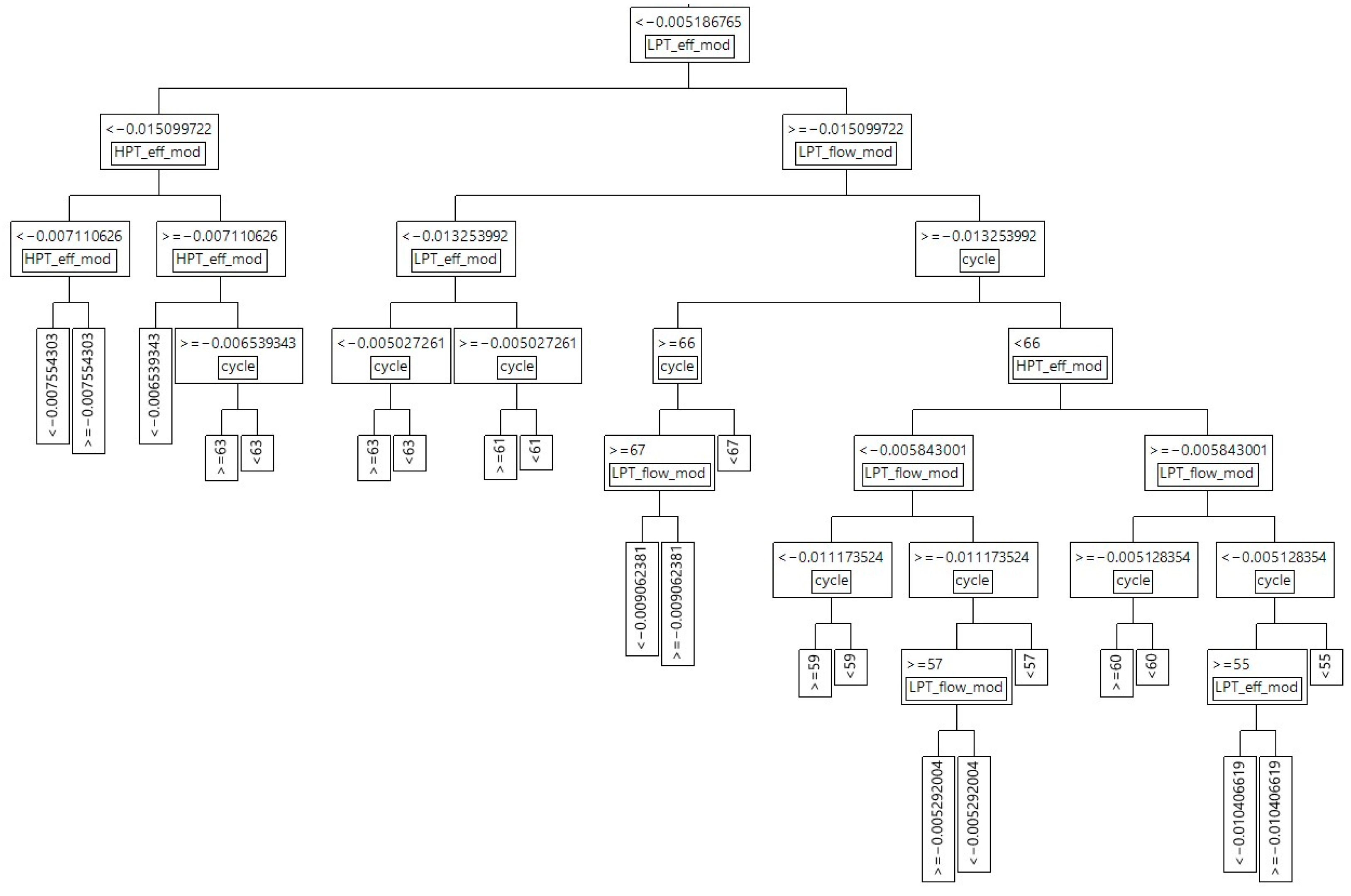


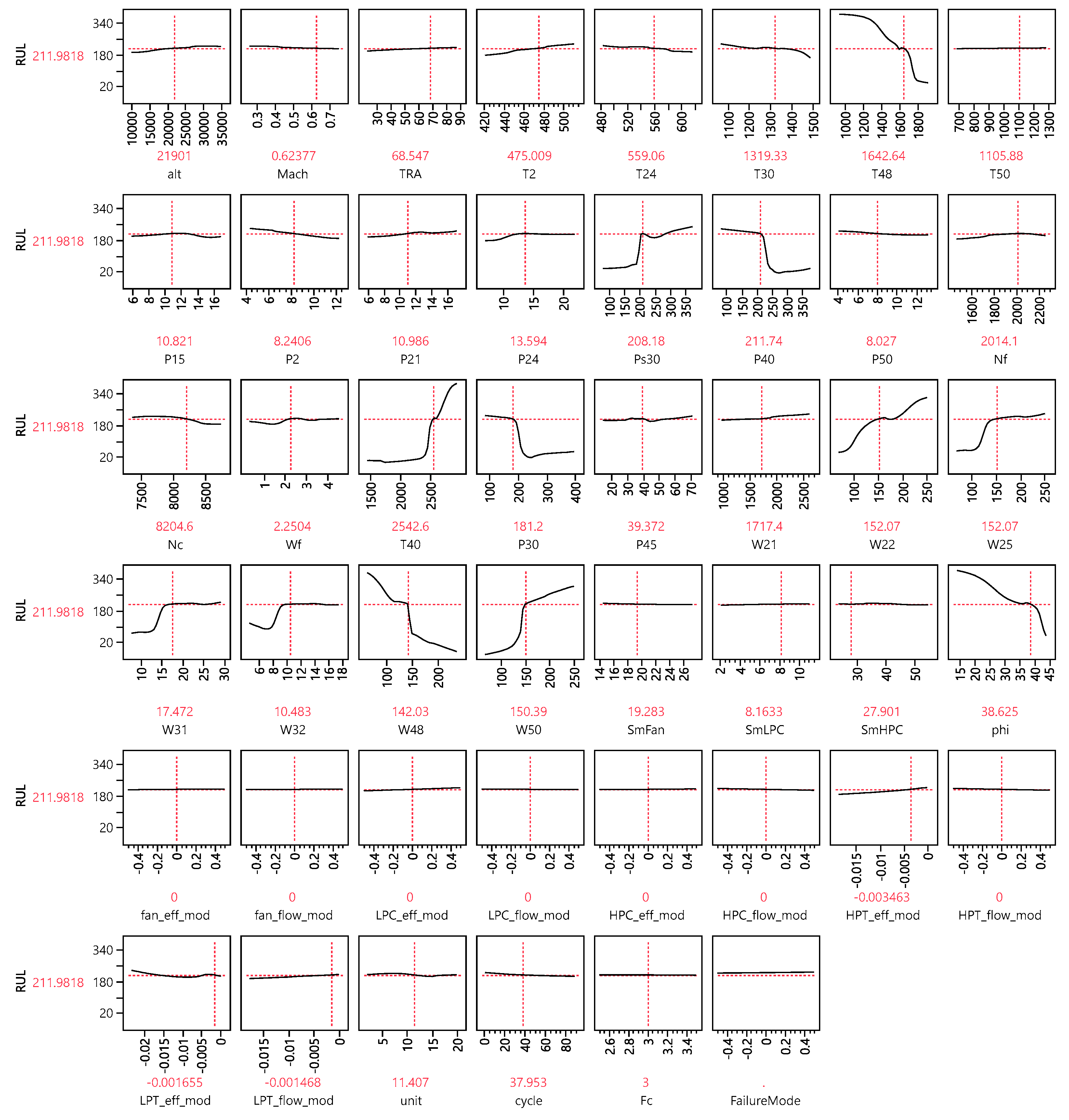



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Engine | Flight Class | Failure Quantity | Fan | LPC | HPC | HPT | LPT | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | F | E | F | E | F | E | F | E | F | ||||
| DS01 | 10 | 1,2,3 | 1 | Y | |||||||||
| DS02 | 9 | 1,2,3 | 2 | Y | Y | Y | |||||||
| DS03 | 15 | 1,2,3 | 1 | Y | Y | ||||||||
| DS04 | 10 | 2,3 | 1 | Y | Y | ||||||||
| DS05 | 10 | 1,2,3 | 1 | Y | Y | ||||||||
| DS06 | 10 | 1,2,3 | 1 | Y | Y | Y | Y | ||||||
| DS07 | 10 | 1,2,3 | 1 | Y | Y | ||||||||
| DS08 | 54 | 1,2,3 | 1 | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| Tree | Splits | Rank | OOB Loss | OOB Loss/N | RSquare | IB SSE | IB SSE/N | OOB N | OOB SSE | OOB SSE/N |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1069 | 19 | 348,428.61 | 0.179873 | 0.9996 | 588,249.73 | 0.1117613 | 1,937,081 | 345,175.5 | 0.1781936 |
| 2 | 1079 | 75 | 1,129,529.9 | 0.5835069 | 0.9988 | 1,942,589.7 | 0.3690718 | 1,935,761 | 1,125,875.5 | 0.5816191 |
| 3 | 1137 | 48 | 657,177.05 | 0.3395718 | 0.9993 | 1,118,063.7 | 0.2124204 | 1,935,311 | 653,461.42 | 0.3376519 |
| 4 | 1239 | 82 | 1,428,064.1 | 0.737793 | 0.9985 | 2,447,363.9 | 0.4649736 | 1,935,589 | 1,423,022.7 | 0.7351885 |
| 5 | 1037 | 9 | 301,566.33 | 0.1557748 | 0.9997 | 508,044.11 | 0.0965231 | 1,935,912 | 297,525.88 | 0.1536877 |
| 6 | 1139 | 58 | 773,725.04 | 0.3993993 | 0.9992 | 1,328,241.4 | 0.252352 | 1,937,222 | 769,885.82 | 0.3974174 |
| 7 | 1313 | 97 | 2,657,672 | 1.3728297 | 0.9973 | 4,515,957.2 | 0.8579847 | 1,935,908 | 2,651,303.7 | 1.3695401 |
| 8 | 1089 | 16 | 328,339.82 | 0.169505 | 0.9997 | 555,723.73 | 0.1055817 | 1,937,051 | 323,897.8 | 0.1672118 |
| 9 | 1147 | 78 | 1,180,913.6 | 0.6095186 | 0.9988 | 2,026,344.8 | 0.3849844 | 1,937,453 | 1,176,315.3 | 0.6071452 |
| 10 | 1017 | 18 | 347,915.85 | 0.1795507 | 0.9996 | 587,667.48 | 0.1116507 | 1,937,703 | 345,131.72 | 0.1781138 |
| 11 | 1301 | 96 | 2,520,584.1 | 1.3021806 | 0.9974 | 4,315,572.9 | 0.8199138 | 1,935,664 | 2,514,463 | 1.2990183 |
| 12 | 1121 | 45 | 621,068.46 | 0.3207995 | 0.9994 | 1,047,427.3 | 0.1990002 | 1,936,002 | 616,356.03 | 0.3183654 |
| 13 | 1053 | 14 | 320,291.75 | 0.1654456 | 0.9997 | 548,369.07 | 0.1041844 | 1,935,934 | 316,321.09 | 0.1633946 |
| 14 | 1197 | 50 | 690,715.86 | 0.3568014 | 0.9993 | 1,185,768.5 | 0.2252836 | 1,935,855 | 686,576.1 | 0.354663 |
| 15 | 1041 | 17 | 331,125.41 | 0.1710198 | 0.9997 | 556,257.31 | 0.1056831 | 1,936,182 | 326,746.89 | 0.1687584 |
| 16 | 1079 | 38 | 527,248.26 | 0.2724227 | 0.9995 | 900,814.16 | 0.1711453 | 1,935,405 | 524,716.96 | 0.2711148 |
| 17 | 1121 | 71 | 947,161.31 | 0.4894759 | 0.9990 | 1,630,965.7 | 0.3098665 | 1,935,052 | 942,616.88 | 0.4871274 |
| 18 | 1095 | 31 | 463,948.05 | 0.239569 | 0.9995 | 786,811.25 | 0.1494859 | 1,936,595 | 460,580.81 | 0.2378302 |
| 19 | 1053 | 3 | 212,820.83 | 0.1099359 | 0.9998 | 351,663.75 | 0.0668124 | 1,935,863 | 209,515.7 | 0.1082286 |
| 20 | 1053 | 7 | 282,493.4 | 0.1458563 | 0.9997 | 486,220.64 | 0.0923768 | 1,936,793 | 279,462.69 | 0.1442915 |
| 21 | 1077 | 11 | 313,612.15 | 0.1619483 | 0.9997 | 533,892.63 | 0.101434 | 1,936,495 | 310,544.71 | 0.1603643 |
| Method | Penalty Function | Description |
|---|---|---|
| Squared | factors are believed to be influential in enhancing the predictive capacity of the model. | |
| Absolute | variables and suspects that only a subset of them significantly contribute to the predictive capacity of the model, either of the following approaches can be employed. | |
| Weight Decay | ||
| No Penalty | Does not employ a penalty. This option is suitable for situations where there is a substantial volume of data and expeditious completion of the fitting procedure is desired. Nevertheless, this alternative may result in models exhibiting inferior predictive accuracy compared to models that incorporate a penalty. |
| (a) Training Process | (b) Validation Process | ||||||
|---|---|---|---|---|---|---|---|
| Method | N | RSquare | RASE | Method | N | RSquare | RASE |
| K Nearest Neighbours | 5,263,447 | 1.0000 | 0.1386 | Neural Boosted | 1754307 | 0.9968 | 1.2711 |
| Bootstrap Forest | 5,263,447 | 1.0000 | 0.1468 | Bootstrap Forest | - | - | - |
| Boosted Tree | 5,263,447 | 0.9999 | 0.1603 | Boosted Tree | - | - | - |
| Neural Boosted | 3,509,140 | 0.9968 | 1.2688 | K Nearest Neighbours | - | - | - |
| Measures | Description |
|---|---|
| Generalised R2 | Generalised R2 extends the concept of the coefficient of determination (R2) to models that do not fit within the framework of linear regression. The adjusted coefficient of determination quantifies the percentage of variation accounted for by the model while taking into account the number of predictors. It is a useful metric for assessing the goodness of fit between different models. |
| Entropy R2 | It is a statistical measure commonly employed in the analysis of categorical data. The concept of entropy from information theory serves as the foundation for this assessment, which measures the decrease in uncertainty resulting from the model. Higher numbers suggest a model that effectively explains the variability in the categories. |
| R2 | Gives the RSquare for the model. |
| RASE | Gives the root average squared error. When the response is nominal or ordinal, the differences are between 1 and p, where p is the predicted probability of the response level. |
| Mean Abs Dev (MAD) | It quantifies the average absolute difference between expected and observed values, irrespective of their direction. It is a reliable indicator of the extent to which these faults are distributed. |
| Misclassification rate (MR) | The misclassification rate (MR) is a metric employed in classification problems to quantify the proportion of inaccurate predictions out of the total number of predictions made. It is a simplistic approach to assessing the frequency of the model’s inaccuracies. |
| -Loglikelihood | Provides the negative of the loglikelihood |
| SSE | Gives the error sums of squares. It is only available when the response is continuous. |
| Sum Freq | It represents the complete analysis of observations. When a neural network variable Freq is supplied, the Sum Freq function sums the frequency column values. |
| (a) Training Process | (b) Validation Process | ||
|---|---|---|---|
| Measures | Value | Measures | Value |
| R2 | 0.9967847 | R2 | 0.9967703 |
| RASE | 1.2688147 | RASE | 1.2710539 |
| MAD | 0.8863745 | MAD | 0.8882592 |
| -LogLikelihood | 5814721.2 | -LogLikelihood | 2910018 |
| SSE | 5649332.2 | SSE | 2834219.7 |
| Sum Freq | 3509140 | Sum Freq | 1754307 |
| R2 | RASE | SSE | |
|---|---|---|---|
| NtanH(3)NBoost(20) | Training: 0.9967847 Validation: 0.9967703 | Training: 1.2688147 Validation: 1.2710539 | Training: 5649332.2 Validation: 2834219.7 |
| [1] | Average R2: 0.994 | - | - |
| [30] | Average R2: 0.995 | - | - |
| [2] | - | Average: 1.35 | - |
| [3] | - | Average: 1.45 | - |
| [6] | - | - | Average: 6,000,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, S.; Avdelidis, N.P. Novel Prognostic Methodology of Bootstrap Forest and Hyperbolic Tangent Boosted Neural Network for Aircraft System. Appl. Sci. 2024, 14, 5057. https://doi.org/10.3390/app14125057
Fu S, Avdelidis NP. Novel Prognostic Methodology of Bootstrap Forest and Hyperbolic Tangent Boosted Neural Network for Aircraft System. Applied Sciences. 2024; 14(12):5057. https://doi.org/10.3390/app14125057
Chicago/Turabian StyleFu, Shuai, and Nicolas P. Avdelidis. 2024. "Novel Prognostic Methodology of Bootstrap Forest and Hyperbolic Tangent Boosted Neural Network for Aircraft System" Applied Sciences 14, no. 12: 5057. https://doi.org/10.3390/app14125057