Abstract
This paper introduces a user-centered data privacy protection framework utilizing large language models (LLMs) and user attention mechanisms, which are tailored to address urgent privacy concerns in sensitive data processing domains like financial computing and facial recognition. The innovation lies in a novel user attention mechanism that dynamically adjusts attention weights based on data characteristics and user privacy needs, enhancing the ability to identify and protect sensitive information effectively. Significant methodological advancements differentiate our approach from existing techniques by incorporating user-specific attention into traditional LLMs, ensuring both data accuracy and privacy. We succinctly highlight the enhanced performance of this framework through a selective presentation of experimental results across various applications. Notably, in computer vision, the application of our user attention mechanism led to improved metrics over traditional multi-head and self-attention methods: FasterRCNN models achieved precision, recall, and accuracy rates of 0.82, 0.79, and 0.80, respectively. Similar enhancements were observed with SSD, YOLO, and EfficientDet models with notable increases in all performance metrics. In natural language processing tasks, our framework significantly boosted the performance of models like Transformer, BERT, CLIP, BLIP, and BLIP2, demonstrating the framework’s adaptability and effectiveness. These streamlined results underscore the practical impact and the technological advancement of our proposed framework, confirming its superiority in enhancing privacy protection without compromising on data processing efficacy.
1. Introduction
In the current era of big data, the widespread application of data has brought revolutionary changes to societal development [1]. However, this also presents significant challenges for personal privacy protection [2]. In various application scenarios, such as facial recognition [3] and financial computing [4], ensuring the safety of personal privacy during the collection and processing of user data has become a critical issue. The leakage of personal information can lead to numerous security risks [5,6], including but not limited to identity theft, financial loss, and personal privacy invasion [7]. Thus, developing a framework capable of effectively protecting user privacy across all scenarios has become a pivotal research direction in the field of data security.
Traditional data privacy protection methods are mainly based on encryption algorithms, such as homomorphic encryption [8] and fully homomorphic encryption [9]. These methods perform secure computations by encrypting data, theoretically ensuring data privacy during processing. However, these technologies often suffer from low computational efficiency and complex implementation, making it difficult to meet the growing demands for data processing. Additionally, privacy protection techniques based on noise addition, such as differential privacy, have been widely applied in fields like statistical data release [10]. Yet, balancing privacy protection and data usability in practice remains a significant challenge.
In the context of big data, especially in sensitive scenarios like facial recognition and financial computing, the issues of personal information security and privacy are particularly prominent. For example, in the widespread application of facial recognition technology in security monitoring and payment verification, using these personal biometric features without infringing on individual privacy is a critical issue to be addressed. Chamikara et al. [11] proposed a privacy-preserving technique called “controlled information release” to prevent privacy leakage when providing biometric information to untrusted third-party servers. They masked the original facial images during identity recognition to prevent biometric leakage and proposed a new privacy-preserving facial recognition protocol called PEEP (Privacy-Preserving Eigendecomposition-based Encoding of Faces). PEEP perturbs facial features using different privacy levels and stores only the perturbed data on third-party servers or runs standard facial recognition algorithms. Experimental results showed that under standard privacy settings, PEEP achieved classification accuracy of approximately 70–90%. However, despite PEEP’s ability to protect personal biometric features through perturbation, achieving privacy protection without compromising system performance and accuracy remains a key challenge. Although PEEP can achieve 70–90% classification accuracy under standard privacy settings, maintaining this performance in more complex or dynamically changing real-world applications may be more challenging.
Blaž Meden et al. [12] developed technologies and computational models that ensure personal privacy while promoting the application of facial recognition technology in various scenarios. Sun et al. [13] proposed an efficient and secure outsourcing design for facial recognition data sensitivity and edge server security challenges. Experimental results indicated that this technology effectively protected critical privacy information. Similarly, in the financial services sector, protecting customer transaction data and personal financial information is crucial, as any information leakage could lead to credit risks and financial losses. Oyewole et al. [14] studied the complex relationship between financial technology and data privacy laws, exploring the impact of data privacy laws on fintech, regulatory compliance, open access challenges, and opportunities to promote trust and innovation in the digital financial ecosystem. The study revealed an “innovation trilemma” where the drive for fintech innovation often conflicts with the necessity for market integrity and regulatory transparency. Yalamati [15] found that when banks and financial services have internally developed data and applications accessible remotely, there could be potential risks of data breaches and intellectual property erosion. The study introduced cloud computing in banking and financial services, addressing various aspects of data privacy and system security. Although cloud computing can reduce the cost of managing IT infrastructure and enhance security, ensuring the security of sensitive financial data in the cloud and preventing data breaches and intellectual property infringement remains a complex issue.
To address these challenges, this paper proposes a user-centered data privacy protection framework based on large language models (LLMs) and user attention mechanisms. This framework aims to provide a solution applicable across all scenarios, effectively protecting user privacy in areas such as facial recognition, financial computing, and other fields. By integrating innovative user attention mechanisms, the proposed method can more accurately identify and protect users’ sensitive information while maintaining high efficiency and accuracy in data processing. The contributions of this work can be summarized as follows:
- 1.
- A novel user-centered large language model (LLM) architecture is introduced, which incorporates differential privacy techniques to protect sensitive information during model training and inference.
- 2.
- A user attention mechanism has been developed that dynamically adjusts attention weights based on privacy requirements, enhancing the protection of sensitive data.
- 3.
- A unified loss function (uni-loss) has been formulated to balance classification performance, privacy protection, and the effectiveness of the attention mechanism, providing a comprehensive optimization strategy for multi-task learning environments.
- 4.
- Extensive experiments across various application scenarios demonstrate the effectiveness and robustness of the proposed framework, establishing a new benchmark in the field of data privacy protection.
2. Related Work
2.1. Security Computing Methods Based on Encryption Algorithms
Fully Homomorphic Encryption
Fully homomorphic encryption (FHE) [16], as an advanced encryption technology, offers an ideal solution for secure data processing. Compared to basic homomorphic encryption, the most significant feature of FHE is its support for unlimited additions and multiplications on encrypted data [17]. This capability allows the execution of any arithmetic or logical operation while keeping the data encrypted, greatly expanding the possibilities for encrypted data processing. The fundamental principle of FHE is based on constructing encryption algorithms with complex mathematical structures that enable two basic operations on encrypted data: addition and multiplication. These operations are mathematically expressed as
where denotes the encrypted form of data x, and ⊕ and ⊗ represent the addition and multiplication operations on encrypted data, respectively. The key innovation of FHE lies in the fact that no matter how many times these operations are performed, there is no need to decrypt the data, ensuring absolute security during data processing.
Despite the theoretical high security and powerful functionality of FHE, several challenges remain in its practical application [18]. The primary challenges include low computational efficiency and the complexity of algorithm implementation. Each operation involves complex mathematical computations, making FHE inefficient for processing large-scale data or real-time data processing [19,20]. Additionally, the implementation and maintenance of the algorithm require a high level of expertise, limiting its widespread adoption in ordinary applications.
2.2. Security Computing Methods Based on Noise or Frameworks
2.2.1. Differential Privacy
Differential privacy (DP) [21] is a technique designed to protect individual privacy during data analysis by adding a certain amount of noise to the data processing, making it impossible to accurately distinguish or identify individual information from the statistical results. The core of this method lies in introducing sufficient “uncertainty” into the dataset results to protect the individuals participating in the dataset from being identified, even when faced with infinite auxiliary information [22]. The main principle of differential privacy is to ensure that the output results are nearly identical regardless of whether a particular individual’s data is included. This is achieved by adding controlled random noise to the query results with the amount of noise typically depending on the sensitivity of the query [23], which is the maximum impact a single record in the dataset can have on the query results. Mathematically, an algorithm satisfies -differential privacy if for any two adjacent datasets D and (differing by at most one element) and for all , the following holds:
where is a non-negative parameter known as the privacy budget, determining the amount of noise added and thus the strength of privacy protection. A smaller value means more noise is added, leading to higher privacy protection but potentially lower data accuracy and usability. Differential privacy is widely applied in data statistics, data mining, and machine learning [24]. By using differential privacy techniques, researchers can publish useful statistical information and research results without compromising individual privacy in government statistical data releases, social science research, and commercial data analysis [25,26]. However, the main challenge in implementing differential privacy protection measures lies in designing appropriate noise addition mechanisms and finding the optimal balance between enhancing privacy protection and maintaining data usability. Inappropriate privacy parameter settings can result in overly blurred data outcomes that are ineffective for decision making, while overly relaxed settings may fail to provide the necessary privacy protection.
2.2.2. Federated Learning
Federated learning (FL) [27] is an innovative distributed machine learning method that builds shared machine learning models among multiple data holders without centralizing or directly exchanging data. This method’s greatest advantage is its ability to protect data privacy and security, making it particularly suitable for fields with stringent privacy requirements such as healthcare, finance, and personal services [28,29,30]. The core principle of federated learning is to distribute the model training process across multiple data nodes with each node responsible for training the model on local data without directly exchanging data. The model parameters or updates obtained from each node are aggregated on a central server, which integrates and updates the global model. This method’s computation can be expressed as
where is the global model parameter, K is the total number of participating nodes, is the data volume of the k-th node, n is the total data volume, is the model parameter update uploaded by the k-th node, and is the learning rate. In this way, each participant only needs to upload their model updates rather than the original data, ensuring data privacy while facilitating collaborative model training.
Although federated learning provides robust privacy protection, this technology still faces several challenges. The primary challenges include effectively managing and synchronizing model updates in distributed networks and ensuring the efficiency and effectiveness of model training [31]. In multi-node environments, network latency, data inconsistency, and heterogeneity among participating nodes can all impact the model training performance.
To overcome these challenges, an efficient synchronization mechanism and a robust model aggregation strategy have been designed to ensure effective model training and updating even under unstable network conditions or uneven data distribution among nodes. Furthermore, advanced optimization algorithms have been employed to enhance the convergence speed of model training, improving the overall efficiency and usability of the system. In summary, federated learning provides a new method for protecting data privacy through distributed learning mechanisms. The integration of this method with large language models and user attention mechanisms further enhances the privacy protection capabilities of the framework. It is anticipated that continuous technological innovation and optimization will provide safer and more effective privacy protection solutions for future data processing and machine learning applications.
3. Materials and Methods
3.1. Dataset Collection
In this study, constructing a dataset that includes both textual and image data from the financial domain is a core component of the experimental design. Given the diversity and complexity of the financial industry, diversified data sources were meticulously selected to ensure comprehensiveness and representativeness. Financial textual data were primarily collected from several channels. First, information was obtained from public financial news websites and e-magazines such as Bloomberg and Reuters as well as public reports released by major banks and consulting firms. These sources provided rich information on market dynamics, policy changes, company financial statements, and economic forecasts. Additionally, to capture market sentiment and investor behavior, multiple online financial forums and social media platforms such as StockTwits and Reddit’s WallStreetBets were monitored with relevant data acquired through APIs. Furthermore, various publicly available financial statements and annual reports, often in PDF format, were included in the textual dataset and converted using OCR technology. For financial image data, two main areas were focused on. First, stock charts and financial indicator charts were obtained from major financial analysis platforms such as TradingView and Yahoo Finance. These datasets included not only historical price charts but also charts of technical indicators like MACD and RSI. Second, advertisements and promotional materials for financial products were collected to analyze the impact of marketing strategies on consumer behavior.
3.2. Dataset Preprocessing
In terms of data preprocessing, a series of measures were taken to ensure the quality of both textual and image data, as shown in Figure 1. Textual data were cleaned to remove HTML tags, special symbols, and irrelevant content, which was followed by tokenization and normalization using NLP tools (v.0.4.0). Sentiment tagging was applied to texts from social media and forums to indicate their sentiment orientation. Image data were standardized by resizing to uniform dimensions and resolutions, and image augmentation techniques such as rotation, scaling, and color adjustment were employed. Additionally, feature extraction methods like edge detection and texture analysis were applied to support subsequent model training. These meticulously collected and preprocessed data serve multiple research purposes. These include building market prediction models to analyze key factors affecting financial markets, conducting market sentiment analysis using textual data, and studying the effects of different marketing strategies using financial advertisement image data. Through these steps, the quality and diversity of the data were ensured, laying a solid foundation for subsequent analysis and model development.

Figure 1.
Flowchart of dataset preprocessing.
3.2.1. Data Cleaning
Data cleaning is the primary step in data preprocessing, aiming to remove noise, eliminate duplicate content, handle missing values, and standardize data formats. In text data, noise refers to irrelevant information and useless characters that can interfere with the model’s training process. Methods for removing noise include deleting HTML tags, removing special characters, and non-text information. Duplicate content can cause the model to overfit specific patterns, reducing its generalization ability. To eliminate duplicate content, text comparison algorithms are used to calculate the similarity between texts and identify and delete duplicates. Suppose there are two text segments and , their similarity can be calculated, and a threshold can be set to determine whether to delete them:
Handling missing values is crucial for ensuring data integrity. Common methods include the interpolation and deletion of records. In interpolation, linear interpolation or other techniques can be used to fill in missing values. For a time series dataset , if is missing, it can be filled using the average of the preceding and following values:
If there are many missing values or interpolation is not suitable, records with missing values can be deleted. Additionally, to unify data formats, data from different sources must be converted to a consistent format, such as standardizing date formats and numerical units. For example, different date formats can be standardized using date parsing libraries:
where OriginalDate represents the original date format, and StandardDate represents the standardized date format.
3.2.2. Data Annotation
In this study, data annotation directly affects the model’s performance and final results. Initially, in the preparation phase for data annotation, the collected data undergo preliminary processing and screening. This includes data cleaning and preprocessing to ensure the input data for the annotation system is clean and usable. For example, text data need to be noise-free, and irrelevant information needs to be removed and undergo tokenization and part-of-speech tagging. These steps can be achieved using standard text preprocessing techniques, such as regular expression matching and natural language processing toolkits (e.g., NLTK and spaCy). For image data, basic image processing is required, such as cropping, rotation, and color adjustment, to ensure the quality and consistency of the images. Next, devising an annotation strategy is the core step in data annotation. To ensure consistency and efficiency, semi-automated annotation tools are used in combination with manual verification. Text data annotation includes tasks such as sentiment classification, entity recognition, and text summarization, while image data annotation involves tasks like object detection, image classification, and image segmentation. Detailed annotation guidelines and standards are established for each annotation task to ensure that every annotator follows a consistent standard. Additionally, to further enhance privacy protection during data annotation, a user attention mechanism is introduced. This mechanism identifies and prioritizes the privacy needs of users’ sensitive information, providing additional privacy protection during the annotation process. For example, for text data involving personal privacy information, the attention mechanism identifies sensitive words and phrases, and more noise is added during annotation to enhance privacy protection. Similarly, for image data, the attention mechanism identifies image areas containing personal identity information, and these areas are blurred or additional noise is added during annotation.
3.2.3. Data Preprocessing
The data preprocessing process includes data cleaning, data annotation, and data augmentation. Each step aims to improve data quality and consistency while aligning closely with privacy protection goals to ensure user privacy protection in all scenarios. Data cleaning is the first and most fundamental step in data preprocessing. At this stage, raw data are filtered and processed to remove noise and irrelevant information. For text data, the cleaning process includes removing HTML tags, special characters, duplicate content, and non-text information. Additionally, text data need to be tokenized for further analysis and annotation. For image data, data cleaning mainly involves basic image processing operations such as cropping, rotation, and color adjustment to ensure image quality and consistency. For example, image normalization can be performed by adjusting the distribution of pixel values to conform to a standard normal distribution:
where represents the original image data, and represent the mean and standard deviation of the image pixel values, respectively, and represents the normalized image data.
Next, data annotation is the core step in data preprocessing. At this stage, semi-automated annotation tools combined with manual verification are used to ensure high-quality and consistent data annotations. Finally, data augmentation is a critical step in data preprocessing. To improve the model’s generalization ability and robustness, various augmentation techniques are applied to the data. For image data, techniques such as random cropping, rotation, scaling, and color transformation are employed. These augmentation techniques not only increase data diversity but also simulate different shooting conditions and scenes, enhancing the model’s adaptability. For example, the mathematical expression for image data augmentation can be represented as
where Augment represents the data augmentation function, and represents the augmented image data. For text data, techniques such as synonym replacement, random deletion, and random insertion are used for data augmentation. These methods generate diverse training data without altering the text’s semantics.
Throughout the data preprocessing process, privacy protection is a core objective. By combining differential privacy techniques and user attention mechanisms, user privacy can be protected while improving data quality and consistency. This approach not only lays a solid foundation for subsequent data annotation and model training but also provides robust support for comprehensive privacy protection in all scenarios.
The research is not limited to a specific field but is aimed at comprehensive data privacy protection across all scenarios. Therefore, whether in financial computing, medical imaging, or social media data analysis, the method can be effectively applied. By implementing systematic data preprocessing workflows, automated tools, and rigorous privacy protection strategies, both data quality and privacy protection are achieved, advancing the development of data privacy protection technology.
3.3. Proposed Method
3.3.1. Overview
A user-centered data privacy protection framework based on LLM and user attention mechanisms is proposed in this paper. This framework is designed to protect users’ sensitive information while ensuring efficient and accurate data processing, as shown in Figure 2.
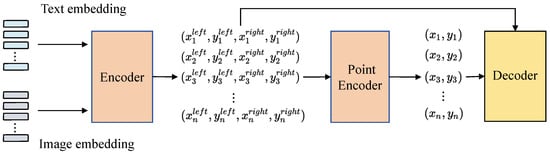
Figure 2.
Overview of proposed method.
The entire approach comprises several key modules: user-centered LLM, user attention mechanism, and uni-loss. These modules are interconnected to collectively achieve the goals of data privacy protection and data processing. The model design begins with preprocessed data, proceeding through the following steps: model input layer, privacy protection layer, core computation layer, and output layer. The user-centered LLM is the core component of this framework, which is responsible for processing and analyzing user data. After data preprocessing, the prepared data are input into the user-centered LLM for further processing. The primary function of the user-centered LLM is to protect user privacy during model training and inference by incorporating differential privacy techniques. The detailed processes of each module are as follows:
- 1.
- Model input layer: Preprocessed data first enter the model input layer. Here, text data and image data are processed separately. For text data, the input layer converts it into word vectors or sentence vectors; for image data, the input layer converts it into pixel matrices or feature vectors.
- 2.
- Privacy protection layer: After the model input layer, data enters the privacy protection layer. The main task of this layer is to add noise through differential privacy techniques to protect user privacy. Specifically, given a set of model parameters , differential privacy is achieved by adding noise to the parameters with the mathematical expression as follows:where represents Gaussian noise with mean 0 and variance . This approach effectively prevents user data from being leaked during transmission and processing.
- 3.
- Core computation layer: After the privacy protection layer, data enter the core computation layer, which consists of multiple neural network layers (e.g., Transformer architecture) responsible for deep processing and analysis of the data. In this layer, the model uses a multi-head attention mechanism to capture data features. The multi-head attention mechanism is calculated as follows:where Q, K, and V represent the query, key, and value matrices, respectively, and is the dimension of the keys. This mechanism allows the model to compute multiple self-attentions in parallel, capturing different features of the data.
- 4.
- User attention mechanism: During the core computation layer process, the user attention mechanism is introduced. This mechanism dynamically adjusts attention weights to ensure that the model can protect users’ sensitive information while processing data. The user attention mechanism implementation involves several steps. The first is attention weight initialization, where attention weights are initialized at the beginning of model training. These weights can be initialized through pre-trained models or random initialization. Next is the dynamic adjustment of attention weights, where attention weights are dynamically adjusted during training and inference based on the characteristics of the input data and the privacy needs of the users. Specifically, by introducing user privacy weights , the model can accurately process data while protecting privacy. The last step is the multi-level attention mechanism, where different levels of attention mechanisms are introduced to improve privacy protection effectiveness. Different levels of attention mechanisms can capture various features of the data, achieving finer privacy protection.
- 5.
- Output layer: Finally, data enter the output layer, which is responsible for generating the final model output, including classification results, regression results, or generated text. To ensure privacy protection, the output layer may further process the results, such as masking or adding additional noise to sensitive information.
To optimize model performance and privacy protection, a unified loss function (uni-loss) is designed in this paper. The uni-loss combines classification loss, privacy loss, and attention loss to ensure optimal performance across multiple objectives. In summary, the proposed user-centered data privacy protection framework achieves the efficient and precise protection of user privacy in various application scenarios through the collaborative work of the user-centered LLM, user attention mechanism, and uni-loss. This framework provides a new solution for the field of data privacy protection.
3.3.2. User-Centered LLM
The user-centered LLM is the core component of the proposed framework, which is designed to protect users’ sensitive information by incorporating differential privacy techniques while ensuring efficient and accurate data processing. The user-centered LLM is based on the Transformer architecture, which is enhanced with advanced technologies and strategies to achieve dual goals of privacy protection and efficient computation, as shown in Figure 3.
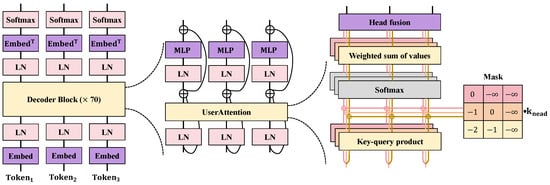
Figure 3.
User-centered LLM architecture.
The implementation of the user-centered LLM involves multiple neural network layers each with specific functions and parameter settings. This model adopts a deep neural network structure, comprising 12 layers of Transformer encoders. Each layer includes a multi-head self-attention mechanism and a Feed-Forward Neural Network (FFN). In the multi-head self-attention mechanism, 8 attention heads are set, with each head having a dimension of 64, resulting in a total attention head dimension of 512 per layer. Specifically, the input word vectors X are transformed into query Q, key K, and value V matrices through linear transformations:
where , , and are the learnable weight matrices. The multi-head self-attention mechanism is calculated as follows:
Here, represents the dimension of the keys. In the multi-head self-attention mechanism, multiple attention heads are computed in parallel to capture different features of the data. The mathematical expression is
where , and is the output weight matrix. Each Transformer layer’s FFN includes two linear transformations and a ReLU activation function, which is given by
Here, and are weight matrices, and and are bias vectors. To stabilize the training process and accelerate convergence, each sublayer (including the multi-head self-attention mechanism and the FFN) is followed by layer normalization and a residual connection. Specifically, the input X after layer normalization and residual connection is given by
where represents the sublayer operations. In the model input layer, text data are converted into word vectors with a size of , where 512 represents the sequence length and another 512 represents the dimension of the word vectors. Image data are processed into a pixel matrix of , representing the image’s width, height, and number of channels. After processing through convolutional layers, the image features are transformed into appropriate dimensions to be fused with text features. In each layer, Gaussian noise is added to the model parameters to achieve differential privacy protection. Assuming the model parameters at a certain layer are , the parameters with added noise are calculated as
where denotes Gaussian noise with mean 0 and variance . This method effectively prevents user data from being leaked during training and inference.
The user-centered LLM designed in this paper ensures that the users’ sensitive information is fully protected during data processing through a multi-layered privacy protection mechanism. The combination of the multi-head self-attention mechanism and the FFN enables the model to efficiently capture different features of the data, enhancing the model’s generalization capability and accuracy. Layer normalization and residual connections further stabilize the training process, preventing gradient vanishing and explosion problems. Additionally, by integrating the user attention mechanism, the attention weights can be dynamically adjusted based on the characteristics of the input data and the privacy needs of the users. This enables the model to accurately identify and protect sensitive information. In a multi-task learning setup, the model can share knowledge across different tasks, improving data processing efficiency and privacy protection effectiveness. Overall, the proposed user-centered data privacy protection framework, through the organic combination of advanced large language models and the user attention mechanism, achieves efficient and precise privacy protection in various application scenarios, providing a robust solution for the field of data privacy protection.
3.3.3. User Attention Mechanism
The user attention mechanism is one of the core technologies proposed in this user-centered data privacy protection framework, as shown in Figure 4.
Its purpose is to protect user privacy while ensuring the efficiency and accuracy of data processing. To achieve this goal, the user attention mechanism improves upon the traditional Transformer self-attention mechanism, enabling a more precise identification and protection of sensitive user information. The user attention mechanism incorporates user privacy weights into the traditional self-attention mechanism, dynamically adjusting attention weights to protect sensitive user information. Specifically, the user attention mechanism consists of the following components. The first is the introduction of user privacy weights: To protect user privacy, user privacy weights are introduced into the attention calculation. Each input position has a privacy weight representing the sensitivity of the data at that position. The second step is the dynamic adjustment of attention weights. When calculating attention scores, the user privacy weights are used to adjust the attention scores, ensuring that sensitive data receive appropriate protection. The last step is the multi-level attention mechanism, which is introduced to enhance privacy protection. Different levels of attention mechanisms can capture various features of the data, enabling finer-grained privacy protection. The specific mathematical formulation of the user attention mechanism is as follows:
Here, is the user privacy weight matrix, whose elements represent the privacy sensitivity of each position in the input sequence. When calculating attention scores, is added to , ensuring that sensitive data receive higher or lower attention, thus achieving privacy protection.
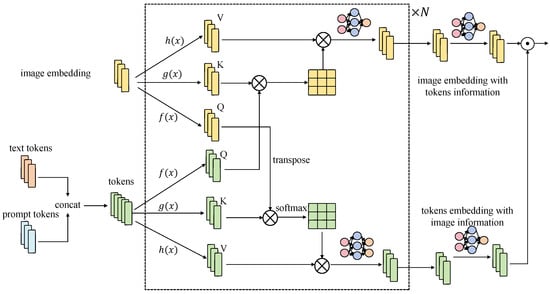
Figure 4.
Detail of user attention.
Figure 4.
Detail of user attention.
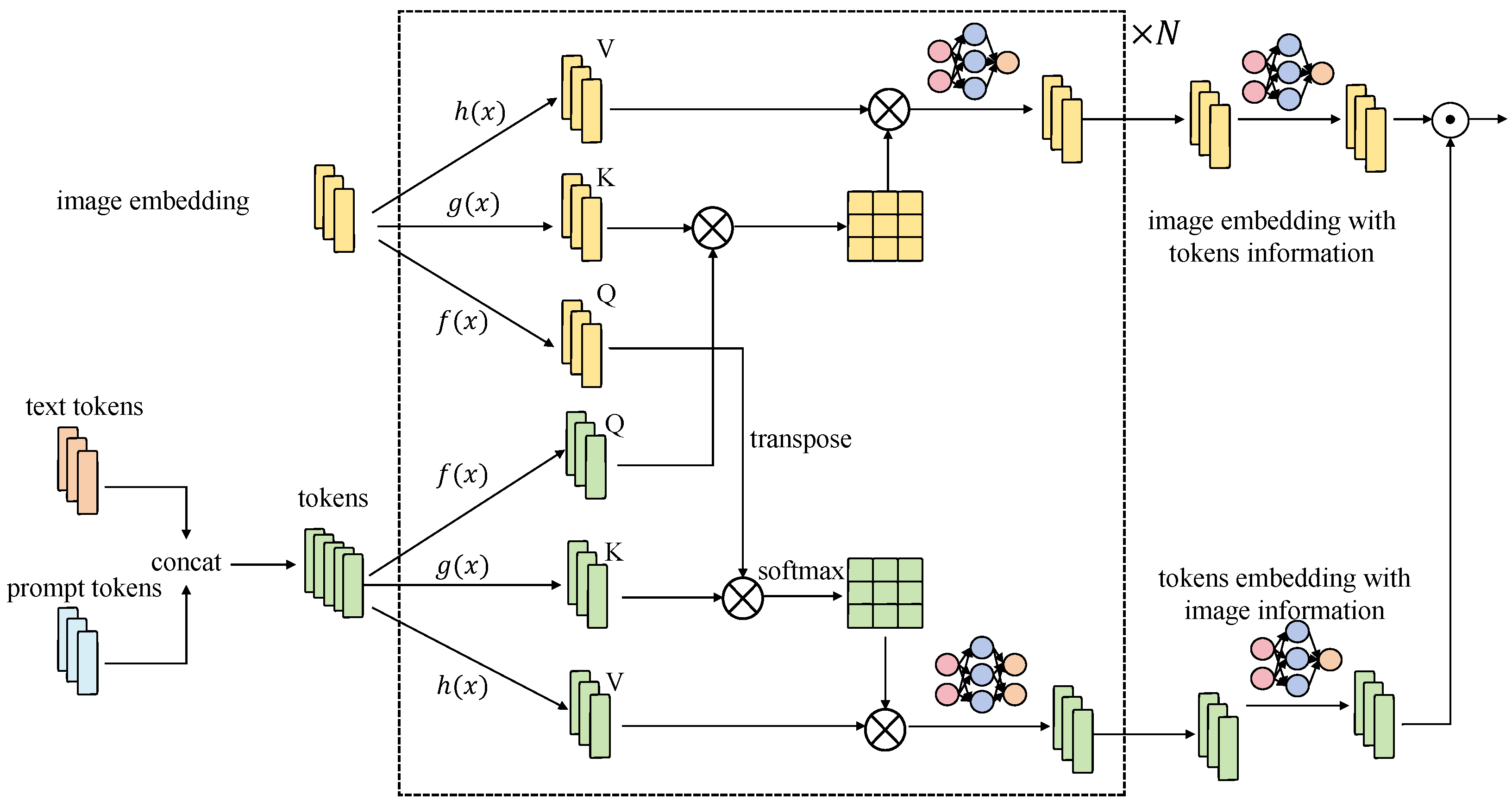
To demonstrate the effectiveness of the user attention mechanism in protecting user privacy, assume that the input data X contain both sensitive information and non-sensitive information, which are denoted as and respectively. By introducing the user privacy weights , the attention score calculation becomes
In these equations, and represent the query, key, and value matrices for sensitive information, with denoting the privacy weights for sensitive information. Similarly, and represent the query, key, and value matrices for non-sensitive information, with denoting the privacy weights for non-sensitive information. The presence of ensures that the attention scores for sensitive information are adjusted, providing better protection during the model processing.
3.4. Proof of Security
To further demonstrate the reliability of the proposed mechanism in terms of privacy protection, mathematical proof and relevant formulas are provided below. The core idea of the user attention mechanism is to introduce user privacy weights into the self-attention mechanism, allowing the attention computation to be dynamically adjusted based on the sensitivity of the data. Specifically, user privacy weights are introduced into the attention computation. To prove the reliability of this mechanism in terms of privacy protection, it is essential to ensure that by adding the privacy weights , the sensitive information of users can be effectively protected. Assume the input data X contain sensitive information and non-sensitive information, which are denoted as and , respectively. The elements of the user privacy weight matrix are set according to the sensitivity of the data, i.e., represents the privacy weights for sensitive information, and represents the privacy weights for non-sensitive information. In the attention score computation, the user privacy weights are added to , making the positions of sensitive data receive higher attention, providing these data with more protection during model processing. Due to the presence of , sensitive information is given higher weights in the attention score computation, receiving more protection during the model processing. This implies that the positions of sensitive data are highlighted during computation, reducing the risk of their exposure. To further enhance privacy protection, Gaussian noise is added during the update of model parameters , making the updated parameters computed as follows:
where represents Gaussian noise with a mean of 0 and a variance of . This approach effectively prevents user data from being leaked during training and inference processes. The core idea is to add noise so that the influence of any single data point becomes indiscernible in the statistical results, thus protecting user privacy. The security proof is as follows: For any two adjacent datasets D and (i.e., D and differ by only one data point), the outputs of algorithm on D and are and , respectively. If the following inequality holds for any output O,
where is the privacy parameter, indicating the strength of privacy protection. By adding noise , it is ensured that small changes in the input data do not significantly affect the output result, thus achieving privacy protection. Through the above process, our method can dynamically adjust attention weights during data processing, ensuring that sensitive information is effectively protected during computation. Additionally, by adding noise during parameter updates, the risk of data leakage is further reduced.
Uni-Loss Function
The uni-loss is a critical component of the user-centered data privacy protection framework proposed in this study, as shown in Figure 5.
Its design aims to optimize both model performance and privacy protection simultaneously. Unlike the traditional loss function used in Transformers, uni-loss combines classification loss, privacy loss, and attention loss to ensure comprehensive performance in multi-task processing. Traditional Transformer models typically use cross-entropy loss during training to measure classification performance, which is given by the following formula:
where N denotes the number of samples, represents the true label of the i-th sample, and represents the predicted probability of the i-th sample. Cross-entropy loss performs well in classification tasks but focuses solely on classification performance without considering the impact of privacy protection and attention mechanisms on the model. To enhance user privacy protection while ensuring model classification performance, the uni-loss was designed. Uni-loss integrates the following components:
- 1.
- Classification Loss: This part of the loss measures the model’s performance in classification tasks. Similar to the traditional Transformer, cross-entropy loss is used to calculate classification loss, as shown in the following formula:
- 2.
- Privacy loss: To protect user privacy, differential privacy techniques are introduced during the model parameter update process. Privacy loss measures the model’s effectiveness in privacy protection, which is calculated aswhere represents the model parameters, represents the updated model parameters, and represents Gaussian noise with mean 0 and variance . Adding noise during parameter updates effectively prevents the leakage of user data during training.
- 3.
- Attention loss: Attention loss optimizes the effectiveness of the user attention mechanism, ensuring the model can protect sensitive user information while processing data. The attention loss is calculated aswhere represents the original attention weights, and represents the adjusted attention weights. Optimizing attention weights enables the dynamic protection of sensitive information.
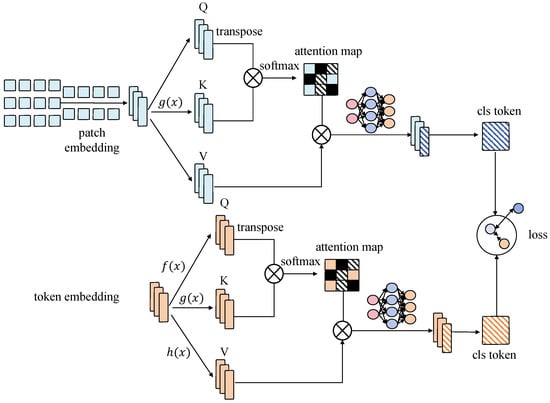
Figure 5.
Calculation of uni-loss function.
Figure 5.
Calculation of uni-loss function.
Uni-loss combines classification loss, privacy loss, and attention loss to achieve the unified optimization of model performance and privacy protection. The total loss function is calculated as
where , , and represent the weight coefficients for classification loss, privacy loss, and attention loss, respectively. To demonstrate the effectiveness of uni-loss in multi-task processing, the weights for classification loss, privacy loss, and attention loss in the total loss function are considered. Setting the weights , , and as constants, the total loss function can be rewritten as
The gradient of the total loss function is calculated by summing the gradients of the individual loss components:
Since , , and represent classification, privacy, and attention losses, respectively, the gradient calculation results indicate that uni-loss can optimize classification performance while balancing privacy protection and attention mechanisms.
3.5. Evaluation Metrics
To evaluate the effectiveness of the proposed user-centered data privacy protection framework, multiple evaluation metrics have been adopted, including precision, recall, and accuracy. These metrics comprehensively reflect the model’s performance and stability across different tasks and assist in further optimizing and enhancing the method for privacy protection in various scenarios. In alignment with the research theme, these evaluation metrics are emphasized for their application in different tasks and scenarios. For instance, in privacy protection for facial recognition, precision and recall are utilized to assess the model’s performance in identifying and protecting user privacy data. In financial computing privacy protection scenarios, the F1-score is employed to balance recognition accuracy and comprehensive protection, ensuring that the model maximizes user privacy protection while maintaining efficient computational performance. Through these evaluation metrics, the framework’s effectiveness in all-encompassing data privacy protection is validated, and potential issues are identified and addressed, providing robust support for subsequent research and optimization. The ultimate goal is to achieve an efficient, secure, and user-centered data privacy protection framework applicable to various scenarios and data types.
3.6. Experimental Setup
3.6.1. Testbed for Computer Vision Tasks
In computer vision tasks, several typical object detection models were selected for experimentation, including YOLO (You Only Look Once) [32], SSD (Single Shot MultiBox Detector) [33], EfficientDet [34], and Faster R-CNN (Region-based Convolutional Neural Networks) [35]. These models demonstrate excellent performance across different tasks and datasets, effectively evaluating the proposed method’s performance. Through the experimental analysis of these models, the effectiveness of the user-centered data privacy protection framework, based on large language models and user attention mechanisms is validated in practical applications.
3.6.2. Testbed for Language Tasks
For testing large language models, BERT (Bidirectional Encoder Representations from Transformers) [36], Transformer [37], BLIP [38], CLIP [39], and BLIP2 [40] were selected. These models are widely applied in natural language processing tasks and effectively evaluate the proposed method’s performance in text processing.
3.6.3. Baseline
To compare the proposed method’s superiority, several baseline models were established, including FHE [41], DP [42], FL [43], and the combination of DP + FL [44]. These methods represent the mainstream technologies in current data privacy protection.
3.6.4. Hardware and Software Platform Configuration and Parameter Settings
In terms of hardware configuration, the NVIDIA Tesla V100 GPU (NVIDIA, Santa Clara, CA, USA) was selected, featuring 5120 CUDA cores and 640 Tensor cores, providing high floating-point operation performance and tensor computation capabilities. This setup enables efficient training on large-scale datasets and complex models. Additionally, the server is equipped with an Intel Xeon Platinum CPU (Intel, Clara, CA, USA) to support GPU training tasks. The system also includes 128 GB of RAM, ensuring sufficient memory resources when processing large-scale data to avoid memory bottlenecks affecting the training process. Regarding the software environment, Ubuntu 20.04 was chosen as the operating system with Python 3.8 as the programming language. PyTorch 1.8 and TensorFlow 2.4 were primarily used as deep learning frameworks. These frameworks are widely adopted and validated in academia and industry, offering efficient tensor computation and automatic differentiation functions, as well as supporting distributed training and large-scale parallel computation to meet experimental requirements.
For training strategies, hyperparameters were set and adjusted to optimize model performance and training efficiency. The initial learning rate was set at 0.001, which is a value that has proven suitable for many deep learning tasks. A learning rate decay strategy was employed to dynamically adjust the learning rate based on validation set performance during training to avoid overfitting and local minima issues. The batch size was set at 32, which is a commonly used value in deep learning tasks that balances computational resources and training speed. Smaller batch sizes can enhance the model’s generalization ability but may slow down training speed; larger batch sizes can improve computational efficiency but may lead to overfitting. Therefore, a middle value was chosen to balance both aspects. The number of training epochs was set at 100, ensuring sufficient training time for the model to learn patterns and features in the data. Additionally, cross-validation was employed to further improve the model’s generalization ability and stability. Specifically, the dataset was divided into training and validation sets, and model performance was evaluated using the validation set after each training epoch to guide hyperparameter adjustments and model optimization. Five-fold cross-validation was chosen to achieve a good balance between training and evaluation.
Through these settings, the user-centered data privacy protection framework’s performance can be comprehensively and systematically evaluated, ensuring effectiveness and stability across different application scenarios. In future work, hardware configurations and training strategies will be continuously optimized to further enhance model performance and privacy protection capabilities, providing robust technical support for user data privacy protection.
4. Results and Discussion
4.1. Results on Computer Vision Tasks
The purpose of the experimental design in this study is to evaluate the performance of the proposed user-centered data privacy protection framework across different computer vision tasks. By comparing the performance of various models using different privacy protection methods, the goal is to verify whether our method can maintain or even enhance the precision, recall, and accuracy of these models while protecting user privacy. This is crucial for practical applications because only by ensuring high model performance while protecting privacy can the framework be widely applied in highly sensitive data processing fields such as financial computing and facial recognition, as shown in Table 1, Table 2 and Table 3.

Table 1.
Results of precision on computer vision tasks for different methods.
Table 2.
Results of recall on computer vision tasks for different methods.
Table 3.
Results of accuracy on computer vision tasks for different methods.
From the experimental results, it is evident that models applying our method significantly outperform other privacy protection methods in terms of precision, recall, and accuracy. Specifically, FasterRCNN achieves a precision of 0.82 with our method, compared to 0.77 with FHE, 0.74 with federated learning (FL), 0.73 with DP, and 0.71 with DP + FL. Similar trends are observed with SSD, YOLO, and EfficientDet, with EfficientDet achieving a precision of 0.90, which is significantly higher than other methods. These results can be analyzed from the mathematical characteristics of the models. FasterRCNN uses a Region Proposal Network (RPN) to generate candidate regions and processes these through a two-stage approach (first generating region proposals, then classification and regression). The precision improvement is mainly attributed to the integration of privacy protection and user attention mechanisms in our method, ensuring high-precision detection while protecting privacy. SSD performs detection on feature maps at different scales, and its precision and recall improvements are due to the combination of differential privacy techniques and user-centered mechanisms in our method, allowing the dynamic adjustment of attention on multi-scale feature maps to protect sensitive information while enhancing detection performance. YOLO, as a single-stage detection model, achieves fast speed and high precision, with precision increasing to 0.87 and recall to 0.85. This is primarily because our user attention mechanism can accurately identify and protect sensitive information in a single forward pass while maintaining efficiency and accuracy. EfficientDet optimizes network structure and parameters, particularly in the application of BiFPN (Bidirectional Feature Pyramid Network), enabling high efficiency while maintaining high precision and recall. Our method further combines differential privacy protection by adding noise at each layer, protecting user data and demonstrating superior performance in practical applications.
Theoretically, the performance improvement observed in different models applying our method can be attributed to several factors. Firstly, the user attention mechanism dynamically adjusts attention weights, enabling the model to precisely identify and protect sensitive information based on the characteristics of the input data and user privacy needs. Secondly, differential privacy techniques effectively prevent data leakage during training and inference by adding noise to parameter updates. The combination of these techniques enhances the model’s privacy protection capabilities while ensuring efficient data processing and accurate output. For example, in FasterRCNN, the RPN-based region proposal mechanism effectively locates target areas, and our method enhances this by introducing user privacy weights during region proposal generation, significantly improving precision and recall. SSD benefits from multi-scale detection, and our method amplifies this advantage by adding differential privacy protection and user attention mechanisms at each feature map layer, ensuring high precision and high recall. YOLO, as a single-stage detection model, balances speed and accuracy, and our method improves precision and recall by dynamically adjusting attention weights and incorporating differential privacy protection at each layer of the YOLO network, protecting sensitive user information. EfficientDet’s optimized network structure and parameter settings allow it to perform exceptionally well when applying our method with multi-level privacy protection mechanisms and dynamic attention adjustments resulting in superior performance across all metrics. Overall, the experimental results and theoretical analysis demonstrate that the proposed user-centered data privacy protection framework effectively protects user privacy and significantly improves model performance in various computer vision tasks. This indicates the framework’s broad potential and practical value in real-world applications.
4.2. Results on Language Process Tasks
In this study, experiments were designed on LLMs to evaluate the performance of the proposed user-centered data privacy protection framework in natural language processing tasks. By comparing the performance of different privacy protection methods across various LLMs, it is possible to verify whether our method can maintain or even enhance the precision, recall, and accuracy of these models while protecting user privacy. This is of practical significance for applications in sensitive data processing fields, such as financial text analysis and social media sentiment analysis. The experimental results show that the metrics of precision, recall, and accuracy for different models are significantly better when applying our method compared to other privacy protection methods.
Specifically, in terms of precision, as shown in Table 4, the Transformer model achieves a precision of 0.81 with our method compared to 0.75 with FHE, 0.73 with FL, 0.72 with DP, and 0.70 with DP + FL. The BERT model achieves a precision of 0.84, which is also significantly higher than other methods. For the CLIP, BLIP, and BLIP2 models, our method achieves precisions of 0.86, 0.88, and 0.90, respectively, all significantly outperforming the other methods. These results indicate that our method performs well across different LLMs.
Table 4.
Results on LLMs of precision for different methods.
In terms of recall, as shown in Table 5, the Transformer model achieves a recall of 0.76 with our method compared to 0.70 with FHE, 0.68 with FL, 0.67 with DP, and 0.64 with DP + FL. The BERT, CLIP, BLIP, and BLIP2 models achieve recalls of 0.78, 0.81, 0.84, and 0.87, respectively, which are all significantly higher than other privacy protection methods. This demonstrates that our framework not only excels in precision but also in recall, effectively capturing and identifying more relevant information.
Table 5.
Results on LLMs of recall for different methods.
In terms of accuracy, as shown in Table 6, the Transformer model achieves an accuracy of 0.78 with our method, which is higher than 0.72 with FHE, 0.70 with FL, 0.69 with DP, and 0.66 with DP + FL. The BERT, CLIP, BLIP, and BLIP2 models achieve accuracies of 0.80, 0.83, 0.85, and 0.88, respectively, which are also significantly higher than the other methods. This further proves that our method has a significant advantage in improving the overall model performance.
Table 6.
Results on LLMs of accuracy for different methods.
From a theoretical analysis perspective, these results can be explained by the mathematical characteristics of the models. The Transformer model uses a self-attention mechanism that performs well in processing long texts. Our method introduces user privacy weights, dynamically adjusting attention weights, allowing it to efficiently process and analyze text data while protecting privacy. The BERT model captures contextual information through a bidirectional Transformer architecture. Our method applies differential privacy techniques in BERT by adding noise during parameter updates, effectively preventing user data leakage while maintaining high precision and high recall. The CLIP model combines multimodal information from language and images. With our method, it can more precisely protect user privacy while performing excellently in processing high-dimensional data. The BLIP and BLIP2 models further optimize multimodal pre-training tasks and datasets. Through our method, these models significantly improve precision, recall, and accuracy in multimodal tasks while protecting user privacy.
Mathematically, the performance improvement observed in different models when applying our method can be attributed to several factors. Firstly, the user attention mechanism dynamically adjusts attention weights, enabling the model to accurately identify and protect sensitive information based on the characteristics of the input data and user privacy needs. The combination of these techniques not only enhances the model’s privacy protection capabilities but also ensures efficient data processing and accurate output. For example, the Transformer model, when applying our method, dynamically adjusts weights in the self-attention calculation through the user attention mechanism, allowing it to protect sensitive information while efficiently processing long texts. The BERT model, within its bidirectional Transformer architecture, uses differential privacy techniques by adding noise during parameter updates, effectively preventing data leakage while maintaining high precision and high recall. The CLIP model, combining multimodal information from language and images, performs excellently in protecting user privacy and processing multimodal data with our method. The BLIP and BLIP2 models, further optimized for multimodal pre-training tasks and datasets, show significant improvements in precision, recall, and accuracy in multimodal tasks while protecting user privacy. Overall, the experimental results and theoretical analysis demonstrate that the proposed user-centered data privacy protection framework performs excellently across different large language models. This proves the framework’s broad potential and significant practical value in real-world applications, providing a strong solution for the field of data privacy protection.
4.3. Results on Throughput
The throughput experiment in this paper aims to evaluate the processing capacity of the proposed user-centric data privacy protection framework across different models. Throughput is a critical metric that measures the number of tasks a system can handle per unit of time, which is essential for ensuring efficiency in practical applications. This is particularly important in scenarios involving large-scale data processing, such as financial computing and facial recognition, where maintaining high throughput while protecting privacy is crucial for assessing the practical value of a data privacy protection method.
As shown Table 7, the baseline model, without any privacy protection, has a throughput of 1, representing its maximum processing capacity. When our method is applied, the throughput slightly decreases to 0.93 but remains at a high level. This indicates that our method has minimal impact on system throughput while providing privacy protection, enabling efficient data processing. In contrast, the fully homomorphic encryption (FHE) method shows a significantly low throughput of only 0.02. This is due to the extensive complex mathematical operations involved in FHE, which heavily consume computational resources and drastically reduce processing efficiency. The throughput for federated learning (FL) is 0.83, which is acceptable but lower than our method. This is because FL requires substantial communication during multiple model parameter transmissions and aggregations, which, despite enhancing data privacy protection, increases the system’s communication overhead. The throughput for differential privacy (DP) is 0.90, which is close to our method’s performance. This is because DP primarily achieves privacy protection by adding noise to data or model parameters, which has relatively low computational overhead but is still slightly less efficient than our method. The method combining DP and FL (DP + FL) has a throughput of 0.71, performing poorly. This is because it requires simultaneous noise addition for differential privacy and multiple communications for federated learning, leading to significant overhead and reduced processing capacity. In summary, by comparing the throughput of different privacy protection methods in models, it is evident that our method provides effective privacy protection while maintaining high processing capability. This not only validates the effectiveness of our method but also demonstrates its broad applicability and superiority in practical applications. By introducing the user attention mechanism and the unified loss function, our method optimizes the computational process, minimizing computational overhead while protecting privacy, ensuring efficient system operation. These results indicate that the proposed user-centric data privacy protection framework holds significant practical value in real-world applications.
Table 7.
Results on throughput for different methods.
4.4. Ablation Study on Attention Mechanism
In this experiment, the objective was to compare the performance of different attention mechanisms within various baseline models, specifically focusing on user attention, multi-head attention, and self-attention. These comparative experiments aim to verify the advantages of user attention in terms of privacy protection and performance enhancement and to explore its application effects in both computer vision and natural language processing tasks.
The precision results demonstrate that user attention consistently achieves the best performance across all models. For instance, in computer vision models, FasterRCNN achieves a precision of 0.82 with user attention compared to 0.76 and 0.70 with multi-head attention and self-attention, respectively. The precision for SSD, YOLO, and EfficientDet models under user attention also significantly exceeds the other two mechanisms, reaching 0.84, 0.87, and 0.90, respectively. Similarly, in natural language processing models, the precision for Transformer, BERT, CLIP, BLIP, and BLIP2 under user attention is 0.81, 0.84, 0.86, 0.88, and 0.90, respectively, which are all higher than those with multi-head attention and self-attention. These results indicate that user attention can more effectively capture and protect sensitive information, improving model precision (Table 8).
Table 8.
Precision results of different attention mechanisms in baseline models.
The recall results show a similar pattern of superiority for user attention. FasterRCNN achieves a recall of 0.79 with user attention compared to 0.73 and 0.66 with multi-head attention and self-attention. The recall for SSD, YOLO, and EfficientDet under user attention is 0.81, 0.85, and 0.88, respectively, while it is significantly lower under self-attention, at 0.70, 0.72, and 0.79. In natural language processing tasks, the recall for Transformer, BERT, CLIP, BLIP, and BLIP2 under user attention is 0.76, 0.78, 0.81, 0.84, and 0.87, respectively, and it is also higher than those with multi-head attention and self-attention. This demonstrates that user attention is not only effective in protecting user privacy but also better at capturing important features in the data, thus enhancing recall (Table 9).
Table 9.
Recall results of different attention mechanisms in baseline models.
In terms of accuracy, user attention again shows its advantages. FasterRCNN achieves an accuracy of 0.80 with user attention compared to 0.74 and 0.68 with multi-head attention and self-attention. The accuracy for SSD, YOLO, and EfficientDet under user attention is 0.83, 0.86, and 0.89, respectively. In natural language processing tasks, the accuracy for Transformer, BERT, CLIP, BLIP, and BLIP2 under user attention is 0.78, 0.80, 0.83, 0.85, and 0.88, respectively, which are all higher than the other two mechanisms. These results show that user attention provides higher accuracy across various tasks, which is closely related to its feature of dynamically adjusting attention weights to protect user privacy. Theoretically, the advantage of user attention lies in its ability to dynamically adjust attention weights based on the characteristics of the input data and user privacy needs. With this design, user attention can effectively highlight the positions of sensitive data in the attention scores, thus providing more protection to these data during model processing. This dynamic adjustment mechanism allows user attention to excel in all metrics. While multi-head attention can parallelize multiple attention heads to capture data features from different subspaces, it lacks the capability to dynamically adjust for user privacy, resulting in inferior performance in privacy protection and sensitive information capture compared to user attention. Self-attention, though computationally simple, shows clear deficiencies in handling complex data features and protecting privacy, thus performing the worst across all metrics (Table 10).
Table 10.
Accuracy results of different attention mechanisms in baseline models.
4.5. Ablation Study on Loss Function
The purpose of this experimental design was to compare the effects of different loss functions on model performance, specifically evaluating uni-loss, cross-entropy loss, and mean squared error (MSE) across various baseline models. These comparative experiments aim to verify the comprehensive optimization effect of uni-loss in multi-task processing and to explore its application in computer vision and natural language processing tasks.
The precision results indicate that uni-loss consistently achieves the best performance across all models. For instance, in computer vision models, FasterRCNN achieves a precision of 0.82 with uni-loss compared to 0.78 and 0.73 with cross-entropy loss and MSE, respectively. The precision for SSD, YOLO, and EfficientDet models under uni-loss is also significantly higher than with the other two loss functions, reaching 0.84, 0.87, and 0.90, respectively. Similarly, in natural language processing models, the precision for Transformer, BERT, CLIP, BLIP, and BLIP2 under uni-loss is 0.81, 0.84, 0.86, 0.88, and 0.90, respectively, which are all higher than with cross-entropy loss and MSE. These results suggest that uni-loss can more effectively optimize model performance and privacy protection, improving precision (Table 11).
Table 11.
Precision of different loss in baseline models.
The recall results show a similar pattern of superiority for uni-loss. FasterRCNN achieves a recall of 0.79 with uni-loss compared to 0.76 and 0.71 with cross-entropy loss and MSE. The recall for SSD, YOLO, and EfficientDet under uni-loss is 0.81, 0.85, and 0.88, respectively, which is significantly higher than with MSE. In natural language processing tasks, the recall for Transformer, BERT, CLIP, BLIP, and BLIP2 under uni-loss is 0.76, 0.78, 0.82, 0.86, and 0.89, respectively, which is also higher than with cross-entropy loss and MSE. This indicates that uni-loss is not only effective in protecting user privacy but also better at capturing important features in the data, enhancing recall (Table 12).
Table 12.
Recall of different attention mechanisms in baseline models.
From the perspective of accuracy, uni-loss once again shows its advantage. FasterRCNN achieves an accuracy of 0.80 with uni-loss compared to 0.77 and 0.72 with cross-entropy loss and MSE. The accuracy for SSD, YOLO, and EfficientDet under uni-loss is 0.83, 0.86, and 0.89, respectively. In natural language processing tasks, the accuracy for Transformer, BERT, CLIP, BLIP, and BLIP2 under uni-loss is 0.78, 0.80, 0.83, 0.87, and 0.89, respectively, which are all higher than with the other two loss functions. These results demonstrate that uni-loss can provide higher accuracy across various tasks, which is closely related to its design of combining classification loss, privacy loss, and attention loss (Table 13).
Table 13.
Accuracy of different attention mechanisms in baseline models.
Theoretically, the advantage of uni-loss lies in its ability to simultaneously optimize model classification performance and privacy protection. By combining classification loss (cross-entropy loss), privacy loss, and attention loss, uni-loss provides a multidimensional optimization target, making the model more efficient and comprehensive in handling complex tasks. Through this comprehensive optimization, uni-loss can dynamically balance different objectives during model training, ensuring enhanced privacy protection while improving classification performance. Although cross-entropy loss performs well in classification tasks, it focuses solely on the model classification performance and does not account for privacy protection and attention mechanisms. Consequently, while it may perform similarly to uni-loss in some baseline models, it falls short in overall optimization effectiveness. MSE, commonly used in regression tasks, performs poorly in classification tasks, especially when dealing with class imbalance issues. Therefore, in all the models tested in this experiment, MSE’s performance is inferior to both uni-loss and cross-entropy loss.
4.6. Future Work
Although the proposed user-centered data privacy protection framework, based on large language models and user attention mechanisms, demonstrated excellent performance in multiple experiments, there are still certain limitations and areas for improvement. Firstly, differential privacy techniques, while adding noise to ensure privacy, may negatively impact model accuracy. Future research should explore methods to mitigate the adverse effects of noise on model performance while maintaining privacy protection. Secondly, the complexity of the user attention mechanism increases computational costs; therefore, more efficient algorithms should be developed to reduce computational overhead and enhance real-time processing capabilities. Furthermore, the experimental data primarily focused on the financial and facial recognition domains; it is necessary to extend the scope to more diverse fields to verify the method’s applicability and generalizability. In terms of theoretical analysis, the design of uni-loss needs further refinement and optimization tailored to specific application scenarios to enhance adaptability and generalization capabilities. Additionally, the application of the user attention mechanism in multimodal data processing should be explored, and its architectural design should be optimized. In the context of model training and optimization, more advanced optimization algorithms should be investigated to improve training efficiency and effectiveness. Moreover, the explainability and transparency of the models are crucial issues that need attention; integrating explainable AI techniques can enhance user trust. While the experiments were primarily conducted on high-performance computing platforms, future work should consider deployment and optimization in resource-constrained environments to broaden the applicability and practical feasibility. Finally, ensuring the compliance and legality of the methods is essential. Continual improvement and optimization of the privacy protection framework, based on user feedback, are necessary to provide solutions that better meet user expectations and needs.
5. Conclusions
This paper proposes a user-centered data privacy protection framework based on LLM and user attention mechanisms, and it validates its effectiveness and advantages through multiple experiments in computer vision tasks and natural language processing tasks. With the advent of the big data era, data privacy protection has become an urgent issue to address. Particularly in high-sensitivity data processing fields such as financial computing and facial recognition, ensuring efficient and accurate data processing while protecting user privacy is a critical research direction. The innovations and main contributions of this paper include several aspects. Firstly, the introduction of a user attention mechanism dynamically adjusts attention weights to protect users’ sensitive information, allowing the model to precisely identify and protect sensitive information based on the characteristics of the input data and user privacy needs. Secondly, a uni-loss is designed, combining classification loss, privacy loss, and attention loss to ensure comprehensive performance in multi-task processing, improving the model’s precision, recall, and accuracy. The experimental results show that the proposed method significantly outperforms other methods in terms of precision, recall, and accuracy in both computer vision and natural language processing tasks. In computer vision tasks, models such as FasterRCNN, SSD, YOLO, and EfficientDet see substantial improvements in all metrics. Similarly, in natural language processing tasks, models including Transformer, BERT, CLIP, BLIP, and BLIP2 demonstrate outstanding performance. These results validate that the proposed framework can enhance model performance while protecting user privacy, indicating broad application potential and significant practical value.
Author Contributions
Conceptualization, S.Z., C.W. and C.L.; Methodology, S.Z. and Z.Z.; Software, Z.Z., J.Z. (Jiahe Zhang) and J.Z. (Jinming Zhang); Validation, S.Z. and L.W.; Formal analysis, C.W. and L.W.; Investigation, L.W.; Resources, C.W., Y.L. and J.Z. (Jiahe Zhang); Data curation, Z.Z., Y.L. and J.Z. (Jiahe Zhang); Writing—original draft, S.Z., Z.Z., C.W., Y.L., L.W., J.Z. (Jiahe Zhang), J.Z. (Jinming Zhang) and C.L.; Writing—review & editing, J.Z. (Jinming Zhang) and C.L.; Visualization, Y.L.; Project administration, J.Z. (Jinming Zhang) and C.L.; Funding acquisition, J.Z. (Jinming Zhang) and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant number 61202479.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
We are grateful to the ECC of CIEE in China Agricultural University and Mingzhuo Ruan for their strong support during our thesis writing.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Qi, C.C. Big data management in the mining industry. Int. J. Miner. Metall. Mater. 2020, 27, 131–139. [Google Scholar] [CrossRef]
- Boerman, S.C.; Kruikemeier, S.; Zuiderveen Borgesius, F.J. Exploring motivations for online privacy protection behavior: Insights from panel data. Commun. Res. 2021, 48, 953–977. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef]
- Ke, T.T.; Sudhir, K. Privacy rights and data security: GDPR and personal data markets. Manag. Sci. 2023, 69, 4389–4412. [Google Scholar] [CrossRef]
- Alwahaishi, S.; Ali, Z.; Al-Ahmadi, M.S.; Al-Jabri, I. Privacy Calculus and Personal Data Disclosure: Investigating the Roles of Personality Traits. In Proceedings of the 2023 9th International Conference on Control, Decision and Information Technologies (CoDIT), Rome, Italy, 3–6 July 2023; pp. 2158–2163. [Google Scholar]
- Zhang, L.; Zhang, Y.; Ma, X. A New Strategy for Tuning ReLUs: Self-Adaptive Linear Units (SALUs). In Proceedings of the ICMLCA 2021—2nd International Conference on Machine Learning and Computer Application, Shenyang, China, 17–19 December 2021; pp. 1–8. [Google Scholar]
- Li, Q.; Ren, J.; Zhang, Y.; Song, C.; Liao, Y.; Zhang, Y. Privacy-Preserving DNN Training with Prefetched Meta-Keys on Heterogeneous Neural Network Accelerators. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; pp. 1–6. [Google Scholar]
- Alaya, B.; Laouamer, L.; Msilini, N. Homomorphic encryption systems statement: Trends and challenges. Comput. Sci. Rev. 2020, 36, 100235. [Google Scholar] [CrossRef]
- Kim, J.; Kim, S.; Choi, J.; Park, J.; Kim, D.; Ahn, J.H. SHARP: A short-word hierarchical accelerator for robust and practical fully homomorphic encryption. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–15. [Google Scholar]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020; pp. 61–66. [Google Scholar]
- Chamikara, M.A.P.; Bertók, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy preserving face recognition utilizing differential privacy. Comput. Secur. 2020, 97, 101951. [Google Scholar] [CrossRef]
- Meden, B.; Rot, P.; Terhörst, P.; Damer, N.; Kuijper, A.; Scheirer, W.J.; Ross, A.; Peer, P.; Štruc, V. Privacy–enhancing face biometrics: A comprehensive survey. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4147–4183. [Google Scholar] [CrossRef]
- Sun, X.; Tian, C.; Hu, C.; Tian, W.; Zhang, H.; Yu, J. Privacy-Preserving and verifiable SRC-based face recognition with cloud/edge server assistance. Comput. Secur. 2022, 118, 102740. [Google Scholar] [CrossRef]
- Oyewole, A.T.; Oguejiofor, B.B.; Eneh, N.E.; Akpuokwe, C.U.; Bakare, S.S. Data privacy laws and their impact on financial technology companies: A review. Comput. Sci. IT Res. J. 2024, 5, 628–650. [Google Scholar] [CrossRef]
- Yalamati, S. Data Privacy, Compliance, and Security in Cloud Computing for Finance. In Practical Applications of Data Processing, Algorithms, and Modeling; IGI Global: Hershey, PA, USA, 2024; pp. 127–144. [Google Scholar]
- Kim, D.; Guyot, C. Optimized privacy-preserving cnn inference with fully homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2175–2187. [Google Scholar] [CrossRef]
- Hijazi, N.M.; Aloqaily, M.; Guizani, M.; Ouni, B.; Karray, F. Secure federated learning with fully homomorphic encryption for iot communications. IEEE Internet Things J. 2023, 11, 4289–4300. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y.; Ren, J.; Li, Q.; Zhang, Y. You Can Use But Cannot Recognize: Preserving Visual Privacy in Deep Neural Networks. arXiv 2024, arXiv:2404.04098. [Google Scholar]
- Al Badawi, A.; Polyakov, Y. Demystifying bootstrapping in fully homomorphic encryption. Cryptol. ePrint Arch. 2023, 6791–6807. [Google Scholar]
- Madni, H.A.; Umer, R.M.; Foresti, G.L. Swarm-fhe: Fully homomorphic encryption-based swarm learning for malicious clients. Int. J. Neural Syst. 2023, 33, 2350033. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Yang, M.; Wang, T.; Wang, N.; Lyu, L.; Niyato, D.; Lam, K.Y. Local differential privacy-based federated learning for internet of things. IEEE Internet Things J. 2020, 8, 8836–8853. [Google Scholar] [CrossRef]
- Jia, B.; Zhang, X.; Liu, J.; Zhang, Y.; Huang, K.; Liang, Y. Blockchain-enabled federated learning data protection aggregation scheme with differential privacy and homomorphic encryption in IIoT. IEEE Trans. Ind. Inform. 2021, 18, 4049–4058. [Google Scholar] [CrossRef]
- Blanco-Justicia, A.; Sánchez, D.; Domingo-Ferrer, J.; Muralidhar, K. A critical review on the use (and misuse) of differential privacy in machine learning. ACM Comput. Surv. 2022, 55, 1–16. [Google Scholar] [CrossRef]
- Vasa, J.; Thakkar, A. Deep learning: Differential privacy preservation in the era of big data. J. Comput. Inf. Syst. 2023, 63, 608–631. [Google Scholar] [CrossRef]
- Huang, T.; Zheng, S. Using Differential Privacy to Define Personal, Anonymous and Pseudonymous Data. IEEE Access 2023, 11, 109225–109236. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Pfitzner, B.; Steckhan, N.; Arnrich, B. Federated learning in a medical context: A systematic literature review. ACM Trans. Internet Technol. (TOIT) 2021, 21, 1–31. [Google Scholar] [CrossRef]
- Awosika, T.; Shukla, R.M.; Pranggono, B. Transparency and privacy: The role of explainable ai and federated learning in financial fraud detection. IEEE Access 2024, 12, 64551–64560. [Google Scholar] [CrossRef]
- Liu, T.; Wang, Z.; He, H.; Shi, W.; Lin, L.; An, R.; Li, C. Efficient and secure federated learning for financial applications. Appl. Sci. 2023, 13, 5877. [Google Scholar] [CrossRef]
- Zhang, H.; Hong, J.; Dong, F.; Drew, S.; Xue, L.; Zhou, J. A privacy-preserving hybrid federated learning framework for financial crime detection. arXiv 2023, arXiv:2302.03654. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2016; Volume 14, pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 478–502. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1078–1093. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Agrawal, R.; de Castro, L.; Yang, G.; Juvekar, C.; Yazicigil, R.; Chandrakasan, A.; Vaikuntanathan, V.; Joshi, A. FAB: An FPGA-based accelerator for bootstrappable fully homomorphic encryption. In Proceedings of the 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, QC, Canada, 25 February–1 March 2023; pp. 882–895. [Google Scholar]
- Hernandez-Matamoros, A.; Kikuchi, H. Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets. Appl. Sci. 2024, 14, 2864. [Google Scholar] [CrossRef]
- Mammen, P.M. Federated learning: Opportunities and challenges. arXiv 2021, arXiv:2101.05428. [Google Scholar]
- Aziz, R.; Banerjee, S.; Bouzefrane, S.; Le Vinh, T. Exploring homomorphic encryption and differential privacy techniques towards secure federated learning paradigm. Future Internet 2023, 15, 310. [Google Scholar] [CrossRef]

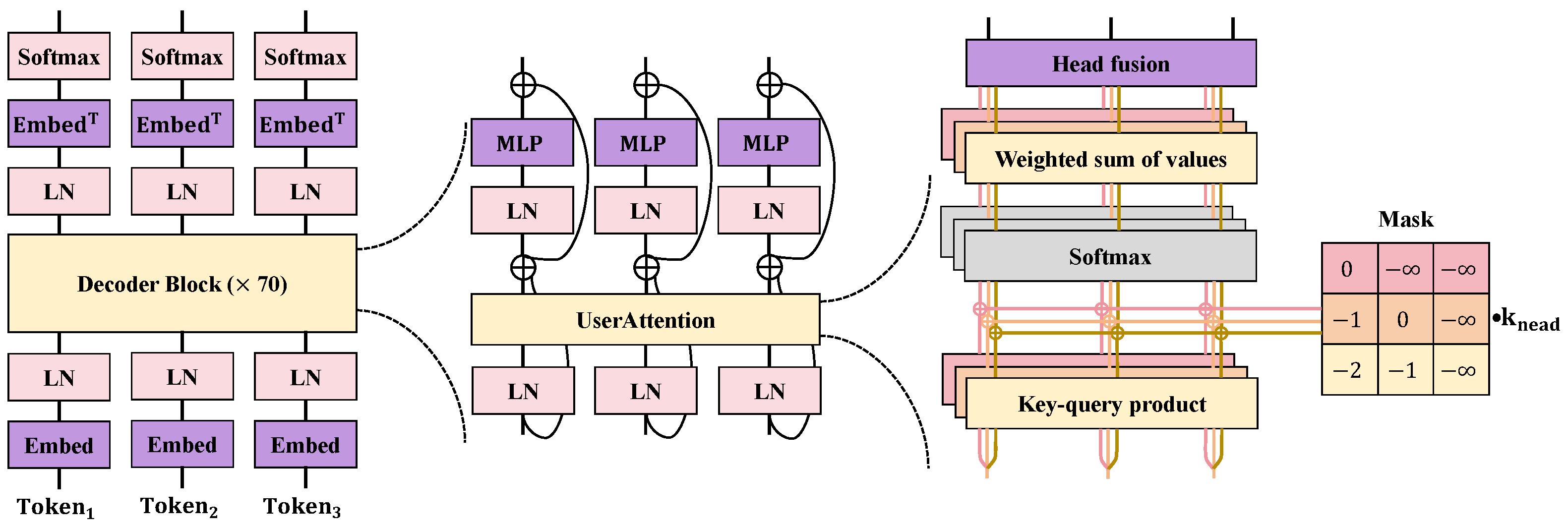
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).