
A Closer Look at Few-Shot Classification with Many Novel Classes


Abstract
:1. Introduction
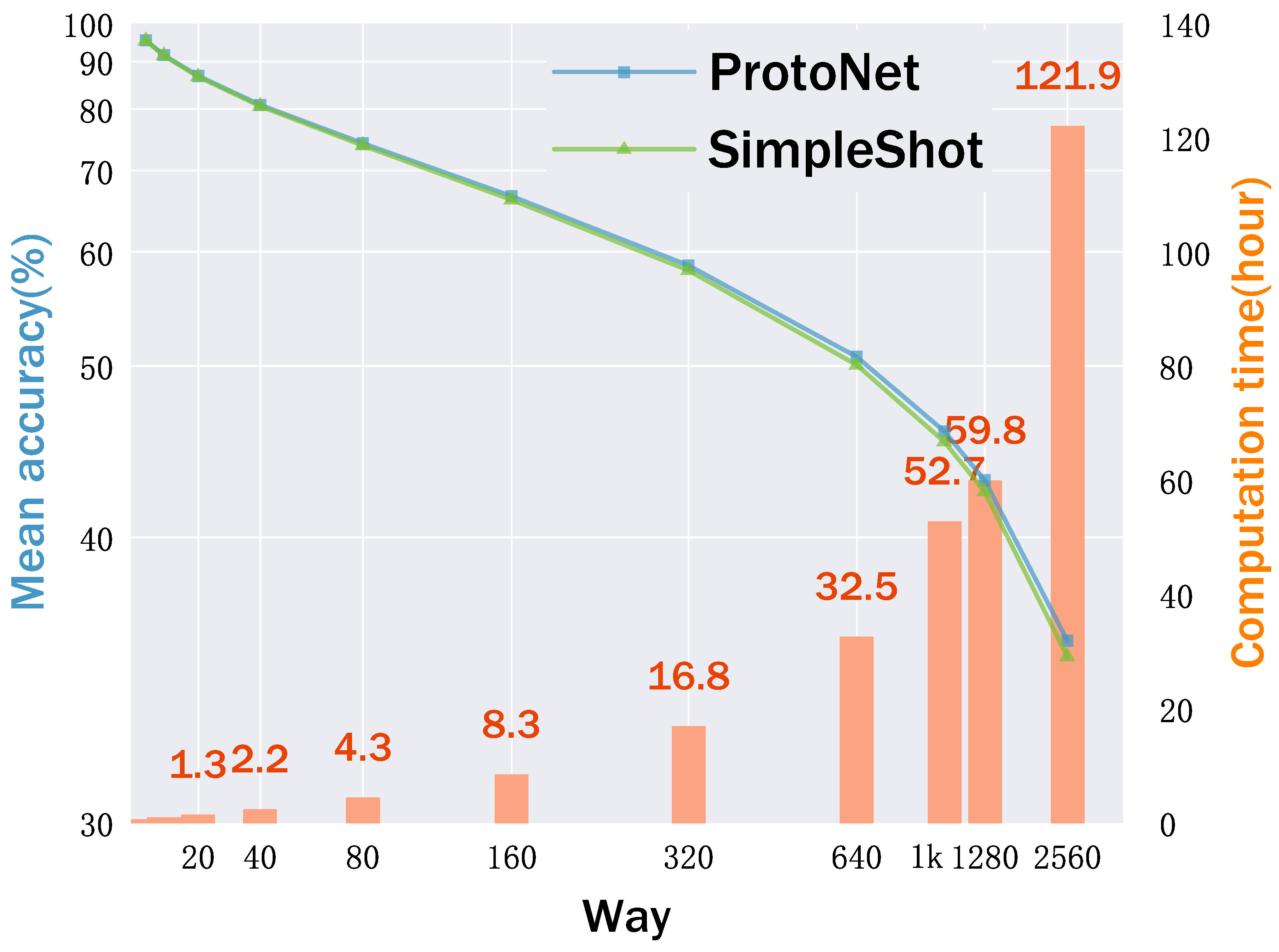
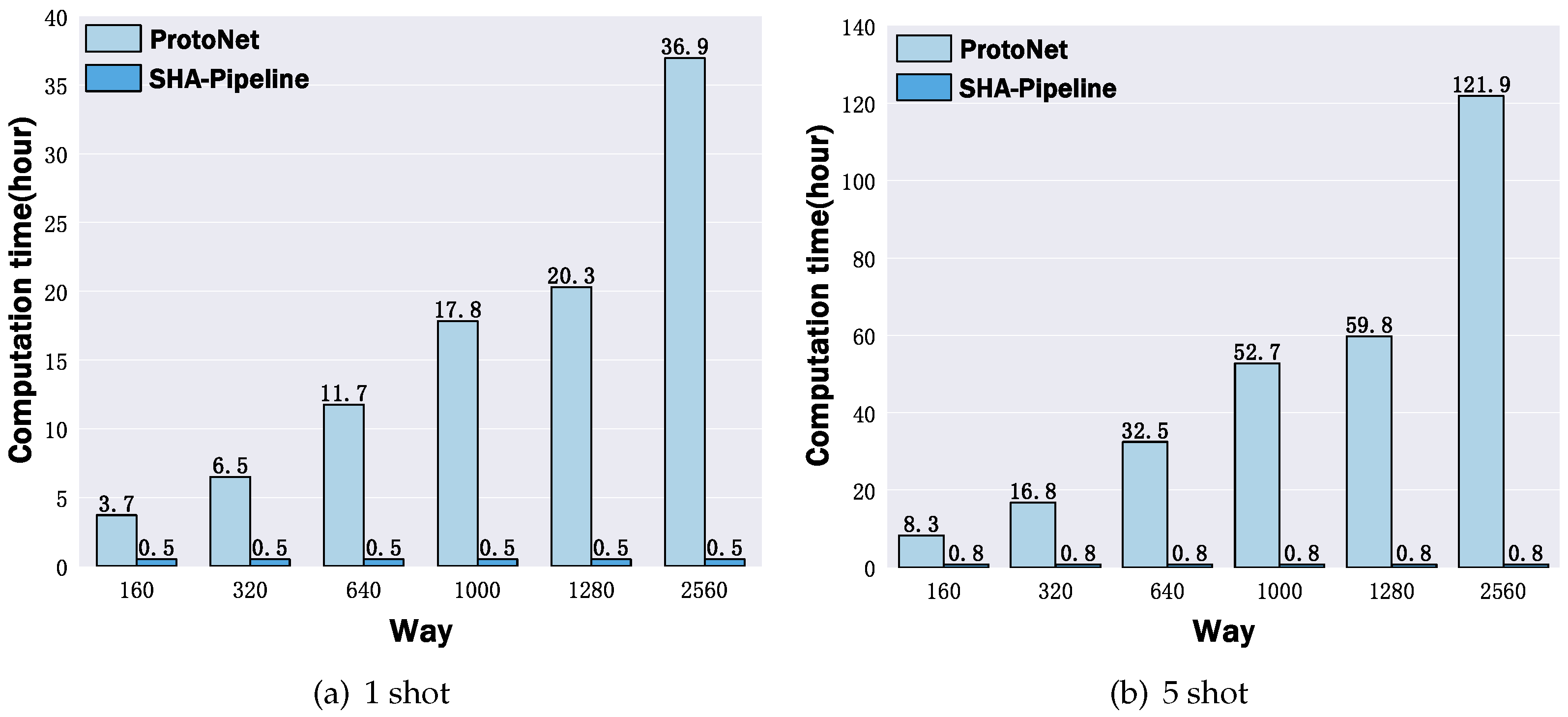
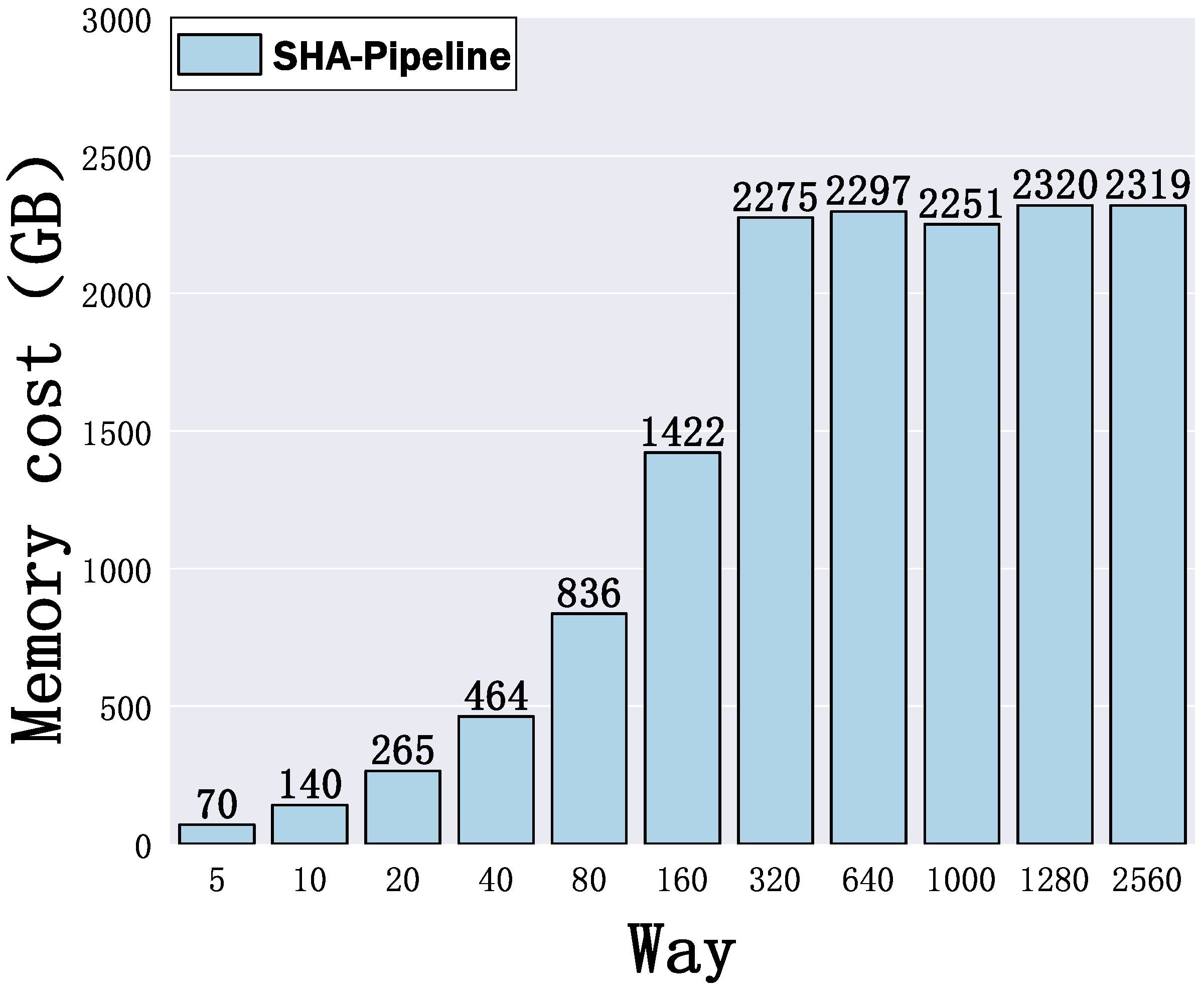
- Efficiency Enhancement. Our extensive experiments reveal that the efficiency of EML in FSL-MNC remains nearly constant across different numbers of ways when utilizing various backbones. By maintaining the number of ways in episodes at five, we significantly reduce the complexity associated with the number of ways in EML. Additionally, to expedite the training process, we minimize the communication overhead of support samples and avoid GPU memory overflow by efficiently distributing the support and partial query sets, as shown in Section 5.3.
- Performance Improvement. We enhance classification performance by employing a fast, non-parametric hierarchy clustering strategy to capture the class hierarchy, and then we leverage such class hierarchy by structured representation learning. This approach enhances representation learning on two levels: prototype-level and sample-level. At the prototype level, we strive to maintain the hierarchical structure of class prototypes by maximizing the Cophenetic Correlation Coefficient (CPCC). At the sample level, we use hierarchical triplet loss to ensure that similar samples from different parent classes remain distinctly separate.
2. Related Work
2.1. Traditional Few-Shot Learning
2.2. Large-Scale Few-Shot Learning
2.3. FSL with Class Hierarchy
3. Few-Shot Learning with Many Novel Classes
3.1. Problem Formulation
3.1.1. Few-Shot Learning
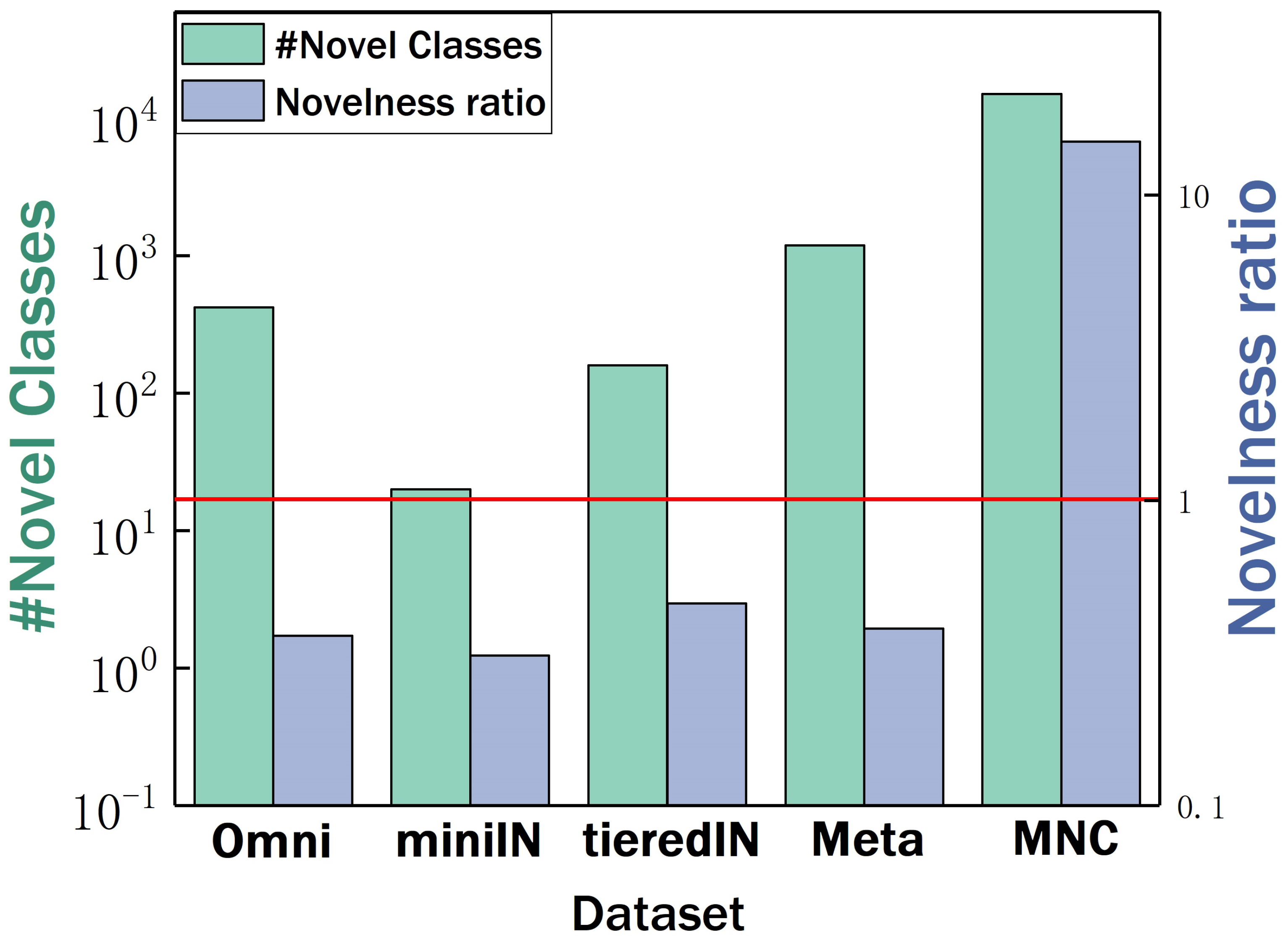
3.1.2. Few-Shot Learning with Many Novel Classes
3.1.3. Class Hierarchical Structure
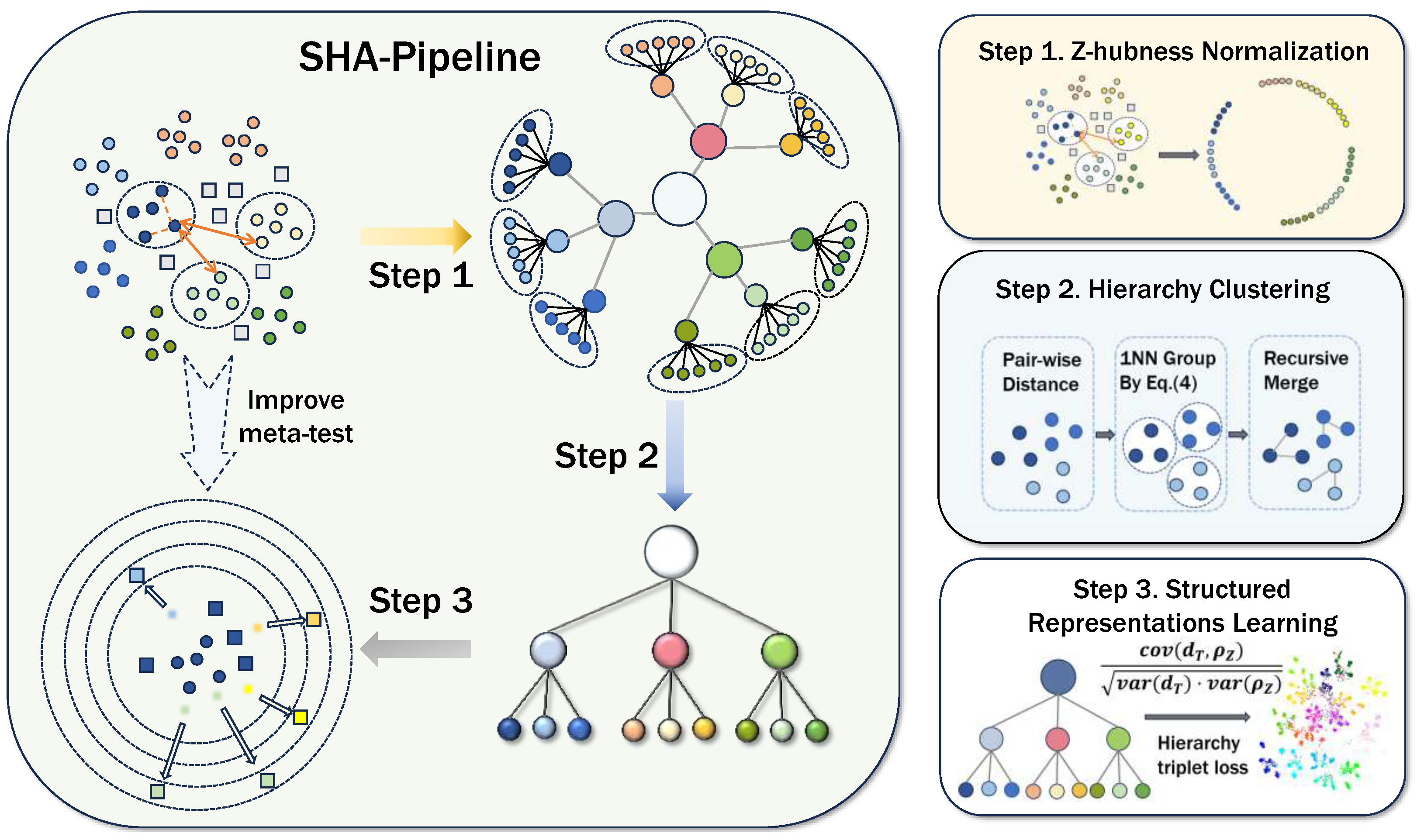
4. Simple Hierarchy-Aware Pipeline
4.1. Enhancing Efficiency
4.1.1. A Strategy for Meta-Learning
4.1.2. Lightweight Parallel Framework
| Algorithm 1: A Lightweight Parallel Framework for meta-training |
| Require: : distribution over tasks Require: : step size hyperparameters, n: GPU numbers
|
| Algorithm 2: A Lightweight Parallel Framework for meta-testing |
| Require: : distribution over tasks Require: : step size hyperparameters, n: GPU numbers
|
4.2. Fine-Tuning with Class Hierarchy Capturing
| Algorithm 3: Algorithm for Fine-Tuning |
Require: N-way M-shot episodes (, ), learning rate , fine-tune step I, backbone weights
|
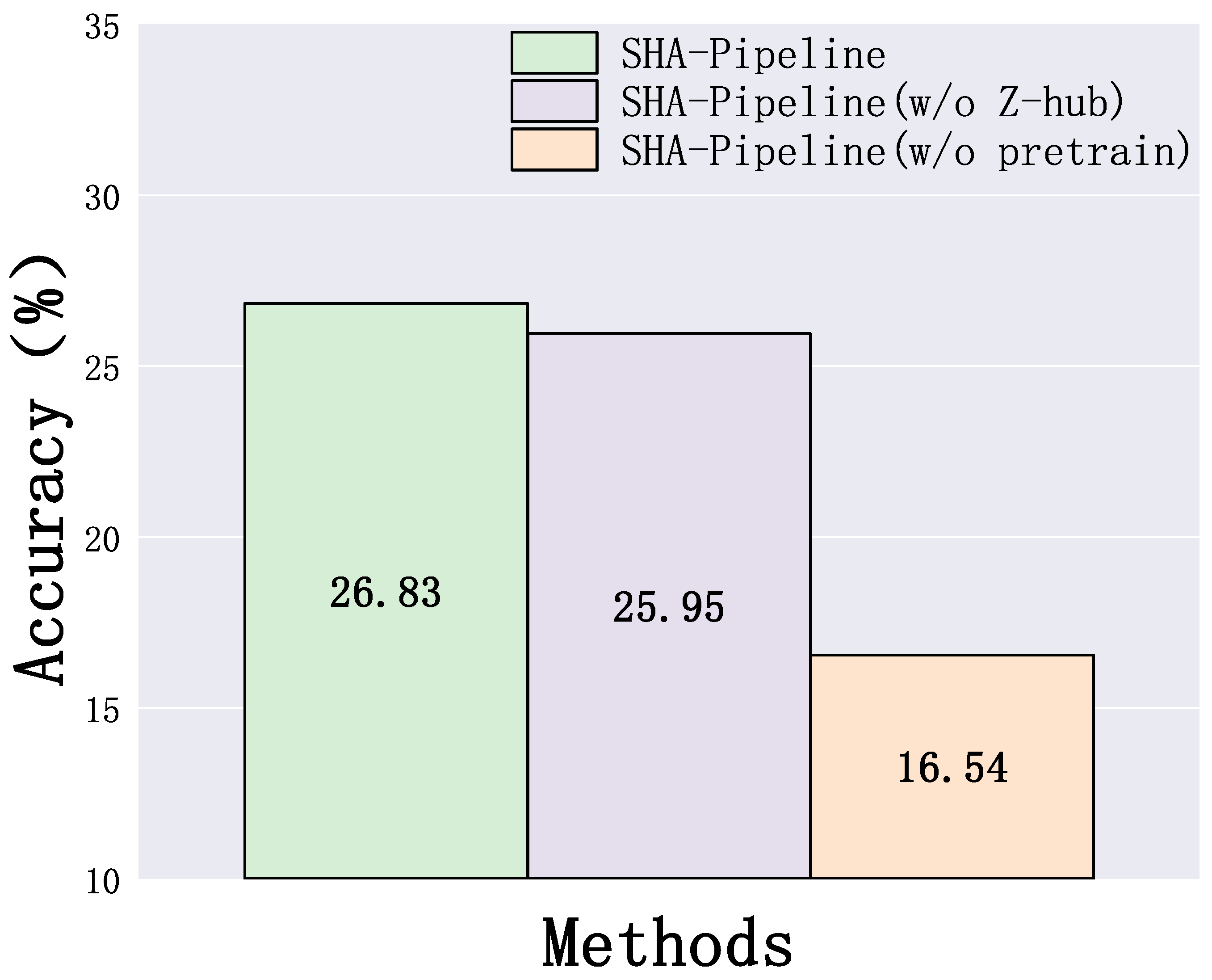
4.2.1. Z-Hubness Normalization
4.2.2. Hierarchical Clustering with the First Neighbor
4.2.3. Structured Representation Learning with Class Hierarchy
5. Experiments
5.1. Experimental Setup
5.1.1. Datasets
5.1.2. Experimental Protocols
5.1.3. Baselines
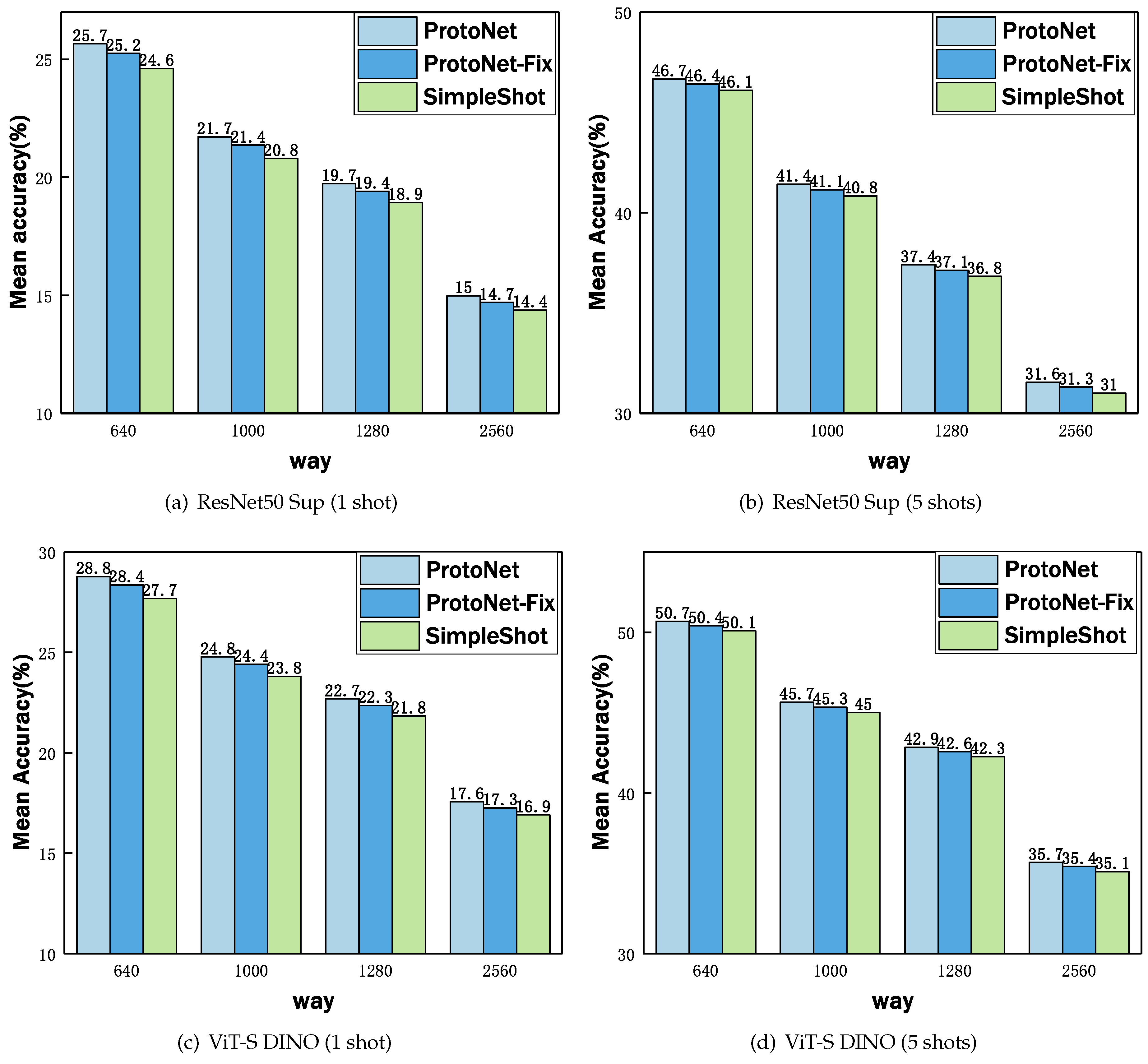
- ProtoNet [35] is widely regarded as a robust task-agnostic embedding baseline model that utilizes support set samples to form prototypes for each class. Classification is performed by computing the distances between query samples and these prototypes. This method notably emphasizes rapid adaptation to new categories without the need for specific task optimization.
- ProtoNet-Fix, a variant of ProtoNet, fixes the number of classes at five (i.e., 5-way classification) during meta-training, simplifying the training process and enhancing the model’s generalizability post-training. ProtoNet-Fix is employed to assess the impact of different meta-training strategies.
- SimpleShot [21] represents a baseline method for few-shot learning that employs L2 normalization techniques on each sample’s feature vector. Its key feature lies in simplifying the processing flow: it eliminates the need for meta-learning or complex fine-tuning steps. By directly utilizing normalized feature vectors and a nearest-neighbor classifier, SimpleShot achieves impressive performance across multiple few-shot learning tasks.
- Few-shot baseline [3] focuses on optimizing model performance in few-shot settings through fine-tuning. Specifically, it fine-tunes the network backbone using cross-entropy loss applied on the support set to adapt to newly emerged classes. This method is straightforward and effective, particularly suitable for environments with strict label constraints.
- P > M > F [22] employs a cutting-edge method that utilizes ProtoNet for meta-training, building robust class prototype learning mechanisms during the meta-training phase and fine-tuning the meta-traininged backbone through data augmentation techniques in subsequent stages. This strategy not only improves the model’s performance on standard testing tasks but also significantly enhances its adaptability to new domains by extending training data diversity. This method effectively bridges meta-learning and fine-tuning, optimizing the knowledge transfer from base classes to new classes. As SHA-Pipeline also employs data augmentation, P > M > F is replicated within the parallel framework of this study for experimental testing.
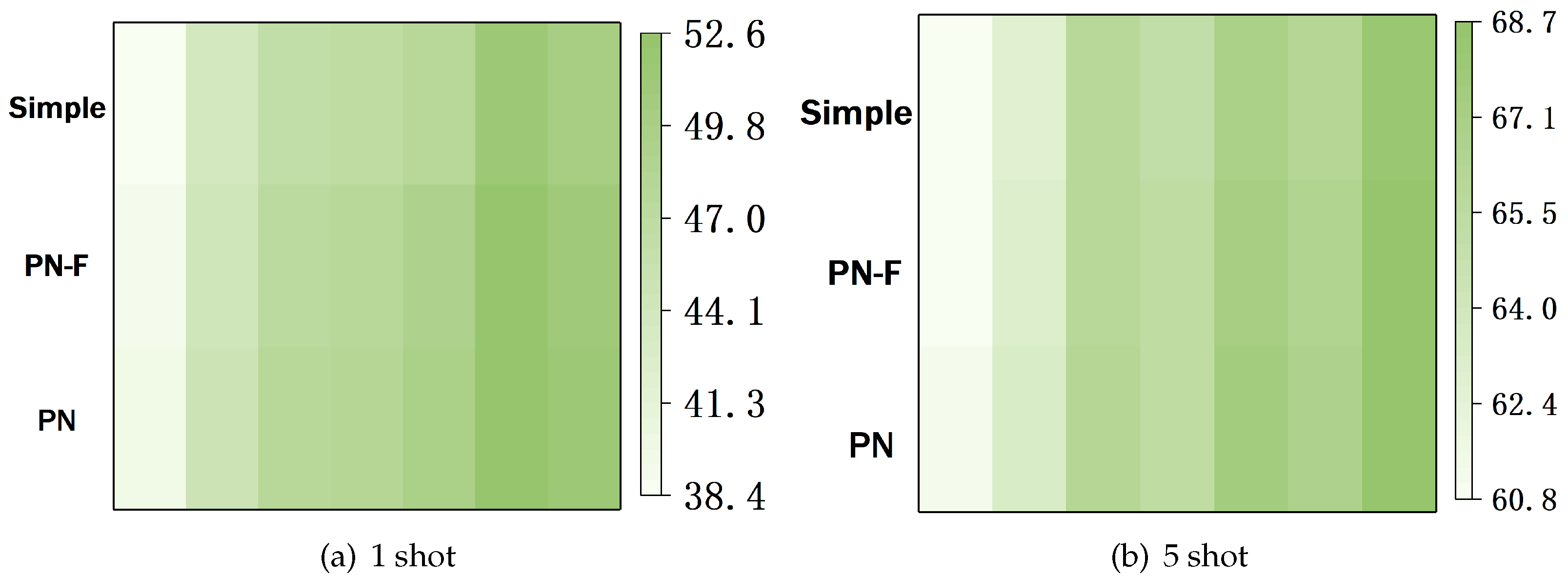
5.2. Analysis of Meta-Training Strategy
5.3. Analysis of Computation Overhead
5.4. FSL-MNC Performance
5.5. Standard Benchmark Performance
5.6. Ablation Study
5.7. Visualization Study
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- An, Y.; Xue, H.; Zhao, X.; Wang, J. From Instance to Metric Calibration: A Unified Framework for Open-World Few-Shot Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9757–9773. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2021, 53, 63:1–63:34. [Google Scholar] [CrossRef]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A Baseline for Few-Shot Image Classification. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; OpenReview.net: Addis Ababa, Ethiopia, 2020. [Google Scholar]
- Lin, Z.; Yang, W.; Wang, H.; Chi, H.; Lan, L.; Wang, J. Scaling Few-Shot Learning for the Open World. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 13846–13854. [Google Scholar]
- Willes, J.; Harrison, J.; Harakeh, A.; Finn, C.; Pavone, M.; Waslander, S. Bayesian embeddings for few-shot open world recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 1513–1529. [Google Scholar] [CrossRef] [PubMed]
- Parmar, J.; Chouhan, S.S.; Raychoudhury, V.; Rathore, S.S. Open-world Machine Learning: Applications, Challenges, and Opportunities. ACM Comput. Surv. 2023, 55, 205:1–205:37. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Baz, A.E.; Ullah, I.; Alcobaça, E.; de Carvalho, A.C.P.L.F.; Chen, H.; Ferreira, F.; Gouk, H.; Guan, C.; Guyon, I.; Hospedales, T.M.; et al. Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification. In Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track, Online, 6–14 December 2021; Kiela, D., Ciccone, M., Caputo, B., Eds.; Proceedings of Machine Learning Research (PMLR): London, UK, 2021; Volume 176, pp. 80–96. [Google Scholar]
- Rajeswaran, A.; Finn, C.; Kakade, S.M.; Levine, S. Meta-Learning with Implicit Gradients. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 113–124. [Google Scholar]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- Novack, Z.; McAuley, J.; Lipton, Z.C.; Garg, S. Chils: Zero-shot image classification with hierarchical label sets. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: London, UK, 2023; pp. 26342–26362. [Google Scholar]
- Guo, Y.; Xu, M.; Li, J.; Ni, B.; Zhu, X.; Sun, Z.; Xu, Y. Hcsc: Hierarchical contrastive selective coding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9706–9715. [Google Scholar]
- Hospedales, T.M.; Antoniou, A.; Micaelli, P.; Storkey, A.J. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; Conference Track Proceedings. OpenReview.net: Toulon, France, 2017. [Google Scholar]
- Ye, H.; Hu, H.; Zhan, D.; Sha, F. Few-Shot Learning via Embedding Adaptation with Set-to-Set Functions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation: New York, NY, USA; IEEE: Piscataway, NJ, USA, 2020; pp. 8805–8814. [Google Scholar] [CrossRef]
- Ye, H.; Chao, W. How to Train Your MAML to Excel in Few-Shot Classification. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Geng, C.; Huang, S.; Chen, S. Recent Advances in Open Set Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3614–3631. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Proceedings of Machine Learning Research (PMLR): London, UK, 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Wang, Y.; Chao, W.; Weinberger, K.Q.; van der Maaten, L. SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning. arXiv 2019, arXiv:1911.04623. [Google Scholar] [CrossRef]
- Hu, S.X.; Li, D.; Stühmer, J.; Kim, M.; Hospedales, T.M. Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 9058–9067. [Google Scholar] [CrossRef]
- Liu, L.; Zhou, T.; Long, G.; Jiang, J.; Zhang, C. Many-Class Few-Shot Learning on Multi-Granularity Class Hierarchy. IEEE Trans. Knowl. Data Eng. 2022, 34, 2293–2305. [Google Scholar] [CrossRef]
- Li, A.; Luo, T.; Lu, Z.; Xiang, T.; Wang, L. Large-Scale Few-Shot Learning: Knowledge Transfer with Class Hierarchy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation: New York, NY, USA; IEEE: Piscataway, NJ, USA, 2019; pp. 7212–7220. [Google Scholar] [CrossRef]
- Sarfraz, M.S.; Sharma, V.; Stiefelhagen, R. Efficient Parameter-Free Clustering Using First Neighbor Relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation: New York, NY, USA; IEEE: Piscataway, NJ, USA, 2019; pp. 8934–8943. [Google Scholar] [CrossRef]
- Fei, N.; Gao, Y.; Lu, Z.; Xiang, T. Z-Score Normalization, Hubness, and Few-Shot Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 142–151. [Google Scholar] [CrossRef]
- Bertinetto, L.; Henriques, J.F.; Torr, P.H.S.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Triantafillou, E.; Zhu, T.; Dumoulin, V.; Lamblin, P.; Evci, U.; Xu, K.; Goroshin, R.; Gelada, C.; Swersky, K.; Manzagol, P.; et al. Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Doersch, C.; Gupta, A.; Zisserman, A. CrossTransformers: Spatially-aware few-shot transfer. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9630–9640. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021; Virtual Event, 18–24 July 2021, Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research (PMLR): London, UK, 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R.B. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 15979–15988. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 4077–4087. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar] [CrossRef]
- Oreshkin, B.N.; López, P.R.; Lacoste, A. TADAM: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 719–729. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. Conference Track Proceedings. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Piscataway, NJ, USA, 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Chen, W.; Liu, Y.; Kira, Z.; Wang, Y.F.; Huang, J. A Closer Look at Few-shot Classification. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-Learning With Differentiable Convex Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation: New York, NY, USA; IEEE: Piscataway, NJ, USA, 2019; pp. 10657–10665. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9042–9051. [Google Scholar] [CrossRef]
- Afham, M.; Khan, S.; Khan, M.H.; Naseer, M.; Khan, F.S. Rich Semantics Improve Few-Shot Learning. In Proceedings of the 32nd British Machine Vision Conference 2021, BMVC 2021, Online, 22–25 November 2021; BMVA Press: Durham, UK, 2021; p. 152. [Google Scholar]
- Hu, S.X.; Moreno, P.G.; Xiao, Y.; Shen, X.; Obozinski, G.; Lawrence, N.D.; Damianou, A.C. Empirical Bayes Transductive Meta-Learning with Synthetic Gradients. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Hu, Y.; Gripon, V.; Pateux, S. Leveraging the Feature Distribution in Transfer-Based Few-Shot Learning. In Proceedings of the Artificial Neural Networks and Machine Learning-ICANN 2021-30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Proceedings, Part II. Farkas, I., Masulli, P., Otte, S., Wermter, S., Eds.; Springer: Cham, Switzerland, 2021; Volume 12892, pp. 487–499, Lecture Notes in Computer Science. [Google Scholar] [CrossRef]
- Bateni, P.; Barber, J.; van de Meent, J.; Wood, F. Enhancing Few-Shot Image Classification with Unlabelled Examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, 3–8 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1597–1606. [Google Scholar] [CrossRef]
- Gidaris, S.; Bursuc, A.; Komodakis, N.; Pérez, P.; Cord, M. Boosting Few-Shot Visual Learning with Self-Supervision. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8058–8067. [Google Scholar] [CrossRef]
- Chen, D.; Chen, Y.; Li, Y.; Mao, F.; He, Y.; Xue, H. Self-Supervised Learning for Few-Shot Image Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1745–1749. [Google Scholar] [CrossRef]
- Rodríguez, P.; Laradji, I.H.; Drouin, A.; Lacoste, A. Embedding Propagation: Smoother Manifold for Few-Shot Classification. In Proceedings of the Computer Vision-ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVI. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Cham, Switzerland, 2020; Volume 12371, pp. 121–138, Lecture Notes in Computer Science. [Google Scholar] [CrossRef]
- Li, X.; Sun, Q.; Liu, Y.; Zhou, Q.; Zheng, S.; Chua, T.; Schiele, B. Learning to Self-Train for Semi-Supervised Few-Shot Classification. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 10276–10286. [Google Scholar]
- Huang, K.; Geng, J.; Jiang, W.; Deng, X.; Xu, Z. Pseudo-loss Confidence Metric for Semi-supervised Few-shot Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8651–8660. [Google Scholar] [CrossRef]
- Baik, S.; Choi, M.; Choi, J.; Kim, H.; Lee, K.M. Meta-Learning with Adaptive Hyperparameters. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Saikia, T.; Brox, T.; Schmid, C. Optimized Generic Feature Learning for Few-shot Classification across Domains. arXiv 2020, arXiv:2001.07926. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, X.; Zhang, Z.; Lan, L.; Zhang, W.; Luo, Z. Nocal-Siam: Refining Visual Features and Response with Advanced Non-Local Blocks for Real-Time Siamese Tracking. IEEE Trans. Image Process. 2021, 30, 2656–2668. [Google Scholar] [CrossRef] [PubMed]
- Lan, L.; Wang, X.; Hua, G.; Huang, T.S.; Tao, D. Semi-online Multi-people Tracking by Re-identification. Int. J. Comput. Vis. 2020, 128, 1937–1955. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Arch | Pre-Train | MetaTr | Shot | Way | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 10 | 20 | 40 | 80 | 160 | 320 | 640 | 1000 | 1280 | 2560 | ||||||
| 1 | ResNet50 | DINO | - | 1 | 76.78 | 67.44 | 58.57 | 49.84 | 41.32 | 33.66 | 26.85 | 21.13 | 17.97 | 16.48 | 12.70 | 38.43 |
| 2 | - | 5 | 92.74 | 87.90 | 82.22 | 75.54 | 68.10 | 60.04 | 51.98 | 44.19 | 39.42 | 36.83 | 30.41 | 60.85 | ||
| 3 | Sup. | - | 1 | 84.26 | 75.54 | 66.38 | 57.07 | 47.75 | 39.13 | 31.37 | 24.62 | 20.79 | 18.94 | 14.37 | 43.66 | |
| 4 | - | 5 | 94.51 | 90.36 | 84.97 | 78.44 | 71.04 | 62.86 | 54.52 | 46.11 | 40.84 | 36.83 | 31.01 | 62.86 | ||
| 5 | ViT-small | DINO | - | 1 | 85.34 | 77.07 | 68.76 | 59.87 | 50.95 | 42.36 | 34.65 | 27.68 | 23.80 | 21.84 | 16.91 | 46.29 |
| 6 | - | 5 | 95.20 | 91.39 | 86.52 | 80.50 | 73.71 | 66.02 | 58.09 | 50.09 | 45.02 | 42.25 | 35.11 | 65.81 | ||
| 7 | Deit | - | 1 | 83.84 | 76.66 | 68.87 | 60.77 | 52.44 | 44.00 | 36.08 | 28.78 | 24.55 | 22.39 | 17.02 | 46.85 | |
| 8 | - | 5 | 94.63 | 91.09 | 86.41 | 80.51 | 73.57 | 65.71 | 57.50 | 49.06 | 43.54 | 40.69 | 33.11 | 65.07 | ||
| 9 | ViT-base | DINO | - | 1 | 86.35 | 78.80 | 70.75 | 62.03 | 53.08 | 44.37 | 36.43 | 29.20 | 25.07 | 23.02 | 17.80 | 47.90 |
| 10 | - | 5 | 95.49 | 92.16 | 87.49 | 81.80 | 75.16 | 67.63 | 59.81 | 51.82 | 46.63 | 43.54 | 36.57 | 67.10 | ||
| 11 | Deit | - | 1 | 83.28 | 76.09 | 68.70 | 60.99 | 52.98 | 44.86 | 59.04 | 50.73 | 25.58 | 23.42 | 17.91 | 51.24 | |
| 12 | - | 5 | 94.50 | 91.13 | 86.63 | 81.10 | 74.58 | 67.06 | 59.04 | 50.73 | 45.21 | 42.67 | 35.25 | 66.17 | ||
| 13 | MAE | - | 1 | 85.43 | 78.97 | 71.98 | 64.48 | 56.48 | 48.10 | 40.05 | 32.38 | 27.78 | 25.43 | 19.52 | 50.05 | |
| 14 | - | 5 | 95.51 | 92.34 | 88.35 | 83.12 | 76.90 | 69.56 | 61.60 | 53.24 | 47.63 | 44.55 | 37.25 | 68.19 | ||
| 15 | ResNet50 | DINO | PN | 1 | 77.62 | 69.04 | 60.47 | 51.29 | 42.74 | 34.96 | 28.02 | 22.19 | 18.91 | 17.28 | 13.32 | 39.62 |
| 16 | PN | 5 | 92.84 | 88.05 | 82.44 | 75.86 | 68.46 | 60.45 | 52.47 | 44.76 | 40.02 | 37.41 | 30.97 | 61.25 | ||
| 17 | Sup. | PN | 1 | 85.08 | 77.11 | 68.24 | 58.49 | 49.14 | 40.40 | 32.51 | 25.65 | 21.72 | 19.73 | 14.98 | 44.82 | |
| 18 | PN | 5 | 94.60 | 90.51 | 85.19 | 78.75 | 71.38 | 63.27 | 54.99 | 46.66 | 41.43 | 37.40 | 31.55 | 63.25 | ||
| 19 | ViT-small | DINO | PN | 1 | 86.21 | 78.74 | 70.74 | 61.38 | 52.43 | 43.73 | 35.86 | 28.78 | 24.78 | 22.68 | 17.56 | 47.54 |
| 20 | PN | 5 | 95.30 | 91.55 | 86.75 | 80.83 | 74.08 | 66.45 | 58.60 | 50.68 | 45.65 | 42.85 | 35.69 | 66.22 | ||
| 21 | Deit | PN | 1 | 84.70 | 78.29 | 70.81 | 62.25 | 53.89 | 45.33 | 37.27 | 29.86 | 25.51 | 23.21 | 17.66 | 48.07 | |
| 22 | PN | 5 | 94.72 | 91.25 | 86.64 | 80.83 | 73.93 | 66.13 | 58.00 | 49.64 | 44.15 | 41.27 | 33.68 | 65.48 | ||
| 23 | ViT-base | DINO | PN | 1 | 87.36 | 80.73 | 73.05 | 63.78 | 54.79 | 45.95 | 37.84 | 30.48 | 26.21 | 23.99 | 18.55 | 49.34 |
| 24 | PN | 5 | 95.60 | 92.34 | 87.76 | 82.18 | 75.59 | 68.12 | 60.40 | 52.51 | 47.36 | 44.23 | 37.24 | 67.58 | ||
| 25 | Deit | PN | 1 | 84.26 | 77.95 | 70.92 | 62.68 | 54.64 | 46.38 | 60.41 | 51.96 | 26.68 | 24.36 | 18.64 | 52.63 | |
| 26 | PN | 5 | 94.61 | 91.31 | 86.89 | 81.47 | 74.99 | 67.54 | 59.62 | 51.39 | 45.91 | 43.34 | 35.90 | 66.63 | ||
| 27 | MAE | PN | 1 | 86.47 | 80.95 | 74.33 | 66.27 | 58.24 | 49.72 | 41.49 | 33.69 | 28.94 | 26.43 | 20.29 | 51.53 | |
| 28 | PN | 5 | 95.62 | 92.54 | 88.62 | 83.51 | 77.34 | 70.07 | 62.21 | 53.94 | 48.38 | 45.26 | 37.94 | 68.68 | ||
| 29 | ResNet50 | DINO | PN-F | 1 | 77.62 | 68.76 | 59.95 | 51.18 | 42.49 | 34.67 | 27.67 | 21.78 | 18.56 | 16.97 | 13.03 | 39.33 |
| 30 | PN-F | 5 | 92.84 | 88.05 | 82.34 | 75.72 | 68.29 | 60.26 | 52.24 | 44.50 | 39.73 | 37.14 | 30.72 | 61.07 | ||
| 31 | Sup. | PN-F | 1 | 85.08 | 76.83 | 67.73 | 58.38 | 48.90 | 40.11 | 32.17 | 25.25 | 21.37 | 19.42 | 14.70 | 44.54 | |
| 32 | PN-F | 5 | 94.60 | 90.51 | 85.09 | 78.61 | 71.22 | 63.08 | 54.78 | 46.41 | 41.14 | 37.13 | 31.31 | 63.08 | ||
| 33 | ViT-small | DINO | PN-F | 1 | 86.21 | 78.44 | 70.19 | 61.27 | 52.17 | 43.42 | 35.50 | 28.36 | 24.41 | 22.35 | 17.26 | 47.23 |
| 34 | PN-F | 5 | 95.30 | 91.55 | 86.64 | 80.68 | 73.90 | 66.25 | 58.37 | 50.41 | 45.34 | 42.57 | 35.43 | 66.04 | ||
| 35 | Deit | PN-F | 1 | 84.70 | 78.00 | 70.27 | 62.14 | 53.64 | 45.03 | 36.91 | 29.44 | 25.14 | 22.89 | 17.37 | 47.78 | |
| 36 | PN-F | 5 | 94.72 | 91.25 | 86.53 | 80.68 | 73.76 | 65.93 | 57.77 | 49.38 | 43.85 | 41.00 | 33.43 | 65.30 | ||
| 37 | ViT-base | DINO | PN-F | 1 | 87.36 | 80.38 | 72.41 | 63.65 | 54.50 | 45.59 | 37.42 | 29.98 | 25.78 | 23.61 | 18.21 | 48.99 |
| 38 | PN-F | 5 | 95.60 | 92.34 | 87.63 | 82.01 | 75.38 | 67.89 | 60.14 | 52.19 | 47.00 | 43.91 | 36.94 | 67.37 | ||
| 39 | Deit | PN-F | 1 | 84.26 | 77.62 | 70.31 | 62.56 | 54.36 | 46.04 | 60.00 | 51.48 | 26.26 | 23.99 | 18.30 | 52.29 | |
| 40 | PN-F | 5 | 94.61 | 91.31 | 86.77 | 81.30 | 74.79 | 67.32 | 59.36 | 51.09 | 45.57 | 43.03 | 35.61 | 66.43 | ||
| 41 | MAE | PN-F | 1 | 86.47 | 80.60 | 73.68 | 66.14 | 57.94 | 49.35 | 41.06 | 33.18 | 28.50 | 26.04 | 19.93 | 51.17 | |
| 42 | PN-F | 5 | 95.62 | 92.54 | 88.49 | 83.33 | 77.13 | 69.83 | 61.93 | 53.62 | 48.01 | 44.93 | 37.63 | 68.46 | ||
| Method | Shot | Way | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 10 | 20 | 40 | 80 | 160 | 320 | 640 | 1000 | 1280 | 2560 | |||
| ProtoNet | 1 | 86.21 | 78.74 | 70.74 | 61.38 | 52.43 | 43.73 | 35.86 | 28.78 | 24.78 | 22.68 | 17.56 | 47.54 |
| 5 | 95.30 | 91.55 | 86.75 | 80.83 | 74.08 | 66.45 | 58.60 | 50.68 | 45.65 | 42.85 | 35.69 | 66.22 | |
| ProtoNet-Fix | 1 | 86.21 | 78.44 | 70.19 | 61.27 | 52.17 | 43.42 | 35.50 | 28.3555 | 24.41 | 22.35 | 17.26 | 47.23 |
| 5 | 95.30 | 91.55 | 86.64 | 80.68 | 73.90 | 66.25 | 58.37 | 50.41 | 45.34 | 42.57 | 35.43 | 66.04 | |
| SimpleShot | 1 | 85.34 | 77.07 | 68.76 | 59.87 | 50.95 | 42.36 | 34.65 | 27.68 | 23.80 | 21.84 | 16.91 | 46.29 |
| 5 | 95.20 | 91.39 | 86.52 | 80.50 | 73.71 | 66.02 | 58.09 | 50.09 | 45.02 | 42.25 | 35.11 | 65.81 | |
| few-shot-baseline | 1 | 86.21 | 78.59 | 70.47 | 61.32 | 52.30 | 43.57 | 35.77 | 28.68 | 24.68 | 22.60 | 17.49 | 47.43 |
| 5 | 95.30 | 91.55 | 86.70 | 80.75 | 73.99 | 66.35 | 58.54 | 50.61 | 45.57 | 42.78 | 35.62 | 66.16 | |
| P > M > F | 1 | 86.82 | 79.91 | 72.13 | 62.81 | 53.83 | 45.02 | 37.02 | 29.83 | 25.71 | 23.48 | 18.18 | 48.61 |
| 5 | 95.78 | 92.49 | 87.86 | 81.97 | 75.20 | 67.49 | 59.53 | 51.52 | 46.40 | 43.49 | 36.18 | 67.08 | |
| SHA-Pipeline (CPCC) | 1 | 88.24 | 81.59 | 73.60 | 64.25 | 55.31 | 46.38 | 38.23 | 30.98 | 26.83 | 24.40 | 19.02 | 49.89 |
| 5 | 97.06 | 94.00 | 89.18 | 83.27 | 76.54 | 68.71 | 60.62 | 52.55 | 47.41 | 44.32 | 36.93 | 68.24 | |
| SHA-Pipeline (Triplet Loss) | 1 | 89.74 | 82.01 | 73.49 | 63.35 | 53.82 | 44.75 | 36.80 | 29.88 | 26.08 | 23.85 | 18.91 | 49.33 |
| 5 | 97.63 | 94.30 | 89.29 | 83.26 | 76.68 | 69.03 | 61.21 | 52.88 | 47.90 | 44.89 | 37.25 | 68.57 | |
| Method (Backbone) | External | External | CIFAR-FS | MiniImageNet | ||
|---|---|---|---|---|---|---|
| Data | Label | 5w1s | 5w5s | 5w1s | 5w5s | |
| Inductive | ||||||
| ProtoNet (CNN-4-64) [35] | 49.4 | 68.2 | 55.5 | 72.0 | ||
| Baseline++ (CNN-4-64) [40] | 48.2 | 66.4 | ||||
| MetaOpt-SVM (ResNet12) [41] | 72.0 | 84.3 | 61.4 | 77.9 | ||
| Meta-Baseline (ResNet12) [42] | 68.6 | 83.7 | ||||
| RS-FSL (ResNet12) [43] | ✓ | 65.3 | ||||
| Transductive | ||||||
| Fine-tuning (WRN-28-10) [3] | 76.6 | 85.8 | 65.7 | 78.4 | ||
| SIB (WRN-28-10) [44] | 80.0 | 85.3 | 70.0 | 79.2 | ||
| PT-MAP (WRN-28-10) [45] | 87.7 | 90.7 | 82.9 | 88.8 | ||
| CNAPS + FETI (ResNet18) [46] | ✓ | ✓ | 79.9 | 91.5 | ||
| Self-supervised | ||||||
| ProtoNet (WRN-28-10) [47] | 73.6 | 86.1 | 62.9 | 79.9 | ||
| ProtoNet (AMDIM ResNet) [48] | ✓ | 76.8 | 91.0 | |||
| EPNet + SSL (WRN-28-10) [49] | ✓ | 79.2 | 88.1 | |||
| Semi-supervised | ||||||
| LST (ResNet12) [50] | ✓ | 70.1 | 78.7 | |||
| PLCM (ResNet12) [51] | ✓ | 77.6 | 86.1 | 70.1 | 83.7 | |
| ProtoNet (IN1K, IN1K, ViT-Small) | ✓ | 80.7 | 91.8 | 92.5 | 97.7 | |
| SimpleShot (IN1K, ViT-Small) | ✓ | 80.3 | 92.1 | 92.8 | 97.2 | |
| few-shot-baseline (IN1K, ViT-Small) | ✓ | 80.9 | 91.9 | 92.7 | 97.4 | |
| P > M > F (IN1K, ViT-Small) | ✓ | 81.1 | 92.5 | 92.7 | 98.0 | |
| SHA-Pipeline (IN1K, ViT-Small, CPCC) | ✓ | 81.9 | 93.4 | 93.6 | 98.9 | |
| Training Dataset = ImageNet | In-Domian | Cross-Domian | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| INet | Omglot | Acraft | CUB | DTD | QDraw | Fungi | Flower | Sign | COCO | Avg Acc (%) | |
| ProtoNet [28] (RN18) | 50.5 | 59.9 | 53.1 | 68.7 | 66.5 | 48.9 | 39.7 | 85.2 | 47.1 | 41.0 | 56.1 |
| ALFA+FP-MAML [52] (RN12) | 52.8 | 61.8 | 63.4 | 69.7 | 70.7 | 59.1 | 41.4 | 85.9 | 60.7 | 48.1 | 61.4 |
| BOHB [53] (RN18) | 51.9 | 67.5 | 54.1 | 70.6 | 68.3 | 50.3 | 41.3 | 87.3 | 51.8 | 48.0 | 59.1 |
| CTX [29] (RN34) | 62.7 | 82.2 | 79.4 | 80.6 | 75.5 | 72.6 | 51.8 | 95.3 | 82.6 | 59.9 | 74.2 |
| ProtoNet (DINO/IN1K, ViT-small) | 74.3 | 80.3 | 76.0 | 84.2 | 84.9 | 69.8 | 54.2 | 93.6 | 87.9 | 62.3 | 76.8 |
| SimpleShot (DINO/IN1K, ViT-small) | 73.2 | 79.1 | 76.4 | 84.6 | 85.8 | 70.5 | 53.7 | 92.7 | 87.4 | 61.9 | 76.5 |
| few-shot-baseline (DINO/IN1K, ViT-small) | 74.3 | 80.3 | 75.6 | 83.8 | 86.6 | 71.2 | 54.8 | 94.6 | 87.0 | 61.6 | 77.0 |
| P > M > F (DINO/IN1K, ViT-small) | 74.7 | 80.7 | 76.8 | 85.0 | 86.6 | 71.3 | 54.8 | 94.6 | 88.3 | 62.6 | 77.5 |
| SHA-Pipeline (DINO/IN1K, ViT-small, CPCC) | 75.4 | 81.5 | 77.5 | 85.9 | 87.5 | 72.0 | 55.3 | 95.2 | 89.2 | 63.2 | 78.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Yang, W.; Wang, H.; Chi, H.; Lan, L. A Closer Look at Few-Shot Classification with Many Novel Classes. Appl. Sci. 2024, 14, 7060. https://doi.org/10.3390/app14167060
Lin Z, Yang W, Wang H, Chi H, Lan L. A Closer Look at Few-Shot Classification with Many Novel Classes. Applied Sciences. 2024; 14(16):7060. https://doi.org/10.3390/app14167060
Chicago/Turabian StyleLin, Zhipeng, Wenjing Yang, Haotian Wang, Haoang Chi, and Long Lan. 2024. "A Closer Look at Few-Shot Classification with Many Novel Classes" Applied Sciences 14, no. 16: 7060. https://doi.org/10.3390/app14167060