
Target-Oriented Multi-Agent Coordination with Hierarchical Reinforcement Learning


Abstract
:1. Introduction
2. Related Work
3. Preliminaries
3.1. Reinforcement Learning
- is a n-dimensional state space;
- is a m-dimensional action space;
- is a transition probability function;
- is reward function;
- is the discount f.
3.2. Actor–Critic Method
3.3. Multi-Agent Deep Deterministic Policy Gradient
4. Method
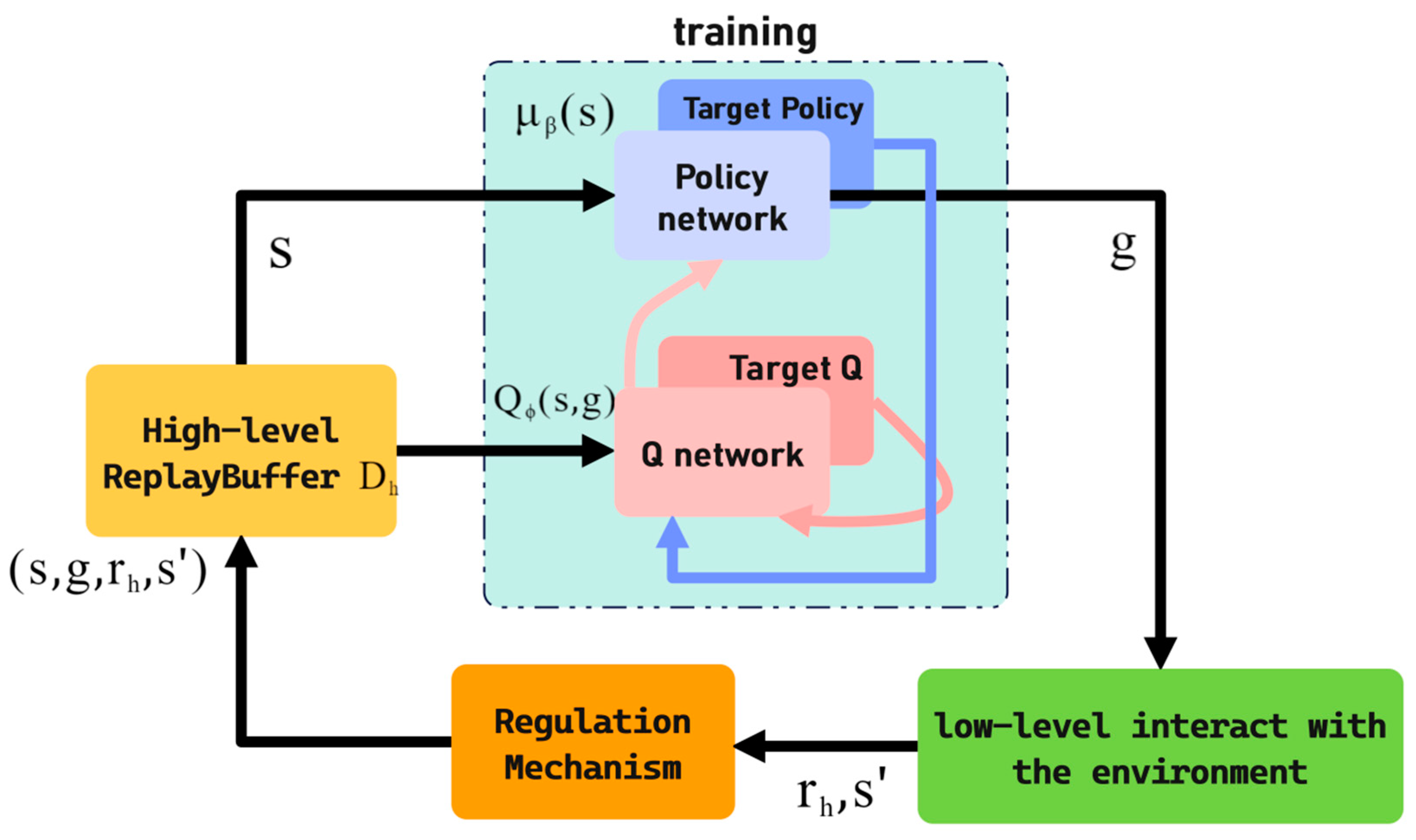
4.1. Mechanism Description
- (1)
- High-Level Policy (Symbol 1): The high-level policy is responsible for target allocation. It considers the overall state of the environment and assigns targets to agents. This level focuses on global coordination and strategic planning, ensuring that each agent is directed towards a target that optimizes the overall system performance.
- (2)
- Low-Level Policy (Symbol 2): The low-level policy deals with the execution of actions. Based on the assigned targets and local observations, agents choose primitive actions. This level emphasizes local decision-making and immediate interactions with the environment.
- (1)
- Both Regulation Mechanism: This mechanism aims to stabilize the training process by reducing the high-level policy’s dependence on modifications in low-level behavior. By implementing a regularization term in the reward function, we ensure that the high-level policy remains robust despite the dynamic changes at the low-level. This helps maintain consistent learning and prevents the high-level policy from being adversely affected by the non-stationarity of the low-level policies.
- (2)
- Target-Conditioned Filter: The target-conditioned filter helps in refining the action selection process by incorporating target-specific information into the decision-making framework. This filter ensures that the actions chosen by the low-level policy are more aligned with the high-level targets, thus improving coordination and efficiency. By conditioning on the target, the filter reduces the variability in low-level actions, leading to more predictable and stable transitions, which in turn enhances the performance of the high-level policy.
4.2. High-Level Target Assignment
4.3. Low-Level Primitive Action
4.4. Regulation Mechanism
| Algorithm 1 Regulation Mechanism |
| Input: the state information s and target assignation g Output: estimated high-level reward rh 1: Initialize the number of the action d, reward rh |
| 2: Initialize the dynamic programming array dp Given the action function act(.), counting function cnt(.) and reward function r(.) |
| 3: for i := 1 → n do |
| 4: for j := 1 → d do |
| 5: Compute the tracking status mask in act(i,j) |
| 6: for k := 1 → d do |
| 7: if i = 0 then |
| 8: |
| 9: else |
| 10: |
| 11: |
| 12: end if |
| 13: end if |
| 14: end for |
| 15: end for |
| 16: end for |
| 17: for i := 1 → n do |
| 18: |
| 19: end for |
| 20: return rh |
| Algorithm 2 RHMC Method |
| for episode := 1 → M do |
| 2: Initialize a random process for action exploration |
| Receive initial state x |
| 4: for t := 1 → max-episode-length do do |
| The highlevel outputs target assignment policy |
| 6: For each agent i, select action w.r.t the current policy and exploration after filtering treatment g by using 0. |
| Execute action a = (a1, …, aN) and observe lowlevel reward rl, high-level reward rh and new state |
| 8: Store in replay buffer Bl |
| Regulate high-level rewards rh by using Algorithm 1 |
| 10: Store in replay buffer Bh |
| 12: for agent := 1 → N do |
| Sample a random minibatch of Dl samples from Bl |
| 14: Update critic by minimizing the 0 |
| Update actor using the sampled policy gradient in 0 |
| 16: Update target network parameters for agent 0 |
| end for |
| 18: Sample a random minibatch of Dh samples from Bh |
| Update high-level critic by minimizing the 0 |
| 20: Update low-level actor by 0 |
| Update target network parameters using 0 |
| 22: end for |
| end for |
| 24: return |
5. Experiments
5.1. Environmental Settings
5.2. Results and Comparisons
5.3. Ablation Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yun, W.J.; Ha, Y.J.; Jung, S.; Kim, J. Autonomous aerial mobility learning for drone-taxi flight control. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; IEEE: Piscataway, NJ, USA; pp. 329–332. [Google Scholar]
- Wang, X.; Krasowski, H.; Althoff, M. Commonroad-rl: A configurable reinforcement learning environment for motion planning of autonomous vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–14 July 2021; pp. 466–472. [Google Scholar]
- Peng, S.; Xiong, Y. A new sensing direction rotation approach to area coverage optimization in directional sensor network. J. Adv. Comput. Intell. Intell. Inform. 2020, 24, 206–213. [Google Scholar] [CrossRef]
- Mason, F.; Chiariotti, F.; Zanella, A.; Popovski, P. Multi-agent reinforcement learning for coordinating communication and control. IEEE Trans. Cogn. Commun. Netw. 2024. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; PMLR: Breckenridge, CO, USA; pp. 387–395. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Ye, D.; Liu, Z.; Sun, M.; Shi, B.; Zhao, P.; Wu, H.; Yu, H.; Yang, S.; Wu, X.; Guo, Q.; et al. Mastering complex control in MOBA games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6672–6679. [Google Scholar]
- Chebotar, Y.; Hausman, K.; Lu, Y.; Xiao, T.; Kalashnikov, D.; Varley, J.; Irpan, A.; Eysenbach, B.; Julian, R.; Finn, C.; et al. Actionable models: Unsupervised offline reinforcement learning of robotic skills. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, 18–24 July 2021. [Google Scholar]
- Chen, H. Robotic manipulation with reinforcement learning, state representation learning, and imitation learning (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar]
- Gao, H.; Huang, W.; Liu, T.; Yin, Y.; Li, Y. PPO2: Location privacy-oriented task offloading to edge computing using reinforcement learning for intelligent autonomous transport systems. IEEE Trans. Intell. Transp. Syst. 2022, 24, 7599–7612. [Google Scholar] [CrossRef]
- Wang, X.; Hu, J.; Lin, H.; Garg, S.; Kaddoum, G.; Jalilpiran, M.; Hossain, M.S. QoS and privacy-aware routing for 5G enabled industrial internet of things: A federated reinforcement learning approach. IEEE Trans. Ind. Inform. 2022, 18, 4189–4197. [Google Scholar] [CrossRef]
- Zhong, K.; Yang, Z.; Xiao, G.; Li, X.; Yang, W.; Li, K. An efficient parallel reinforcement learning approach to cross-layer defense mechanism in industrial control systems. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 2979–2990. [Google Scholar] [CrossRef]
- Krnjaic, A.; Thomas, J.D.; Papoudakis, G.; Schäfer, L.; Børsting, P.; Albrecht, S.V. Scalable multi-agent reinforcement learning for warehouse logistics with robotic and human co-workers. arXiv 2022, arXiv:2212.11498. [Google Scholar]
- Zhang, R.; Zong, Q.; Zhang, X.; Dou, L.; Tian, B. Game of drones: Multi-UAV pursuit-evasion game with online motion planning by deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7900–7909. [Google Scholar] [CrossRef]
- Yun, J.; Goh, Y.; Yoo, W.; Chung, J.-M. 5G multi-RAT URLLC and eMBB dynamic task offloading with MEC resource allocation using distributed deep reinforcement learning. IEEE Internet Things J. 2022, 9, 20733–20749. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent cooperation and competition with deep reinforcement learning. PLoS ONE 2017, 12, e0172395. [Google Scholar] [CrossRef] [PubMed]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 7234–7284. [Google Scholar]
- Ma, T.; Peng, K.; Rong, H.; Qian, Y.; Al-Nabhan, N. Hierarchical coordination multi-agent reinforcement learning with spatio-temporal abstraction. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 533–545. [Google Scholar] [CrossRef]
- Gui, Y.; Zhang, Z.; Tang, D.; Zhu, H.; Zhang, Y. Collaborative dynamic scheduling in a self-organizing manufacturing system using multi-agent reinforcement learning. Adv. Eng. Inform. 2024, 62, 102646. [Google Scholar] [CrossRef]
- Xie, S.; Li, Y.; Wang, X.; Zhang, H.; Zhang, Z.; Luo, X.; Yu, H. Hierarchical relationship modeling in multi-agent reinforcement learning for mixed cooperative–competitive environments. Inf. Fusion 2024, 108, 102318. [Google Scholar] [CrossRef]
- Geng, M.; Pateria, S.; Subagdja, B.; Tan, A.-H. HiSOMA: A hierarchical multi-agent model integrating self-organizing neural networks with multi-agent deep reinforcement learning. Expert. Syst. Appl. 2024, 252, 124117. [Google Scholar] [CrossRef]
- Tang, Y.; Sun, J.; Wang, H.; Deng, J.; Tong, L.; Xu, W. A method of network attack-defense game and collaborative defense decision-making based on hierarchical multi-agent reinforcement learning. Comput. Secur. 2024, 142, 103871. [Google Scholar] [CrossRef]
- Xi, J.; Wang, C.; Yang, X.; Yang, B. Limited-budget output consensus for descriptor multiagent systems with energy constraints. IEEE Trans. Cybern. 2020, 50, 4585–4598. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, G.; Zhang, S.; Li, C. A knowledge-based approach for multiagent collaboration in smart home: From activity recognition to guidance service. IEEE Trans. Instrum. Meas. 2019, 69, 317–329. [Google Scholar] [CrossRef]
- Tian, Y.; Zheng, B.; Wang, Y.; Zhang, Y.; Wu, Q. College library personalized recommendation system based on hybrid recommendation algorithm. Procedia CIRP 2019, 83, 490–494. [Google Scholar] [CrossRef]
- Pérolat, J.; Leibo, J.Z.; Zambaldi, V.F.; Beattie, C.; Tuyls, K.; Graepel, T. A multi-agent reinforcement learning model of common-pool resource appropriation. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Feehan, G.; Fatima, S.S. Augmenting reinforcement learning to enhance cooperation in the iterated prisoner’s dilemma. In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART), Vienna, Austria, 3–5 February 2022. [Google Scholar]
- Li, S.; Wu, Y.; Cui, X.; Dong, H.; Fang, F.; Russell, S.J. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of MAPPO in cooperative multi-agent games. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, 18–24 July 2021. [Google Scholar]
- Zhang, C.; Tian, Y.; Zhang, Z.; Xue, W.; Xie, X.; Yang, T.; Ge, X.; Chen, R. Neighborhood cooperative multiagent reinforcement learning for adaptive traffic signal control in epidemic regions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25157–25168. [Google Scholar] [CrossRef]
- Foerster, J.N.; Chen, R.Y.; Al-Shedivat, M.; Whiteson, S.; Abbeel, P.; Mordatch, I. Learning with opponent-learning awareness. arXiv 2017, arXiv:1709.04326. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.F.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Chen, M.; Li, Y.; Wang, E.; Yang, Z.; Wang, Z.; Zhao, T. Pessimism meets invariance: Provably efficient offline mean-field multi-agent RL. Adv. Neural Inf. Process. Syst. 2021, 34, 17913–17926. [Google Scholar]
- Xu, X.; Li, R.; Zhao, Z.; Zhang, H. Stigmergic independent reinforcement learning for multiagent collaboration. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4285–4299. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Nam, W.; Kim, H.; Kim, J.-H.; Kim, G. Curiosity-bottleneck: Exploration by distilling task-specific novelty. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; PMLR: Breckenridge, CO, USA; pp. 3379–3388. [Google Scholar]
- Kulkarni, T.D.; Narasimhan, K.; Saeedi, A.; Tenenbaum, J. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Eysenbach, B.; Gupta, A.; Ibarz, J.; Levine, S. Diversity is all you need: Learning skills without a reward function. arXiv 2018, arXiv:1802.06070. [Google Scholar]
- Xu, J.; Zhong, F.; Wang, Y. Learning multi-agent coordination for enhancing target coverage in directional sensor networks. Adv. Neural Inf. Process. Syst. 2020, 33, 10053–10064. [Google Scholar]
- Van Otterlo, M.; Wiering, M. Reinforcement learning and Markov decision processes. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar]
- Grondman, I.; Busoniu, L.; Lopes, G.A.D.; Babuska, R. A survey of actor-critic reinforcement learning: Standard and natural policy gradients. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef]
- Nachum, O.; Norouzi, M.; Xu, K.; Schuurmans, D. Bridging the gap between value and policy based reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Fontanesi, L.; Gluth, S.; Spektor, M.S.; Rieskamp, J. A reinforcement learning diffusion decision model for value-based decisions. Psychon. Bull. Rev. 2019, 26, 1099–1121. [Google Scholar] [CrossRef] [PubMed]
- Ghavamzadeh, M.; Mahadevan, S.; Makar, R. Hierarchical multi-agent reinforcement learning. Auton. Agents Multi-Agent. Syst. 2006, 13, 197–229. [Google Scholar] [CrossRef]
- Yang, J.; Borovikov, I.; Zha, H. Hierarchical Cooperative Multi-Agent Reinforcement Learning with Skill Discovery. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), Auckland, New Zealand, 9–13 May 2020. [Google Scholar]
- Loo, Y.; Gong, C.; Meghjani, M. A Hierarchical Approach to Population Training for Human-AI Collaboration. In Proceedings of the 32nd International Joint Conference on Artificial Intelligence (IJCAI), Macau, China, 19–25 August 2023. [Google Scholar]
- Ibrahim, M.; Fayad, A. Hierarchical Strategies for Cooperative Multi-Agent Reinforcement Learning. arXiv 2022, arXiv:2206.12345. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | Key Features | Addressed Issues | Application Scenarios | RHMC Advantages |
|---|---|---|---|---|
| MADDPG | Deep RL method with deterministic gradients; focuses on stability via centralized training and decentralized execution. | Enhances stability in dynamic, continuous action spaces. | Suitable for robotic collaboration and autonomous fleets. | Boosts robustness in continuous action environments. |
| CTDE | Combines centralized training with decentralized execution to tackle environmental non-stationarity. | Improves stability by addressing learning issues from independent agent actions. | Ideal for cooperative multi-agent systems like intelligent traffic. | Resolves non-stationarity in multi-agent learning effectively. |
| QMIX | Integrates agent value functions using a mixing network for consistent policy updates; includes global information. | Ensures consistent policies and cooperation, managing update conflicts. | Used in complex scenarios requiring consistent policies, such as multiplayer games. | Provides a novel method for enhancing policy consistency and cooperation. |
| RHMC | Introduces a clear hierarchical structure, explicitly handling both local and global coordination needs. Focuses on structured exploration and policy optimization. | Enhances coordination between local and global tasks in multi-agent systems, optimizing overall task performance. | Applicable to multi-agent environments requiring complex coordination and efficient execution. |
| Method | Final Reward | Performance Improvement |
|---|---|---|
| Full RHMC | 70.5 | N/A |
| Without regulation mechanism | 35.6 | 50.9% |
| Without target-conditioned filter | 55.1 | 21.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Zhai, Z.; Li, W.; Ma, J. Target-Oriented Multi-Agent Coordination with Hierarchical Reinforcement Learning. Appl. Sci. 2024, 14, 7084. https://doi.org/10.3390/app14167084
Yu Y, Zhai Z, Li W, Ma J. Target-Oriented Multi-Agent Coordination with Hierarchical Reinforcement Learning. Applied Sciences. 2024; 14(16):7084. https://doi.org/10.3390/app14167084
Chicago/Turabian StyleYu, Yuekang, Zhongyi Zhai, Weikun Li, and Jianyu Ma. 2024. "Target-Oriented Multi-Agent Coordination with Hierarchical Reinforcement Learning" Applied Sciences 14, no. 16: 7084. https://doi.org/10.3390/app14167084