Abstract
Monitoring ships on water surfaces encounters obstacles such as weather conditions, sunlight, and water ripples, posing significant challenges in accurately detecting target ships in real time. Synthetic Aperture Radar (SAR) offers a viable solution for real-time ship detection, unaffected by cloud coverage, precipitation, or light levels. However, SAR images are often affected by speckle noise, salt-and-pepper noise, and water surface ripple interference. This study introduces LCAS-DetNet, a Multi-Location Cross-Attention Ship Detection Network tailored for the ships in SAR images. Modeled on the YOLO architecture, LCAS-DetNet comprises a feature extractor, an intermediate layer (“Neck”), and a detection head. The feature extractor includes the computation of Multi-Location Cross-Attention (MLCA) for precise extraction of ship features at multiple scales. Incorporating both local and global branches, MLCA bolsters the network’s ability to discern spatial arrangements and identify targets via a cross-attention mechanism. Each branch utilizes Multi-Location Attention (MLA) and calculates pixel-level correlations in both channel and spatial dimensions, further combating the impact of salt-and-pepper noise on the distribution of objective ship pixels. The feature extractor integrates downsampling and MLCA stacking, enhanced with residual connections and Patch Embedding, to improve the network’s multi-scale spatial recognition capabilities. As the network deepens, we consider this structure to be cascaded and multi-scale, providing the network with a richer receptive field. Additionally, we introduce a loss function based on Wise-IoUv3 to address the influence of label quality on the gradient updates. The effectiveness of our network was validated on the HRSID and SSDD datasets, where it achieved state-of-the-art performance: a 96.59% precision on HRSID and 97.52% on SSDD.
1. Introduction
The Synthetic Aperture Radar (SAR) system boasts unparalleled capabilities for all-weather surveillance, offering distinct advantages when compared to traditional optical remote sensing satellites for terrestrial observation [1,2]. Variations in the brightness of SAR imagery are intricately linked to the backscatter coefficient of the target area, mirroring critical physical parameters such as surface texture, soil moisture, and the complex dielectric constant. The application of SAR technology has shown exceptional promise in various fields including marine environmental monitoring, geological surveys, agricultural development, emergency management, and naval reconnaissance [3,4,5,6].
Ship detection is pivotal for ensuring maritime safety and providing essential data support. However, the utility of optical imagery is significantly hampered by its inherent limitations, chiefly, its inability to facilitate real-time monitoring of vessels during nocturnal hours. Moreover, optical imagery often fails in conditions of sea fog, dense cloud coverage, rainfall, and various extreme or adverse weather scenarios, leading to a complete loss of the detection targets in the imagery [7]. In contrast, SAR boasts remarkable penetration capabilities and provides consistent monitoring across all weather conditions, be it day or night, under cloud cover, or amidst rainfall. The inherent benefits of SAR technology effectively offset the shortcomings associated with optical satellites, thereby delivering a robust, continuous, and reliable data source for the enhancement of real-time ship monitoring processes.
In the past, there have been a large number of excellent solutions in the field of machine learning and machine vision, which have been used for ship identification from the perspective of data processing and image processing, such as Support Vector Machines (SVMs) [8], threshold segmentation [9], statistical feature methods [3], and various manually crafted feature-based methods [10,11]. Nevertheless, these approaches exhibit limited performance in scenarios characterized by complex environmental backgrounds, ship deformations, and prevalent noise [12]. Furthermore, while these traditional methods might show exceptional capabilities in certain specific scenarios, they suffer from a lack of versatility and adaptability across diverse situations [13]. Deep learning has proven adept at navigating the intricacies of object detection tasks, showcasing remarkable adaptability in complex scenarios [14,15]. Its proficiency in executing multiple classification detections, alongside unparalleled accuracy and data processing capabilities, has propelled its application in the analysis of Synthetic Aperture Radar (SAR) imagery. Currently, these techniques have yielded substantial improvements in the domain of ship detection using SAR images [16]. Predominantly, general object detection algorithms are classified into two broad categories: one-stage and two-stage detection methods. One-stage detection algorithms, such as SSD [17] and YOLO [18], approach detection as a comprehensive end-to-end regression challenge. Though they compromise on the accuracy of detecting smaller objects, these algorithms exhibit a significant advantage in real-time detection capabilities. On the other hand, classical two-stage detection algorithms, such as R-CNN [19], Faster R-CNN [20], Mask R-CNN [21], and SPP-Net [22], enhance the model’s sensitivity towards smaller objects. However, they introduce computational complexity that can hinder overall detection efficiency.
Detecting ships on water surfaces demands algorithms that deliver both high-speed and robust performance. Given the typical image characteristics obtained through satellite remote sensing, the target ship usually occupies only a minor portion of the overall pixel count, resulting in its identification as a small target. To this end, a vast array of detection algorithms specifically tailored for ship identification has been introduced in recent research. For instance, Kang et al. [23] utilized a blend of downsampled shallow layers along with upsampled deeper layers to create region proposals. Li et al. [24] applied a technique involving high-frequency sub-band channel fusion to enhance ship features in SAR imagery. Meanwhile, Yu et al. [25] enhanced the YOLOv5 model with a bidirectional feature pyramid network to improve the ability to detect ships of various scales. In another advancement, Chen et al. [26] introduced the SAS-FPN module, merging porous spatial pyramid pooling with shuffled attention strategies to minimize the loss of ship features. Furthermore, Li et al. [27] achieved rotation-invariant properties of the SAR ship hull in the frequency domain by applying a Fourier transform to the multi-scale features derived from the Feature Pyramid Network (FPN). Additionally, Chen et al. [28] formulated a novel loss function integrated with GIoU to diminish the network’s sensitivity to scale variations, thereby focusing on enhancing the algorithm’s performance in detecting ship targets within SAR imagery characterized by complex backgrounds. Despite the availability of advanced deep learning methods for ship detection, SAR imagery, known for its unique radar imaging features, presents considerable interpretation challenges. Factors such as self-scattering mechanisms, terrain interference, and atmospheric noise contribute to issues like salt-and-pepper noise, blurred edges, and shape distortion during the imaging process, posing significant hurdles in accurately locating and identifying ship shapes [29].
Detecting ships using SAR imagery presents numerous challenges: (1) In SAR imagery, the majority of ships are depicted by only a small cluster of pixels, thereby imposing high requirements on the detection algorithm’s capability to recognize small targets. (2) The existence of salt-and-pepper noise and radar interference within SAR images leads to the blurring of boundaries, ghosting effects, and misplacement of the identified ships. This significantly undermines the reliability of target identification and localization. (3) The visual interpretation of SAR imagery is significantly dependent on the expertise of specialists in the field. A notable challenge in this domain is that considerable inconsistencies in the annotation quality of datasets complicate the ship detection situation.
In order to tackle the previously mentioned challenges, this paper introduces a Multi-Location Cross-Attention Ship Detection Network (LCAS-DetNet), which is based on the YOLO architecture [18]. This architecture comprises a feature extraction component, an intermediate neck layer, and a detection head. Furthermore, to mitigate the effects of noise interference in detection tasks, we present the Multi-Location Cross-Attention (MLCA) framework. The MLCA strategy integrates both global and local perspectives to pinpoint ship locations with high precision. It employs a dual-branch structure that acts as a filter during feature extraction, identifying relevant targets amid perceptual features, thus eliminating non-informative noise and random noise points. To enhance the accuracy in determining the spatial location of ships, our approach maintains the spatial coordinates of the target across multiple scales leveraging a residual structure for location data. Notably, drawing inspiration from Wise-IoUv3 [30], this research integrates a focusing mechanism into the loss calculation process. This is achieved by adopting the degree of deviation as a weight factor, which helps in minimizing the influence of dataset quality discrepancies on the gradient updates. The main contributions are as follows:
- We propose a Multi-Location Cross-Attention (MLCA) to enhance the network’s focus on key regions, suppress salt-and-pepper noise interference, and highlight ship features.
- An multi-scale cascaded feature extractor with spatial coordinates is proposed. It is used for extracting ship features while retaining the multi-scale spatial coordinates of the ships.
- We integrate the focusing mechanism Wise-IoUv3 [30] loss into the bounding-box regression loss calculation. This helps minimize the influence of dataset quality differences on gradient updates.
- We propose a Multi-Location Cross-Attention Ship Detection Network (LCAS-DetNet), a multi-scale cascaded object detection algorithm. LCAS-DetNet was tested on two ship detection datasets (HRSID [31] and SSDD [32]), and the results demonstrated state-of-the-art performance.
2. Methods
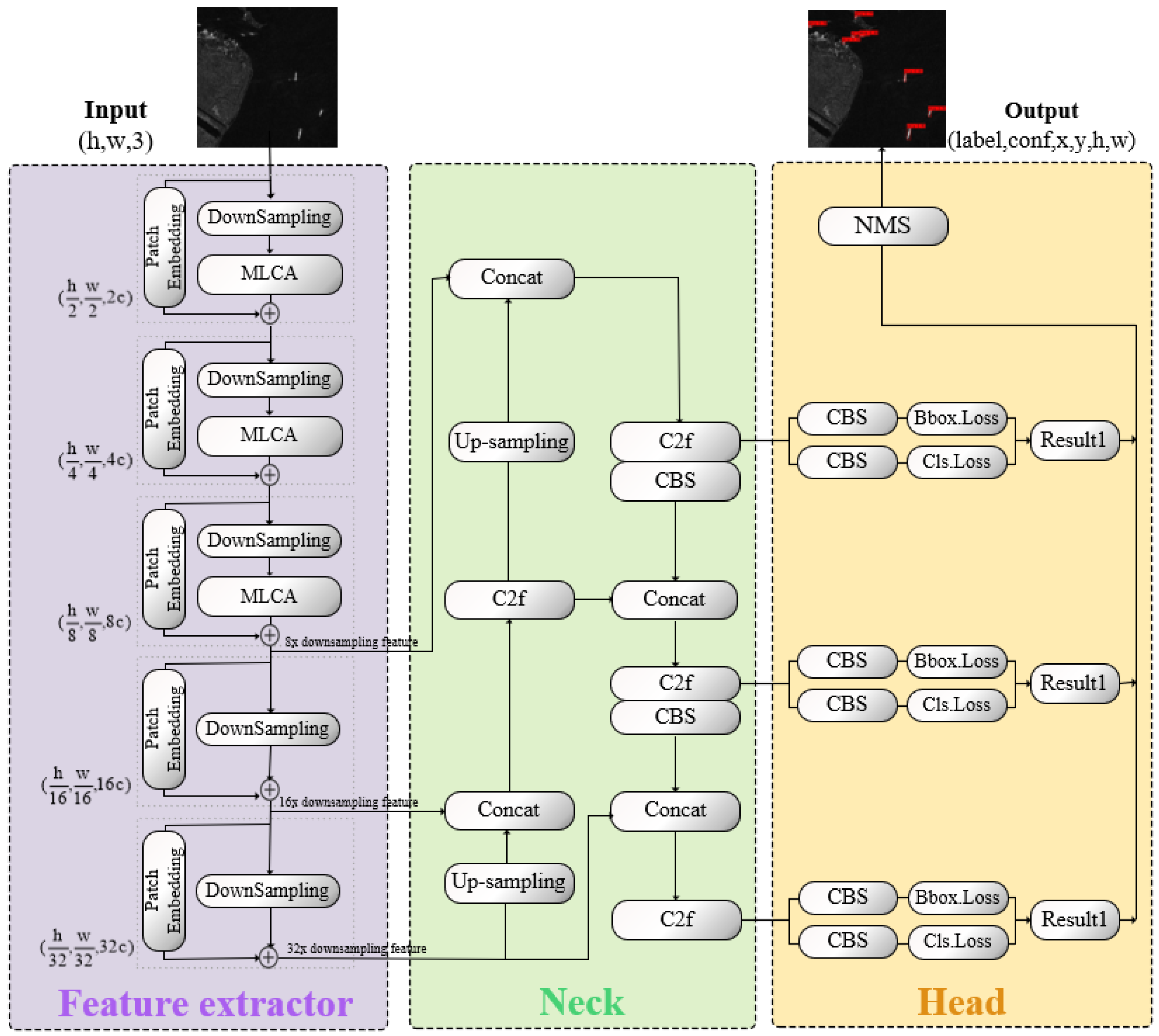
This study proposes LCAS-DetNet for the detection of surface ships based on SAR images. LCAS-DetNet provides a small target detection solution with advantages in denoising and real-time performance for ship detection tasks. As shown in Figure 1, it follows the YOLO structure, consisting of multiple location feature extractor, a feature fusion neck layer, and a detection head. To more accurately pinpoint the locations of small target ships, this study introduces an attention scheme called Multi-Location Cross-Attention (MLCA) into the feature extractor. MLCA implicitly re-encodes the spatial locations of targets in the feature extractor, enhancing the network’s spatial perception and object location capabilities. At the same time, it acts as a filter by calculating correlations to filter out salt-and-pepper noise in SAR data.
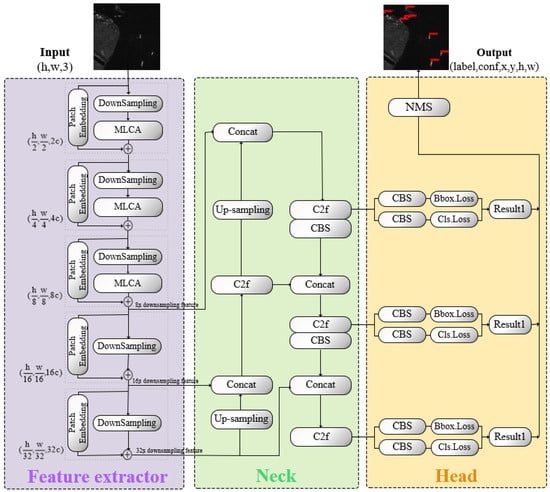
Figure 1.
In the LCAS-DetNet network, the input SAR image is processed by a feature extractor to extract multi-scale semantic features. Subsequently, the neck layer fuses the features obtained from the feature extractor and pass them into the detection head. The final output is generated by the detection head layer.
As a Multi-Location Cross Attention mechanism, LCAS-DetNet demonstrates significant potential in enhancing the precision of ship localization. This improvement is primarily facilitated by the integration of implicit global position encoding, achieved through the attention mechanism, alongside local position encoding, enabled by convolutional operations. This dual encoding framework effectively delineates the spatial relationships between the ship and its surrounding environment, as well as the interactions among ships at varying distances. Consequently, this design offers more possibilities for multi-target monitoring.
2.1. Multi-Location Cross-Attention
The success of ViT [33] has introduced the Transformer into visual computing, prompting increased discussion among researchers regarding the significance of attention mechanisms in computer vision. Inspired by [34,35], this study proposes a Multi-Location Cross-Attention (MLCA) to further explore the utility of attention mechanisms in SAR images and ship detection tasks.
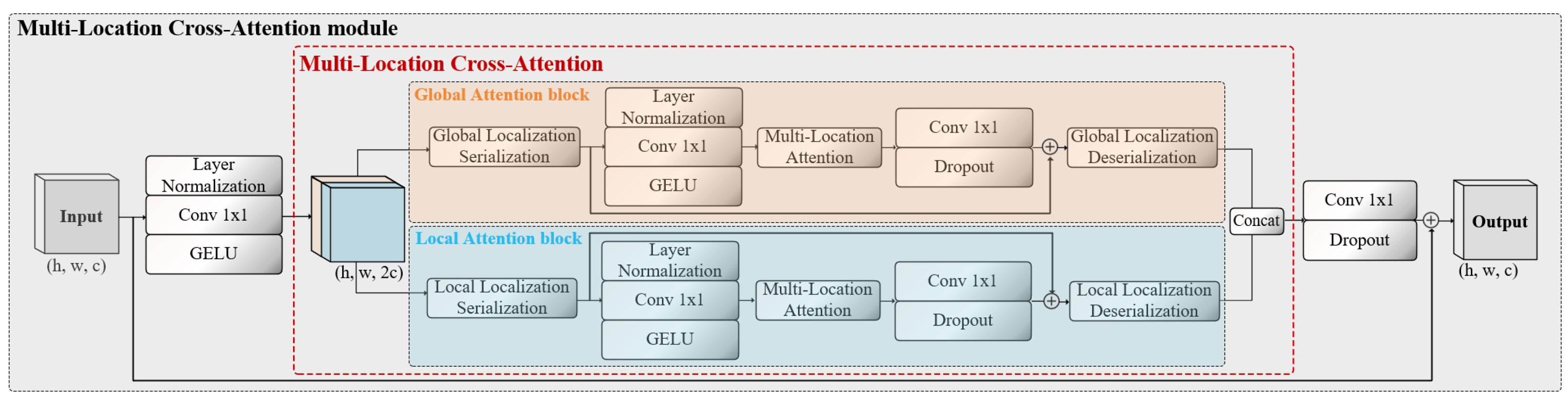
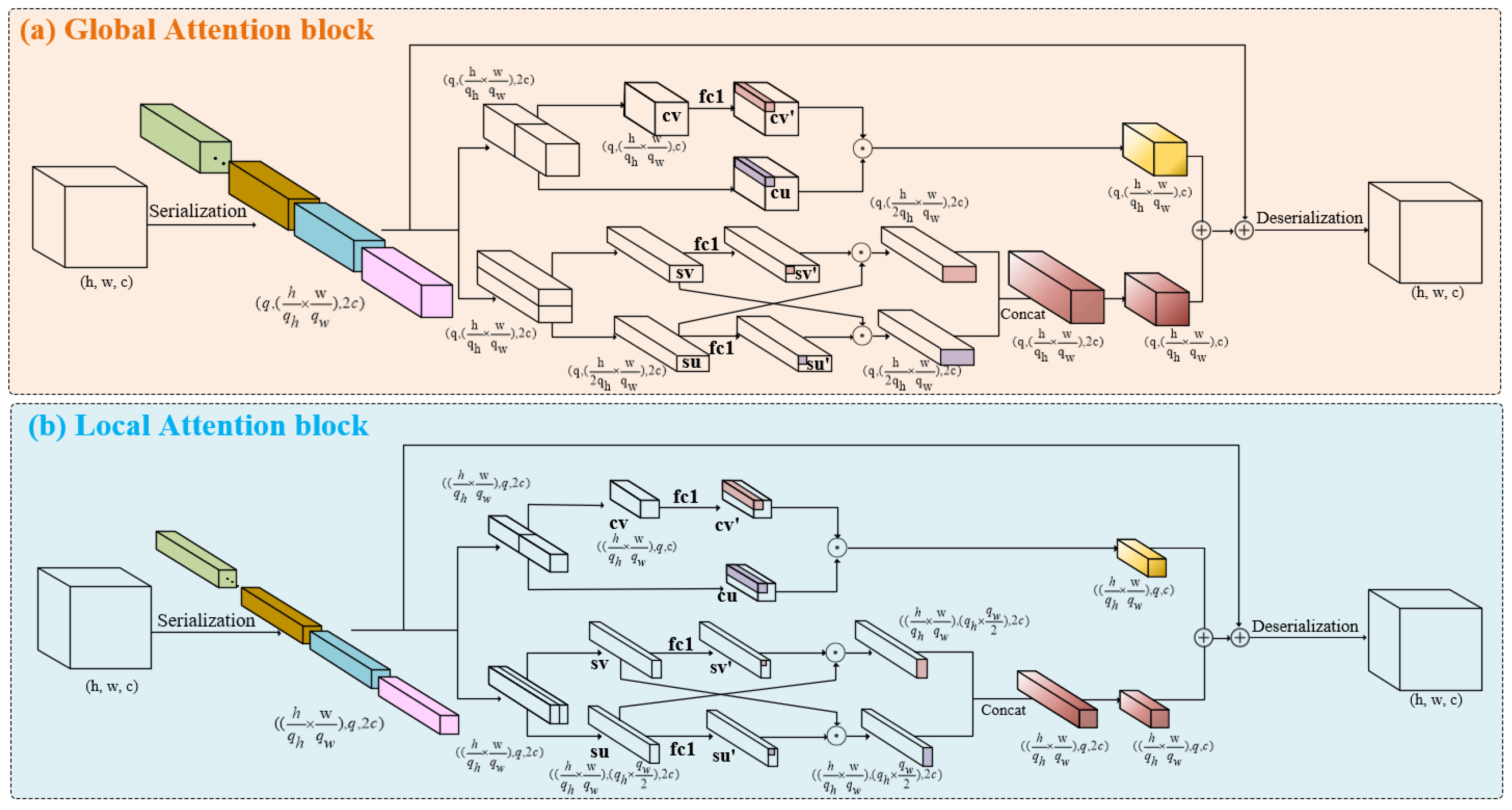
As shown in Figure 2, MLCA consists of local and global branches, to obtain features at different scales and spatial coordinate location. This form of attention is referred to as cross-attention [36]. Within each branch, additional branches are embedded to acquire attention from both channel and spatial perspectives, named Multi-Location Attention (MLA). On one hand, this enables the stabilization of ship features against interference caused by noise from multiple dimensions. On the other hand, the spatial position of ships can be implicitly encoded through a correlation calculation.
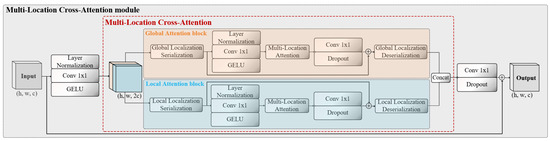
Figure 2.
The framework of the Multi-Location Cross-Attention module consists of a dual-branch structure, with local and global branches.
To maintain the plug-and-play characteristic of MLCA, the channel dimensions of the input and output, as well as the tensor shape, remain consistent after undergoing complex transformations. Assuming that the input , the output . After x undergoes normalization–convolution–activation, the channel dimension is increased , providing homologous raw materials for the dual-branch structure.
As shown in Figure 3, after is sliced along the channel dimension, it is separately input into the global and local branches. Different scales of patches are obtained through serialization, assuming the patch window is . Window q plays different roles in the two branches. In the global branch, q represents the number of patch windows, while in the local branch, q represents the size of a patch window. q is a hyperparameter that can take different values depending on the task and dataset. In the global branch, the serialized tensor . In the local branch, the serialized tensor . MLCA obtains the spatial positions and receptive fields of different scales within the same layer. Such cross-attention introduces richer features and spatial information into the network.
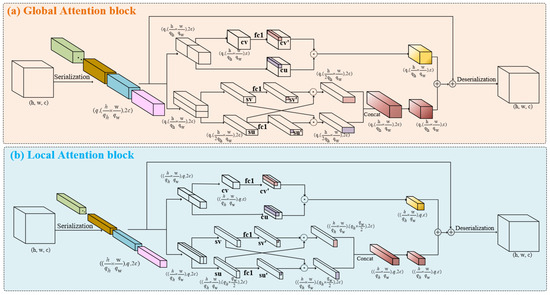
Figure 3.
Tensor shape changes in the global and local branches in Multi-Location Cross-Attention.
As illustrated in Figure 3a, the MLA module contains channels and spatial branches, taking the global branch as an example.
In the channel branch, the input is divided into two parts in the channel dimension, resulting in two different sequences of shape , named and . Among them, represents the input reserve, while serves as an index to search for features with high similarity. As shown in Equation (1), and measure spatial distance through dot product in the channel dimension, serving as the evaluation criterion for feature correlation. During backpropagation, it guides the weight update of . We believe that such a design helps resist interference caused by water surface fluctuations and abnormal weather conditions at sea. This interference can cause water bodies that should be surface scattering to be easily confused with volume scattering from ships.
In the spatial branch, the emphasis is on pixel-level correlation on the spatial plane, that is, the dimension. As shown in Figure 3, when is input into the spatial branch, it is divided into two along the h dimension, resulting in and . As shown in Equation (2), a pixel-level dot product interaction is performed between the slices. To ensure the integrity of the attention of the feature maps, we perform a linear transformation with learnable weights on and , resulting in and . A dot product is then performed between and , as well as and , to guide the backpropagation and update the learnable weight coefficients. It is worth noting that in order to ensure multi-perspective learning of attention, the local branch performs the slice interaction along the w dimension. We believe that a pixel-level multi-perspective dot product can better cope with the challenges brought by salt-and-pepper noise in SAR imaging. Such high-granularity attention calculation can accurately focus on the pixel values of the target object from the features, thereby ignoring small salt-and-pepper noise.
We sum up the obtained and to obtain the Multi-Location Attention, as shown in Equation (3), adding the global and local attention linearly to obtain the final MLCA.
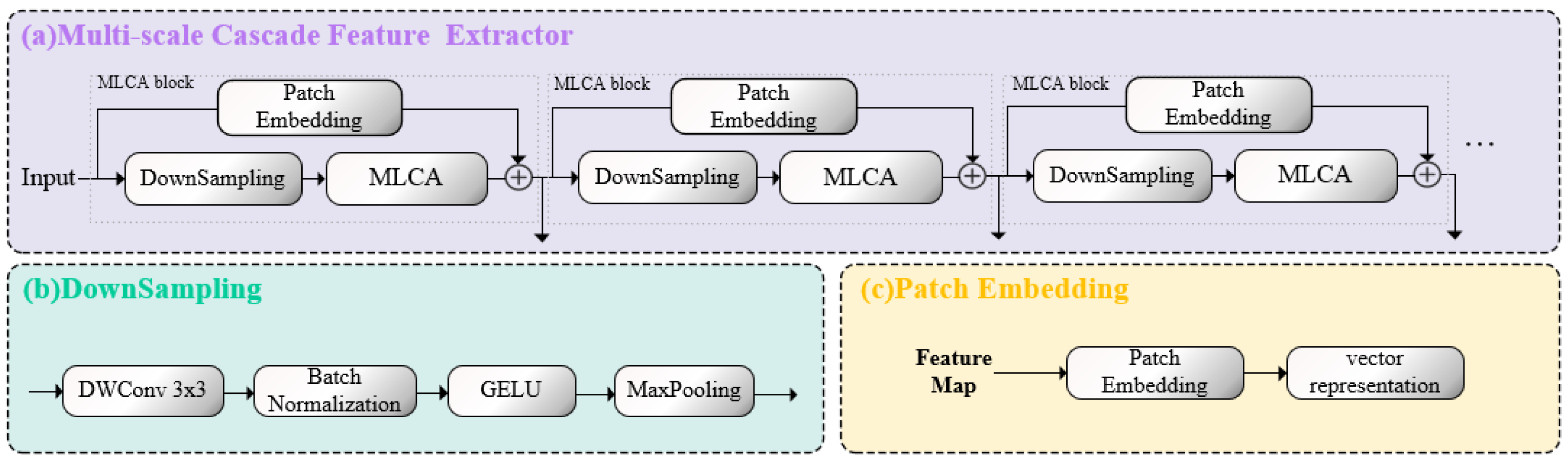
2.2. Multi-Scale Cascade Feature Extractor
The entire multi-scale cascade feature extractor consists of stacked MLCA blocks, as shown in Figure 4a. After passing through each MLCA block, the feature map of shape becomes . Through the cascading design, our feature extractor makes it possible for information to be passed and exchanged between different layers, combining features from different layers to produce richer and more complex feature representations, which enhances the network’s representational and learning capabilities. In the SAR image ship detection task of this study, we obtain 8×, 16×, and 32× downsampled features from the multi-scale cascade feature extractor and pass them to the neck layer for feature fusion.
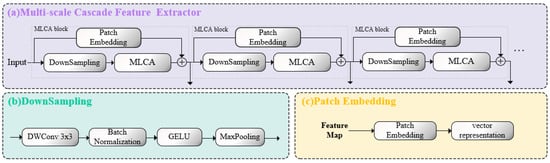
Figure 4.
Different parts of the multi-scale cascade feature extractor. (a) The overall structure of the multi-scale cascade feature extractor. (b) The downsampling module. (c) The patch embedding module.
MLCA module: It is the core of LCAS-DetNet, designed to handle the challenges posed by small targets and noise interference in the network. The MLCA module is a dual-branch structure, consisting of a local branch and a global branch, forming cross-attention, as shown in Figure 2. The feature of the input MLCA module is passed through layer normalization–convolution–GELU (NCG) to provide raw material for the two branches. NCG is a reusable module that ensures the learnability of the attention mechanism in feature maps using convolution, normalization, and GELU activation function, continuously updating the relevance weights through backpropagation. Ensuring the nonlinear transformation of features while computing the relevance of different targets. Upon entering the branches, the feature map is serialized and undergo NCG to increase the dimensionality, serving as the input for the MLA block. After undergoing the transformation shown in Figure 4, the feature map generates attention maps for both global and local branches. The attention maps from both global and local branches are concatenated and then linearly integrated. Following the residual connection with the input, an output with attention is obtained. The network extracts multi-scale features and obtains multi-scale attention maps by vertically stacking MLCA blocks, enriching the network’s receptive field.
Downsampling module: It is an important part of the feature extractor and is designed to decrease the feature map size while retaining important information. It consists of four parts: Depthwise Separable Convolution (DWConv) [37], batch normalization [38], GELU activation function [39], and MaxPooling [40], as illustrated in Figure 4b. DWConv [37] is an advanced convolutional operation that integrates depthwise convolution with pointwise convolution; it significantly reduces the number of parameters while simultaneously enabling the extraction of both spatial and channel features. Batch normalization [38] adjusts the input values of the activation function to lie within a more responsive region, thereby increasing the gradient and mitigating the issue of gradient disappearance. The GELU [39] is a nonlinear activation function based on the Gaussian error, endowing the network with superior expressive and abstract capabilities. MaxPooling [40] reduces the spatial size of the feature map by half.
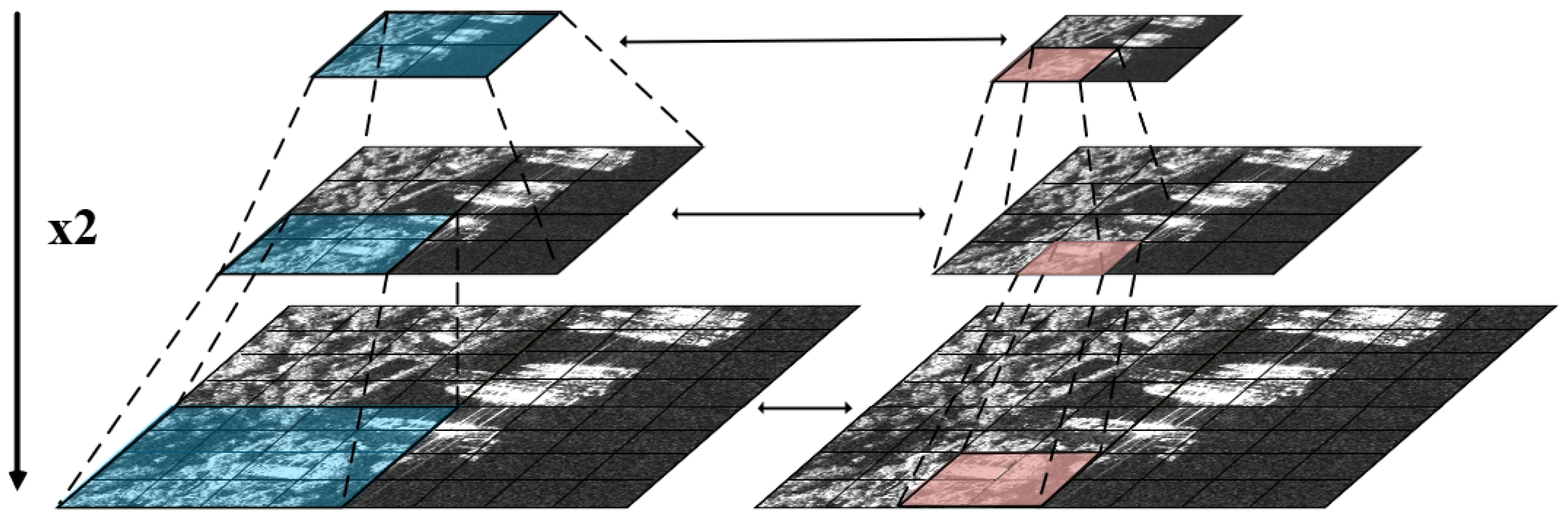
Patch embedding module: It is a residual structure used for multi-scale localization of target ships. This module consists of an adaptive convolution, whose kernel size is the same as the patch size. It encodes the implicit local positions of the target ships in units of patches, as illustrated in Figure 4c. As the network deepens, the positional information from the upper layer is transmitted to the next layer through residual connections. Furthermore, in the network, the feature scale decreases layer by layer while the patch size remains unchanged. The receptive field of the patch embedding also gradually expands, allowing for the acquisition of position information from multiple scales and perspectives, leading to better ship localization, which is as shown in Figure 5.
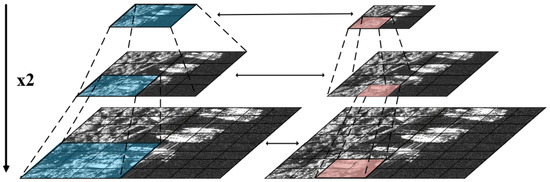
Figure 5.
The MLCA module forms a double pyramid-like structure in the multi-scale cascade feature extractor. It reflects the changes in scale of the feature maps and the expansion of their attention receptive fields.
2.3. Loss Function
Within LCAS-DetNet, the loss function comprises two components: a category classification loss () and a bounding-box regression loss ().
The category classification loss is depicted in Equation (4), which is used to determine whether the predicted category can correspond to the real label category and output the confidence score of each category.
where and represent the true distribution and predicted distribution, respectively.
The bounding-box regression loss is depicted in Equation (5), comprising both the DFL loss and Wise-IoUv3 loss [30]. We integrate the focusing mechanism into the bounding-box regression loss calculation by adopting the degree of deviation as a weight factor. This design helps minimize the influence of dataset quality differences on gradient updates.
where l is the true distribution, while and are the nearest integer to the left and right of l. is the difference between and the predicted distribution. We use and to represent the size of the minimum enclosing box. x, y and , are the horizontal and vertical coordinates of the predict box and real box. The outlier degree is an index used to assess the quality of anchor boxes. and are two definable parameters used to construct the non-monotone focusing coefficient .
2.4. Network Design
The feature extractor part of our network consists of a cascade of MLCA blocks, illustrated in the purple region of Figure 1. We input a SAR image with dimensions into the network and acquire multi-scale features with dimensions (, , ), (, , ), and (, , ) after passing through the third, fourth, and fifth layer MLCA block, respectively, where c is set to 32.
Drawing inspiration from YOLO framework [18], we incorporate its straightforward and efficient feature fusion and detection methodology, showcased in the green and yellow regions of Figure 1. The task of the neck part is to fuse multi-scale features from the feature extractor. Through a series of operations of the conv–batch normalization–SiLU (CBS) module, C2f module, and upsampling module, the network has information from different semantic spaces. In the head part, multiple prediction bounding boxes at different scales are derived by performing regression and classification on feature maps across three distinct scales, then an NMS [41] algorithm is employed to remove redundant detections exhibiting substantial overlap, yielding the final output in the form of , where is the label index value corresponding to the target, and is the confidence score of the target. x, y and h, w represent the position information and scale information of the marking box, respectively.
3. Materials and Experiments
3.1. Datasets
We selected the HRSID [31] and SSDD [32] datasets for the training and validation of our proposed method. These datasets encompass a variety of scenes, such as islands, ports, and inland regions, offering a comprehensive range of environments for assessment. Further details are provided below.
The HRSID [31] dataset stands as one of the most extensively utilized publicly accessible datasets in the field of SAR ship detection. It encompasses SAR imagery of ships featuring varied polarization modes, geographic regions, and resolutions, as shown in Figure 6. The HRSID dataset comprises 5604 high-resolution SAR images acquired by three high-resolution satellite sensors: TerraSAR-X, TandemiX, and Sentinel-1B. The images include three polarization modes, VV, HV, and HH, and the dataset contains a cumulative tally of 16,951 ship detection targets. The image resolutions in the HRSID dataset range from 0.5 m to 3 m per pixel. It encompasses diverse scenes including docks, nearshore areas, and ports, featuring 321 large, 7388 medium, and 9242 small ships. This distribution translates to proportions of 2% for large ships, 43.5% for medium ships, and 54.5% for small ships.

Figure 6.
Image samples from the HRSID dataset exhibiting ships of diverse sizes amidst intricate scenes, including coastal regions, ports, and docks. The HRSID dataset includes vessels of large, medium, and small scales captured in diverse scenarios.
The SSDD [32] dataset, also frequently employed in SAR ship detection research, contains raw SAR image data captured by three satellite sensors. The dataset encompasses four polarization modes, VV, VH, HH, and HV, with a count of 1160 images and 2456 annotated ship detection targets. The image resolution of the SSDD dataset ranges from 1 m to 15 m per pixel, covering various ship scenarios in open seas and coastal areas, as shown in Figure 7. The dataset includes a distribution of large, medium, and small ships, with quantities of 76, 935, and 1529, constituting proportions of 3%, 36.8%, and 60.2%.

Figure 7.
Image samples from the SSDD dataset, annotated in PASCAL VOC format, showcasing ships of various sizes, including large, medium, and small vessels.
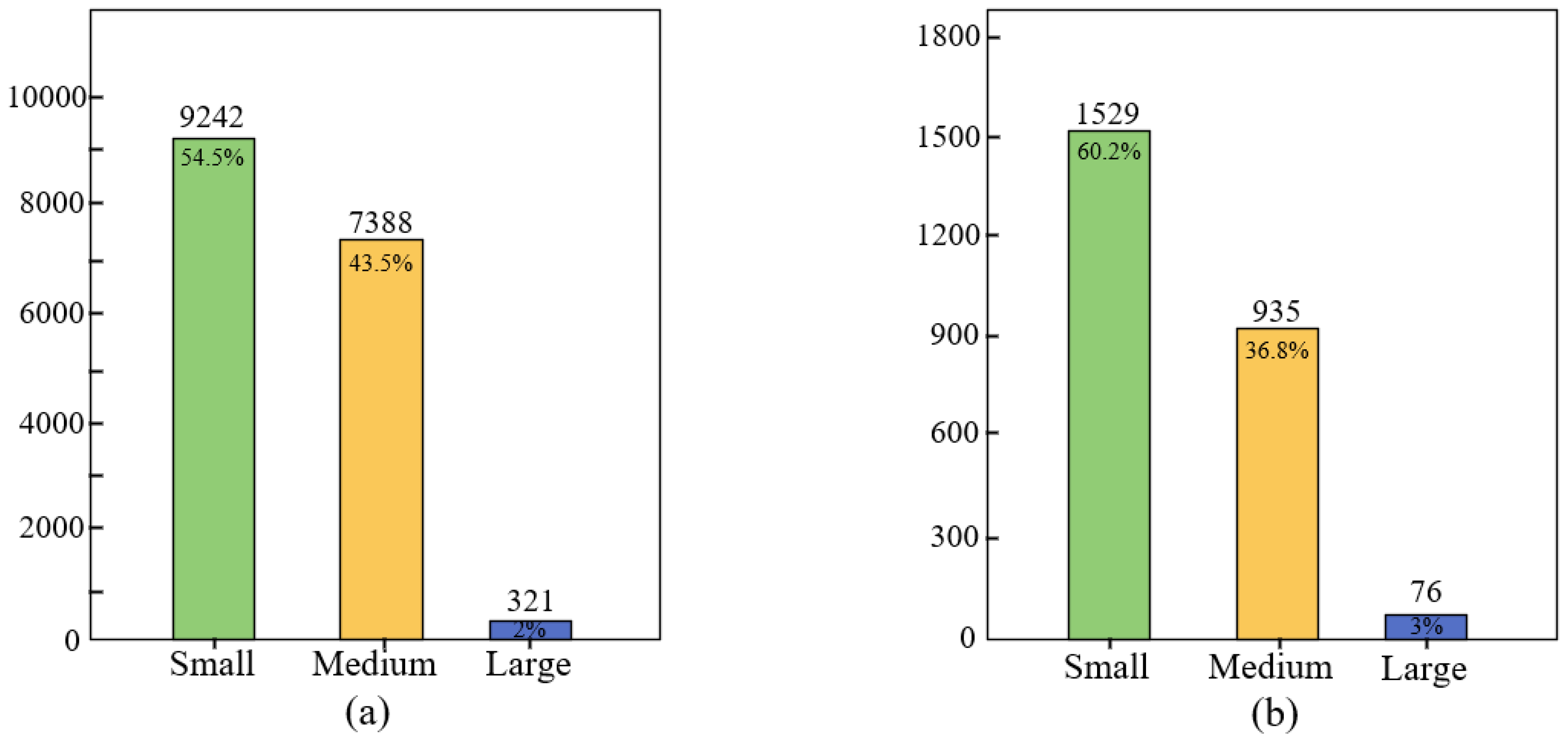
We provide significant details for the HRSID and SSDD datasets in Table 1. Moreover, we performed a statistical assessment regarding the distribution of large, medium, and small ships across both HRSID and SSDD datasets, presenting the findings through bar charts for visual clarity. The corresponding statistical data for the HRSID and SSDD datasets are depicted in Figure 8a,b. The analysis of the figures clearly reveals that small-sized ships predominate in both datasets, posing significant challenges for our ship detection endeavors.

Table 1.
The significant information table for the HRSID and SSDD datasets.
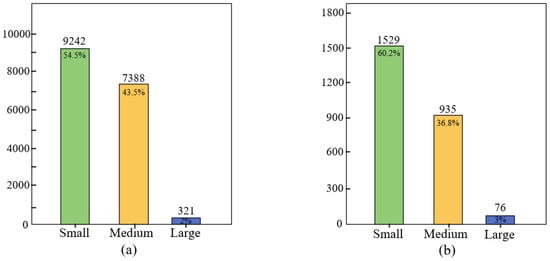
Figure 8.
Statistical data plots for different ship sizes in the HRSID and SSDD dataset. (a) shows the number and percentage of small, medium, and large ships in the HRSID dataset. (b) shows the same statistics in the SSDD dataset. The number of small-sized ships is the highest.
3.2. Experimental Setting
In this study, our algorithm was implemented using the PyTorch 1.8.1 framework and used the NVIDIA Quadro RTX 5000 GPU for accelerated computing. We employed SGD as the optimizer, with an initial learning rate of 0.01 and momentum of 0.937. The batch size was four, and the training epochs were fixed at 200.
3.3. Evaluation Indicators
We used a general target detection evaluation system to evaluate the effectiveness of various models in ship detection tasks. The definitions of precision and recall are given by Equations (6) and (7).
where TP stands for true positives, FP for false positives, and FN for false negatives.
When assessing model performance, individual precision and recall metrics may not provide sufficient information, as a model could exhibit a situation with extremely high precision and very low recall. To comprehensively consider the model’s performance, we used the F1-score as one of the model evaluation indicators. Specifically, the definition of the F1-score is provided in Equation (8).
In addition, the mean Average Precision (mAP) is a key indicator for evaluating the effectiveness of object detection algorithms. The definition is given in Equations (9) and (10). In Equation (9), P represents precision and R represents recall. The curve obtained by plotting precision with recall is denoted as P(R), where recall is on the horizontal axis and precision on the vertical axis. In Equation (10), N represents the number of label types in the downstream task, and AP(i) represents the AP value of the i-th label.
4. Results
4.1. Quantitative Analysis
We chose the above evaluation indicators as quantitative indicators to evaluate network performance. Among them, precision represents the model’s capability to correctly detect ships, while recall represents the model’s ability to capture all existing ships. The F1-score index and mAP are used together as a comprehensive evaluation index to assess the overall performance of the model.
On the HRSID dataset [31], our method exhibited superior performance in ship detection when contrasted with other advanced target detection algorithms, for example, Faster R-CNN [20], YOLOv5 [18], YOLOv7 [42], RetinaNet [43], CSD-YOLO [26], the work of Yu [25], and YOLOv8. Table 2 shows the experimental results of different methods on the HRSID dataset. The evaluation metrics precision and recall achieved 96.59% and 86.62%, while the overall assessment metrics F1-Score and mAP were 0.862 and 86.96%, demonstrating excellent performance compared to other networks. Precision showed an improvement of 1.16–17.61%, recall increased by 2.44–19.36%. Moreover, both F1-Score and mAP outperformed the results achieved by other networks. The quantitative results on the HRSID dataset indicated that only 3.41% of non-ship objects were incorrectly identified as ships. This suggests that the proposed LCAS-DetNet demonstrates remarkable potential in practical ship detection applications. Only a very small number of interfering noise is mistaken as ship hulls, which greatly enhances the reliability and practicality of the system.
Table 2.
Experimental results of different methods on the HRSID dataset. We have highlighted the superior performance of each evaluation indicator in bold.
On the SSDD dataset [32], we compared Faster R-CNN [20], YOLOv5 [18], YOLOv7 [42], FBR-Net [44], SSGE-Net [45], ARR-Net [46], the work of Yu [25], and YOLOv8 to our LCAS-DetNet. Table 3 shows the experimental results of different methods on the SSDD dataset. Our method demonstrated improvements in SAR ship detection. The precision value of LCAS-DetNet reached 97.52%, showing an improvement of 2.81–19.46% compared to other methods. The recall value reached 96.35%, showing an improvement of 4.21–12.94%. In the overall evaluation, the F1-Score reached 0.969, and the mAP reached 98.66%. The outstanding performance of the proposed network on the SSDD dataset further confirms its practical potential. The 96.35% recall rate indicates that in actual prediction results, only 3–4 ships out of every 100 are missed, providing a more reliable solution for the real-time monitoring of maritime ships.
Table 3.
Experimental results of different methods on the SSDD dataset. We have highlighted the superior performance of each evaluation indicator in bold.
4.2. Qualitative Analysis
This section presents the results of qualitative experiments on our proposed method. The ground truth is marked with a yellow detection box. The detection results of YOLOv5-L, YOLOv7, and LCAS-DetNet use green, purple, and pink detection boxes, respectively. The red ellipses in the figure indicate false detection results, and the orange ellipses indicate missed detection results.
The detection results depicted in Figure 9 exhibit the outstanding performance of LCAS-DetNet on the HRSID dataset. Figure 9a showcases images from the dataset captured in complex scenes. The ground truth shows in Figure 9b reveals a plethora of small ships, posing a significant challenge for detection. Despite these complexities, as evidenced in Figure 9e, our method demonstrated remarkable performance in such intricate scenarios. It effectively mitigated the missed detection of target ships and reduced the likelihood of false positives. This reinforced our confidence in the ability of LCAS-DetNet to attain multi-scale receptive fields through Multi-Location Cross-Attention (MLCA). Such a design accentuates both local and global features crucial for ship detection, consequently yielding outstanding performance in ship detection tasks.

Figure 9.
The detection results of different methods on the HRSID dataset. (a) shows the original image, while (b) depicts the ground truth. (c,d) illustrate the detection results of YOLOv5-L and YOLOv7, respectively. Finally, (e) showcases the detection results of LCAS-DetNet.
As illustrated in the comparison of detection results in Figure 10, our proposed method maintained excellent performance on the SSDD dataset. Figure 10a,b reveal that in complex scenes, there was interference in pixel values, thereby heightening the challenge of ship detection. It became easy to overlook the detection of small boats, and even some bright noises near the shore were mistakenly identified. Nevertheless, as depicted in Figure 10e, our proposed method effectively suppressed noise interference, accurately distinguished between background and ships, and minimized the likelihood of misjudgment. We attribute this to Multi-Location Attention (MLA), which computes pixel-level correlations in channel and spatial dimensions, further combating the impact of noise on the target ship’s pixel distribution.

Figure 10.
The detection results of different methods on the SSDD dataset. (a) shows the original image, while (b) depicts the ground truth. (c,d) illustrate the detection results of YOLOv5-L and YOLOv7, respectively. Finally, (e) showcases the detection results of LCAS-DetNet.
4.3. Ablation Study
Figure 1 shows our proposed network architecture, which mainly has the advantages of two parts: (1) a cascade feature extractor composed of MLCA blocks and (2) with a dynamic focusing mechanism. This section presents the results of ablation experiments, validating the efficacy of the MLCA mechanism and with a dynamic focusing mechanism in the SAR ship detection tasks. Below is a description of the notations used:
Basic network: a target detection network following the YOLOv8 framework without any MLCA mechanism or with a dynamic focusing mechanism.
Basic network-MLCA: improved basic network using a multi-scale cascade feature extractor composed of MLCA blocks.
Basic network-LOSS: improved basic network using with a dynamic focusing mechanism.
LCAS-DetNet: a target detection network using a cascade feature extractor composed of MLCA blocks and using with a dynamic focusing mechanism.
As shown in Table 4 and Table 5, adding MLCA and with a dynamic focusing mechanism, respectively, or adding both at the same time, the performance of the network was significantly enhanced on both datasets. The first row is the basic network of YOLOv8, and the remaining rows are variants improved by MLCA and with a dynamic focusing mechanism. The last line is our proposed LCAS-DetNet, which adopts the above two improvements simultaneously. The comprehensive evaluation index mAP showed an improvement of 6.94% and 2.51% on the HRSDI dataset and SSDD dataset.
Table 4.
Ablation experiments on the HRSID dataset. We have highlighted the superior performance of each evaluation indicator in bold.
Table 5.
Ablation experiments on the SSDD dataset. We have highlighted the superior performance of each evaluation indicator in bold.
Our method focused on SAR images from a multi-location perspective and fused the semantic information extracted locally and globally to determine the location of ships. We believe that such fused information has a good guiding role in improving the spatial awareness of the network. We additionally employed a calculation method featuring a dynamic focusing mechanism to construct . This strategy mitigated the influence of dataset quality discrepancies on gradients, enabling the network to prioritize average-quality examples during backpropagation updates. By leveraging these approaches, our network boosted its detection accuracy.
5. Conclusions
This study proposed a Multi-Location Cross-Attention Ship Detection Network (LCAS-DetNet) for ship detection on SAR images. The network’s ability in multi-scale feature extraction and noise resistance was validated on two datasets. Through ablative experiments, the effectiveness of the proposed Multi-Location Cross-Attention (MLCA) in spatial localization, salt-and-pepper noise suppression, and water surface ripple interference was investigated, thus further improving the ship detection accuracy. The demonstrated potential of the MLCA mechanism in ship monitoring tasks confirmed its robust adaptability to SAR image data. Future work will focus on optimizing the MLCA mechanism to further investigate the impact of correlation attention on target localization and target value classification outcomes. Additionally, we aim to extend its application to a broader spectrum of remote sensing downstream tasks.
Author Contributions
Conceptualization, J.L. (Junlin Liu) and D.L.; methodology, J.L. (Junlin Liu), D.L., and X.W.; software, J.L. (Junlin Liu), D.L., and X.W.; validation, J.L. (Junlin Liu); formal analysis, B.Y. and G.C.; investigation, B.Y. and G.C.; writing—original draft preparation, J.L. (Junlin Liu) and X.W.; writing—review and editing, J.L. (Jun Li); visualization, J.L. (Junlin Liu); resources, J.L. (Jun Li); supervision, J.L. (Jun Li); project administration, J.L. (Jun Li); funding acquisition, J.L. (Jun Li). All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code can be obtained at https://github.com/AaronLiu0702/LCAS-DetNet (accessed on 18 May 2024).
Acknowledgments
The authors express gratitude to the anonymous reviewers for their insightful comments, which contributed to the enhancement of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SAR | Synthetic Aperture Radar |
| LCAS-DetNet | Multi-Location Cross-Attention Ship Detection Network |
| MLCA | Multi-Location Cross-Attention |
| MLA | Multi-Location Attention |
| SVM | Support Vector Machine |
| GIoU | Generalized Intersection over Union |
| CNNs | Convolutional Neural Networks |
| CSP | Cross Stage Partial |
| ViT | Vision Transformer |
| GELU | Gaussian Error Linear Unit |
| NMS | Non-Maximum Suppression |
| SGD | Stochastic Gradient Descent |
| DW-Conv | Depthwise Separable Convolution |
| FPN | Feature Pyramid Network |
| GPU | Graphics Processing Unit |
| CUDA | Compute Unified Device Architecture |
| GIoU | Generalized Intersection over Union |
References
- Xu, X.; Zhang, X.; Zhang, T. Lite-yolov5: A lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Zou, B.; Qin, J.; Zhang, L. Vehicle detection based on semantic-context enhancement for high-resolution sar images in complex background. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4503905. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, S.; Zhang, H.; Wu, F.; Zhang, B. Ship detection for high-resolution sar images based on feature analysis. IEEE Geosci. Remote Sens. Lett. 2013, 11, 119–123. [Google Scholar] [CrossRef]
- Gaber, A.; Koch, M.; Griesh, M.H.; Sato, M. Sar remote sensing of buried faults: Implications for groundwater exploration in the western desert of egypt. Sens. Imaging Int. J. 2011, 12, 133–151. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Ratha, D.; Dey, S.; Bhattacharya, A.; Lopez-Sanchez, J.M.; McNairn, H.; Rao, Y.S. Dual polarimetric radar vegetation index for crop growth monitoring using sentinel-1 sar data. Remote Sens. Environ. 2020, 247, 111954. [Google Scholar] [CrossRef]
- Yamaguchi, Y. Disaster monitoring by fully polarimetric sar data acquired with alos-palsar. Proc. IEEE 2012, 100, 2851–2860. [Google Scholar] [CrossRef]
- Pang, L.; Li, B.; Zhang, F.; Meng, X.; Zhang, L. A lightweight yolov5-mne algorithm for sar ship detection. Sensors 2022, 22, 7088. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Principe, J.C. Support vector machines for sar automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 643–654. [Google Scholar] [CrossRef]
- Lombardo, P.; Sciotti, M. Segmentation-based technique for ship detection in sar images. IEE Proc.-Radar Sonar Navig. 2001, 148, 147–159. [Google Scholar] [CrossRef]
- Iervolino, P.; Guida, R. A novel ship detector based on the generalized-likelihood ratio test for sar imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3616–3630. [Google Scholar] [CrossRef]
- Lang, H.; Xi, Y.; Zhang, X. Ship detection in high-resolution sar images by clustering spatially enhanced pixel descriptor. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5407–5423. [Google Scholar] [CrossRef]
- Li, Y.; Ding, Z.; Zhang, C.; Wang, Y.; Chen, J. Sar ship detection based on resnet and transfer learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1188–1191. [Google Scholar]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An anchor-free detection method for ship targets in high-resolution sar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- Shin, H.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on yolov5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A sar dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for sar ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Li, S.; Fu, X.; Dong, J. Improved ship detection algorithm based on yolox for sar outline enhancement image. Remote Sens. 2022, 14, 4070. [Google Scholar] [CrossRef]
- Yu, C.; Shin, Y. Sar ship detection based on improved yolov5 and bifpn. ICT Express 2023, 10, 28–33. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-scale ship detection algorithm based on yolov7 for complex scene sar images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A novel multidimensional domain deep learning network for sar ship detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5203213. [Google Scholar] [CrossRef]
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. A deep neural network based on an attention mechanism for sar ship detection in multiscale and complex scenarios. IEEE Access 2019, 7, 104848–104863. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise separable convolution neural network for high-speed sar ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-iou: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. Hrsid: A high-resolution sar images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. Sar ship detection dataset (ssdd): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, W.; Liu, K.; Zhang, L.; Cheng, F. Object detection based on an adaptive attention mechanism. Sci. Rep. 2020, 10, 11307. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, C.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the ICML’15: Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: New York, NY, USA, 2015; pp. 448–456. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of cnn activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 850–855. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An anchor-free method based on feature balancing and refinement network for multiscale ship detection in sar images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1331–1344. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale sar images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2020, 59, 379–391. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in sar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).