Abstract
Recent advancements in deep learning have enabled gaze estimation from images of the face and eye areas without the need for precise geometric locations of the eyes and face. This approach eliminates the need for complex user-dependent calibration and the issues associated with extracting and tracking geometric positions, making further exploration of gaze position performance enhancements challenging. Motivated by this, our study focuses on an ensemble loss function that can enhance the performance of existing 2D-based deep learning models for gaze coordinate (x, y) prediction. We propose a new function and demonstrate its effectiveness by applying it to models from prior studies. The results show significant performance improvements across all cases. When applied to ResNet and iTracker models, the average absolute error reduced significantly from 7.5 cm to 1.2 cm and from 7.67 cm to 1.3 cm, respectively. Notably, when implemented on the AFF-Net, which boasts state-of-the-art performance, the average absolute error was reduced from 4.21 cm to 0.81 cm, based on our MPIIFaceGaze dataset. Additionally, predictions for ranges never encountered during the training phase also displayed a very low error of 0.77 cm in terms of MAE without any personalization process. These findings suggest significant potential for accuracy improvements while maintaining computational complexity similar to the existing models without the need for creating additional or more complex models.
1. Introduction
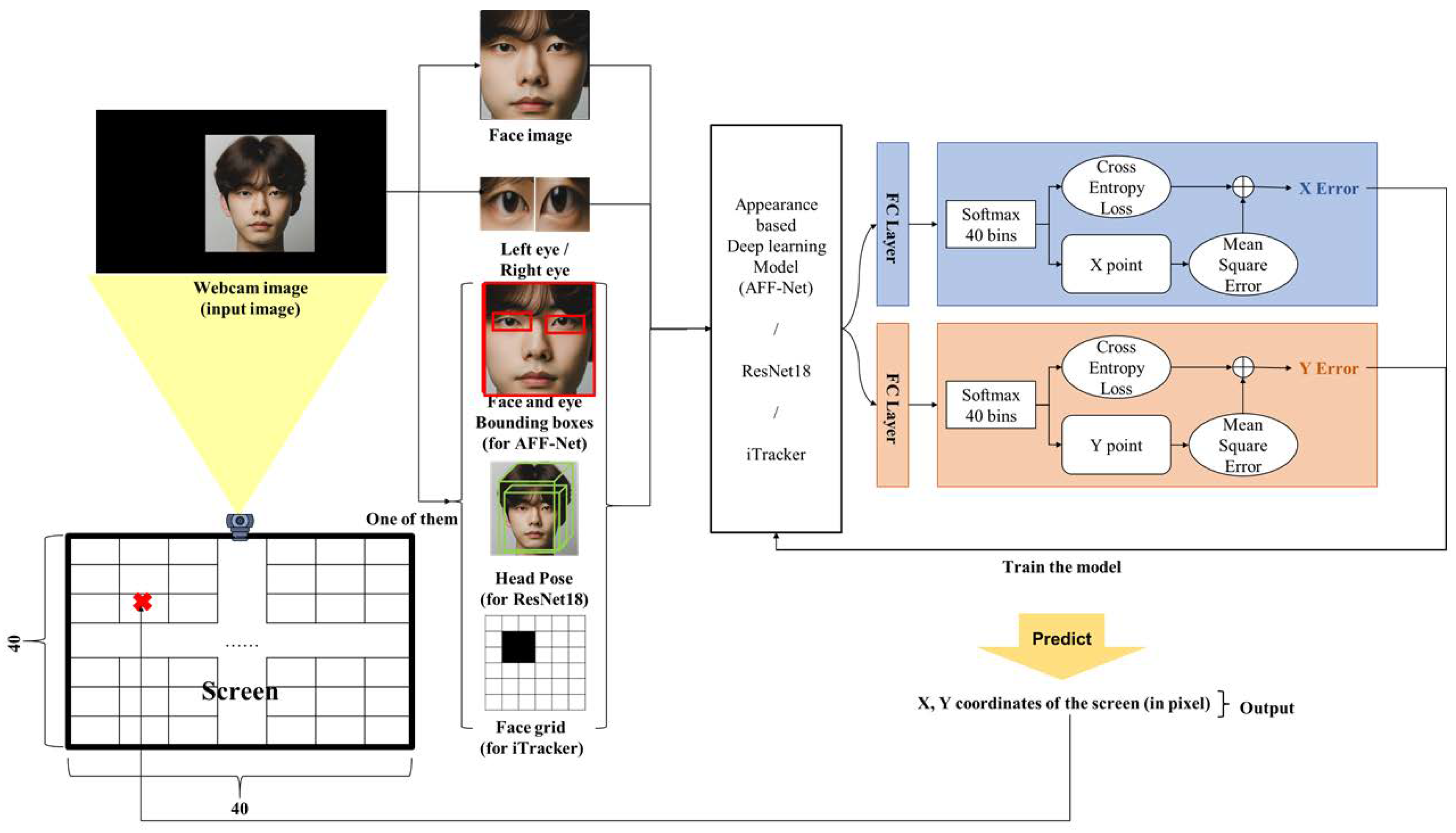
Gaze estimation is a field that involves tracking the direction of a person’s gaze, allowing for the control of input devices such as a mouse or keyboard solely through eye movements [1] or as a reference to a consumer’s area of interest when creating ads [2]. Additionally, in virtual reality settings, it can predict user attention and analyze emotions to enhance device recognition [3]. Furthermore, in the field of human–computer interaction (HCI), user engagement can be indicated through gaze tracking in interactions with robots [4] and open dialogue systems. Various approaches have been suggested to enhance gaze estimation’s functionality and deliver enhanced user satisfaction. Classical gaze estimation methods relied on the numerical computations of facial features, including pupil size, distance between pupils, and the position of pupils relative to each other [5]. However, these methods proved inflexible in response to differing targets and environments. Once a numerical model was established for a specific target, it could not be utilized elsewhere. In the last decade, hardware capabilities have made significant progress, and the collection of extensive datasets such as MPIIGaze [6], GazeCapture [7], and Gaze360 [8] has given rise to deep-learning-based gaze estimation techniques. Appearance-based models have shown impressive performance in predicting gaze direction. For instance, FAZE [9] employs facial images and gaze direction as input, utilizing meta-learning on latent vectors to predict gaze direction. Additionally, a ResNet-trained model that uses images of faces and pairs of eyes has outperformed iTracker [7] in gaze accuracy. Another notable gaze estimation model, SAGE (fast accurate gaze tracker) [10], combines eye images and landmarks, demonstrating high effectiveness. These and many other types of research have been done on gaze estimation from facial images [11,12,13]. However, a significant obstacle to furthering these models is the limited availability of resources. High-performance models often require sophisticated deep architectures and significant computational resources, along with extensive datasets [14]. This creates a formidable impediment, hindering developers from deploying these models in everyday services and applications. This paper presents a computational framework for gaze estimation through regression analysis, utilizing ensemble loss functions to enhance efficiency. Our aim is to comprehensively estimate gaze coordinates while preserving computational resources. Our methodology enhances gaze tracking precision by integrating an ensemble loss approach within the deep learning framework. Specifically, we employ an ensemble of loss functions that not only evaluate the regression accuracy of the predicted gaze coordinates but also incorporate a multi-class classification scheme. By combining these distinct aspects of loss functions, our model effectively addresses both the precision of gaze coordinates and their categorical accuracy, leading to improved performance in gaze tracking applications. This innovative approach enables the achievement of highly accurate gaze coordinates by adjusting loss functions, eliminating the need for extensive network rebuilding, complex neural network training, or the accumulation of immense datasets tailored to a specific deep neural network. Our proposed framework reduces computational and resource expenses and enhances resource efficiency significantly. Additionally, there have been advancements in appearance-based models for predicting gaze direction in 3D angles and forecasting standardized X and Y coordinates on a 2D plane [15,16]. These advancements are applicable to various devices, including laptops, smartphones, and tablet PCs. As the field progresses, this research contributes to the enhancement of gaze estimation techniques, providing a practical and resource-efficient solution with broad applicability. This approach is akin to the method proposed in the previous work [17], where the squeeze-and-excitation network (SE-Net) introduced SE blocks that could be applied to various existing deep learning models to improve performance. In this paper, the effectiveness of ensemble loss applied as blocks to various existing gaze tracking models is experimentally evaluated. The overall structure of the proposed method is shown in Figure 1.
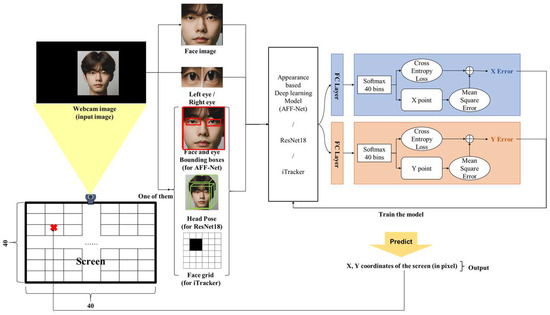
Figure 1.
The brief usage of proposed method.
2. Related Works
In recent times, there are broadly two methods for gaze prediction: The first method is the model-based approach, and the second is the appearance-based approach. The model-based approach predicts gaze by modeling physical features and shapes such as facial rotation and eye information. It utilizes a 3D model of the head and eyes to calculate the movement vector of the pupil based on the motion information of these two features. However, it has the drawback of being limited in terms of applicable environments and equipment. Next, the appearance-based approach extracts features (such as eyes and face) from input face images to predict gaze. This method allows gaze prediction from images acquired with relatively cost-effective equipment. In recent years, advances in hardware performance have made it possible to build large datasets (MPIIGaze, Gaze360, GazeCapture, etc.), making it possible to study eye tracking using deep learning. As a result, the research on utilizing deep learning-based appearance-based models for gaze prediction has been active [18,19,20,21]. First, Zhang et al. [6] proposed an architecture that employs a convolutional neural network(CNN)-based VGG model for predicting gaze using solely images. The inputs consist of images of the face, both eyes, and head pose, whereas the outputs use gaze angle vectors. Their proposed technique demonstrated an accuracy of 13.9° on the MPIIGaze dataset and 10.5° on the Eyediap dataset [22], based on mean errors. Although this study introduced the MPIIGaze data, the model’s performance itself is not high. Next, FAZE [9] takes face images and gaze direction vectors as input and utilizes meta-learning to perform gaze prediction using the latent vectors of the encoder–decoder. For this method, they performed calibration on person ID with a small number of images, around three. Without the calibration on GazeCapture data, the mean error is approximately 3.49°, but with three calibration samples, it is 3.18 degrees, which is the state-of-the-art performance at the time. For MPIIGaze, the mean error is 5.23° without calibration, which is lower than [6], but with calibration, the error decreased to 3.42°. However, the disadvantage of this study is that while it can be used on personal devices, it is difficult to use it in situations where the calibration step is difficult to apply, such as the problem of tracking an unspecified number of eyes. The same difficulty appears in another dictionary study, Sage [10]. iTracker [7] is a study on predicting the gaze point on a mobile device, a smartphone, or tablet PC in a 2D plane using only the bilateral eye and face images in the input video. The study introduces a new dataset, GazeCapture, which consists of approximately 2.5 M images from 1450 identities. The study used a CNN model based on AlexNet, which is a lightweight model that can achieve 10–15 fps that can be performed in real-time. Based on the mean absolute error without calibration, the accuracy was 1.71 cm on a mobile phone and 2.53 cm on a tablet PC. With calibration, the accuracy improved to 1.34 cm and 2.12. For this model, the input dataset was obtained from input image and the output performance was satisfactory. Therefore, we used this model as one of the backbone models to apply the ensemble loss proposed in our study. An adaptive feature fusion network (AFF-Net) [23] is a model that has shown the best performance on the problem of predicting X and Y coordinates in a 2D plane [5]. As input, it takes a photo of a face and both eyes, and the coordinate values of the face and both eyes. In the prediction phase, we used a single, fully connected layer to infer the outputs, which are the X and Y coordinates, via regression. Using the GazeCapture dataset, they achieved a mean absolute error of 1.62 cm on smartphones and 2.30 cm on tablets. For the MPIIFaceGaze dataset, they reported a mean absolute error of 3.9 cm. Since the results of that study show state-of-the-art performance among studies using RGB-based images to predict 2D planes, we also used that model as a backbone model to show the validity of our ensemble loss. Table 1 summarizes the related works for performance comparison with our work. In this paper, a deep learning model design incorporating the proposed ensemble loss is presented, aiming to perform regression on the user’s gaze location (2D gaze) based on appearance inputs such as eyes and face images and the corresponding coordinates. One is a state-of-the-art performing model [23], one is a very simple but poor performing model [21], and the last is a moderate performer [7]. Another difference between the models is that they use images of the eyes and face, and the additional inputs are head-pose [21], face grid [7], and the coordinates of the face and eyes in the image [23]. We intentionally chose to experiment with models of varying performance with different inputs to show that they all perform better in a wider range of cases.

Table 1.
A summary of related research with comparative performance.
3. Materials and Methods
In this paper, we propose structural changes to improve the gaze prediction performance and generalization function of the model used to predict gaze position in the existing appearance-based deep learning models. In the past, the predicted values from the final fully connected (FC) layer were used as the gaze position result (in 2D, this would be (x, y) coordinates; in 3D, it would be the gaze angle vector). However, in this paper, an additional loss block is designed on top of the FC layer results to predict the 2D gaze coordinates on a PC screen. First, as in the conventional approach, a CNN-based feature extractor is used to extract feature maps from appearance data such as face images, eye images, coordinates of face and eye images from input picture, head poses, and face grid images. These feature maps are then used to predict 40 bins for both the x and y coordinates based on the resolution of the monitor. For gaze tracking, a combination of euclidean distance loss for gaze coordinates and cross-entropy loss for the bins corresponding to the coordinates is applied. This results in improved generalization capabilities and prediction accuracy for various gaze tracking feature extractors that have been previously utilized.
3.1. Dataset
As the demand for improving gaze tracking performance through deep-learning-based approaches, particularly in the context of appearance-based methods, has been on the rise, large-scale datasets have been constructed. These datasets encompass various environments, ranging from controlled experimental settings to unconstrained outdoor scenarios. In this paper, to verify the versatility of the ensemble loss in terms of accuracy enhancement, we trained our model using the MPIIFaceGaze dataset [6], which was collected in an unconstrained experimental environment. We evaluated the accuracy of the predicted gaze coordinates using the Euclidean distance metric. This dataset is one of the most commonly used datasets for appearance-based gaze tracking methods and consists of cropped face, left eye, right eye images, grid information, and head pose information from facial datasets, tailored for our research. MPIIGaze is a publicly available dataset that provides a total of 213,659 images collected over several months from 15 participants for the gaze estimation task. It offers appearance-based data such as face images, eye images, and head pose, along with 2D gaze positions in pixel coordinates for each participant. The dataset comprises images captured under various backgrounds, lighting conditions, and natural head movements during data acquisition. Utilizing this dataset, we aimed to train a model that is robust in gaze tracking across diverse environments. In this paper, we employed a leave-one-out cross-validation approach, training the model using data from 14 out of the 15 participants and evaluating it on the data from the remaining participant. This process was repeated 15 times to perform leave-one-out cross-validation.
3.2. Models
In this paper, we performed an experiment to evaluate the accuracy improvement when applying ensemble loss to an existing deep learning model for eye tracking. To achieve this, we leveraged various existing deep learning models designed for eye tracking and applied them for feature extraction and training, and in the final step, we added a fully connected layer to regress x and y coordinates based on the features extracted from these models. A model involving ensemble loss is described in Figure 1. One of the deep learning models used in this paper is AFF-Net [23]. AFF-Net is a deep-learning-based model used in existing eye tracking, and extracts features by inputting 2D image information of the face and eyes. AFF-Net is a model that improves eye tracking accuracy by adaptively fusing two eye features and extracting the eye features derived from facial appearance characteristics and is a model that demonstrates cutting-edge performance. As you can see in Figure 1, we learn the features of the face and eye images and the landmark coordinates of their locations. These learned features are used for training by applying ensemble loss.
The second model is an eye tracking model using the residual neural network (ResNet) proposed by En Teng Wong [21]. ResNet can solve the performance saturation problem caused by deep networks by using residual blocks. Additionally, it has excellent learning stability and can learn complex features, making it suitable for eye tracking. As you can see in Figure 1, face images, eye images, and head pose information are taken as inputs to the ResNet-18 model to learn features, and then ensemble loss is applied in the final stage of training.
The third model is iTracker [7]. iTracker is a deep learning model that predicts gaze using a deep convolutional neural network (CNN) using input consisting of cropped images of both eyes and the face, along with facial position coordinates, called a face grid, from image data. Although iTracker has a simple structure, it provides fast and accurate gaze prediction because it integrates facial grid information. As seen in Figure 1, we extract features based on CNN and similarly apply ensemble loss for training.
3.3. Ensemble Loss Function
We applied the results of each loss function to the x- and y-axis. This is to reduce the impact of the increase and decrease on each axis on the other, since they are independent from each other. The formula for the loss function for each axis is shown in Equation (1) below. Furthermore, unlike the previous studies that used cm values of X and Y as label values, we used pixel values as input. This was chosen because they have a larger range than cm, so the gradient to reduce loss was larger, and the accuracy upon convergence was confirmed to be higher than when cm was used. Through experiments, we confirmed that the use of pixel values is useful. Finally, we did not end the loss by predicting the X and Y coordinate points. We additionally learned the loss for the category prediction of where the predicted coordinates are located in the width and height zones, each divided into 40 columns (a total of 1600 zones). This helps improve performance in that it adds a larger penalty loss if the coordinate prediction is not located in the correct answer area among the 1600 areas. The overall loss is the cross-entropy loss plus the mean square error value, and the learning is performed by calculating the loss for the x and y axes, respectively.
In Equation (1), gt means the correct answer and pred means the predicted value. The first term in the right hand side is the cross-entropy loss, and the second term is the mean square error. For every prediction, learning progressed in the direction of decreasing the cross-entropy loss for the correct answer and discovering which cell the prediction was located in, as well as the mean square error value for the actual prediction value.
4. Results
We compared the results before and after implementing the loss function for the three models we applied. The training data remained the same, and we averaged the results over 15 trials using the leave-one-out method [24]. Additionally, no preliminary performance data were available for the ResNet-based model [21], so our reimplementation was based on the paper. Notably, the results of model [21], which is based on ResNet, are of particular interest.
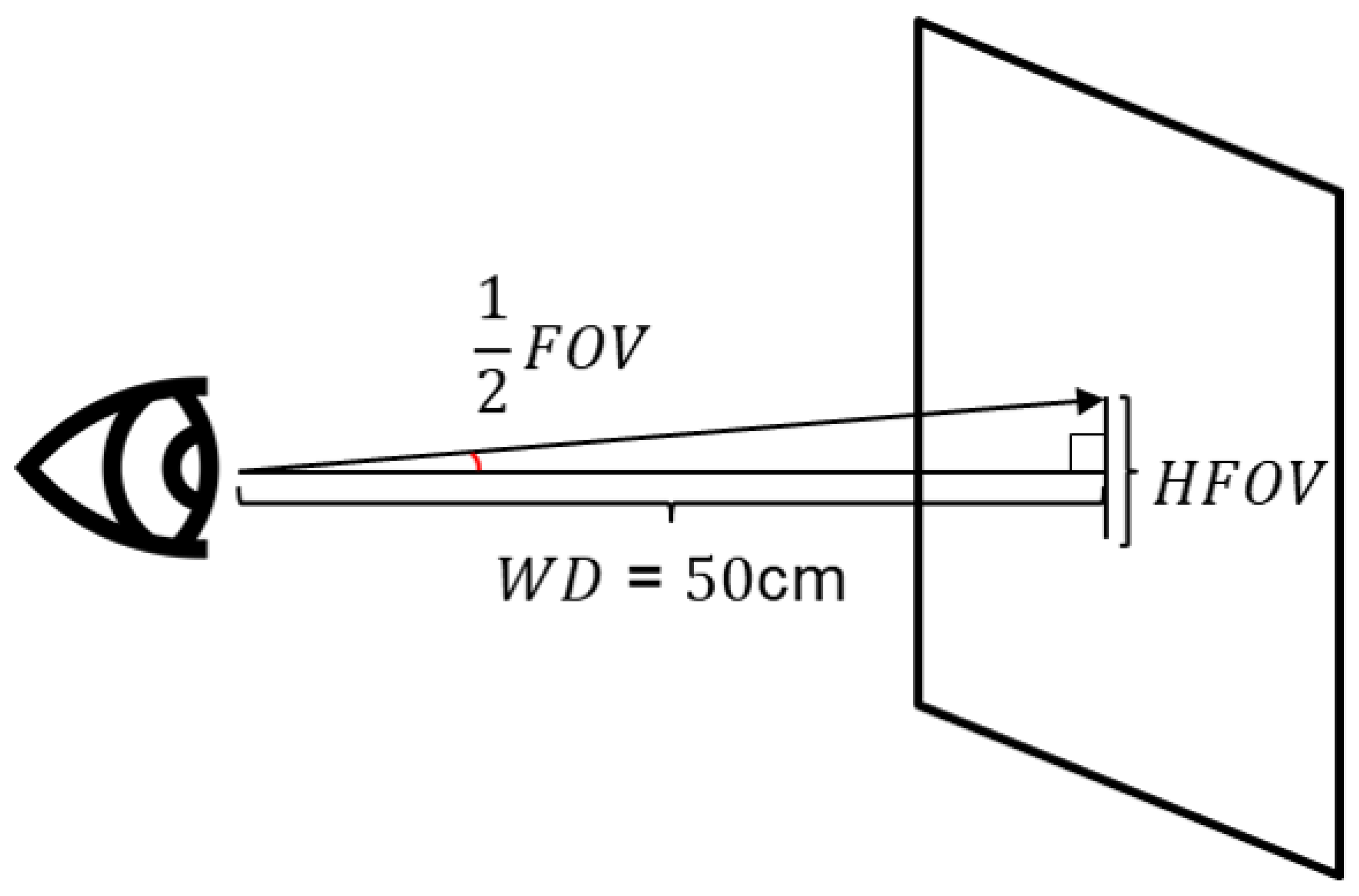
In Table 2, the error of the gaze coordinate predicted by the fully-connected layer of the existing deep learning model (cm) and the error of the gaze coordinate predicted by applying the ensemble loss proposed in this study (cm) were used in the experiment. It was expressed in each of the three models used and converted to 3D error using Equation (2). The picture in Figure 2 provides an additional explanation of the formulas and conversion. Equation (2) is a field of view (FOV) formula that calculates 3D error. In the formula, working distance (WD) refers to the working distance from the lens, which means the millimeter distance between the camera and the subject’s eyes, and horizontal FOV (HFOV) represents the millimeter distance when the line of sight is expressed in 2D. In this study, WD was set according to the MPIIFaceGaze dataset construction environment used in the experiment. Lastly, the prediction within two centimeters based on Euclidean distance is expressed as a percent. As a result, there is a clear performance difference between the results of eye tracking in Equation (2), with and without the proposed loss function. In particular, AFF-Net, which currently has the highest level of performance, has implemented a new level of performance by strengthening the loss function. We also retrieved the results for each individual ID and displayed individual error measures in Table 3 below.
Table 2.
Average results of each model.
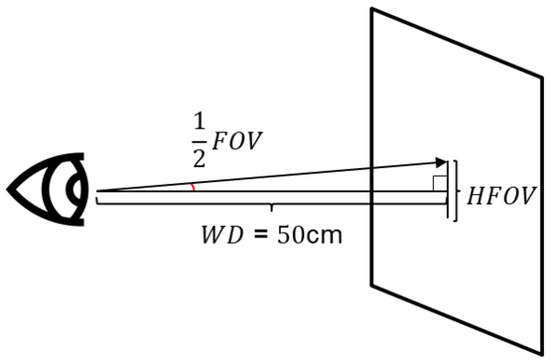
Figure 2.
Illustration to explain how conversion to 3D degree is applied.
Table 3.
Average Euclidean distance between actual and predicted values for each person ID (cm).
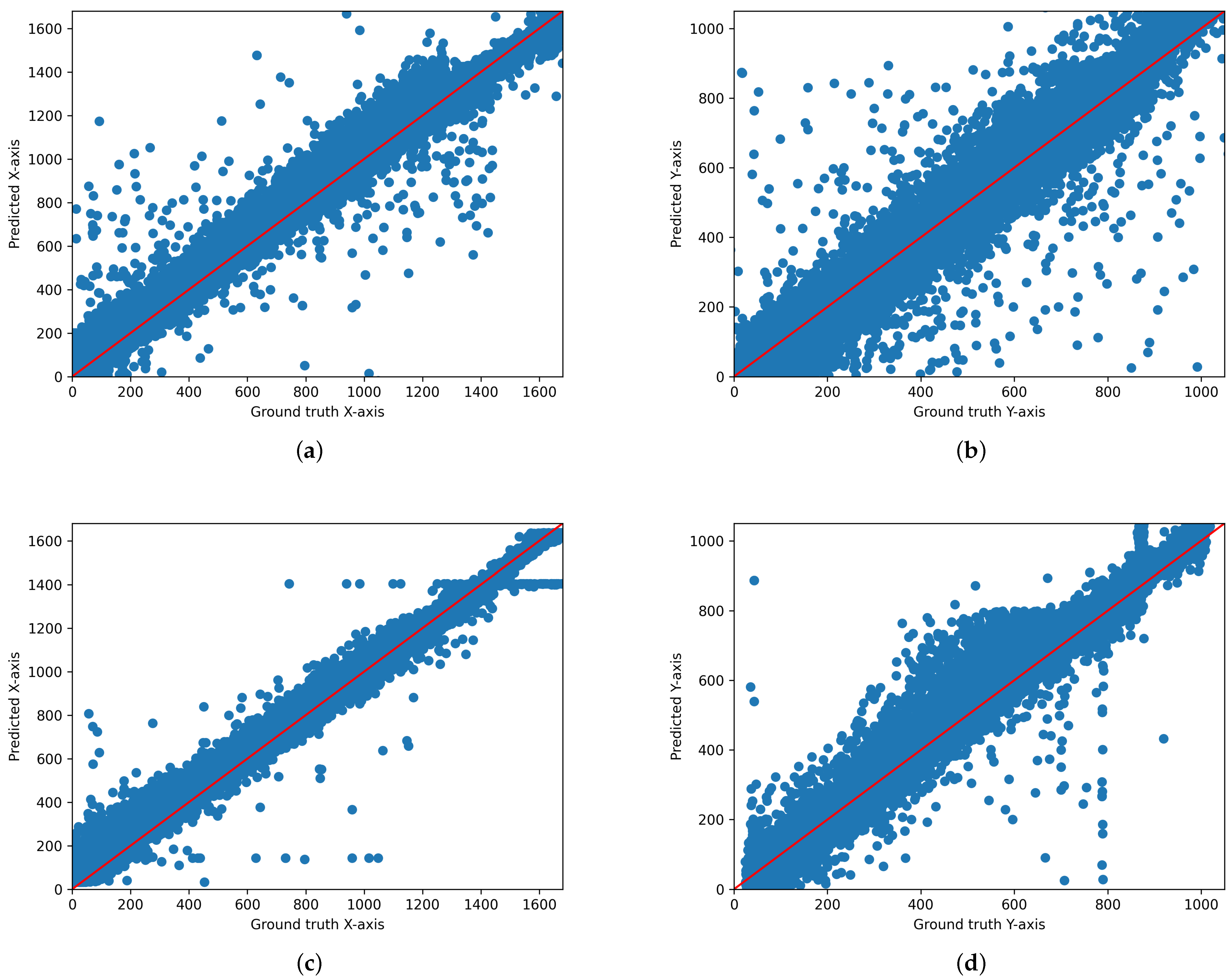
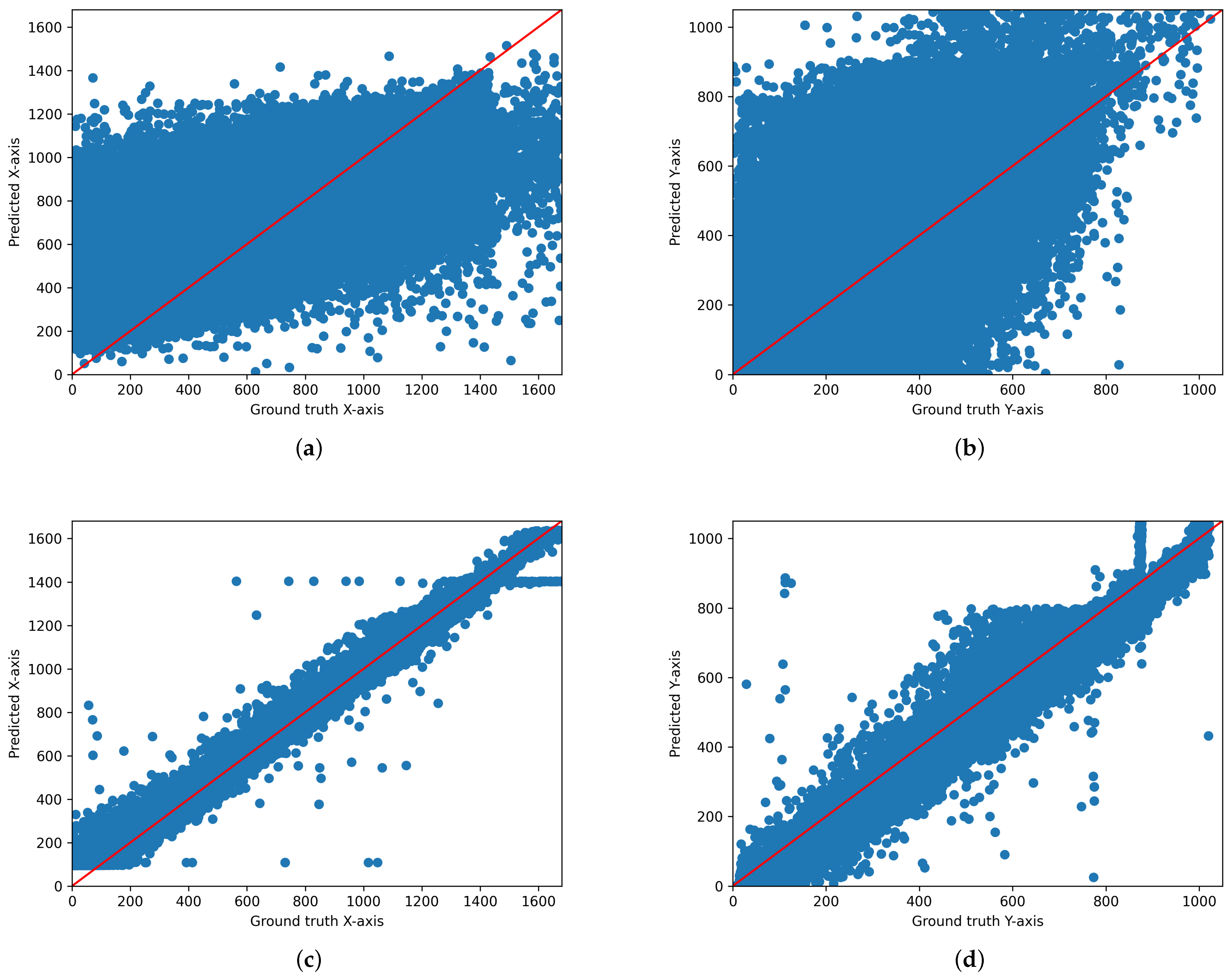
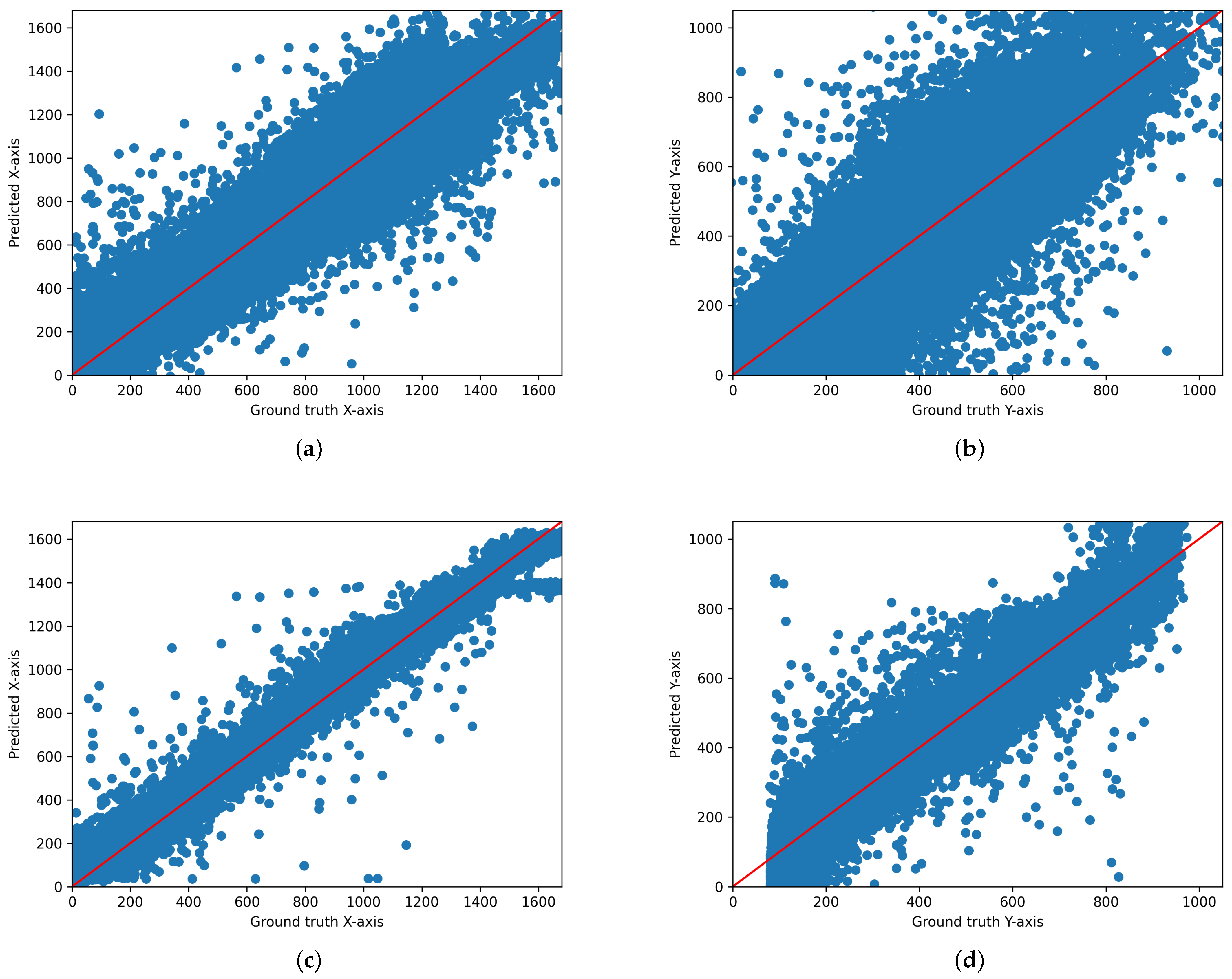
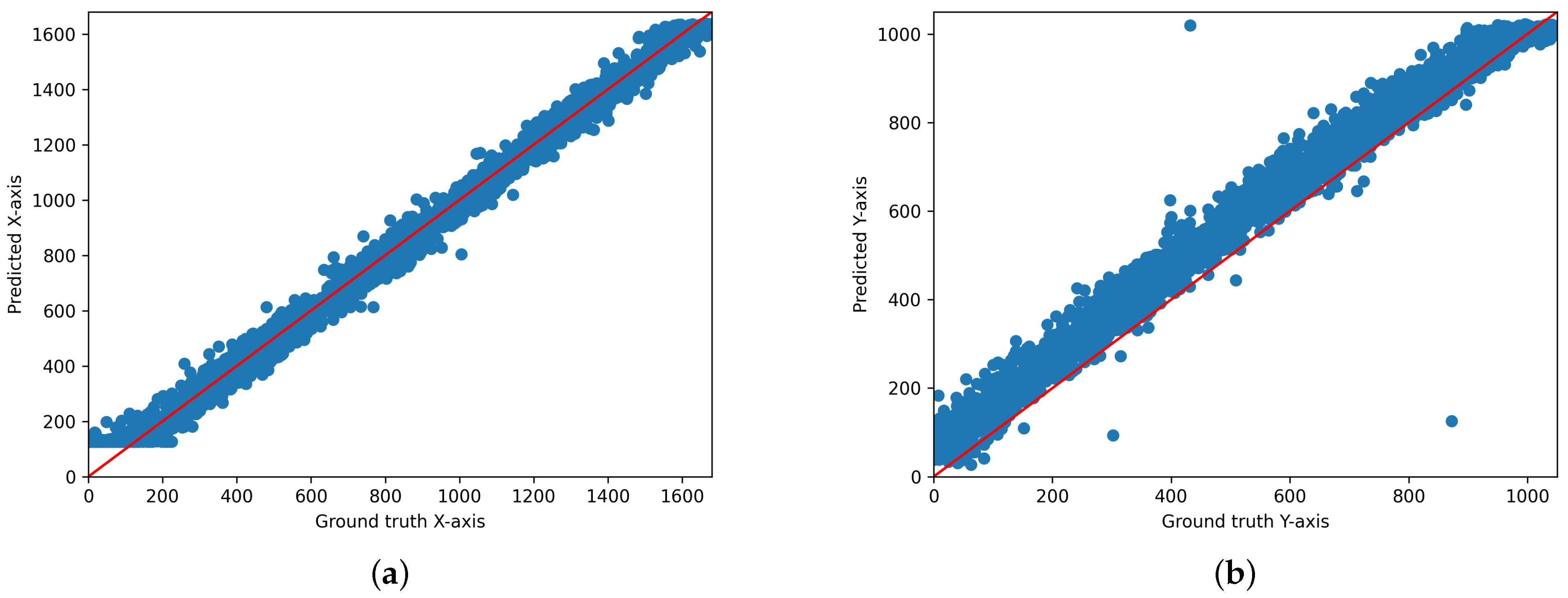
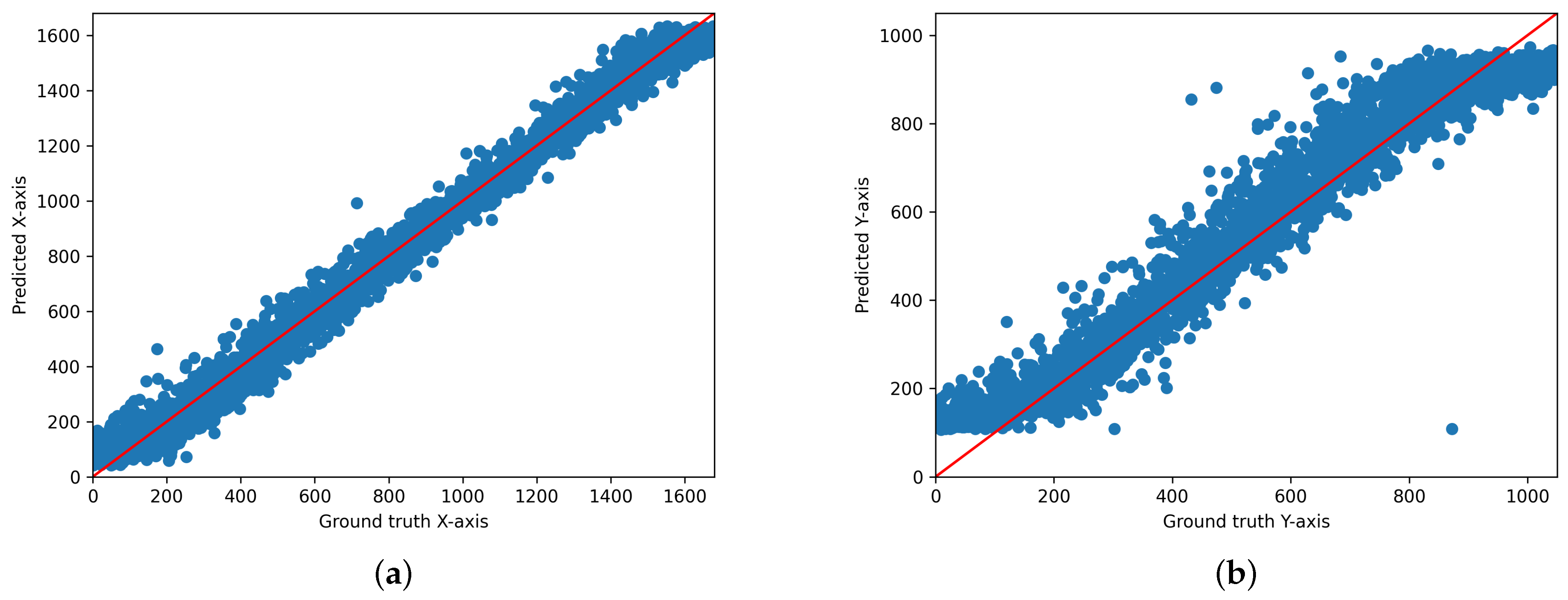
We output the scatter plot of ground truth and predicted values for each model. Figure 3, Figure 4 and Figure 5 illustrate the gaze coordinates predicted by the model using the proposed ensemble loss function, displayed in pixel units at a resolution of 1680 × 1050. The results show that all models align more closely with the x = y axis. Specifically, the ResNet model [21] exhibited a low correlation between predicted and actual values when trained solely on the original model. However, the graph demonstrates that there is a significant correlation when the loss function is implemented. This indicates that the loss function enhances the performance of both state-of-the-art and under performing models.
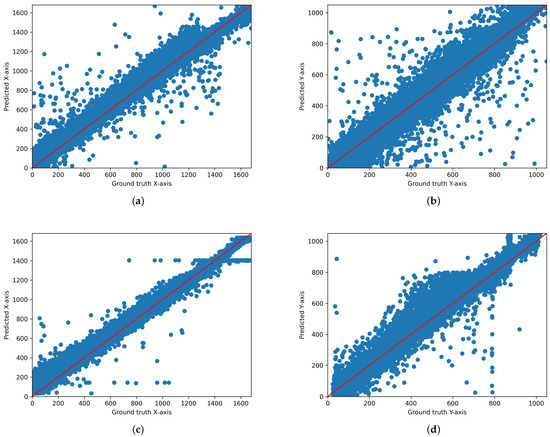
Figure 3.
Scatter plot of the predicted and actual values on the x-axis and y-axis for AFF-Net. (a) Original AFF-Net (x-axis), (b) Original AFF-Net (y-axis), (c) AFF-Net with ensemble loss function (x-axis), (d) AFF-Net with ensemble-loss function (y-axis). These graphs are displayed in pixel units at a resolution of 1680 × 1050.
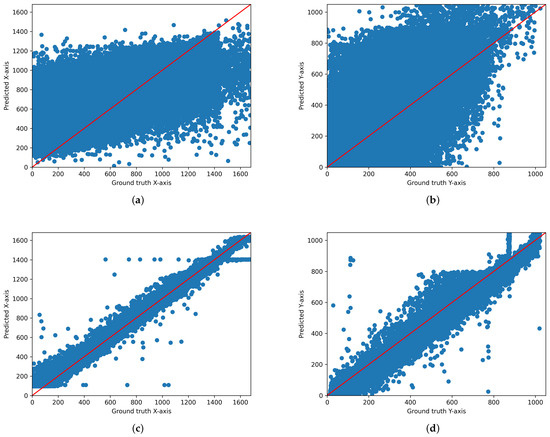
Figure 4.
Scatter plot of the predicted and actual values on the x-axis and y-axis for ResNet18. (a) Original ResNet18 (x-axis), (b) Original ResNet18 (y-axis), (c) ResNet18 with ensemble loss function (x-axis), (d) ResNet18 with ensemble loss function (y-axis). These graphs are displayed in pixel units at a resolution of 1680 × 1050.
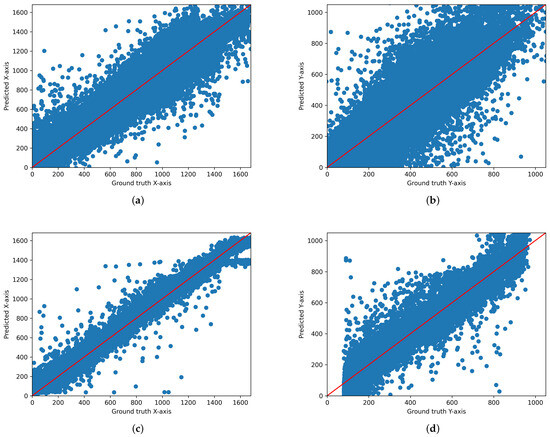
Figure 5.
Scatter plot of the predicted and actual values on the x-axis and y-axis for iTracker. (a) Original iTracker (x-axis), (b) Original iTracker (y-axis), (c) iTracker with ensemble-loss function (x-axis), (d) iTracker with ensemble-loss function (y-axis). These graphs are displayed in pixel units at a resolution of 1680 × 1050.
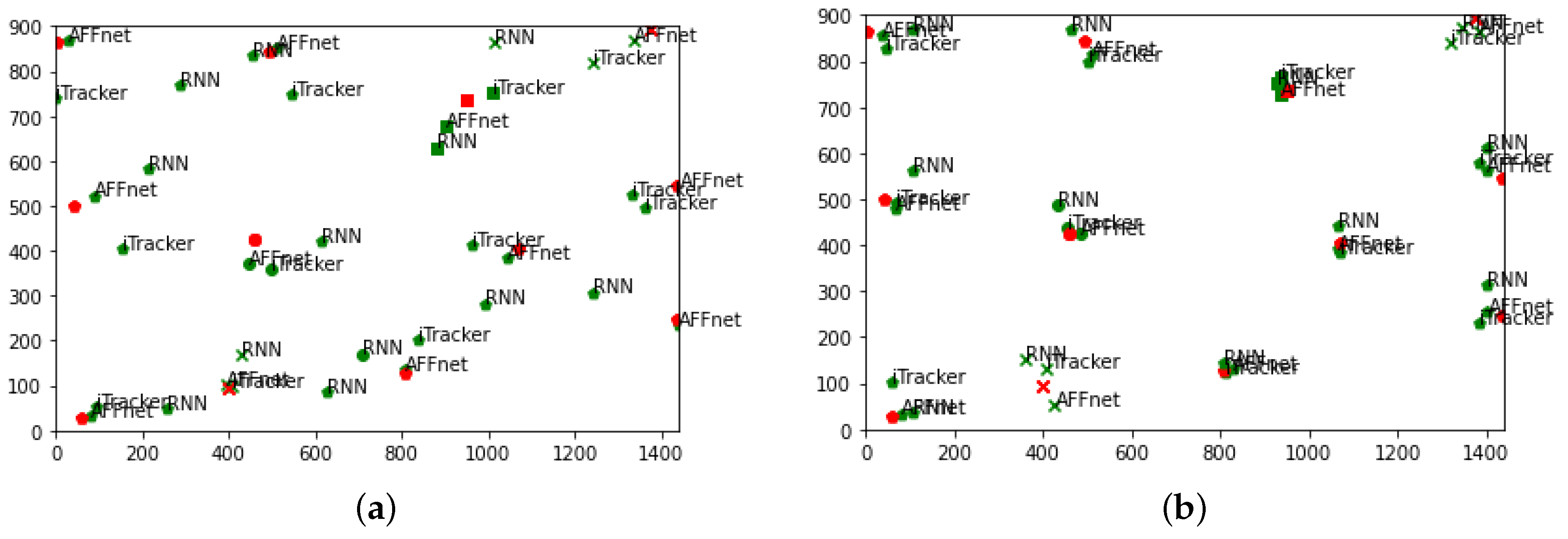
We additionally imported some example images of the predictions in Figure 6. The four correct coordinates are shown in red, and each prediction is shown in green, with the name of the model used next to it. Looking first at Figure 6a, we can see that AFF-Net tends to make some predictions for each coordinate. However, in the case of ResNet18, it tends to deviate a lot from the actual coordinates. In the case of iTracker, the top-right and bottom-left coordinates are predicted in a somewhat valid range, but the top-left and bottom-right coordinates are incorrect, just like ResNet18. On the other hand, we can see from Figure 6b that when the training is performed by applying a penalty for area through the ensemble-loss function, all three models make a good range of predictions.
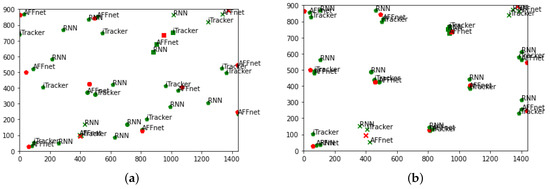
Figure 6.
Prediction points comparison of original models and ensemble-loss algorithm implemented models. (Red points represent the ground truth and green points represent the predicted points).
5. Discussion
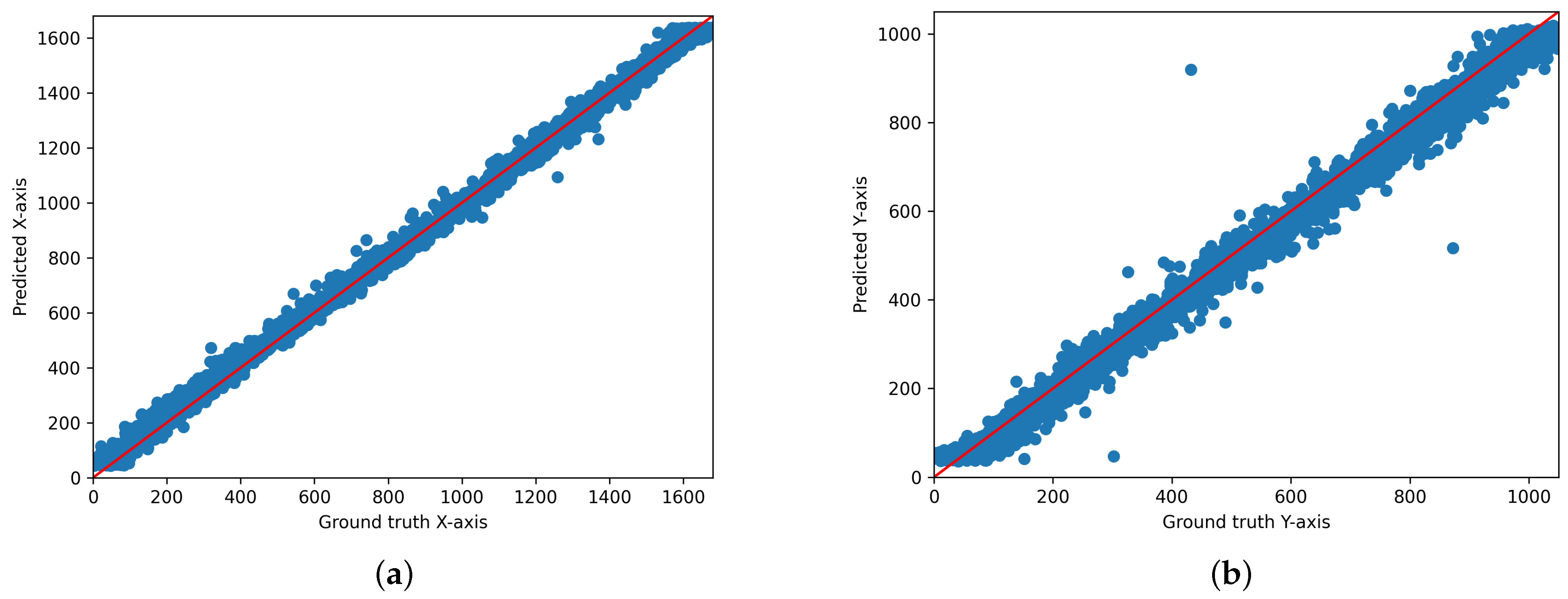
As a result, the best performance was achieved when the ensemble loss function was applied. Comparing the performance of various models before and after applying the ensemble loss function revealed that the proposed ensemble loss function itself significantly contributes to improving the performance of existing models. This can be used as an additional technique to improve performance at a lower computational cost when applied to other models studied in the future. Furthermore, out of the 15 people, the results of person number 6 particularly stood out. Figure 7, Figure 8 and Figure 9 below are the results for person 6, and they are a scatter output of the x-axis and y-axis predictions in distributed form by applying the ensemble loss function to the AFF-Net, ResNet-18, and iTracker models. For this ID, the x coordinate extends up to 1680 and the y coordinate up to 1050, making it the highest resolution among the 15 subjects. This implies that during leave-one-out validation, data exceeding the maximum resolution of 1440 for the x-axis and 900 for the y-axis from the other subjects are not included in the training process. However, as you can see from the test results, if you look at the scatter plot, you can see that the predictions for the x = y axis fit in the area above 1440. Similarly, for the y-axis, we can see that the prediction fits x = y. This is because the loss function does not consider the size of the entire region; instead, it first divides the region into 40 equal parts and then predicts the detailed coordinates of each class. These results suggest that this model has the potential to be used in a wide range of device environments, considering that the dataset used was collected from various device environments.
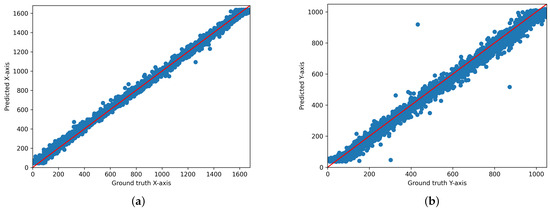
Figure 7.
Scatter plot of the predicted and actual values of the x- and y-axis planes of the two-dimensional gaze coordinates predicted by applying the ensemble loss function to the existing AFF-Net for Person 6 ((a): x-axis, (b): y-axis).
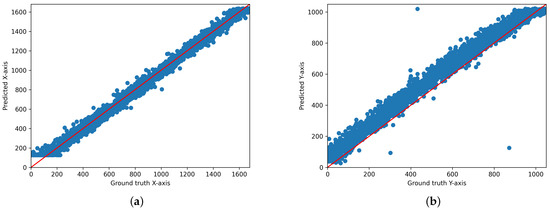
Figure 8.
Scatter plot of the predicted and actual values of the x- and y-axis planes of the two-dimensional gaze coordinates predicted by applying the ensemble loss function to the existing ResNet-18 for Person 6 ((a): x-axis, (b): y-axis).
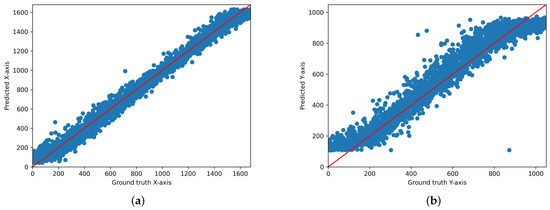
Figure 9.
Scatter plot of the predicted and actual values of the x- and y-axis planes of the two-dimensional gaze coordinates predicted by applying the ensemble loss function to the existing iTracker for Person 6 ((a): x-axis, (b): y-axis).
6. Conclusions
The devices used for gaze tracking are expensive, and most predictive models use infrared cameras, making them unusable on a wide range of devices. Therefore, to overcome this problem, many studies using only RGB cameras are being conducted. In addition, models that can be used straight away without any calibration steps are more usable as they can be used in a wider range of situations. Therefore, our primary goal was to develop a model that accurately predicts the user’s gaze position using only RGB images, without the need for individual calibration. As a result, state-of-the-art performance was achieved by applying a new loss function. In addition, as a result of comparing the performance before and after applying the proposed loss function to various existing models, it was confirmed that the performance of all models improved, showing that the loss function itself can help improve the performance of existing models. This can be used as an additional triggering method to improve performance with lower computational cost when applied to other models to be studied in the future. Lastly, as mentioned in the discussion, the model was able to make predictions and show sufficient performance even in a monitored environment that the model did not experience during the training phase. This means that the model is not dependent on the training data set and is applicable to a wider range of environments. Our future research direction is to expand not only to the computer monitor environment but also to many mobile devices such as mobile phones and tablets. As most mobile devices are equipped with RGB cameras for eye tracking technology, we can expect greater accessibility to eye tracking technology. Therefore, our future work is to present the results of this study on data obtained from a wider range of devices.
Author Contributions
Conceptualization, E.C.L., S.K. and S.L.; methodology, S.K. and S.L.; software, S.K. and S.L.; validation, S.K. and S.L.; formal analysis, S.K. and S.L.; investigation, S.K. and S.L.; resources, S.K. and S.L.; data curation, S.K. and S.L.; writing—original draft preparation, S.K. and S.L.; writing—review and editing, S.K. and S.L.; visualization, S.K. and S.L.; supervision, E.C.L.; project administration, E.C.L.; funding acquisition, E.C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by a 2024 Research Grant from Sangmyung University (2024-A000-0090).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Since the data used in this study are a public open dataset, they can be used by contacting the data holder (https://perceptualui.org/research/datasets/MPIIFaceGaze/, accessed on 18 May 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Majaranta, P.; Räihä, K.J. Twenty Years of Eye Typing: Systems and Design Issues. In Proceedings of the ETRA ’02: 2002 Symposium on Eye Tracking Research & Applications, New Orleans, LA, USA, 25–27 March 2002; pp. 15–22. [Google Scholar] [CrossRef]
- Ou, W.L.; Cheng, Y.H.; Chang, C.C.; Chen, H.L.; Fan, C.P. Calibration-free and deep-learning-based customer gaze direction detection technology based on the YOLOv3-tiny model for smart advertising displays. J. Chin. Inst. Eng. 2023, 46, 856–869. [Google Scholar] [CrossRef]
- He, H.; She, Y.; Xiahou, J.; Yao, J.; Li, J.; Hong, Q.; Ji, Y. Real-Time Eye-Gaze Based Interaction for Human Intention Prediction and Emotion Analysis. In Proceedings of the CGI 2018: Computer Graphics International, Bintan Island, Indonesia, 11–14 June 2018; pp. 185–194. [Google Scholar] [CrossRef]
- Damm, O.; Malchus, K.; Jaecks, P.; Krach, S.; Paulus, F.; Naber, M.; Jansen, A.; Kamp-Becker, I.; Einhäuser, W.; Stenneken, P.; et al. Different gaze behavior in human-robot interaction in Asperger’s syndrome: An eye-tracking study. In Proceedings of the 2013 IEEE RO-MAN, Gyeongju, Republic of Korea, 26–29 August 2013; pp. 368–369. [Google Scholar] [CrossRef]
- Chennamma, H.; Yuan, X. A Survey on Eye-Gaze Tracking Techniques. Indian J. Comput. Sci. Eng. 2013, 4, 388–393. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically Unconstrained Gaze Estimation in the Wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Park, S.; Mello, S.D.; Molchanov, P.; Iqbal, U.; Hilliges, O.; Kautz, J. Few-Shot Adaptive Gaze Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9367–9376. [Google Scholar] [CrossRef]
- He, J.; Pham, K.; Valliappan, N.; Xu, P.; Roberts, C.; Lagun, D.; Navalpakkam, V. On-Device Few-Shot Personalization for Real-Time Gaze Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1149–1158. [Google Scholar] [CrossRef]
- Yang, H.; Yang, Z.; Liu, J.; Chi, J. A new appearance-based gaze estimation via multi-modal fusion. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; pp. 498–502. [Google Scholar] [CrossRef]
- Bandi, C.; Thomas, U. Face-Based Gaze Estimation Using Residual Attention Pooling Network. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Lisabon, Portugal, 19–21 February 2023; pp. 541–549. [Google Scholar] [CrossRef]
- Huang, L.; Li, Y.; Wang, X.; Wang, H.; Bouridane, A.; Chaddad, A. Gaze Estimation Approach Using Deep Differential Residual Network. Sensors 2022, 22, 5462. [Google Scholar] [CrossRef]
- Negrinho, R.; Gordon, G. Deeparchitect: Automatically designing and training deep architectures. arXiv 2017, arXiv:1704.08792. [Google Scholar]
- Dias, P.A.; Malafronte, D.; Medeiros, H.; Odone, F. Gaze Estimation for Assisted Living Environments. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar] [CrossRef]
- Cazzato, D.; Leo, M.; Distante, C.; Voos, H. When I look into your eyes: A survey on computer vision contributions for human gaze estimation and tracking. Sensors 2020, 20, 3739. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Chen, Z.; Shi, B.E. Appearance-Based Gaze Estimation Using Dilated-Convolutions. In Proceedings of the Computer Vision—ACCV 2018; Jawahar, C., Li, H., Mori, G., Schindler, K., Eds.; Springer: Cham, Switzerland, 2019; pp. 309–324. [Google Scholar]
- Palmero, C.; Selva, J.; Bagheri, M.A.; Escalera, S. Recurrent CNN for 3D Gaze Estimation using Appearance and Shape Cues. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- L R D, M.; Biswas, P. Appearance-based Gaze Estimation using Attention and Difference Mechanism. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 3137–3146. [Google Scholar] [CrossRef]
- Wong, E.T.; Yean, S.; Hu, Q.; Lee, B.S.; Liu, J.; Rajan, D. Gaze Estimation Using Residual Neural Network. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kyoto, Japan, 11–15 March 2019; pp. 411–414. [Google Scholar]
- Funes Mora, K.A.; Monay, F.; Odobez, J.M. Eyediap: A database for the development and evaluation of gaze estimation algorithms from rgb and rgb-d cameras. In Proceedings of the Symposium on Eye Tracking Research and Applications, Safety Harbor, FL, USA, 26–28 March 2014; pp. 255–258. [Google Scholar]
- Shen, R.; Zhang, X.; Xiang, Y. AFFNet: Attention Mechanism Network Based on Fusion Feature for Image Cloud Removal. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2254014. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).