
IFF-Net: Irregular Feature Fusion Network for Multimodal Remote Sensing Image Classification

Abstract
1. Introduction
- (1)
- In this study, we propose a novel approach for classifying multimodal remote sensing data using irregular feature extraction. To enhance the model’s generalization capability, we employ weight-sharing residual blocks in a cascaded manner for feature extraction and adjust the number of parallel branches to facilitate collaborative processing without introducing extra parameters.
- (2)
- By privatizing the judgment factors within the BN layer, we effectively substitute redundant information in the channel. This enables us to fully leverage the complementary advantages of multimodal remote sensing data, while also imposing sparse constraints on specific judgment factors to mitigate any undesired feature propagation.
- (3)
- A module for normalizing and calibrating features was developed to enhance information integration, optimize spatial information discrimination, and minimize redundancy. The self-attention module underwent a calibration process as part of this enhancement.
2. Materials and Methods
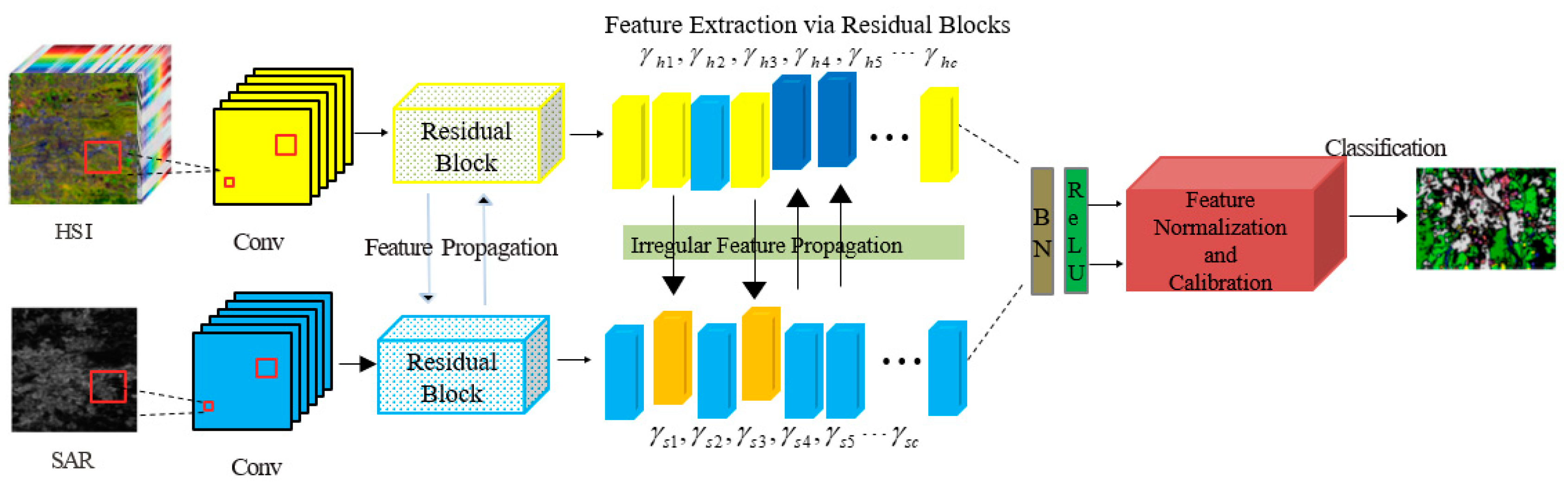
2.1. Feature Extraction via Residual Blocks
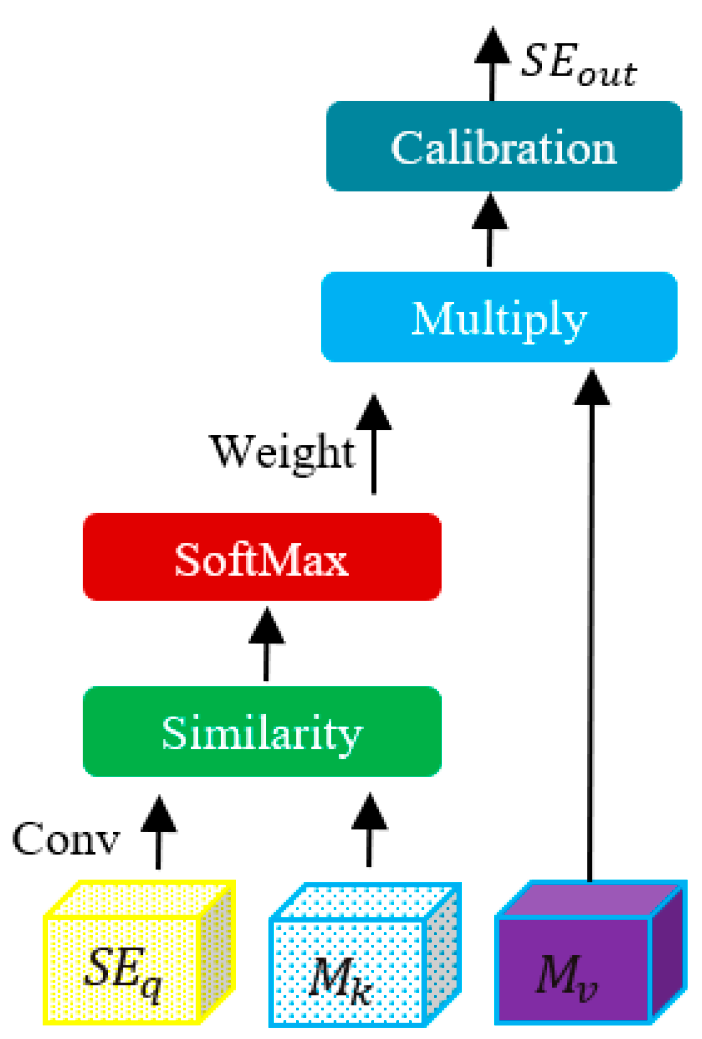
2.2. Irregular Feature Propagation
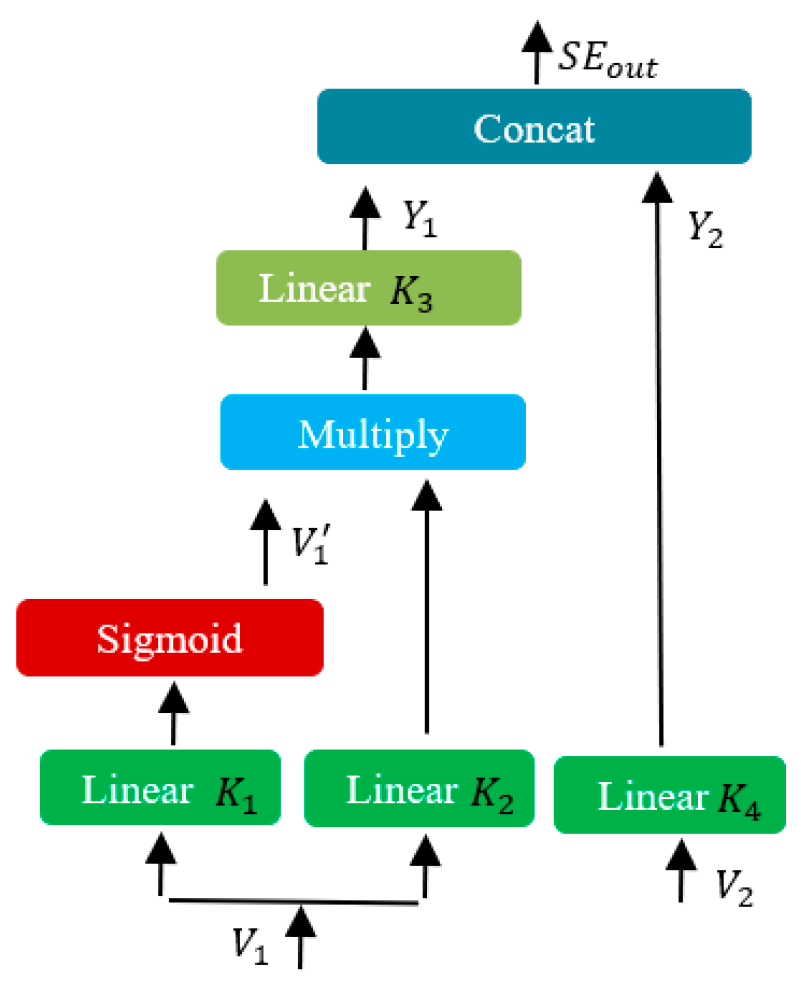
2.3. Feature Normalization and Calibration
3. Results
3.1. Data Description
3.2. Experimental Setup
3.3. Results and Analysis on Augsburg Data
3.4. Results and Analysis on Berlin Data
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Li, W.; Zhang, Y.; Tao, R.; Du, Q. Hyperspectral and LiDAR data classification based on structural optimization transmission. IEEE Trans. Cybern. 2022, 53, 3153–3164. [Google Scholar] [CrossRef]
- Yue, J.; Fang, L.; He, M. Spectral–spatial latent reconstruction for open-set hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 5227–5241. [Google Scholar] [CrossRef]
- Sun, L.; Cheng, S.; Zheng, Y.; Wu, Z.; Zhang, J. SPANet: Successive pooling attention network for semantic segmentation of remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 4045–4057. [Google Scholar] [CrossRef]
- Shirmard, H.; Farahbakhsh, E.; Müller, R.D.; Chandra, R. A review of machine learning in processing remote sensing data for mineral exploration. Remote Sens. Environ. 2022, 268, 112750. [Google Scholar] [CrossRef]
- Bin, J.; Zhang, R.; Wang, R.; Cao, Y.; Zheng, Y.; Blasch, E.; Liu, Z. An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery. Sensors 2022, 22, 7167. [Google Scholar] [CrossRef]
- Virtriana, R.; Riqqi, A.; Anggraini, T.S.; Fauzan, K.N.; Ihsan, K.T.N.; Mustika, F.C.; Suwardhi, D.; Harto, A.B.; Sakti, A.D.; Deliar, A.; et al. Development of spatial model for food security prediction using remote sensing data in west Java, Indonesia. ISPRS Int. J. Geo-Inf. 2022, 11, 284. [Google Scholar] [CrossRef]
- Wang, J.; Gao, F.; Dong, J.; Du, Q. Adaptive Drop Block-enhanced generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5040–5053. [Google Scholar] [CrossRef]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Dong, J.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517010. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, B.; Zhang, H.; Liu, H. Unsupervised hyperspectral and multispectral images fusion based on nonlinear variational probabilistic generative model. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 721–735. [Google Scholar] [CrossRef]
- Dabbiru, L.; Samiappan, S.; Nobrega, R.A.A.; Aanstoos, J.A.; Younan, N.H.; Moorhead, R.J. Fusion of synthetic aperture radar and hyperspectral imagery to detect impacts of oil spill in Gulf of Mexico. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1901–1904. [Google Scholar]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Deep learning for classification of hyperspectral data: A comparative review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef]
- Wang, Z.; Menenti, M. Challenges and opportunities in LiDAR remote sensing. Front. Remote Sens. 2021, 2, 641723. [Google Scholar] [CrossRef]
- Liao, W.; Pizurica, A.; Bellens, R.; Gautama, S.; Philips, W. Generalized graph-based fusion of hyperspectral and LiDAR data using morphological features. IEEE Geosci. Remote Sens. Lett. 2015, 12, 552–556. [Google Scholar] [CrossRef]
- Ghamisi, P.; Benediktsson, J.A.; Phinn, S. Land-cover classification using both hyperspectral and LiDAR data. Int. J. Image Data Fusion 2015, 6, 189–215. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Iwasaki, A. Fusion of hyperspectral and LiDAR data with a novel ensemble classifier. IEEE Geosci. Remote Sens. Lett. 2018, 15, 957–961. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Muñoz-Marí, J.; Rojo-Álvarez, J.L.; Martínez-Ramón, M. Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1822–1835. [Google Scholar] [CrossRef]
- Yan, L.; Cui, M.; Prasad, S. Joint Euclidean and angular distance-based embeddings for multisource image analysis. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1110–1114. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. CoSpace: Common subspace learning from hyperspectral-multispectral correspondences. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4349–4359. [Google Scholar] [CrossRef]
- Hong, D.; Chanussot, J.; Yokoya, N.; Kang, J.; Zhu, X.X. Learning shared cross-modality representation using multispectral-LiDAR and hyperspectral data. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1470–1474. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Ge, N.; Chanussot, J.; Zhu, X.X. Learnable manifold alignment (LeMA): A semi-supervised cross-modality learning framework for land cover and land use classification. ISPRS J. Photogramm. Remote Sens. 2019, 147, 193–205. [Google Scholar] [CrossRef]
- Hu, J.; Hong, D.; Zhu, X.X. MIMA: MAPPER-induced manifold alignment for semi-supervised fusion of optical image and polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9025–9040. [Google Scholar] [CrossRef]
- Mura, M.D.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and opportunities of multimodality and data fusion in remote sensing. Proc. IEEE 2015, 103, 1585–1601. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Hong, D.; Kang, J.; Yokoya, N.; Chanussot, J. Graph-induced aligned learning on subspaces for hyperspectral and multispectral data. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4407–4418. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Ghamisi, P.; Hong, D.; Xia, G.; Liu, Q. Classification of hyperspectral and LiDAR data using coupled CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4939–4950. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Hang, R.; Zhang, B.; Chanussot, J. Deep encoder-decoder networks for classification of hyperspectral and LiDAR data. IEEE Geosci. Remote. Sens. Lett. 2020, 19, 5500205. [Google Scholar] [CrossRef]
- Gadiraju, K.K.; Ramachandra, B.; Chen, Z.; Vestavia, R.R. Multimodal deep learning-based crop classification using multispectral and multitemporal satellite imagery. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 3234–3242. [Google Scholar]
- Suel, E.; Bhatt, S.; Brauer, M.; Flaxman, S.; Ezzati, M. Multimodal deep learning from satellite and street-level imagery for measuring income, overcrowding, and environmental deprivation in urban areas. Remote Sens. Environ. 2021, 257, 112339. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Tao, R.; Li, H.; Du, Q. Information fusion for classification of hyperspectral and LiDAR data using IP-CNN. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5506812. [Google Scholar] [CrossRef]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Convolutional recurrent neural networks for hyperspectral data classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. Spectral Former: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518615. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Rasti, B.; Plaza, A.; Chanussot, J. Multimodal fusion transformer for remote sensing image classification. arXiv 2022, arXiv:2203.16952. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Haklay, M.; Weber, P. OpenStreetMap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Hu, J.; Liu, R.; Hong, D.; Camero, A.; Yao, J.; Schneider, M.; Zhu, X. MDAS: A new multimodal benchmark dataset for remote sensing. Earth Syst. Sci. Data 2023, 15, 113–131. [Google Scholar] [CrossRef]
- Hong, D.; Hu, J.; Yao, J.; Chanussot, J.; Zhu, X.X. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model. ISPRS J. Photogramm. Remote Sens. 2021, 178, 68–80. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Li, H.C.; Wang, W.Y.; Pan, L.; Li, W.; Du, Q.; Tao, R. Robust capsule network based on maximum correntropy criterion for hyperspectral image classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 738–751. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2021, 163, 113819. [Google Scholar] [CrossRef]

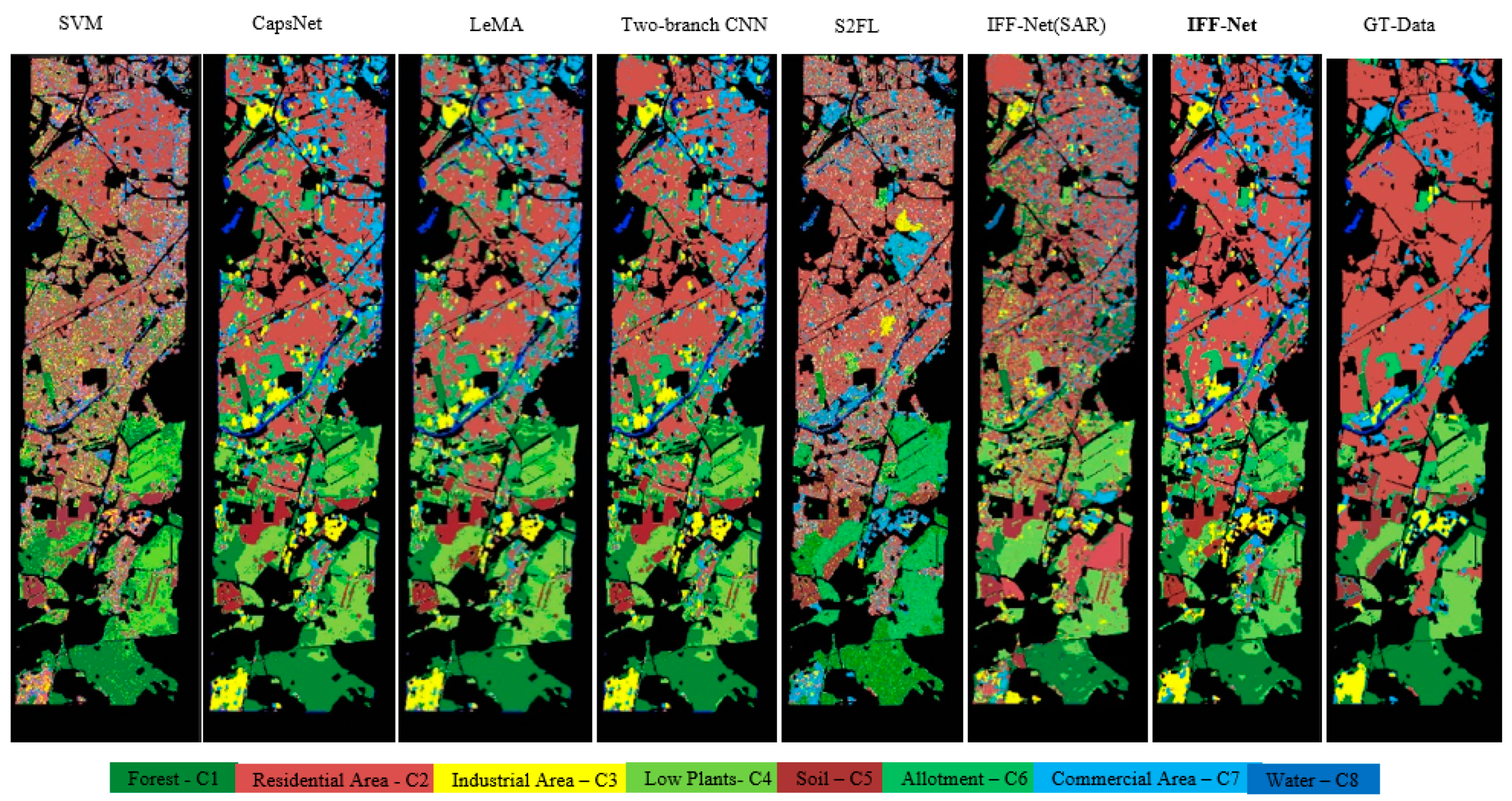

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class No | Class Name | Training Set | Testing Set |
|---|---|---|---|
| C1 | Forest | 2026 | 11,481 |
| C2 | Residential Area | 4549 | 25,780 |
| C3 | Industrial Area | 578 | 3273 |
| C4 | Low Plants | 4029 | 22,828 |
| C5 | Allotment | 86 | 489 |
| C6 | Commercial Area | 247 | 1398 |
| C7 | Water | 230 | 1300 |
| Total | 11,745 | 66,549 |
| Class No | Class Name | Training Set | Testing Set |
|---|---|---|---|
| C1 | Forest | 8243 | 46,711 |
| C2 | Residential Area | 40,296 | 228,346 |
| C3 | Industrial Area | 2935 | 16,631 |
| C4 | Low Plants | 8887 | 50,368 |
| C5 | Soil | 2614 | 14,812 |
| C6 | Allotment | 1996 | 11,309 |
| C7 | Commercial Area | 3724 | 21,100 |
| C8 | Water | 1001 | 5671 |
| Total | 69,696 | 394,948 |
| Classification Method | Time(s) on Berlin | Time(s) on Augsburg |
|---|---|---|
| SVM | 276.21 | 256.51 |
| CapsNet | 280.26 | 262.36 |
| S2FL | 157.18 | 121.68 |
| LeMA | 164.12 | 152.32 |
| Two-branch CNN | 371.42 | 312.12 |
| IFF-Net | 421.65 | 361.25 |
| r | Berlin (OA%) | Augsburg (OA%) |
|---|---|---|
| 5 | 68.21 | 88.36 |
| 7 | 68.86 | 88.58 |
| 9 | 69.85 | 88.96 |
| 12 | 71.02 | 90.52 |
| 13 | 69.92 | 86.42 |
| 15 | 68.91 | 86.06 |
| n | Berlin (OA%) | Augsburg (OA%) |
|---|---|---|
| 1 | 67.31 | 88.46 |
| 2 | 71.02 | 90.52 |
| 3 | 68.84 | 89.25 |
| 4 | 69.10 | 89.32 |
| 5 | 66.79 | 87.43 |
| λ | Berlin (OA%) | Augsburg (OA%) |
|---|---|---|
| 1 | 65.71 | 88.96 |
| 0.5 | 68.86 | 88.48 |
| 0.1 | 69.44 | 89.73 |
| 0.05 | 71.02 | 90.52 |
| 0.01 | 69.59 | 90.16 |
| Class No | SVM (HSI) | SVM (SAR) | SVM (HIS + SAR) | LeMA (HIS + SAR) | CapsNet (HIS + SAR) | Two-Branch CNN (HIS + SAR) | S2FL (HIS + SAR) | IFF-Net (SAR) | IFF-Net (HIS + SAR) |
|---|---|---|---|---|---|---|---|---|---|
| C1 | 82.01 ± 01.04 | 83.23 ± 01.35 | 90.33 ± 01.26 | 86.86 ± 02.05 | 85.10 ± 00.85 | 93.76 ± 00.61 | 88.80 ± 01.11 | 84.25 ± 00.84 | 98.21 ± 00.31 |
| C2 | 86.24 ± 01.44 | 85.51 ± 01.46 | 90.47 ± 01.31 | 90.08 ± 01.85 | 89.02 ± 01.25 | 94.19 ± 00.44 | 89.36 ± 01.25 | 86.36 ± 01.37 | 97.23 ± 00.46 |
| C3 | 21.97 ± 00.84 | 5.20 ± 00.76 | 20.37 ± 01.12 | 42.00 ± 02.26 | 40.44 ± 01.16 | 58.73 ± 01.21 | 45.90 ± 00.61 | 17.64 ± 00.81 | 50.95 ± 00.38 |
| C4 | 80.81 ± 01.42 | 67.98 ± 01.04 | 84.57 ± 00.64 | 86.79 ± 01.56 | 85.35 ± 00.44 | 85.51 ± 00.67 | 87.53 ± 00.53 | 91.31 ± 00.45 | 91.63 ± 01.21 |
| C5 | 36.63 ± 02.08 | 5.42 ± 00.37 | 36.71 ± 00.55 | 47.34 ± 01.04 | 45.00 ± 01.31 | 51.86 ± 00.72 | 68.64 ± 00.61 | 30.15 ± 01.23 | 83.36 ± 00.35 |
| C6 | 11.72 ± 00.86 | 1.14 ± 01.08 | 9.58 ± 00.29 | 23.30 ± 00.87 | 21.80 ± 00.21 | 28.35 ± 00.53 | 10.97 ± 01.36 | 12.64 ± 00.14 | 38.35 ± 00.72 |
| C7 | 45.12 ± 01.21 | 12.60 ± 01.35 | 45.65 ± 00.72 | 46.99 ± 01.16 | 45.38 ± 02.05 | 49.37 ± 01.05 | 47.65 ± 00.44 | 14.85 ± 00.36 | 28.51 ± 00.44 |
| OA (%) | 81.20 ± 00.76 | 79.63 ± 00.54 | 82.01 ± 01.04 | 83.49 ± 01.34 | 82.12 ± 00.52 | 86.83 ± 00.71 | 83.86 ± 00.29 | 80.98 ± 00.52 | 90.52 ± 00.38 |
| AA (%) | 53.50 ± 01.32 | 40.73 ± 01.13 | 53.95 ± 01.61 | 60.48 ± 01.51 | 58.87 ± 00.64 | 65.97 ± 00.66 | 62.40 ± 00.37 | 48.17 ± 00.29 | 69.74 ± 00.27 |
| κ | 74.53 ± 00.87 | 72.41 ± 00.46 | 73.74 ± 00.62 | 77.54 ± 01.32 | 75.80 ± 00.38 | 81.91 ± 00.59 | 78.03 ± 00.49 | 74.19 ± 00.63 | 86.74 ± 00.67 |
| Class No | SVM (HSI) | SVM (SAR) | SVM (HSI + SAR) | CapsNet (HSI + SAR) | LeMA (HSI + SAR) | Two-Branch CNN (HSI + SAR) | S2FL (HSI + SAR) | IFF-NET (SAR) | IFF-Net (HSI + SAR) |
|---|---|---|---|---|---|---|---|---|---|
| C1 | 72.57 ± 00.68 | 31.33 ± 01.04 | 68.11 ± 01.21 | 84.86 ± 01.27 | 84.11 ± 00.84 | 85.09 ± 00.75 | 79.52 ± 01.44 | 40.12 ± 00.98 | 82.59 ± 00.54 |
| C2 | 41.93 ± 01.24 | 28.52 ± 01.42 | 62.22 ± 00.65 | 65.22 ± 00.43 | 64.84 ± 01.53 | 68.48 ± 00.44 | 49.41 ± 02.15 | 61.21 ± 01.34 | 64.53 ± 00.72 |
| C3 | 37.72 ± 01.13 | 35.60 ± 02.11 | 29.01 ± 01.26 | 48.32 ± 00.51 | 42.53 ± 00.76 | 48.09 ± 00.39 | 45.18 ± 01.31 | 11.43 ± 00.76 | 60.12 ± 00.36 |
| C4 | 68.23 ± 02.06 | 43.07 ± 00.72 | 78.93 ± 00.58 | 80.70 ± 01.23 | 80.04 ± 01.27 | 78.43 ± 01.27 | 70.50 ± 02.17 | 46.28 ± 00.58 | 81.88 ± 00.59 |
| C5 | 80.01 ± 00.44 | 51.00 ± 00.36 | 80.99 ± 01.34 | 69.08 ± 00.49 | 80.66 ± 00.69 | 80.25 ± 00.65 | 81.47 ± 00.75 | 45.03 ± 00.68 | 82.48 ± 00.67 |
| C6 | 61.89 ± 00.54 | 32.27 ± 00.81 | 44.12 ± 00.72 | 55.08 ± 01.24 | 54.07 ± 01.47 | 48.70 ± 00.61 | 61.31 ± 00.81 | 7.24 ± 00.43 | 71.26 ± 01.13 |
| C7 | 35.84 ± 00.36 | 12.03 ± 01.06 | 31.75 ± 00.68 | 26.11 ± 00.61 | 27.40 ± 00.58 | 25.16 ± 02.16 | 29.63 ± 00.45 | 14.85 ± 00.62 | 48.61 ± 00.34 |
| C8 | 66.13 ± 01.27 | 33.78 ± 00.82 | 66.06 ± 01.41 | 59.59 ± 00.78 | 57.75 ± 02.06 | 58.52 ± 00.17 | 57.24 ± 01.21 | 34.64 ± 00.37 | 70.71 ± 00.29 |
| OA (%) | 51.11 ± 01.12 | 31.56 ± 01.10 | 63.25 ± 00.68 | 67.05 ± 01.12 | 66.21 ± 01.26 | 67.45 ± 00.48 | 56.06 ± 01.13 | 49.80 ± 00.75 | 71.02 ± 00.38 |
| AA (%) | 58.04 ± 00.93 | 33.45 ± 00.87 | 57.65 ± 00.73 | 61.12 ± 00.87 | 62.05 ± 01.13 | 61.59 ± 00.57 | 59.28 ± 01.25 | 32.60 ± 00.67 | 70.27 ± 00.29 |
| κ | 37.38 ± 00.75 | 25.60 ± 01.12 | 48.62 ± 00.44 | 52.07 ± 01.08 | 52.12 ± 01.21 | 54.36 ± 00.72 | 42.46 ± 00.87 | 36.18 ± 00.53 | 70.03 ± 00.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Wang, H.; Wu, L. IFF-Net: Irregular Feature Fusion Network for Multimodal Remote Sensing Image Classification. Appl. Sci. 2024, 14, 5061. https://doi.org/10.3390/app14125061
Wang H, Wang H, Wu L. IFF-Net: Irregular Feature Fusion Network for Multimodal Remote Sensing Image Classification. Applied Sciences. 2024; 14(12):5061. https://doi.org/10.3390/app14125061
Chicago/Turabian StyleWang, Huiqing, Huajun Wang, and Linfeng Wu. 2024. "IFF-Net: Irregular Feature Fusion Network for Multimodal Remote Sensing Image Classification" Applied Sciences 14, no. 12: 5061. https://doi.org/10.3390/app14125061
APA StyleWang, H., Wang, H., & Wu, L. (2024). IFF-Net: Irregular Feature Fusion Network for Multimodal Remote Sensing Image Classification. Applied Sciences, 14(12), 5061. https://doi.org/10.3390/app14125061