Abstract
This paper describes a multistage framework for face image analysis in computer-aided speech diagnosis and therapy. Multimodal data processing frameworks have become a significant factor in supporting speech disorders’ treatment. Synchronous and asynchronous remote speech therapy approaches can use audio and video analysis of articulation to deliver robust indicators of disordered speech. Accurate segmentation of articulators in video frames is a vital step in this agenda. We use a dedicated data acquisition system to capture the stereovision stream during speech therapy examination in children. Our goal is to detect and accurately segment four objects in the mouth area (lips, teeth, tongue, and whole mouth) during relaxed speech and speech therapy exercises. Our database contains 17,913 frames from 76 preschool children. We apply a sequence of procedures employing artificial intelligence. For detection, we train the YOLOv6 (you only look once) model to catch each of the three objects under consideration. Then, we prepare the DeepLab v3+ segmentation model in a semi-supervised training mode. As preparation of reliable expert annotations is exhausting in video labeling, we first train the network using weak labels produced by initial segmentation based on the distance-regularized level set evolution over fuzzified images. Next, we fine-tune the model using a portion of manual ground-truth delineations. Each stage is thoroughly assessed using the independent test subset. The lips are detected almost perfectly (average precision and F1 score of 0.999), whereas the segmentation Dice index exceeds 0.83 in each articulator, with a top result of 0.95 in the whole mouth.
1. Introduction
Speech disorders form a significant social problem as they can mean the individual is alienated, rejected by peers, or handicapped in the labor market [1]. The earlier speech therapy starts, the higher the chance for recovery. Thus, proper screening and treatment seem essential in children as young as four or even earlier [2]. Conventional therapy highly depends on speech and language pathologists’ (SLPs’) availability. As this remains an issue in many countries, e.g., in rural areas in the United States [3], Australia [4], or Poland [5], each attempt to provide an advanced speech pathology screening tool is welcome. One way to do so is to use remote consultations with the SLP. Such solutions have become more popular recently, also due to the restrictions related to the COVID-19 outbreak [6,7]. However, the development of automated or semi-automated computer-aided speech diagnosis (CASD) methods is also an option, with access to reliable and fast telemedicine solutions and personal devices enabling easy audio and video data acquisition. CASD follows the computer-aided diagnosis (CAD) concept in medicine, focusing on speech-related areas [8]. CAD systems use advanced computer methods to analyze and process medical data. An extensive subset of CAD employs medical imaging in terms of detection, classification, segmentation, or recognition [9,10,11]. Depending on the task, multimodal systems are increasingly expected to make the diagnosis as objective as possible [12]. There has been continuous research interest in CAD development for a long time due to its proven effectiveness and positive impact on specialist work [12,13]. CASD systems use speech-related data to support experts in decision making through a numerical description of cases, visualizations, suggestions of disorders, etc. Diagnosis based on visual observation by an SLP requires experience, yet specific patterns are difficult to notice and differ between speakers. CASD tools might indicate areas for in-depth examination or reassure specialists in the decision and possible direction of therapy.
The speech diagnosis relies mainly on the articulators’ observation (lips, tongue, mandible, and soft palate). Recent attempts to support the examinations and describe the articulation phenomena in normative and disordered speech involve various data types. Some offer high spatial and temporal accuracy for the price of invasiveness or considerable experimental requirements or cost. This refers to, e.g., the electromagnetic articulography [14,15] used to track the articulators in the alternating magnetic field, electropalatography [16,17] monitoring the tongue–palate contact during pronunciation, or magnetic resonance imaging [18,19]. Many researchers intuitively employ the audio signal recorded in various setups by single or multiple microphones [20,21,22,23,24,25]. The idea of using a non-invasive and readily available video of relevant face regions is another attempt to support the SLP’s work. Solutions proposed in this paper follow strict recording protocols, providing repeatable circumstances and results. However, with today’s development of robust image analysis algorithms driven by deep learning concepts, implementing our findings into less standardized recordings, e.g., from remote diagnostic consultations, can be considered a natural step further.
Recent studies cover both synchronous and asynchronous remote speech therapy approaches. The synchronous mode mainly refers to the video conferences of a therapist and a patient using laptops or smartphones. Such remote therapy is considered comparable to the stationary examination [3,26,27,28]. The asynchronous mode is more useful in treatment than diagnosis. It uses dedicated web platforms to provide patients with online exercises prepared by the SLP based on their prior diagnosis [29,30,31]. In both cases, there is great potential for collecting data to design tools for computerized speech and hearing diagnosis methods, including initial assessment of selected disorders [20,32,33,34,35,36,37]. Additionally, the SLPs often use smartphone-recorded videos during the in-person examinations to document their findings, enable later verification, or monitor the therapy progress. Even though such hand-held recordings can be labile or have low quality in audio or video, they still can be considered helpful in automated diagnosis support.
The non-invasiveness and easy application of audio and video recording open perspectives for hybrid frameworks. Each source delivers data with its own indicators of speech disorders. If synchronized and merged, they can improve the inference and eventual diagnosis [38]. The hybridization of input data and their confrontation with SLP annotations of normal and disordered articulation features support the underlying goal of our research project: finding, describing, and exploiting knowledge on the relationships between articulation, acoustics, and face imaging in preschool children. Here, we focus on image analysis to accurately detect and segment relevant articulators: lips, teeth, tongue, and the whole mouth. Segmentation of articulators is the essential step towards a quantitative description of visual aspects of pronunciation. We believe monitoring the mouth area dynamics can bring valuable indicators of speech disorders. It can be performed by using object features describing the appearance, shape, size, or texture of articulators, which leads us back to the issue of reliable segmentation. The visual findings can essentially enrich the CASD research, which relies mainly on the acoustics so far. We aim to prepare extensive data collection and methods to link face imaging, acoustics, and articulation SLP diagnoses.
Visual face observation and analysis methods are present in both scientific literature and commercial solutions. The range of motives covers automatic speech recognition and lip reading, computer-aided strategies for dental issues, rehabilitation, or health monitoring purposes. Just a few works concern computer-aided speech diagnosis and therapy. Canonic studies on mouth or lip segmentation investigated various state-of-the-art methods, e.g., expectation-maximization-based unsupervised clustering [39], shape-based fuzzy clustering [40,41], or multi-scale wavelet edge detection [42]. Several valuable studies have been proposed for mouth/lip segmentation in the last three years, mostly taking advantage of deep learning concepts. None of them were dedicated directly to supporting child speech pathology diagnosis, yet the scope of the analysis is somehow coherent with our goals. Müller et al. [43] used a deep architecture to segment the infrared thermal image of the entire face into nine classes, including the mouth. Their framework was based on a multiclass U-Net encapsulated by the conditional generative adversarial network (cGAN). The average mouth segmentation intersection-over-union (IoU) was below 0.7 (corresponding to a Dice similarity coefficient of ca. 0.82). Two recent studies focused on video-based word recognition from lip motion. Birara and Gebremeskel [44] proposed a multistage lip motion detector as a part of a framework for classifying Amharic words. They used machine learning tools for classification, yet the segmentation relied on more traditional methods: Viola–Jones-based object detection, contrast enhancement, Sobel edge detection, and thresholding. The classification was based on a set of hand-crafted geometric and hybrid features. The overall accuracy over a collection of 14 words reached 66.43% using a support vector machine (SVM); the study does not report mouth segmentation efficiency. Miled et al. [45] designed a spatiotemporal model for lip segmentation in a sequence of video frames using a combination of CNNs and bi-directional gated recurrent units (Bi-GRUs). Their approach was also supported by preprocessing for the initial mouth and lip localization through the Haar cascade classifier and hybrid active contours. Again, the authors focused on quantitative word recognition results (accuracy over 90% in a public database of BBC TV segments), limiting the mouth segmentation assessment to some illustrations. Chotikkakamthorn et al. [46] used deep architectures to segment lips in two extensive image databases. Based on the experiments over nine different state-of-the-art networks, they selected the Mobile DeepLabV3 model as the core of their methodology. Depending on the test dataset, the lip segmentation Dice index balanced around a notable value of 0.93.
On the other hand, the list of studies addressing teeth or tongue segmentation in color images is significantly shorter. Teeth analysis is almost absent in the field, except as a minor part of more general face image research [47,48], practically without reliable numerical assessment. Tongue segmentation is often conducted in a highly specific area, where the tongue’s behavior hardly retains its motion during ordinary speech, e.g., traditional Chinese medicine (TCM) [49,50,51,52]. In such cases, a large part of the tongue has to be clearly visible in the central part of the picture, sticking out of the mouth, and the segmentation IoU may reach 0.97 [50,52]. Instead, the tongue is mostly hidden behind the teeth or lips during pronunciation. Among individual studies addressing tongue segmentation for speech therapy, the research of Bílková’s team seems very promising [53,54] with the use of deep models like U-Net. Still, their methods for segmenting the tongue, lips, and teeth were not assessed quantitatively, so we can hardly refer to the results. Our preliminary attempt to analyze the tongue [55] was targeted strictly at segmentation in a dedicated setup, using well-illuminated high-resolution videos. Our CNN trained from scratch produced segmentation outcomes highly dependent on the object size (visibility), with a mean IoU reaching 0.74.
In this study, we aim to prepare the tool for the automated analysis of images of the speaker’s face during pronunciation. Our wearable multimodal data acquisition device containing two cameras can capture the unobstructed frontal view of the extended mouth area from a distance not exceeding 15 cm. A stereovision system can allow a more comprehensive observation of the speaker’s articulation organs during pronunciation through 3D scene mapping based on a pair of cameras. Stereoscopic vision reflects the depth of the observed scenes and is how humans perceive reality. To our knowledge, our study [38] is the first report on implementing this idea in the articulation data. It generates a 4D multimodal speaker model based on a 3D point cloud textured with camera images and spatial acoustic signals. The segmentation of articulators can bring additional information to improve the model and provide foundations for quantitative support of the diagnosis. During the recording sessions, we collected a database containing stereo recordings from 76 children aged four to seven (36 girls and 40 boys). With a total of 17,913 single-view frames, we propose a multistage framework to design a model for automated segmentation of selected articulators: lips, teeth, tongue, and the entire mouth region. In the model, we merge two deep networks: YOLOv6 (you only look once) for object detection [56], and DeepLab v3+ for semantic segmentation [57,58]. Semi-supervised learning of the deep segmentation model is our attempt to overcome the time-consuming problem of preparing ground-truth delineations over an extensive image dataset. It is performed in two steps and involves a dedicated initial segmentation method based on a distance-regularized level set evolution producing weak ground-truth data for the initial training. The network is then fine-tuned using a small portion of data delineated manually by an expert. The segmentation Dice index exceeds 0.83 in each articulator, with a top result of 0.95 in the whole mouth. Such results are promising for a more in-depth speech disorder analysis of the mouth area, including shape and texture analysis, to be conducted and correlated to the corresponding data on articulation and acoustics.
The paper is organized as follows. After the introduction in Section 1, the data acquisition equipment, image specification, and database management are shown in Section 2. Section 3 describes the methodology in detail, including the specification of deep structures and training procedures involving initial level set-based segmentation. In Section 4, we explain the experiments and provide the quantitative evaluation of the relevant stages of the workflow. Section 5 discusses the methodology and results, with an overview of future development directions regarding CASD, while Section 6 concludes the manuscript.
2. Materials
2.1. Data Acquisition Equipment
The image data analyzed in this study were collected using a multimodal data acquisition device described in detail in [38]. It records the audio signal from fifteen spatially distributed channels (a semicylindrical microphone array) and captures the video data using a stereovision module (Figure 1). Before the recording session, the device is safely and comfortably placed on the speaker’s head. The operator can reposition its mobile part to adjust the distance from the sound source to the sensors. We prepared a dedicated adjustment interface to secure repeatable interspeaker and intraspeaker data acquisition.

Figure 1.
The multimodal data acquisition device [38].
Each of the three audio measuring arcs uses five electret microphones with omnidirectional characteristics. The resulting fifteen signals are recorded at a 44.1 kHz sampling rate and synchronized in time. Two Arducam 8MP 1080P Auto Focus cameras [59] installed between two bottom measuring arcs produce the data for our study. The video stream shows an unobstructed view of the articulators during pronunciation from a distance of ca. 15 cm. Both streams are captured at 30 frames per second with a 480 × 640 resolution each. The picture is relatively stable regardless of head movements as the device is attached to the head. Our previous research used stereo data to produce depth maps and point clouds for a speaker face model generation [38]. The data are part of a public PAVSig dataset (Polish Audio-Visual child speech dataset for computer-aided diagnosis of sigmatism) [60]. Here, we focus on image analysis to segment the mouth region.
2.2. Image Dataset Management
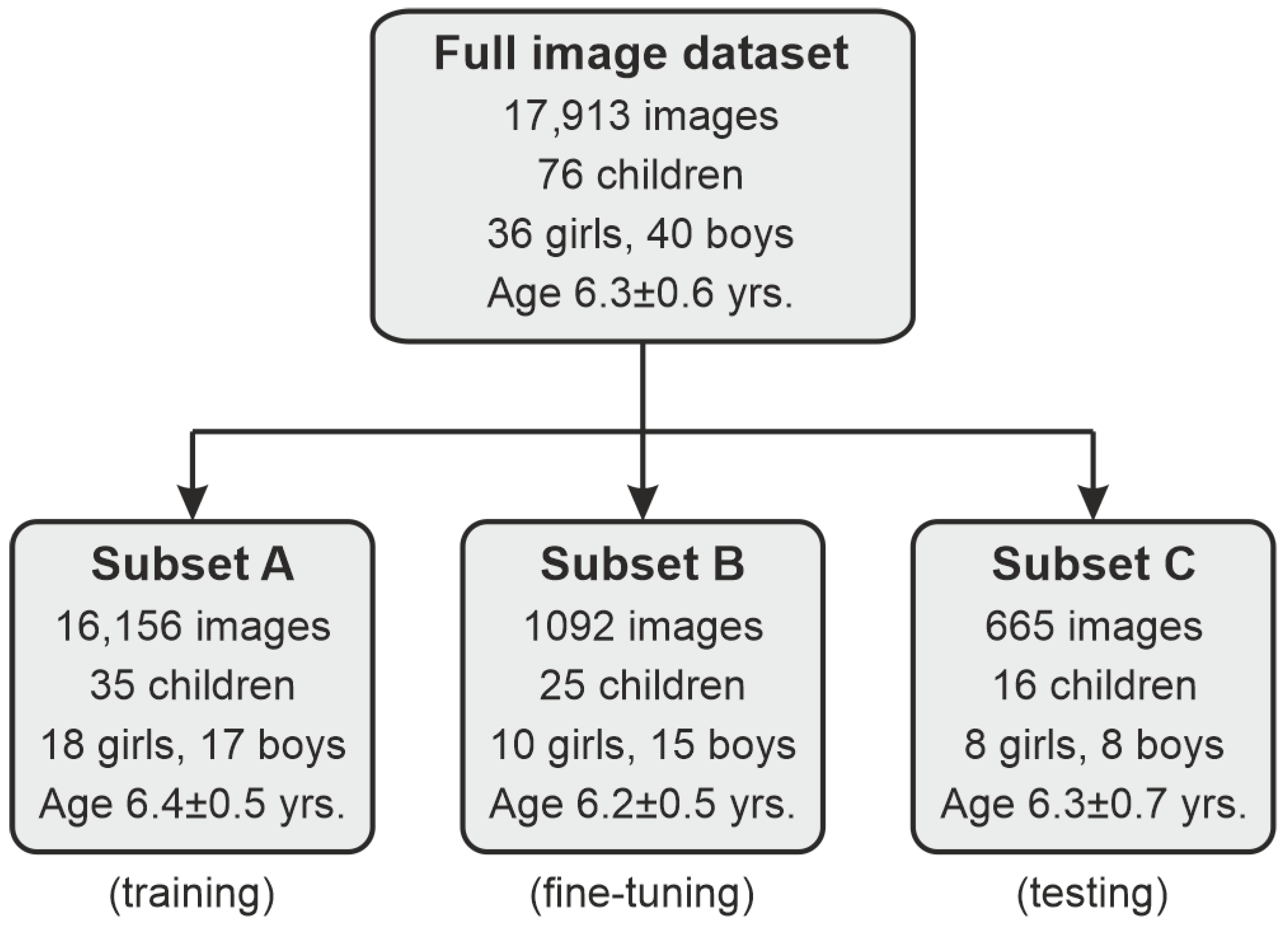
To design and validate our methodology, we used a total of 17,913 frames produced by the video system described in Section 2.1 from 76 children (36 girls and 40 boys) aged four to seven (a mean of ). To secure dataset diversity, we randomly selected an image from either the left or right camera from each stereo shot, so there are no two views in the dataset captured at the exact moment. Since the selection probability was 50%, we obtained an approximately equal number of left/right views in the dataset. The frames were recorded during relaxed speech and speech therapy exercises. As individual processing stages require different image data, we prepared dedicated procedures for the data preparation and dataset partitioning (Figure 2):
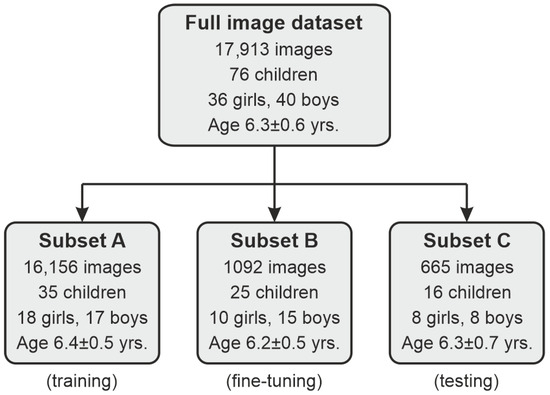
Figure 2.
Illustration of the image dataset management.
- First, we took a portion of 665 images from 16 speakers (8 girls/8 boys; mean age of yrs.) for testing purposes (subset C).
- Another subset (B) consisting of 1092 frames from 25 speakers (10 girls/15 boys; yrs.) was extracted for manual expert delineations for fine-tuning the segmentation model (note Section 3.3.2).
- The remaining subset A of 16,156 frames from 35 children (18 girls/17 boys; yrs.) constituted a base training and validation collection for our processing pipeline.
In each partition, we took care of the speaker-wise division, i.e., the data from a single child were present in one subset only. The distribution of frames per child in subsets A–C is given in Table 1.

Table 1.
Class distribution in the datasets.
2.3. Expert Delineations
Depending on the purpose and subset, we prepared ground-truth manual delineations for training and testing. In object detection, that referred to bounding-box-type objects for each of the three classes: lips, teeth, and tongue (Figure 3a) in each subset A–C. The lips/mouth were present in almost all frames (except for some cases where they were covered with a hand), whereas the teeth and tongue appeared in a limited number of images (Table 1). For image segmentation, each object was manually contoured (Figure 3b), but only in subsets B and C. Delineations of both types were prepared using Matlab, including the Image Labeller App. The expert manually drew either bounding boxes or contours of objects of corresponding classes appearing in the frame.
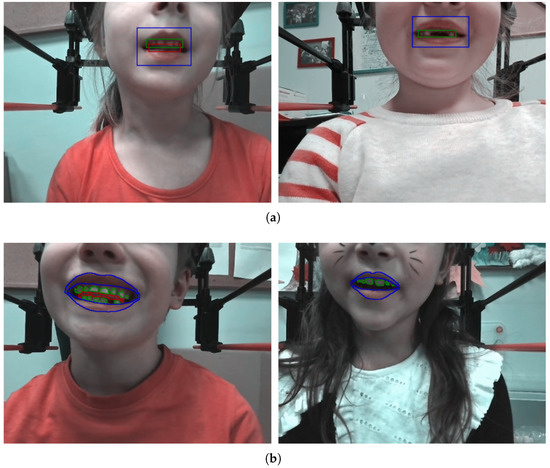
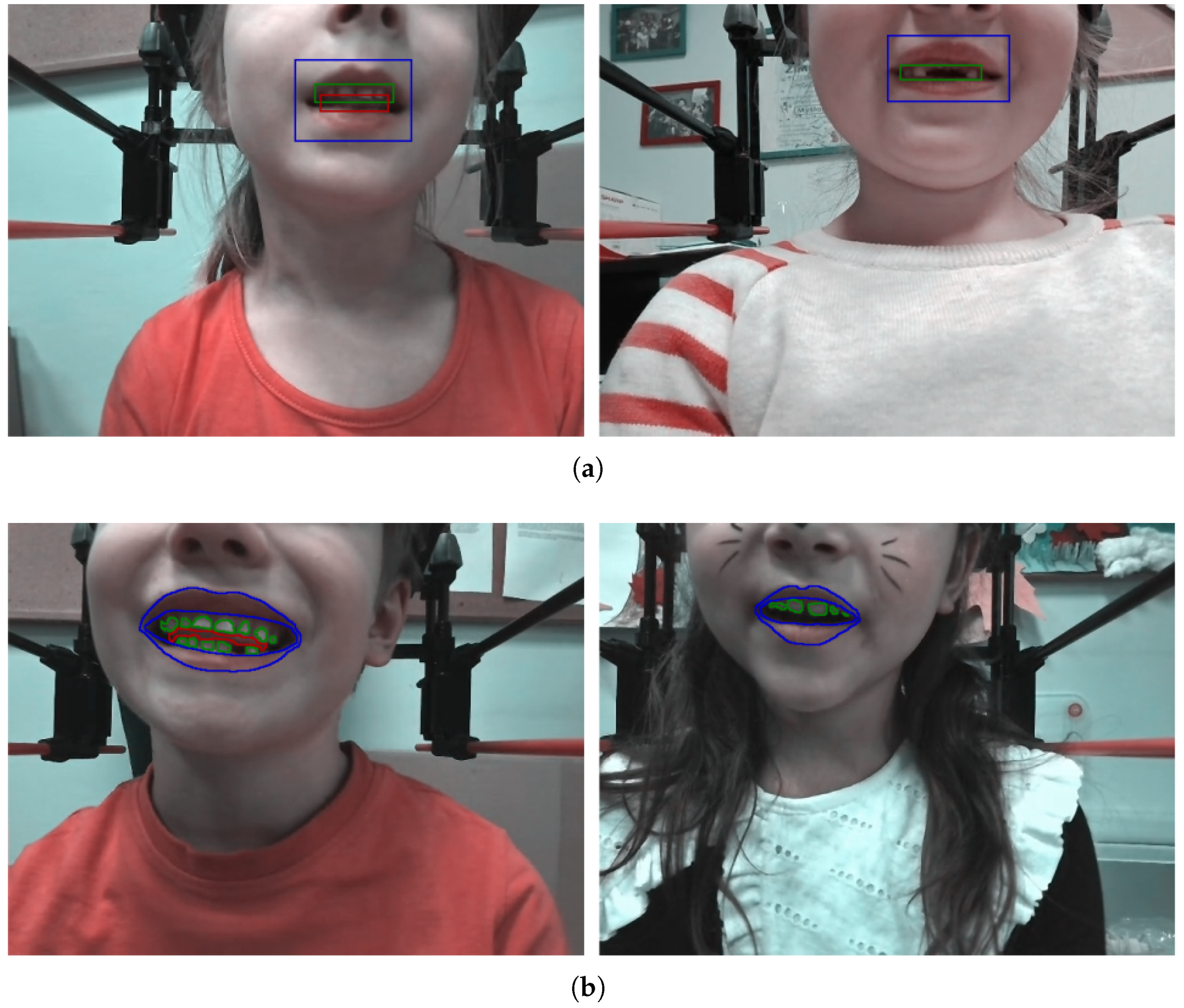
Figure 3.
Sample frames with manual delineation for object detection (a) and segmentation (b). The lips are marked in blue, the teeth in green, and the tongue in red.
3. Methods
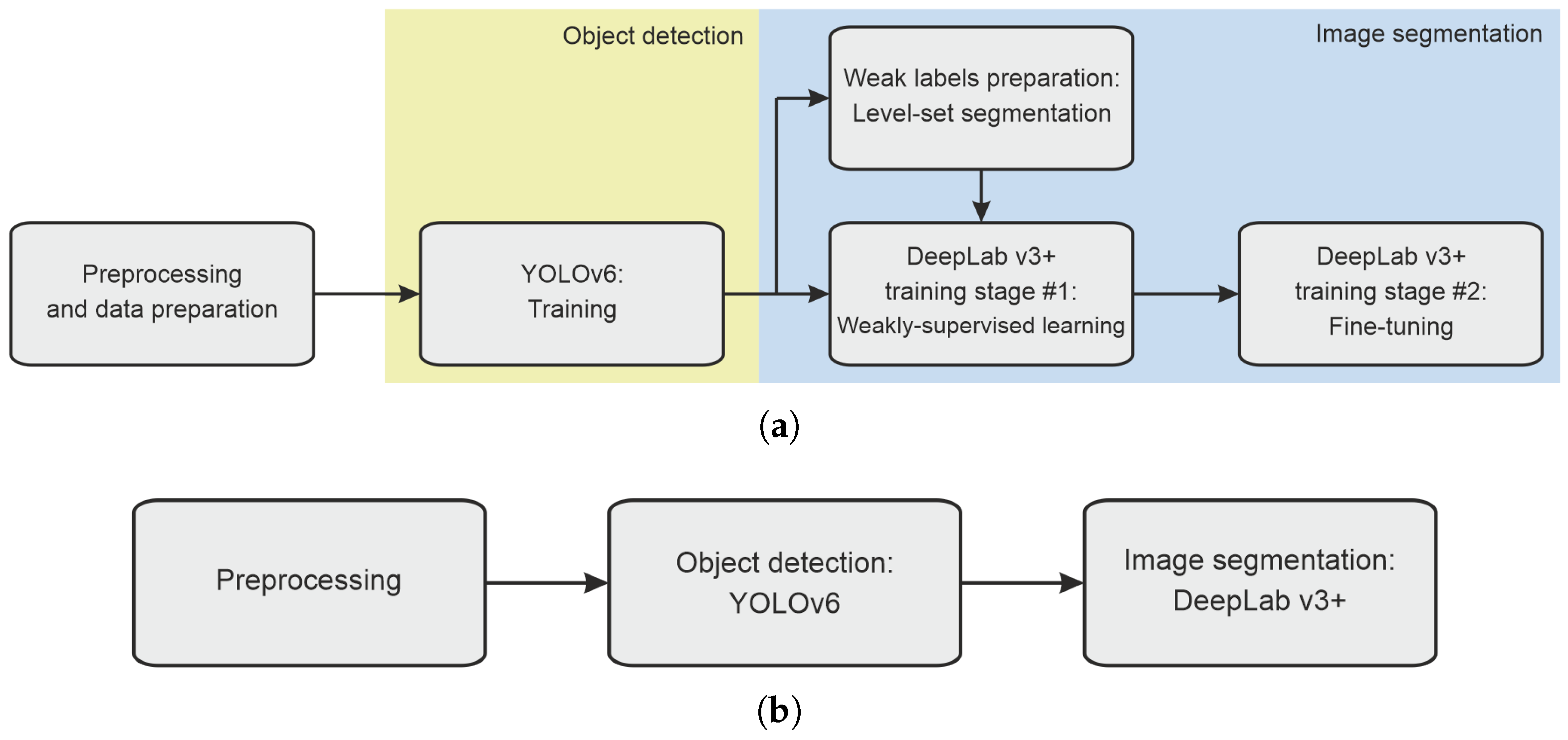
The proposed framework involves three stages of data analysis: (1) preprocessing and preparing the input data, (2) automated object detection using YOLOv6, (3) segmentation based on DeepLab v3+ model trained in two steps with weak labels prepared via initial segmentation using the level set approach. Figure 4 shows the data processing pipeline in two modes: training (Figure 4a) and regular operation (Figure 4b).
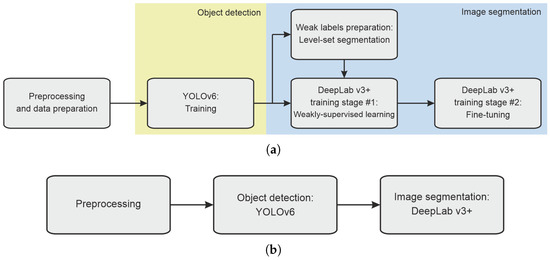
Figure 4.
The general workflow of the proposed method in training (a) and regular operation mode (b).
3.1. Preprocessing and Data Preparation for Training
Data preprocessing consists of image cropping and contrast-limited adaptive histogram equalization (CLAHE) [61]. The mouth region appears in a repeatable position in our data acquisition setup. Thus, we can safely crop the area of interest and limit the amount of data in the analysis. We empirically defined a cropping protocol with fixed settings for the left and right camera (Figure 5a), yielding frames of a 300 × 440 size. Since the cameras show the mouth in the upper part of the scene, we cut off the lower 180 rows. Moreover, 200 columns are excluded unevenly on both sides depending on the camera. Next, we equalize the image histogram to improve contrast, particularly in cases with poor external illumination. We use CLAHE with the empirically adjusted 8 × 8 grid size and contrast enhancement limit of 6.
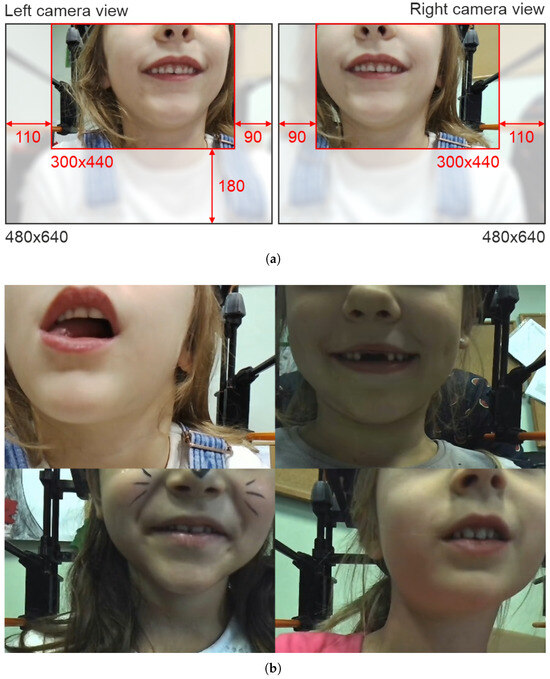
Figure 5.
Illustration of preprocessing procedures: initial frame cropping (a) and mosaic structuring for object detector training (b).
The additional data preparation stage is related to the object detector training. Our ultimate YOLOv6 training approach involves feeding the model with four-frame mosaics of original images organized in a 2 × 2 patchwork (Figure 5b). We employ mosaic input data to increase the number of class instances in a single image. Such an approach is often used as a type of data augmentation and, according to the literature, improves YOLO training performance [62,63]; our experiments with single-frame inputs support this claim. We also tried mosaics composed of more images, e.g., 3 × 3 and 5 × 5. However, large mosaics would require either working with YOLO of a larger input size (a significant increase in processing time) or reducing their size (a loss of information, especially in small objects like teeth or tongue). Thus, a 2 × 2 mosaic is a reasonable tradeoff between processing time and efficiency. We randomly partition the training data (subset A, 16,156 images) into four-element batches (4039 mosaics). In general, a single mosaic contains frames from various speakers. The mosaic size is 600 × 880 at that point.
3.2. Object Detection
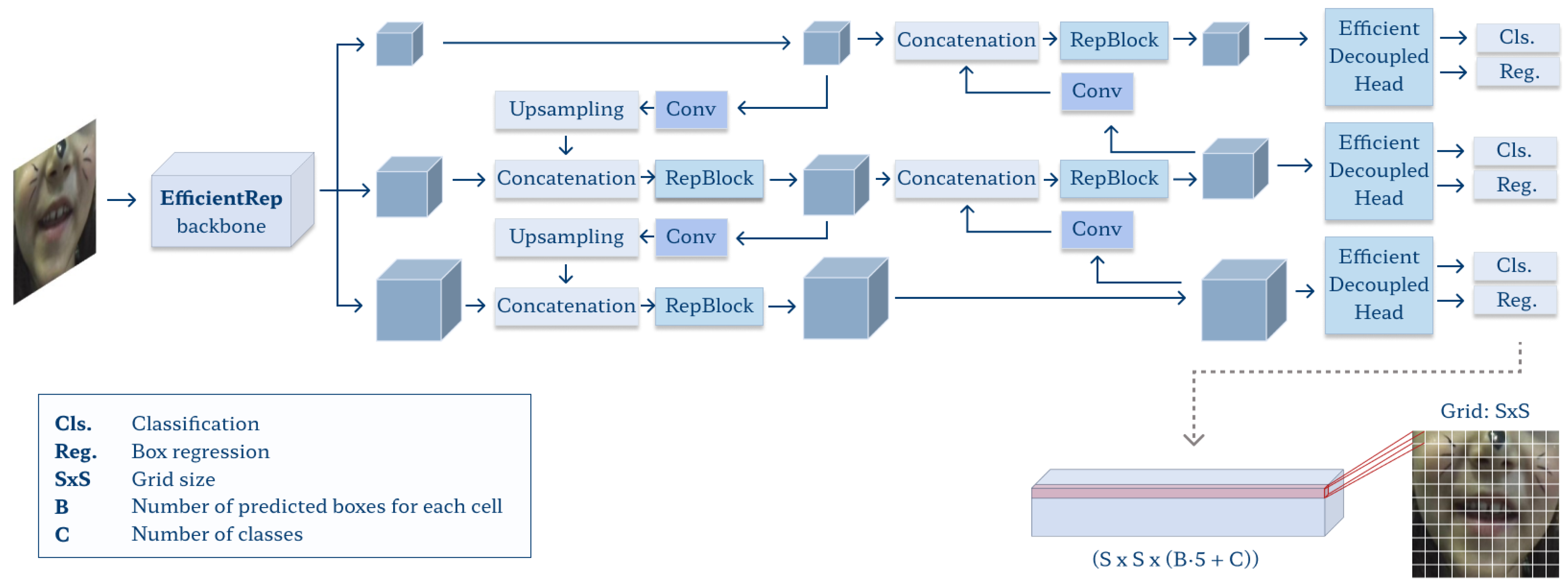
We use a YOLOv6 model [56] to perform automated lips, teeth, and tongue area detection (Figure 6). The network accepts square-shaped input data, so the image is resized using bilinear interpolation to match the required format (here, we use 320 × 320 pixel input size). We apply data augmentation in training: random distortions in the HSV color model (factors of 0.015, 0.7, and 0.4 for hue, saturation, and value, respectively), horizontal and vertical translation (±10% of image width and height), scaling (±50%), and horizontal flip (50% probability of occurrence). With 151 mosaics (604 images −4%, 10 children) extracted for validation, the training set consists of 3888 mosaics (15,552 images −96%, 25 children). We use the stochastic gradient-descent (SGD) optimizer with the number of epochs experimentally set to 300, the mini-batch size to 16, the initial learning rate to 0.02, and weight decay to 0.0005.
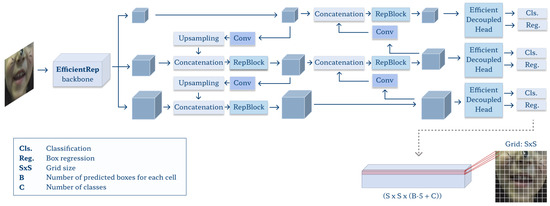
Figure 6.
Architecture of the YOLOv6 model.
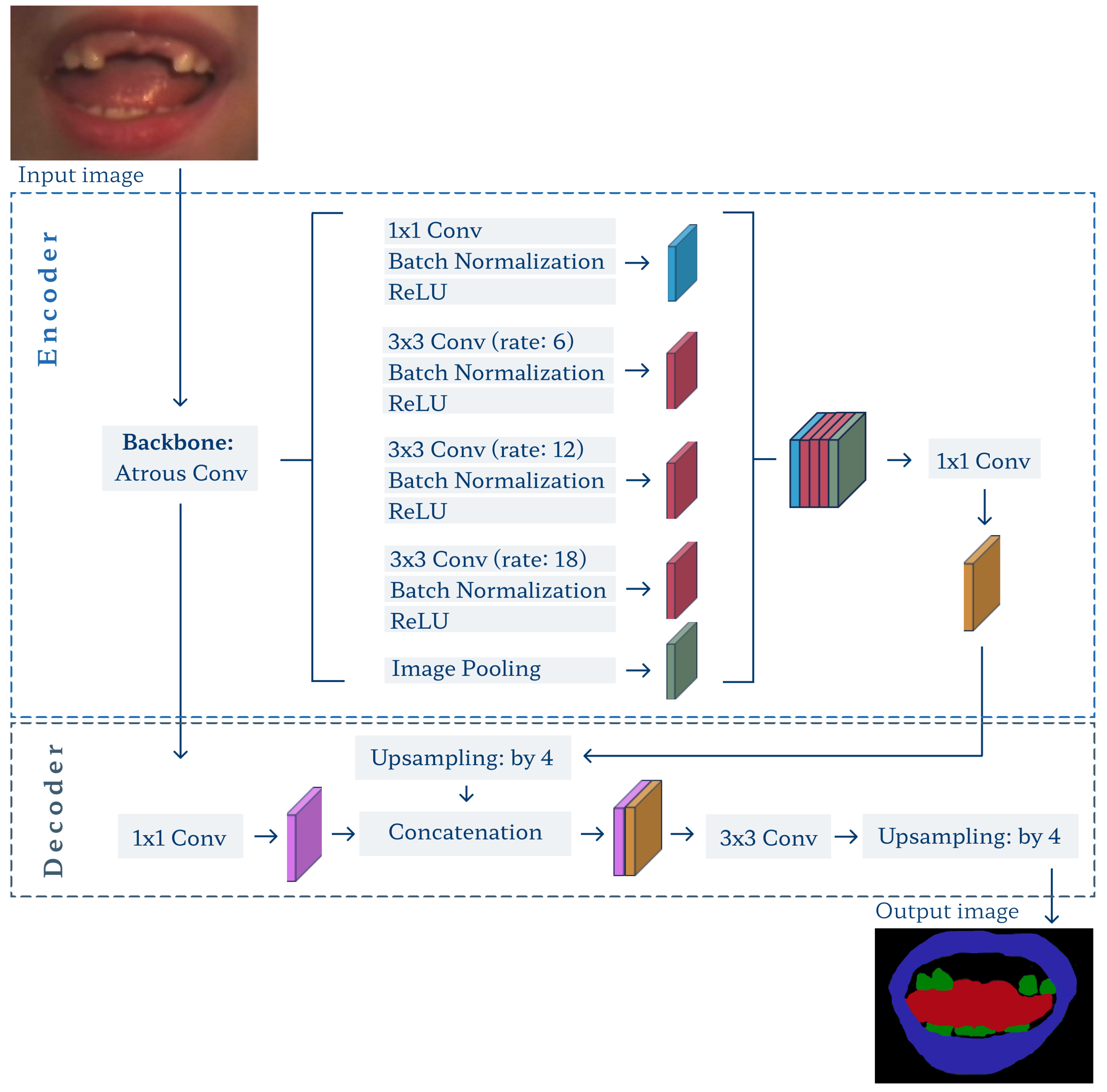
3.3. Image Segmentation
The core part of the proposed framework involves the DeepLab v3+ network [57,58]. We have chosen the model architecture guided by literature reports. Although multiple semantic segmentation approaches exist, the DeepLab v3+ network is among the most efficient in recent surveys [64,65,66,67]. It often outperforms conventional models like FCN or U-net due to the combination of advantages coming from [58,68]: depthwise separable convolutions (to reduce computation complexity), residual networks in the backbone (to extract features), atrous convolutions (to give larger information context), spatial pyramid pooling, and atrous pyramid pooling (both contribute to processing multi-scale features). The performance depends also on the residual network used as a backbone. We tested several backbone options and found Xception [69], pre-trained over the ImageNet, to be the most efficient for our problem. The training consists of three steps (Figure 4a): (1) initial segmentation using level sets over the training subset A to prepare coarse delineations, (2) weakly-supervised transfer learning of the ImageNet-pre-trained DeepLab v3+ model using weak labels, and (3) fine-tuning using subset B with manual delineations. We decided to design a semi-supervised two-step training to overcome the manual expert delineation availability issues.
The input image for segmentation is prepared based on the object detection result in a given frame. We determine the minimum rectangular bounding box that covers all objects’ regions of interest (ROI) produced by either YOLO (in weakly-supervised learning) or expert labeling (in fine-tuning). In most cases, it reflects the lips’ ROI, except for a few frames where the tongue extends beyond the lips. We crop the frame using the above ROI, leaving a three-pixel margin on either side.
3.3.1. Preparation of Weak Labels Using Level Set Segmentation
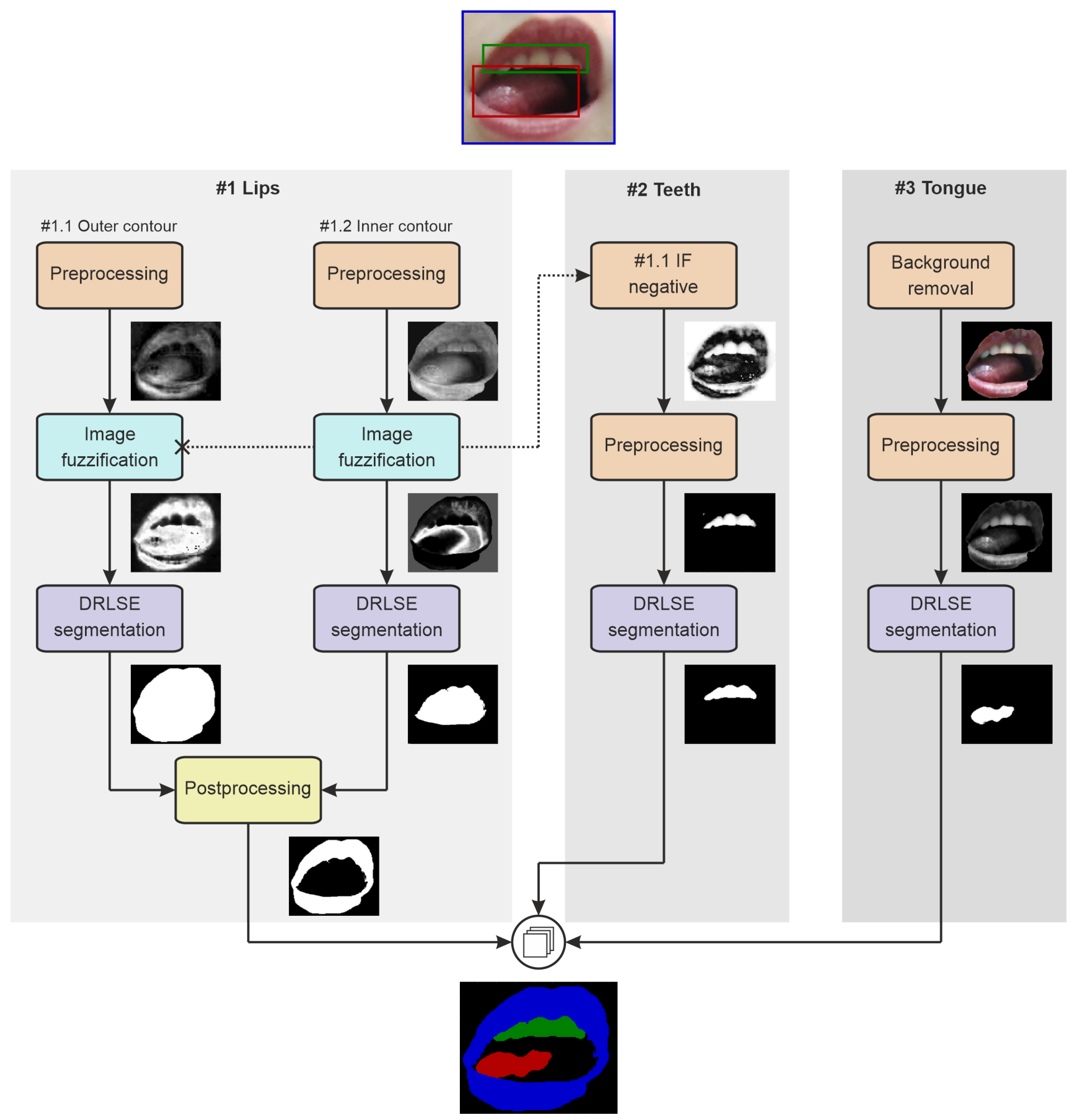
The coarse delineations of three articulators are produced by a multi-branch approach based on multiple instances of the distance-regularized level set evolution (DRLSE) [70] (Figure 7).
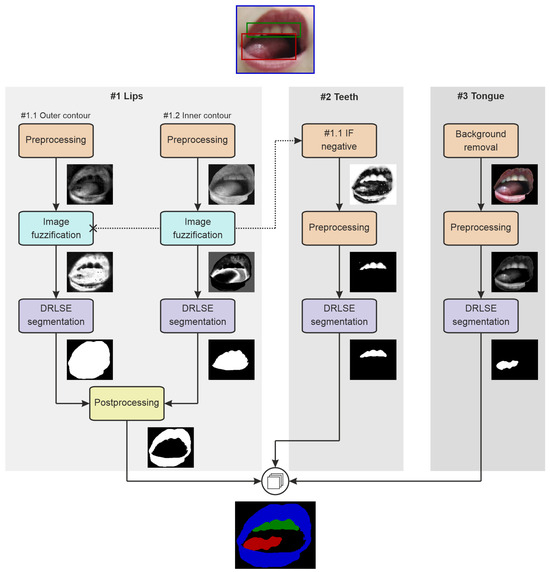
Figure 7.
The general workflow of initial segmentation for preparation of weak labels.
Lips
Segmentation of lips (path #1 in Figure 7) splits into two branches: finding the outer and inner contours. The external contour determination (#1.1 in Figure 7) starts with subtracting the red and green channels of the RGB frame to intensify lip pixels. Then, we define image fuzzification curve parameters using statistical measures of the initial lip region intensities (mean and standard deviation). We use a Gaussian fuzzy membership function to transform the image to the 0–1 range for the DRLSE [71], whose initial contour is the lips ROI from YOLO. The level set evolution parameters are weighted-area coefficient , weighted-length coefficient , Dirac delta width , Gaussian kernel scale , and 125 iterations. Finally, we adjust the DRLSE outcome through the morphological opening using a disk kernel of a five-pixel radius. The result at that point can be treated as a mask for the entire mouth region.
The inner lips contour analysis (Figure 7, path #1.2) involves only the red channel of the input image. Statistical measures of the central part of the ROI (limited by morphologically eroded mouth mask; a vertical kernel of a 5-pixel length to remove the lips) define the Gaussian fuzzification curve, which, in turn, should favor non-lip regions. The DRLSE finds the inner lips contours or, in fact, the external boundaries of the area between the lips, with the initial zero level set determined by the outer lips contour, and the evolution parameters experimentally set to , , , , and 100 iterations. Then, we adjust the outcome through morphological operations: removing single-pixel components, filling holes, and closing with a disk kernel of a five-pixel radius. The final lips mask comes from subtracting the current result from the mouth mask (path ).
Teeth
In the teeth segmentation pipeline (Figure 7, path #2), DRLSE operates on the complement of fuzzification result from branch #1.1 (outer lips). First, it is subjected to a grayscale morphological opening with a disk kernel of a two-pixel radius. Then, we zero all pixels outside the YOLO teeth ROI and all remaining pixels with intensities below the average intensity. The initial contour for DRLSE is the teeth bounding box from YOLO, and the DRLSE parameters are , , , , and 125 iterations.
Tongue
In tongue segmentation (Figure 7, path #3), the DRLSE input is the red channel of the frame masked with the binary mouth object (#1.1 outcome). The initial zero level set is the rectangular ROI of the tongue from YOLO. The contour evolves with the following parameters: , , , , and 125 iterations.
3.3.2. Deeplab v3+ Model
In both training stages, we use similar settings and parameters. We apply data augmentation, including random contrast adjustment (contrast factor of 0.1), translation (vertical and horizontal shift of up to ±10% of image height and width), rotation (), scaling (±10%), and horizontal flip (50% probability of occurrence). Training experiments favored the Adam optimizer and weighted cross-entropy loss as the most efficient. We set the training batch size to 16, the maximum number of epochs to 150 with the early-stopping strategy to avoid overfitting, and the initial learning rate to 0.001. A total of 10% of training images were taken out as validation data.
For training and segmentation, the input ROI and corresponding label image are resized to a 224 × 224 size required by the DeepLab v3+ model (Figure 8). Note that in the fine-tuning stage, which skips both the YOLO detector and level set segmentation, we have to crop the original frame based on objects’ ground-truth ROIs prepared manually over subset C. Again, we take the minimum overall bounding box plus a three-pixel margin.
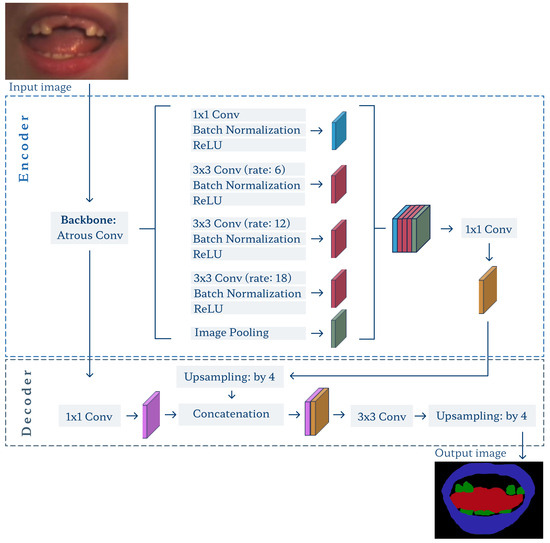
Figure 8.
Architecture of the DeepLab v3+ model.
The model was trained to extract three objects, the lips, teeth, and tongue, from the background. With its output, we can define the fourth and likely most important object: the whole mouth. In each case, it is defined as a union of all three classes with filled holes.
4. Experiments and Results
4.1. Object Detection
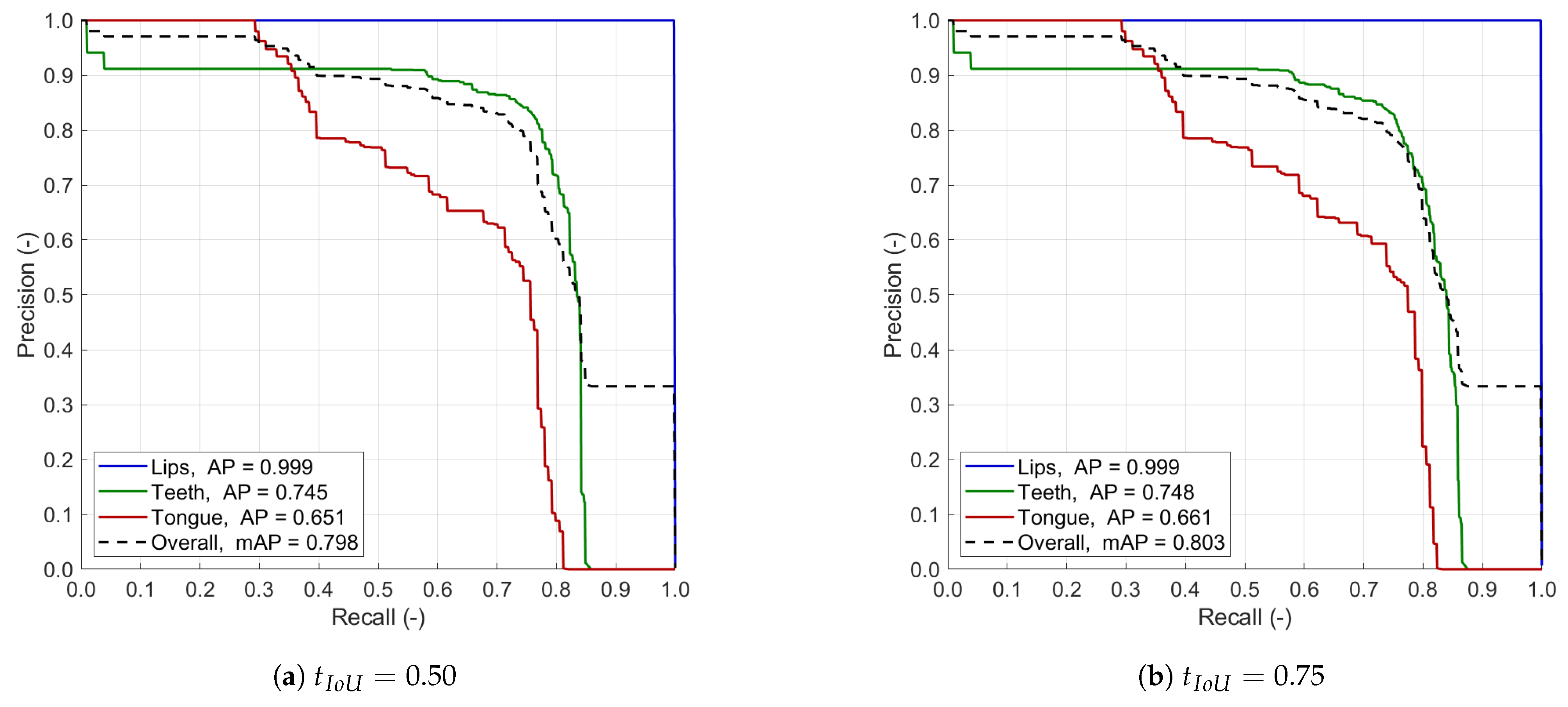
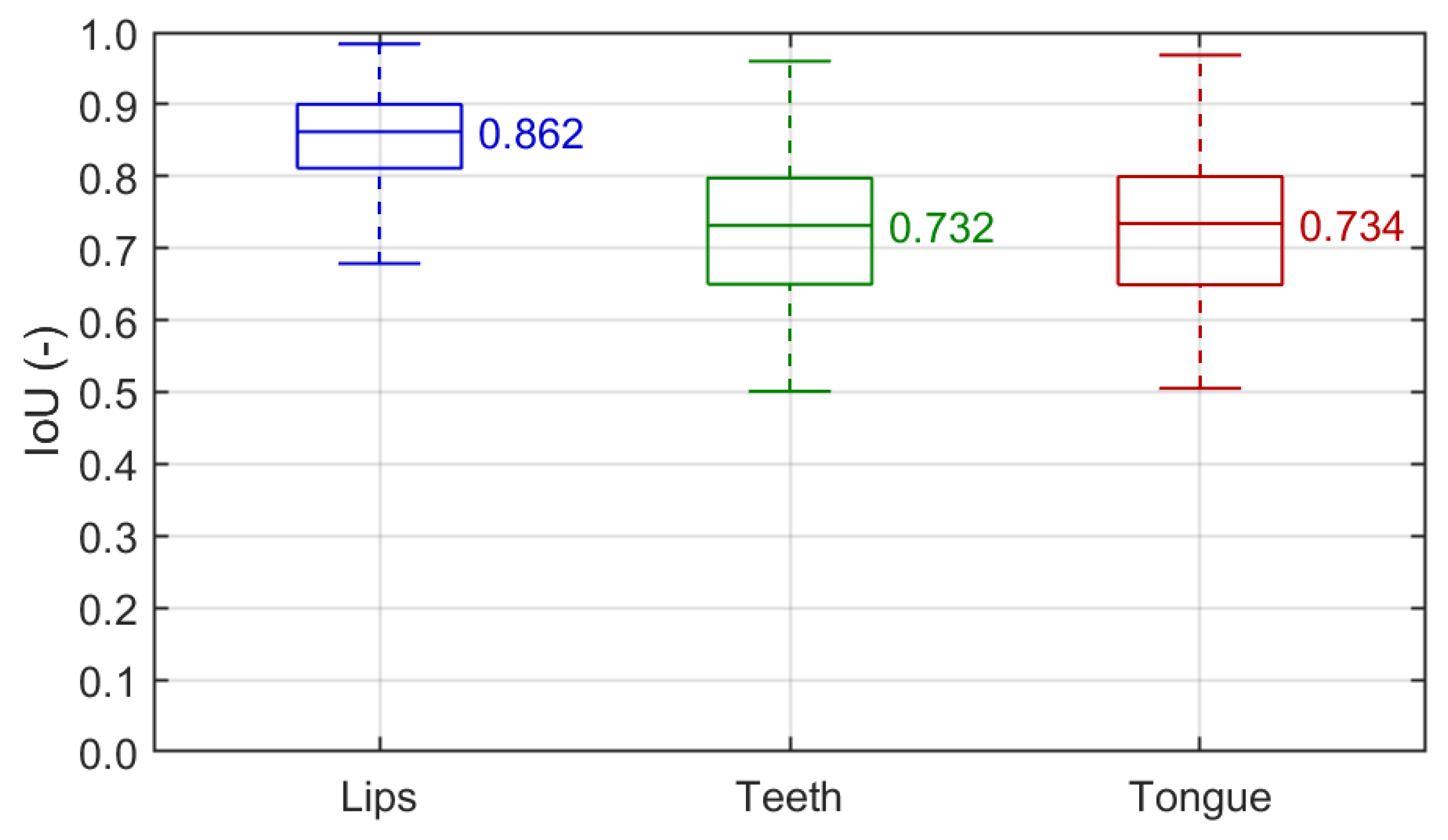
We performed several experiments to train and assess object detection. Measures commonly used in the field were used for evaluation over the test subset C: precision vs. recall curve (PvR), average precision (AP) for each articulator, mean average precision, and top F1 score. We also summarize the IoUs to show individual-match fidelity by measuring the spatial overlap between the target and detected ROIs in a single image.
Figure 9 shows the precision vs. recall curves with two different IoU thresholds of 0.50 and 0.75. Table 2 presents the class-wise and overall average precision and F1 score. The IoU box plots of successful detections used for the segmentation training are given in Figure 10. In general, the detection of lips is the most efficient of all classes, with an almost perfect PvR shape and AP and F1 measures. It is also the least sensitive to the IoU thresholding and output confidence level. The individual IoU rarely falls below 0.8, with a median of 0.862, indicating excellent detection agreement. That meets our primary goal, as the lips/mouth ROI is essential for further processing, e.g., by defining the input data for the segmentation pipeline. The other two articulators are detected at a solid level for the DRLSE-based preparation of weak labels. The PvR curves show that the top recall approachable is between 0.8 and 0.9 in both cases, so the model always misses some instances of teeth and tongue. Perfect precision is available in tongue with recall below 0.3 and practically unavailable in teeth. Overall, teeth detection performs better, as the average precision and F1 score are consistently greater than in tongue, though, once detected, both are identified with similar accuracy (the IoU of ca. 0.73 in Figure 10). The differences between results obtained with two thresholds are not significant. Hence, we decided to apply the lower threshold of 0.50 to the general workflow as it supports detecting smaller objects, which is vital in spotting teeth and tongue.
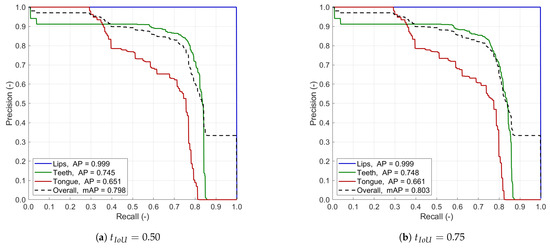
Figure 9.
Precision vs. recall curve obtained by our YOLOv6 model with the IoU threshold equal 0.50 (a) and 0.75 (b).
Table 2.
Summary of our object detection results using different IoU thresholds .
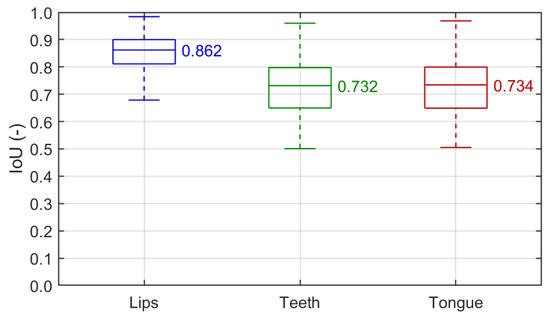
Figure 10.
Detection IoU box plots for individual classes (). Each box covers the interquartile range (IQR) with a median given and indicated by a central line. Whiskers refer to .
Our experiments slightly favor YOLOv6 architecture over other versions of YOLO (v3, v5–v7) [72,73,74]. Table 3 compares their performances in similar settings. The two oldest YOLOs (v3, v5) were outperformed by the two most recent ones in almost all measures. YOLOs v6 and v7 compete in particular articulators, with v6 being significantly better in tongue and v7 more accurate regarding the F1 score in teeth. With a similar overall F1 score and better average precision, YOLO v6 is our selection for object detection.
Table 3.
Comparison of state-of-the-art object detectors to our YOLOv6 approach (). Bold font indicates top values.
4.2. Image Segmentation
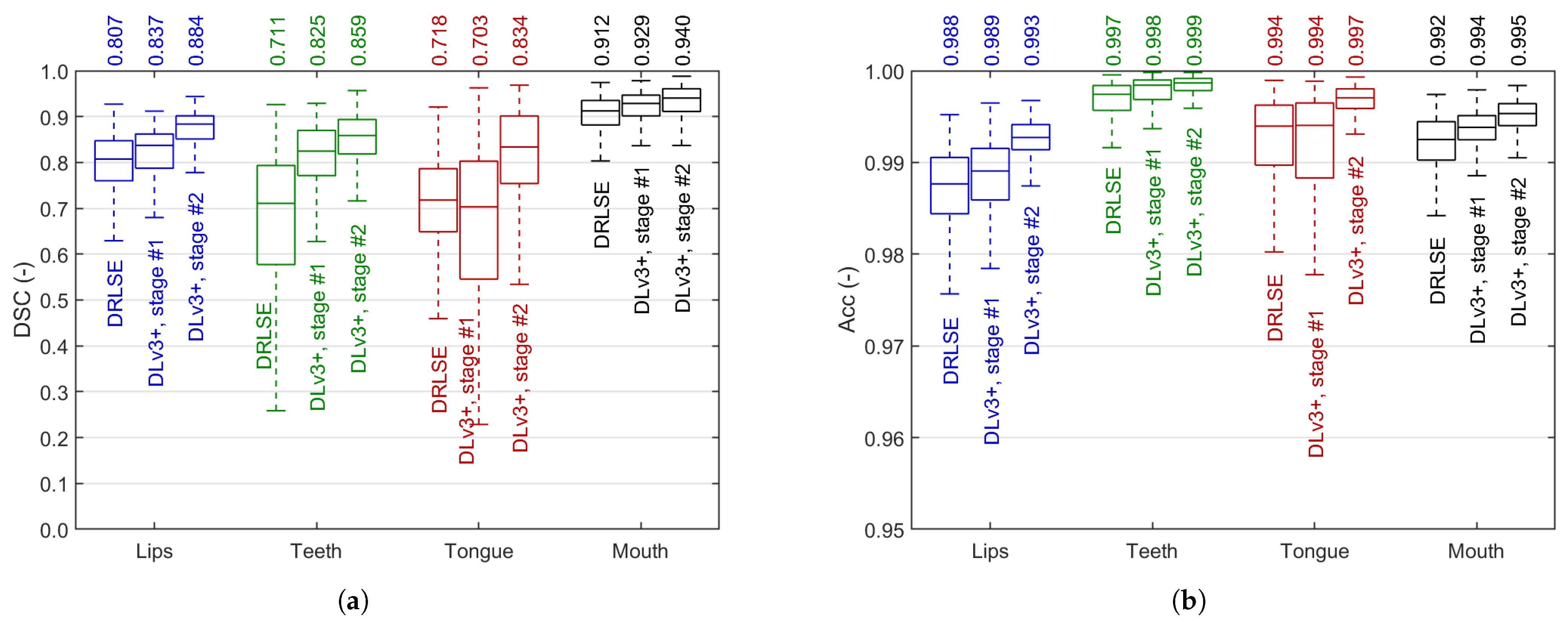
We used pixel-wise Dice similarity coefficient (DSC) and accuracy (Acc) to assess all stages of the segmentation workflow. Using frames from subset C, we validated the segmentation performance of each of the three blocks from the blue part of Figure 4a: (1) DRLSE initial segmentation, (2) weakly-trained DeepLab v3+ model, and (3) fine-tuned DeepLabv3+. Figure 11 presents the results in all four classes, including the whole mouth. In both cases, the segmentation results consistently improve in subsequent stages except for the tongue, where the efficiency slightly drops in weakly supervised training, and is raised significantly by fine-tuning.
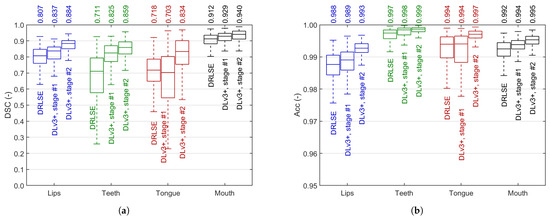
Figure 11.
Image segmentation results: Dice similarity coefficient (a) and accuracy (b) in each segmentation stage. Each box covers the interquartile range (IQR) with a median given above and indicated by a central line. Whiskers refer to .
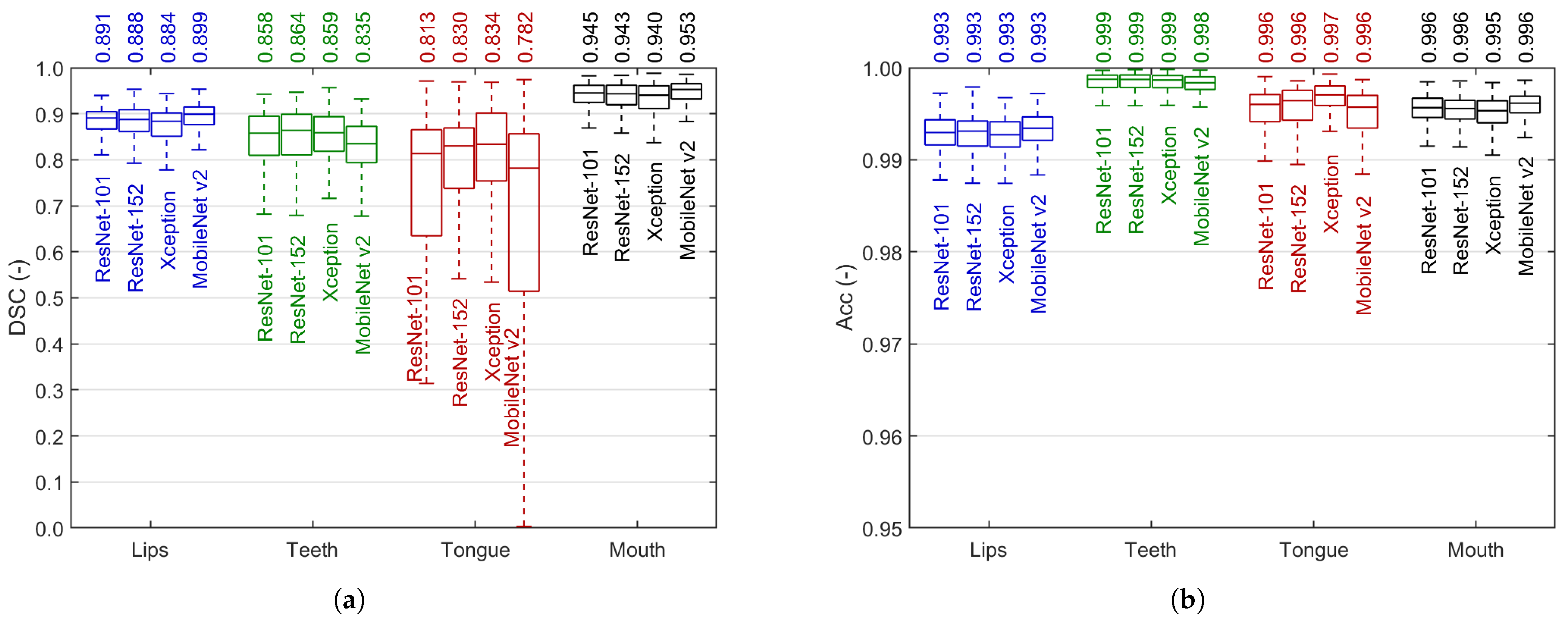
Figure 12 reports the experiments with four DeepLabv3+ backbones: ResNet-101, ResNet-152, Xception, and MobileNet v2. The top median DSC reaches 0.953 in mouth, 0.899 in lips, 0.864 in teeth, and 0.834 in tongue, with the accuracy above 0.99 in either case. These results were obtained in cases where the detection was successful (the number of true positive pixels is greater than zero). When taking misdetected cases into consideration, the median DSC does not change in lips and mouth, slightly falls in teeth (0.857), and more noticeably decreases in tongue (0.796). In general, the models trade off the efficiency in larger and smaller objects. We discuss this issue and justify our decision to choose the Xception backbone in Section 5. Three sample segmented stereo recordings are added as Supplementary Material to this paper to show the performance of our method.
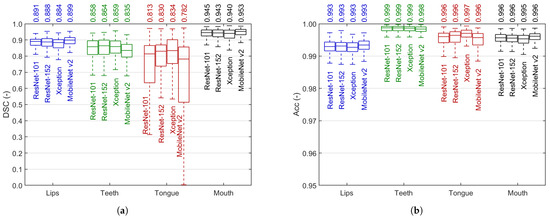
Figure 12.
Comparison of image segmentation results: Dice similarity coefficient (a) and accuracy (b) after full semi-supervised training in various DeepLab v3+ backbone selections. Each box covers the interquartile range (IQR) with a median given above and indicated by a central line. Whiskers refer to .
4.3. Time Consumption and Processing Speed
The experiments involved Python 3.7 (TensorFlow and PyTorch deep learning framework) and Matlab (R2022b) on a workstation with an 8-Core CPU @3.70 GHz, 64 GB RAM, and Nvidia Quadro RTX 6000 24 GB GPU. Processing a single frame took ms ( ms in object detection, including preprocessing, and ms in frame segmentation). Thus, we can analyze 16.5 frames per second (8.3 stereo shots per second), which excludes real-time processing in the current setup, primarily due to the DeepLab v3+ limitations. However, the framework is ready for asynchronous CADS applications and open for reimplementation involving parallel computing and other optimization concepts.
5. Discussion
The experiments presented in Section 4 justify our methodology by indicating high segmentation efficiency for the lips, teeth, tongue, and mouth. A reliable face image analysis tool is a solid basis for a more in-depth analysis of speech disorders in children. We can use the obtained regions to extract different features. Since we use stereo video streaming, we can think of a variety of clues derived not only from plain-image texture or shape but also from three-dimensional objects formed by concatenating data from subsequent frames. A stereovision presentation of the data is also possible in the current setup [38]. As our dataset contains corresponding audio data and comprehensive expert SLP annotations, we can now hybridize the video and acoustic information to prepare a multivariate statistical analysis of the possibility of detecting speech disorders based on automated data analysis. That opens perspectives for an efficient and broadly applicable CASD tool, as no similar approaches are reported.
Recall that our primary goal in this study was to design robust segmentation supported by effective object detection using an extensive image dataset without a need to perform an exhausting and time-consuming expert delineation of objects under consideration. Therefore, we implemented a semi-supervised learning framework merging machine learning and soft computing concepts. The process follows the rules of art supported by our ideas, e.g., preparing weak labels through DRLSE segmentation over a fuzzified image. The main novelty can be found in (1) segmenting various articulators for CASD, especially tongue and teeth, which have not been studied in this matter, and (2) integrating multi-purpose instances of deep learning and fuzzy computations and proposing a semi-supervised approach over an extensive and diversified dataset to solve significant real-life CASD problems in children. The model meets our expectations regarding quality, but the study brings several issues to the discussion.
YOLOv6 offers efficient object detection at levels sufficient for our objectives. The teeth and tongue were moderately difficult to detect. The tongue detection issues are its color (often resembling lips), mostly small area, ambiguous contours, dark conditions inside the mouth, and relatively rare frequency of occurrence. Teeth detection suffers from variability in the completeness of the dentition, distribution of teeth, their sizes and shapes, and being covered by the lips and tongue. However, both articulators were detected accurately enough to prepare a reliable base for initial segmentation. Note that the ultimate model does not rely directly on teeth or tongue detection. On the other hand, lips detection is as essential in regular image segmentation as in training. The results in Section 4.1 indicate practically perfect detection (AP and F1 score at 0.999) with an outstanding fidelity (median IoU of 0.862). Hence, all our goals for object detection were met. We tested and compared multiple versions of YOLO and confirmed YOLOv6 trained with mosaic-type input data was the most robust.
A two-step training of the DeepLab v3+ model is justified by the results presented in Figure 11. In all articulators, the step-by-step progress is noticeable and consistent. The rough DRLSE-based segmentation sets the fair starting point for the method: a median DSC from 0.718 in tongue to 0.912 in mouth. These results are significantly raised by intensive weakly-supervised transfer learning using over 16k images with DRLSE-made labels (we can observe a drop in median DSC after the first training stage only in tongue). Fine-tuning using ca. 6% of all frames available for training brings further considerable progress. However, the decision to select the final backbone for our model is not obvious. Figure 12 indicates the tradeoff in segmentation efficiency between the smaller and more irregular objects (teeth and tongue) and the larger lips and mouth. The latter are extracted better by ResNets and MobileNet v2 (top mouth DSC of 0.953), but their advantage is tiny in absolute differences. On the other hand, the results indicate the tongue is the most challenging to extract, and the differences between the models are more significant. The Xception model offers the highest and least dispersed results here, so we pick this backbone for our ultimate model. Moreover, of the two most effective backbones in tongue and teeth segmentation, Xception is smaller and faster than ResNet-152. However, such a tradeoff leaves the opportunity to make a selection later, at the image feature specification and extraction stage. Further research can determine whether it is better to correctly define the overall shape of the mouth or the boundaries of the inner organs (e.g., the tongue).
In general, the teeth and tongue are the most difficult to detect and segment for several reasons mentioned before (teeth: multiple tiny gray objects; tongue: variable shape and covering by teeth or lips; both: illumination issues). Therefore, we are satisfied with the median segmentation Dice index exceeding 0.83 in both cases with a fully-automated method, as it reaches the accuracy level obtained in our previous study involving better-illuminated and established tongue segmentation [55], being hardly comparable to significantly different TCM approaches to the tongue [49,50,51,52], and having no teeth segmentation benchmarks. Not surprisingly, the tongue requires special attention as it is not always detected correctly, particularly in small, covered, or poorly illuminated appearances. The DSC of over 0.88 in lips and over 0.94 in the mouth are rewarding too, comparable to or better than the state-of-the-art approaches trained on fine-labeled databases [44,45,46,55].
Labor time requirements regarding various parts of the study were different. The manual data annotation is the most time-consuming in such approaches, although the ROI labeling for object detection brings significantly less burden than the precise delineation of articulators. That was the main reason for designing a semi-supervised learning workflow with a small portion of strong ground-truth labels for fine-tuning. The training itself took relatively much time in multi-instance level set segmentation and a standard few hours for training either of the models. The ultimate framework takes 60.5 ms to process a single frame, which enables fast, though not real-time, processing of a 30-fps stereo stream. The stereo processing rate is ca. 3.6× the stream frame rate, so our ca. 2 min recordings can be segmented in ca. 7 min without additional implementation optimization. It safely meets asynchronous CASD requirements, and a synchronous mode is not a distant prospect.
We can point out some limitations of the study. First, the analysis is sensitive to lips detection, especially if the ROI is underestimated, as the false negative area is highly unwelcome. Thus, we apply outer margins to the YOLO outcome to avoid missing parts of the mouth during segmentation. It is better to segment a too-large patch than a too-narrow one. Second, we noticed some level of sensitivity to scene illumination. Our database contains frames with various brightness and contrast levels due to external light or skin tone. Thus, it is still advisable to retrain the model later using diverse data for higher robustness. In the current study, we addressed this issue with intense data augmentation. Note also that our database is prominent in the field of CASD, where the research often relies on fewer than a dozen cases. Third, we are aware that the tongue is definitely the most challenging of all objects and leaves room for improvement. Further study on feature extraction can bring additional feedback to improve the segmentation. Nonetheless, we believe that the texture analysis of the correctly delineated mouth area can provide relevant information also produced by the tongue appearance. Finally, the current study follows a relatively strict recording protocol that does not distract the articulation process and secures a stable, unobstructed view with a fixed scene. In a more flexible setup, e.g., involving a steady laptop camera to capture a moving head of a child, the methodology has to be validated and possibly adjusted for remote CASD. However, recall that we currently aim at finding and describing relationships between face image features, acoustic clues, and the nature of articulation. Our framework meets the requirements and expectations in this matter.
6. Conclusions
The automated framework for mouth area segmentation proposed in this paper can reliably analyze the speaker’s face. We developed and verified a multistage approach to detecting and segmenting articulators during pronunciation. The framework involves two up-to-date models: YOLO for the detection and DeepLab v3+ for the segmentation, both adjusted in the experiments. We designed a semi-supervised learning workflow to train the segmentation model and assessed all intermediate stages. The method proved its robustness and speed over an extensive database in different conditions. The mouth area was detected with the average precision and F1 score both at 0.999, while the Dice coefficient in the segmentation reached 0.88, 0.86, 0.83, and 0.94 in lips, teeth, tongue, and mouth, respectively. The study is ready to move towards investigating relationships between the image indicators, acoustic cues, and speech therapy diagnosis.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/app14167146/s1.
Author Contributions
Conceptualization, A.S. and P.B.; methodology, A.S.; software, A.S.; validation, A.S. and P.B.; formal analysis, A.S. and P.B.; investigation, A.S. and P.B.; resources, A.S. and P.B.; data curation, A.S. and P.B.; writing—original draft preparation, A.S.; writing—review and editing, P.B.; visualization, A.S. and P.B.; supervision, P.B.; project administration, P.B.; funding acquisition, P.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by he National Science Centre, Poland, research project No. 2018/30/E/ST7/00525: “Hybrid System for Acquisition and Processing of Multimodal Signal in the Analysis of Sigmatism in Children”.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Bioethics Committee for Scientific Research at the Jerzy Kukuczka University of Physical Education in Katowice, Poland (Decision No. 3/2021, issued 25 February 2021).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| SLP | Speech and language pathologist |
| CASD | Computer-aided speech diagnosis |
| CAD | Computer-aided diagnosis |
| ROI | Region of interest |
| CLAHE | Contrast-limited adaptive histogram equalization |
| DRLSE | Distance-regularized level set evolution |
| CNN | Convolutional neural network |
| YOLO | You only look once |
| DLv3+ | DeepLabv3+ |
| IoU | Intersection-over-union |
| AP | Average precision |
| PvR | Precision vs. recall curve |
| DSC | Dice similarity coefficient |
| Acc | Accuracy |
References
- Fogle, P.T. Essentials of Communication Sciences & Disorders; Jones & Bartlett Pub Inc.: Burlington, MA, USA, 2022. [Google Scholar]
- Shipley, K.G.; McAfee, J.G. Assessment in Speech-Language Pathology: A Resource Manual; Plural Publishing, Inc.: San Diego, CA, USA, 2019. [Google Scholar]
- Scheideman-Miller, C.; Clark, P.; Smeltzer, S.; Carpenter, J.; Hodge, B.; Prouty, D. Two year results of a pilot study delivering speech therapy to students in a rural Oklahoma school via telemedicine. In Proceedings of the 35th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 10 January 2002. [Google Scholar] [CrossRef]
- Fairweather, G.C.; Lincoln, M.A.; Ramsden, R. Speech-language pathology teletherapy in rural and remote educational settings: Decreasing service inequities. Int. J. Speech Lang. Pathol. 2016, 18, 592–602. [Google Scholar] [CrossRef] [PubMed]
- Ministry of Science and Higher Education, (PL) Ministerstwo Edukacji i Nauki. Register of Schools and Educational Institutions, (PL) Rejestr Szkół i Placówek Oświaty. 2022. Available online: https://rspo.gov.pl/ (accessed on 18 January 2023).
- Campbell, D.R.; Goldstein, H. Evolution of Telehealth Technology, Evaluations, and Therapy: Effects of the COVID-19 Pandemic on Pediatric Speech-Language Pathology Services. Am. J. Speech Lang. Pathol. 2022, 31, 271–286. [Google Scholar] [CrossRef] [PubMed]
- Favot, K.; Marnane, V.; Easwar, V.; Kung, C. The Use of Telepractice to Administer Norm-Referenced Communication and Cognition Assessments in Children With Hearing Loss: A Rapid Review. J. Speech Lang. Hear Res. 2024, 67, 244–253. [Google Scholar] [CrossRef] [PubMed]
- Dural, R.; Ünal Logacev, O. Comparison of the computer–aided articulation therapy application with printed material in children with speech sound disorders. Int. J. Pediatr. Otorhinolaryngol. 2018, 109, 89–95. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yang, N.; Zhou, M.; Zhang, Z.; Yang, X. A configurable deep learning framework for medical image analysis. Neural Comput. Appl. 2022, 34, 7375–7392. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Chen, J.; Yu, S.; Li, K. Region-to-boundary deep learning model with multi-scale feature fusion for medical image segmentation. Biomed. Signal Process. Control. 2022, 71, 103165. [Google Scholar] [CrossRef]
- Guetari, R.; Ayari, H.; Sakly, H. Computer-aided diagnosis systems: A comparative study of classical machine learning versus deep learning-based approaches. Knowl. Inf. Syst. 2023, 65, 3881–3921. [Google Scholar] [CrossRef]
- Rabie, A.H.; Saleh, A.I. Diseases diagnosis based on artificial intelligence and ensemble classification. Artif. Intell. Med. 2024, 148, 102753. [Google Scholar] [CrossRef]
- Katz, W.; Mehta, S.; Wood, M.; Wang, J. Using Electromagnetic Articulography with a Tongue Lateral Sensor to Discriminate Manner of Articulation. J. Acoust. Soc. Am. 2017, 141, 57–63. [Google Scholar] [CrossRef]
- Kroos, C. Evaluation of the Measurement Precision in Three-dimensional Electromagnetic Articulography (Carstens AG500). J. Phon. 2012, 40, 453–465. [Google Scholar] [CrossRef]
- Wood, S.; Wishart, J.; Hardcastle, W.; Cleland, J.; Timmins, C. The use of Electropalatography (EPG) in the Assessment and Treatment of Motor Speech Disorders in Children with Down’s Syndrome: Evidence from two Case Studies. Dev. Neurorehabilit. 2009, 12, 66–75. [Google Scholar] [CrossRef] [PubMed]
- Cleland, J.; Timmins, C.; Wood, S.; Hardcastle, W.; Wishart, J. Electropalatographic Therapy for Children and Young People with Down’s Syndrome. Clin. Linguist. Phon. 2009, 23, 926–939. [Google Scholar] [CrossRef] [PubMed]
- Kochetov, A.; Savariaux, C.; Lamalle, L.; Noûs, C.; Badin, P. An MRI-based articulatory analysis of the Kannada dental-retroflex contrast. J. Int. Phon. Assoc. 2023, 54, 227–263. [Google Scholar] [CrossRef]
- Cunha, C.; Hoole, P.; Voit, D.; Frahm, J.; Harrington, J. The physiological basis of the phonologization of vowel nasalization: A real-time MRI analysis of American and Southern British English. J. Phon. 2024, 105, 101329. [Google Scholar] [CrossRef]
- Bilibajkić, R.; Vojnović, M.; Šarić, Z. Detection of Lateral Sigmatism using Support Vector Machine. Speech Lang. 2019, 2019, 322–328. [Google Scholar]
- Król, D.; Lorenc, A.; Święciński, R. Detecting Laterality and Nasality in Speech with the use of a Multi-channel Recorder. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2015, ICASSP’15, South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5147–5151. [Google Scholar] [CrossRef]
- Lorenc, A.; Król, D.; Klessa, K. An acoustic camera approach to studying nasality in speech: The case of Polish nasalized vowels. J. Acoust. Soc. Am. 2018, 144, 3603–3617. [Google Scholar] [CrossRef] [PubMed]
- Krecichwost, M.; Mocko, N.; Badura, P. Automated detection of sigmatism using deep learning applied to multichannel speech signal. Biomed. Signal Process. Control. 2021, 68, 102612. [Google Scholar] [CrossRef]
- Wei, S.; Hu, G.; Hu, Y.; Wang, R.H. A New Method for Mispronunciation Detection using Support Vector Machine based on Pronunciation Space Models. Speech Commun. 2009, 51, 896–905. [Google Scholar] [CrossRef]
- Valentini-Botinhao, C.; Degenkolb-Weyers, S.; Maier, A.; Nöth, E.; Eysholdt, U.; Bocklet, T. Automatic Detection of Sigmatism in Children. Int. J. Child Comput. Interact. 2012, 1–4. Available online: https://www.isca-archive.org/wocci_2012/valentinibotinhao12_wocci.html (accessed on 1 July 2024).
- Raman, N.; Nagarajan, R.; Venkatesh, L.; Monica, D.S.; Ramkumar, V.; Krumm, M. School-based language screening among primary school children using telepractice: A feasibility study from India. Int. J. Speech Lang. Pathol. 2019, 21, 425–434. [Google Scholar] [CrossRef] [PubMed]
- Coufal, K.; Parham, D.; Jakubowitz, M.; Howell, C.; Reyes, J. Comparing Traditional Service Delivery and Telepractice for Speech Sound Production Using a Functional Outcome Measure. Am. J. Speech Lang. Pathol. 2018, 27, 82–90. [Google Scholar] [CrossRef] [PubMed]
- Kokotek, L.E.; Washington, K.N.; Cunningham, B.J.; Acquavita, S.P. Speech-Language Outcomes in the COVID-19 Milieu for Multilingual Jamaican Preschoolers and Considerations for Telepractice Assessments. Am. J. Speech Lang. Pathol. 2024, 33, 1698–1717. [Google Scholar] [CrossRef]
- Hair, A.; Monroe, P.; Ahmed, B.; Ballard, K.J.; Gutierrez-Osuna, R. Apraxia World: A Speech Therapy Game for Children with Speech Sound Disorders. In Proceedings of the 17th ACM Conference on Interaction Design and Children, New York, NY, USA, 27–30 June 2018; IDC ’18. pp. 119–131. [Google Scholar] [CrossRef]
- Ahmed, B.; Monroe, P.; Hair, A.; Tan, C.T.; Gutierrez-Osuna, R.; Ballard, K.J. Speech-driven mobile games for speech therapy: User experiences and feasibility. Int. J. Speech Lang. Pathol. 2018, 20, 644–658. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Kim, M.; Kim, J.; Song, T.J. Smartphone-Based Speech Therapy for Poststroke Dysarthria: Pilot Randomized Controlled Trial Evaluating Efficacy and Feasibility. J. Med. Internet Res. 2024, 26, e56417. [Google Scholar] [CrossRef]
- Dudy, S.; Bedrick, S.; Asgari, M.; Kain, A. Automatic analysis of pronunciations for children with speech sound disorders. Comput. Speech Lang. 2018, 50, 62–84. [Google Scholar] [CrossRef] [PubMed]
- Rusz, J.; Hlavnička, J.; Tykalová, T.; Novotný, M.; Dušek, P.; Šonka, K.; Růžička, E. Smartphone Allows Capture of Speech Abnormalities Associated with High Risk of Developing Parkinson’s Disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1495–1507. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, S.; Hasan, M.; Simons, A.J.H.; Brumfitt, S.; Green, P. A Lightly Supervised Approach to Detect Stuttering in Children’s Speech. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3433–3437. [Google Scholar] [CrossRef]
- Krecichwost, M.; Miodonska, Z.; Badura, P.; Trzaskalik, J.; Mocko, N. Multi-channel acoustic analysis of phoneme /s/ mispronunciation for lateral sigmatism detection. Biocybern. Biomed. Eng. 2019, 39, 246–255. [Google Scholar] [CrossRef]
- Kuo, Y.M.; Ruan, S.J.; Chen, Y.C.; Tu, Y.W. Deep-learning-based automated classification of Chinese speech sound disorders. Children 2022, 9, 996. [Google Scholar] [CrossRef]
- Miodonska, Z.; Badura, P.; Mocko, N. Noise-based acoustic features of Polish retroflex fricatives in children with normal pronunciation and speech disorder. J. Phon. 2022, 92, 101149. [Google Scholar] [CrossRef]
- Krecichwost, M.; Sage, A.; Miodonska, Z.; Badura, P. 4D Multimodal Speaker Model for Remote Speech Diagnosis. IEEE Access 2022, 10, 93187–93202. [Google Scholar] [CrossRef]
- Lucey, S.; Sridharan, S.; Chandran, V. Adaptive mouth segmentation using chromatic features. Pattern Recognit. Lett. 2002, 23, 1293–1302. [Google Scholar] [CrossRef]
- Leung, S.H.; Wang, S.L.; Lau, W.H. Lip Image Segmentation Using Fuzzy Clustering Incorporating an Elliptic Shape Function. IEEE Trans. Image Process. 2004, 13, 51–62. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.L.; Lau, W.H.; Liew, A.W.C.; Leung, S.H. Robust lip region segmentation for lip images with complex background. Pattern Recognit. 2007, 40, 3481–3491. [Google Scholar] [CrossRef]
- Guan, Y.P. Automatic extraction of lips based on multi-scale wavelet edge detection. IET Comput. Vis. 2008, 2, 23–33. [Google Scholar] [CrossRef]
- Müller, D.; Ehlen, A.; Valeske, B. Convolutional Neural Networks for Semantic Segmentation as a Tool for Multiclass Face Analysis in Thermal Infrared. J. Nondestruct. Eval. 2021, 40, 9. [Google Scholar] [CrossRef]
- Birara, M.; Gebremeskel, G.B. Augmenting machine learning for Amharic speech recognition: A paradigm of patient’s lips motion detection. Multimed. Tools Appl. 2022, 81, 24377–24397. [Google Scholar] [CrossRef]
- Miled, M.; Messaoud, M.A.B.; Bouzid, A. Lip reading of words with lip segmentation and deep learning. Multimed. Tools Appl. 2022, 82, 551–571. [Google Scholar] [CrossRef]
- Chotikkakamthorn, K.; Ritthipravat, P.; Kusakunniran, W.; Tuakta, P.; Benjapornlert, P. A lightweight deep learning approach to mouth segmentation in color images. Appl. Comput. Inform. 2022. [Google Scholar] [CrossRef]
- Zhu, G.; Piao, Z.; Kim, S.C. Tooth Detection and Segmentation with Mask R-CNN. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 070–072. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.E. Evaluating the Precision of Automatic Segmentation of Teeth, Gingiva and Facial Landmarks for 2D Digital Smile Design Using Real-Time Instance Segmentation Network. J. Clin. Med. 2022, 11, 852. [Google Scholar] [CrossRef] [PubMed]
- Lin, B.; Xle, J.; Li, C.; Qu, Y. Deeptongue: Tongue Segmentation Via Resnet. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1035–1039. [Google Scholar] [CrossRef]
- Zhou, C.; Fan, H.; Li, Z. Tonguenet: Accurate Localization and Segmentation for Tongue Images Using Deep Neural Networks. IEEE Access 2019, 7, 148779–148789. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Q.; Zhang, B.; Chen, X. TongueNet: A Precise and Fast Tongue Segmentation System Using U-Net with a Morphological Processing Layer. Appl. Sci. 2019, 9, 3128. [Google Scholar] [CrossRef]
- Huang, Z.; Miao, J.; Song, H.; Yang, S.; Zhong, Y.; Xu, Q.; Tan, Y.; Wen, C.; Guo, J. A novel tongue segmentation method based on improved U-Net. Neurocomputing 2022, 500, 73–89. [Google Scholar] [CrossRef]
- Bílková, Z.; Novozámský, A.; Domínec, A.; Greško, Š.; Zitová, B.; Paroubková, M. Automatic Evaluation of Speech Therapy Exercises Based on Image Data. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 397–404. [Google Scholar] [CrossRef]
- Bilkova, Z.; Bartos, M.; Dominec, A.; Gresko, S.; Novozamsky, A.; Zitova, B.; Paroubkova, M. ASSISLT: Computer-aided speech therapy tool. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 598–602. [Google Scholar] [CrossRef]
- Sage, A.; Miodońska, Z.; Kręcichwost, M.; Trzaskalik, J.; Kwaśniok, E.; Badura, P. Deep Learning Approach to Automated Segmentation of Tongue in Camera Images for Computer-Aided Speech Diagnosis. In Advances in Intelligent Systems and Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 41–51. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- ArduCam. Arducam 8MP 1080P Auto Focus USB Camera Module with Microphone. 2019. Available online: https://www.arducam.com/product/b0197arducam-8mp-1080p-auto-focus-usb-camera-module-with-microphone-1-3-2-cmos-imx179-mini-uvc-usb2-0-webcam-board-with-3-3ft-1m-cable-for-windows-linux-android-and-mac-os/ (accessed on 20 March 2023).
- Kręcichwost, M.; Miodońska, Z.; Sage, A.; Trzaskalik, J.; Kwaśniok, E.; Badura, P. PAVSig: Polish multichannel Audio-Visual child speech dataset with double-expert Sigmatism diagnosis. Sci. Data 2024, in press. [Google Scholar]
- Musa, P.; Rafi, F.A.; Lamsani, M. A Review: Contrast-Limited Adaptive Histogram Equalization (CLAHE) methods to help the application of face recognition. In Proceedings of the 2018 Third International Conference on Informatics and Computing (ICIC), Palembang, Indonesia, 17–18 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zeng, G.; Yu, W.; Wang, R.; Lin, A. Research on Mosaic Image Data Enhancement for Overlapping Ship Targets. arXiv 2021, arXiv:2105.05090. [Google Scholar] [CrossRef]
- Hao, W.; Zhili, S. Improved mosaic: Algorithms for more complex images. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1684, p. 012094. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and Challenges of Image Segmentation: A Review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Cheng, J.; Li, H.; Li, D.; Hua, S.; Sheng, V.S. A Survey on Image Semantic Segmentation Using Deep Learning Techniques. Comput. Mater. Contin. 2023, 74, 1941–1957. [Google Scholar] [CrossRef]
- Ou, J.; Lin, H.; Qiang, Z.; Chen, Z. Survey of images semantic segmentation based on deep learning. In Proceedings of the 2022 IEEE 8th International Conference on Cloud Computing and Intelligent Systems (CCIS), Chengdu, China, 26–28 November 2022; pp. 456–463. [Google Scholar] [CrossRef]
- Khan, Z.; Yahya, N.; Alsaih, K.; Ali, S.; Meriaudeau, F. Evaluation of Deep Neural Networks for Semantic Segmentation of Prostate in T2W MRI. Sensors 2020, 3, 3183. [Google Scholar] [CrossRef] [PubMed]
- Fang, H. Semantic Segmentation of PHT Based on Improved DeeplabV3+. Math. Probl. Eng. 2022, 2022, 6228532. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Li, C.; Xu, C.; Gui, C.; Fox, M.D. Distance Regularized Level Set Evolution and Its Application to Image Segmentation. IEEE Trans. Image Process. 2010, 19, 3243–3254. [Google Scholar] [CrossRef]
- Badura, P.; Wieclawek, W. Calibrating level set approach by granular computing in computed tomography abdominal organs segmentation. Appl. Soft Comput. 2016, 49, 887–900. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Tkianai, L.; Hogan, A.; Fang, J.; Yu, L.; Wang, M.; Akhtar, O.; et al. Ultralytics/yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation. 2020. Available online: https://zenodo.org/records/4154370 (accessed on 1 July 2024).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).