


A One-Class-Based Supervision System to Detect Unexpected Events in Wastewater Treatment Plants
 , , , ,
, , , ,  and
and 
Abstract
1. Introduction
- Real-time control of treatment processes by tracking key parameters.
- Optimization of energy consumption based on treatment demands.
- Early detection of anomalies and implementation of predictive maintenance strategies.
- Optimization of sludge generation and management.
- Adjustment of WWTP operation in response to changes in pollutant load due to climatic factors or temporal patterns in water consumption.
- Ensuring the quality of treated water discharged into water bodies.
2. Materials and Methods
2.1. Dataset Description
2.2. Unexpected Events Description
- Chemical Oxygen Demand:
- –
- Organic Pollution Indicator: COD measures the amount of oxygen needed to oxidize organic matter in a water sample. It is a direct indicator of the amount of organic contaminants present [28].
- –
- Environmental Impact: High levels of COD in water bodies can result in decreased dissolved oxygen, affecting aquatic life and ecosystems [29].
- –
- Process Control: In wastewater treatment plants, COD is essential to monitor and control the efficiency of treatment processes [30].
- Ammonia:
- –
- Direct Toxicity: Ammonia is toxic to many aquatic species. Elevated levels can cause adverse effects in fish and other aquatic organisms [31].
- –
- Eutrophication: Ammonia is a nutrient that, in excess, can contribute to the eutrophication of water bodies, promoting extensive growth of algae and aquatic plants, which can lead to water quality degradation and the death of aquatic fauna by anoxia [32].
- –
- Pollution Indicator: The presence of ammonia can indicate recent contamination by agricultural, industrial, or domestic waste [33].
- Total Kjeldahl Nitrogen:
- –
- Total Nutrient Component: TKN measures the total amount of nitrogen in the form of ammonia and organic matter, providing a more complete view of the nitrogen load in water [34].
- –
- Eutrophication and Water Quality: Like ammonia, TKN is related to eutrophication. Excess nitrogen can promote the growth of oxygen-consuming organisms, degrading water quality and negatively affecting aquatic ecosystems [35].
- –
- Evaluation of Sources of Pollution: TKN helps to identify and quantify the sources of nitrogen pollution, whether agricultural, industrial, or urban [36].
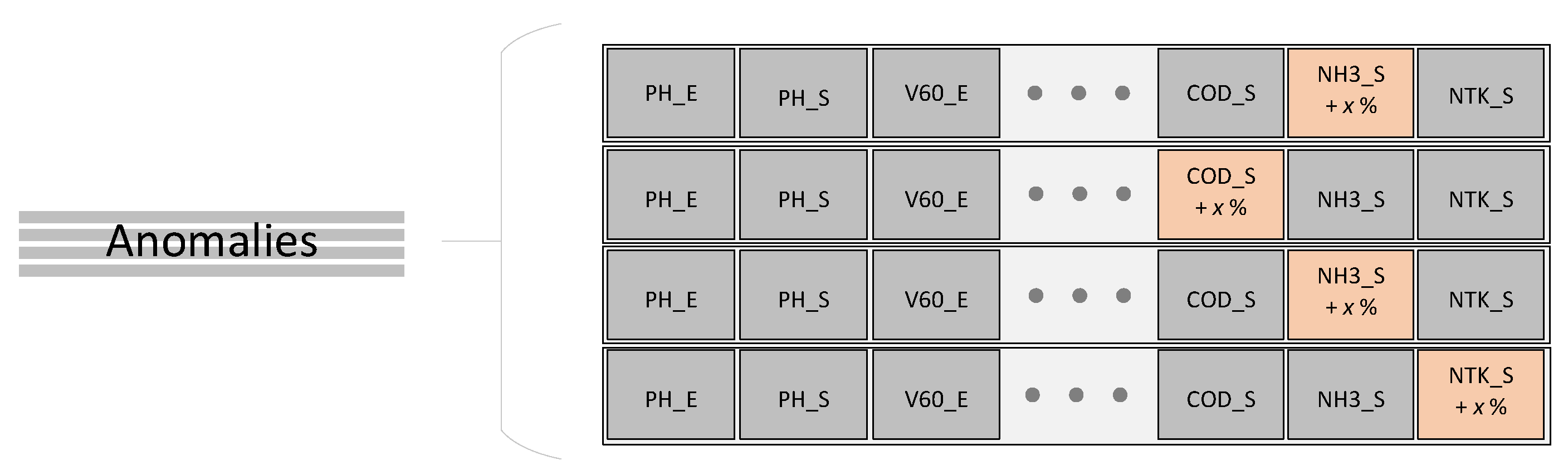
- From the initial 237 samples, 16% were randomly selected to be converted to anomalies.
- For each instance selected, one of the three variables (COD_S, NH3_S, and NTK_S) was randomly selected.
- Once the variable to be modified was selected, its value was deviated by a given percentage.
2.3. One-Class Techniques
2.3.1. Autoencoder
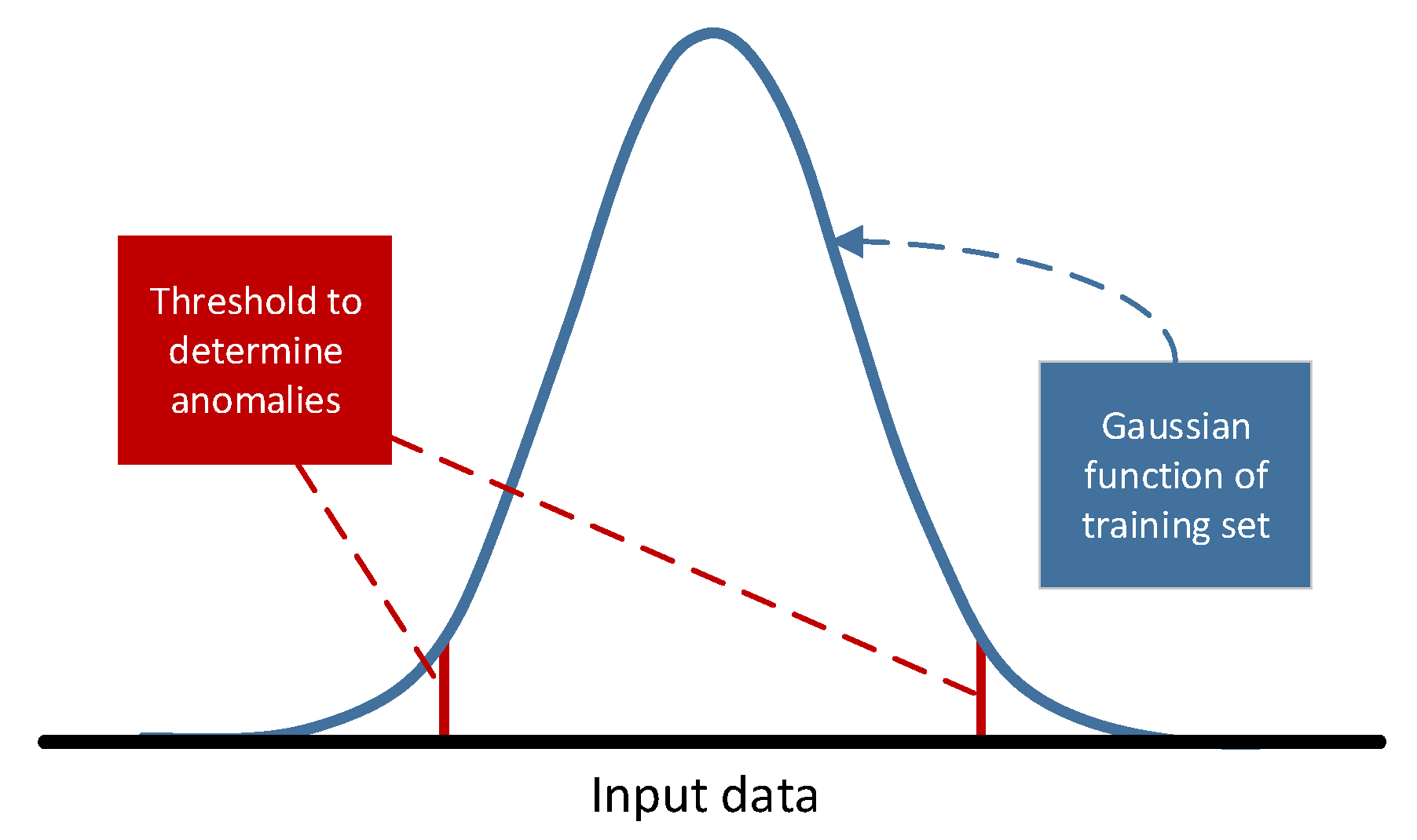
2.3.2. Gaussian Model
2.3.3. The K-means Algorithm
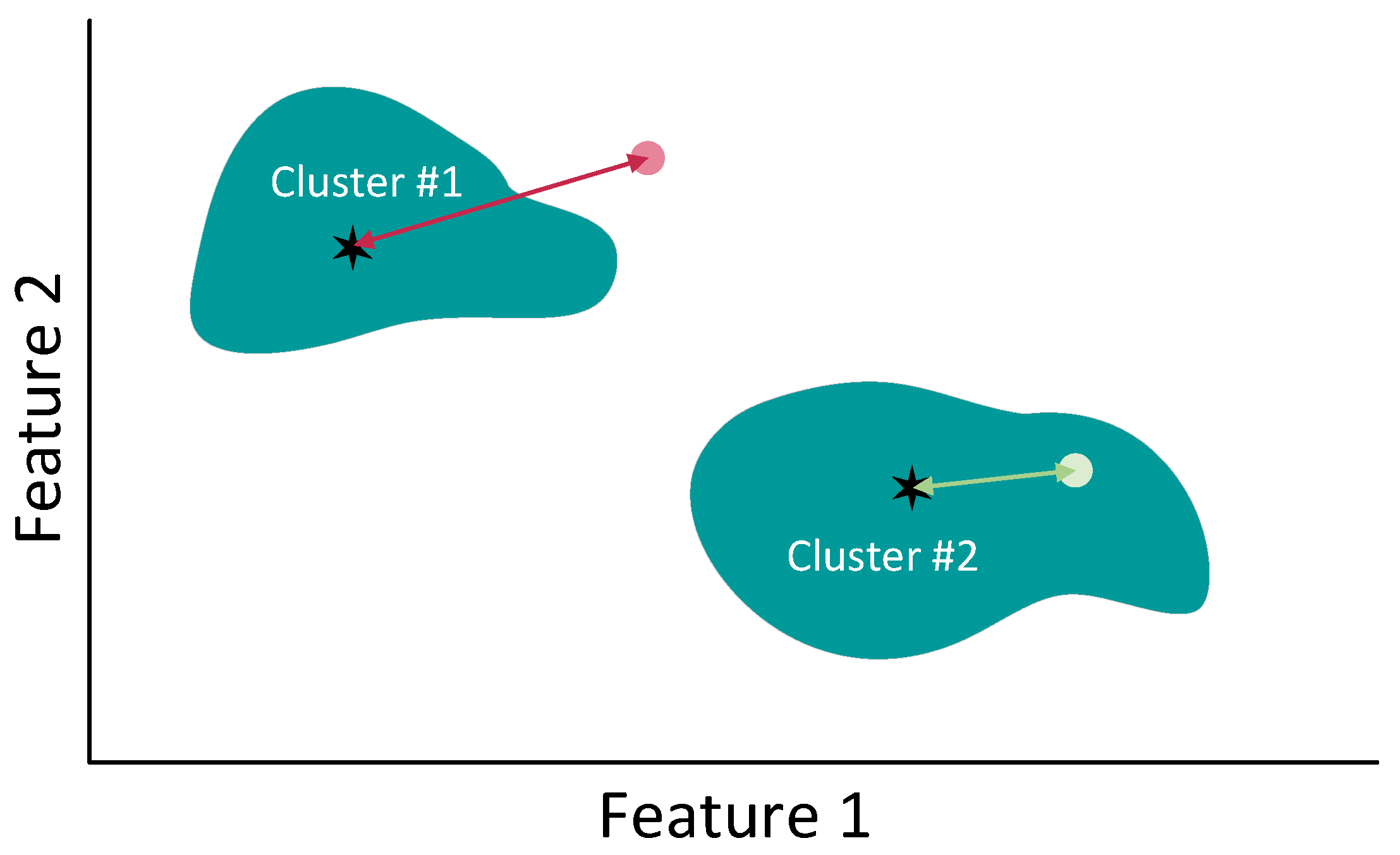
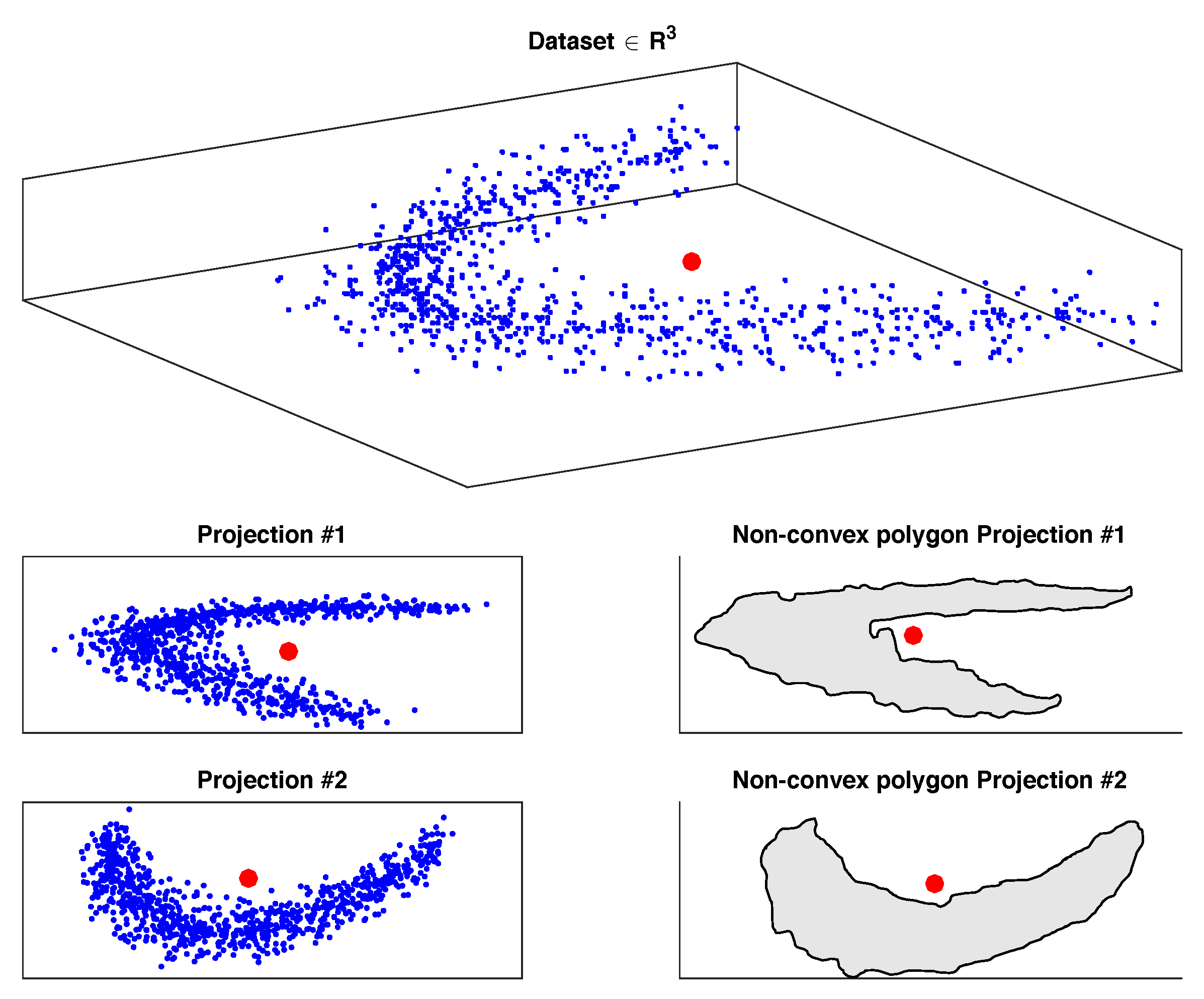
2.3.4. Non-Convex Boundary over Projections
3. Experiments and Results
3.1. Experiment Setup
- Autoencoder: the input data of the neural network are comprised of the 23 variables monitored in the WWTP. The system is trained to learn the patterns from normal operation and replicate, at the output, the same value as the input. Once the model is trained, anomalous instances replicate the data at the output with significant error. This error, known as the reconstruction error, is the criteria to determine the anomaly detection. The number of layers is swept from 1 to 22, which is the number of variables minus one. The possibility of considering a percentage of anomalous points (OP) in the training set is checked: 0%, 5%, 10%, and 15%.
- Gaussian Model: the regularization parameter is swept from 0 to 0.005 with a step of 0.001. The possibility of considering a percentage of anomalous points (OPs) in the training set is checked: 0%, 5%, 10%, and 15%.
- K-means: the number of clusters is swept from 1 to 30. The possibility of considering a percentage of anomalous points (OPs) in the training set is checked: 0%, 5%, 10%, and 15%.
- NCBoP: the projections tested are 10, 50, 100, 500 and 1000. Furthermore, the parameter in charge of reducing and expanding the boundaries is set to 0.6, 0.8, 1, 1.2, and 1.4.
- The instances converted to anomalies are randomly selected from the initial dataset.
- From each selected instance, the variable modified is also randomly selected.
- The process is repeated following K-fold cross-validation, ensuring that all data are subjected to both training and test phases.
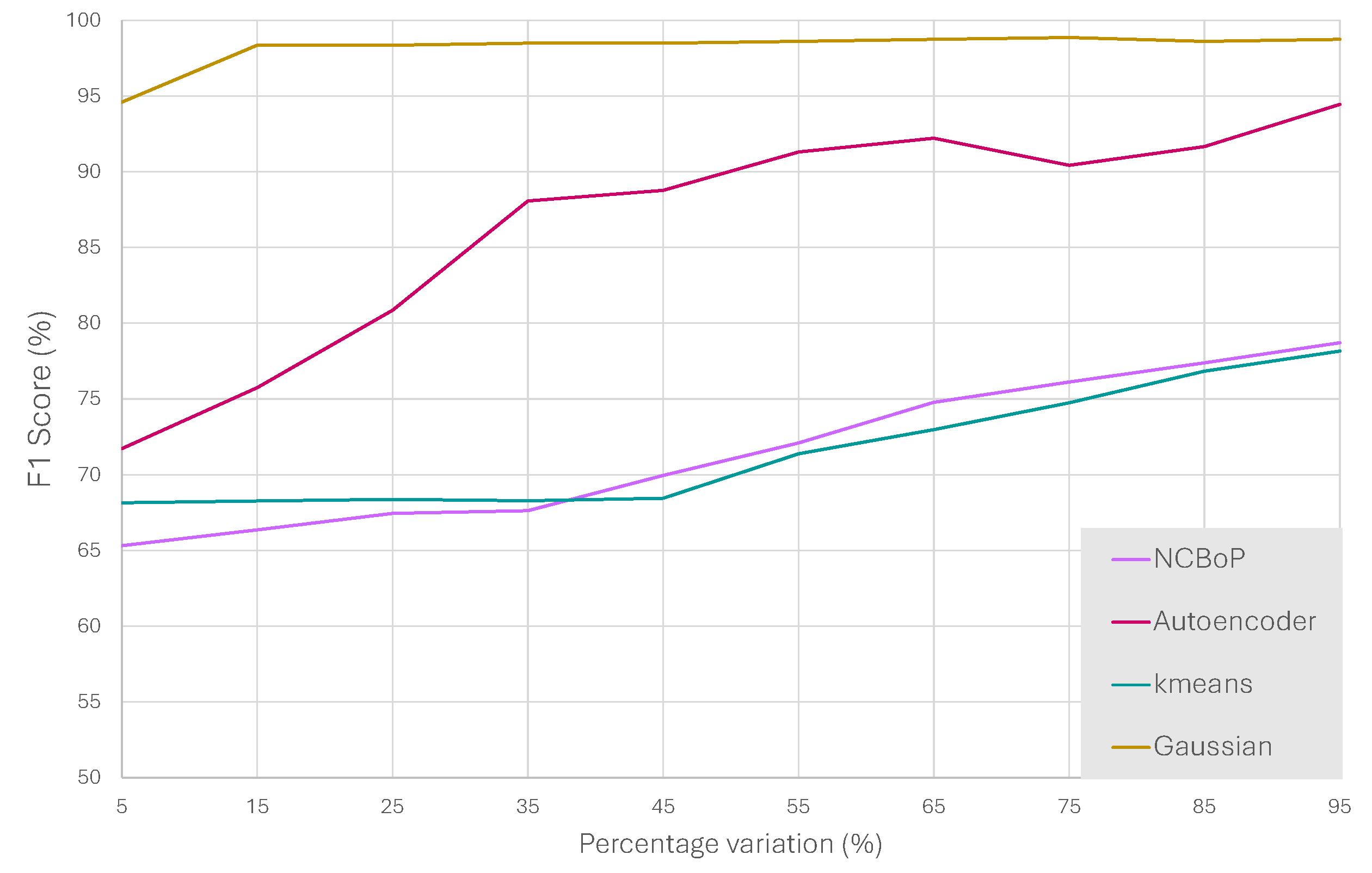
3.2. Results
4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Şenol, R.; Salman, O.; Kaya, Z. Potable water production from ambient moisture. Appl. Water Sci. 2023, 13, 10. [Google Scholar] [CrossRef]
- Brown, T.C.; Mahat, V.; Ramirez, J.A. Adaptation to future water shortages in the United States caused by population growth and climate change. Earth’s Future 2019, 7, 219–234. [Google Scholar] [CrossRef]
- Boretti, A.; Rosa, L. Reassessing the projections of the world water development report. NPJ Clean Water 2019, 2, 15. [Google Scholar] [CrossRef]
- Safarpour, H.; Tabesh, M.; Shahangian, S.A. Environmental Assessment of a Wastewater System under Water demand management policies. Water Resour. Manag. 2022, 36, 2061–2077. [Google Scholar] [CrossRef]
- Spellman, F.R. Handbook of Water and Wastewater Treatment Plant Operations; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Mascher, F.; Mascher, W.; Pichler-Semmelrock, F.; Reinthaler, F.F.; Zarfel, G.E.; Kittinger, C. Impact of Combined Sewer Overflow on Wastewater Treatment and Microbiological Quality of Rivers for Recreation. Water 2017, 9, 906. [Google Scholar] [CrossRef]
- Ianes, J.; Cantoni, B.; Remigi, E.U.; Polesel, F.; Vezzaro, L.; Antonelli, M. A stochastic approach for assessing the chronic environmental risk generated by wet-weather events from integrated urban wastewater systems. Environ. Sci. Water Res. Technol. 2023, 9, 3174–3190. [Google Scholar] [CrossRef]
- Lu, J.Y.; Wang, X.M.; Liu, H.Q.; Yu, H.Q.; Li, W.W. Optimizing operation of municipal wastewater treatment plants in China: The remaining barriers and future implications. Environ. Int. 2019, 129, 273–278. [Google Scholar] [CrossRef] [PubMed]
- Bertanza, G.; Boiocchi, R.; Pedrazzani, R. Improving the quality of wastewater treatment plant monitoring by adopting proper sampling strategies and data processing criteria. Sci. Total Environ. 2022, 806, 150724. [Google Scholar] [CrossRef] [PubMed]
- Longo, S.; d’Antoni, B.M.; Bongards, M.; Chaparro, A.; Cronrath, A.; Fatone, F.; Lema, J.M.; Mauricio-Iglesias, M.; Soares, A.; Hospido, A. Monitoring and diagnosis of energy consumption in wastewater treatment plants. A state of the art and proposals for improvement. Appl. Energy 2016, 179, 1251–1268. [Google Scholar] [CrossRef]
- Martínez, R.; Vela, N.; el Aatik, A.; Murray, E.; Roche, P.; Navarro, J.M. On the Use of an IoT Integrated System for Water Quality Monitoring and Management in Wastewater Treatment Plants. Water 2020, 12, 1096. [Google Scholar] [CrossRef]
- Kizgin, A.; Schmidt, D.; Joss, A.; Hollender, J.; Morgenroth, E.; Kienle, C.; Langer, M. Application of biological early warning systems in wastewater treatment plants: Introducing a promising approach to monitor changing wastewater composition. J. Environ. Manag. 2023, 347, 119001. [Google Scholar] [CrossRef] [PubMed]
- Bagherzadeh, F.; Mehrani, M.J.; Basirifard, M.; Roostaei, J. Comparative study on total nitrogen prediction in wastewater treatment plant and effect of various feature selection methods on machine learning algorithms performance. J. Water Process Eng. 2021, 41, 102033. [Google Scholar] [CrossRef]
- Ye, G.; Wan, J.; Deng, Z.; Wang, Y.; Chen, J.; Zhu, B.; Ji, S. Prediction of effluent total nitrogen and energy consumption in wastewater treatment plants: Bayesian optimization machine learning methods. Bioresour. Technol. 2024, 395, 130361. [Google Scholar] [CrossRef] [PubMed]
- Murei, A.; Kamika, I.; Momba, M.N.B. Selection of a diagnostic tool for microbial water quality monitoring and management of faecal contamination of water sources in rural communities. Sci. Total Environ. 2024, 906, 167484. [Google Scholar] [CrossRef]
- Borzooei, S.; Campo, G.; Cerutti, A.; Meucci, L.; Panepinto, D.; Ravina, M.; Riggio, V.; Ruffino, B.; Scibilia, G.; Zanetti, M. Optimization of the wastewater treatment plant: From energy saving to environmental impact mitigation. Sci. Total Environ. 2019, 691, 1182–1189. [Google Scholar] [CrossRef]
- Muoio, R.; Palli, L.; Ducci, I.; Coppini, E.; Bettazzi, E.; Daddi, D.; Fibbi, D.; Gori, R. Optimization of a large industrial wastewater treatment plant using a modeling approach: A case study. J. Environ. Manag. 2019, 249, 109436. [Google Scholar] [CrossRef]
- Cunha, D.L.; da Silva, A.S.; Coutinho, R.; Marques, M. Optimization of ozonation process to remove psychoactive drugs from two municipal wastewater treatment plants. Water Air Soil Pollut. 2022, 233, 67. [Google Scholar] [CrossRef]
- Garcia-Alvarez, D.; Fuente, M.; Vega, P.; Sainz, G. Fault Detection and Diagnosis using Multivariate Statistical Techniques in a Wastewater Treatment Plant.* *This work was supported in part by the national research agency of Spain (CICYT) through the project DPI2006-15716-C02-02 and the regional government of Castilla y Leon through the project VA052A07. IFAC Proc. Vol. 2009, 42, 952–957. [Google Scholar] [CrossRef]
- Corominas, L.; Villez, K.; Aguado, D.; Rieger, L.; Rosén, C.; Vanrolleghem, P.A. Performance evaluation of fault detection methods for wastewater treatment processes. Biotechnol. Bioeng. 2011, 108, 333–344. [Google Scholar] [CrossRef]
- Schraa, O.; Tole, B.; Copp, J.B. Fault detection for control of wastewater treatment plants. Water Sci. Technol. 2006, 53, 375–382. [Google Scholar] [CrossRef]
- Ruiz, M.; Sin, G.; Berjaga, X.; Colprim, J.; Puig, S.; Colomer, J. Multivariate Principal Component Analysis and Case-Based Reasoning for monitoring, fault detection and diagnosis in a WWTP. Water Sci. Technol. 2011, 64, 1661–1667. [Google Scholar] [CrossRef] [PubMed]
- Carballo Mato, J.; González Vázquez, S.; Fernández Águila, J.; Delgado Rodríguez, A.; Lin, X.; Garabato Gándara, L.; Sobreira Seoane, J.; Silva Castro, J. Foam Segmentation in Wastewater Treatment Plants. Water 2024, 16, 390. [Google Scholar] [CrossRef]
- Lin, H.; Lin, C.; Xie, D.; Acuna, P.; Liu, W. A Counter-Based Open-Circuit Switch Fault Diagnostic Method for a Single-Phase Cascaded H-Bridge Multilevel Converter. IEEE Trans. Power Electron. 2023, 39, 814–825. [Google Scholar] [CrossRef]
- Lin, H.; Cai, C.; Chen, J.; Gao, Y.; Vazquez, S.; Li, Y. Modulation and control independent dead-zone compensation for H-bridge converters: A simplified digital logic scheme. IEEE Trans. Ind. Electron. 2024, 1–6. [Google Scholar] [CrossRef]
- Orhon, D. Evolution of the activated sludge process: The first 50 years. J. Chem. Technol. Biotechnol. 2014, 90, 608–640. [Google Scholar] [CrossRef]
- Matamoros, V.; Salvadó, V. Evaluation of a coagulation/flocculation-lamellar clarifier and filtration-UV-chlorination reactor for removing emerging contaminants at full-scale wastewater treatment plants in Spain. J. Environ. Manag. 2013, 117, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Eddy, M.; Abu-Orf, M.; Bowden, G.; Burton, F.L.; Pfrang, W.; Stensel, H.D.; Tchobanoglous, G.; Tsuchihashi, R.; Firm, A. Wastewater Engineering: Treatment and Resource Recovery; McGraw Hill Education: New York, NY, USA, 2014. [Google Scholar]
- Sawyer, C.N.; McCarty, P.L.; Parkin, G.F. Chemistry for Environmental Engineering and Science; McGraw-Hill: New York, NY, USA, 2003. [Google Scholar]
- Tchobanoglus, G.; Burton, F.; Stensel, H.D. Wastewater engineering: Treatment and reuse. Am. Water Work. Assoc. J. 2003, 95, 201. [Google Scholar]
- Huff, L.; Delos, C.; Gallagher, K.; Beaman, J. Aquatic Life Ambient Water Quality Criteria for Ammonia-Freshwater; US Environmental Protection Agency: Washington, DC, USA, 2013. [Google Scholar]
- Carpenter, S.R.; Caraco, N.F.; Correll, D.L.; Howarth, R.W.; Sharpley, A.N.; Smith, V.H. Nonpoint pollution of surface waters with phosphorus and nitrogen. Ecol. Appl. 1998, 8, 559–568. [Google Scholar] [CrossRef]
- World Health Organization. Ammonia in Drinking-Water: Background Document for Development of WHO Guidelines for Drinking-Water Quality. WHO. 2003. Available online: https://cdn.who.int/media/docs/default-source/wash-documents/wash-chemicals/ammonia.pdf?sfvrsn=3080badd_6 (accessed on 12 June 2024).
- Holmes, D.E.; Dang, Y.; Smith, J.A. Nitrogen cycling during wastewater treatment. Adv. Appl. Microbiol. 2019, 106, 113–192. [Google Scholar]
- Smith, V.H.; Tilman, G.D.; Nekola, J.C. Eutrophication: Impacts of excess nutrient inputs on freshwater, marine, and terrestrial ecosystems. Environ. Pollut. 1999, 100, 179–196. [Google Scholar] [CrossRef]
- Camargo, J.A.; Alonso, Á. Ecological and toxicological effects of inorganic nitrogen pollution in aquatic ecosystems: A global assessment. Environ. Int. 2006, 32, 831–849. [Google Scholar] [CrossRef] [PubMed]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, New York, NY, USA, 2 December 2014; p. 4. [Google Scholar]
- Tax, D.M.J. One-Class Classification: Concept-Learning in the Absence of Counter-Examples. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2001. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Chong, B. K-means clustering algorithm: A brief review. Acad. J. Comput. Inf. Sci. 2021, 4, 37–40. [Google Scholar]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L. A new method for anomaly detection based on non-convex boundaries with random two-dimensional projections. Inf. Fusion 2021, 65, 50–57. [Google Scholar] [CrossRef]
- Sartipizadeh, H.; Vincent, T.L. Computing the approximate convex hull in high dimensions. arXiv 2016, arXiv:1603.04422. [Google Scholar]
- Zakariah, M.; Almazyad, A.S. Anomaly Detection for IOT Systems Using Active Learning. Appl. Sci. 2023, 13, 12029. [Google Scholar] [CrossRef]
- Almotairi, A.; Atawneh, S.; Khashan, O.A.; Khafajah, N.M. Enhancing intrusion detection in IoT networks using machine learning-based feature selection and ensemble models. Syst. Sci. Control Eng. 2024, 12, 2321381. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description of the Measured Variable | Variable Name |
|---|---|
| pH at the Entrance | PH_E |
| pH on Exit | PH_S |
| Conductivity at the Entrance | Conductivity_E |
| Conductivity at the Exit | Conductivity_S |
| V60 at the Entrance | V60_E |
| Solids in Suspension at the Entrance | SS_E |
| Solids in Suspension on Exit | SS_S |
| Biological Oxigen Demand on Exit | BOD_S |
| Chemical Oxygen Demand at the Entrance | COD_E |
| Chemical Oxygen Demand on Exit | COD_S |
| Total Nitrogen at the Entrance | NITROGEN_T_E |
| Total Phosphoro at the Entrance | PHOSPHORO_T_E |
| Total Phosphoro on Exit | PHOSPHORUS_T_S |
| Ammonia at the Entrance | NH3_E |
| Total Kjeldahl Nitrogen at the Entrance | NTK_E |
| Nitrate at the Entrance | NO3_E |
| Nitrogen dioxide at the Entrance | N02_E |
| Ammonia on Exit | NH3_S |
| Total Kjeldahl Nitrogen on Exit | NTK_S |
| Nitrate on Exit | NO3_S |
| Nitrogen dioxide on Exit | N02_S |
| Thickener input | INPUT_ESP |
| Total Nitrogen on Exit | NITROGEN_T_S |
| Dev (%) | Preproc | Hidden Layer | OP (%) | TP | TN | FP | FN | F1 (%) |
|---|---|---|---|---|---|---|---|---|
| 5 | Zscore | 19 | 0 | 38.3 | 8.5 | 28.5 | 1.7 | 71.7 |
| 15 | Zscore | 20 | 5 | 34.2 | 20.9 | 16.1 | 5.8 | 75.7 |
| 25 | Zscore | 20 | 0 | 39.5 | 18.8 | 18.2 | 0.5 | 80.9 |
| 35 | Zscore | 20 | 5 | 34.3 | 33.4 | 3.6 | 5.7 | 88.1 |
| 45 | Zscore | 20 | 5 | 34 | 34.4 | 2.6 | 6 | 88.8 |
| 55 | Zscore | 18 | 5 | 34.1 | 36.4 | 0.6 | 5.9 | 91.3 |
| 65 | Zscore | 18 | 5 | 34.9 | 36.2 | 0.8 | 5.1 | 92.2 |
| 75 | Zscore | 20 | 5 | 34 | 35.8 | 1.2 | 6 | 90.4 |
| 85 | Zscore | 20 | 5 | 34.6 | 36.1 | 0.9 | 5.4 | 91.7 |
| 95 | Zscore | 18 | 5 | 35.8 | 37 | 0 | 4.2 | 94.5 |
| Dev (%) | Preproc | RP | OP (%) | TP | TN | FP | FN | F1 (%) |
|---|---|---|---|---|---|---|---|---|
| 5 | Norm | 0 | 5 | 35.9 | 37.0 | 0.0 | 4.1 | 94.6 |
| 15 | Norm | 0 | 0 | 38.7 | 37.0 | 0.0 | 1.3 | 98.3 |
| 25 | Zscore | 0 | 0 | 38.7 | 37.0 | 0.0 | 1.3 | 98.3 |
| 35 | Norm | 0 | 0 | 38.8 | 37.0 | 0.0 | 1.2 | 98.5 |
| 45 | Zscore | 0.001 | 0 | 38.8 | 37.0 | 0.0 | 1.2 | 98.5 |
| 55 | Norm | 0.001 | 0 | 38.9 | 37.0 | 0.0 | 1.1 | 98.6 |
| 65 | Norm | 0.001 | 0 | 39.0 | 37.0 | 0.0 | 1.0 | 98.7 |
| 75 | Zscore | 0.003 | 0 | 39.1 | 37.0 | 0.0 | 0.9 | 98.9 |
| 85 | Zscore | 0.003 | 0 | 38.9 | 37.0 | 0.0 | 1.1 | 98.6 |
| 95 | Zscore | 0.001 | 0 | 39.0 | 37.0 | 0.0 | 1.0 | 98.7 |
| Dev (%) | Preproc | OP (%) | k | TP | TN | FP | FN | F1 (%) |
|---|---|---|---|---|---|---|---|---|
| 5 | NoNorm | 0 | 1 | 39.8 | 0.0 | 37.0 | 0.2 | 68.2 |
| 15 | NoNorm | 0 | 5 | 39.9 | 0.0 | 37.0 | 0.1 | 68.3 |
| 25 | Zscore | 0 | 3 | 40.0 | 0.0 | 37.0 | 0.0 | 68.4 |
| 35 | Norm | 0 | 29 | 39.4 | 1.0 | 36.0 | 0.6 | 68.3 |
| 45 | Norm | 0 | 12 | 39.7 | 0.7 | 36.3 | 0.3 | 68.4 |
| 55 | Zscore | 15 | 9 | 32.3 | 18.8 | 18.2 | 7.7 | 71.4 |
| 65 | Zscore | 10 | 9 | 34.3 | 17.3 | 19.7 | 5.7 | 73.0 |
| 75 | Zscore | 10 | 13 | 33.9 | 20.2 | 16.8 | 6.1 | 74.8 |
| 85 | Zscore | 10 | 17 | 33.0 | 24.1 | 12.9 | 7.0 | 76.8 |
| 95 | Zscore | 10 | 13 | 33.3 | 25.1 | 11.9 | 6.7 | 78.2 |
| Dev (%) | Preproc | TP | TN | FP | FN | F1 (%) | ||
|---|---|---|---|---|---|---|---|---|
| 5 | NoNorm | 0.8 | 500 | 37.1 | 0.5 | 36.5 | 2.9 | 65.3 |
| 15 | Norm | 1.4 | 10 | 36.5 | 3.5 | 33.5 | 3.5 | 66.4 |
| 25 | Norm | 1.4 | 10 | 37.7 | 2.9 | 34.1 | 2.3 | 67.4 |
| 35 | Zscore | 1.4 | 10 | 37.5 | 3.6 | 33.4 | 2.5 | 67.6 |
| 45 | Zscore | 1.4 | 100 | 30.5 | 20.3 | 16.7 | 9.5 | 70.0 |
| 55 | Zscore | 1.4 | 50 | 32.8 | 18.8 | 18.2 | 7.2 | 72.1 |
| 65 | Zscore | 1.2 | 10 | 33.2 | 21.4 | 15.6 | 6.8 | 74.8 |
| 75 | Zscore | 1.4 | 50 | 33.3 | 22.8 | 14.2 | 6.7 | 76.1 |
| 85 | Zscore | 1.4 | 100 | 31.3 | 27.4 | 9.6 | 8.7 | 77.4 |
| 95 | Zscore | 1.4 | 50 | 32.0 | 27.7 | 9.3 | 8.0 | 78.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arcano-Bea, P.; Timiraos, M.; Díaz-Longueira, A.; Michelena, Á.; Jove, E.; Calvo-Rolle, J.L. A One-Class-Based Supervision System to Detect Unexpected Events in Wastewater Treatment Plants. Appl. Sci. 2024, 14, 5185. https://doi.org/10.3390/app14125185
Arcano-Bea P, Timiraos M, Díaz-Longueira A, Michelena Á, Jove E, Calvo-Rolle JL. A One-Class-Based Supervision System to Detect Unexpected Events in Wastewater Treatment Plants. Applied Sciences. 2024; 14(12):5185. https://doi.org/10.3390/app14125185
Chicago/Turabian StyleArcano-Bea, Paula, Míriam Timiraos, Antonio Díaz-Longueira, Álvaro Michelena, Esteban Jove, and José Luis Calvo-Rolle. 2024. "A One-Class-Based Supervision System to Detect Unexpected Events in Wastewater Treatment Plants" Applied Sciences 14, no. 12: 5185. https://doi.org/10.3390/app14125185
APA StyleArcano-Bea, P., Timiraos, M., Díaz-Longueira, A., Michelena, Á., Jove, E., & Calvo-Rolle, J. L. (2024). A One-Class-Based Supervision System to Detect Unexpected Events in Wastewater Treatment Plants. Applied Sciences, 14(12), 5185. https://doi.org/10.3390/app14125185