
A Blockchain-Driven Smart Broker for Data Quality Assurance of the Tagged Periodic IoT Data in Publisher-Subscriber Model


Abstract
:1. Introduction
- (a)
- An innovative topic drift monitoring module that keeps track of data publishing schedules.
- (b)
- A data quality assessment module. This module evaluates the quality of the data on the publisher’s topics. The smart broker identifies and flags unreliable topics through a peer assessment with other similar data streams in the same time frame. The blockchain guarantees that the quality assessment is impartial and timely.
- (c)
- A topic reputation scoring mechanism continuously assigns a score to each topic as a function of the quality and drift score of the topic data. This real-time score provides subscribers with current information on the topic, enabling them to make informed decisions based on the topic’s current reputation status.
- (d)
- The smart broker also acts as a recommender system for subscribers when the requested data are unavailable. Based on the subscriber’s original request, it offers the most reliable, relevant, and relatable data.
2. Related Works
2.1. Existing Publisher-Subscriber Approach
2.1.1. Centralized Architecture
2.1.2. Scalability and Efficiency Issues
2.1.3. Quality Issue
2.2. Blockchain-Based Publisher Subscribers
2.3. Trust vs. Quality
2.4. Recommendation Strategies
3. Proposed Architecture Overview
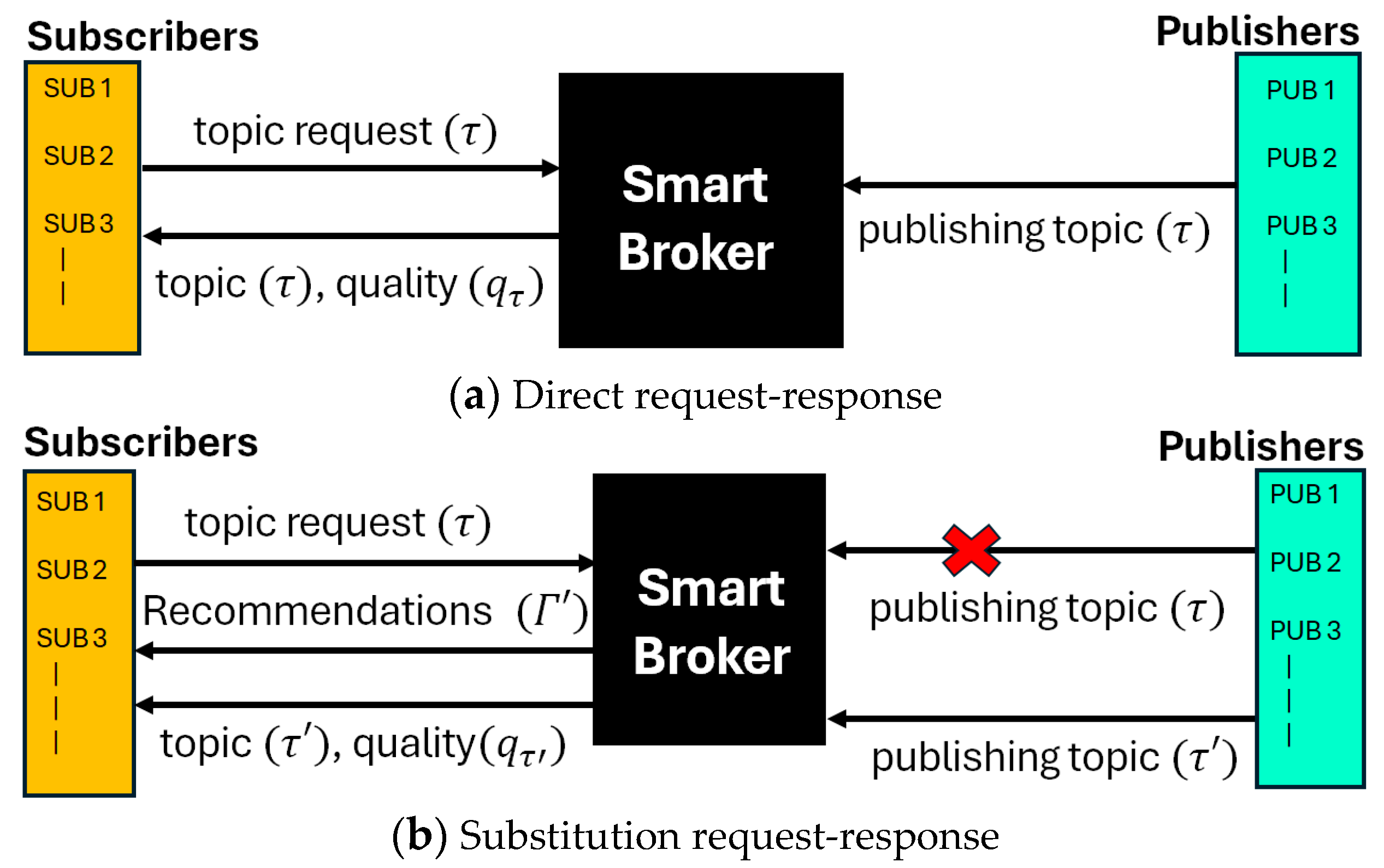
3.1. Request–Response Model
- Direct Request–Response: Like traditional PS models, the subscriber asks for data for a topic (τ), and the smart broker responds with the data. Along with the data, the broker also sends a quality score qτ [0, 1]. It is expected that the broker, if based on a blockchain, will provide reliable, unbiased, and quality information.
- Substitution Request–Response: A special case arises in this model when the requested data are not present at the current time. As the broker is smart and based on blockchain, it can recommend some other topics to the subscriber that are similar to the topic originally requested. These substitution recommendations may also be given if the quality of the data for the qτ drops dramatically. It is then up to the subscriber to decide on a recommended topic. Once the subscriber chooses a substitute topic τ′, further communication follows the direct request–response as before.
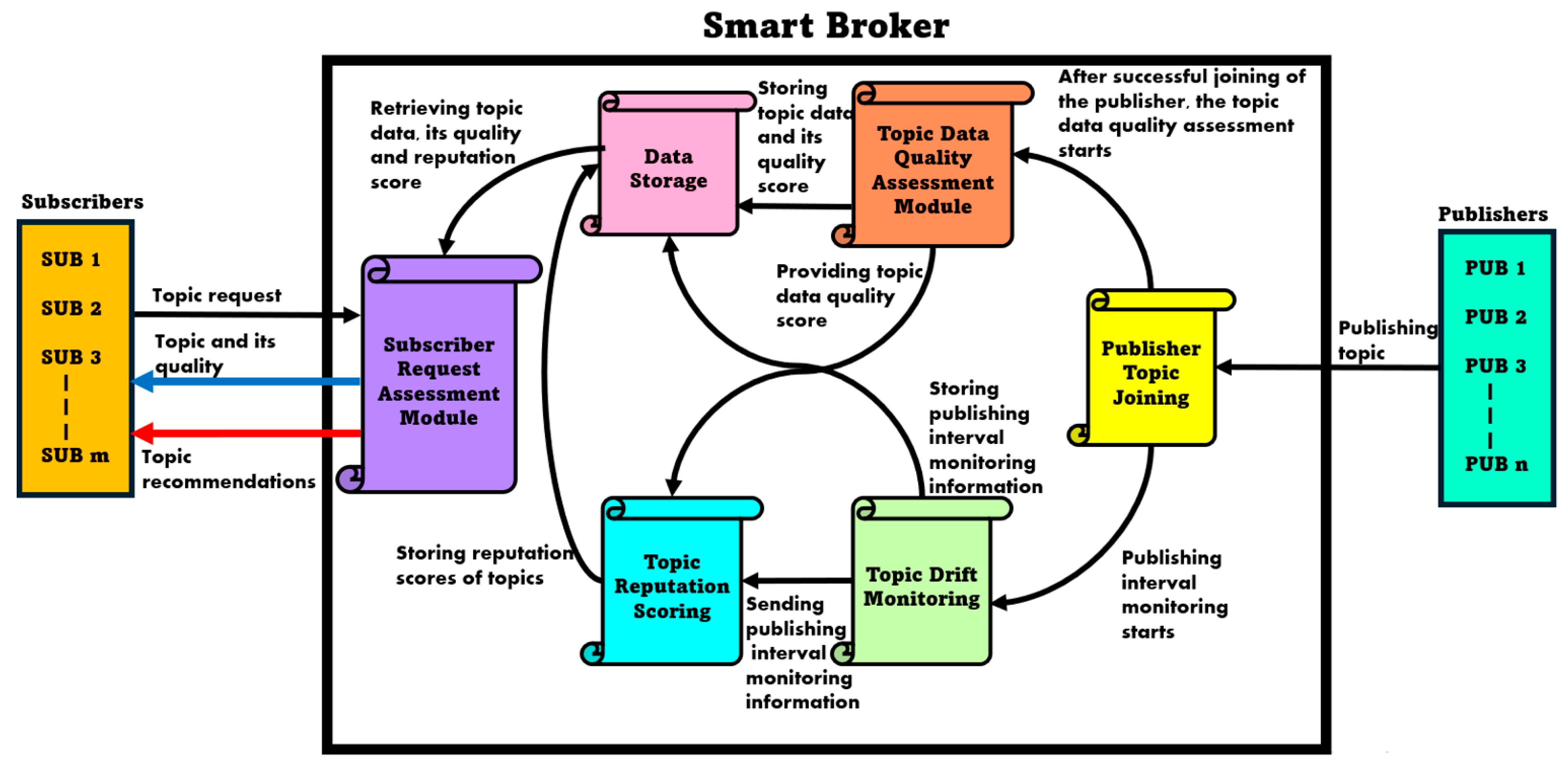
3.2. Proposed System Architecture: Smart Broker
- Calculating the quality of data for the publishers. This is typically performed for individual topics based on various parameters, such as relationship with other topics and timeliness.
- Preparing a list of recommended topics based on the metadata of the topics in case a particular topic is not available.
- (1)
- Publisher-topic registration serves as the first step for any new incoming publisher (IoT device) data within the smart broker. It enables the registration of topics by analyzing the presence of essential tags. Additionally, topics are manually grouped based on their correlation to one another.
- (2)
- The Topic Data Quality Assessment Module (TDQAM) assesses the reliability of registered publisher IoT data by checking its quality and promptly acting to flag publishers providing poor-quality data. The publisher’s data that has gone through reliability checks is granted access to the blockchain-based storage.
- (3)
- The blockchain-based Data Storage Module (DSM) is designed to store data from all the modules, including data that have passed the assessment checks, accompanied by its corresponding quality score.
- (4)
- Topic Drift Monitoring (TDM) monitors the publishing intervals of the publishers by detecting changes in the patterns of these intervals over time. It then transmits this information to the blockchain-based Topic Reputation Scoring (TRS) model.
- (5)
- The TRS continuously monitors the publisher’s reputation by using assessments from both TDQAM and TDM, providing reputation scores to each publisher. The Subscriber Request Assessment Module (SRAM) uses these reputation scores to prepare and send a publisher’s reputation score when a subscriber requests data from that publisher.
- (6)
- The SRAM manages IoT data requests from subscribers. It accepts incoming requests and delivers the requested data, along with its quality score, to the subscriber. It may also recommend substitute topics.
3.3. Assumptions
- Tagged Data: It is assumed that publishers create a limited number of alphanumeric tags accurately for each topic they publish. This framework relies on these tags to identify potential substitutes.
- Periodic Data: The data streams are periodic, that is, they are expected to send data at regular intervals. Periodicity assists in identifying delays in publishing intervals by establishing the expected timing for publication data and identifying deviations from these intervals.
- Manual data stream grouping: To establish quality, the proposed methods rely on sensor associations based on their own proximity and the proximity of the observed environment. It is assumed that this association is performed manually as part of the topic registration, and a group has a minimum of three topics. Under normal circumstances, the blockchain can keep track of and confirm this relationship continuously.
- Fixed Location: The IoT devices are assumed to be in fixed positions. These positions may be geographic or referential, such as in a building or factory. In other words, they are non-mobile by nature. Any change in the location needs to be updated in the blockchain and the pairings.
4. Design
4.1. Publisher-Topic Joining
4.1.1. Overview
- Location Tag (l): The location of the sensors collecting data related to τi is essential for SRAM to provide recommendations to subscribers. SRAM can recommend topics based on data from sensors that are closely related to each other.
- Publishing interval Tag (:The publishing interval of the data related to the τi denotes the frequency or timing at which the data are published. The publishing interval is used by the TDM to calculate the publishing interval monitoring score, which will ultimately be used to calculate the topic’s reputation score in the smart broker.
- Other generic tags, such as sensor type, key timestamps, keywords, and measurement units, provide additional information and descriptions about the topic. There is both an upper and lower limit to the number of tags for a topic. This is to ensure that the recommendation process has sufficient data and, at the same time, is not biased toward any topic. Tags must also be chosen from a preset list of tags.
4.1.2. Topic Registration Process
- Upon receiving the publisher’s topic joining request, the smart broker first verifies the presence of essential tags in the topic.
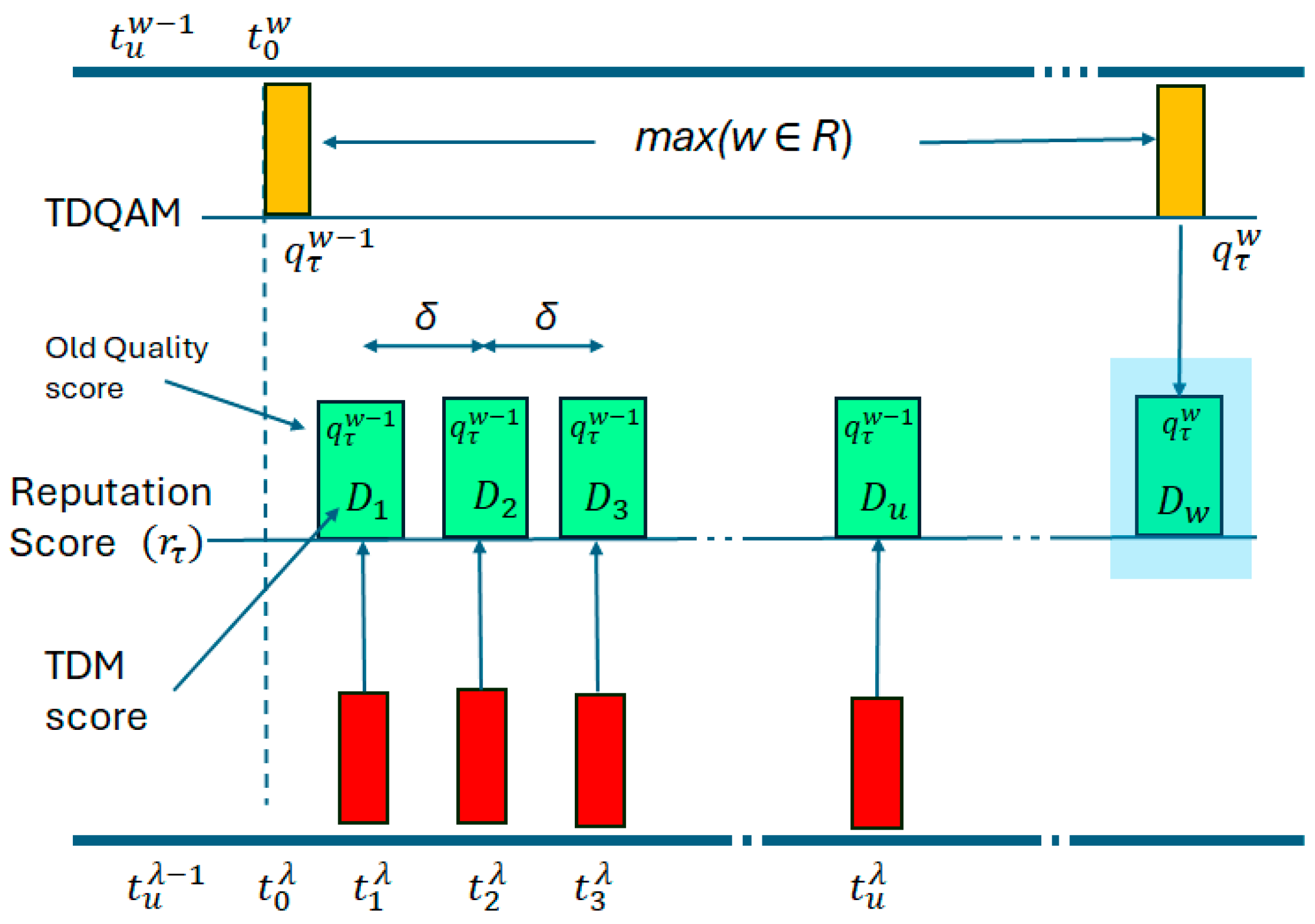
- Then, the manual data grouping of the topics takes place. It relies on the actual relationship that exists among the data streams. The correlation matrix (shown in Equation (3)) represents the actual relationship between the paired topics . Each pair of correlated topics has a predefined expected correlation value indicating the nature of their relationship within a range of −1 to 1, where 1 signifies a perfectly direct relationship, 0 denotes no relationship, and −1 represents a perfectly inverse relationship. These values are mapped to a range of 0 and 1 before storage in the database, where 1 indicates a perfect direct or indirect relationship, and 0 indicates no relationship. By default, , indicating that there is no relation at all. Typically, the smart broker will ignore such values and only consider topic pairs where . This correlation matrix is used by the TDQAM to conduct quality checks on the topic data.where is the reputation time window set corresponding to the topics τi and τj. Each has a corresponding , which is the expected correlation value in that window. As the time series is periodic, the set of windows will keep repeating infinitely. Additionally, λ is stored for the topic itself, which is another window for resetting drift scores. Typically, to ensure that the drift score is calculated quickly enough for reputation scoring.
- Finally, upon successful registration, the smart broker assigns a unique identity to the publisher topic and stores the identity in the blockchain. Upon successful registration, the publisher can start sending IoT data related to the topic.
4.2. Topic Drift Monitoring
4.3. Topic Data Quality Assessment Module
- It needs to establish a reference mechanism to measure the correctness of the currently incoming data. This can be performed in two ways:
- Absolute reference is where the user creates a set of static reference values, and quality is a measurement of deviation from these reference points. This can take the form of self-assessment with its own historical reference value. However, many sensor data may have randomness, meaning matching with its own history or fixed reference may be difficult.
- Relative reference is peer assessment at the current time. If the IoT systems generate a continuous stream of data, then we get a multivariate time series. This mechanism would aim to establish the deviation of one topic’s data compared to other topics. In this paper, we focus on peer assessment using unsupervised methods.
- A mechanism that only considers some of the latest incoming data points, that is, upgrading the quality score whenever the latest window of data are available. In the case of supervised mechanisms, methods of determining time windows may be different from those used in the paper.
- The quality score should be on the same scale. In this paper, we aim to calculate everything as a real number between 0 (worst quality) and 1 (best quality). The scoring should also be uniform across all the topics.
- The most important factor is to ensure that each data stream is evaluated in isolation while being compared to others, that is, the quality score calculation for each data stream must be calculated to reflect its own quality only.
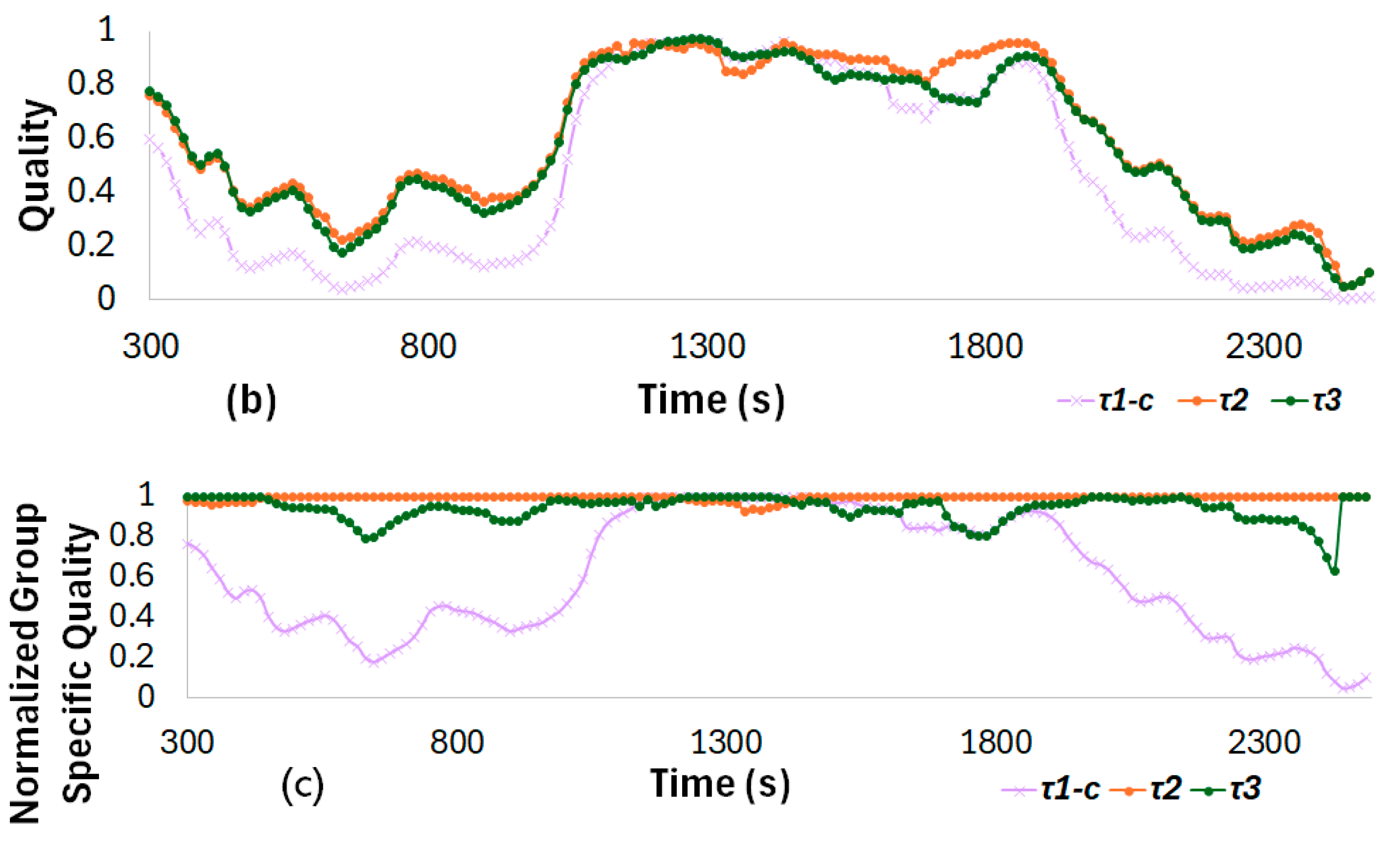
Normalized Group-Specific Quality Assessment
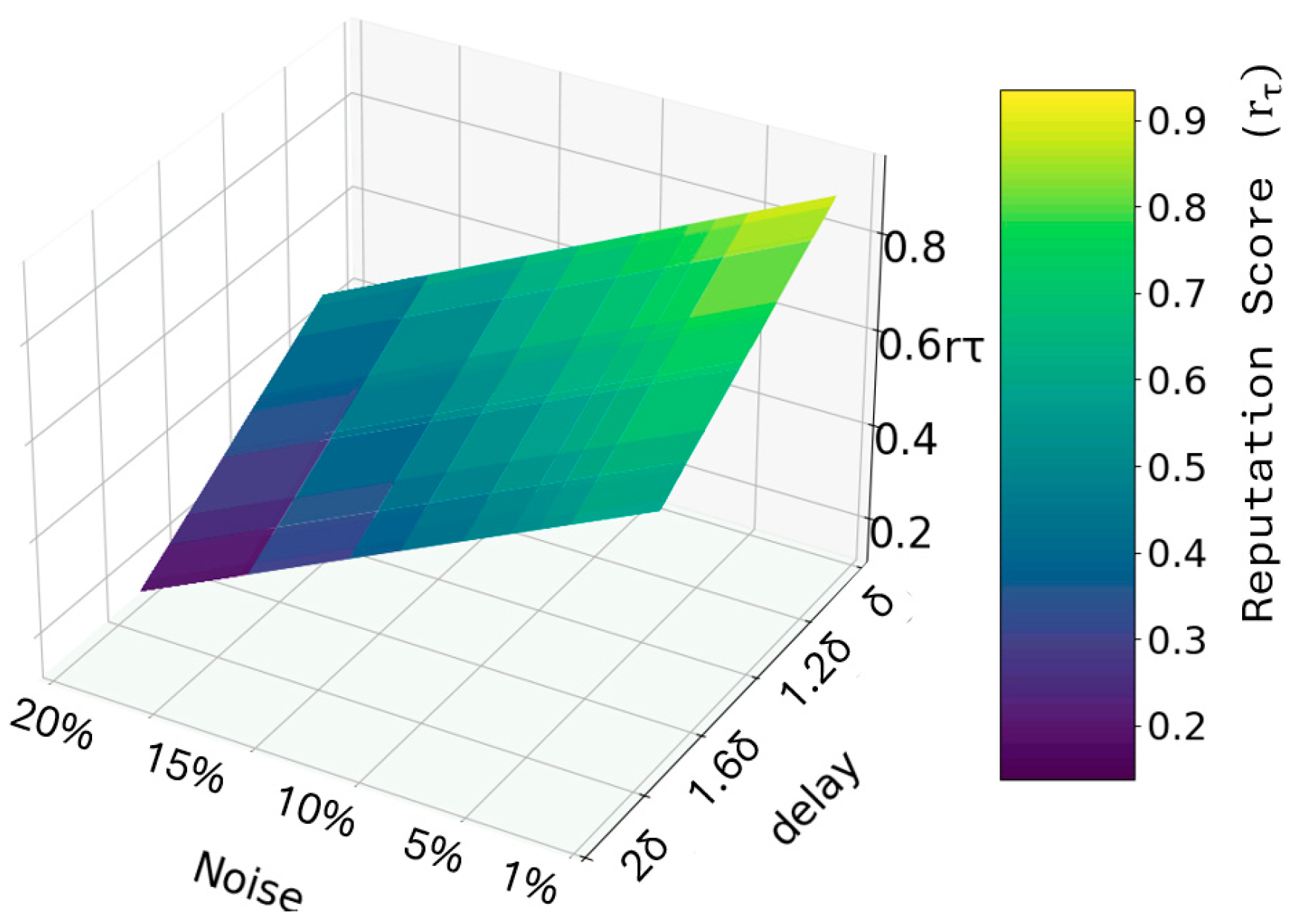
4.4. Topic Reputation Scoring
4.5. Execution of the Smart Broker System
4.5.1. The Continuous Execution
| Algorithm 1. Reputation Scoring at Time for ith Topic in } |
| , . , . , . Calculate , and . Calculate Q = { using Equation (12). Normalize Q, that is, for each . Reset if . Send to subscribers. |
4.5.2. Computational Complexity of the Proposed Smart Broker
4.6. Subscriber Request Assessment Module
5. Implementation and Evaluation
5.1. Setup Overview
5.2. Testing of Smart Broker Components
- Good communication: The blockchain network mainly operates at the application layer, so network delays do not hamper the application’s outcome. The IoT sensors would be sending data at an interval of at least 10 s, making any network-level latency variations and jitters insignificant to the drift score calculations.
- Distributed functionalities: The smart contracts all study fail-safe features. Due to their distributed nature, the functionalities will always be studied as long as there is at least one node. Multiple peer nodes are expected for a practical application, but for this paper, we tested the performance with one peer node.
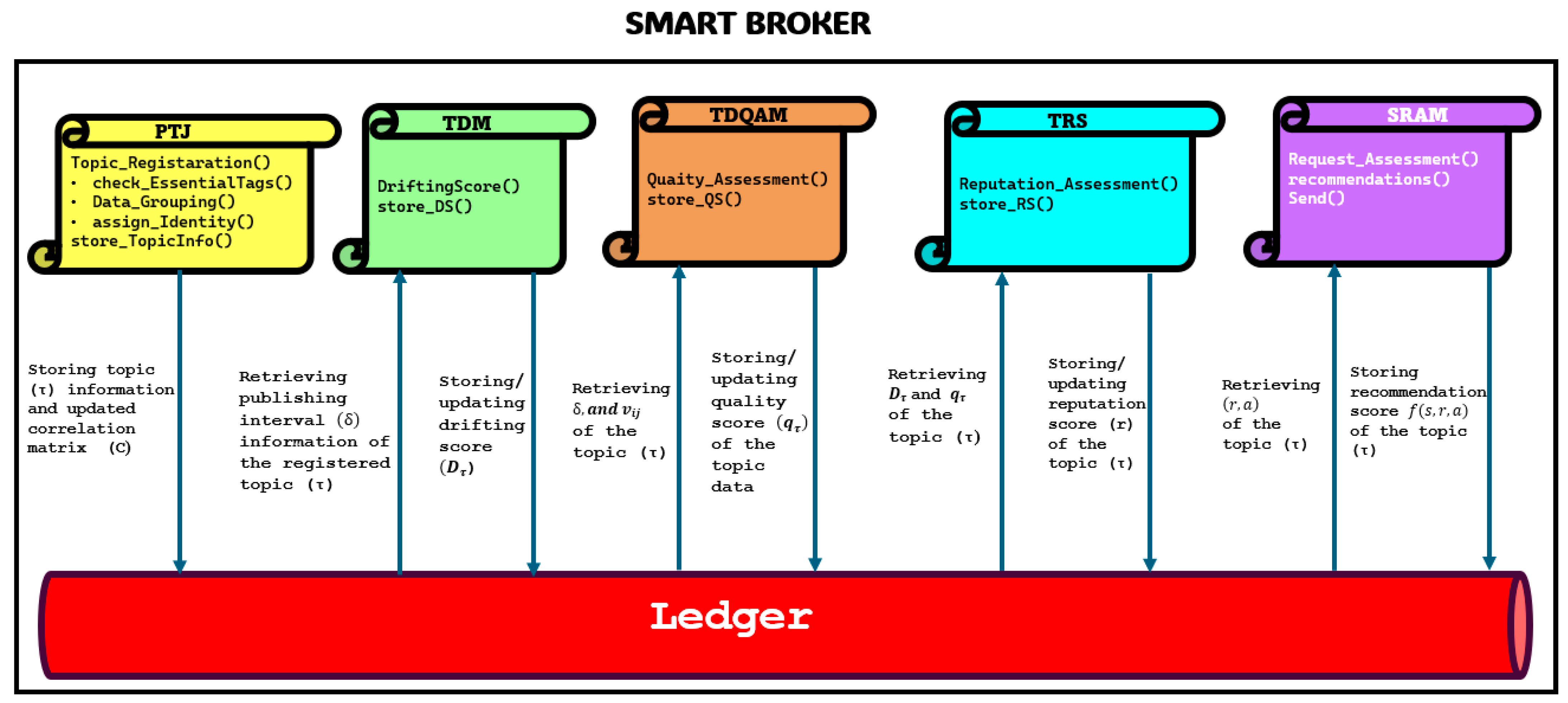
- (1)
- Publisher End Module:
- PTJ: This smart contract performs a topic registration process, which involves verifying essential tags and topic pairing. It updates the correlation matrix accordingly. The contract also stores topic details, including tag information, along with the updated correlation matrix. It also communicates with TDM, TDQAM, and TRS about the newly registered topic and its details so that TDM, TDQAM, and TRS can initiate their assessment of the topic.
- TDM: This smart contract retrieves publishing interval information for topics and continuously monitors the drifting score. It stores the drifting score after each interval, ensuring real-time tracking and analysis.
- TDQAM: This smart contract conducts quality assessments on topic data. It retrieves topic pairing data streams, correlation information, and publishing interval details from the ledger. Using this data, the topic’s quality is calculated, and the real-time quality score is stored in the ledger.
- TRS: The smart contract on the publisher side retrieves the topics’ assessment scores, quality scores, and drifting scores from the ledger. It then calculates the topic’s reputation score and stores it in the ledger.
- (2)
- Subscriber End Module:
- SRAM: This smart contract handles subscriber requests, providing data along with its quality score to the subscriber. It also prepares recommendation topics, if required, by calculating the similarity score, retrieving correlation information, and calculating the reputation score. Then, it prepares the recommendation score for the topics and sends it to the subscriber.
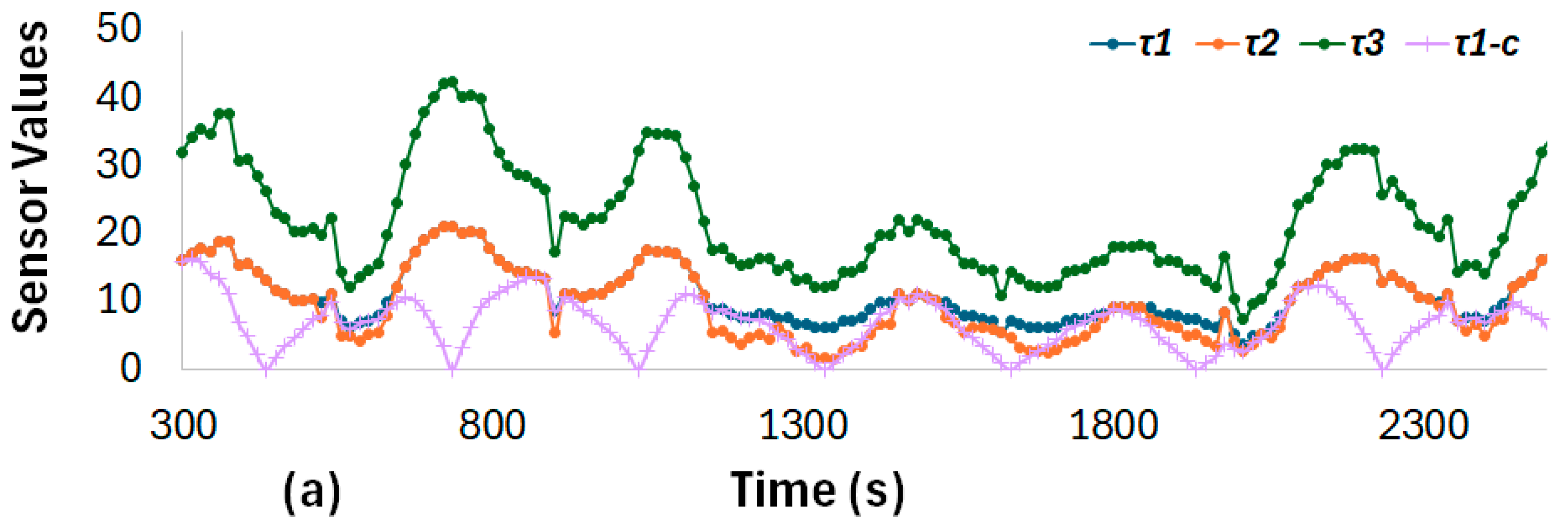
5.2.1. Preparation of a Correlation Matrix
5.2.2. Preparation of Correlated Topics for Testing
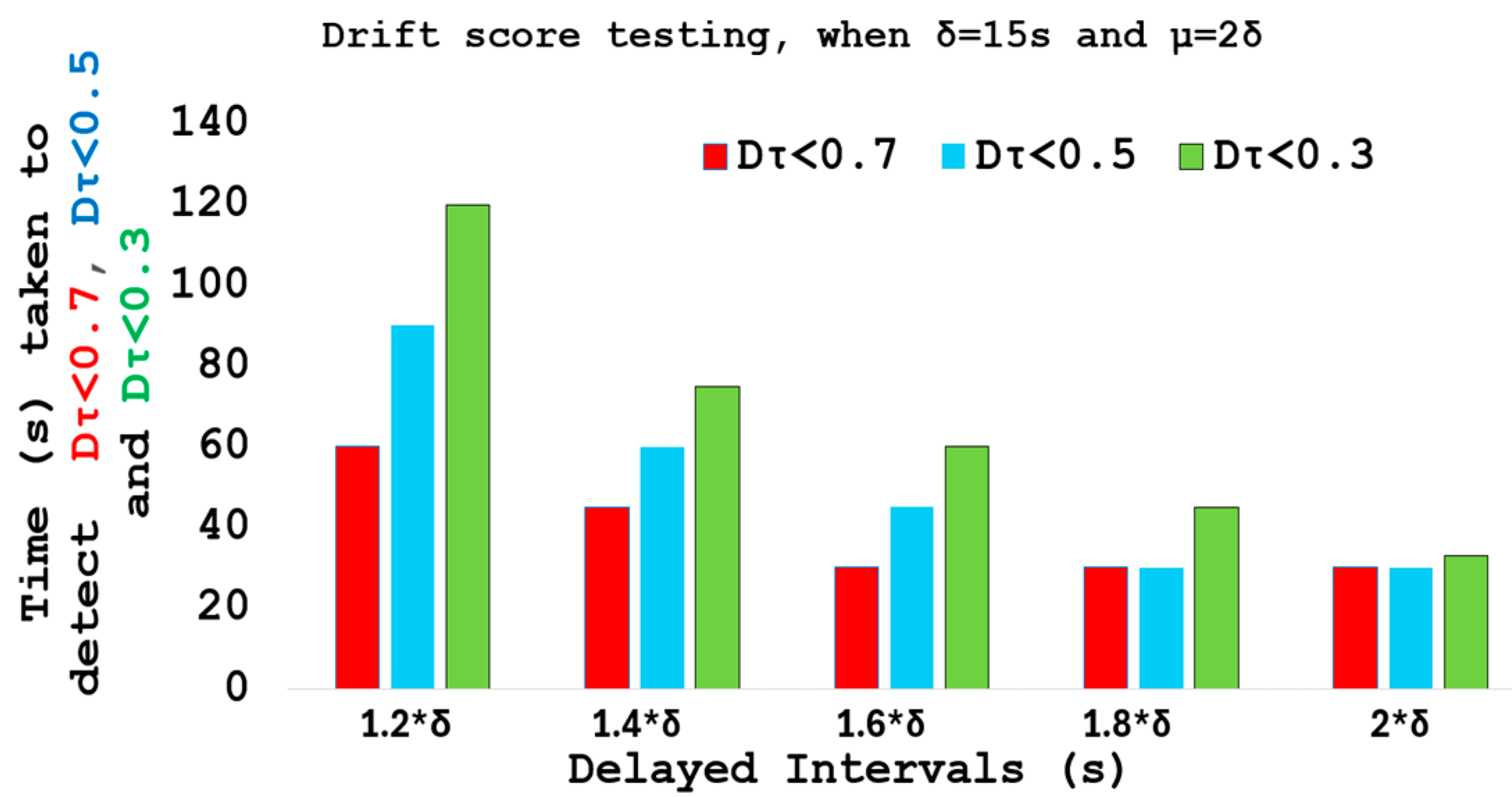
5.3. Drift Score Testing and Results
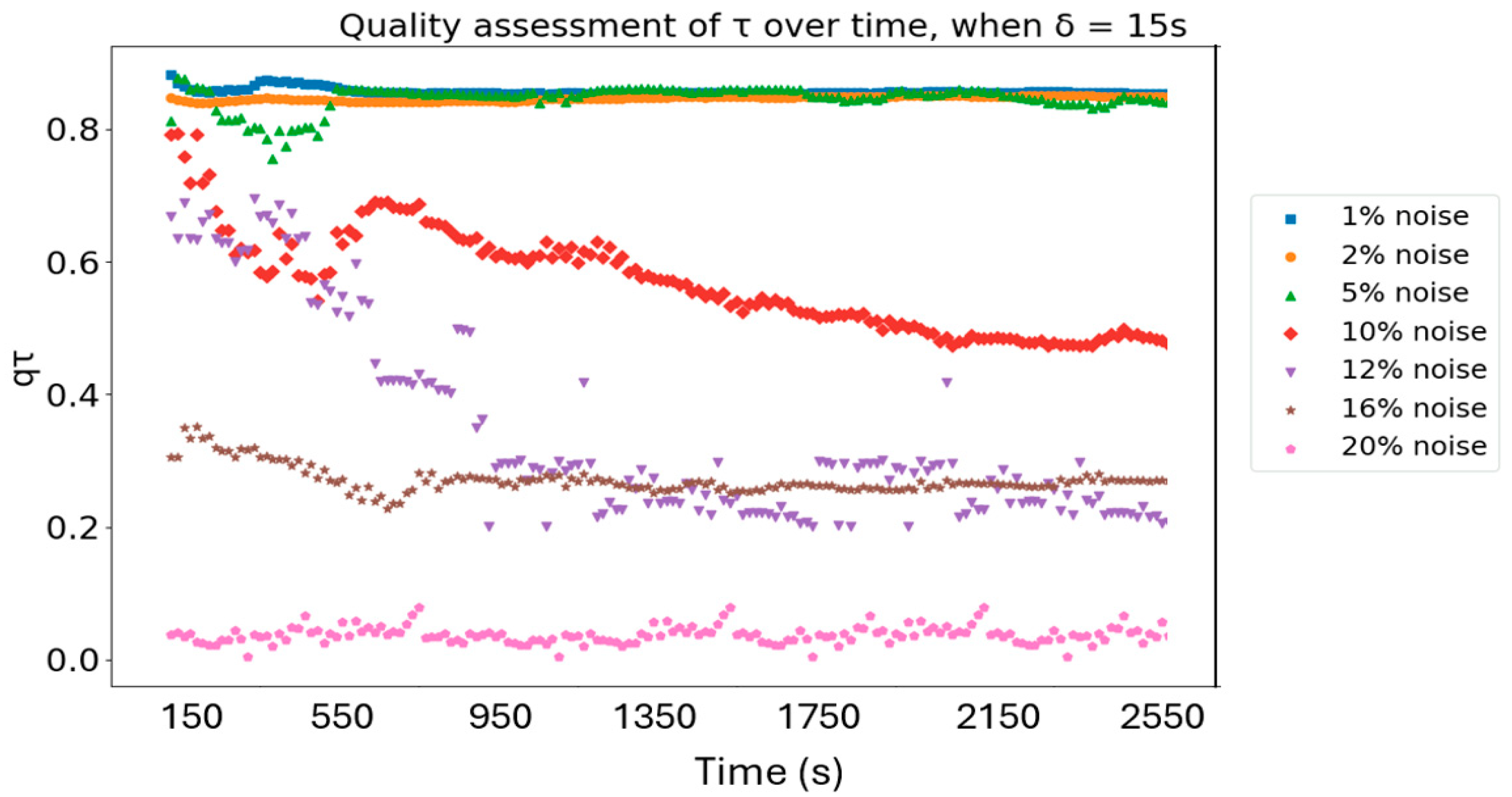
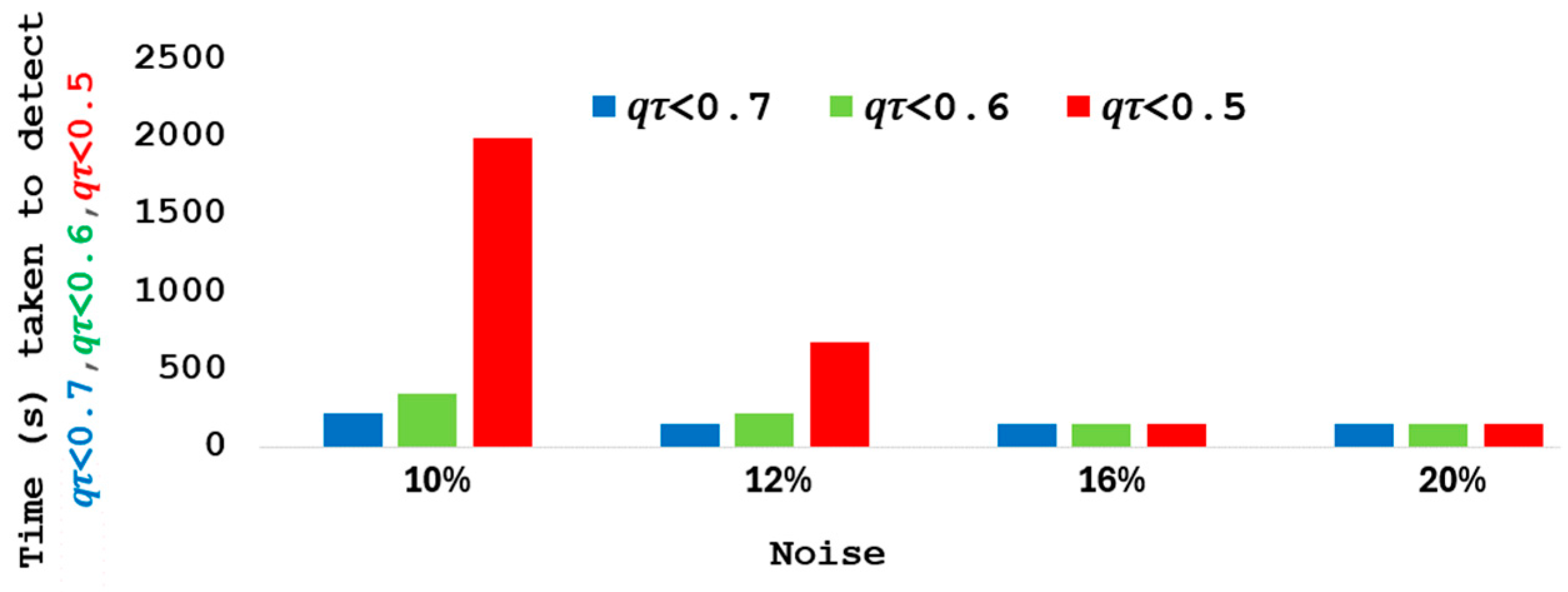
5.4. Quality Testing with Different Levels of Noise
5.4.1. Quality Calculations with Noise and Fixed Windows Size
5.4.2. Understanding the Impact of Large Windows Size
5.5. Reputation Scoring Patterns
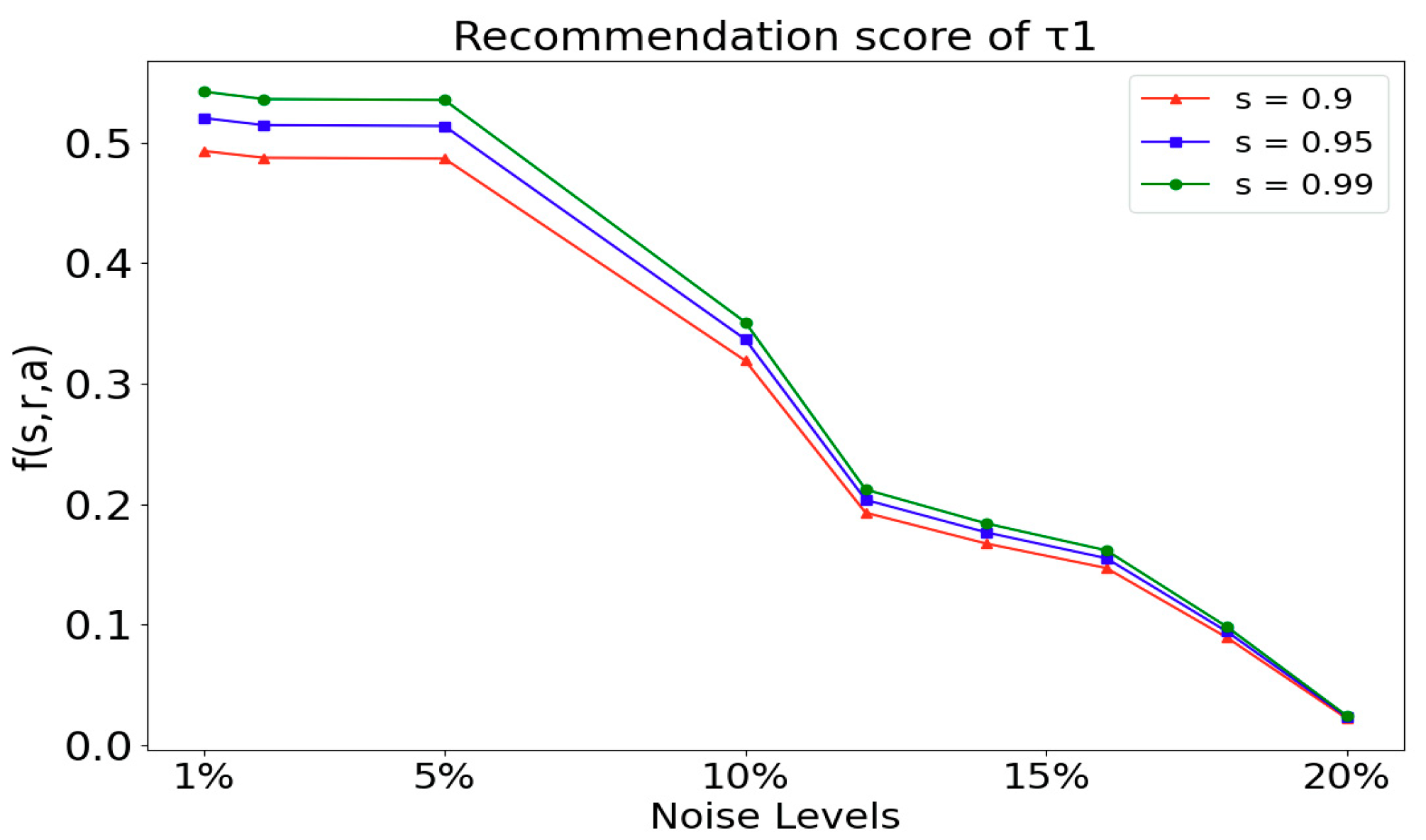
5.6. Recommendation Testing
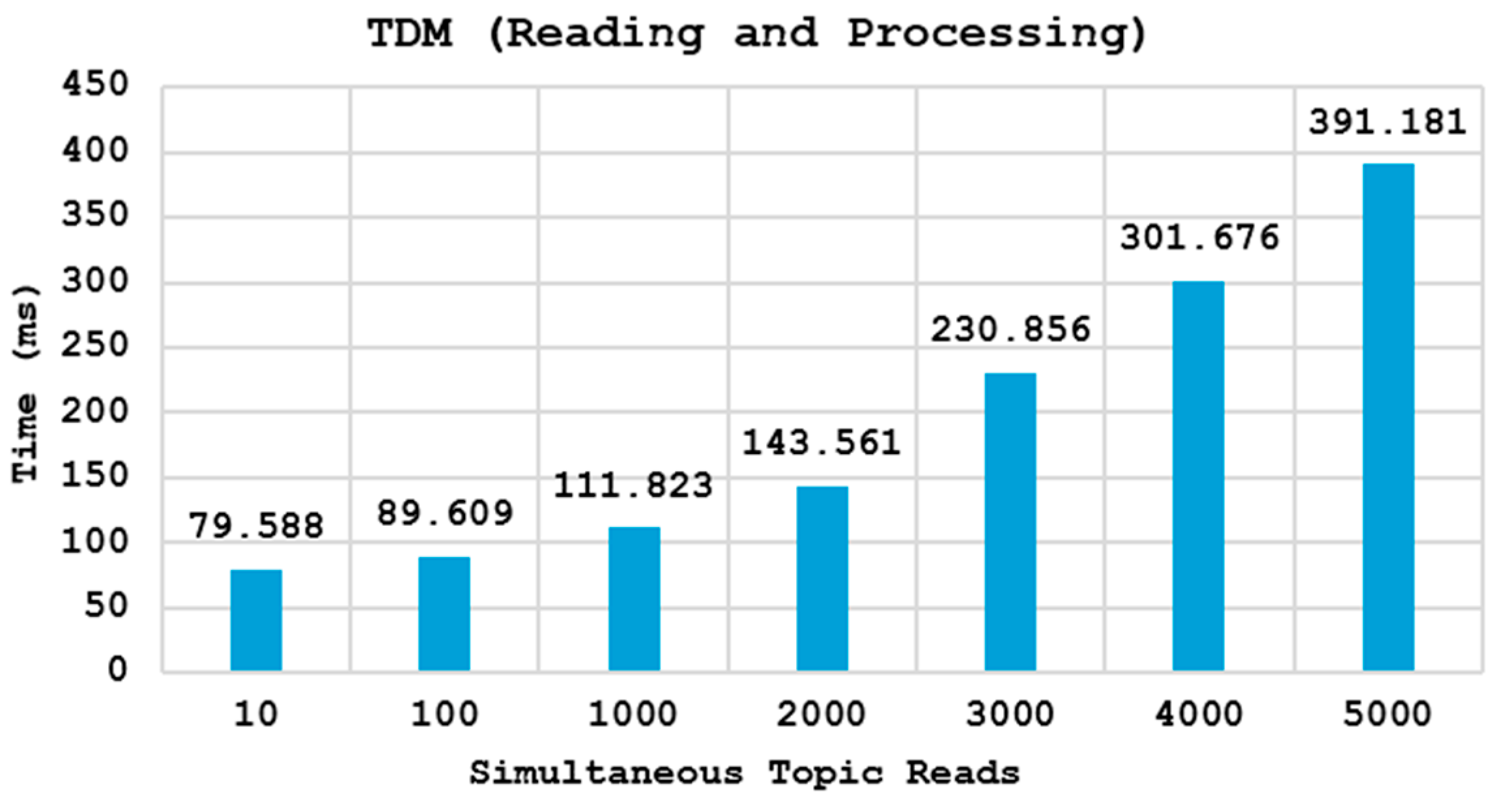
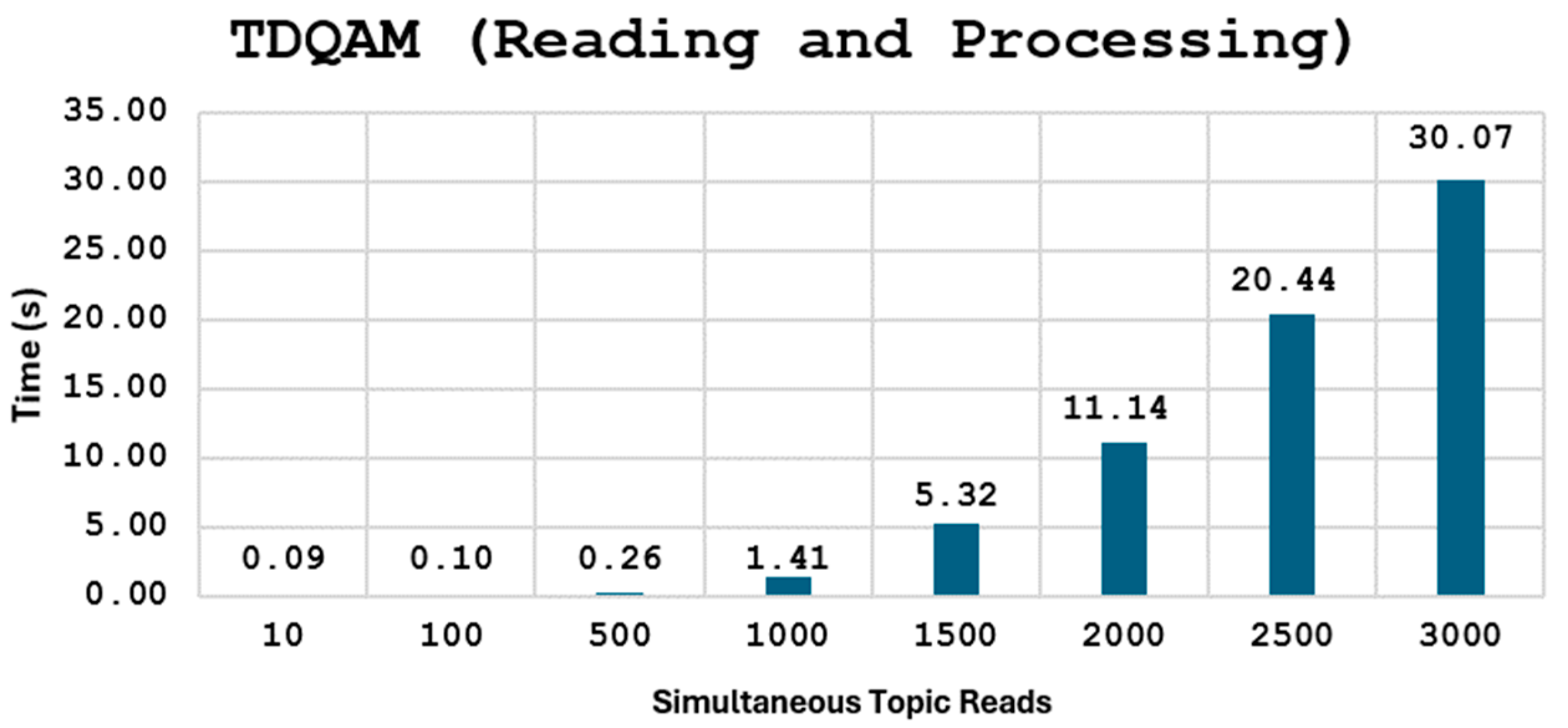
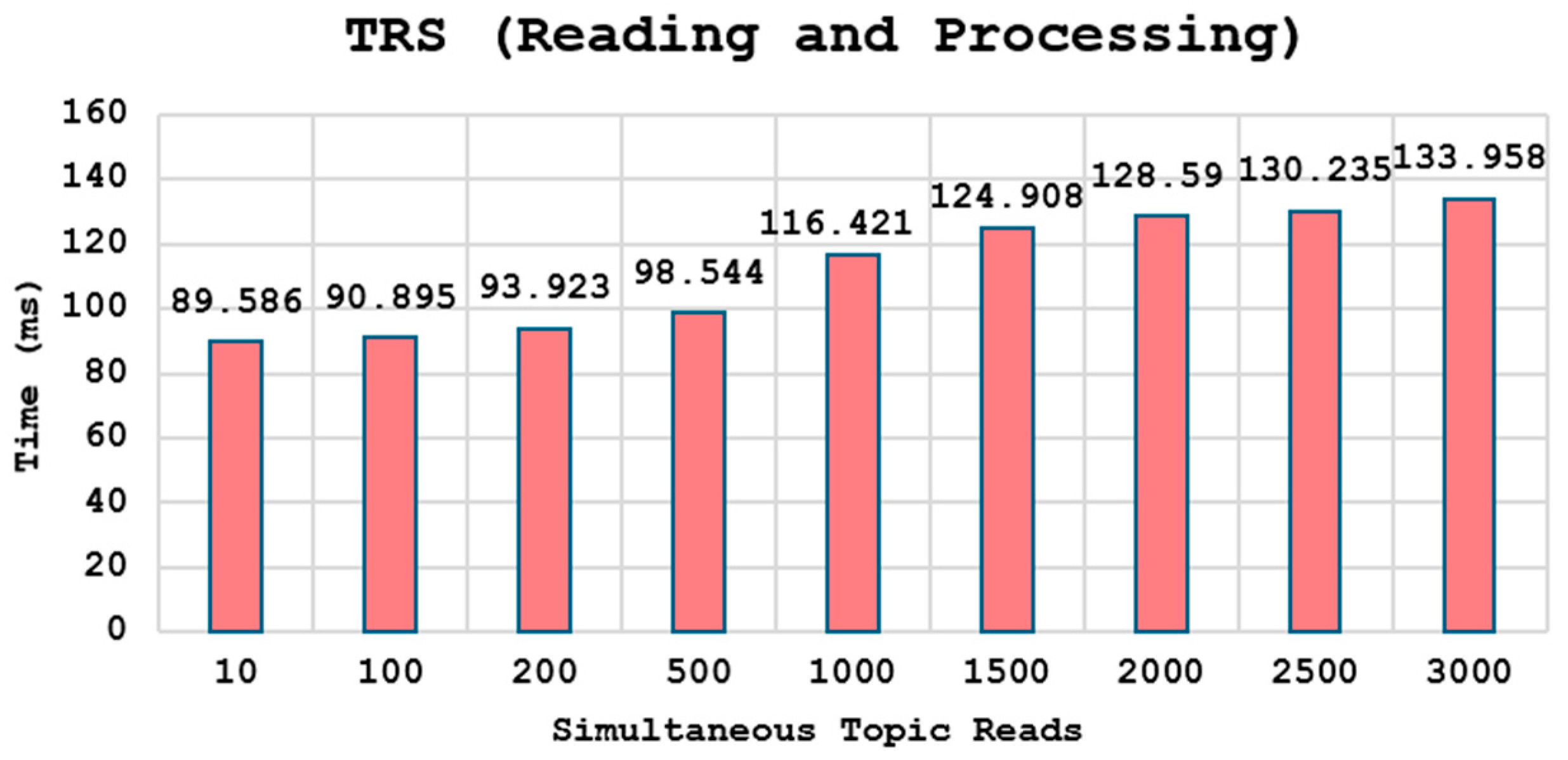
5.7. Performance Evaluation of Smart Broker
6. Characteristics of the Smart Broker
6.1. Characteristics of the Blockchain Inherited by the Smart Broker
6.1.1. Advantage—Trust Management with Automation and Immutability
6.1.2. Advantage—Registration of Publisher Topics
6.1.3. Disadvantage—Scalability Issues
6.1.4. Disadvantage—Bad Network Condition
6.2. Other Advantages of the Smart Broker
6.2.1. Topic Level Reputation Management
6.2.2. Recommendation for Subscribers
6.2.3. Real-Time Monitoring
6.3. Future Works and Limitations
6.3.1. Similarity Detection in a Smart Broker
6.3.2. Non-Linear Relationships
6.3.3. Self-Checks
6.3.4. Speed of Detecting Variations
6.3.5. Ability to Detect Problems
6.3.6. Performance Inside the Blockchain
6.3.7. Handling Event-Based Publishing Intervals
6.4. Real-World Applications
- Traffic Monitoring Sensors, including traffic cameras, speed sensors, and vehicle counters. These publishers can provide topics such as traffic flow, vehicle speed, and vehicle count.
- Environmental Sensors, including air quality monitors and weather stations, can provide information on topics such as the air quality index, temperature, humidity, and pollution levels.
- Public Transit Systems, including buses, trains, and trams, can cover topics such as transit schedules, vehicle locations, and passenger counts.
- Emergency Services, including police, fire departments, and ambulance services, can provide topics such as incident reports, response times, and emergency vehicle locations.
- Infrastructure Sensors, including roadway sensors and bridge monitors, can offer topics like road conditions, structural integrity, and maintenance schedules.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Banti, K.; Louta, M.; Baziana, P. Data Quality in Human-Centric Sensing Based Next Generation IoT Systems: A Comprehensive Survey of Models, Issues and Challenges. IEEE Open J. Commun. Soc. 2023, 4, 2286–2317. [Google Scholar] [CrossRef]
- Teh, H.Y.; Kempa-Liehr, A.W.; Wang, K.I.K. Sensor data quality: A systematic review. J. Big Data 2020, 7, 11. [Google Scholar] [CrossRef]
- Zhang, P.; Pang, X.; Kumar, N.; Aujla, G.S.; Cao, H. A Reliable Data-Transmission Mechanism Using Blockchain in Edge Computing Scenarios. IEEE Internet Things J. 2022, 9, 14228–14236. [Google Scholar] [CrossRef]
- Alshami, A.; Ali, E.; Elsayed, M.; Eltoukhy, A.E.E.; Zayed, T. IoT Innovations in Sustainable Water and Wastewater Management and Water Quality Monitoring: A Comprehensive Review of Advancements, Implications, and Future Directions. IEEE Access 2024, 12, 58427–58453. [Google Scholar] [CrossRef]
- Domínguez-Bolaño, T.; Campos, O.; Barral, V.; Escudero, C.J.; García-Naya, J.A. An overview of IoT architectures, technologies, and existing open-source projects. Internet Things 2022, 20, 100626. [Google Scholar] [CrossRef]
- Agrawal, A.; Choudhary, S.; Bhatia, A.; Tiwari, K. Pub-SubMCS: A privacy-preserving publish–subscribe and blockchain-based mobile crowdsensing framework. Future Gener. Comput. Syst. 2023, 146, 234–249. [Google Scholar] [CrossRef]
- Hamad, M.; Finkenzeller, A.; Liu, H.; Lauinger, J.; Prevelakis, V.; Steinhorst, S. SEEMQTT: Secure End-to-End MQTT-Based Communication for Mobile IoT Systems Using Secret Sharing and Trust Delegation. IEEE Internet Things J. 2022, 10, 3384–3406. [Google Scholar] [CrossRef]
- Junior, F.M.R.; Kamienski, C.A. A Survey on Trustworthiness for the Internet of Things. IEEE Access 2021, 9, 42493–42514. [Google Scholar] [CrossRef]
- Zhu, R.; Boukerche, A.; Long, L.; Yang, Q. Design Guidelines On Trust Management for Underwater Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2024. early access. [Google Scholar] [CrossRef]
- Liu, J.; Yang, J.; Wu, W.; Huang, X.; Xiang, Y. Lightweight Authentication Scheme for Data Dissemination in Cloud-Assisted Healthcare IoT. IEEE Trans. Comput. 2022, 72, 1384–1395. [Google Scholar] [CrossRef]
- Sai Lohitha, N.; Pounambal, M. Integrated publish/subscribe and push-pull method for cloud based IoT framework for real time data processing. Meas. Sens. 2023, 27, 100699. [Google Scholar] [CrossRef]
- Vilenski, E.; Bak, P.; Rosenblatt, J.D. Multivariate anomaly detection for ensuring data quality of dendrometer sensor networks. Comput. Electron. Agric. 2019, 162, 412–421. [Google Scholar] [CrossRef]
- Abubakar, M.A.; Jaroucheh, Z.; Al-Dubai, A.; Liu, X. Blockchain-based identity and authentication scheme for MQTT protocol. In Proceedings of the 2021 3rd International Conference on Blockchain Technology, Shanghai, China, 26–28 March 2021; pp. 73–81. [Google Scholar]
- Paul, G.A.; Jagnani, Y.; Supraja, P. Improving Fault Tolerance and Tackling Broker Failure in MQTT through Blockchain. In Proceedings of the 2023 Third International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 5–6 January 2023; pp. 1–6. [Google Scholar]
- Ramachandran, G.; Wright, K.-L.; Zheng, L.; Navaney, P.; Naveed, M.; Krishnamachari, B.; Dhaliwal, J. Trinity: A Byzantine Fault-Tolerant Distributed Publish-Subscribe System with Immutable Blockchain-based Persistence. In Proceedings of the 2019 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Seoul, Republic of Korea, 14–17 May 2019; pp. 227–235. [Google Scholar]
- Hossain, M.I.; Steigner, D.T.; Hussain, M.I.; Akther, A. Enhancing Data Integrity and Traceability in Industry Cyber Physical Systems (ICPS) through Blockchain Technology: A Comprehensive Approach. arXiv 2024, arXiv:2405.04837. [Google Scholar]
- Bakar, K.; Zuhra, F.; Isyaku, B.; Sulaiman, S. A Review on the Immediate Advancement of the Internet of Things in Wireless Telecommunications. IEEE Access 2023, 11, 21020–21048. [Google Scholar] [CrossRef]
- Goknil, A.; Nguyen, P.; Sen, S.; Politaki, D.; Niavis, H.; Pedersen, K.J.; Suyuthi, A.; Anand, A.; Ziegenbein, A. A Systematic Review of Data Quality in CPS and IoT for Industry 4.0. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Lv, P.; Wang, L.; Zhu, H.; Deng, W.; Gu, L. An IOT-Oriented Privacy-Preserving Publish/Subscribe Model Over Blockchains. IEEE Access 2019, 7, 41309–41314. [Google Scholar] [CrossRef]
- Li, L.; Jin, D.; Zhang, T.; Li, N. A Secure, Reliable and Low-Cost Distributed Storage Scheme Based on Blockchain and IPFS for Firefighting IoT Data. IEEE Access 2023, 11, 97318–97330. [Google Scholar] [CrossRef]
- Turner, S.W.; Karakus, M.; Guler, E.; Uludag, S. A Promising Integration of SDN and Blockchain for IoT Networks: A Survey. IEEE Access 2023, 11, 29800–29822. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, H.; Zhang, X.; Jin, Z.; Wen, Q. Secure and Efficiently Searchable IoT Communication Data Management Model: Using Blockchain as a New Tool. IEEE Internet Things J. 2018, 10, 11985–11999. [Google Scholar]
- Ataei, M.; Eghmazi, A.; Shakerian, A.; Landry, R.; Chevrette, G. Publish/Subscribe Method for Real-Time Data Processing in Massive IoT Leveraging Blockchain for Secured Storage. Sensors 2023, 23, 9692. [Google Scholar] [CrossRef]
- Buttar, H.M.; Aman, W.; Rahman, M.M.U.; Abbasi, Q.H. Countering Active Attacks on RAFT-Based IoT Blockchain Networks. IEEE Sens. J. 2023, 23, 14691–14699. [Google Scholar] [CrossRef]
- Li, K.C.; Shi, R.H. A Flexible and Efficient Privacy-Preserving Range Query Scheme for Blockchain-Enhanced IoT. IEEE Internet Things J. 2023, 10, 720–733. [Google Scholar] [CrossRef]
- Deebak, D.B.D.; Hussain, F.; Khowaja, S.; Dev, K.; Wang, W.; Qureshi, N.M.F.; Su, C. A Lightweight Blockchain Based Remote Mutual Authentication for IoT-Enabled Sustainable Computing Systems. IEEE Internet Things J. 2022, 8, 6652–6660. [Google Scholar] [CrossRef]
- AbuHalimeh, A.; Ali, O. Comprehensive review for healthcare data quality challenges in blockchain technology. Front. Big Data 2023, 6, 1173620. [Google Scholar] [CrossRef] [PubMed]
- Ashok, K.; Gopikrishnan, S. Statistical Analysis of Remote Health Monitoring Based IoT Security Models & Deployments From a Pragmatic Perspective. IEEE Access 2023, 11, 2621–2651. [Google Scholar] [CrossRef]
- Sanghami, S.V.; Lee, J.J.; Hu, Q. Machine-Learning-Enhanced Blockchain Consensus With Transaction Prioritization for Smart Cities. IEEE Internet Things J. 2023, 10, 6661–6672. [Google Scholar] [CrossRef]
- Li, C.; Chen, R.; Wang, Y.; Xing, Q.; Wang, B. REEDS: An Efficient Revocable End-to-End Encrypted Message Distribution System for IoT. IEEE Trans. Dependable Secur. Comput. 2024, 1–18. [Google Scholar] [CrossRef]
- Dedeoglu, V.; Jurdak, R.; Dorri, A.; Lunardi, R.C.; Michelin, R.A.; Zorzo, A.F.; Kanhere, S.S. Blockchain Technologies for IoT. In Advanced Applications of Blockchain Technology; Kim, S., Deka, G.C., Eds.; Springer: Singapore, 2020; pp. 55–89. [Google Scholar]
- Zhang, L.; Jeong, D.; Lee, S. Data Quality Management in the Internet of Things. Sensors 2021, 21, 5834. [Google Scholar] [CrossRef] [PubMed]
- Byabazaire, J.; O’Hare, G.; Delaney, D. Data Quality and Trust: Review of Challenges and Opportunities for Data Sharing in IoT. Electronics 2020, 9, 2083. [Google Scholar] [CrossRef]
- ISO 8000-8:2015; Data Quality—Part 8: Information and Data Quality: Concepts and Measuring. International Organization for Standardization: Geneva, Switzerland, 2015.
- KaradaŞ, H.B.; Kalkan, K. IBAM: IPFS and Blockchain based Authentication for MQTT protocol in IoT. In Proceedings of the 2023 IEEE Symposium on Computers and Communications (ISCC), Gammarth, Tunisia, 9–12 July 2023; pp. 537–542. [Google Scholar]
- Zupan, N.; Zhang, K.; Jacobsen, H.-A. Hyperpubsub: A decentralized, permissioned, publish/subscribe service using blockchains: Demo. In Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference: Posters and Demos, Las Vegas, NV, USA, 11–15 December 2017; pp. 15–16. [Google Scholar]
- Zhao, Y.; Li, Y.; Mu, Q.; Yang, B.; Yu, Y. Secure Pub-Sub: Blockchain-Based Fair Payment With Reputation for Reliable Cyber Physical Systems. IEEE Access 2018, 6, 12295–12303. [Google Scholar] [CrossRef]
- Buccafurri, F.; Romolo, C. A Blockchain-Based OTP-Authentication Scheme for Constrainded IoT Devices Using MQTT. In Proceedings of the 2019 3rd International Symposium on Computer Science and Intelligent Control, Amsterdam, The Netherlands, 25–27 September 2020. Article 55. [Google Scholar]
- Hsu, T.C.; Lu, H.-S. Designing a Secure and Scalable Service Model Using Blockchain and MQTT for IoT Devices. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 645–653. [Google Scholar]
- Liu, Z.; Meng, L.; Zhao, Q.; Li, F.; Song, M.; Dai, D.; Yang, X.; Guan, S.; Wang, Y.; Tian, H. A Blockchain-Based Privacy-Preserving Publish-Subscribe Model in IoT Multidomain Data Sharing. Wirel. Commun. Mob. Comput. 2022, 2022, 2381365. [Google Scholar] [CrossRef]
- Sharma, A.; Pilli, E.S.; Mazumdar, A.P.; Gera, P. Towards trustworthy Internet of Things: A survey on Trust Management applications and schemes. Comput. Commun. 2020, 160, 475–493. [Google Scholar] [CrossRef]
- Wang, J.; Yan, Z.; Wang, H.; Li, T.; Pedrycz, W. A Survey on Trust Models in Heterogeneous Networks. IEEE Commun. Surv. Tutor. 2022, 24, 2127–2162, Fourthquarter 2022. [Google Scholar] [CrossRef]
- Wairimu, S.; Iwaya, L.H.; Fritsch, L.; Lindskog, S. On the Evaluation of Privacy Impact Assessment and Privacy Risk Assessment Methodologies: A Systematic Literature Review. IEEE Access 2024, 12, 19625–19650. [Google Scholar] [CrossRef]
- Yin, C.; Xi, J.; Sun, R.; Wang, J. Location Privacy Protection Based on Differential Privacy Strategy for Big Data in Industrial Internet of Things. IEEE Trans. Ind. Inform. 2018, 14, 3628–3636. [Google Scholar] [CrossRef]
- Siboni, S.; Sachidananda, V.; Meidan, Y.; Bohadana, M.; Mathov, Y.; Bhairav, S.; Shabtai, A.; Elovici, Y. Security Testbed for Internet-of-Things Devices. IEEE Trans. Reliab. 2019, 68, 23–44. [Google Scholar] [CrossRef]
- Cai, B.; Li, X.; Kong, W.; Yuan, J.; Yu, S. A Reliable and Lightweight Trust Inference Model for Service Recommendation in SIoT. IEEE Internet Things J. 2022, 9, 10988–11003. [Google Scholar] [CrossRef]
- Shao, R.; Mao, H.; Jiang, J. Time-Aware and Location-Based Personalized Collaborative Recommendation for IoT Services. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; pp. 203–208. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Wang, H.; Huang, S.; Lin, C. COSS: Content-Based Subscription as an IoT Service. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 369–376. [Google Scholar] [CrossRef]
- Ugochukwu, N.A.; Goyal, S.B.; Rajawat, A.S.; Verma, C.; Illés, Z. Enhancing Logistics With the Internet of Things: A Secured and Efficient Distribution and Storage Model Utilizing Blockchain Innovations and Interplanetary File System. IEEE Access 2024, 12, 4139–4152. [Google Scholar] [CrossRef]
- Nawara, D.; Kashef, R. Context-Aware Recommendation Systems in the IoT Environment (IoT-CARS)—A Comprehensive Overview. IEEE Access 2021, 9, 144270–144284. [Google Scholar] [CrossRef]
- Ahlawat, P.; Rana, C. A Hybrid Trusted Knowledge Infusion Recommendation System for IoT-Based Applications. In Proceedings of the 2023 6th International Conference on Contemporary Computing and Informatics (IC3I), Gautam Buddha Nagar, India, 14–16 September 2023; pp. 973–977. [Google Scholar] [CrossRef]
- Yu, K.; Guo, Z.; Shen, Y.; Wang, W.; Lin, J.C.; Sato, T. Secure Artificial Intelligence of Things for Implicit Group Recommendations. IEEE Internet Things J. 2022, 9, 2698–2707. [Google Scholar] [CrossRef]
- Kaggle. dwinn183287. TPS July 2021—EDA. 2021. Available online: https://www.kaggle.com/code/dwin183287/tps-july-2021-eda (accessed on 27 June 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Meaning |
|---|---|
| A topic in the PS system | |
| Expected publishing interval | |
| A tag for the topic | |
| Drifting sore Performance indicator of the topic | |
| Reputation of the topic | |
| The quality of the sensor data related to the topic | |
| s | Similarity score |
| t | Current time |
| Expected relationship between the paired topics | |
| Association coefficient between the paired topics | |
| Time window for calculating quality for topics i and j | |
| Tolerance level of drift | |
| λ | Time window for calculating drift for a single topic |
| Parameter Settings | Value |
|---|---|
| 15 s | |
| Delayed intervals | [δ, 2δ] in increments of 0.2 |
| (0, 1] | |
| (0, 1] | |
| Noise µ | 1%, 2%, 5%, 10%, 12%, 16%, and 20% 2*δ |
| Correlation Thresholds for Topic (sensor_1, sensor_2, and sensor_5) | |
|---|---|
| 0.81 | |
| 0.86 | |
| 0.86 | |
| Network Configurations | Values |
|---|---|
| Batch timeout | 2 s |
| PreferredMaxBytes | 500 |
| Ledger Database | CouchDB |
| Block Size | 10 transactions |
| Number of channels | 1 |
| Number of topics | 1–5000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Idrees, R.; Maiti, A. A Blockchain-Driven Smart Broker for Data Quality Assurance of the Tagged Periodic IoT Data in Publisher-Subscriber Model. Appl. Sci. 2024, 14, 5907. https://doi.org/10.3390/app14135907
Idrees R, Maiti A. A Blockchain-Driven Smart Broker for Data Quality Assurance of the Tagged Periodic IoT Data in Publisher-Subscriber Model. Applied Sciences. 2024; 14(13):5907. https://doi.org/10.3390/app14135907
Chicago/Turabian StyleIdrees, Rabbia, and Ananda Maiti. 2024. "A Blockchain-Driven Smart Broker for Data Quality Assurance of the Tagged Periodic IoT Data in Publisher-Subscriber Model" Applied Sciences 14, no. 13: 5907. https://doi.org/10.3390/app14135907