
YOLO-Chili: An Efficient Lightweight Network Model for Localization of Pepper Picking in Complex Environments

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
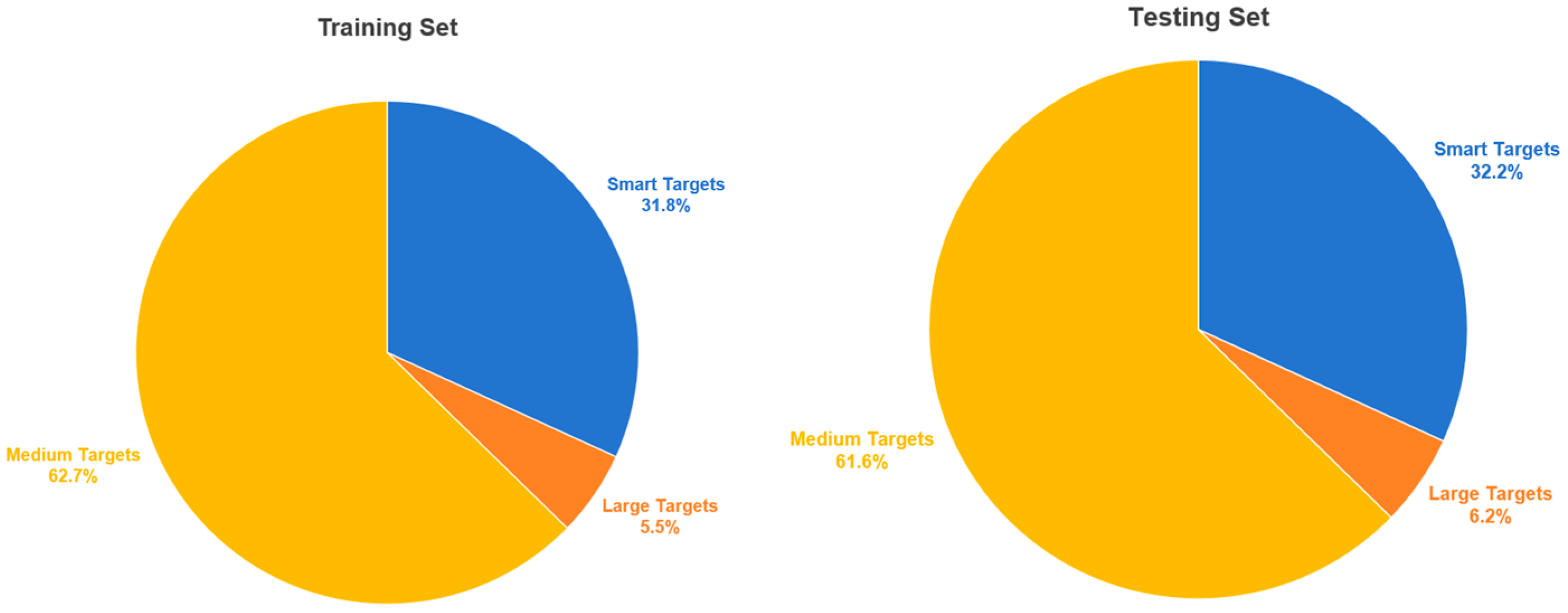
2.1. Data Acquisition
2.2. Data Enhancements
2.3. Experimental Environment
2.4. HFFN (Hierarchical Feature Fusion Network) Module
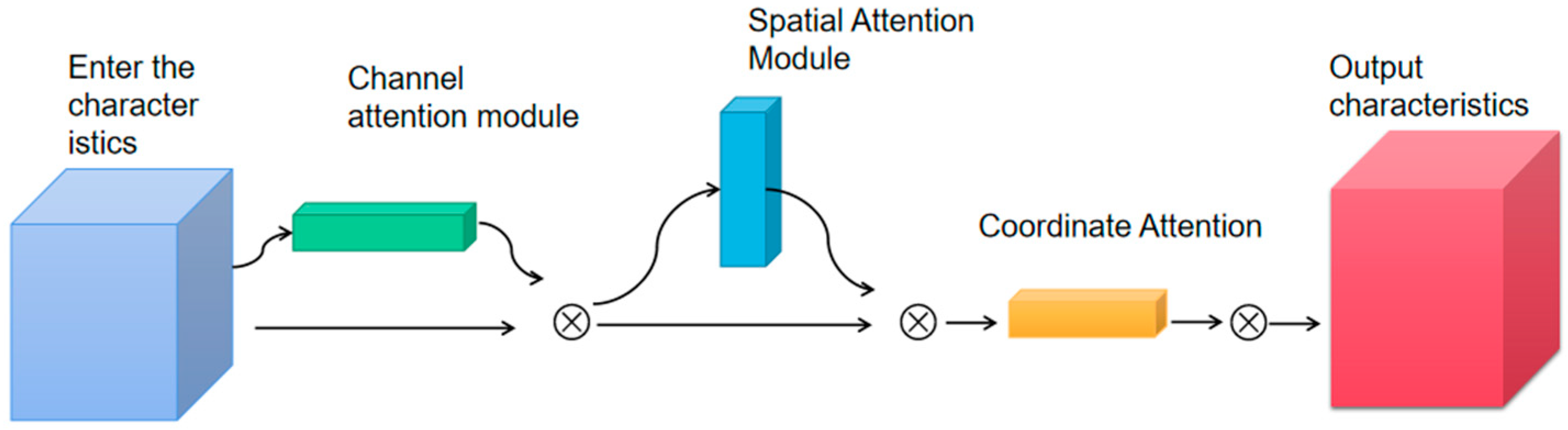
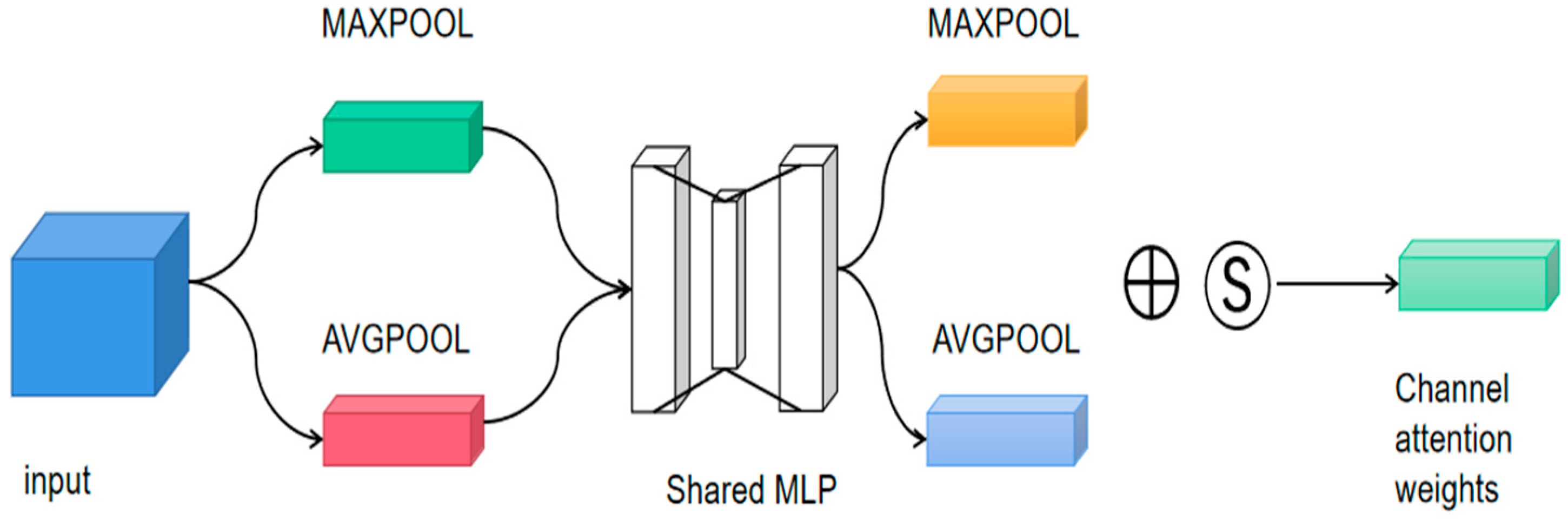
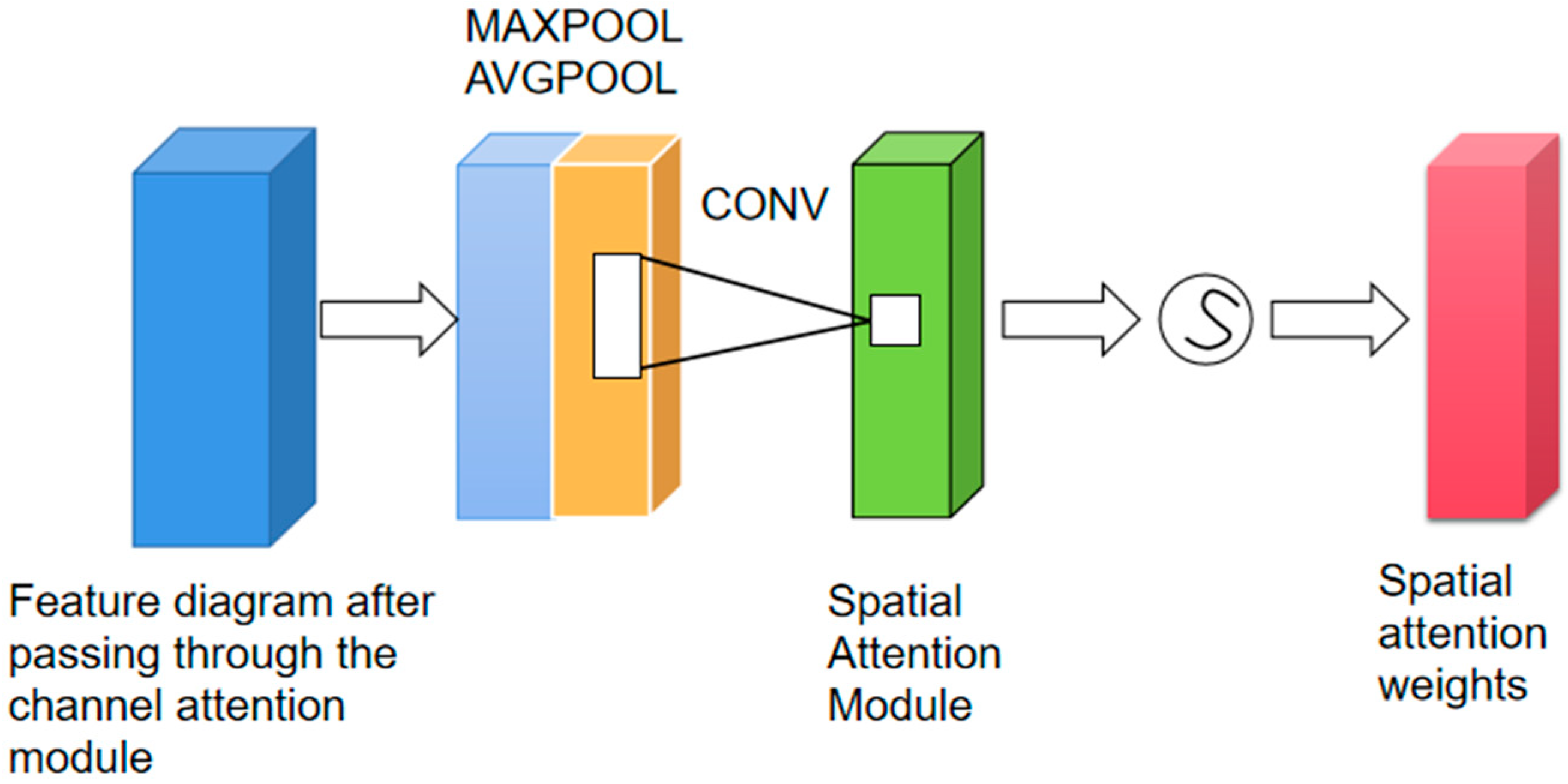
2.5. Three-Channel Attention Mechanism
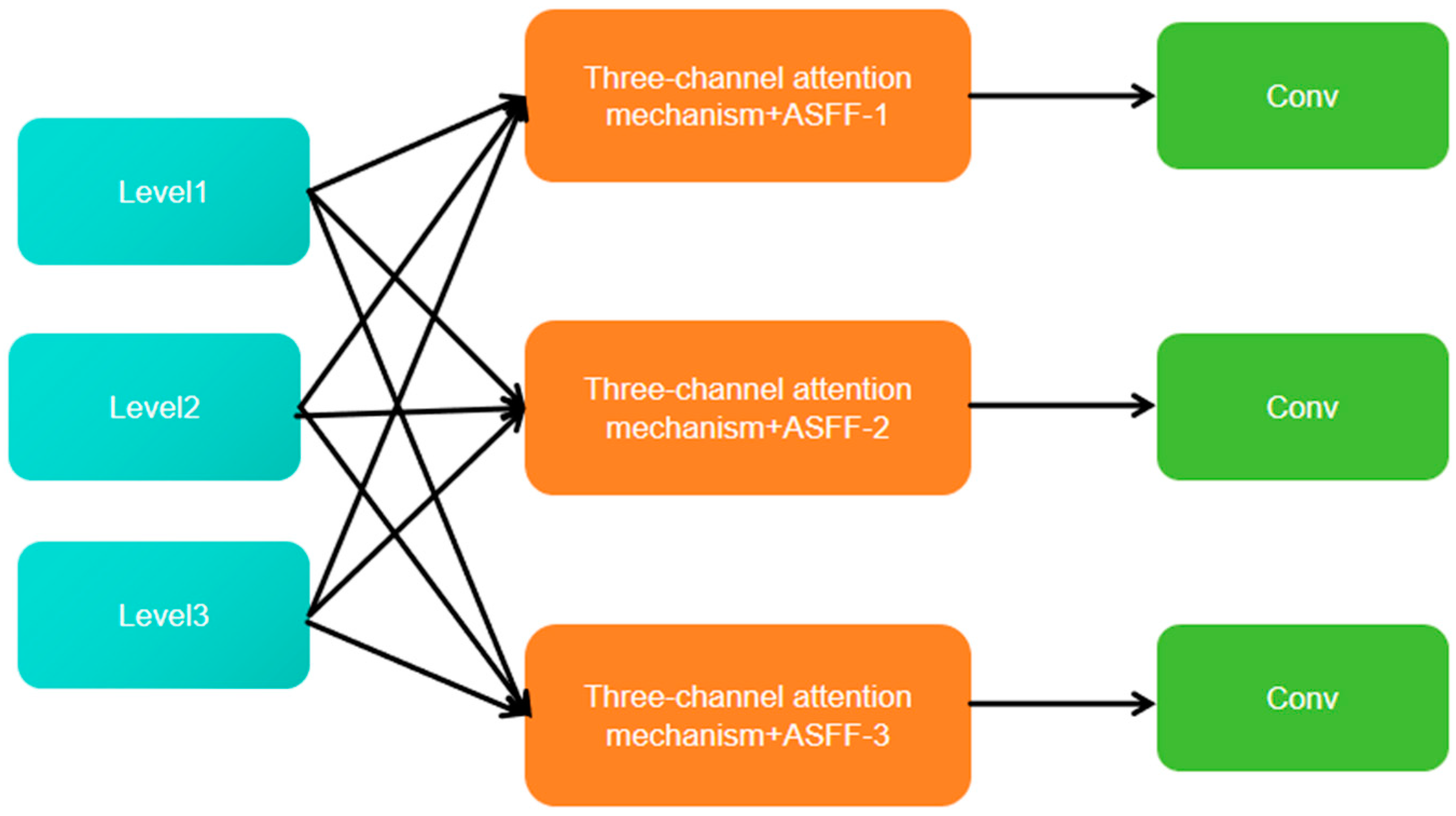
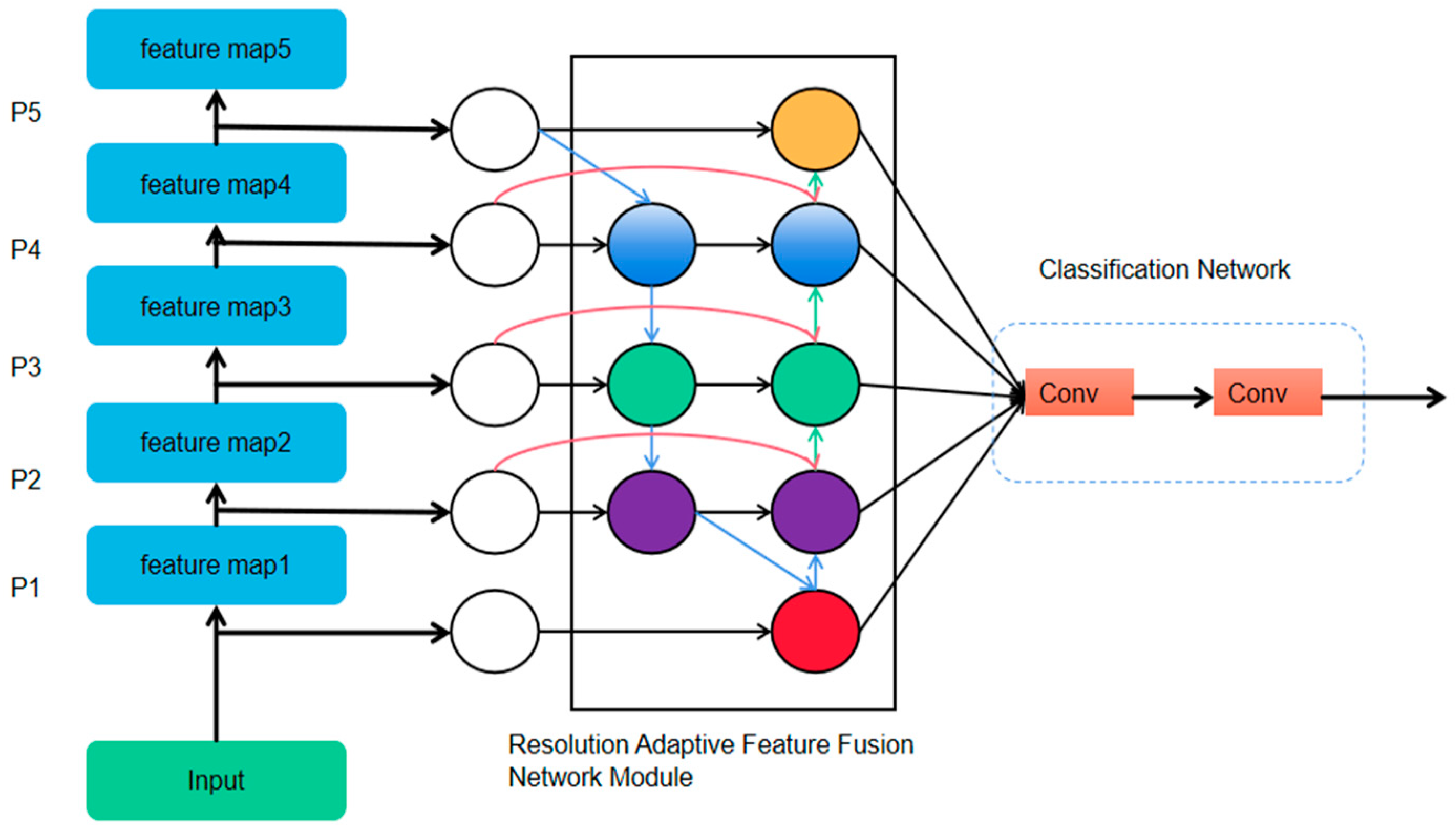
2.6. Resolution Adaptive Feature Fusion Network Module
2.7. YOLO-Chili Network
3. Results and Discussion
3.1. Parameter Setting
3.2. Evaluation Indicators
3.3. YOLO-Chili Ablation Test Performance Comparison
3.4. Comparison of the Performance of Different Object Detection Models
3.5. Reducing Model Size Using Quantitative Pruning
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fu, L.; Duan, J.; Zou, X.; Lin, J.; Zhao, L.; Li, J.; Yang, Z. Fast and accurate detection of banana fruits in complex background orchards. IEEE Access 2020, 8, 196835–196846. [Google Scholar] [CrossRef]
- Mathew, M.P.; Mahesh, T.Y. Leaf-based disease detection in bell pepper plant using YOLOv5. Signal Image Video Process. 2022, 16, 841–847. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Liu, T.H.; Nie, X.N.; Wu, J.M.; Zhang, D.; Liu, W.; Cheng, Y.F.; Qi, L. Pineapple (Ananas comosus) fruit detection and localization in natural environment based on binocular stereo vision and improved YOLOv3 model. Precis. Agric. 2023, 24, 139–160. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Jiang, M.; Song, L.; Wang, Y.; Li, Z.; Song, H. Fusion of the YOLOv4 network model and visual attention mechanism to detect low-quality young apples in a complex environment. Precis. Agric. 2022, 23, 559–577. [Google Scholar] [CrossRef]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A lightweight YOLOv8 tomato detection algorithm combining feature enhancement and attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Li, E.; Yang, G.; Liang, Z.; Tan, M. MD-YOLO: Multi-scale Dense YOLO for small target pest detection. Comput. Electron. Agric. 2023, 213, 108233. [Google Scholar] [CrossRef]
- Lin, Y.; Huang, Z.; Liang, Y.; Liu, Y.; Jiang, W. AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion. Agriculture 2024, 14, 114. [Google Scholar] [CrossRef]
- Yang, S.; Xing, Z.; Wang, H.; Dong, X.; Gao, X.; Liu, Z.; Zhang, X.; Li, S.; Zhao, Y. Maize-YOLO: A new high-precision and real-time method for maize pest detection. Insects 2023, 14, 278. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, Y.; Xu, X.; Sun, C. Precision detection of crop diseases based on improved YOLOv5 model. Front. Plant Sci. 2023, 13, 1066835. [Google Scholar] [CrossRef] [PubMed]
- Karthikeyan, M.; Subashini, T.S.; Srinivasan, R.; Santhanakrishnan, C.; Ahilan, A. YOLOAPPLE: Augment YOLOv3 deep learning algorithm for apple fruit quality detection. Signal Image Video Process. 2024, 18, 119–128. [Google Scholar] [CrossRef]
- Tang, R.; Lei, Y.; Luo, B.; Zhang, J.; Mu, J. YOLOv7-Plum: Advancing plum fruit detection in natural environments with deep learning. Plants 2023, 12, 2883. [Google Scholar] [CrossRef] [PubMed]
- Parico, A.I.B.; Ahamed, T. Real time pear fruit detection and counting using YOLOv4 models and deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef]
- Lawal, O.M.; Huamin, Z.; Fan, Z. Ablation studies on YOLOFruit detection algorithm for fruit harvesting robot using deep learning. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2021; Volume 922, p. 012001. [Google Scholar]
- Li, T.; Sun, M.; Ding, X.; Li, Y.; Zhang, G.; Shi, G.; Li, W. Tomato recognition method at the ripening stage based on YOLO v4 and HSV. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 183–190. [Google Scholar]
- Guo, J.; Xiao, X.; Miao, J.; Tian, B.; Zhao, J.; Lan, Y. Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model. Agriculture 2023, 13, 821. [Google Scholar] [CrossRef]
- Yang, J.; Qian, Z.; Zhang, Y.; Qin, Y.; Miao, H. Real-time recognition of tomatoes in complex environments based on improved YOLOv4-tiny. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 215–221. [Google Scholar]
- Wang, L.; Qin, M.; Lei, J.; Wang, X.; Tan, K. Blueberry maturity recognition method based on improved YOLOv4-Tiny. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 170–178. [Google Scholar]
- Sun, F.; Wang, Y.; Lan, P.; Zhang, X.; Chen, X.; Wang, Z. Identification of Apple Fruit Diseases Using Improved YOLOv5s and Transfer Learning. Trans. Chin. Soc. Agric. Eng. 2022, 38, 171–179. [Google Scholar]
- Ren, R.; Zhang, S.; Sun, H.; Liu, J.; Cheng, J.; Li, Y.; Wang, Q. Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network. Sensors 2021, 21, 5305. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Hu, W.; Zou, A.; Liu, H.; Zhang, Q.; Wu, X.; Zheng, H. Lightweight Detection Algorithm of Kiwifruit Based on Improved YOLOX-s. Agriculture 2022, 12, 993. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel Pruned YOLO V5s-Based Deep Learning Approach for Rapid and Accurate Apple Fruitlet Detection Before Fruit Thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, J.; Chen, Y.; Li, H.; Zhang, S.; Luo, Q.; Liu, X. Rapid Detection of Yunnan Xiaomila Based on Lightweight YOLOv7 Algorithm. Front. Plant Sci. 2023, 14, 1200144. [Google Scholar] [CrossRef]
- Fu, L.; Yang, Z.; Wu, F.; Liu, S.; Zhao, C.; Zhao, Z.; Xiong, J.; Guo, Y. YOLO-Banana: A Lightweight Neural Network for Rapid Detection of Banana Bunches and Stalks in the Natural Environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Fang, W.; Guan, F.; Yu, H.; Wang, Y.; Li, J.; Zhang, X. Identification of Wormholes in Soybean Leaves Based on Multi-Feature Structure and Attention Mechanism. J. Plant Dis. Prot. 2023, 130, 401–412. [Google Scholar] [CrossRef]
- Abade, A.; Ferreira, P.A.; de Barros Vidal, F. Plant diseases recognition on images using convolutional neural networks: A systematic review. Comput. Electron. Agric. 2021, 185, 106125. [Google Scholar] [CrossRef]
- Zeng, W.; Li, M. Crop Leaf Disease Recognition Based on Self-Attention Convolutional Neural Network. Comput. Electron. Agric. 2020, 172, 105341. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shah, R.; He, K.; Zhao, Y.; Da Xu, X.; Liu, T.; Wang, G. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Yu, L.; Xiong, J.; Fang, X.; Yang, Z.; Chen, Y.; Lin, X.; Chen, S. A litchi fruit recognition method in a natural environment using RGB-D images. Biosyst. Eng. 2021, 204, 50–63. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configure | Para |
|---|---|
| CPU | core i5-11400H |
| GPU | Nvidia GeForce RTX 3050TI |
| Accelerated environment | CUDA10.1 CUDNN7.5.0 |
| development environment (computer) | Pycharm2020.1.3 |
| operating system | Windows 10 64-bit system |
| software environment | Anaconda 4.8.4 |
| storage environment | Memory 16.0 GB Mechanical Hard Disk 2 T |
| YOLO-Chili | HFFN | Three-Channel Attention Mechanism | Resolution Adaptive Feature Fusion Network Module | AP (Average Precision) (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| ✓ | 83.24 | 91.33 | 81.77 | |||
| ✓ | ✓ | 91.39 | 92.74 | 91.65 | ||
| ✓ | ✓ | 82.32 | 87.93 | 81.62 | ||
| ✓ | ✓ | 85.54 | 93.54 | 82.15 | ||
| ✓ | ✓ | ✓ | 92.24 | 93.42 | 91.19 | |
| ✓ | ✓ | ✓ | 91.27 | 93.20 | 91.62 | |
| ✓ | ✓ | ✓ | ✓ | 94.11 | 94.42 | 92.25 |
| Models | Parameters/M | FLOPs/G | Model Size/MB | AP (%) | Precision (%) | Recall (%) | Test Time/ms |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 7.24 | 16.6 | 14.1 | 85.53 | 91.33 | 81.77 | 47.7 |
| YOLOv7 | 37.49 | 123.5 | 74.5 | 92.39 | 94.24 | 91.65 | 97.2 |
| YOLOv7-tiny | 6.51 | 14.2 | 12.1 | 89.32 | 93.93 | 87.62 | 46.8 |
| SSD | 26.29 | 62.8 | 93.3 | 91.24 | 93.42 | 73.19 | 65.5 |
| Faster-RCNN | 137.10 | 370.2 | 111.5 | 83.63 | 67.84 | 81.62 | 126.3 |
| YOLO-chili | 11.4 | 21.2 | 18.7 | 94.11 | 94.42 | 92.25 | 55.4 |
| Models | M-Params | AP | Recall | Precision | FPS |
|---|---|---|---|---|---|
| YOLO-chili | 18.7 | 94.11 | 92.25 | 94.42 | 94 |
| pruned_quantized_model | 9.64 | 93.66 | 97 | 97 | 87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, R.; Peng, J.; Peng, H.; Hu, W.; Wang, Y.; Jiang, P. YOLO-Chili: An Efficient Lightweight Network Model for Localization of Pepper Picking in Complex Environments. Appl. Sci. 2024, 14, 5524. https://doi.org/10.3390/app14135524
Chen H, Zhang R, Peng J, Peng H, Hu W, Wang Y, Jiang P. YOLO-Chili: An Efficient Lightweight Network Model for Localization of Pepper Picking in Complex Environments. Applied Sciences. 2024; 14(13):5524. https://doi.org/10.3390/app14135524
Chicago/Turabian StyleChen, Hailin, Ruofan Zhang, Jialiang Peng, Hao Peng, Wenwu Hu, Yi Wang, and Ping Jiang. 2024. "YOLO-Chili: An Efficient Lightweight Network Model for Localization of Pepper Picking in Complex Environments" Applied Sciences 14, no. 13: 5524. https://doi.org/10.3390/app14135524