
FA-VTON: A Feature Alignment-Based Model for Virtual Try-On
Abstract
:1. Introduction
2. Related Works
2.1. Image-Based Virtual Try-On
2.2. Parser-Free VTON
3. Twisted Analysis
4. Methods
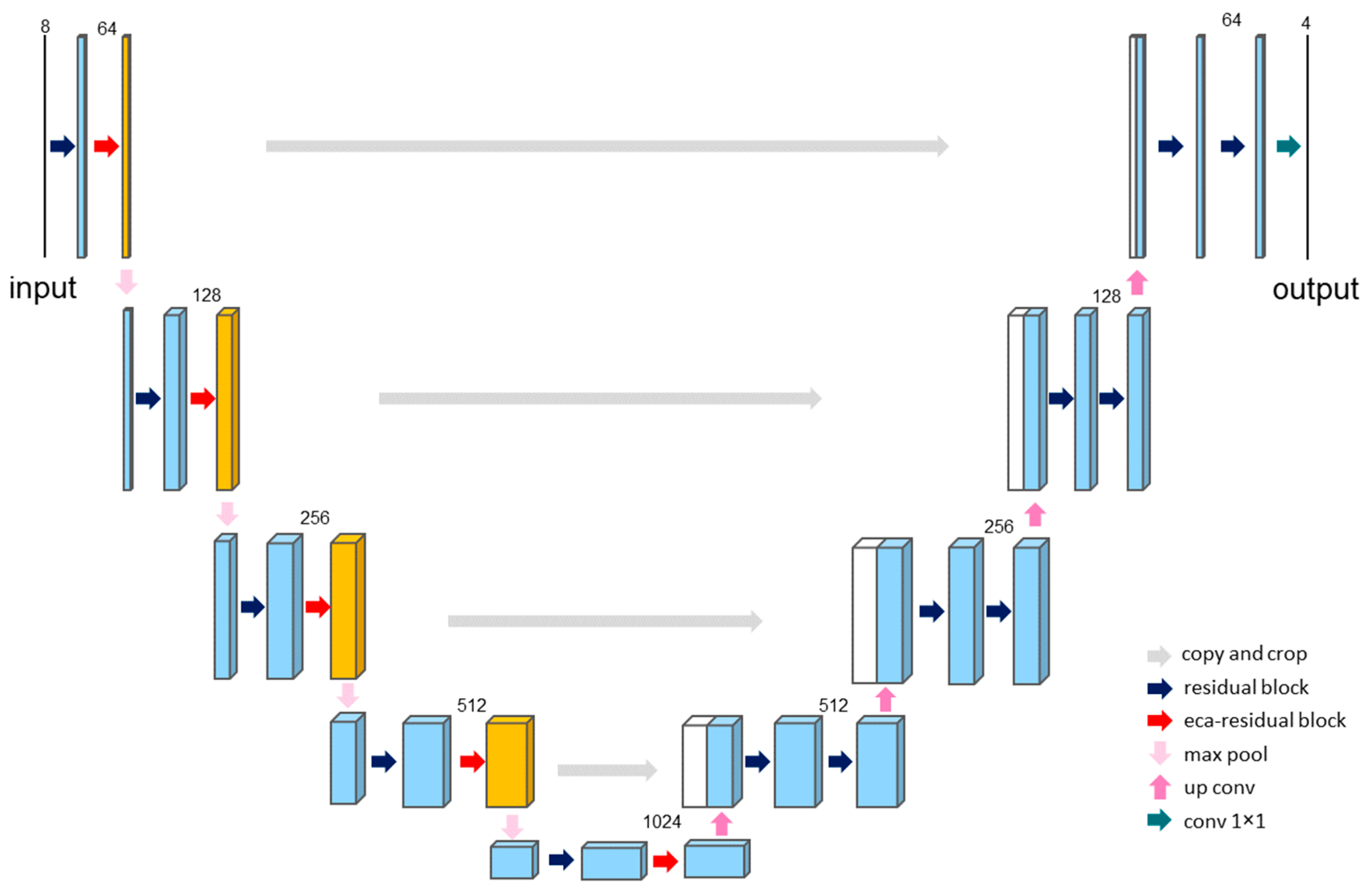
4.1. Overview of FA-VTON Framework
4.2. Feature Extraction Module (FEM)
4.2.1. Feature Alignment Module (FAM)
4.2.2. Feature Selection Module (FSM)
4.3. Coarse-to-Fine Warping Module (CFWM)
4.4. Try-On Generation Module (TGM)
4.5. Parser-Free Framework Based on Knowledge Distillation
4.5.1. Parser-Free Method
4.5.2. Channel-Wise Distillation (CWD)
4.5.3. Loss Function
5. Experiments
5.1. Experimental Settings
5.2. Qualitative Results
5.3. Quantitative Results
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bhatnagar, B.L.; Tiwari, G.; Theobalt, C.; Pons-Moll, G. Multi-garment net: Learning to dress 3d people from images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5420–5430. [Google Scholar]
- Mir, A.; Alldieck, T.; Pons-Moll, G. Learning to transfer texture from clothing images to 3d humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7023–7034. [Google Scholar]
- Saito, S.; Simon, T.; Saragih, J.; Joo, H. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 84–93. [Google Scholar]
- Han, X.; Hu, X.; Huang, W.; Scott, M.R. Clothflow: A flow-based model for clothed person generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10471–10480. [Google Scholar]
- Han, X.; Wu, Z.; Wu, Z.; Yu, R.; Davis, L.S. Viton: An image-based virtual try-on network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7543–7552. [Google Scholar]
- Ge, Y.; Song, Y.; Zhang, R.; Ge, C.; Liu, W.; Luo, P. Parser-free virtual try-on via distilling appearance flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8485–8493. [Google Scholar]
- He, S.; Song, Y.-Z.; Xiang, T. Style-based global appearance flow for virtual try-on. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3470–3479. [Google Scholar]
- Issenhuth, T.; Mary, J.; Calauzenes, C. Do not mask what you do not need to mask: A parser-free virtual try-on. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XX 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 619–635. [Google Scholar]
- Lee, S.; Gu, G.; Park, S.; Choi, S.; Choo, J. High-resolution virtual try-on with misalignment and occlusion-handled conditions. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 204–219. [Google Scholar]
- Wang, B.; Zheng, H.; Liang, X.; Chen, Y.; Lin, L.; Yang, M. Toward characteristic-preserving image-based virtual try-on network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 589–604. [Google Scholar]
- Ge, C.; Song, Y.; Ge, Y.; Yang, H.; Liu, W.; Luo, P. Disentangled cycle consistency for highly-realistic virtual try-on. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16928–16937. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A Skinned Multi-Person Linear Model. ACM Trans. Graph. 2015, 34, 248. [Google Scholar] [CrossRef]
- Jetchev, N.; Bergmann, U. The conditional analogy gan: Swapping fashion articles on people images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2287–2292. [Google Scholar]
- Duchon, J. Splines minimizing rotation-invariant semi-norms in Sobolev spaces. In Proceedings of the Constructive Theory of Functions of Several Variables: Proceedings of a Conference Held at Oberwolfach April 25–May 1, 1976; Springer: Berlin/Heidelberg, Germany, 1977; pp. 85–100. [Google Scholar]
- Zhou, T.; Tulsiani, S.; Sun, W.; Malik, J.; Efros, A.A. View synthesis by appearance flow. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 286–301. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Lin, C.; Li, Z.; Zhou, S.; Hu, S.; Zhang, J.; Luo, L.; Zhang, J.; Huang, L.; He, Y. Rmgn: A regional mask guided network for parser-free virtual try-on. arXiv 2022, arXiv:2204.11258. [Google Scholar]
- Yang, B.; Gu, S.; Zhang, B.; Zhang, T.; Chen, X.; Sun, X.; Chen, D.; Wen, F. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18381–18391. [Google Scholar]
- El Ogri, O.; Daoui, A.; Yamni, M.; Karmouni, H.; Sayyouri, M.; Qjidaa, H. New set of fractional-order generalized Laguerre moment invariants for pattern recognition. Multimedia Tools Appl. 2020, 79, 23261–23294. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Yamni, M.; Karmouni, H.; Sayyouri, M.; Qjidaa, H. Image watermarking using separable fractional moments of Charlier–Meixner. J. Franklin Inst. 2021, 358, 2535–2560. [Google Scholar] [CrossRef]
- Karmouni, H.; Jahid, T.; El Affar, I.; Sayyouri, M.; Hmimid, A.; Qjidaa, H.; Rezzouk, A. Image analysis using separable Krawtchouk-Tchebichef’s moments. In Proceedings of the 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fes, Morocco, 22–24 May 2017; pp. 1–5. [Google Scholar]
- Karmouni, H.; Jahid, T.; Hmimid, A.; Sayyouri, M.; Qjidaa, H. Fast computation of inverse Meixner moments transform using Clenshaw’s formula. Multimedia Tools Appl. 2019, 78, 31245–31265. [Google Scholar] [CrossRef]
- Yang, X.; Ding, C.; Hong, Z.; Huang, J.; Tao, J.; Xu, X. Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-on. arXiv 2024, arXiv:2404.01089. [Google Scholar]
- Morelli, D.; Baldrati, A.; Cartella, G.; Cornia, M.; Bertini, M.; Cucchiara, R. LaDI-VTON: Latent diffusion textual-inversion enhanced virtual try-on. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 8580–8589. [Google Scholar]
- Kim, J.; Gu, G.; Park, M.; Park, S.; Choo, J. StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-on. arXiv 2023, arXiv:2312.01725. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Nguyen-Ngoc, K.-N.; Phan-Nguyen, T.-T.; Le, K.-D.; Nguyen, T.V.; Tran, M.-T.; Le, T.-N. DM-VTON: Distilled Mobile Real-time Virtual Try-on. In Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Sydney, Australia, 16–20 October 2023; pp. 695–700. [Google Scholar]
- Xie, Z.; Huang, Z.; Dong, X.; Zhao, F.; Dong, H.; Zhang, X.; Zhu, F.; Liang, X. Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23550–23559. [Google Scholar]
- Bai, S.; Zhou, H.; Li, Z.; Zhou, C.; Yang, H. Single stage virtual try-on via deformable attention flows. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 409–425. [Google Scholar]
- Huang, S.; Lu, Z.; Cheng, R.; He, C. Fapn: Feature-aligned pyramid network for dense image prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 864–873. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar]
- Yan, K.; Gao, T.; Zhang, H.; Xie, C. Linking garment with person via semantically associated landmarks for virtual try-on. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17194–17204. [Google Scholar]
- Feng, R.; Ma, C.; Shen, C.; Gao, X.; Liu, Z.; Li, X.; Ou, K.; Zhao, D.; Zha, Z.-J. Weakly supervised high-fidelity clothing model generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3440–3449. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Sun, D.; Roth, S.; Black, M.J. A quantitative analysis of current practices in optical flow estimation and the principles behind them. Int. J. Comput. Vis. 2014, 106, 115–137. [Google Scholar] [CrossRef]
- Janai, J.; Guney, F.; Ranjan, A.; Black, M.; Geiger, A. Unsupervised learning of multi-frame optical flow with occlusions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 690–706. [Google Scholar]
- Jin, X.; Wu, L.; Shen, G.; Chen, Y.; Chen, J.; Koo, J.; Hahm, C.-h. Enhanced bi-directional motion estimation for video frame interpolation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5049–5057. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5311–5320. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Choi, S.; Park, S.; Lee, M.; Choo, J. VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 25–34. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | VITON | VITON-HD | ||||
|---|---|---|---|---|---|---|
| Method | SSIM ↑ | FID ↓ | LPIPS ↓ | SSIM ↑ | FID ↓ | LPIPS ↓ |
| ACGPN | 0.69 | 16.64 | 0.226 | 0.78 | 14.99 | 0.170 |
| PF-AFN | 0.79 | 10.09 | 0.213 | 0.69 | 25.44 | 0.229 |
| SDAFN | 0.78 | 9.42 | 0.228 | 0.82 | 9.97 | 0.113 |
| FS-VTON | 0.85 | 8.89 | 0.200 | 0.83 | 10.00 | 0.102 |
| DM-VTON | 0.81 | 10.57 | 0.213 | 0.82 | 11.81 | 0.125 |
| Ours | 0.86 | 8.72 | 0.184 | 0.85 | 9.53 | 0.096 |
| SSIM ↑ | FID ↓ | LPIPS ↓ | |
|---|---|---|---|
| FAM | 0.857 | 8.86 | 0.193 |
| FSM | 0.855 | 8.99 | 0.196 |
| FAM + FSM | 0.860 | 8.82 | 0.189 |
| SSIM ↑ | FID ↓ | LPIPS ↓ | |
|---|---|---|---|
| w/o ECA | 0.859 | 8.79 | 0.191 |
| w ECA | 0.856 | 8.72 | 0.187 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Y.; Ding, N.; Yao, L. FA-VTON: A Feature Alignment-Based Model for Virtual Try-On. Appl. Sci. 2024, 14, 5255. https://doi.org/10.3390/app14125255
Wan Y, Ding N, Yao L. FA-VTON: A Feature Alignment-Based Model for Virtual Try-On. Applied Sciences. 2024; 14(12):5255. https://doi.org/10.3390/app14125255
Chicago/Turabian StyleWan, Yan, Ning Ding, and Li Yao. 2024. "FA-VTON: A Feature Alignment-Based Model for Virtual Try-On" Applied Sciences 14, no. 12: 5255. https://doi.org/10.3390/app14125255
APA StyleWan, Y., Ding, N., & Yao, L. (2024). FA-VTON: A Feature Alignment-Based Model for Virtual Try-On. Applied Sciences, 14(12), 5255. https://doi.org/10.3390/app14125255