
Named Entity Recognition for Chinese Texts on Marine Coral Reef Ecosystems Based on the BERT-BiGRU-Att-CRF Model

Abstract
:1. Introduction
2. A BERT-BiGRU-Att-CRF Chinese Coral Reef Ecosystem Named Entity Recognition Model Combined with Attention Mechanism
2.1. Overall Framework of Model
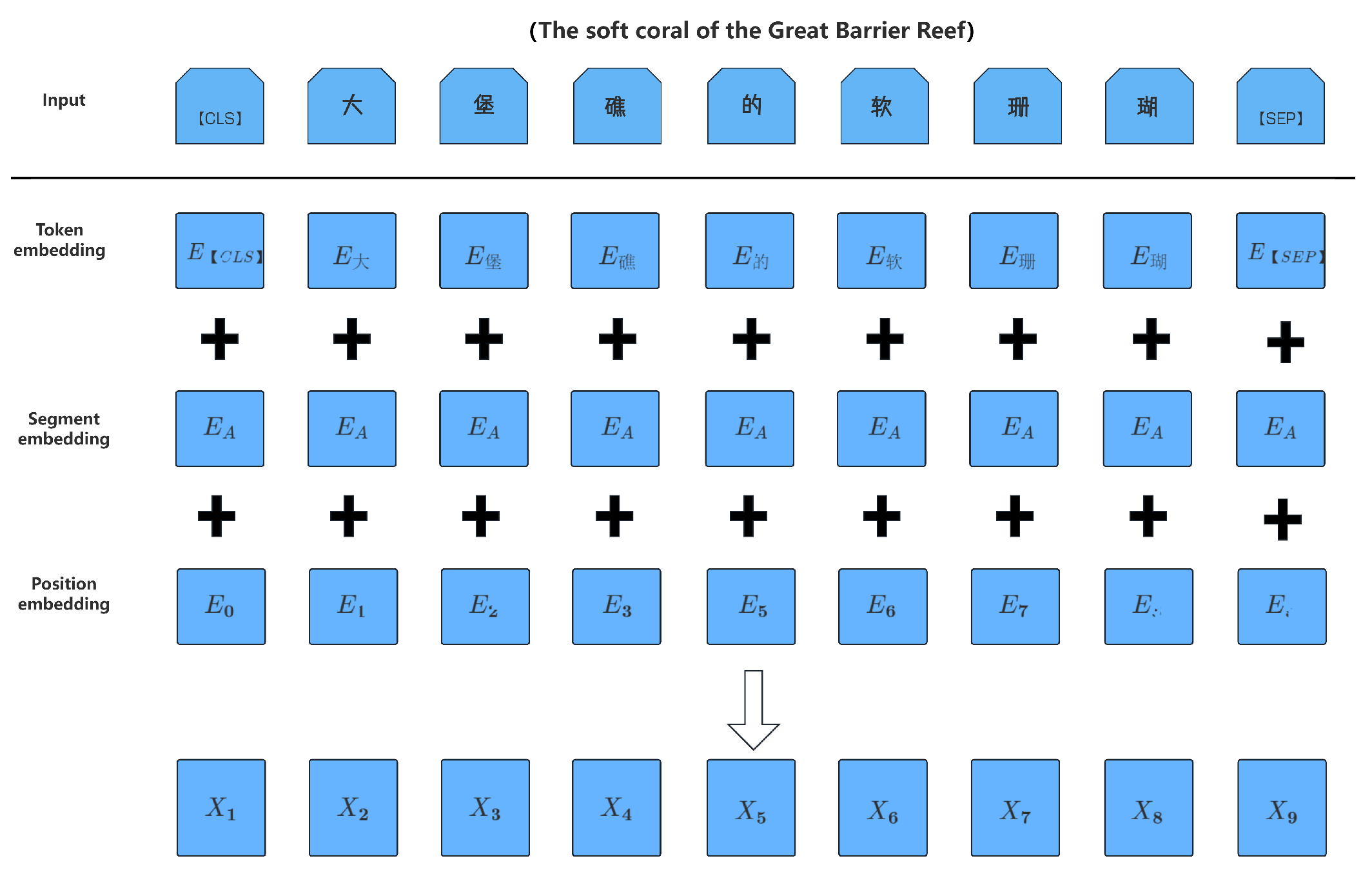
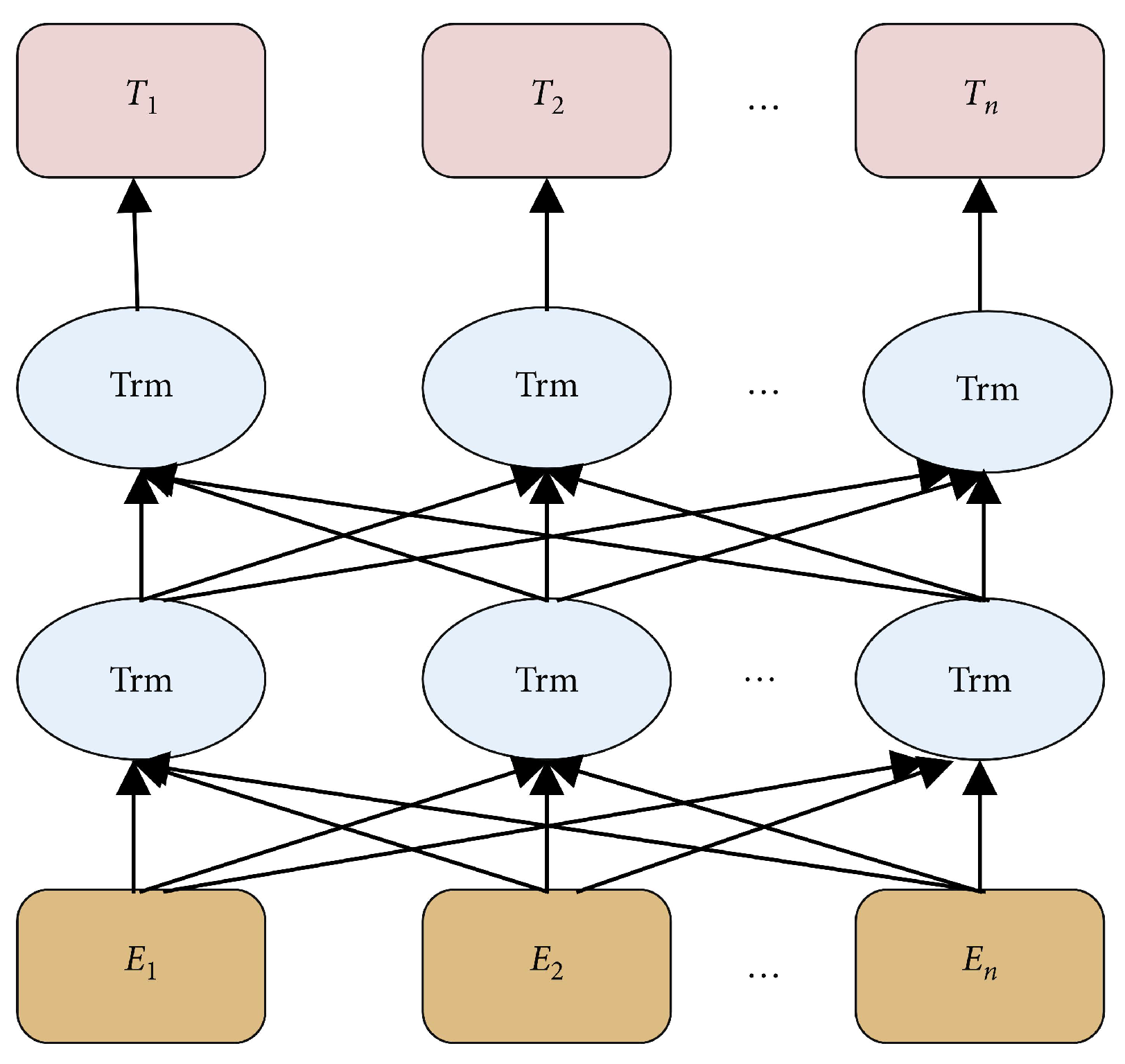
2.2. Embedding Layer: BERT Model
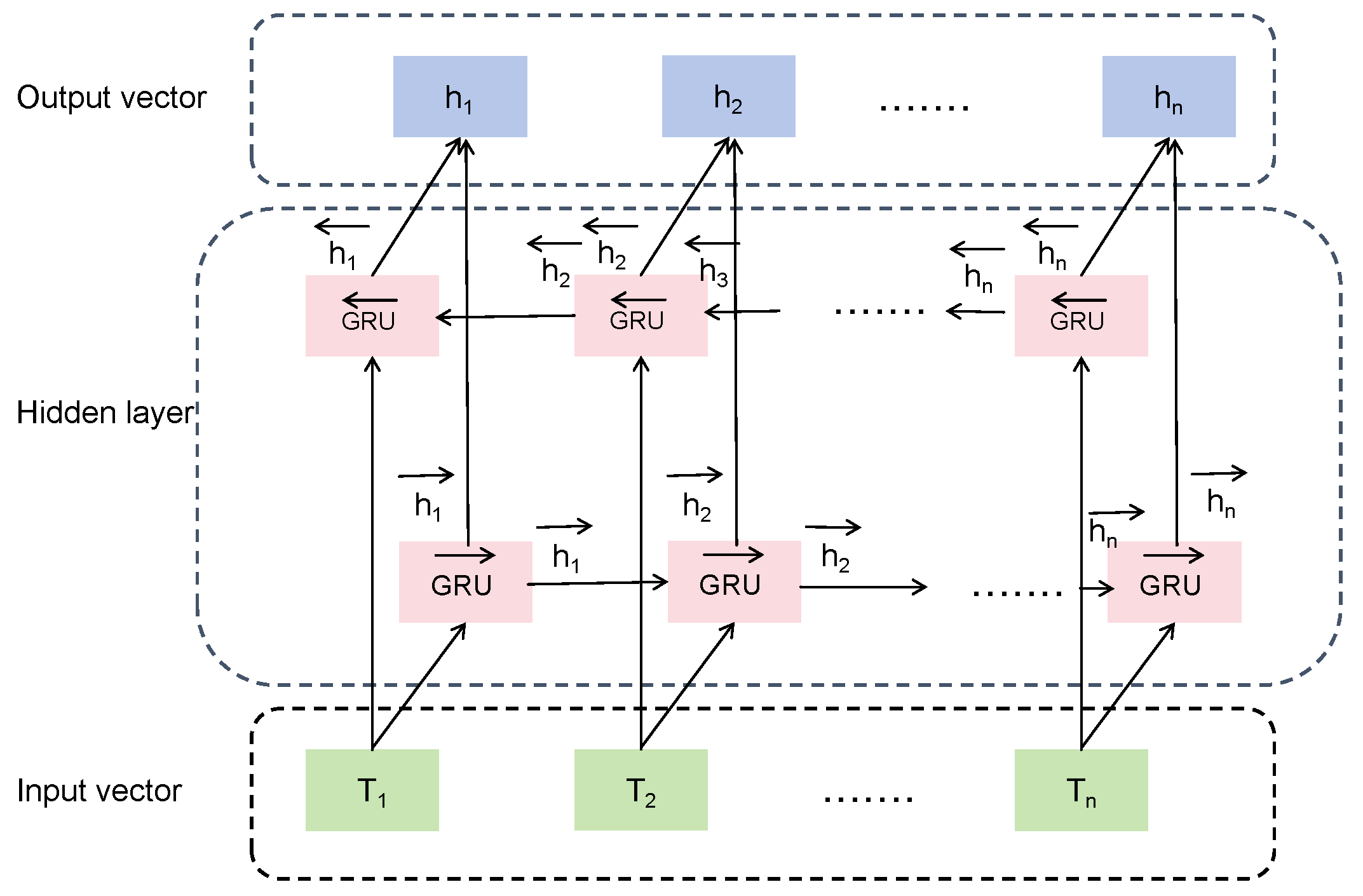
2.3. Encoder Layer: BiGRU Layer
2.4. Attention Layer
2.5. Decoding CRF Layer
3. Experiment and Results Analysis
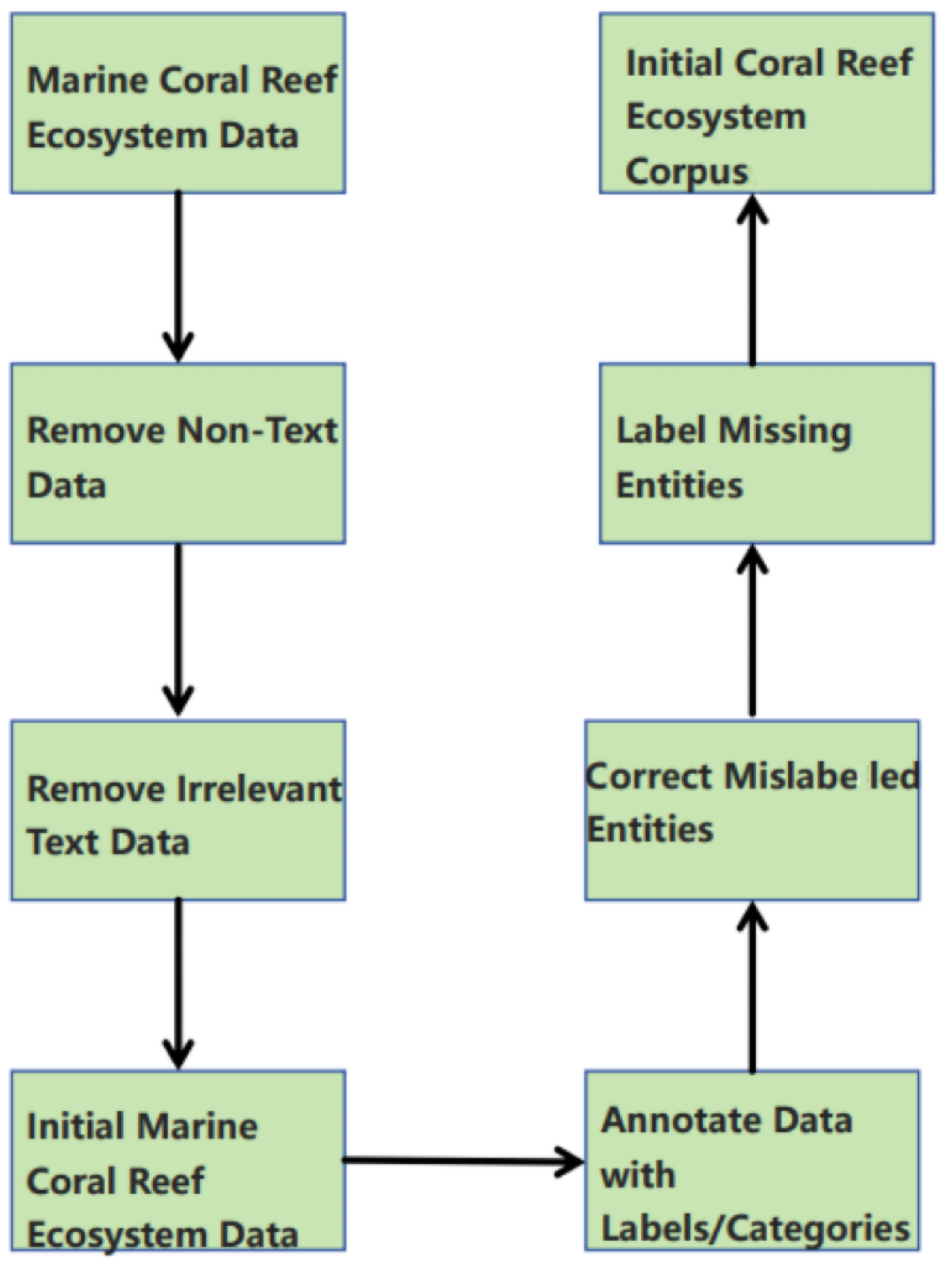
3.1. Data Processing and Annotation
3.1.1. Data Preprocessing
3.1.2. Data Annotation Guidelines
3.2. Network Model Evaluation Metrics
3.3. Experimental Results and Analysis
4. Discussion
4.1. Model Performance and Structural Advantages
4.2. Limitations and Future Work
4.3. Practical Application Prospects
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hughes, T.P.; Barnes, M.L.; Bellwood, D.R.; Cinner, J.E.; Cumming, G.S.; Jackson, J.B.; Kleypas, J.; Van De Leemput, I.A.; Lough, J.M.; Morrison, T.H.; et al. Coral reefs in the Anthropocene. Nature 2017, 546, 82–90. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Lou, Y.; Song, W.; Huang, D.; Wang, X. Stability analysis of reef fish communities based on symbiotic graph model. Aquac. Fish. 2023; in press. [Google Scholar] [CrossRef]
- Liu, P.; Guo, Y.; Wang, F.; Li, G. Chinese named entity recognition: The state of the art. Neurocomputing 2022, 473, 37–53. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, W.; Zhao, Y.; Luu, A.T.; Bing, L. Is translation all you need? A study on solving multilingual tasks with large language models. arXiv 2024, arXiv:2403.10258. [Google Scholar]
- Morwal, S.; Jahan, N.; Chopra, D. Named entity recognition using hidden Markov model (HMM). Int. J. Nat. Lang. Comput. 2012, 1, 15–23. [Google Scholar] [CrossRef]
- Song, S.; Zhang, N.; Huang, H. Named entity recognition based on conditional random fields. Clust. Comput. 2019, 22, 5195–5206. [Google Scholar] [CrossRef]
- Ekbal, A.; Bandyopadhyay, S. Named entity recognition using support vector machine: A language independent approach. Int. J. Electr. Comput. Eng. 2010, 4, 589–604. [Google Scholar]
- Cao, X.; Yang, Y. Research on Chinese Named Entity Recognition in the Marine Field. In Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 21–23 December 2018; pp. 1–7. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- He, L.; Zhang, Y.; Ba, H. Named entity recognition of exotic marine organisms based on attention mechanism and deep learning network. J. Dalian Ocean. Univ. 2021, 36, 503–509. [Google Scholar]
- He, S.; Sun, D.; Wang, Z. Named entity recognition for Chinese marine text with knowledge-based self-attention. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–15. [Google Scholar]
- Ma, X.; Yu, R.; Gao, C.; Wei, Z.; Xia, Y.; Wang, X.; Liu, H. Research on named entity recognition method of marine natural products based on attention mechanism. Front. Chem. 2023, 11, 958002. [Google Scholar] [CrossRef] [PubMed]
- Perera, N.; Dehmer, M.; Emmert-Streib, F. Named entity recognition and relation detection for biomedical information extraction. Front. Cell Dev. Biol. 2020, 8, 673. [Google Scholar] [CrossRef] [PubMed]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open, 2023; in press. [Google Scholar] [CrossRef]
- Wu, Y.; Huang, J.; Xu, C.; Zheng, H.; Zhang, L.; Wan, J. Research on named entity recognition of electronic medical records based on roberta and radical-level feature. Wirel. Commun. Mob. Comput. 2021, 2021, 1–10. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; NIPS Foundation: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Zulqarnain, M.; Ghazali, R.; Ghouse, M.G.; Mushtaq, M.F. Efficient processing of GRU based on word embedding for text classification. Int. J. Inform. Vis. 2019, 3, 377–383. [Google Scholar] [CrossRef]
- Zhang, X.; Shen, F.; Zhao, J.; Yang, G. Time series forecasting using GRU neural network with multi-lag after decomposition. In Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017, Proceedings, Part V 24; Springer: Berlin/Heidelberg, Germany, 2017; pp. 523–532. [Google Scholar]
- She, D.; Jia, M. A BiGRU method for remaining useful life prediction of machinery. Measurement 2021, 167, 108277. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Yu, S.; Gu, X.; Song, M.; Peng, Y.; Chen, J.; Liu, Q. Bi-GRU relation extraction model based on keywords attention. Data Intell. 2022, 4, 552–572. [Google Scholar] [CrossRef]
- Souza, F.; Nogueira, R.; Lotufo, R. Portuguese named entity recognition using BERT-CRF. arXiv 2019, arXiv:1909.10649. [Google Scholar]
- Liu, W.; Hu, Z.; Zhang, J.; Liu, X.; Lin, F. Optimized Named Entity Recognition of Electric Power Field Based on Word-Struct BiGRU. In Proceedings of the 2021 IEEE Sustainable Power and Energy Conference (iSPEC), Nanjing, China, 23–25 December 2021; pp. 3696–3701. [Google Scholar]
- Cai, G.; Su, X.; Wu, T. Causality Extraction of Fused Character Features with BiGRU-Attention-CRF. Int. Core J. Eng. 2023, 9, 47–59. [Google Scholar] [CrossRef]
- Ke, J.; Wang, W.; Chen, X.; Gou, J.; Gao, Y.; Jin, S. Medical entity recognition and knowledge map relationship analysis of Chinese EMRs based on improved BiLSTM-CRF. Comput. Electr. Eng. 2023, 108, 108709. [Google Scholar] [CrossRef]
- Jia, C.; Shi, Y.; Yang, Q.; Zhang, Y. Entity enhanced BERT pre-training for Chinese NER. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6384–6396. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Tu, Z.; Lu, Z.; Liu, Y.; Liu, X.; Li, H. Modeling coverage for neural machine translation. arXiv 2016, arXiv:1601.04811. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data; Icml: Williamstown, MA, USA, 2001; Volume 1, p. 3. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019, Proceedings 18; Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Ratner, A.J.; De Sa, C.M.; Wu, S.; Selsam, D.; Ré, C. Data programming: Creating large training sets, quickly. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Zhao, D.; Yang, X.; Song, W.; Zhang, W.; Huang, D. Visibility graph analysis of the sea surface temperature irreversibility during El Ni no events. Nonlinear Dyn. 2023, 111, 17393–17409. [Google Scholar] [CrossRef]
- Hedley, J.D.; Roelfsema, C.M.; Chollett, I.; Harborne, A.R.; Heron, S.F.; Weeks, S.; Skirving, W.J.; Strong, A.E.; Eakin, C.M.; Christensen, T.R.; et al. Remote sensing of coral reefs for monitoring and management: A review. Remote Sens. 2016, 8, 118. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag | Full Name | Description |
|---|---|---|
| B | Begin | Position at the beginning of an entity |
| I | Inside | Position inside an entity |
| E | End | Position at the end of an entity |
| S | Single | Single-character entity |
| O | Other | Any part that is not an entity (including punctuation, etc.) |
| Entity Category | Number of Annotated Entities |
|---|---|
| Coral species | 1946 |
| Biological species | 1459 |
| Geographic locations | 973 |
| Environmental factors | 487 |
| Index | Model | Precision (P) | Recall (R) | F1 Score |
|---|---|---|---|---|
| 1 | CRF | 75.23 | 73.65 | 74.44 |
| 2 | BiLSTM+CRF | 81.03 | 82.05 | 81.62 |
| 3 | BiGRU+CRF | 81.56 | 82.33 | 81.94 |
| 4 | BERT+BiLSTM+CRF | 83.95 | 83.81 | 83.88 |
| 5 | BERT+BiGRU+CRF | 84.14 | 84.09 | 84.11 |
| 6 | BERT-BiLSTM-Att-CRF | 85.96 | 85.68 | 86.06 |
| 7 | BERT-BiGRU-Att-CRF | 86.25 | 86.77 | 86.54 |
| Index | Model | Precision (P) | Recall (R) | F1 Score |
|---|---|---|---|---|
| 1 | IDCNN+CRF | 81.14 | 79.90 | 80.57 |
| 2 | BERT+IDCNN+CRF | 85.29 | 85.17 | 85.22 |
| 3 | BERT-BiGRU-Att-CRF | 86.25 | 86.77 | 86.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Chen, X.; Chen, Y. Named Entity Recognition for Chinese Texts on Marine Coral Reef Ecosystems Based on the BERT-BiGRU-Att-CRF Model. Appl. Sci. 2024, 14, 5743. https://doi.org/10.3390/app14135743
Zhao D, Chen X, Chen Y. Named Entity Recognition for Chinese Texts on Marine Coral Reef Ecosystems Based on the BERT-BiGRU-Att-CRF Model. Applied Sciences. 2024; 14(13):5743. https://doi.org/10.3390/app14135743
Chicago/Turabian StyleZhao, Danfeng, Xiaolian Chen, and Yan Chen. 2024. "Named Entity Recognition for Chinese Texts on Marine Coral Reef Ecosystems Based on the BERT-BiGRU-Att-CRF Model" Applied Sciences 14, no. 13: 5743. https://doi.org/10.3390/app14135743