
Adaptive Evolutionary Computing Ensemble Learning Model for Sentiment Analysis



Abstract
:1. Introduction
1.1. Background
1.2. Our Contributions
- TF-IDF was used to extract text features, and grid search was used to select the frequency and optimize the features according to the sentence size of different data sets.
- The intelligent optimization algorithm cuckoo search (CS) is introduced to adaptively search the penalty coefficient C and kernel function radius gamma associated with a support vector machine classifier (SVM).
- The training set was split into multiple subsets, and a sub-classifier was trained on each subset of the training set. The output of all sub-classifiers was combined to generate the final prediction.
- Comparative experiments were carried out on six real data sets, including imdbs, yelp, sen_pol, amazon_cells, SST-2, and IMDBR. Experimental results showed that AdaECELM was superior to other machine learning models in all short text SA. Therefore, the proposed AdaECELM short-text sentiment analysis computational framework is superior to most existing models.
2. Related Works
2.1. Machine Learning
2.2. Ensemble Learning
2.3. Intelligent Computing
2.4. Fairness in Sentiment Analysis
3. Proposed Method
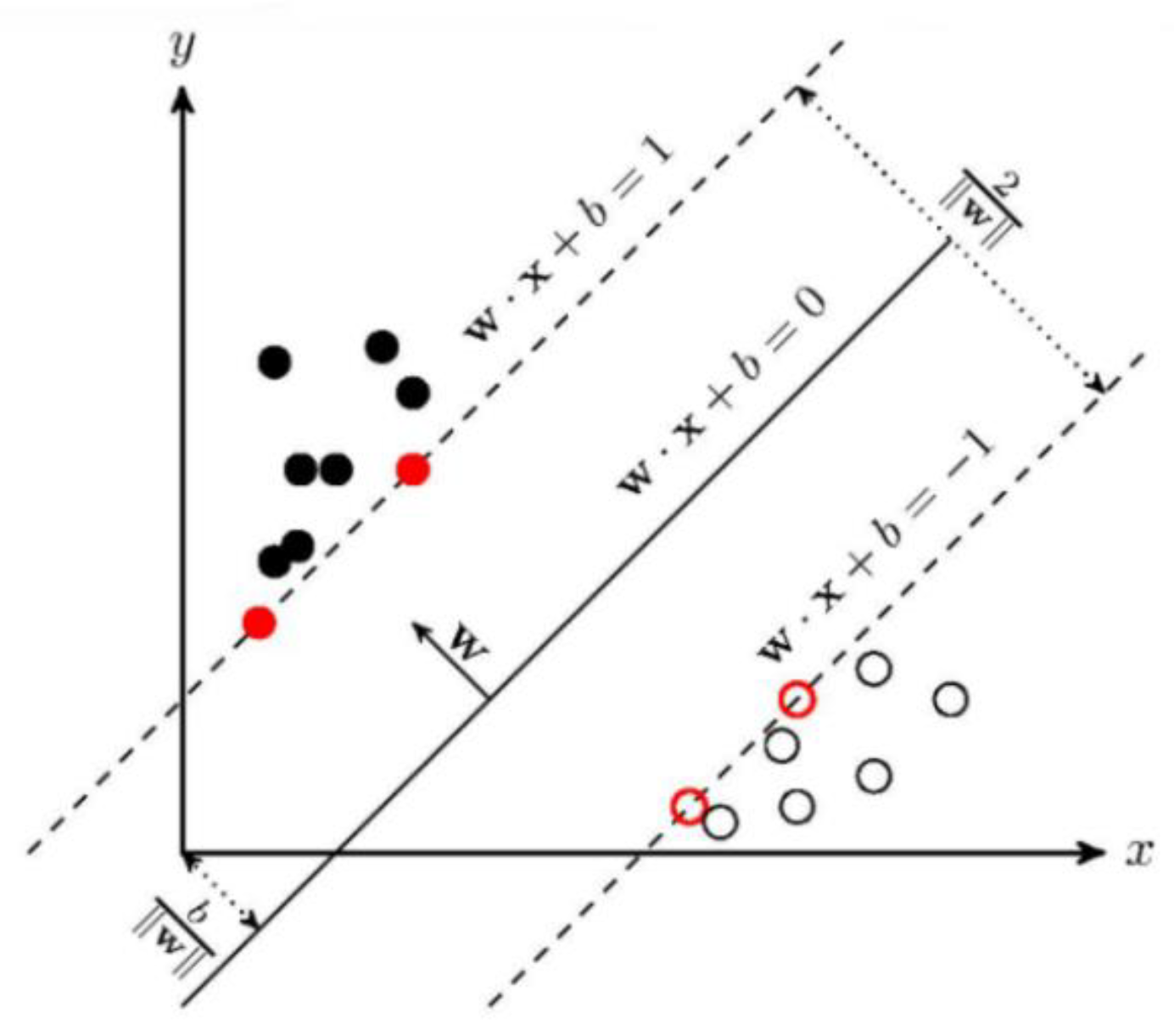
3.1. Problem Definition
- How do we design a text analysis system that can leverage multiple classifiers and combine the answers provided by each of them to obtain a more precise estimate of the polarity of a sentence?
- How do we achieve an accurate representation of sentences using numerical features that are free from issues such as redundancy and feature sparsity?
- Since available classifiers often depend on multiple hyperparameters, is it possible to implement a fast and automated mechanism to choose the best hyperparameter configuration (i.e., the configuration that maximizes the accuracy of our system)?
3.2. AdaECELM Model
- Step 1: Set parameters, initialize the population, and calculate the fitness value of everyone. At the same time, record the current optimal cuckoo nest and its fitness.
- Step 2: Continuously update the cuckoo’s location within a preset number of cycles, combined with the cuckoo’s local and global search strategy. Once a better solution set is found, the corresponding nest is updated immediately, and the global fitness and optimal solution are retained.
- Step 3: At each generation, the current nests may be discarded with a specific probability, and new nests will be randomly generated to keep the total population unchanged.
- Step 4: Check whether the termination conditions are met. If not, repeat the loop consisting of Step 2 and Step 3. If yes, the loop is stopped, and the global optimal fitness value and corresponding solution are output.
| Algorithm1: CS+SVM parameters optimization |
| Input: Range of penalty coefficient C and RBF nuclear coefficient gamma to be searched Output: Result of adaptive hyperparameter combination 1 CS Parameters: 2 //Maximum number of iterations, population size, discovery probability, step size adjustment 3 Initialization: 4 //Total number of nests, number of iterations, discovery probability, dimension, step size 5 for t in Max_iterations do //t is the current iteration of the CS 6 for i in Np do //Np is the population size of the CS 7 Levy Flight Updates: 8 Regeneration of next generation population 9 Discovery probability: Reset abandoned nest 10 Population renewal: 11 Update hyperparameter combination [C, gamma] 12 return the hyperparameter combination with the highest score |
4. Experimental Results and Analysis
4.1. Experimental Description
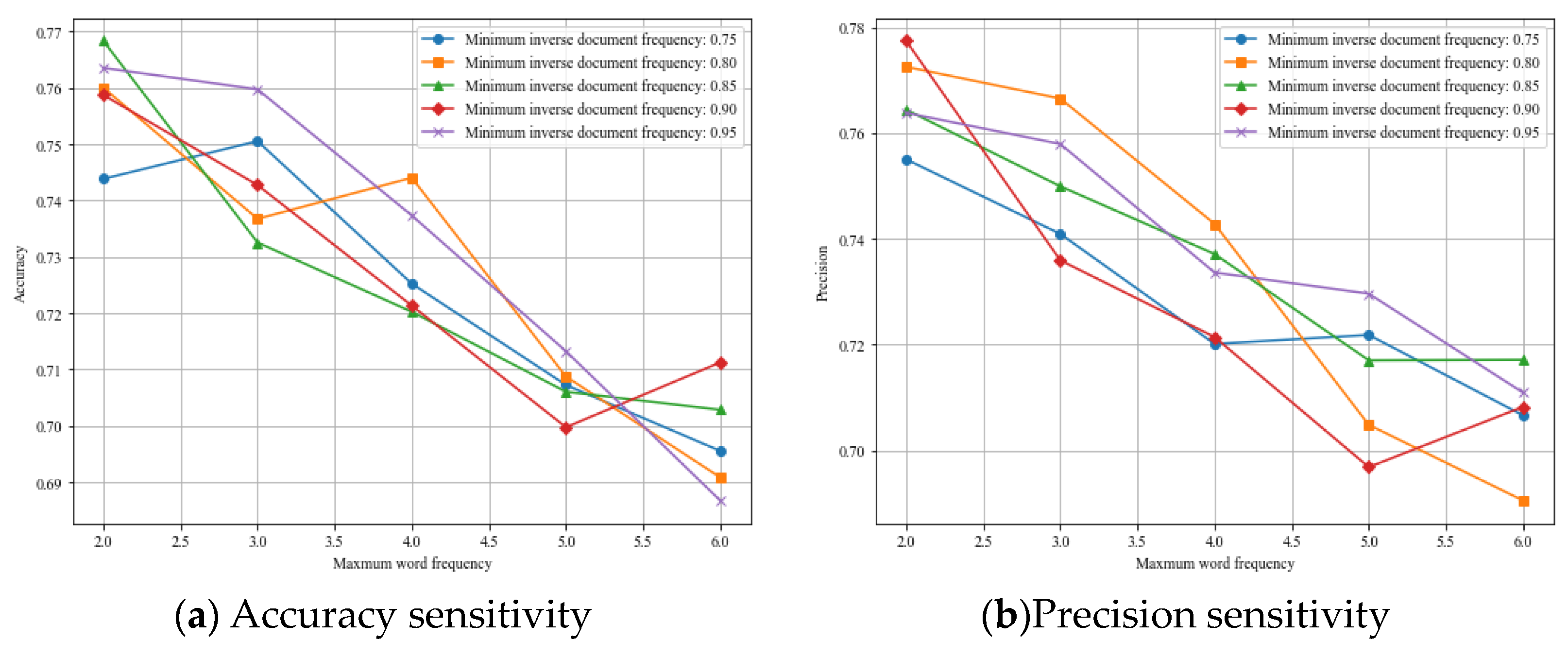
4.2. Experimental Results and Performance Analysis
4.3. Ablation Experiment
5. Discussion
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, L.; Zhang, Z. A nearly-linear time algorithm for minimizing risk of conflict in social networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2648–2656. [Google Scholar]
- Liu, X.; Ye, S.; Fiumara, G.; De Meo, P. Influence Nodes Identifying Method via Community-based Backward Generating Network Framework. IEEE Trans. Netw. Sci. Eng. 2024, 11, 236–253. [Google Scholar] [CrossRef]
- Hupkes, D.; Giulianelli, M.; Dankers, V.; Artetxe, M.; Elazar, Y.; Pimentel, T.; Christodoulopoulos, C.; Lasri, K.; Saphra, N.; Sinclair, A.; et al. A taxonomy and review of generalization research in NLP. Nat. Mach. Intell. 2023, 5, 1161–1174. [Google Scholar] [CrossRef]
- Wang, S.I.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL), Jeju, Republic of Korea, 8–14 July 2012; Volume 2, pp. 90–94. [Google Scholar]
- Malla, S.J.; Alphonse, P.J.A. COVID-19 outbreak: An ensemble pre-trained deep learning model for detecting informative tweets. Appl. Soft Comput. 2021, 107, 107495. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Chen, L.; Luo, R.; Zhu, J. A combination model based on multi-angle feature extraction and sentiment analysis: Application to EVS sales forecasting. Expert Syst. Appl. 2023, 224, 119986. [Google Scholar] [CrossRef]
- Liu, X.; Ye, S.; Fiumara, G.; De Meo, P. Information Propagation Prediction Based on Spatial–Temporal Attention and Heterogeneous Graph Convolutional Networks. IEEE Trans. Comput. Soc. Syst. 2024, 11, 945–958. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Qin, B.; Yang, N.; Liu, T.; Zhou, M. Sentiment embeddings with applications to sentiment analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 496–509. [Google Scholar] [CrossRef]
- Zhu, L.; Li, W.; Shi, Y.; Guo, K. SentiVec: Learning sentiment-context vector via kernel optimization function for sentiment analysis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2561–2572. [Google Scholar] [CrossRef] [PubMed]
- Forman, G. BNS feature scaling: An improved representation over tf-idf for svm text classification. In Proceedings of the 17th ACM conference on Information and knowledge management, Napa Valley, CA, USA, 26–30 October 2008; pp. 263–270. [Google Scholar]
- Hu, C.; Zhang, C.; Lei, D.; Wu, T.; Liu, X.; Zhu, L. Achieving privacy-preserving and verifiable support vector machine training in the cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3476–3491. [Google Scholar] [CrossRef]
- Luo, X. Efficient English text classification using selected machine learning techniques. Alex. Eng. J. 2021, 60, 3401–3409. [Google Scholar] [CrossRef]
- Marie-Sainte, S.L.; Alalyani, N. Firefly algorithm based feature selection for Arabic text classification. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 320–328. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A survey on text classification: From traditional to deep learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41. [Google Scholar] [CrossRef]
- Lin, Y.; Chen, S.; Liu, J.; Lin, C. Linear Classifier: An Often-Forgotten Baseline for Text Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 1876–1888. [Google Scholar]
- Zhang, J.; Zhang, Q.; Qin, X.; Sun, Y. A two-stage fault diagnosis methodology for rotating machinery combining optimized support vector data description and optimized support vector machine. Measurement 2022, 200, 111651. [Google Scholar] [CrossRef]
- Zhou, J.; Zhu, S.; Qiu, Y.; Armaghani, D.J.; Zhou, A.; Yong, W. Predicting tunnel squeezing using support vector machine optimized by whale optimization algorithm. Acta Geotech. 2022, 17, 1343–1366. [Google Scholar] [CrossRef]
- Ying, X.; Liu, L.; Wang, Y.; Li, R.; Chen, N.; Lin, Z.; Sheng, W.; Zhou, S. Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15528–15538. [Google Scholar]
- Wang, H.; Xu, Y.; Wang, Z.; Cai, Y.; Chen, L.; Li, Y. Centernet-auto: A multi-object visual detection algorithm for autonomous driving scenes based on improved centernet. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 742–752. [Google Scholar] [CrossRef]
- Du, M.; He, F.; Zou, N.; Tao, D.; Hu, X. Shortcut learning of large language models in natural language understanding. Commun. ACM 2023, 67, 110–120. [Google Scholar] [CrossRef]
- Kazmaier, J.; Van Vuuren, J.H. The power of ensemble learning in sentiment analysis. Expert Syst. Appl. 2022, 187, 115819. [Google Scholar] [CrossRef]
- Bountakas, P.; Xenakis, C. Helphed: Hybrid ensemble learning phishing email detection. J. Netw. Comput. Appl. 2023, 210, 103545. [Google Scholar] [CrossRef]
- Hartmann, J.; Heitmann, M.; Siebert, C.; Schamp, C. More than a feeling: Accuracy and application of sentiment analysis. Int. J. Res. Mark. 2023, 40, 75–87. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Zheng, J.; Wang, J.; Yuan, Y.; Lv, Z.; Wei, Y.; Han, Q.; Gao, J.; Liu, W. China’s public firms’ attitudes towards environmental protection based on sentiment analysis and random forest models. Sustainability 2022, 14, 5046. [Google Scholar] [CrossRef]
- Han, K.X.; Chien, W.; Chiu, C.C.; Cheng, Y.T. Application of support vector machine (SVM) in the sentiment analysis of twitter dataset. Appl. Sci. 2020, 10, 1125. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, B.; Liao, B.; Gabbay, D.M. A self-explanatory contrastive logical knowledge learning method for sentiment analysis. Knowl. Based Syst. 2023, 278, 110863. [Google Scholar] [CrossRef]
- Cam, H.; Cam, A.V.; Demirel, U.; Ahmed, S. Sentiment analysis of financial Twitter posts on Twitter with the machine learning classifiers. Heliyon 2024, 10, e23784. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yu, Z.; Cao, W.; Chen, C.L.P. Adaptive dense ensemble model for text classification. IEEE Trans. Cybern. 2022, 52, 7513–7526. [Google Scholar] [CrossRef] [PubMed]
- Zhou, K.; Yang, Y.; Qiao, Y.; Xiang, T. Domain adaptive ensemble learning. IEEE Trans. Image Process. 2021, 30, 8008–8018. [Google Scholar] [CrossRef] [PubMed]
- Alam, K.M.R.; Siddique, N.; Adeli, H. A dynamic ensemble learning algorithm for neural networks. Neural Comput. Appl. 2020, 32, 8675–8690. [Google Scholar] [CrossRef]
- Lee, K.; Laskin, M.; Srinivas, A.; Abbeel, P. Sunrise: A simple unified framework for ensemble learning in deep reinforcement learning. Proceedings of the International Conference on Machine Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6131–6141. [Google Scholar]
- Kaushik, M.; Sharma, R.; Peious, S.A.; Shahin, M.; Yahia, S.B.; Draheim, D. A systematic assessment of numerical association rule mining methods. SN Comput. Sci. 2021, 2, 348. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), IEEE, Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Chopra, N.; Ansari, M.M. Golden jackal optimization: A novel nature-inspired optimizer for engineering applications. Expert Syst. Appl. 2022, 198, 116924. [Google Scholar] [CrossRef]
- Cao, Z.C.; Lin, C.R.; Zhou, M.C. A knowledge-based cuckoo search algorithm to schedule a flexible job shop with sequencing flexibility. IEEE Trans. Autom. Sci. Eng. 2021, 18, 56–69. [Google Scholar] [CrossRef]
- She, B.; Fournier, A.; Yao, M.; Wang, Y.; Hu, G. A self-adaptive and gradient-based cuckoo search algorithm for global optimization. Appl. Soft Comput. 2022, 122, 108774. [Google Scholar] [CrossRef]
- Lin, C.R.; Cao, Z.C.; Zhou, M.C. Learning-based cuckoo search algorithm to schedule a flexible job shop with sequencing flexibility. IEEE Trans. Cybern. 2022, 53, 6663–6675. [Google Scholar] [CrossRef] [PubMed]
- Bello, A.; Ng, S.C.; Leung, M.F. A BERT framework to sentiment analysis of tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef] [PubMed]
- Im, S.K.; Chan, K.H. Neural Machine Translation with CARU-Embedding Layer and CARU-Gated Attention Layer. Mathematics 2024, 12, 997. [Google Scholar] [CrossRef]
- Chan, K.H.; Ke, W.; Im, S.K. CARU: A content-adaptive recurrent unit for the transition of hidden state in NLP. In Neural Information Processing: 27th International Conference, ICONIP 2020, Bangkok, Thailand, 23–27 November 2020; Proceedings, Part I 27; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 693–703. [Google Scholar]
- Darwish, A.; Hassanien, A.E.; Das, S. A survey of swarm and evolutionary computing approaches for deep learning. Artif. Intell. Rev. 2020, 53, 1767–1812. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Mohammad, S. Examining Gender and Race Bias in Two Hundred Sentiment Analysis Systems. arXiv 2018, arXiv:1805.04508. [Google Scholar]
- Liu, H.; Dacon, J.; Fan, W.; Liu, H.; Liu, Z.; Tang, J. Does gender matter? Towards fairness in dialogue systems. arXiv 2019, arXiv:1910.10486. [Google Scholar]
- Raza, S.; Reji, D.J.; Ding, C. Dbias: Detecting biases and ensuring fairness in news articles. Int. J. Data Sci. Anal. 2024, 17, 39–59. [Google Scholar] [CrossRef] [PubMed]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Chen, Y.; Mahoney, C.; Grasso, I.; Wali, E.; Matthews, A.; Middleton, T.; Njie, M.; Matthews, J. Gender bias and under-representation in natural language processing across human languages. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Virtual Event, 19–21 May 2021; pp. 24–34. [Google Scholar]
- Liu, X.; Gao, L.; Fiumara, G.; Meo, D.P. Key Node Identification Method Integrating Information Transmission Probability and Path Diversity in Complex Network. Comput. J. 2024, 67, 127–141. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, M.; Liu, Y.; Liu, C.; Li, C.; Wang Wei Zhang, X.; Bouyer, A. Semi-supervised Community Detection Method Based on Generative Adversarial Networks. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102008. [Google Scholar] [CrossRef]
- Almuzaini, A.A.; Singh, V.K. Balancing fairness and accuracy in sentiment detection using multiple black box models. In Proceedings of the 2nd International Workshop on Fairness, Accountability, Transparency and Ethics in Multimedia, Seattle, WA, USA, 20 October 2020; pp. 13–19. [Google Scholar]
- Khoo, L.S.; Bay, J.Q.; Yap, M.L.K.; Lim, M.K.; Chong, C.Y.; Yang, Z.; Lo, D. Exploring and repairing gender fairness violations in word embedding-based sentiment analysis model through adversarial patches. In Proceedings of the 2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, Taipa, Macao, 21–24 March 2023; pp. 651–662. [Google Scholar]
- Pastaltzidis, I.; Dimitriou, N.; Quezada-Tavarez, K.; Aidinlis, S.; Marquenie, T.; Gurzawska, A.; Tzovaras, D. Data augmentation for fairness-aware machine learning: Preventing algorithmic bias in law enforcement systems. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 2302–2314. [Google Scholar]
- Dwork, C. Differential Privacy. In Automata, Languages and Programming; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Liu, X.; Xiao, W.; Liu, C.; Wang, W.; Li, C. Meta Graph Network Recommendation Based on Multi-Behavior Encoding. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102050. [Google Scholar] [CrossRef]
- Ramírez, J.J.E.; Gomez, J.C. Evolutionary learning of selection hyper-heuristics for text classification. Appl. Soft Comput. 2023, 147, 110721. [Google Scholar] [CrossRef]
- Bryman, A. Social Research Methods; Oxford University Press: Oxford, UK, 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Task | #Cat | #Docs | Source |
|---|---|---|---|---|
| imdbs | Sentiment | 2 | 748 | https://bit.ly/3mGPBx4 |
| yelp | Sentiment | 2 | 1000 | https://bit.ly/3mGPBx4 |
| sen_pol | Sentiment | 2 | 10,662 | https://bit.ly/3Lbh3xf |
| amazon_cells | Sentiment | 2 | 1000 | https://bit.ly/3mGPBx4 |
| SST-2 | Sentiment | 2 | 9602 | https://www.kaggle.com/datasets/jkhanbk1/sst2-dataset |
| IMDBR | Sentiment | 2 | 50,000 | https://bit.ly/3ZUUUYd |
| Methods | Imdbs | Yelp | Sen_Pol | Amazon_Cells |
|---|---|---|---|---|
| LR | 0.7205 | 0.7782 | 0.7595 | 0.7895 |
| DT | 0.6277 | 0.7072 | 0.6002 | 0.7327 |
| RF | 0.6958 | 0.7618 | 0.6956 | 0.7785 |
| SVM | 0.7253 | 0.7820 | 0.7655 | 0.7958 |
| KNN | 0.6518 | 0.6453 | 0.5094 | 0.6502 |
| MNB | 0.7350 | 0.7675 | 0.7678 | 0.7873 |
| MLP | 0.7023 | 0.7513 | 0.7082 | 0.7683 |
| GBT | 0.7102 | 0.7610 | 0.6575 | 0.7832 |
| AdaECELM | 0.7683 | 0.8010 | 0.7732 | 0.8017 |
| Models | SST-2 | IMDBR | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | |
| SVM | 0.6220 | 0.6367 | 0.6214 | 0.6290 | 0.7731 | 0.7655 | 0.8114 | 0.7878 |
| ELM | 0.6420 | 0.6605 | 0.6698 | 0.6651 | 0.7760 | 0.7737 | 0.7694 | 0.7715 |
| ECELM | 0.6570 | 0.6498 | 0.7168 | 0.6817 | 0.7938 | 0.7931 | 0.7950 | 0.7940 |
| AdaECELM | 0.6880 | 0.6949 | 0.9379 | 0.7983 | 0.8180 | 0.8591 | 0.7979 | 0.8274 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.-Y.; Zhang, K.-Q.; Fiumara, G.; Meo, P.D.; Ficara, A. Adaptive Evolutionary Computing Ensemble Learning Model for Sentiment Analysis. Appl. Sci. 2024, 14, 6802. https://doi.org/10.3390/app14156802
Liu X-Y, Zhang K-Q, Fiumara G, Meo PD, Ficara A. Adaptive Evolutionary Computing Ensemble Learning Model for Sentiment Analysis. Applied Sciences. 2024; 14(15):6802. https://doi.org/10.3390/app14156802
Chicago/Turabian StyleLiu, Xiao-Yang, Kang-Qi Zhang, Giacomo Fiumara, Pasquale De Meo, and Annamaria Ficara. 2024. "Adaptive Evolutionary Computing Ensemble Learning Model for Sentiment Analysis" Applied Sciences 14, no. 15: 6802. https://doi.org/10.3390/app14156802