
Cognitive Principles for Remote Condition Monitoring Applied to a Rail Pantograph System


Abstract
:1. Introduction
- A high-level conceptual architecture for a pantograph monitoring system that is linked to cognitively-orientated HMIs
- Demonstration of cognitively-orientated HMIs for the pantograph system
2. Background
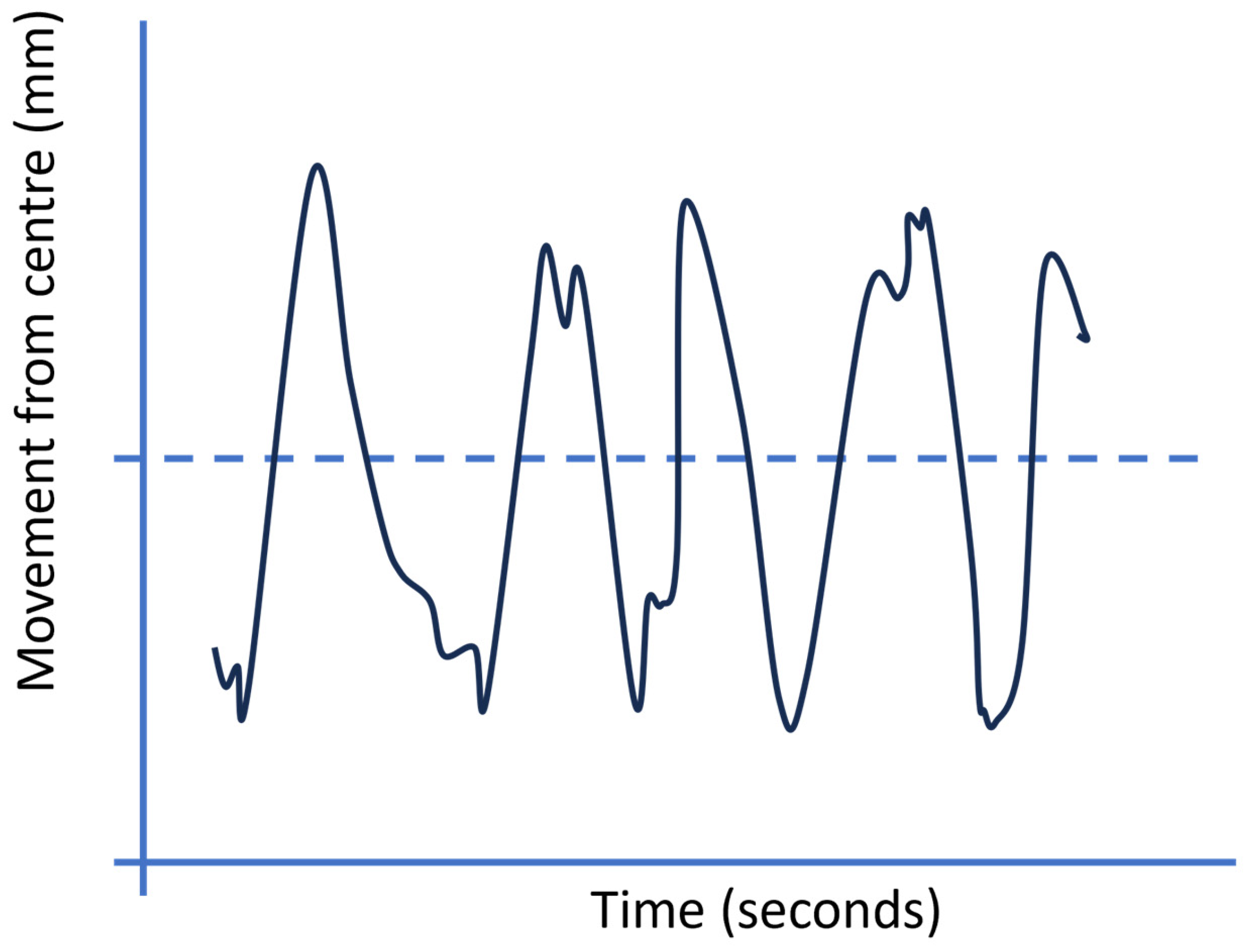
2.1. Pantograph System
- − Pantograph aerodynamics are disturbed or set incorrectly
- − Worn pantograph contact strip
- − Pantograph geometry set incorrectly
- − Incorrect contact wire height
- − Catastrophic failure of pantograph or catenary system (often caused by other failure modes)
- − Failure or displacement of droppers (often causing damage through contact with a pantograph)
- − Uneven contact wire wear at discontinuity
- − Formation of ice coating on contact wire (only an issue in certain seasons and/or climates).
2.2. Cognition for Remote Condition Monitoring
- Is there a fault?
- Is the fault legitimate?
- What was the cause of the fault?
- What should be done about the fault?
3. High-Level Conceptual Architecture
4. Demonstration HMI Design
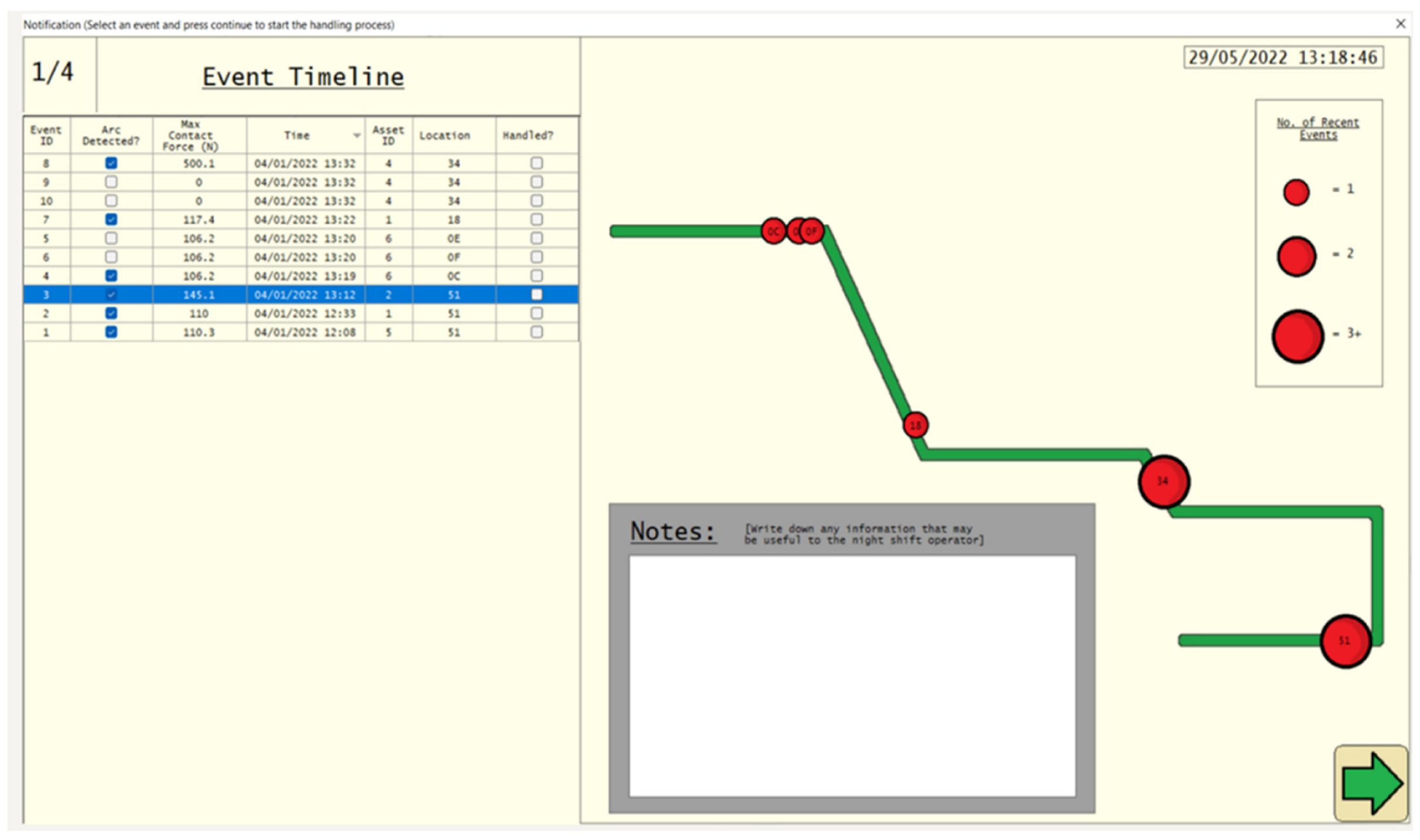
4.1. Stage 1—Notification
4.2. Stage 2—Acceptance
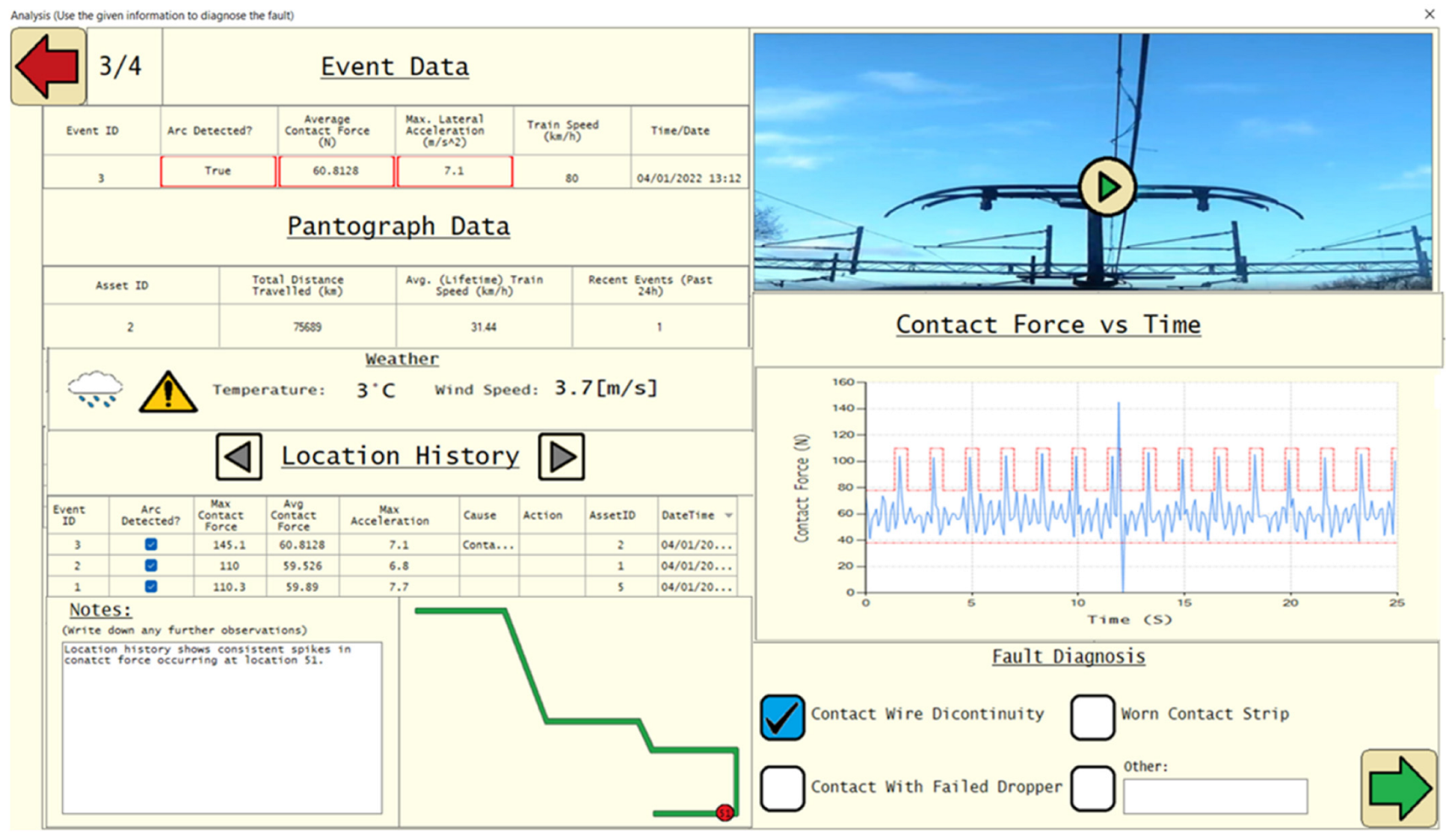
4.3. Stage 3—Analysis
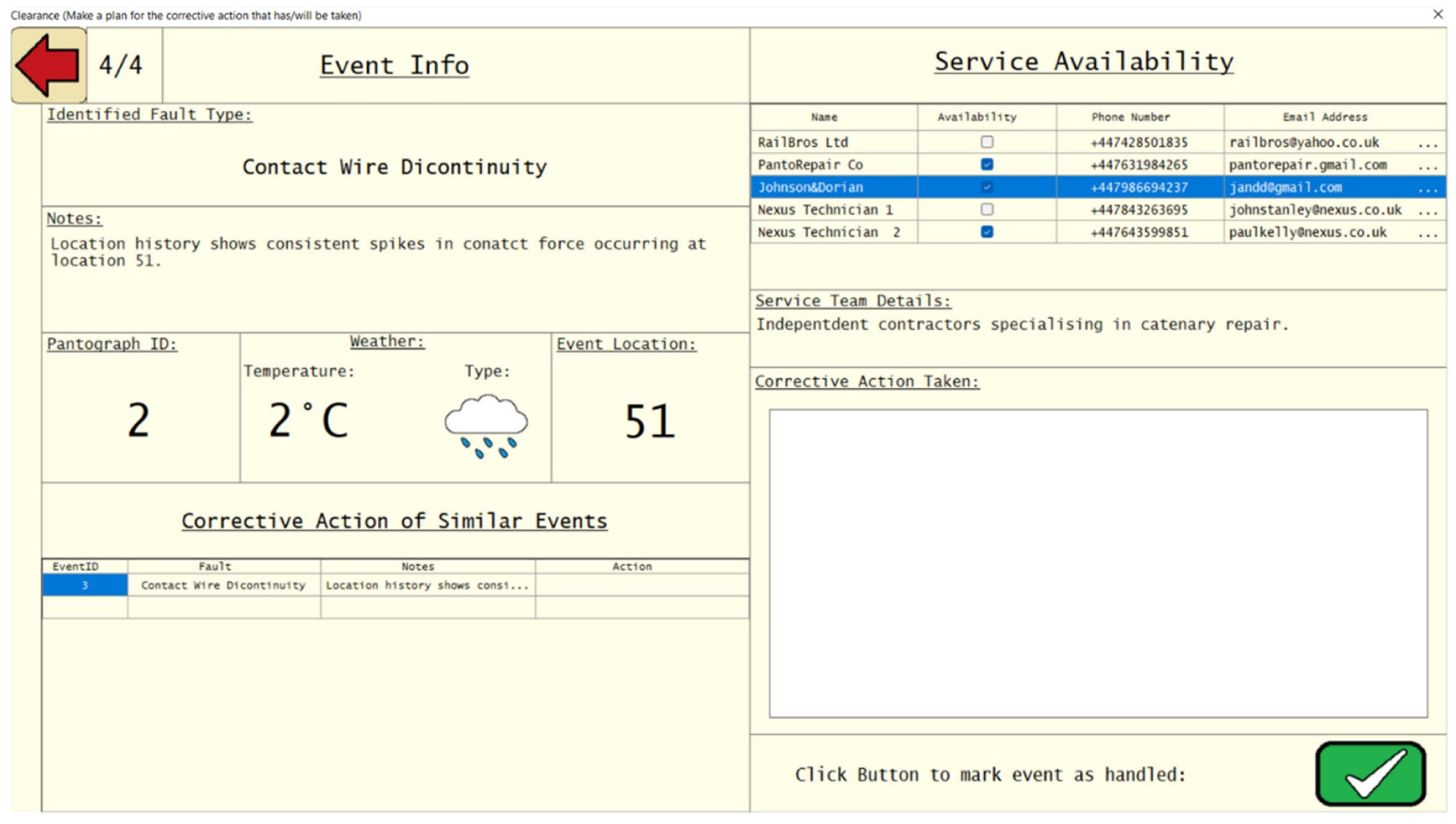
4.4. Stage 4—Clearance
5. Subject Matter Validation
5.1. Methodology
5.1.1. Participants
5.1.2. Materials
5.1.3. Procedure
5.1.4. Analysis
5.2. Results
- Where a significant issue has arisen, and the train needs to be stopped or pantograph needs to be dropped immediately to prevent further damage to the system. In this case, once it is clear that the train needs to be stopped the number of clicks should be minimized;
- Where trends in the data show a developing issue that should be investigated and resolved before it develops into a significant issue.
5.2.1. Notification
5.2.2. Acceptance
5.2.3. Analysis
5.2.4. Clearance
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wilson, J.R.; Farrington-Darby, T.; Cox, G.; Bye, R.; Hockey GR, J. The railway as a socio-technical system: Human factors at the heart of successful rail engineering. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2007, 221, 101–115. [Google Scholar] [CrossRef]
- Waterson, P.; Robertson, M.M.; Cooke, N.J.; Militello, L.; Roth, E.; Stanton, N.A. Defining the methodological challenges and opportunities for an effective science of sociotechnical systems and safety. Ergonomics 2015, 58, 565–599. [Google Scholar] [CrossRef] [PubMed]
- Palin, E.J.; Oslakovic, I.S.; Gavin, K.; Quinn, A. Implications of climate change for railway infrastructure. WIREs Clim. Chang. 2021, 12, e728. [Google Scholar] [CrossRef]
- Naweed, A.; Young, M.S.; Aitken, J. Caught between a rail and a hard place: A two-country meta-analysis of factors that impact Track Worker safety in Lookout-related rail incidents. Theor. Issues Ergon. Sci. 2019, 20, 731–762. [Google Scholar] [CrossRef]
- Rail Accident Investigation Branch (2020) Report 11/2020: Track Workers Struck by a Train at Margam. Available online: https://www.gov.uk/raib-reports/report-11-2020-track-workers-struck-by-a-train-at-margam (accessed on 15 June 2024).
- Márquez FP, G.; Schmid, F.; Collado, J.C. A reliability centered approach to remote condition monitoring. A railway points case study. Reliab. Eng. Syst. Saf. 2003, 80, 33–40. [Google Scholar]
- Hodge, V.J.; O’Keefe, S.; Weeks, M.; Moulds, A. Wireless sensor networks for condition monitoring in the railway industry: A survey. IEEE Trans. Intell. Transp. Syst. 2014, 16, 1088–1106. [Google Scholar] [CrossRef]
- Durazo-Cardenas, I.; Starr, A.; Turner, C.J.; Tiwari, A.; Kirkwood, L.; Bevilacqua, M.; Tsourdos, A.; Shehab, E.; Baguley, P.; Xu, Y.; et al. An autonomous system for maintenance scheduling data-rich complex infrastructure: Fusing the railways’ condition, planning and cost. Transp. Res. Part C Emerg. Technol. 2018, 89, 234–253. [Google Scholar] [CrossRef]
- Dadashi, N.; Golightly, D.; Sharples, S.; Bye, R. Intelligent Infrastructure: User-Centred Remote Condition Monitoring; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Emmanouilidis, C.; Pistofidis, P.; Fournaris, A.; Bevilacqua, M.; Durazo-Cardenas, I.; Botsaris, P.N.; Vassilis, K.; Christos, K.; Starr, A.G. Context-based and human-centred information fusion in diagnostics. IFAC-PapersOnLine 2016, 49, 220–225. [Google Scholar] [CrossRef]
- Dadashi, N.; Golightly, D.; Sharples, S. Modelling decision-making within rail maintenance control rooms. Cogn. Technol. Work. 2021, 23, 255–271. [Google Scholar] [CrossRef]
- Houghton, R.J.; Patel, H. Interface design for prognostic asset maintenance. In Proceedings of the 19th Triennial Congress of the IEA, Melbourne, Australia, 9–14 August 2015; Volume 9, p. 14. [Google Scholar]
- Vollert, S.; Atzmueller, M.; Theissler, A. Interpretable Machine Learning: A brief survey from the predictive maintenance perspective. In Proceedings of the 2021 26th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vasteras, Sweden, 7–10 September 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar]
- Goel, P.; Datta, A.; Mannan, M.S. Industrial alarm systems: Challenges and opportunities. J. Loss Prev. Process Ind. 2017, 50, 23–36. [Google Scholar] [CrossRef]
- Golightly, D.; Kefalidou, G.; Sharples, S. A cross-sector analysis of human and organisational factors in the deployment of data-driven predictive maintenance. Inf. Syst. e-Bus. Manag. 2018, 16, 627–648. [Google Scholar] [CrossRef]
- Cortés-Leal, A.; Cárdenas, C.; Del-Valle-Soto, C. Maintenance 5.0: Towards a worker-in-the-loop framework for resilient smart manufacturing. Appl. Sci. 2022, 12, 11330. [Google Scholar] [CrossRef]
- Stanton, N.A. Alarm initiated activities. In International Encyclopaedia of Ergonomics and Human Factors, 2nd ed.; Karwowski, W., Ed.; Taylor & Francis Group, LLC: Abingdon, UK, 2006; pp. 1008–1011. [Google Scholar]
- Zhang, D.; Gao, S.; Yu, L.; Kang, G.; Zhan, D.; Wei, X. A robust pantograph–catenary interaction condition monitoring method based on deep convolutional network. IEEE Trans. Instrum. Meas. 2019, 69, 1920–1929. [Google Scholar] [CrossRef]
- Xin, T.; Roberts, C.; Weston, P.; Stewart, E. Condition monitoring of railway pantographs to achieve fault detection and fault diagnosis. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2020, 234, 289–300. [Google Scholar] [CrossRef]
- Keen, P.M. Monitoring overhead line equipment. In Proceedings of the IEE Current Collections for High Speed Trains Seminar (Ref. No. 1998/509), London, UK, 2 October 1998; IET: Birmingham, UK, 1998. [Google Scholar]
- Ostlund, S.; Gustafsson, A.; Buhrkall, L.; Skoglund, M. Condition monitoring of pantograph contact strip. In Proceedings of the 2008 4th IET International Conference on Railway Condition Monitoring, Derby, UK, 18–20 June 2008; IET: Birmingham, UK, 2008; pp. 1–6. [Google Scholar]
- Betts, A.; Hall, J.; Keen, P. Condition monitoring of pantographs. In Proceedings of the International Conference on Main Line Railway Electrification, North Yorkshire, UK, 25–28 September 1989; IET: Birmingham, UK, 1989. [Google Scholar]
- Karakose, M.; Yaman, O. Complex fuzzy system based predictive maintenance approach in railways. IEEE Trans. Ind. Inform. 2020, 16, 6023–6032. [Google Scholar] [CrossRef]
- Wei, X.; Jiang, S.; Li, Y.; Li, C.; Jia, L.; Li, Y. Defect detection of pantograph slide based on deep learning and image processing technology. IEEE Trans. Intell. Transp. Syst. 2019, 21, 947–958. [Google Scholar] [CrossRef]
- Na, K.M.; Lee, K.; Shin, S.K.; Kim, H. Detecting deformation on pantograph contact strip of railway vehicle on image processing and deep learning. Appl. Sci. 2020, 10, 8509. [Google Scholar] [CrossRef]
- Aydin, I. A new approach based on firefly algorithm for vision-based railway overhead inspection system. Measurement 2015, 74, 43–55. [Google Scholar] [CrossRef]
- Illingworth, J.; Kittler, J. A survey of the Hough transform. Comput. Vis. Graph. Image Process. 1988, 44, 87–116. [Google Scholar] [CrossRef]
- Aydin, I.; Karaköse, M.; Akin, E. A new contactless fault diagnosis approach for pantograph-catenary system. In Proceedings of the 15th International Conference MECHATRONIKA, Prague, Czech Republic, 5–7 December 2012; IEEE: New York, NY, USA, 2012; pp. 1–6. [Google Scholar]
- Ikeda, M.; Nagasaka, S.; Takayuki, A.U. A precise contact force measuring method for overhead catenary system. In Proceedings of the World Congress on Railway Research, Köln, Germany, 25–29 September 2001; pp. 1–12. [Google Scholar]
- Report 09/2015: Parting of Live Overhead Wire at Walkergate. GOV.UK. 2015. Available online: https://www.gov.uk/government/news/report-092015-parting-of-live-overhead-wire-at-walkergate (accessed on 22 April 2022).
- Dadashi, N.; Wilson, J.R.; Golightly, D.; Sharples, S. A framework to support human factors of automation in railway intelligent infrastructure. Ergonomics 2014, 57, 387–402. [Google Scholar] [CrossRef]
- Hollnagel, E.; Woods, D.A. Joint Cognitive Systems: Foundations of Cognitive Systems Engineering; CRC Press: Boca Raton, FL, USA, 2005; pp. 177–195. [Google Scholar]
- ISO DIS 9241-210; Ergonomics of Human System Interaction—Part 210: Human-Centred Design for Interactive Systems. International Organization for Standardization: Geneva, Switzerland, 2010.
- Aboelmaged, M.G. Predicting e-readiness at firm-level: An analysis of technological, organizational and environmental (TOE) effects on e-maintenance readiness in manufacturing firms. Int. J. Inf. Manag. 2014, 34, 639–651. [Google Scholar] [CrossRef]
- Ciocoiu, L.; Siemieniuch, C.E.; Hubbard, E.M. From preventative to predictive maintenance: The organisational challenge. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2017, 231, 1174–1185. [Google Scholar] [CrossRef]
- Jonsson, K.; Holmström, J.; Levén, P. Organizational dimensions of e-maintenance: A multi-contextual perspective. Int. J. Syst. Assur. Eng. Manag. 2010, 1, 210–218. [Google Scholar] [CrossRef]
- Ingemarsdotter, E.; Kambanou, M.L.; Jamsin, E.; Sakao, T.; Balkenende, R. Challenges and solutions in condition-based maintenance implementation-A multiple case study. J. Clean. Prod. 2021, 296, 126420. [Google Scholar] [CrossRef]
- Garrone, A.; Minisi, S.; Oneto, L.; Dambra, C.; Borinato, M.; Sanetti, P.; Vignola, G.; Papa, F.; Mazzino, N.; Anguita, D. Simple Non Regressive Informed Machine Learning Model for Prescriptive Maintenance of Track Circuits in a Subway Environment. In Proceedings of the International Conference on System-Integrated Intelligence, Genova, Italy, 7–9 September 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 74–83. [Google Scholar]
- Nielsen, J. 10 Usability Heuristics for User Interface Design. Nielsen Norman Group. 2020. Available online: https://www.nngroup.com/articles/ten-usability-heuristics (accessed on 22 April 2022).
- Bhaskar, N.; Naidu, P.; Ravi Chandra Babu, S.; Govindarajulu, P. General Principles of User Interface Design and Websites. Int. J. Softw. Eng. IJSE 2011, 2, 45–60. [Google Scholar]
- Dixon, S.R.; Wickens, C.D.; McCarley, J.S. On the independence of compliance and reliance: Are automation false alarms worse than misses? Hum. Factors 2007, 49, 564–572. [Google Scholar] [CrossRef] [PubMed]
- Følstad, A.; Hornbæk, K. Work-domain knowledge in usability evaluation: Experiences with Cooperative Usability Testing. J. Syst. Softw. 2010, 83, 2019–2030. [Google Scholar] [CrossRef]
- Hignett, S.; McDermott, H. Qualitative methodology. In Evaluation of Human Work; CRC Press: Boca Raton, FL, USA, 2015; pp. 119–138. [Google Scholar]
- Golightly, D.; Easton, J.M.; Roberts, C.; Sharples, S. Applications, value and barriers of common data frameworks in the rail industry of Great Britain. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2013, 227, 693–703. [Google Scholar] [CrossRef]
- Dadashi, N.; Wilson, J.R.; Golightly, D.; Sharples, S.; Clarke, T. Practical use of work analysis to support rail electrical control rooms: A case of alarm handling. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2013, 227, 148–160. [Google Scholar] [CrossRef]
- Naikar, N.; Moylan, A.; Pearce, B. Analysing activity in complex systems with cognitive work analysis: Concepts, guidelines and case study for control task analysis. Theor. Issues Ergon. Sci. 2006, 7, 371–394. [Google Scholar] [CrossRef]
- Rasmussen, J. Information Processing and Human-Machine Interaction: An Approach to cognitive Engineering; North-Holland: New York, NY, USA, 1986. [Google Scholar]
- Bevan, N.; Barnum, C.; Cockton, G.; Nielsen, J.; Spool, J.; Wixon, D. The “magic number 5” is it enough for web testing? In Proceedings of the CHI’03 Extended Abstracts on Human factors in Computing Systems, Ft. Lauderdale, FL, USA, 5–10 April 2003; pp. 698–699. [Google Scholar]
- Bangor, A.; Kortum, P.T.; Miller, J.T. An empirical evaluation of the system usability scale. Intl. J. Hum.–Comput. Interact. 2008, 24, 574–594. [Google Scholar] [CrossRef]
- Quin, F.; Weyns, D.; Galster, M.; Silva, C.C. A/B testing: A systematic literature review. J. Syst. Softw. 2024, 211, 112011. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information | Data | Data Recording Method(s) |
|---|---|---|
| Indication of pantograph contact strip condition | Maximum lateral acceleration (m/s2) of the contact wire at the most recently passed sensor Average train speed (km/h) over contact strip lifetime Distance travelled (km) over contact strip lifetime | Optical accelerometers attached to the top of the contact wire oriented perpendicular to the direction of the tracks every 0.5 km [22] or a vison-based system [26] identifying movement parameters through machine learning Average speed is calculated from wheel rotation using a digital counter on one of the train’s wheelset shafts: Speed (m/s) = Wheel Circumference (m) × Shaft rotations per second (rps) Distance travelled also calculated from wheel rotation: Distance (m) = Wheel circumference (m) × Total number of shaft rotations |
| Risk posed by force between contact strip and contact wire | Contact force (N) over a 25 s period | When using the model described in [25] to calculate the dynamic contact force, for this low-speed application the new method described in [25] is not required and the vibration of subsystem 1 (the pantograph contact strip) can be treated as simple rigid-body motion. One accelerometer placed at the centre of the panhead can be used to calculate the inertial force and three load cells placed underneath the contact strip to measure the force of subsystem 2 (panhead) acting on subsystem 1 (contact strip). |
| Risk posed by the weather | Wind speed (m/s) Weather type Ambient temperature (°C) | Using local weather available online |
| Risk posed by the presence of arcing | Whether an arc is detected or not (Yes/No) | Using video footage from a camera mounted to the roof of the vehicle that is analysed using a vision-based algorithm like that of the firefly algorithm used in [26]. |
| Type | Fault |
|---|---|
| OHLE Condition | Thinning of contact wire due to wear, resulting in eventual failure. |
| Failure/wear of section insulation | |
| Contact wire height going out of tolerance | |
| Contact wire stagger going out of tolerance | |
| Failed droppers can cause damage to the pantograph contact strip. | |
| Kinks/Imperfections in the contact wire can cause localised increases in wear as well as damage to the pantograph contact strip. | |
| Bearings/points of movement seizing can result in incorrect contact wire height/tension | |
| Pantograph Condition | Thinning of the contact strip due to wear (particularly in icy weather) eventually results in damage to the contact wire or entanglement. Additionally, the build-up of carbon dust can cause a breakdown of insulation. |
| The seizing of a bearing or the failure of the pantograph air supply can result in the arm exerting the incorrect pressure on the contact wire. | |
| External Factors | Wind can cause objects like plastic bags or tree branches to wrap themselves around overhead line equipment. |
| Trespass and vandalism, particularly shoes thrown over the OHLE, can cause catastrophic failure. | |
| The accumulation of dirt in tunnels or under bridges | |
| Bird strikes can damage pantographs though arcing as well as direct impact. |
| Screen | Notification | Acceptance | Analysis | Clearance |
|---|---|---|---|---|
| Suggestions for additional features/ information | Train speed Ambient temperature Contact wire deviation A colour coded indication of how far past the expected value something is, rather than a binary indication | Vehicle ID number GPS Location Number of times this alarm has happened in this area History of any engineering works or repairs to this pantograph/location A colour coded indication of how far past the expected value something is, rather than a binary indication | Suggestion of whether a fault is caused by infrastructure or rolling stock Infographic to spot fault trends more easily A colour coded indication of how far past the expected value something is, rather than a binary indication | Head code Vehicle ID Operating Company Time/Date/User stamp for each cleared event A feature that automatically sends a text/email with the fault information and corrective action to the chosen person/people A feature to automatically produce a fault or condition report with one click |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richards, J.; Golightly, D.; Palacin, R. Cognitive Principles for Remote Condition Monitoring Applied to a Rail Pantograph System. Appl. Sci. 2024, 14, 5801. https://doi.org/10.3390/app14135801
Richards J, Golightly D, Palacin R. Cognitive Principles for Remote Condition Monitoring Applied to a Rail Pantograph System. Applied Sciences. 2024; 14(13):5801. https://doi.org/10.3390/app14135801
Chicago/Turabian StyleRichards, Joseph, David Golightly, and Roberto Palacin. 2024. "Cognitive Principles for Remote Condition Monitoring Applied to a Rail Pantograph System" Applied Sciences 14, no. 13: 5801. https://doi.org/10.3390/app14135801
APA StyleRichards, J., Golightly, D., & Palacin, R. (2024). Cognitive Principles for Remote Condition Monitoring Applied to a Rail Pantograph System. Applied Sciences, 14(13), 5801. https://doi.org/10.3390/app14135801